
��Ϊ�����������������Ȼ���Դ���������ȵ㣬֪ʶͼ��������������������֪ʶ�����ת�䡣�ڰ���ġ������������У�֪ʶͼ������ؼ����Ĺ㷺Ӧ�ò����ܰ����û��ҵ�����Ҫ����Ϣ���������û������벻����֪ʶ�ջ�
�������
Ϊ�˲��������������飬����������֪ʶͼ����Ӧ���Ŷӣ�һֱ�ڲ���̽��������ͼ�Ĺ������������У�������Ϣ��ȡ��Open Information Extraction�������ͨ����Ϣ��ȡ��ּ�ڴӴ��ģ�ṹ����Ȼ�����ı��г�ȡ�ṹ����Ϣ������֪ʶͼ�����ݹ����ĺ��ļ���֮һ��������֪ʶͼ�ɳ���������������
���磺�����������������㲻����֪������Ӫ����Ч������������˳��ѧ���Ҹ�ţ��������������������ʱ��ɡ�ů�С��ˣ�ԭ�������С�֪ʶͼ�ס����ǿ�������������������ͼʾ����
����������������
���ľ۽��ڿ�����Ϣ��ȡ�е���Ҫ��������ϵ��ȡ�����ȶԹ�ϵ��ȡ�ĸ��������������и�����������ҵ���е�ѡ����Ӧ�ã��ص�����˻���DeepDive�ķ�������������������֪ʶͼ�����ݹ��������е�Ӧ�ý�չ��
��ϵ��ȡ����
��ϵ��ȡ��������
���еĹ�ϵ��ȡ������Ҫ�ɷ�Ϊ���� ��
�мල��ѧϰ���� ���÷�������ϵ��ȡ�������������⣬����ѵ�����������Ч���������Ӷ�ѧϰ���ַ���ģ�ͣ�Ȼ��ʹ��ѵ���õķ�����Ԥ���ϵ���÷���������������Ҫ�������˹���עѵ�����ϣ������ϱ�ע����ͨ���dz���ʱ������
��ල��ѧϰ���� ���÷�����Ҫ����Bootstrapping���й�ϵ��ȡ������Ҫ��ȡ�Ĺ�ϵ���÷��������ֹ��趨��������ʵ����Ȼ������ش����ݴӳ�ȡ��ϵ��Ӧ�Ĺ�ϵģ������ʵ����
�ල��ѧϰ���� ���÷�������ӵ����ͬ�����ϵ��ʵ���ӵ�����Ƶ���������Ϣ����˿�������ÿ��ʵ��Զ�Ӧ��������Ϣ��������ʵ��Ե������ϵ����������ʵ��Ե������ϵ���о��ࡣ
�����ַ����У��мලѧϰ����Ϊ�ܹ���ȡ����Ч�����������ڻ�ø�ȷ�ʺ��ٻ��ʷ���������ƣ���Ŀǰҵ��Ӧ����㷺��һ�����
Զ�̼ල�㷨
Ϊ�˴����мලѧϰ���˹����ݱ�ע�ľ����ԣ�Mintz���������Զ�̼ල��Distant Supervision���㷨�����㷨�ĺ���˼���ǽ��ı�����ģ֪ʶͼ����ʵ����룬����֪ʶͼ�����е�ʵ����ϵ���ı����б�ע��Զ�̼ල���ڵĻ��������ǣ������֪ʶͼ���пɻ�ȡ��Ԫ��R��E1��E2����ע��R������ϵ��E1��E2��������ʵ�壩����E1��E2���������S�У���S������E1��E2��Ĺ�ϵR����עΪѵ��������
Զ�̼ල�㷨��Ŀǰ�����Ĺ�ϵ��ȡϵͳ�㷺���õķ�����Ҳ�Ǹ�������о��ȵ�֮һ�����㷨�ܺõؽ�������ݱ�ע�Ĺ�ģ���⣬�������ڵĻ��������ǿ������������������ݡ����磬��֪ʶͼ��ȡ��Ԫ�飺��ʼ�ˣ��Dz�˹��ƻ����˾�����±���1�;�2��ȷ�����˸ù�ϵ������3�;�4��û�б��������Ĺ�ϵ����˶Ծ�3�;�4Ӧ�û�������ʱ��õ�����ı�ע��Ϣ���������ͨ����Ϊ the wrong label problem��
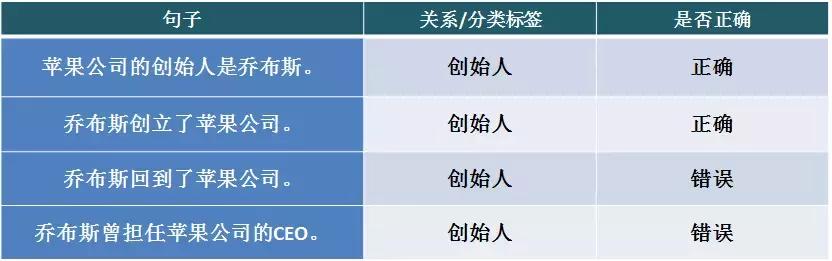
���� the wrong label problem �ĸ���ԭ����Զ�̼ල����һ��ʵ���ֻ��Ӧһ�ֹ�ϵ����ʵ����ʵ��Լ����ͬʱ���ж��ֹ�ϵ���������л�����CEO���Dz�˹��ƻ����˾���Ĺ�ϵ��ʵ��Լ�Ҳ���ܲ�����ͨ�������ij�ֹ�ϵ��������Ϊ��ͬ�漰��ij��������ھ��й��֡�
Ϊ�˼�С the wrong label problem ��Ӱ�죬ѧ����½������˶��ָĽ��㷨����Ҫ������
���ڹ���ķ�����ͨ����wrong label cases��ͳ�Ʒ��������ӹ���ԭ�����������ע��wrong label casesֱ�ӱ�Ϊ��������ͨ����ֵ���ƣ�����ԭ�е�����ע��
