DeepMind������Լ�������������°�AlphaGo���ģ�Ҳ���������µ�Nature���ģ�������������ǿ���µİ汾AlphaGo Zero��ʹ�ô�ǿ��ѧϰ������ֵ����Ͳ�����������Ϊһ���ܹ���3��ѵ�������100��0��������һ�汾��AlphaGo��AlphaGo�Ѿ����ݣ����������档DeepMind�Ѿ����Χ���ϵĸ���֤����������������ǿ��ѧϰ����ı�����ļ�ֵ��
����5������Χ�����ʱ��DeepMind CEO Hassabis ��ʾ�����ڽ�����Щʱ��սʤ�˿½���ǰ�AlphaGo�ļ���ϸ�ڡ����죬�����ŵ��Լ���֣�DeepMind���������·�����Nature��һƪ�����У�������������ǿ���һ��AlphaGo���� AlphaGo Zero �ļ���ϸ�ڡ�
AlphaGo Zero��ȫ���������������ݣ���ˣ���һϵͳ�ijɹ�Ҳ�dz����˹������о�����������Ŀ�ꡪ���������û����������������£��������ս�Ե�����ʵ�ֳ�Խ�����������㷨����������һ��
������������д����AlphaGo Zero ֤���˼�ʹ�������ս������ǿ��ѧϰ�ķ���Ҳ����ȫ���еģ�����Ҫ�����������ָ�������ṩ��������������κ�����֪ʶ��ʹ��ǿ��ѧϰ�ܹ�ʵ�ֳ�Խ�����ˮƽ�����⣬��ǿ��ѧϰ����ֻ���Ѷ�����ٵ�ѵ��ʱ�䣬�����ʹ���������ݣ�ʵ���˸��õĽ������ܣ�asymptotic performance����
�ںܶ�����£��������ݣ�������ר�����ݣ�����̫�������߸�������á�������Ƶļ�������Ӧ�õ����������ϣ���Щͻ�ƾ��п��ܶ�������������Ӱ�졣
�ǵģ������Ҫ˵��AlphaGo�Ѿ��ڽ���5���������ݣ���AlphaGo�ļ��������棬����һ����ǰ��չ��������DeepMind�Ѿ����Χ���ϵĸ���֤���������������������ǵ�ǿ��ѧϰ�ı����硣
��Ҳ��Ϊʲô����������Ҫ���ܵ���ƪ���������Ҫ�����������Ǻܶ��������Ѿõļ������棬Ҳ���˹�����һ���µļ����ڵ㡣��δ���������õ��ܶ����ã���Ϊ����AI��ҵ�ͷ���Ļ�����
������ǿ���Χ�����ʹ�������֪ʶ
DeepMind��ƪ���µ�Nature����һ�����ص����֡�������ʹ������֪ʶ����Χ�塷��

ժҪ
�˹����ܳ���������һ��Ŀ���Ǵ���һ���ܹ��ھ�����ս�Ե������Գ�Խ����ľ�ͨ�̶�ѧϰ���㷨����tabula rasa������ע��һ����֪�۹����Ϊָ������û�����쾫�����ݵ�����µ��������е�֪ʶ�������ں���ľ�����֪������ǰ��AlphaGo��Ϊ����Χ����սʤ��������ھ���ϵͳ��AlphaGo����Щ������ʹ������ר����������ݽ��мලѧϰѵ����ͬʱҲͨ�����Ҷ��Ľ���ǿ��ѧϰ��
��������ǽ���һ�ֽ�����ǿ��ѧϰ���㷨����ʹ����������ݡ�ָ����������������֪ʶ��AlphaGo�����Լ�����ʦ������ѵ����һ����������Ԥ��AlphaGo�Լ�������ѡ���AlphaGo���Ҷ��ĵ�Ӯ�ҡ������������������������ǿ�ȣ�ʹ�����������ߣ����Ҷ��ĵ�����ǿ���ӡ�tabula rasa����ʼ�����ǵ���ϵͳAlphaGo Zeroʵ���˳��˵ı��֣���100��0�ijɼ������˴�ǰ������AlphaGo��
DOI��10.1038/nature24270
ȫ�µ�ǿ��ѧϰ���Լ���Ϊ�Լ�����ʦ
DeepMind �о���Ա���� AlphaGo Zero����Ƶ��Դ��DeepMind����Ƶ��Ӣ����Ļ��Nature �Ϻ��칫������
AlphaGo Zero �õ������Ľ������������һ���µ�ǿ��ѧϰ��ʽ������������У�AlphaGo Zero ��Ϊ�Լ�����ʦ�����ϵͳ��һ����Χ����Ϸ��ȫû���κ�֪ʶ�������翪ʼ��Ȼ��ͨ���������������һ��ǿ��������㷨���ϣ����Ϳ����Լ����Լ������ˡ��������Ҷ��ĵĹ����У������类���������£���Ԥ����һ������λ���Լ��Ծֵ�����Ӯ�ҡ�
������º���������ֽ��������㷨������ϣ���������һ���µġ���ǿ��� AlphaGo Zero �汾���ٴ��ظ�������̡���ÿһ�ε����У�ϵͳ�����ܶ��õ�һ�������ߣ����Ҷ��ĵ�����Ҳ����ߣ����ʹ���������Ԥ��Խ��Խȷ���õ�����ǿ��� AlphaGo Zero �汾��
���ּ�������һ�汾�� AlphaGo ��ǿ����Ϊ����������������֪ʶ�ľ��ޡ��෴�������Դ�һ�Ű�ֽ��״̬��ʼ������������ǿ���Χ����ҡ���AlphaGo ��������ѧϰ��
AlphaGo Zero ����������Ҳ��֮ǰ�İ汾������ͬ��
�����������Щ��֮ͬ�������������ϵͳ�����ܣ�ʹ�����ͨ�á���ʹ�����ϵͳ����ǿ���Ч�����㷨�ĸı䡣
�ڽ�����3�������ѵ����AlphaGo Zero ��100�ֱ�������100��0��������һ�汾�� AlphaGo��������һ�汾�� AlphaGo ��������18�λ��Χ������ھ��ĺ����Ŷ���ʿ�����h������ 40 �������ѵ����AlphaGo Zero ��ø���ǿ��Խ�ˡ�Master���汾�� AlphaGo����Master ���������������������ʿ�������һ�Ŀ½ࡣ
�ھ���������Ƶ� AlphaGo vs AlphaGo �Ķ��ĺ����ϵͳ���㿪ʼѧ������Χ�壬�ڶ̶̼����ڻ�����������ǧ����۵�֪ʶ��AlphaGo Zero Ҳ�������µ�֪ʶ���������dz���IJ��Ժʹ����Ե����·�����Щ���·���Խ��������½�������h����ʱ�������¼��ɡ�
����Ŀǰ�Դ������ڽΣ��� AlphaGo Zero ��Ϊ�˳������Ŀ�������Ĺؼ�һ����DeepMind ���ϴ�ʼ�˼� CEO Demis Hassabis ���۳ƣ���AlphaGo�ڶ̶�������ȡ����������˾�̾�ijɹ������ڣ�AlphaGo Zero��������Ŀ����ǿ��İ汾����չʾ�������ڸ��ٵļ���������������ȫ��ʹ���������ݵ�����¿���ȡ����˴�Ľ�չ��
�����գ�����ϣ�������������㷨ͻ�������������ʵ����ĸ��ֽ������⣬���絰�����۵����²�����ơ��������������Щ������ȡ����AlphaGoͬ���Ľ�չ�����п����ƶ��������⣬�������ǵ������������Ӱ�졣��
AlphaGo Zero ����ϸ�ڲ�⣺����ֵ����Ͳ�����������Ϊһ���ܹ����������ؿ����������ϵ���
�·���ʹ����һ����������� f��������Ϊ �ȡ���������罫ԭʼ���̱��� s������λ�ú���ʷ����Ϊ���룬������Ӹ��ʺ�һ��ֵ��p, v��= f�ȣ�s����
���Ӹ������� p ��ʾѡ����ÿһ���壨�������£��ĸ��ʡ�ֵ v ��һ��������ֵ��������ǰ������λ�� s ��ʤ�ĸ��ʡ�
��������罫����� AlphaGo�������е� AlphaGo Fan �� AlphaGo Lee���ֱ�ָ��ս����Ͷ�ս����ʯ�İ汾���IJ�������ͼ�ֵ�������ϵ�һ���ܹ�����кܶ���ھ���������IJв�ģ�飬��Щ�в�ģ����ʹ����������batch normalization���ͷ���������������rectifier nonlinearities����
AlphaGo Zero ��������ʹ�����Ҷ���������ѵ������Щ���Ҷ�������һ���µ�ǿ��ѧϰ�㷨����ɵġ���ÿ��λ�� s�������� f������������ؿ�����������MCTS����MCTS �����ÿ��������Ӹ��� �С����������ó��ĸ���ͨ���������� f�ȣ�s����ԭʼ���Ӹ��� p Ҫ����ǿһЩ��MCTS Ҳ��˿��Ա���Ϊһ������ǿ��IJ������� operator��
ϵͳͨ�������������Ҷ��ģ�Ҳ��ʹ����ǿ�Ļ��� MCTS �IJ���ѡ�����IJ��壬Ȼ��ʹ�û�ʤ�� z ��Ϊ��ֵ������������̿��Ա���Ϊһ��ǿ�����IJ������� operator��
��һ�µ�ǿ��ѧϰ�㷨�ĺ���˼���ǣ��ڲ��Ե����Ĺ����У�����ʹ����Щ���� operator��������IJ������ϸ��£������Ӹ��ʺͼ�ֵ��p,v��= f����s��Խ��Խ�ӽ����ƺ���������ʺ����Ҷ���Ӯ�ң���, z������Щ�µIJ���Ҳ��������һ�����Ҷ��ĵĵ�������������ǿ�������ͼ1 չʾ�����Ҷ���ѵ�������̡�
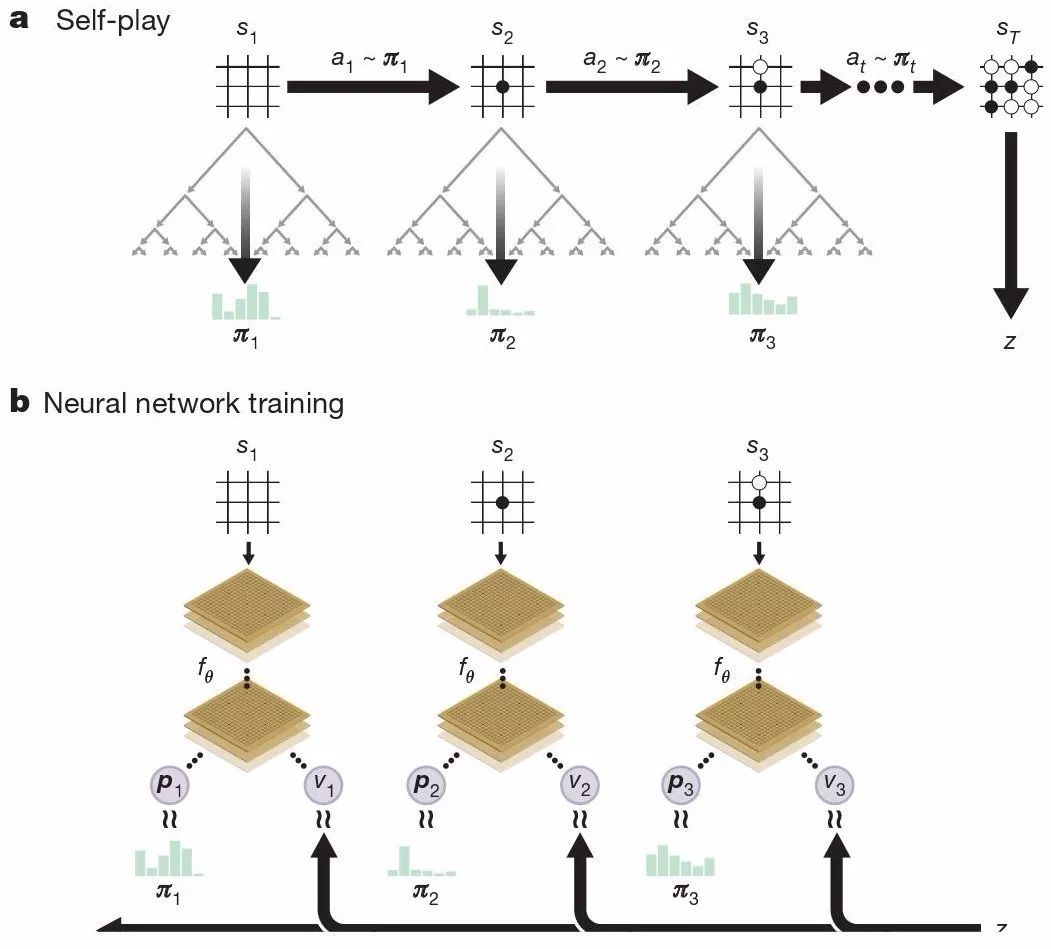
