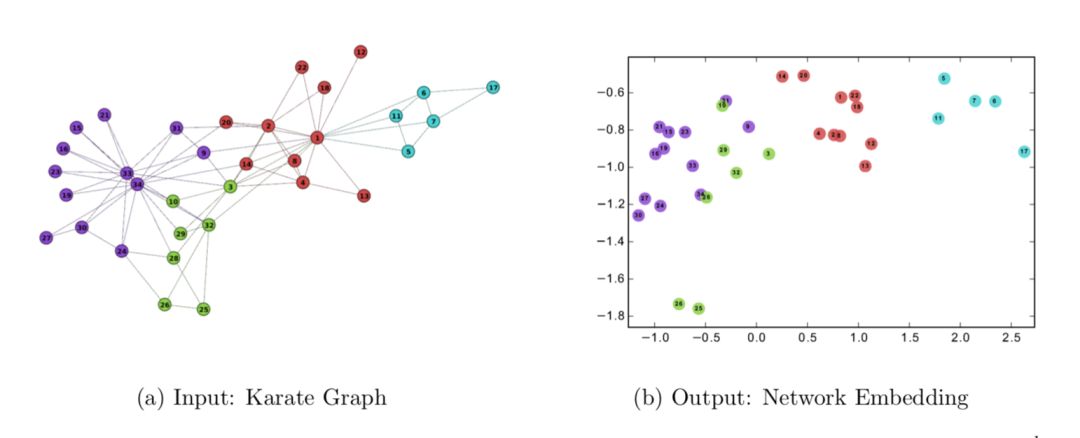
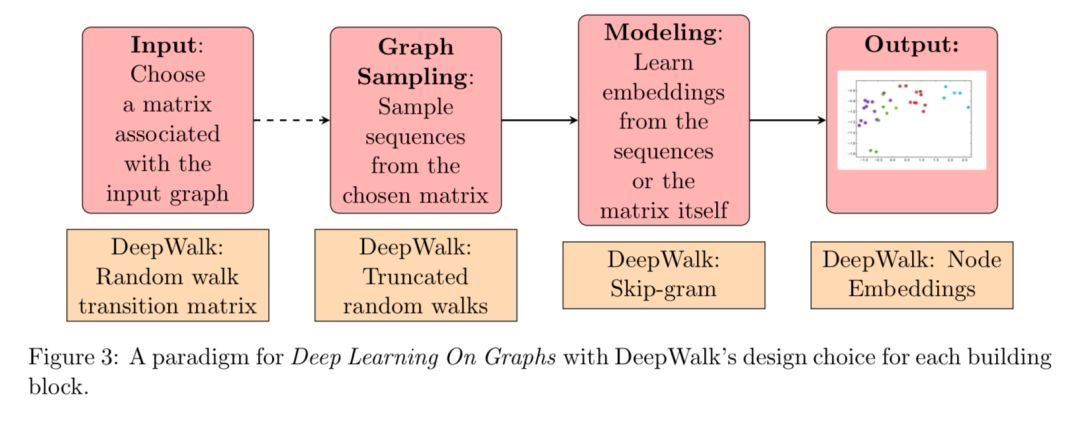
����Ƕ�뷽����Network Embedding��ּ��ѧϰ�����нڵ�ĵ�ά��DZ�ڱ�ʾ����ѧϰ����������ʾ������������ͼ�ĸ��������������������࣬���࣬��·Ԥ��Ϳ��ӻ���
ͨ��������ܽ᱾�о���������½�չ����������Ƕ��ѧϰ��ؽ�չ������������������Ƕ�����������������Ҫ����������Ƕ��ѧϰ����ʷ��Ȼ�����»��������ڲ�ͬ�����µ�����Ƕ�뷽������ල���ලѧϰ��ͬ������ѧϰǶ�����칹����ȡ����½�һ����֤������Ƕ��ѧϰ�����ľ���Ӧ�������ܽ��˸�����δ���Ĺ����о���
Network Embedding ����
������Ϣ������ܰ�����ʮ�ڸ��ڵ�ͱ�Ե�����������������ִ�и��ӵ��������̿��ܻ�dz����֡����������������ڽ���������һ�ַ���������Ƕ�루Network Embedding����NE ������˼������ҵ�һ��ӳ�亯�����ú����������е�ÿ���ڵ�ת��Ϊ��ά�ȵ�DZ�ڱ�ʾ��
�ܵ���˵��NE �������¼���������
��Ӧ�ԣ�Adaptability��- ��ʵ�������ڲ��Ϸ�չ���µ�Ӧ���㷨��Ӧ��Ҫ�ϵ��ظ�ѧϰ���̡�
����չ�ԣ�Scalability��- ��ʵ���籾����ͨ���ܴ��������Ƕ���㷨Ӧ���ܹ��ڶ�ʱ���ڴ������ģ���硣
������֪��Community aware��- DZ�ڱ�ʾ֮��ľ���Ӧ��ʾ���������������Ӧ��Ա֮��������ԵĶ��������Ҫ��ͬ�������ܹ�������
��ά��Low dimensional��- ���������ϡȱʱ����άģ���õ��ƹ㲢����������������
������Continuous��- ��ҪDZ�ڵı�ʾ��ģ�������ռ��еIJ���������Ա�ʸ�
һ�����͵����Ӿ��� DeepWalk����ѧϰ Zachary��s Karate network �����е����˽ṹ��Ϣ��ת����һ����ά��DZ�ڱ�ʾ��latent representation����
Network Embedding ��ʷ
��ͳ�����ϵ� Graph Embedding ��������һ����ά�Ĺ��̣�����Ҫ�ķ����������ɷַ�����PCA���Ͷ�ά���ţ�MDS�������еķ������������������һ�� n �� k �ľ�������ʾԭʼ�� n �� m �������� k << n��
�� 2000 ������ڣ�������������������� IsoMap �� LLE���Ա��ַ��������ε�����ṹ���ܵ���˵����Щ��������С���������ṩ�����õ����ܡ� Ȼ����Щ������ʱ�临���������Ƕ��εģ���ʹ���������ڴ��ģ���������С�
��һ�����еĽ�ά����ʹ�ÿɴ�ͼ�е����ľ���Ĺ������ԣ����磬������������Ƕ��ͼ�Ľڵ㡣������˹����ӳ�䣨Laplacian eigenmaps��ͨ������k����С��ƽ������ֵ�����������������ʾͼ�е�ÿ���ڵ㡣
Deep Learning
DeepWalk [1]�ǵ�һ���������ʹ�ñ�ʾѧϰ�������ѧϰ�������ļ���������Ƕ�뷽����DeepWalk ͨ�����ڵ���Ϊ���ʲ����ɶ����������Ϊ�������ֲ�����Ƕ��͵���Ƕ��֮��IJ�ࡣȻ���Խ����� Skip-gram ֮���������ģ��Ӧ������Щ��������Ի������Ƕ�롣
DeepWalk ���ŵ���Ը���Ϊ�������������������������������� Skip-gram ģ��Ҳ���ÿ�������������Ż������������ߺ� Skip-gram �����ʹ DeepWalk ��Ϊ�����㷨����Σ�DeepWalk �ǿ���չ��������������ߺ��Ż� Skip-gram ģ�͵Ĺ��̶��Ǹ�Ч��ƽ���IJ��л�������Ҫ���ǣ�DeepWalk ���������ѧϰͼ�εķ�����
Unsupervised Network Embeddings

LINE [2]���ù�������������������������Ľڵ���ֻ�о�������ڵ���������Ľڵ�ű���Ϊ�����ڽڵ㡣 ���⣬�� DeepWalk ��ʹ�õķֲ� softmax ��ȣ���ʹ�ø��������Ż� Skip-gram ģ�͡�
Node2vec[3]�� DeepWalk ����չ����������һ��ƫ���������г������ BFS ���� DFS ��������̽����
Walklets [4]��ʾ DeepWalk �� A~1~��A~2~����������A~k~ �ļ�Ȩ�����ѧϰ����Ƕ�롣 �ر������ i<j��DeepWalk ����ƫ���� A~i~ ������ A~j~��Ϊ�˱�������ȱ�㣬Walklets ����� A~1~��A~2~����������A~k~ ��ѧϰ��߶�����Ƕ�롣���ڼ��� A~i~ ��ʱ�临�Ӷ������������нڵ������Ķ��η������ Walklet ͨ���ڶ���������������ڵ������� A~i~������һ��ѧϰ���� A �IJ�ͬȨ��������Ƕ�룬�Բ�ͬ�����Ȳ�������Ľṹ��Ϣ��
GraRep [5]���Ƶ�ͨ����ͼ���ڽӾ�����������ͬ���������ò�ͬ�߶ȵĽڵ㹲����Ϣ��������ֵ�ֽ⣨SVD��Ӧ�����ڽӾ�������Ի�ýڵ�ĵ�ά��ʾ��
Walklet �� GraRep֮�����������Ҫ���졣���ȣ�GraRep ���� A~i~ ��ȷ�����ݣ��� Walklets �ӽ�������Σ�GraRep ���� SVD ����þ��о�ȷ�ֽ�Ľڵ�Ƕ�룬�� Walklet ʹ�� Skip-gram ģ�͡�
��Ȥ���ǣ�Levy �� Goldberg ֤��������������������SGNS�������ؽ��ڵ���������Ľڵ�֮��� PMI ����ֽ⡣�ܶ���֮��GraRep ʹ��������С�Ĺ�����������Ƕ�룬�� Walklet ֤�����߿���չ����
GraphAttention[6]�����һ�� attention ģ�ͣ�������ѧϰ��߶ȱ�ʾ����õ�Ԥ��ԭʼͼ�е�������GraphAttention ����Ԥ��ȷ�������������������Ľڵ�ֲ��������Զ�ѧϰ��ͼת��������ݼ��� attention��
SDNE [7]ѧϰ�ڵ��ʾ��ͨ������Զ����������� 2 ���ھ�֮��Ľӽ�������ͨ����С�����ǵı�ʾ֮���ŷ����¾�������һ���������ڽڵ�֮��Ľӽ��ȡ�
DNGR [8]����һ�ֻ�������������ѧϰ����Ƕ��ķ��������Dz���������˲���������ͼ�νṹ��Ϣ�����ǽ�һ������Щ�ṹ��Ϣת��Ϊ PPMI ����ѵ���ѵ�ȥ���Զ���������SDAE����Ƕ��ڵ㡣
Attributed Network Embeddings
�����ල����Ƕ�뷽������������ṹ��Ϣ����õ�ά�ȵ�����������������ʵ���������еĽڵ�ͱ�Եͨ���븽���������������Щ������Ϊ���ԣ�attribute�������������� Twitter ���罻����վ���У��û����ڵ㣩�������ı������ǿ��õġ������������Ƕ�뷽�����ӽڵ����Ժͱ�Ե�����еķḻ������ѧϰ��
TADW [9]�о��ڵ����ı�����������������TADW ����������֤���� DeepWalk ʵ�����ǽ�ת�Ƹ��ʾ��� M �ֽ�Ϊ������ά�����ܴ˽����������TADW �����ı��������� T ͨ���� M �ֽ�Ϊ W��H �� T �ij˻����������ֽ���̡���� W �� H��T ����������Ϊ�ڵ��DZ�ڱ�ʾ��
CENE [10]��һ������Ƕ�뷽��������ͬģ��ڵ��е�����ṹ���ı�������CENE ���ı�������Ϊ�������͵Ľڵ㣬�����ýڵ�-�ڵ����Ӻͽڵ��������ӽ��нڵ�Ƕ�롣 �Ż�Ŀ���ǹ�ͬ��С������������·����ʧ��
HSCA [11]��һ�ֹ���ͼ������Ƕ�뷽������ͬʱģ��ͬ�����������˽ṹ�ͽڵ�������
Maxmargin DeepWalk��MMDW��[12]��һ�ְ�ල��������ѧϰ���ֱ�������еĽڵ��ʾ��MMDW ����������ɣ���һ�����ǻ��ھ���ֽ�Ľڵ�Ƕ��ģ�ͣ��ڶ������ǽ�ѧϰ�ı�ʾ��Ϊ������ѵ����ǽڵ��ϵ�����Ե SVM ��������ͨ������ƫ���ݶȣ��������ϸ������������еIJ�����
Heterogeneous Network Embeddings
�칹������ж���ڵ���Ե��Ϊ��ģ�ⲻͬ���͵Ľڵ�ͱ�Ե��������칹����Ƕ�뷽��ͨ��������С��ÿ��ģ̬����ʧ��ѧϰ�ڵ�Ƕ�롣��Щ����Ҫôֱ������ͬ��DZ�ڿռ���ѧϰ���нڵ�Ƕ�룬Ҫô����Ϊÿ��ģ̬����Ƕ�룬Ȼ������ӳ�䵽��ͬ��DZ�ڿռ䡣