����ͼģ�͵ķ�������������ͼ��factor graph�����ܱ��������������ͼģ�ͣ�ͨ����������ѧϰ�Ͷ�����Ȩ�ص������Сwrong label cases��ȫ�ֵ�Ӱ�졣
���ڶ�ʾ��ѧϰ��multi-instance learning���ķ����������а�����E1��E2���ľ������һ��bag����ÿ��bag�Ծ��ӽ���ɸѡ������ѵ��������������������ʱ�������֪ʶͼ���д���R��E1��E2�����������к���E1��E2��������instance��������һ�������˹�ϵR��һ��������ͼģ�ͽ�ϣ������ÿ���������Ŷ���ߵ���������Ϊ����ѵ��ʾ�����ü����Զ�̼ල�ļ����������������ʧ�ܶ�ѵ�����������������Ϣ�Ķ�ʧ��ѵ���IJ���֡�Ϊ���ܵõ����ḻ��ѵ���������������multi-instance multi-labels�ķ������÷����ļ����ǣ�ͬһ�����У�һ��sentenceֻ�ܱ�ʾ��E1��E2����һ�ֹ�ϵ��Ҳ����ֻ�ܸ���һ��label�����Dz�ͬ��sentence���Ա�����E1��E2���IJ�ͬ��ϵ���Ӷ��õ���ͬ��label����label��ע��labelֵ������������ijһ�ֹ�ϵ����Ϊͬʱ�ھ�һ��ʵ��ԵĶ��ֹ�ϵ�ṩ�˿��ܵ�ʵ��;������һ�ָĽ��ķ����Ǵ�һ������ѡȡ���valid sentences��Ϊѵ������һ�������ѧϰ�������ϣ����ַ�������ϸ�Ľ����ʵ�ֻᰲ���ں����������ѧϰģ�͵��½��С�
����֪ʶͼ�����еĹ�ϵ��ȡ����ѡ��
֪ʶͼ�����ݹ�����������Դ���ԣ���Ϊ�ṹ�����ݣ���ṹ�����ݺ��ṹ�������ࡣ���У��ṹ���������Ӵ�����ȡ����Դ��ͬʱҲ���ڴ��������÷����Ѷ�������Դ������֪ʶͼ���������Ѿ���չΪһ��ӵ�н�5000��ʵ�壬��30�ڹ�ϵ�Ĵ��ģ֪ʶͼ�ס��ھ�����ǰ���Խṹ���Ͱ�ṹ������Ϊ��������ͼ�����Σ�����֪ʶͼ�����ݹ����ص��Ѿ���ת��Ϊ���ȷ��Ч�������ṹ���ݽ���ʵ�����ϵ���Զ�ʶ�����ȡ����һ��������ʹ������֪ʶͼ����ͨ������Ľ���Ϳɳ������������к�ǿ�ľ�������
Զ�̼ල�㷨����֪ʶͼ��������Ϣ��ʹ���мලѧϰ������Ĵ��ģ�ı���ע��Ϊ���ܡ�һ���棬Զ�̼ල�ںܴ�̶����������мලѧϰ��ϵ��ȡ�Ĺ�ģ��ȷ�ʣ�Ϊ���ģ��֪ʶͼ�����ݹ����Ͳ����ṩ�˿��ܣ���һ���棬Զ�̼ල������֪ʶͼ�����ݺ�ģ�н�ǿ���������ḻ�ı�ע���ݶԻ���ѧϰ�����������кܴ������Ϊ�˳������֪ʶͼ��ģ��Զ�̼ලѧϰ�����ศ��ɵ����ԣ�������֪ʶͼ���ֽ����ݹ���ҵ���У����Dz�������ͼ�����еĴ��ģʵ�����ϵ����Ϊ���У���Զ�̼ල�㷨Ϊ���ߵĹ�ϵ��ȡ������
����һ�µ������У����ǽ��ܹ����ֻ���Զ�̼ල˼��ĸĽ��������ھ����ҵ��ʵ���У�����ѡȡ����������ҵ��������Ϊ���ϵ����ִ����Է���������DeepDive�ij�ȡϵͳ�ͻ������ѧϰ��ȡ�㷨�����ַ����ศ��ɣ��������ƣ�DeepDiveϵͳ�϶���������Ȼ���Դ������ߺͻ��������ĵ��������г�ȡ�������Ϲ�ģ��ѡ���ϸ�Ϊ���ܽ���������ԵĹ�ϵ��ȡ�����ܷ�����ڳ�ȡ�����н����˹������Ԥ�������ѧϰ�ķ�����ҪӦ���˴������;��������磬�ڴ��ģ���ϴ����Ͷ��ϵ��ȡ�������������Ե����ơ���������½��У�����������ϸ���˽������ַ�����ʵ����Ӧ�á�
DeepDiveϵͳ����
DeepDive����
DeepDive��http://deepdive.stanford.edu/����˹̹����ѧ��������Ϣ��ȡϵͳ���ܴ����ı�������ͼ����ͼƬ�ȶ��ָ�ʽ���ṹ���ݣ����г�ȡ�ṹ������Ϣ��ϵͳ�������ļ���������Ϣ��ȡ����Ϣ���ϡ�����Ԥ��ȹ��ܡ�Deepdive����ҪӦ�����ض��������Ϣ��ȡ��ϵͳ�����������ڽ�ͨ�����š�������ҽ�Ƶȶ���������Ŀʵ����ȡ�������õ�Ч�����ڿ��������Ӧ�ã���TAC-KBP������ά���ٿƵ�infobox��Ϣ�Զ���������Ŀ��Ҳ�в����ı��֡�
DeepDiveϵͳ�Ļ������������
�ṹ���ݣ�����Ȼ�����ı�
����֪ʶ���֪ʶͼ���е����֪ʶ
��������ʽ����
DeepDiveϵͳ�Ļ������������
�涨��ʽ�Ľṹ��֪ʶ������Ϊ��ϵ��ʵ��1��ʵ��2���������ԣ�ʵ�壬����ֵ������ʽ
��ÿһ����ȡ��Ϣ�ĸ���Ԥ��
DeepDiveϵͳ���й����л�����һ����Ҫ�ĵ������ڣ���ÿ��������ɺ��û���Ҫ�����н�����д��������ͨ����������������֪ʶ����Ϣ���Ĺ�����ֶθ�Ԥϵͳ��ѧϰ�������Ľ��������������ʹ��ϵͳ��������ϵõ��Ľ���
DeepDiveϵͳ�ܹ���������
DeepDive��ϵͳ�ܹ�����ͼ��ʾ�����·�Ϊ���ݴ��������ݱ�ע��ѧϰ�����ͽ��������ĸ����̣�
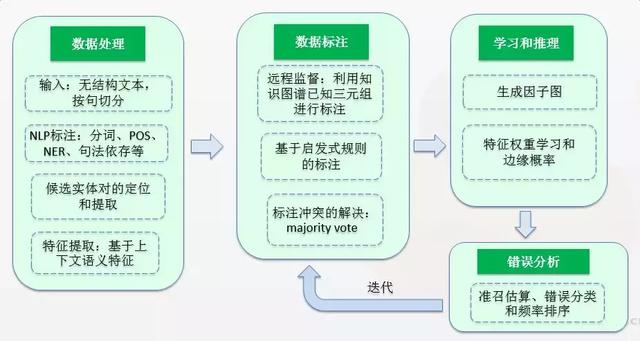
���ݴ���
1�� �������з�
�����ݴ��������У�DeepDive���Ƚ����û����������ݣ�ͨ������Ȼ�����ı����Ծ���Ϊ��λ�����з֡�ͬʱ�Զ������ı�id��ÿ���������ı��е�index��doc_id + sentence_index ������ÿ�����ӵ�ȫ��Ψһ��ʶ��
2�� NLP��ע
����ÿ���зֺõľ��ӣ�DeepDive��ʹ����Ƕ��Stanford CoreNLP���߽�����Ȼ���Դ����ͱ�ע������token�з֣��ʸ���ԭ��POS��ע��NER��ע��token���ı��е���ʼλ�ñ�ע�������ķ������ȡ�
3�� ��ѡʵ�����ȡ
������Ҫ��ȡ��ʵ�����ͺ�NER��������ȶ�ʵ��mentions���ж�λ����ȡ���������һ������Թ������ɺ�ѡʵ��ԡ���Ҫ�ر�ע�⣬��DeepDive�У�ÿһ��ʵ��mention�ı궨����ȫ��Ψһ�ģ���doc_id��sentence_index�Լ���mention�ھ����е���ʼ�ͽ���λ�ù�ͬ��ʶ����ˣ���ͬλ�ó��ֵ�ͬ����ʵ��ԣ�E1��E2����ӵ�в�ͬ�ģ�E1_id��E2_id�������յ�Ԥ����Ҳ����ͬ��
4�� ������ȡ
�ò����Ŀ���ǽ�ÿһ����ѡʵ�����һ��������ʾ�������Ա�����Ļ���ѧϰģ���ܹ�ѧϰ��ÿ����������ҪԤ���ϵ������ԡ�Deepdive�ں��Զ���������ģ��DDlib����Ҫ��ȡ���������ĵ�������������������ʵ��mention���token sequence��NER tag sequence��ʵ��ǰ���n-gram�ȡ�DeepdiveҲ֧���û��Զ����������ȡ�㷨��
���ݱ�ע
�����ݱ�ע�Σ����ǵõ��˺�ѡʵ����Լ����Ƕ�Ӧ���������ϡ������ݱ�ע�Σ����ǽ�����Զ�̼ල�㷨������ʽ����ÿ����ѡʵ��Խ���label��ע���õ�����ѧϰ�������������������
1�� Զ�̼ල
ʵ��Զ�̼ල��ע��������Ҫ����֪��֪ʶ���֪ʶͼ���л�ȡ��ص���Ԫ�顣�Ի�����ϵΪ����DeepDive��DBpedia�л�ȡ���еķ���ʵ��ԡ�����ѡʵ���������֪�ķ���ʵ������ҵ�ƥ��ӳ��ʱ���ú�ѡ�Ա��Ϊ�����������ı�ע�����Ҫ��ȡ�IJ�ͬ��ϵ�в�ͬ�Ŀ�ѡ������������Խ�û����֪ʶ���г��ֵ�ʵ��Ա�עΪ����������֪ʶ�����벻����������¸÷�������������������Ҳ������֪ʶ���л����ϵ�µ�ʵ������������ע�����縸ĸ-��Ů��ϵ���ֵܽ��ù�ϵ�����������ϵ���⣬���ڱ�ע����������������������
2�� ����ʽ����
���������ı�ע������ͨ���û���д����ʽ������ʵ�֡��Գ�ȡ������ϵΪ�������Զ������¹���
Candidates with person mentions that are too far apart in the sentence are marked as false.
Candidates with person mentions that have another person in between are marked as false.
Candidates with person mentions that have words like "wife" or "husband" in between are marked as true.
