��֪ʶ�ʴ��У�Ҫ��һ����Ȼ���Ե��ʾ�ӳ�䵽֪ʶ�� KB ���Ǻ��ѵ���Ŀǰ���ʴ�ϵͳͨ���ǽ� NLP �ʾ�ת����һ�� SPARQL ��ѯ���ȥ���� KB����������һת�����������źܶ����⣬������ô�� KB ���ҵ����ʾ���ƥ���ʵ�����ϵ��
���������е�ʵ�������ܲ���ȫ�������ݿ��е����ƣ�ͬһ��ʵ���ж��ֽз���������ݿ��ж��ʵ���Ӧ�����ƿ�����һ���ġ����� Freebase ��� apple �ľ��� 218 ��ʵ�塣��ȷƥ��Ļ������ҵ��𰸣�ģ��ƥ���ֻ�Ӵ������ݿ�����������������ݡ�
������ѧϰ�㷨�����ϲ����� learning-to-rank ���ص��ע���ֹ������Ե���ʵ��ʶ������⡣
ģ�ͽ���
����Ҫ��ɵ������Ǹ��� KB ֪ʶ���ش���Ȼ����������������һ���� Aqqu ��ϵͳ������Ϊ��������һЩ��ѡ query��Ȼ��ʹ��ѧϰ����ģ��������Щ��ѡ query ��������������������ߵ� query�������������£�
����Ҫ�ش�������⣺What character does Ellen play in finding Nemo?
1. Entity Identification ʵ��ʶ��
������ KB ���ҵ����ʾ�������ƥ�����ŶȽϸߵ�ʵ�弯�ϣ���Ϊ�ʾ��е� Ellen��finding Nemo ���ﲢ����ȷ����ƥ�䵽 KB �еĶ��ʵ�塣
���� Stanford Tagger ���д��Ա�ע��Ȼ����ݴ�������������ʵ��Ĵ��� KB ����ƥ�䣬������ CrossWikis ���ݼ�ƥ�䵽�������ƻ�������Ƶ�ʵ�壬���������ƶ����ֺʹ������ж����֡�
2. Template Matching ģ��ƥ��
��һ������һ���õ��ĺ�ѡʵ�������ݿ��н��в�ѯ��Ȼ����������ģ�����ɶ����ѡ query������ģ���ʾ����ͼ��ʾ��
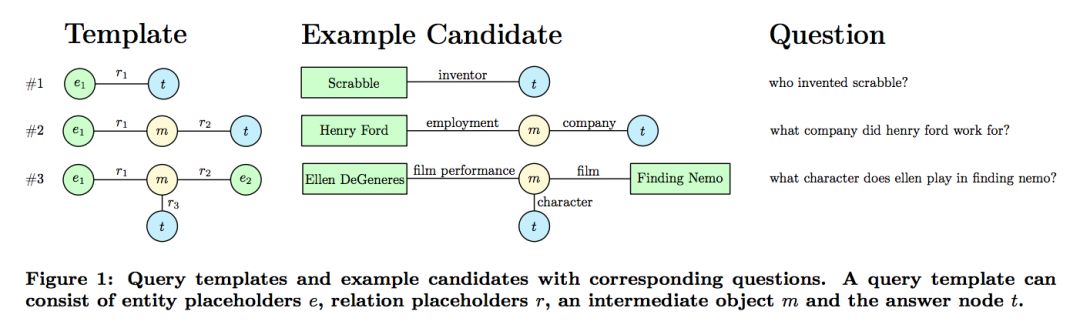
3. Relation Matching ��ϵƥ��
��һ������ѡ query �е� relation ���ʾ���ʣ�µIJ���ʵ��Ĵʽ���ƥ�䣬�ֱ�� Literal��Derivation��Synonym �� Context �ĸ��ǶȽ���ƥ�䡣
Literal ������ƥ�䣬Derivation ���� WordNet ����������ƥ�䣬Synonym ���� word2vec��ƥ��ͬ��ʡ�Context ���Ǵ� wiki ���ҳ��� relation ƥ��ľ��ӣ�Ȼ��������Щ���Ӽ���ԭ�ʾ��еĴ������Щ relation ƥ����ֵĸ��ʣ����� tf-idf �㷨��
4. Answer Type Matching ������ƥ��
��������˽�Ϊ���ķ������� relation ���ӵĶ������ͺ��ʾ��е����ʴ�ƥ�䣬���� when Ӧ�ú�����Ϊ���ڵĶ���ƥ�䡣
5. Candidate Features �˹���Ƶ�����
- ʵ��ƥ�����������1����ѡ query ��ʵ��ĸ�����2�������ƥ���ʵ�������3��ʵ����ƥ���token��������4-5��ʵ��ƥ����ʵ�ƽ��ֵ���ܺͣ�6-7��ʵ��ƥ�����жȵ�ƽ��ֵ���ܺ�
- ��ϵƥ�����������8��ƥ��ģ���еĹ�ϵ������9������ƥ��Ĺ�ϵ������10-13���ֱ��� literal��derivation��synonym �� context �ĸ��Ƕ�ƥ��� token ������14��ͬ���ƥ���ܷ֣�15����ϵ������ƥ���ܷ֣�16���𰸵� relation �� KB �г��ֵĴ�����17��n-gram ����ƥ���
- �ۺ���������18������ 3 �� 10 ���ܺͣ�19���ʾ���ƥ�䵽ʵ����ϵ�Ĵ���ռ���أ�20-22�������ƽ����СΪ 0 �� 1-20 ����� 20��23��������ƥ��Ķ�Ԫ���
6. Ranking
���IJ����˻��� learning-to-ranking �ķ����������������Ա�ѡ������� ranking������ʹ���� pairwise ranking�����������ѡ�� query��Ԥ����һ�����ָ��ߣ�Ȼ��ȡʤ�������Ǹ���
������������ logistic regression �� random forest��
ʵ����
����ʹ�� Freebase ��Ϊ KB�������� WikiData ͬ����Ч��
���ݼ�ʹ���� Free917 �� WebQuestions��ǰ���ֶ���д�˸��� 81 �� domain ����Ȼ�����ʾ䣬�ȷ��ÿ���ʾ䶼��Ӧһ�� SPARQL ��䣬���������� KB �в鵽���𰸡�ѵ�����Ͳ��Լ�����Ϊ 7:3��
WebQuestions ���� 5810 ���� Google Suggest API �����������ʾ䣬�� Free917 ��ͬ���ǣ����ȽϿ��ﻯ�����һ��ȷ���������⸲�ǵ������Ϊ Google �ϱ��ʵ��������������ڰ����ɵģ������ϴ�ѵ�����Ͳ��Լ�����Ϊ 7:3��
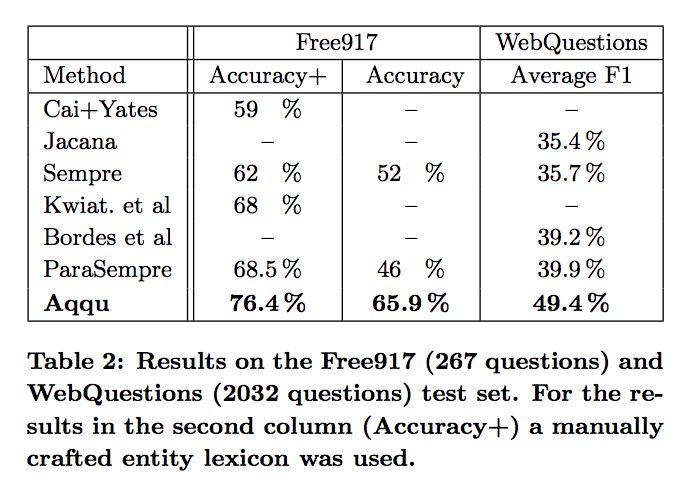
�� Sempre��GraphParser �Ƚ���Ϻõ�ģ�ͱȽ��� accuracy �� F1 score��������£�
���»�������ÿ��������ϵͳ�ɿ��Ե�Ӱ�죺
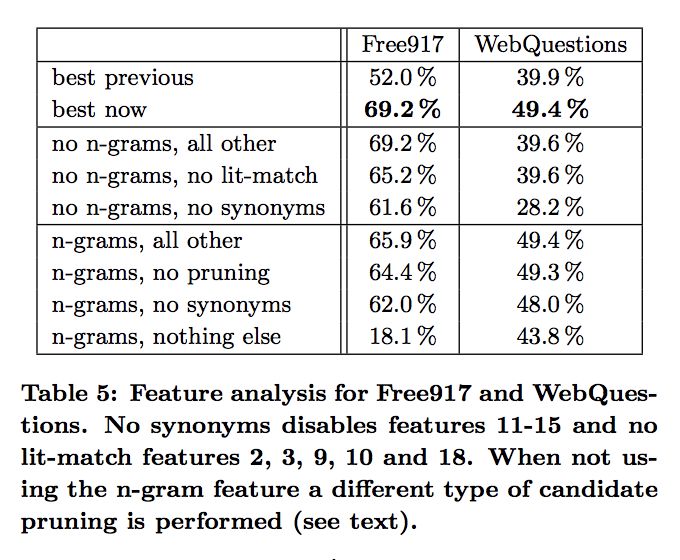
���� 80% �IJ�ѯ����ȷ�𰸶��ܳ����� Top-5 �



