ͼ1��AlphaGo Zero ���Ҷ���ѵ�������̣�a. �����Լ����Լ����壬���Ϊs1, ..., sT����ÿ��λ��st��һ��MCTS ���ȱ�ִ�У���ͼ2����ʹ�����µ�������f�ȡ�ÿ������ѡ���������ͨ��MCTS, at ∼ ��t������������ʡ����յ�λ��sT������Ϸ�������Ծֵ�����ʤ��z��b. AlphaGo Zero ���������ѵ�����������罫����λ��st��Ϊ���룬�������һ�������͵�����ľ����㣬��ͬʱ�����ʾÿһ���ӵĸ��ʷֲ������� pt ��һ����ʾ��ǰ�����λ�� st �ϵ�Ӯ�ʵı���ֵ vt��
MCTS ʹ�������� f��ָ����ģ�⣨�μ�ͼ2�����������е�ÿ���ߣ�s, a�����洢��һ���������� P��s, a����һ�������� N��s, a�����Լ�����ֵ Q��s, a����ÿ��ģ�ⶼ�Ӹ��ڵ�״̬��ʼ�����ϵ�����ѡ���ܽ��������� Q��s, a��+ U��s, a�����ϲ�������ӽ����ֱ���ߵ�Ҷ�ڵ� s�䡣
Ȼ��������������Ҷ�ڵ㣬����ֻ����һ�����������ɸ������������ֵ����P��s��, ����, V��s�䣩��= f����s�䣩����ģ���У�����ÿ���ߣ�s, a������·����� N��s, a����Ȼ����ֵ���£�ȡ����ģ���ƽ��ֵ����
MCTS ���Ա�����һ�����Ҷ����㷨��������������� �� ��һ�����ڵ�λ�� s�������������������Ƽ����� �� = ������s������ÿ����ķ�����ָ�������ȣ��� ���¶Ȳ�������
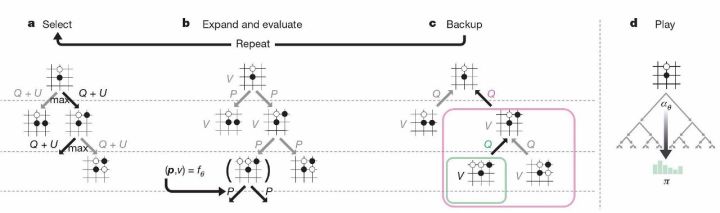
ͼ2��MCTS ʹ�������� f�� ģ������ѡ��Ĺ���ʾ��
������ʹ��������Ҷ��ĵ�ǿ��ѧϰ�㷨��ѵ�����������Ľ��ܣ�����㷨ʹ�� MCTS ��ÿһ���塣���ȣ�������ʹ�����Ȩ�� ��0��ʼ����������ÿһ�ε����У�i �� 1���������Ҷ������ף��μ�ͼ1��a������ÿ��ʱ�䲽�� t������һ�� MCTS ���� ��t= ������st����ʹ����һ�������� f��i−1�����Ľ����Ȼ������������ʲ����³�һ���塣һ�����ڵ� T ��������Ҳ����˫���������ӣ�����ֵ���͵���ֵ���µ�ʱ������мƷ֣��ó����� rT �� {−1,+1}��
ÿһ��ʱ�䲽�� t �����ݶ����洢Ϊ��st, ��t, zt�������� zt = �� rT ���Ǵӵ�ǰ�ⲽ�� t �������ջ�ʤ��Ӯ�ҡ�
ͬʱ���μ�ͼ1 b����ʹ�ô����һ�����Ҷ��ĵ���������ʱ�䲽���л�ȡ�����ݣ�s, ��, z�������µ�������� ��i ����ѵ�������������磨p, v��= f��i��s������Ԥ��ֵ v �����ҶԱ�ʤ�� z ֮������͵���С��ͬʱ�����������Ӹ��� p ���������� �� ֮������ƶ����������
����˵����������ʧ���� l ���ݶ��½������ڲ��� �ȣ������ʧ������ʾ���£����� c �ǿ��� L2 Ȩ������ˮƽ�IJ�������ֹ����ϣ���
���������21��ͱ�սʤ�½��Master��������
DeepMind�ٷ������Ͻ�����AlphaGo Zero���ǰ�汾�ĶԱȡ���ȫ���㿪ʼ��3�쳬ԽAlphaGo����ʯ�汾��21��ﵽMasterˮƽ��
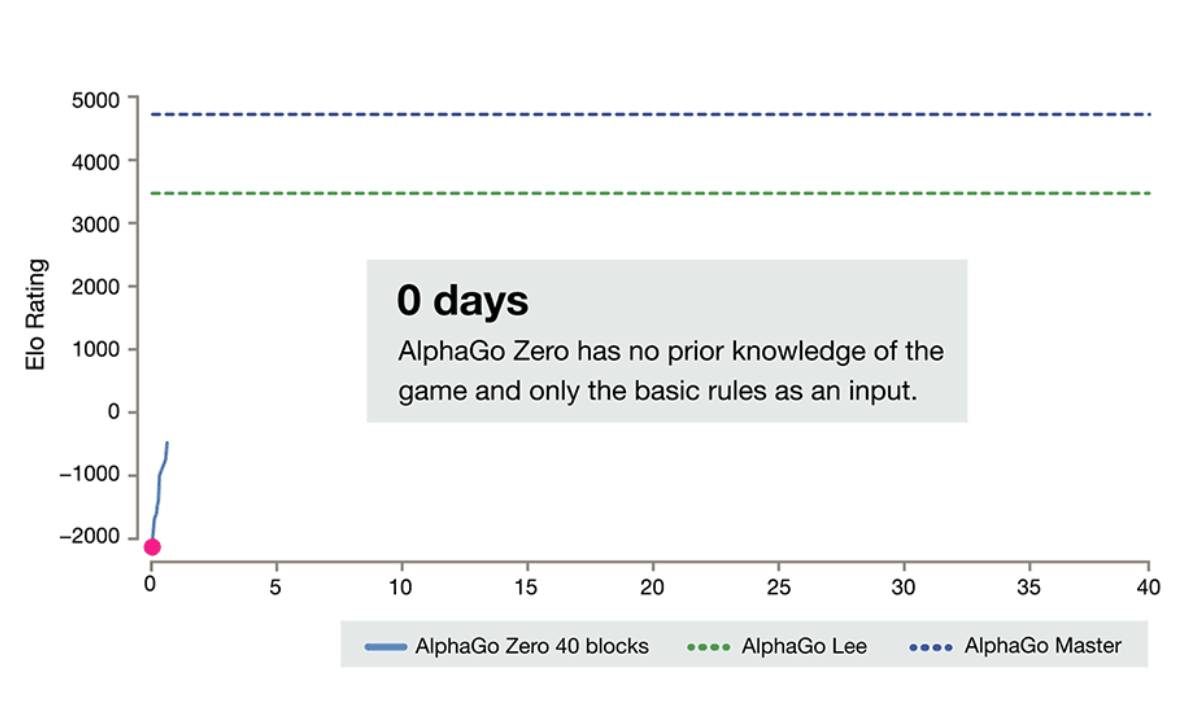
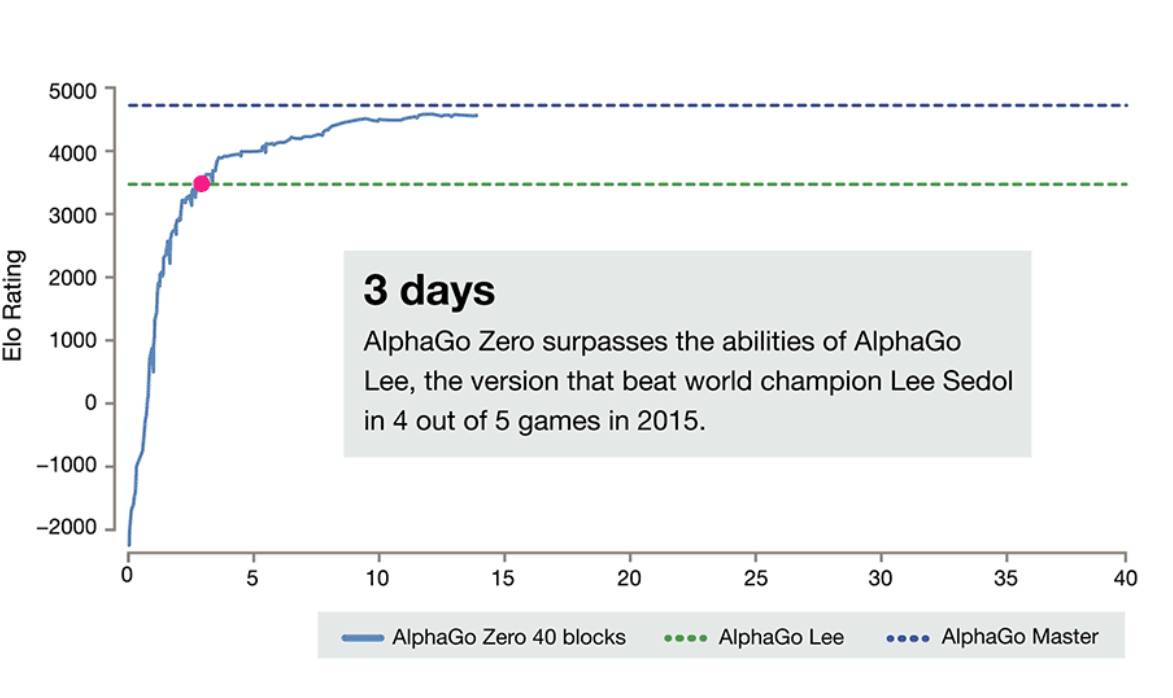
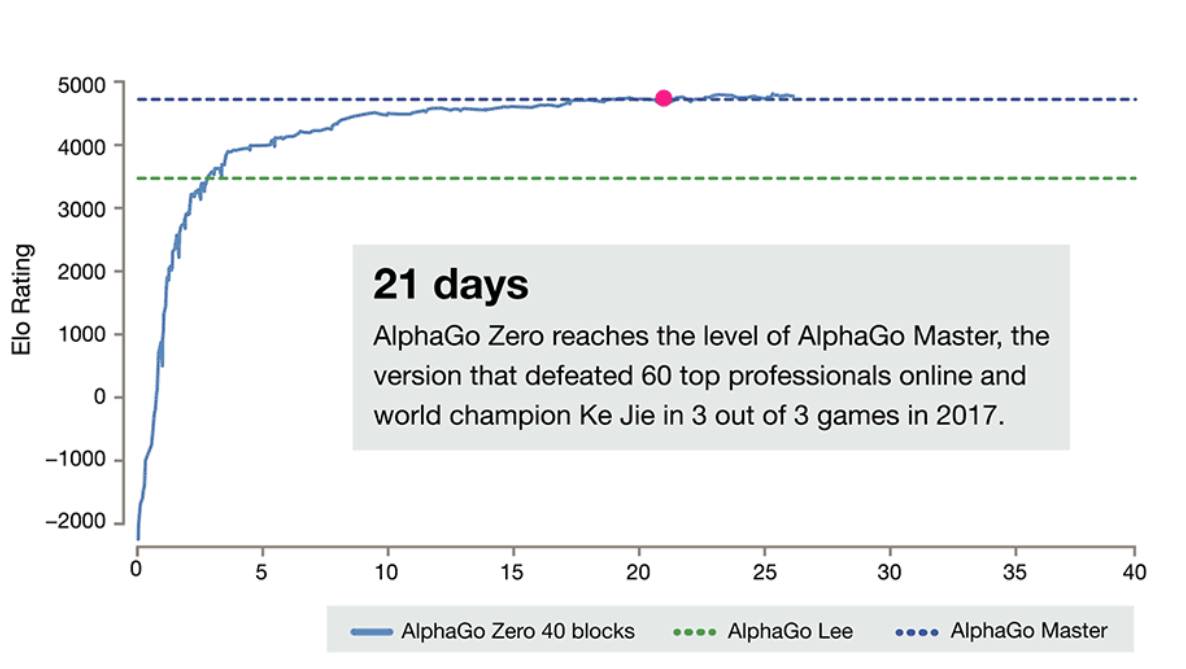
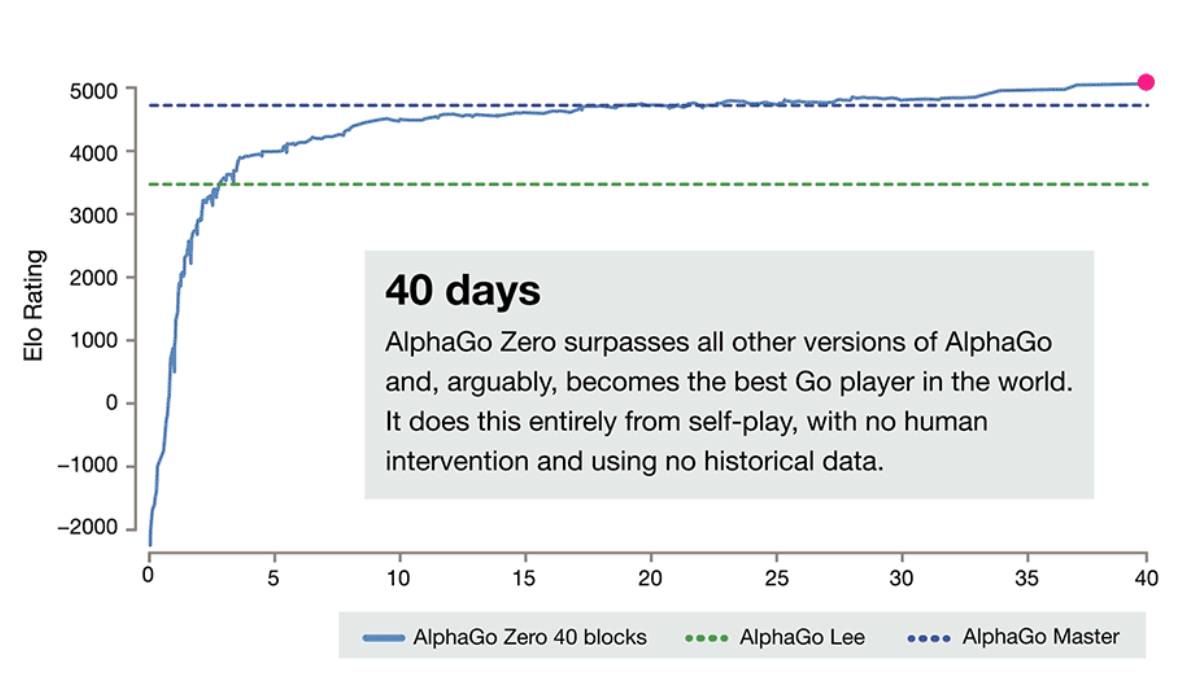
������ͬ�汾�ļ������Ա����£�
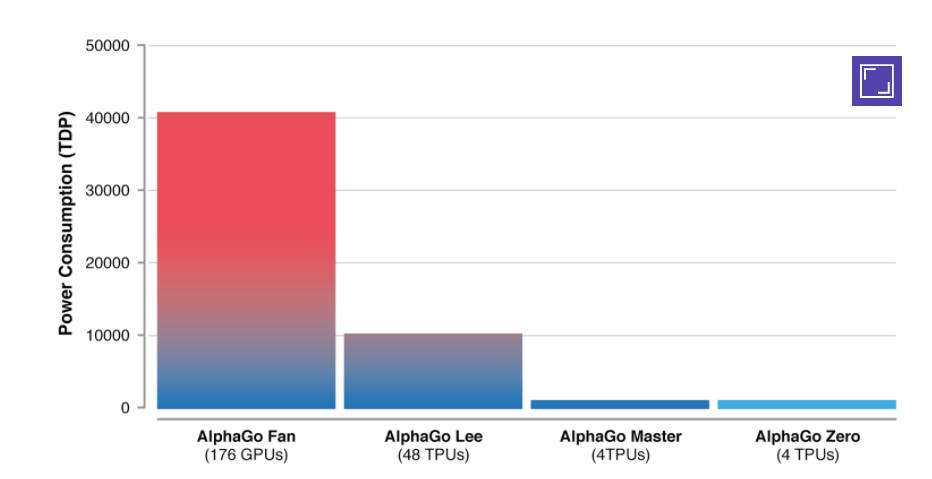
�����У�Ϊ�˷ֿ��ṹ���㷨�Ĺ��ף�DeepMind�о���Ա���Ƚ��� AlphaGo Zero ��������ܹ�����ǰ�������h����ʱ�� AlphaGo ����Ϊ AlphaGo Lee����������ܹ������ܣ���ͼ4����
���ǹ�����4�������磬�ֱ����� AlphaGo Lee ��ʹ�õķֿ��IJ�������ͼ�ֵ���磬������ AlphaGo Zero ��ʹ�õĺϲ��IJ��Ժͼ�ֵ���磻�Լ� AlphaGo Lee ʹ�õľ�������ܹ����� AlphaGo Zero ʹ�õIJв�����ܹ���ÿ�����綼��ѵ������С��ͬһ����ʧ��������ʽ1����ѵ��ʹ�õ��� AlphaGo Zero ��72Сʱ�����Ҷ���֮�������ͬһ�����Ҷ���������ݼ���
ʹ�òв������ȷ�ʸ��ߣ������ͣ��� AlphaGo �ﵽ600 Elo���ȼ��֣���������ߡ������ԣ�policy���ͼ�ֵ��value����ϵ�һ����һ�������еĻ�������Ԥ���ȷ���������ˣ����Ǽ�ֵ����Ҳ�����ˣ����ҽ� AlphaGo �������������600 Elo������һ���̶�������������˼���Ч�ʣ�������Ҫ���ǣ�˫Ŀ��ʹ�����Ϊ֧�ֶ�������ij����ʾ��
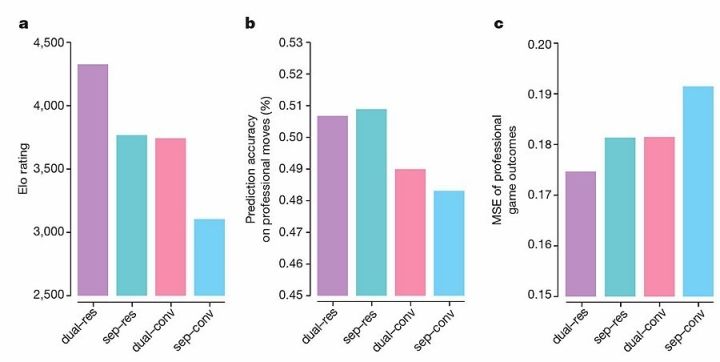
ͼ4��AlphaGo Zero �� AlphaGo Lee ��������ܹ��Ƚϡ�ʹ�÷ֿ��IJ��Ժͼ�ֵ�����Ϊ��sep����ʹ����ϵIJ��Ժͼ�ֵ�����Ϊ��dual����ʹ�þ��������Ϊ��conv����ʹ�òв������Ϊ��res������dual-res���͡�sep-conv���ֱ��ʾ�� AlphaGo Zero �� AlphaGo Lee ��ʹ�õ�������ܹ���ÿ�����綼��ͬһ�����ݼ���ѵ���������ݼ��� AlphaGo Zero �����Ҷ��IJ�����a��ÿ��ѵ���õ����綼�� AlphaGo Zero ���������ϣ��Եõ�һ����ͬ����ҡ�Elo�ȼ���������Щ��ͬ���֮���������Ϸ����õ��ģ�ÿһ������5���˼��ʱ�䡣b����ÿ������ܹ���ְҵ���ֵ��߷�����GoKifu���ݼ���������Ԥ��ȷ�ԡ�c��ÿ������ܹ�������ְҵ���ֵ���ֽ������GoKifu���ݼ���������MSE��
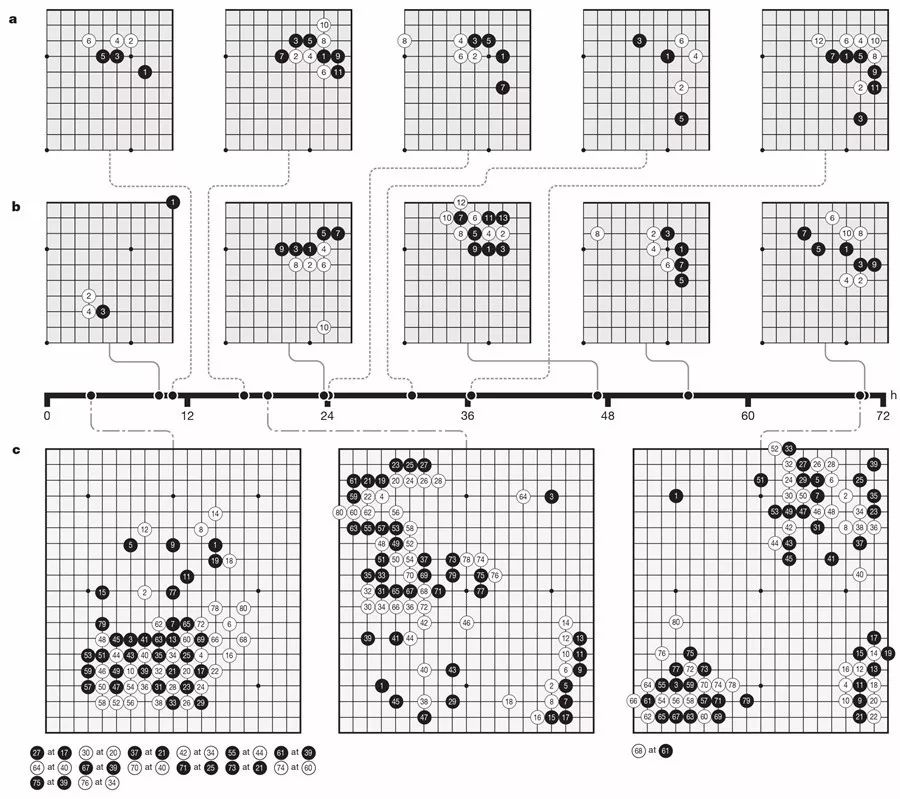
AlphaGo Zeroѧ����֪ʶ��a��AlphaGo Zeroѵ���ڼ䷢�ֵ�������ඨʽ�������Ľ������У���b�����Ҷ����а��õ�5����ʽ��c���ڲ�ͬѵ���ν��е�3�����Ҷ��ĵ�ǰ80���壬ÿ������ʹ��1,600��ģ�⣨Լ0.4s�����ʼ��ϵͳ��ע���ӣ����������ѧ�ߡ�����ע�ƺ͵أ�Ҳ��Χ���������������������ֳ��˺ܺõ�ƽ�⣬�漰���ս����һ�����ӵ�ս���������������ӻ�ʤ��
AlphaGo ��
������AlphaGo��Fan��Lee��Master��Zero��
����������ʦ����������
���գ�2014��
�����أ�Ӣ����
1
���ܷ���
2015��10�£�AlphaGo���ܷ��⣬��Ϊ��һ���������Ӽ�����19·�����ϻ���Χ��ְҵ���ֵĵ���Χ�����д������ʷ����سɹ���2016��1�·�����Nature
2
��������ʯ
2016��3�£�AlphaGo��һ���巬�������4:1���ܼ��ְҵ��������ʯ����Ϊ��һ�����������Ӷ�����Χ��ְҵ�Ŷ����ֵĵ���Χ������ٴ���ʷ�����������Ժ����AlphaGo��ʷ������һλ����ְҵ�Ŷ�
3
�������ݳ�Խ�½�
2016��7��18�գ�AlphaGo��Go Ratings��վ���������������һ��������֮�½෴����
4
������Master����ɨ���
2016�����2017��������ٶ�ǿ����AlphaGo�ԡ�Master��Ϊ������δ��������ʵ���ݵ�����£������ʽ����������ս���в��ԣ���ս�к���̨��һ�����֣�60սȫʤ
5
սʤ�½࣬��Ϊ�����һ
2017��5��23��27������Χ���ᣬ���µ�ǿ����AlphaGo�������һ���ֿ½�Ծ֣�����ϰ˶�����Эͬ��ս��Ծ���λ����Ŷ����ֵ��峡��������ȡ3����ȫʤ��ս�����Ŷ�ս�����սҲȫʤ�����AlphaGo��������Դ���Ľ�����ʯ�汾��ʮ��֮һ������½�ı����������й�Χ��Э������AlphaGoְҵΧ��Ŷεijƺ�
AlphaGo��û��������ֺ�2017��5��25�գ�AlphaGo֮������˹��������˹����AlphaGo���ۡ�AlphaGo���о��ƻ���2014�꿪ʼ����ҵ�����ֵ�ˮƽ�������һ��AlphaGo��������ȡ�����Ľ��������������������ҡ�
AlphaGo�������ݣ����������档
���Դ��ģ��¾�AlphaGo���Լ��з�AlphaGo���ˡ�



