�û�����ͨ��Ԥ����user defined function�ӿڣ�������ʽ������б�д���ġ�
3�� Label��ͻ�Ľ��
��Զ�̼ල���ɺ�����ʽ�������ɵ�label��ͻ����ͬ�������ɵ�label������ͻʱ��DeepDive����majority vote�㷨���н�������磬һ����ѡ����DBpedia���ҵ���ӳ�䣬labelΪ1��ͬʱ������2�е�2�����õ�label Ϊ-1��majority vote������label��ͣ�sum = 1 - 1 = 0�����յõ���labelΪdoubt��
ѧϰ������
ͨ�����ݱ�ע�õ�ѵ��������ѧϰ�������Σ�Deepdive��Ҫͨ����������ͼģ�͵�������ѧϰ������Ȩ�أ������յõ��Ժ�ѡ��Ԫ��Ϊ��ĸ���Ԥ��ֵ��
����ͼ��һ�ָ���ͼģ�ͣ����ڱ��������ͱ�����ĺ�����ϵ����������ͼ���Խ���Ȩ�ص�ѧϰ�ͱ�Ե���ʵ����㡣DeepDiveϵͳ�У�����ͼ�Ķ��������֣�һ�����������������ȡ�ĺ�ѡʵ��ԣ���һ������������ĺ����������е��������ݹ���õ��ĺ������ȷ�����ʵ���ľ����Ƿ����һ����ֵ�ȡ�����ͼ�ı߱�ʾ��ʵ��Ժ�����������Ĺ�����ϵ��
��ѵ���ı��Ĺ�ģ�ܴ��漰��ʵ���ڶ�ʱ�����ɵ�����ͼ���ܷdz������Ӵ�DeepDive���ü���˹������Gibbs sampling������������ͼ�ĸ������㡣������Ȩ�ص�ѧϰ�У����ñ���SGD���̣������ݼ���˹�����Ľ��Ԥ���ݶ�ֵ��Ϊ��ʹ����Ȩ�صĻ�ø�������������ϵͳĬ�ϵ��������̣��û�������ͨ��ֱ�Ӹ�ֵ������ij��������Ȩ�ء�ƪ����ϵ������ϸ��ѧϰ���������̱��IJ���չ�����ܣ��������Ϣ�ɲο�DeepDive�Ĺ�����
��������
�����α�֤ͨ��һ�����˹���Ԥ��ϵͳ�Ĵ�����о������Ӷ�ʹ��ϵͳ�����ʲ�����������������һ��������¼������裺
1�� ���ʵĿ��ٹ���
ȷ�ʣ���P���������ѡ100������ΪTP�ı�����
�ٻ��ʣ������뼯�������ѡ100��positive case�����ж��ٸ����ڼ������P���С�
2�� ������������
���õ���ÿ��extraction failure������FP��FN��������ԭ����з�����ɣ�������������Ƶ�ʽ�������һ����ԣ�����Ҫ����ԭ�������
�ں�ѡ�����ɽ�û�в���Ӧ�����ʵ�壬һ����token�з֡�tokenƴ�ӻ�NER����
������ȡ���⣬û�ܻ�ȡ�����ֶȸߵ�����
�����������⣬���ֶȸߵ�������ѵ����û�л����Ӧ�ĸ߷֣����������߷֣�
3�� ��������
���ݴ���ԭ��ͨ�����ӻ��Ĺ��������������ӻ�ɾ������������Ȩ�ؽ��е�������Ϊ������ϵͳ�����������ĺ����Ӧ���̣��õ��µļ�������
����֪ʶͼ�����е�DeepDiveӦ����Ľ�
���˽���DeepDive�Ĺ�������֮���½������������������֪ʶͼ�����ݹ���ҵ����ʹ��DeepDive��Ϊ�˳������������Ϣ�����ϵͳ����Ч�ʣ����������ϴ����ͱ�ע�������ģ�Ŀ��ơ����������������Ȼ��ڣ���DeepDive����һЩ�Ľ���������Щ�Ľ��ɹ����õ�ҵ����صĹ����С�
����NLP��ע
NLP��ע�����ݴ�����һ����Ҫ���ڡ�DeepDive�Դ���Stanford CoreNLP������Ҫ�����Ӣ�ĵĴ���������֪ʶͼ��Ӧ���У���Ҫ�Ĵ���������������ĵġ���ˣ����ǿ���������NLP��ע���ⲿ������ȡ��CoreNLP����Ҫ�䶯���£�
ʹ��Ali�ִʴ���CoreNLP��token�з֣�ɾ���ʸ���ԭ��POS��ע�������ķ�����������NER��ע��token���ı��е���ʼλ�ñ�ע��
token�з����Դ�Ϊ��λ����Ϊ��ʵ��Ϊ��λ����NER���ڣ���Ali�ִ������token��ʵ��Ϊ����������ϡ�����ִʽ������ʢ�١�����������������ѧ���������Ϊ����ʢ��������ѧ��������Ϊһ��������ʵ���á�University����NER��ǩ��
������з֣��ı��е�ijЩ���������Ϊȱ����ȷ�ı�������ڶಢ�����ԭ�����зֺ�ľ��ӳ��ȳ���һ����ֵ����200�������ַ����������ʹNER�����ʱ�����������������Ԥ�����һϵ�й�����������з֡�
�����Զ�����
���ݴ������ڵ���һ���Ľ��������������Զ���������̡������İٿ��ı�Ϊ����ͳ�Ʒ��֣��н���40%�ľ���ȱ���������ͼ���»��İٿƽ��ܣ��ڶ��������о��Ӿ�ȱ�����

�����ȱʧ�ܶ�ʱ��ֱ����ζ�ź�ѡʵ���������һ��ʵ���ȱʧ���⽫����ϵͳ�Դ�������������Ϣ�ľ���������ѧϰ������Ӱ��ϵͳ��ȷ�ʺ��ٻ��ʡ�������Զ������漰��������жϣ�
����ȱʧ���ж�
ȱʧ���������
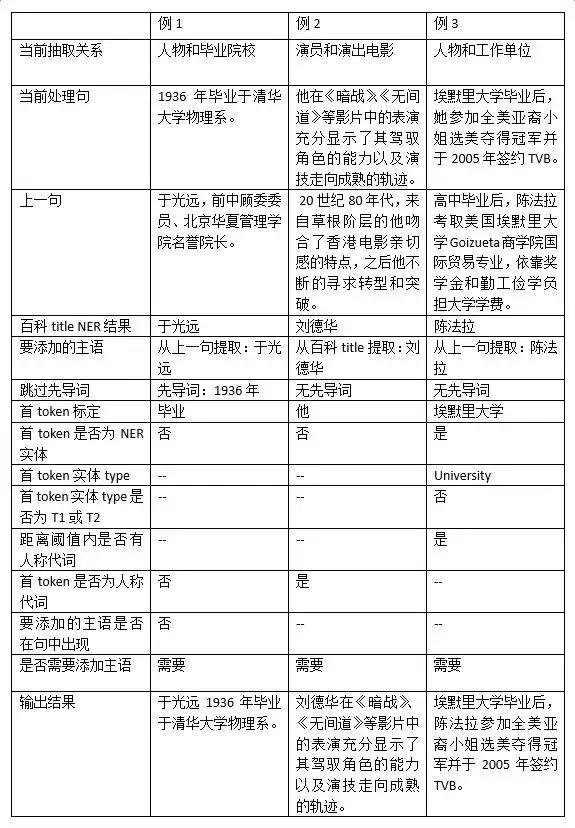
����Ŀǰҵ��Ӧ�����漰�ľ�������ǰٿ��ı���ȱʧ��������Ӳ����˱ȽϼIJ��ԣ����ӵ�ǰ�����һ����ȡ��������һ��Ҳȱʧ����ٿƱ����NER�����ΪҪ���ӵ��������ȱʧ���ж���Ը��ӣ�Ŀǰ��Ҫ���û��ڹ���ķ�����������Ҫ��ȡ�ĺ�ѡ�ԣ�E1�� E2����Ӧ��ʵ������Ϊ��T1�� T2�������ж���������ͼ��ʾ��
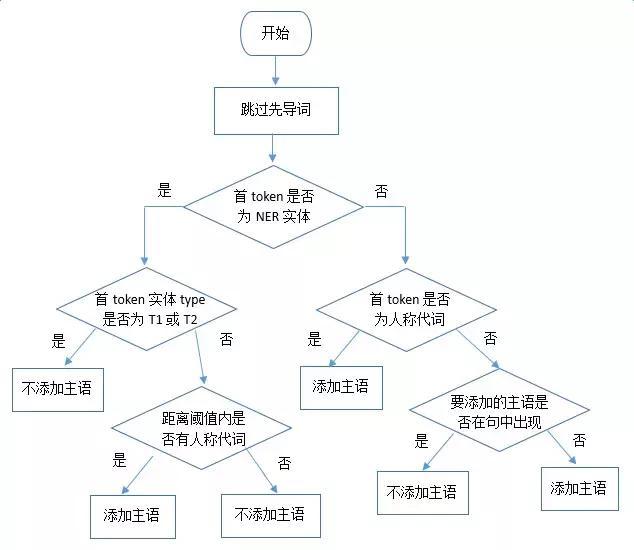
��������ﲹ��ʵ���ʹ������̾������£�
�ٿ��ı�Ϊ������ʵ��ͳ�ƣ����������Զ������㷨��ȷ�ʴ�Լ��92%���ӹ�ϵ��ȡ�Ľ�������������еĴ����ȡcase�У��������������µĴ������������2%��
���ڹ�ϵ��عؼ��ʵ��������
DeepDive��һ������ѧϰϵͳ�����뼯�Ĵ�Сֱ��Ӱ��ϵͳ������ʱ�䣬�����ں�ʱ�ϳ������������ѧϰ�������衣�ڱ�֤ϵͳ�ٻ��ʵ�ǰ���£�������С���뼯��ģ����Ч����ϵͳ������Ч�ʡ�
������Ҫ��ȡ����Ԫ��ΪR��E1�� E2���ң�E1�� E2����Ӧ��ʵ������Ϊ��T1�� T2����DeepDive��Ĭ�����л����ǣ������ݴ����Σ���ȡ������������Ϊ��T1��T2����ʵ�����Ϊ��ѡ���������������Ƿ��б����ϵR�Ŀ����ԡ����磬��ȡ������ϵʱ��ֻҪһ�������г��ִ��ڵ�������������ʵ�壬�þ��Ӿͻ���Ϊ�������ϵͳ�������ݴ�������ע��ѧϰ�Ĺ��̡�������������У����˾�1������4����ȫ���漰������ϵ��

���䵱���е���������ʵ����ͨ��Զ�̼ල��ȡ����������ǩʱ��������������ѧϰ����Ϊϵͳ��ȷ�ʴ������档Ϊ��С�������������ϵͳ����ʱ����ģ�������������¸Ľ��㷨��

ʵ��֤�������øĽ��㷨�õ������뼯��ģ�������ļ�С���ٿ��ı��ij�ȡΪ����������ϵ�����뼯����С��ԭ���뼯��13%������ͱ�ҵԺУ��ϵ�����뼯����С��ԭ���뼯��36%�����뼯����С����������ϵͳ����ʱ�䣬��ʵ��֤�����ų��˴���doubt��עʵ���ѡ�Եĸ��ţ�ϵͳ��ȷ��Ҳ�нϴ���ȵ�������
��Ҫָ�����ǣ���Ȼ�����뻷��ͨ����ϵ��عؼ��ʽ��й��˼�С�����ģ��������Ч�����ϵͳ����Ч�ʣ���Ϊ�����˰���������ȡ���ڵ����к������㲽�裩�����û��ڵĹ������Ծ���Ϊ��λ�����������ڳ�ȡ�ĺ�ѡʵ��ԡ�����һ��������ϵ��ȡ�Ķ�����ʾ����
������骡���Ӣ�ȱ��ݼα�ʢװ��ϯ�⣬���α������ֻ���ƵĻ����ֵ��ܲ���������������С�յ��ݺͷ����췫���Լ����š��ε��������������������Ҳһһ������̺������֧�ִ˴����ֻᡣ
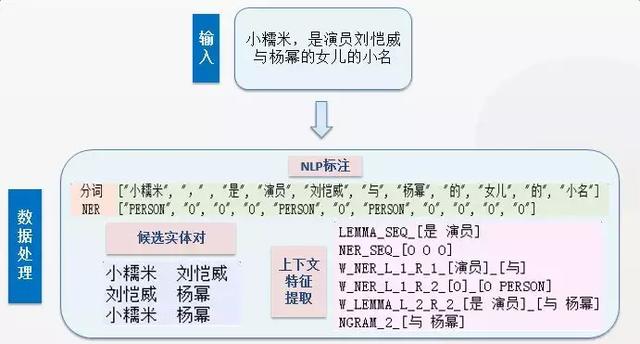
��Ϊ���л�����ϵ��صĹؼ��ʡ����ˡ����þ��ӽ�������Ϊϵͳ���롣�Ӹþ���ȡ�Ķ�������ѡʵ�����Ҫ���������Ƶ�����ʽ��������ɽ�һ���ı�ע���ˡ�
ʵ��Ե���ʵ�����չ
��ϵ��ȡ�ľ���������漰��Ԫ��ij�ȡ����Ԫ��һ����������ʽ��һ��������ʵ�����ij�ֹ�ϵ������R��E1�� E2�������磺������ϵ�����»�������ٻ������һ����ʵ�������ֵ������P��E��V�������磺���ߣ����»���1.74�ף���DeepDiveĬ�ϵĹ�ϵ��ȡģʽ���ǻ�����Ԫ��ġ�����ʵ��Ӧ���У��кܶิ�ӵĹ�ϵ����Ԫ����������������磬����Ľ��������������������ı�ҵԺУ����ѧרҵ��ȡ��ѧλ����ҵʱ��ȡ���Щ���ӵĶ�ʵ���ϵ������֪ʶͼ�����ø�����������ʾ����ˣ�Ϊʹ��ȡ�����ܼ��ݸ������͵Ĺ���ʱ�����Ƕ�DeepDive�Ĵ�������һЩ�ģ�����ѡʵ��Ե���ȡ����չΪ��ѡʵ�������ȡ���������漰����ȡģ���е�app.ddlog���ײ����������Զ����ɵ�DDlib��udf�е�map_entity_mention.py��extract_relation_features.py���ļ�����ͼչʾ��һ����չ���ʵ�����ȡʵ������ȡ��ϵΪ��������ڻ�����ְλ����

Ӧ��DeepDive�����ݹ�������
�������ȸ���һ������ʾ���Լ���ʾ����DeepDive���й�����ÿһ����������������ͼ��ʾ��ͨ�����ʾ�������ǿ��Զ�DeepDive��ģ��Ĺ��ܺ�����и�ֱ�۵���ʶ��
Ϊ�˸���ϸ���˽�DeepDive��Ӧ�úĽ��㷨��Ч�����������Ǹ���һ������Ļ�����ϵ��ȡ���������������ݡ�
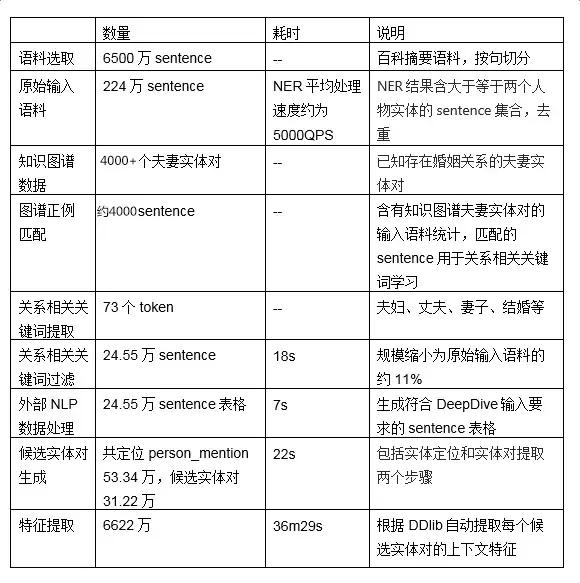
�±���ʾ�˸ó�ȡ���������ݴ����θ�����ĵĺ�ʱ�Ͳ���������
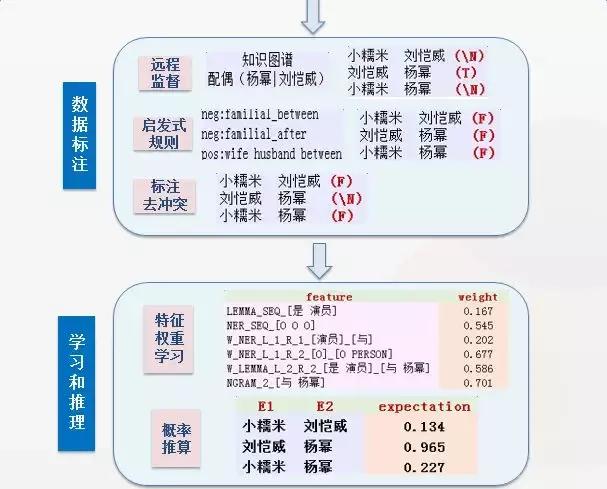
�����ݱ�ע��Զ�̼ල�Σ����dz���ʹ��֪ʶͼ�������еķ���ϵ��������ע����ʹ�������еĸ�ĸ-��Ů��ϵ���ֵܽ��ù�ϵ��������ע���õ�������ǧ����������ע��ѡʵ��ı���ԼΪ1:2��
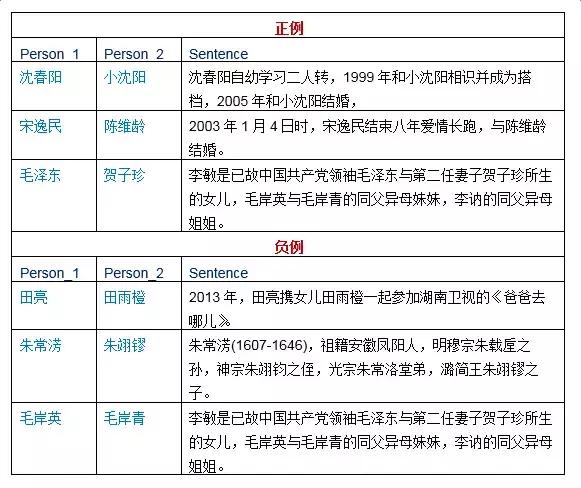
��DeepDiveϵͳ�У�Զ�̼ල��wrong label problem��������������д������ʽ����õ�һ���̶ȵľ������۲������ϵ��wrong label���������Ƿ��ֽϴ������wrong label�Ƿ���ʵ����ij�ֺ�����ʽ��������ݳ��������ݳ�����������ȣ�������һ�������У�����ʵ����һ����������������ʱ��Ҳ���������С����磺
