
今日,DeepMind 团队公布最强版 AlphaGo ,代号 AlphaGo Zero。它的独门秘籍,是“自学成才”。而且,是从一张白纸开始,零基础学习,在短短3天内,成为顶级高手。在对阵曾赢下韩国棋手李世石那版 AlphaGo 时,AlphaGo Zero 取得了100:0的压倒性战绩。
伦敦当地时间10月18日18:00,AlphaGo 再次登上世界顶级科学杂志――《自然》。
一年多前,AlphaGo 便是2016年1月28日当期的封面文章,Google旗下Deepmind公司重磅介绍了这个击败欧洲围棋冠军樊麾的人工智能程序。今年5月,以3:0的比分赢下中国棋手柯洁后,AlphaGo宣布退役,但 DeepMind 公司并没有停下研究的脚步。

此次,DeepMind团队公布最强版 AlphaGo ,代号 AlphaGo Zero。它的独门秘籍,是“自学成才”。而且,是从一张白纸开始,零基础学习,在短短3天内,成为顶级高手。
团队称,AlphaGo Zero 的水平已经超过之前所有版本的AlphaGo。在对阵曾赢下韩国棋手李世石那版AlphaGo时,AlphaGo Zero取得了100:0的压倒性战绩。
DeepMind团队将关于AlphaGo Zero的相关研究以论文的形式,刊发在了10月18日的《自然》杂志上,由此再次引起轰动,以下是国内外几位人工智能专家,对此给予的深度解析和点评。

1
新一代的AlphaGo Zero(阿法元), 完全从零开始,不需要任何历史棋谱的指引,更不需要参考人类任何的先验知识,完全靠自己一个人强化学习和参悟, 棋艺增长远超AlphaGo(阿法狗),百战百胜,击溃AlphaGo(阿法狗)100:0。
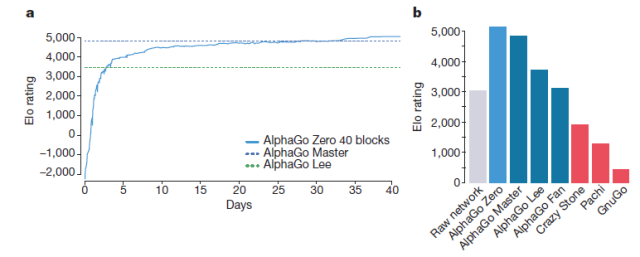
阿法狗元棋力的增长与积分比较
达到这样一个水准,阿法元只需要在4个TPU上,花三天时间,自己左右互搏490万棋局。而它的哥哥阿法狗,需要在48个TPU上,花几个月的时间,学习三千万棋局,才打败人类。

这篇论文的第一和通讯作者是 DeepMind 的 David Silver 博士,阿法狗项目负责人。他介绍说阿法元远比阿法狗强大,因为它不再被人类认知所局限,而能够发现新知识,发展新策略。

