
�����ڿ���������һ�����ǿ������Ļ���������Ҫ��һЩ�ֶν������ֳ�����
����ȥ�е����ã���������
�ܣ�
���գ���ʿ��ɣ��������ѧԺ������ʵ���ң�Laboratory of Wave Engineering��EPFL����һ��С�����ó����Ͻ�����ѧϰ�����Ĵ���˼·ʵ����������̡�
2020 �� 8 �� 7 �գ����о�С����Ϊ Far-Field Subwavelength Acoustic Imaging by Deep Learning���������ѧϰ��Զ����ѧ�Dz������ijɹ������ڹ��ʶ�������ѧ�ڿ� Physical Review X��
��С�����һ����Ҫ������ѧ�еġ����伫�ޡ���Diffraction limit��˵��
������һ�������ճ������ж������������������������ϰ���ʱ��ƫ��ԭ����ֱ�ߴ��������ڴ˻����ϵ����伫������ָ���ܵ�������������ƣ�һ����㾭��ѧϵͳ�������ܵõ�������㡣
����һ������ij��������ܹ��������������ĹⲨ����������һ����ν��Զ����far-field���������Դ���������屾����
Ϊʵ����һĿ�ģ���Ϊ�ؼ���һ�������dz���ķֱ��ʡ��ֱ��������ڲ�������Խ�̣��ֱ���Խ�ߡ�
Ҳ����˵��������Ϊ���伫�ޣ�����ij�����������Ӱ�졣��ˣ�Զ���۲졢ʶ����Щ�ߴ�ȹⲨ��С�ö�����壬�������������ս�ԡ�
��Ȼ��ѧ���Ǵ�ǰ�Ѿ���Ƴ��˼��ַ������˷��������ƣ�����Щ����������һЩ���⣬���磺
�����κ�һ���ѧ�о����ԣ���������֮��Ҫ����о����⣬���Ը�����������ˡ�
�о�С���������б�ʾ��
����ѧϰ�ڲ��Ͻ�������ͬ����Ŀ�ѧ���ǿ�ʼ����ͨ�����ѧϰ�����о����繤�̡����ҽѧ�����������ȡ������������ѧϰ�ɹ������Ӱ���ҽѧͼ�����������ʶ��ͼ����ࡢ����������Լ����ָ��ӵķ������⡣
ʵ���ϣ��ɾ��з�����ģ��Ķ����������ɵ���������磬�ܹ�ͨ���Ե���ÿһ����ڲ����������֡�ѧϰ�����ڸ��������еĽṹ�������˹���Ԥ��
�ܴ�������������ʵ�����о�С���˼·�ǣ��������������ѧϰ������ϣ������伫�������Ʊ�����ƣ�Ϊ�ޱ�dz���������Ӧ�ÿ���һ����·��
���������ںţ��������˽�������ϼ� Metamaterial����ָһ����Ȼ���в����ڵġ��˹�����ķǻ��帴�ϲ��ϻ�ṹ������һ�о��У�С����õ�������ģ�С���صؽ��е���ƣ���г�������
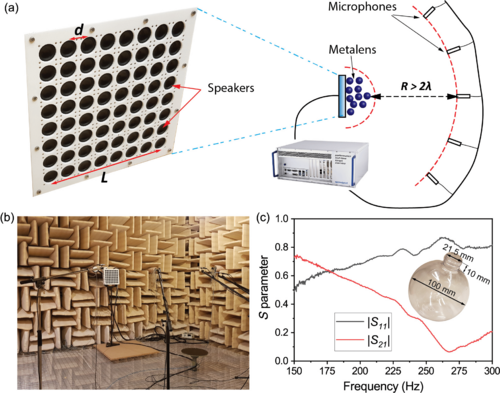
�����Dz���ͼ���ؽ���ʶ���ʵ��װ��
�о�С�����Dz�������ͼ��subwavelength input images���������ý�������ѵ��������ֱ�Ӷ�ͼ������ع��ͷ��ࡣ���У�������������ʧ����Чѧϰ�Ĺؼ���
����ԭ������ͼ��
�������֡�5������״��һ���Dz�����Դ��
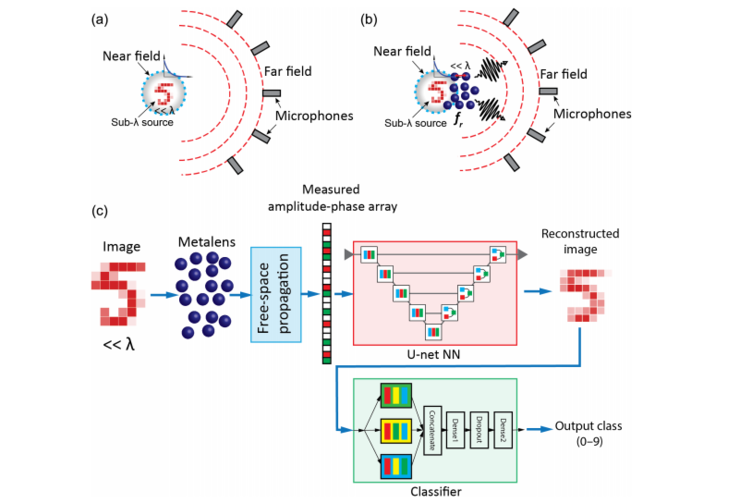
�� a ������ʾ��������Զ���е���˷����в�����źŲ�����������Դ���Dz���ϸ�ڵ��κ���Ϣ�����仰˵������ʹ��ʲô�źŴ������ԣ���������ʵ�ֳ���
�� b ������ʾ�����������һ���Dz�����ķ����г����֮�����Dz���ϸ�ڵ���Ϣ���䵽��Զ���С�
�� c ������ʾ��С�齫��˷����вɼ�����Զ����ֵ����λ���뵽�������С�
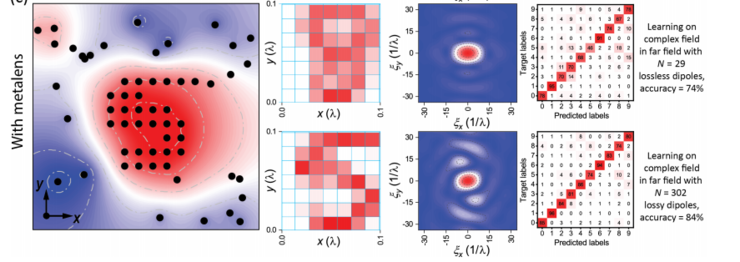
С��ʹ�������ֲ�ͬ���͵������磬һ�� U -net �;��������磬����ͼ���ؽ������Ƕ�㲢�� CNN������ͼ����ࡣ
ʵ������������û�н���Ԫ�ص�����£� U -net �;��������������ؽ�ͼ����㲢�� CNN �ķ���������Խϸߣ�������Զ���ֱ�Ϊ 67.5�� �� 57.5����
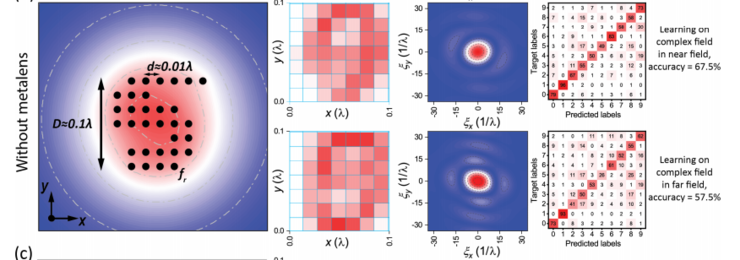
���ڼ��� ñ=29 ����г����������£�Զ�����ྫ�ȴ� 57.5�� ��ߵ� 74��������ͼ���ؽ���Ȼ�����ϵͣ���ͼ��һ�У���
�ڼ��� ñ=302 ����г����������£�����������ྫ����ߵ��� 84���������Dz���ͼ����ؽ�Ҳ�dz�ȷ���ֱ�����ߵ��� 30 ������ͼ�ڶ��У���
�ڳ���֤�����������ܹ���Զ���м�¼�ķ�����λ�ֲ��ָ���ʼ���Dz���ͼ��֮��С��������һ����Ŀ�꣺֤ʵ�������������ݿ��п�������ѧϰ��������
���˽⣬�о�С�鴴����һ������ 600 ����ѵ������ 200 �����������������ݼ������а����ĸ���ĸ E�� F��L �� P��Ȼ��������µġ���С�����ݼ�������ѵ�� U -net �;��������磬Ҫ������������ݼ��е�δ֪��ĸ���з�����ع���

����ͼ��ʾ����������ѧϰ������ʵ���� ��0.94 ��ͼ����ȣ�����ָ������ĸ���ع���ĸ֮��IJ��죩��˵�����ַ������и߶���Ӧ�ԣ���ѧϰ����������ʱ���Ը��Ӹ�Ч�������������ݶ����Ե����ơ�
���ĺ�����֮һ Romain Fleury ǿ������һ�����Ķ����ԣ�
ͨ��ʹ�ó��ȴ�ԼΪһ�����������ɷֱ��ʽ�Ϊ������ͼ������ԶԶ���������伫�ޡ����ͬʱ�������������ź�������Ϊ��һ���ܴ��ȱ�㣬����ʵ֤����������������ʱ��������һ�����ơ�
ʵ�����о�С�黹��Ϊ����һ����������ѧͼ�������������⡢��������н���Ӧ�ã�����������ҽѧӦ������Ϊһ�������ޱ����ѧ���й��ߡ��������ĺ�����֮һ Romain Fleury ��˵��
��ҽѧ��������ʹ�ó������۲�dz�С�����彫����һ���ش�ͻ�ơ�������ζ��ҽ������ʹ�ø��͵�Ƶ�ʣ�������������ܵĹ���֯��Ҳ�ܻ�ȡ����Ч����ѧ����
������Դ��

