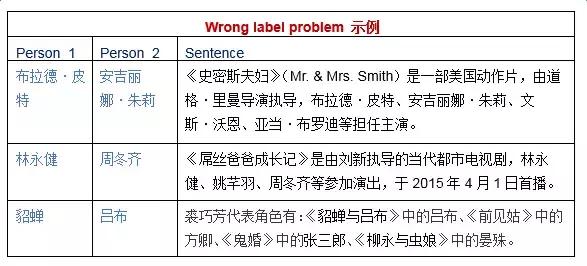
���ƵĹ۲���ܽ���Ա�д������ʽ���������ӹ���õ��ĸ���ע�ֳ�Զ�̼ල�õ�������ע����Сϵͳ��ѧϰ������ʱ��ƫ�
��Ȼ����ʽ����ı�д�������ר��֪ʶ���˹�������ɣ�����������ƺ������������ijЩ�Զ�����������ʵ�֡����磬�����壺���г��֡�P_1��P_2��顱����P_1��P_2���õ�����ע�����ݶԡ��͡��͡���顱��token����չ�����ǿ��Եõ���P_1��P_2��顱����P_1��P2�����P_1��P_2�Ļ�������Ӧ�ñ�עΪ�����ᄈ�����token����չ����ͨ��word2vec�㷨���˹�����ʵ�֡��±������˸ó�ȡ�������õ��Ĺ������Ӧ��ͳ�����ݡ��������ݱ�ע���̺�Ϊ14m21s��
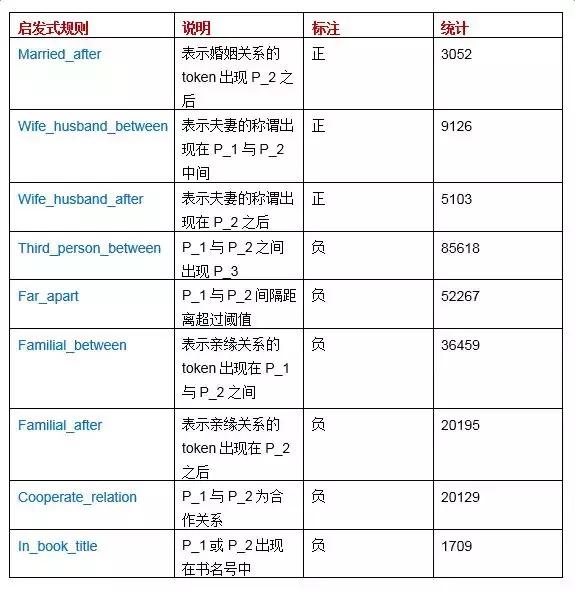
ѧϰ���������̺�ʱԼ38m50s�����������ȡ�˲���֪ʶͼ��δ��¼��Ԥ��ʵ��Ե�������չʾ���£�

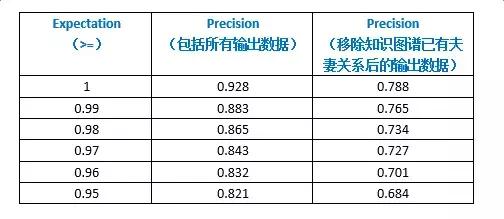
����ϵͳ��ȷ�ʣ�����ȡexpectationΪ [0.95,1][0.95,1] �����ڵ����������зֶ�ͳ�ƣ�ͳ�ƽ��������ͼ����ʾ��
��ϵͳԤ��Ĵ����������з����������ܽ��˼��ִ������ͣ��±����ճ���Ƶ�ʴӸߵ��ͣ������˴��������ʹ���ʾ����
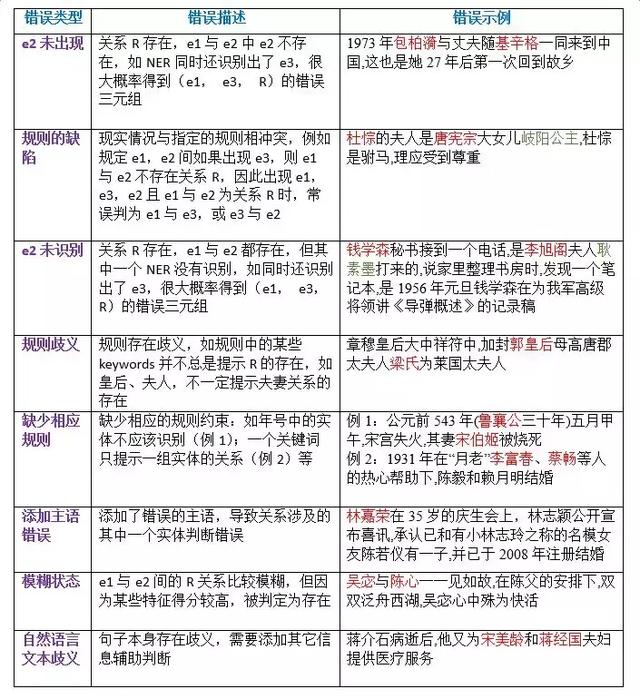
ϵͳ�ٻ��ʵļ������ȷ�ʵļ����Ϊ���ӣ������Ϲ�ģ�ϴ������£�ȷ�����ٻ��ʽ��ķѴ��������������Dz����˳������ķ�ʽ�������ٻ��ʣ�����ʵ�����������ַ�����ͳ����expectation��ȡ>=0.95����
��������ij��ָ��ʵ�������sentences�������ٻأ���ʵ�� �����ݡ� ��sentences��78������ �����ݣ� ��������ʵ��Ե�sentences��13�����˹��ж�����9�������˸�ʵ��ԵĻ�����ϵ������5�����ٻأ��ٻ���Ϊ0.556��
����Զ�̼ල������ע��֪ʶͼ��ʵ��Գ���4000�ԣ�ͳ�Ʊ���������42.7%��ʵ��Գ������������У�26.5%��ʵ��Ա��ٻأ��ٻ���Ϊ0.621��
���뼯�����ѡ100��positive cases������49����expectationֵ>=0.95, �ٻ���Ϊ0.49��
����DeepDive�Ĺ�ϵ��ȡ�о�Ŀǰ�ѽ�Ϊ���������Ѿ�������֪ʶͼ�Ĺ���ҵ������ء�Ŀǰ�����ݹ����е�Ӧ���漰�����ʷ����֯������ͼ�顢Ӱ�ӵȶ�����������ѳ�ȡ��ϵ��������ĸ�ĸ����Ů���ֵܽ��á���������ʷ�¼�������ĺϳơ�ͼ������ߡ�Ӱ����Ʒ�ĵ��ݺ���Ա������ı�ҵԺУ�;�ҵ��λ�ȡ��ٿ�ȫ������Ϊ����ÿ����ϵ��ȡ�����ѡsentence���ϵĹ�ģ��80w��1000w�����Ľ��㷨���ˣ������ģ��15w��200w֮�䣬���ɵĺ�ѡʵ��Թ�ģ��30w��500w֮�䡣ϵͳÿ�ֵ������е�ʱ����1Сʱ��8Сʱ֮�䣬Լ����3-4�ֵ����ɲ���ȷ�ʺ��ٻ��ʶ��ϸߵ����ݸ���Ӫ��˻��ڡ�ϵͳ�����������ۼƲ�����ѡ��Ԫ���3ǧ��
����֮�⣬�������ѧϰģ�͵Ĺ�ϵ��ȡ��������������֪ʶͼ�����ݹ����е�Ӧ�ã�����Ҳ�ڲ���̽����ʵ�������죬�����ý�����Ϊ��ҽ�����صļ�����չ��ҵ����ع�����������һЩ��ս�������עŶ��
�����
[1]. ���ܿ�����֪Զ���������ѧϰ�Ĺ�ϵ��ȡ
[2]. Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In EMNLP. 1753�C1762.
[3]. Guoliang Ji, Kang Liu, Shizhu He, Jun Zhao. 2017. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Deions. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
[4]. Siliang Tang, Jinjian Zhang, Ning Zhang, Fei Wu, Jun Xiao, Yueting Zhuang. 2017. ENCORE��External Neural Constraints Regularized Distant Supervision for Relation Extraction. SIGIR'17
[5]. Zeng, D.; Liu, K.; Chen, Y.; and Zhao, J. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. EMNLP.
[6]. Riedel, S.; Yao, L.; and McCallum, A. 2010. Modeling relations and their mentions without labeled text. In Machine Learning and Knowledge Discovery in Databases. Springer. 148�C163.
[7]. Ce Zhang. 2015. DeepDive��A Data Management System for Automatic Knowledge Base Construction. PhD thesis.
[8]. Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; and Weld, D. S. 2011. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics��Human Language Technologies-Volume 1, 541�C550. Association for Computational Linguistics.
[9]. Surdeanu, M.; Tibshirani, J.; Nallapati, R.; and Manning, C. D. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 455�C465. Association for Computational Linguistics.
[10]. Shingo Takamatsu, Issei Sato and Hiroshi Nakagawa. 2012. Reducing Wrong Labels in Distant Supervision for Relation Extraction. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, pages 721�C729
[11]. Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J.; et al. 2014. Relation classification via convolutional deep neural network. In COLING, 2335�C2344.
[12]. Ce zhang, Cheistopher Re; et al. 2017. Communications of the ACM CACM Homepage archive
Volume 60 Issue 5, Pages 93-102
[13]. Mintz, M.; Bills, S.; Snow, R.; and Jurafsky, D. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP��Volume 2, 1003�C1011. Association for Computational Linguistics.


















