OpenAI: 我们开发了一个非监督的系统,能够很好地表征情感。虽然研究中只是用亚马逊网站上的评论进行了训练,用于预测下一个字母。
一个线性模型使用这一表征,在一个小型但是被深度研究过的数据集 Stanford Sentiment Treebank上,获得了当下行业内最高的情感分析准度( 准确率达到91.8%,此前最好的只有90.2%),并且,这一非监督式的学习系统,在性能上也能与此前的监督式学习系统相媲美,使用的标签样本要少30-100倍。我们的表征还包含了一个独特的“情感神经元”(distinguish emotional neurons),这一神经元中包含了几乎所有的情感信号。
我们的系统击败了 Stanford Sentiment Treebank 数据集上的最佳的方法,同时使用的数据量有大幅地减少。
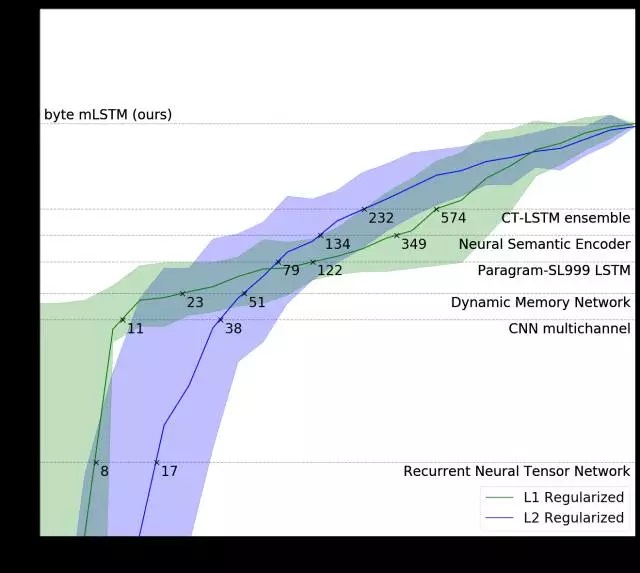
标注示例的数量需要我们模型的两个变体(绿色和蓝色线条),以配合完全监督的方法,每个训练有6,920个例子(虚线)。
我们的L1正则化模型(在亚马逊评论中以无监督的方式预先训练)将多通道CNN性能与11个带标记的示例相匹配,并且使用最先进的 CT-LSTM Ensembles与232个例子相匹配。
我们非常惊讶地看到,我们的模型学习了一个可解释的特征,并且通过发现情感概念,简单地预测出亚马逊评论中的下一个字符。我们认为这种现象不是我们的模型所特有的,而是一些大型神经网络的通用性质,这些大型神经网络被训练来预测其输入中的下一步或维度。
我们首先在8200万亚马逊评论的语料库上训练了4,096个单位的乘法LSTM,以预测一小段文本中的下一个字符。整个训练在四个NVIDIA Pascal GPU上花费了一个月的时间,我们的模型处理速度为每秒12,500个字符。
这4,096个单位(只是浮标的向量)可以被认为是表示模型读取的字符串的特征向量。在训练mLSTM后,我们采用这些单位的线性组合将模型转换为情感分类器,通过可用的监督数据学习组合的权重。
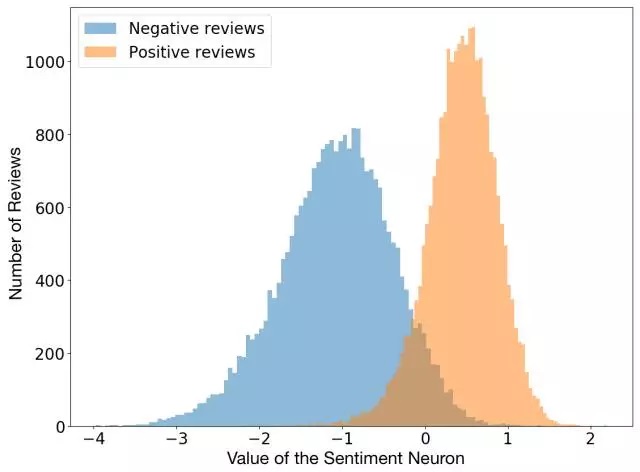
在用L1正则化训练线性模型的同时,我们注意到,它使用了的学习单位令人意外的少。深入挖掘后,我们意识到,实际上存在着一种高度预测情绪值的“情感神经元”。