Chang[13]������칹��������Ƕ���������ǵ�ģ������Ϊÿ��ģ̬����ͼ���ı�������һ��������ʾ��Ȼ��ͬģ̬��Ƕ��ӳ�䵽ͬһ��Ƕ��ռ䡣�Ż�Ŀ����������ӽڵ��Ƕ��֮��������ԣ�ͬʱ��С��δ���ӽڵ��Ƕ�롣ע�⣬�߿�������ͬģ̬�ڵ������ڵ�֮���Լ����Բ�ͬģ̬�Ľڵ�֮�䡣
Zhao [14]����һ���������칹�����й���ڵ��ʾ�Ŀ����������˵��������Ϊά���ٿ��������������͵Ľڵ㣺ʵ�壬���ʺ���𡣽�����ͬ�Ͳ�ͬ���ͽڵ�֮��Ĺ��־�����ʹ���������ֽ�����о�������ѧϰʵ�壬�ʺ����ı�ʾ��
Li [15]�����һ��������ģ�ͣ�����ѧϰ�칹�罻�����е��û���ʾ�����ǵķ�������ģ���û����ɵ��ı����û�������û����û�����֮��Ķ���ϵ��
HEBE [16]��һ��Ƕ����ģ�칹�¼�������㷨�������¼�������Ϊ������һ��ڵ㣨�����Dz�ͬ���ͣ�֮��Ľ�������Ȼ��ǰ�Ĺ������¼��ֽ�Ϊ�¼����漰��ÿ�Խڵ�֮��ijɶԽ������� HEBE �������¼���Ϊ���߽粢ͬʱ�������в���ڵ�֮��Ľӽ��ȡ�
������ԣ����ڳ���Ե�е�ÿ���ڵ㣬HEBE ������ΪĿ��ڵ㣬�������߽��е�����ڵ���Ϊ�����Ľڵ㡣��ˣ������Ż�Ŀ�����ڸ������������Ľڵ�������Ԥ��Ŀ��ڵ㡣
EOE [17]����������칹���������Ƕ�뷽������������ͬ��������������Ե������EOE ѧϰ���������DZ�ڽڵ��ʾ�������ú�гǶ�����ͬ����ı�ʾת��Ϊ��ͬ�Ŀռ䡣
Metapath2vec [18]�� DeepWalk ����չ���������칹������Ϊ�˹���������Σ�Metapath2vec ʹ�û���Ԫ·��������������ͬ���ͽڵ�֮��Ĺ�ϵ��������������������е�ѧϰ��ʾ����������칹 Skip-gram������ģ���Ż��ڼ俼�ǽڵ�������Ϣ��
�ܽ�
�� Network Embedding �������½�Ϊϵͳ�ز�����Ŀǰ NE �ķ�չ��״������ Unsupervised Network Embeddings, Attributed Network Embeddings �� Heterogeneous Network Embeddings �ȼ������ֽ����˽��ܡ����ʼ���Ҫ�����ڽ������е�һϵ�з������������ڲ�ͬ������Ӧ�ò�����ϸ������
�����
[1] Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk��Online learning of social representations.In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701�C710. ACM, 2014.