美国的两位棋手在Nature对阿法元的棋局做了点评:
它的开局和收官和专业棋手的下法并无区别,人类几千年的智慧结晶,看起来并非全错,但是中盘看起来则非常诡异。
美国杜克大学人工智能专家陈怡然教授也表示,这篇论文数据显示学习人类选手的下法虽然能在训练之初获得较好的棋力,但在训练后期所能达到的棋力却只能与原版的AlphaGo相近,而不学习人类下法的AlphaGo Zero最终却能表现得更好。
这或许说明人类的下棋数据将算法导向了局部最优,而实际更优或者最优的下法与人类的下法存在一些本质的不同,人类实际’误导’了AlphaGo。有趣的是如果AlphaGo Zero放弃学习人类而使用完全随机的初始下法,训练过程也一直朝着收敛的方向进行,而没有产生难以收敛的现象。
阿法元是如何实现无师自通的呢? 杜克大学博士研究生吴春鹏描述了技术细节:
在AlphaGo Zero出现之前,基于深度学习的增强学习方法按照使用的网络模型数量可以分为两类:一类使用一个DNN"端到端"地完成全部决策过程(比如DQN),这类方法比较轻便,对于离散动作决策更适用;另一类使用多个DNN分别学习policy和value等(比如之前战胜李世石的AlphaGoGo),这类方法比较复杂,对于各种决策更通用。
此次的AlphaGo Zero综合了二者长处,采用类似DQN的一个DNN网络实现决策过程,并利用这个DNN得到两种输出policy和value,然后利用一个蒙特卡罗搜索树完成当前步骤选择。
其次,AlphaGo Zero没有再利用人类历史棋局,训练过程从完全随机开始。AlphaGo Zero是在双方博弈训练过程中尝试解决对人类标注样本的依赖,这是以往没有的。
再者,AlphaGo Zero在DNN网络结构上吸收了最新进展,采用了ResNet网络中的Residual结构作为基础模块。之前大量论文表明,ResNet使用的Residual结构比GoogLeNet使用的Inception结构在达到相同预测精度条件下的运行速度更快。AlphaGo Zero采用了Residual应该有速度方面的考虑。
这个工作意义何在呢?人工智能专家、美国北卡罗莱纳大学夏洛特分校洪韬教授也发表了看法,他说:“我非常仔细从头到尾读了这篇论文。首先要肯定工作本身的价值。从用棋谱到扔棋谱,是重大贡献。神经网络的设计和训练方法都有改进,是创新。从应用角度,以后可能不再需要耗费人工去为AI的产品做大量的前期准备工作,这是其意义所在。”
洪教授还对人工智能做了并不十分乐观的展望:
回到阿法狗下棋这个事儿,伴随着大数据的浪潮,数据挖掘、机器学习、神经网络和人工智能突然间又火了起来。这次火的有没有料呢?我认为是有的,有海量的数据、有计算能力的提升、有算法的改进。这就好比当年把backpropagation用在神经网络上,的确是个突破。
最终这个火能烧多久,还得看神经网络能解决多少实际问题。二十年前的大火之后,被神经网络“解决”的实际问题寥寥无几,其中一个比较知名的是电力负荷预测问题,就是用电量预测,刚好是我的专业。
由于当年神经网络过于火爆,导致科研重心几乎完全离开了传统的统计方法。等我刚进入这个领域做博士论文的时候,就拿传统的多元回归模型秒杀了市面上的各种神经网络遗传算法的。我一贯的看法,对于眼前流行的东西,不要盲目追逐,要先审时度势,看看自己擅长啥、有啥积累,看准了坑再跳。
美国密歇根大学人工智能实验室主任Satinder Singh也表达了和洪教授类似的观点:这并非任何结束的开始,因为人工智能和人甚至动物相比,所知所能依然极端有限:
This is not the beginning of any end because AlphaGo Zero, like all other successful AI so far, is extremely limited in what it knows and in what it can do compared with humans and even other animals.
不过,Singh教授仍然对阿法元大加赞赏:这是一项重大成就, 显示强化学习而不依赖人的经验,可以做的更好:
The improvement in training time and computational complex¬ity of AlphaGo Zero relative to AlphaGo, achieved in about a year, is a major achieve¬ment… the results suggest that AIs based on reinforcement learning can perform much better than those that rely on human expertise.
陈怡然教授则对人工智能的未来做了进一步的思考:
AlphaGo Zero没有使用人类标注,只靠人类给定的围棋规则,就可以推演出高明的走法。有趣的是,我们还在论文中看到了AlphaGo Zero掌握围棋的过程。比如如何逐渐学会一些常见的定式与开局方法 ,如第一手点三三。相信这也能对围棋爱好者理解AlphaGo的下棋风格有所启发。
除了技术创新之外,AlphaGo Zero又一次引发了一个值得所有人工智能研究者思考的问题: 在未来发展中,我们究竟应该如何看待人类经验的作用。在AlphaGo Zero自主学会的走法中,有一些与人类走法一致,区别主要在中间相持阶段。AlphaGo Zero已经可以给人类当围棋老师,指导人类思考之前没见过的走法,而不用完全拘泥于围棋大师的经验。也就是说AlphaGo Zero再次打破了人类经验的神秘感,让人脑中形成的经验也是可以被探测和学习的。
陈教授最后也提出一个有趣的命题:
未来我们要面对的一个挑战可能就是:在一些与日常生活有关的决策问题上,人类经验和机器经验同时存在,而机器经验与人类经验有很大差别,我们又该如何去选择和利用呢?
不过David Silver对此并不担心,而对未来充满信心。他指出:
If similar techniques can be applied to other structured problems, such as protein folding, reducing energy consumption or searching for revolutionary new materials, the resulting breakthroughs have the potential to positively impact society.
以下为DeepMind David Silver 博士专访视频,中文字幕由Nature上海办公室制作:
>> 附:DeepMind David Silver 博士专访
您觉得哪一个突破更加关键呢?是阿法狗拜人为师最后打败老师,还是阿法元无师自通打败阿法狗?不妨留言告诉我们,并和大伙分享您对人工智能何去何从的看法。
更多讯息,请参见Nature论文链接http://nature.com/articles/doi:10.1038/nature24270


