我们模型中的情绪神经元可以将评论归为负面或正面,即使模型只是被训练来预测文本中的下一个字符。


就像类似的模型一样,我们的模型可以用来生成文本。与这些模型不同,我们用直接拨号(direct dial)来控制产出文字的情绪:我们只是重新设置了情绪神经元的value。
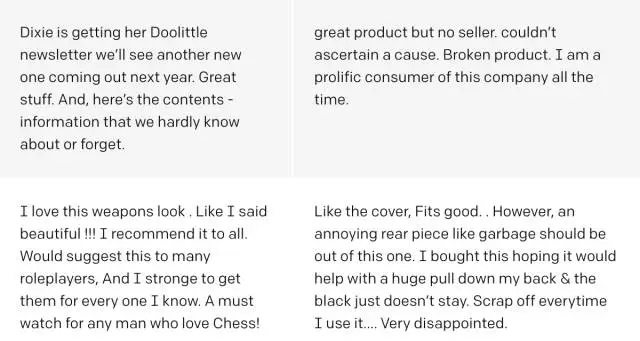
由训练模型生成的合成文本的示例。以上,我们在确定情绪单元的value后,从模型中选择随机样本,以确定评论中的情绪。下面,我们还通过模型传递前缀“我无法弄清楚”,并选择高相似度样本。
下图表示情绪神经元的字符到字符的符值(value),负值显示为红色和正值为绿色。请注意,像“最好的”或“可怕”这样强烈的指示性词语会引起颜色的特别大变化。

情感神经元以字符到字符的值为基础,逐个调整其value。

有趣的是,在完成句子和短语之后,系统也会进行大量更新。例如,在“约有99.8%的电影丢失”中,即使“影片中”本身没有任何情绪内容,“丢失”还有更新更新的消息。
标签数据是今天机器学习的燃料。收集数据很容易,但可扩展标记数据很难得到。人们一般在性价比可观,或者重要程度够高的问题上才会去给数据做标签,比如,机器翻译,语音识别或自驾驾驶。
机器学习研究人员长期以来一直梦想着开发无监督的学习算法来学习数据集的良好表征,然后可以仅使用几个标记的例子就能解决任务。
我们的研究证明。在创建具有良好表征学习能力的系统时,在大量的数据中,简单地训练一个大型的非监督式“下一步”预测模型,可能是一种很好的方法。
我们的结果对于迈向通用无监督表征学习(general unsupervised representation learning)是很有希望的一步。我们探索通过语言建模是否可以学习到优质表征,从而找到结果,并在精心挑选的数据集上扩大现有模型。然而,潜在的现象并没有变清晰,反而更神秘了。
这些结果对于长文档的数据集不是很强。我们怀疑我们的字符级别模型努力记住了数百到数千个时间段的信息。我们认为值得尝试用层次模型以适应他们的时间尺度。进一步扩大这些模型可能进一步提高表征、情绪分析和类似任务的保真度和性能。
这一模型处理越来越多的输入文本与评论数据分歧。值得验证的是,扩展文本样本的语料库可以获得同样适用于更广泛领域的信息表征。
我们的研究结果表明,存在一种设置使得超大的下一步预测模型(next-step-prediction models)能学到很好的无监督表征。训练一个大型神经网络以预测大量视频集合中的下一帧可能会得到对于对象、场景和动作分类器的无监督表征。
总的来说,了解模型的性质、训练方式和能够导致如此优秀的表征的数据集,这是非常重要的。