[2] Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. Line��Largescale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, pages 1067�C1077. ACM, 2015.
[3] Aditya Grover and Jure Leskovec. node2vec��Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 855�C864. ACM, 2016.
[4] Bryan Perozzi, Vivek Kulkarni, Haochen Chen, and Steven Skiena. Don��t walk, skip! online learning of multi-scale network embeddings. In 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining��ASONAM��. IEEE/ACM, 2017.
[5] Shaosheng Cao, Wei Lu, and Qiongkai Xu. Grarep��Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, pages 891�C900. ACM, 2015.
[6] Sami Abu-El-Haija, Bryan Perozzi, Rami Al-Rfou, and Alex Alemi. Watch your step��Learning graph embeddings through attention. arXiv preprint arXiv:1710.09599, 2017.
[7] Daixin Wang, Peng Cui, and Wenwu Zhu. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1225�C1234. ACM, 2016.
[8] Shaosheng Cao, Wei Lu, and Qiongkai Xu. Deep neural networks for learning graph representations. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, pages 1145�C1152. AAAI Press, 2016.
[9] Cheng Yang, Zhiyuan Liu, Deli Zhao, Maosong Sun, and Edward Y Chang. Network representation learning with rich text information. In IJCAI, pages 2111�C2117, 2015.
[10] Xiaofei Sun, Jiang Guo, Xiao Ding, and Ting Liu. A general framework for content-enhanced network representation learning. arXiv preprint arXiv:1610.02906, 2016.
[11] Daokun Zhang, Jie Yin, Xingquan Zhu, and Chengqi Zhang. Homophily, structure, and content augmented network representation learning. In Data Mining��ICDM��, 2016 IEEE 16th International Conference on, pages 609�C618. IEEE, 2016.
[12] Cunchao Tu, Weicheng Zhang, Zhiyuan Liu, and Maosong Sun. Max-margin deepwalk��discriminative learning of network representation. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence��IJCAI 2016��, pages 3889�C3895, 2016.
[13] Shiyu Chang, Wei Han, Jiliang Tang, Guo-Jun Qi, Charu C Aggarwal, and Thomas S Huang. Heterogeneous network embedding via deep architectures. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 119�C128. ACM, 2015.
[14] Yu Zhao, Zhiyuan Liu, and Maosong Sun. Representation learning for measuring entity relatedness with rich information. In IJCAI, pages 1412�C1418, 2015.
[15] Jiwei Li, Alan Ritter, and Dan Jurafsky. Learning multi-faceted representations of individuals from heterogeneous evidence using neural networks. arXiv preprint arXiv:1510.05198, 2015.
[16] Huan Gui, Jialu Liu, Fangbo Tao, Meng Jiang, Brandon Norick, and Jiawei Han. Large-scale embedding learning in heterogeneous event data. 2016.
[17] Linchuan Xu, Xiaokai Wei, Jiannong Cao, and Philip S Yu. Embedding of embedding��eoe����Joint embedding for coupled heterogeneous networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, pages 741�C749. ACM, 2017.
[18] Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. metapath2vec��Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 135�C144. ACM, 2017.