ǰ��
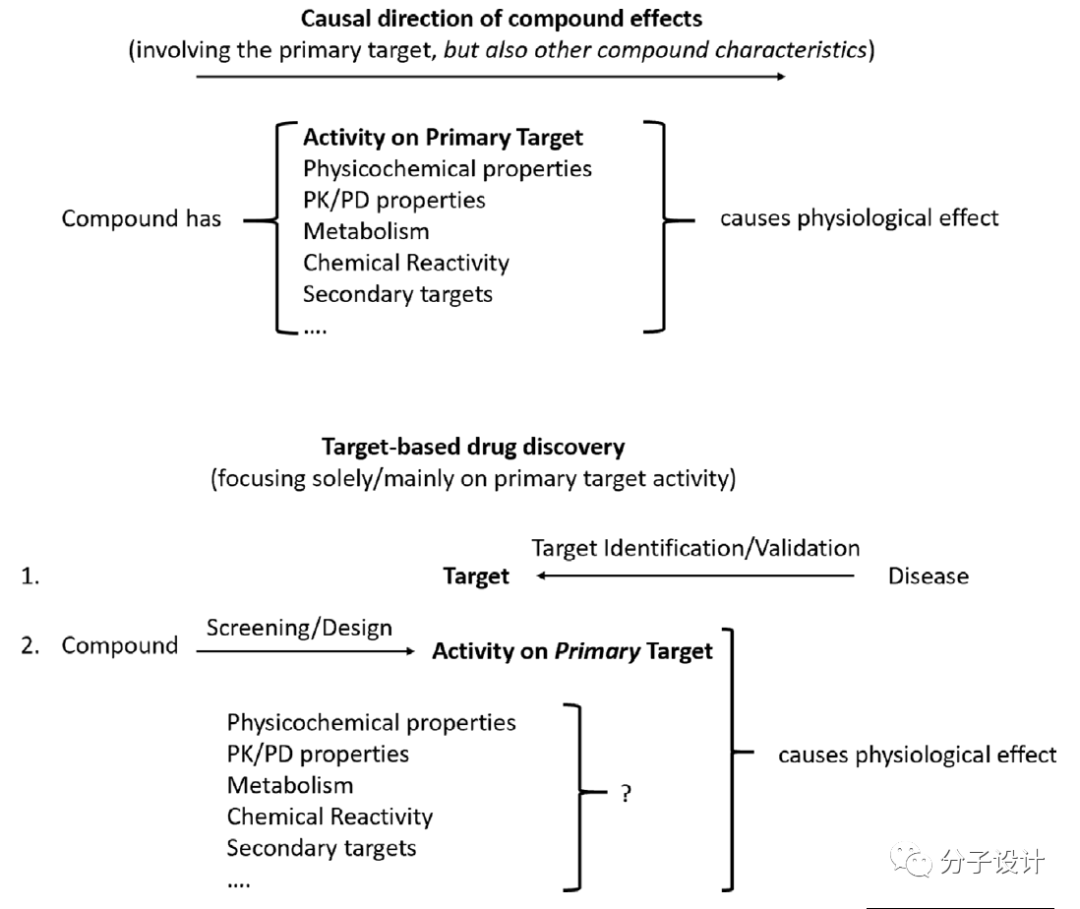
�˹����ܣ�AI�������ͼ�������ʶ��������������Զ��Ӱ�죬��һ��չ�Ѿ�ת��Ϊʵ��Ӧ�á�Ȼ������ҩ����������ֽ�չ��Ȼ���٣�����һ��ԭ������ʹ�õ����ݱ�������ͬ��������ݴ��������IJ��죬��ͼ����������ѧ�����������������������������ڿ������ݵ��������Լ���ҩ��ֵ�����ԣ���Щ��������AI��ҩ��������Ӧ�á�
δ����Ҫ���ǸĽ�������ϵͳ�����⣬�Լ����������㹻������ʵ��������ݣ��������ƽ�AI��ҩ�������ķ�չ���Ӷ��ܹ������µĻ�����Լ��µ�����ģʽ���Ӷ��ܹ���ʵ�ʵ��ٴ�Ӧ���б��ֳ��������Ч�Ͱ�ȫ�ԡ�
�������ݺ��������ݵIJ���
�˹������Ѿ��ı�����������������������ͼ�������ʶ���������㷨���������ݵ�Ҫ��Ҳ�dz���Ҫ���ر����ڡ����ѧϰ���ı����£����ݸ���������Ҫ�ģ����漰���������ݵ���������ֲ���
��ͬ����Ŀ������������ܴӽ������ٸ���������ע�͵����ݵ㣨����ע���п����շ�ҩ���Ը����˵�ҩ�DILI������˹����Ӫ�ij���ÿ����õ�Zettabytes��1021�ֽڣ������������ɹ�ʹ�õĻ�ѧ��������������Խ��١�
���˴������������⣬�Լ�������ĵ���ʽ��ʾ���ݵ�����Ҳ������Ҫ��Ϊ�����ھ�ʹ����ض˵������ݵ�����Ҳ����ˡ����ⷽ��ͼ��ʶ��ͻ�ѧ������������������IJ��졣
�ڶ�ͼ����������з���ʱ���Զ����ģ�ͽṹ�ı�ʾ�ͳ��ֱ�ʹ�û�ѧ����������ʱ��Ϊ��������ǩ�ķ���Ҳ��Բ���ôģ�����ڻ�ѧ����һ���������ѱ���ͨ����δ֪�ģ�һ�ֻ�ѧ���ʵIJ�ͬ���浼�²�ͬ���͵�ЧӦ����Щ������������йأ���Щ��������������йء��������������������͵���Ϣ�ṩ�����ĸ��յ���ص���ϢҲ�Ǻ�ģ���ġ���ѧ����������Ĺ�ͬ���ǣ���ǩ�ںܴ�̶���ȡ�����ض�ʵ������ã���ʹ��Щ��ͬ�Ķ����ڡ�ԭ���ϡ��ǿɲ����ġ�
�˹�������Χ������͵���Ϸ��ȡ����ͻ���ԵĽ�չ������������Ϸ��ҩ������üö࣬��Ϊ����һ������״̬����������ȷ����ģ����ҿ�����ؼ��㣨�������������ǣ���Ȼ��������ѧ����ϵͳͨ������ѭ��ȷ����Ĺ�����������Щͨ������δ֪�Ĺ�����ֻ�ܴӿ��õ����������л�ȡ�����෴��ϵͳ�����ڴ�����ͬ��ˮƽ�϶��壬����ת¼��ѧ����������ѧ�ʹ�л��ѧˮƽ��Ҳ���Դӱ����Ŵ����������ˮƽ����ʱ��Ϳռ�ֱ�ķ�ʽ��ͬʱ����ϸ���ں�ϸ�����źţ���ϸ������������ˮƽ��
���⣬����������Ĺ۲��Ǹ߶������Եģ�ȡ���ڴ����IJ���������ͨ����δ֪�ġ������縱������Դ��SIDER��֮������ݿ��У����ǿ��ԶԾ����ض������õ�ҩ�����ע�ͣ���ʹ����Щ��Ϣѵ������ģ���Խ���Ԥ�⡣Ȼ�������˸�ҩ�����⣬����ЧӦ��ȡ���ڣ���i����������ii��������Ŵ����û��Ŵ���̬�ԣ���iii��Ӱ��ҩ��ҩ������ѧ��PK�����Ե����أ���ʳ��������������iv��������ҩ����v������״̬����vi���Ա𣻣�vii�����䣻���ߣ�viii�������飻Ȼ�����ÿ���ֻ�������ض���һ���ֻ������ϣ����ҿ����ڲ�ͬ�����س̶ȡ���ͬ���������Բ�ͬ����ʽ���֡��������Կ�������ͬ��������ݼ��京����ںܴ���죬����ÿ����һ��������Ч�ķ���������ֱ��ת�Ƶ���һ������ѧ���������ݵ�ʹ�ñ���dz���������ʼ�����䱳���¼��Խ��͡�
�ѵ�1����ν�������ԺͲ�����Ӧ��ϵ����
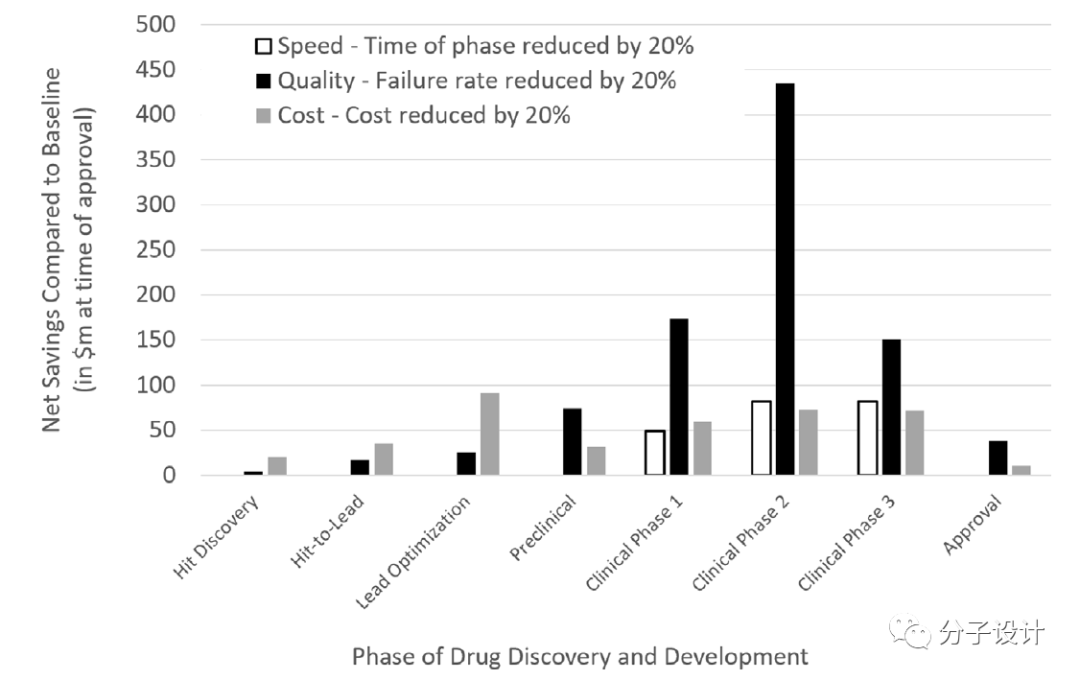
�������ڸ��ݼ�ӵ�ҩ��ѧ�������ݣ����������ʻ��ŵ��������������������ϵ��������ͼ˵����ѧ������������۵ĸ����ԡ��������ǿ��Լ��裬��Ե����ʰе�Ļ����������ⲢԤ����������ϵͳ�е����ã���ȷʵ������ҩ����е��˹����ܷ������������ҵ��ǣ�ʵ�����������ˡ�
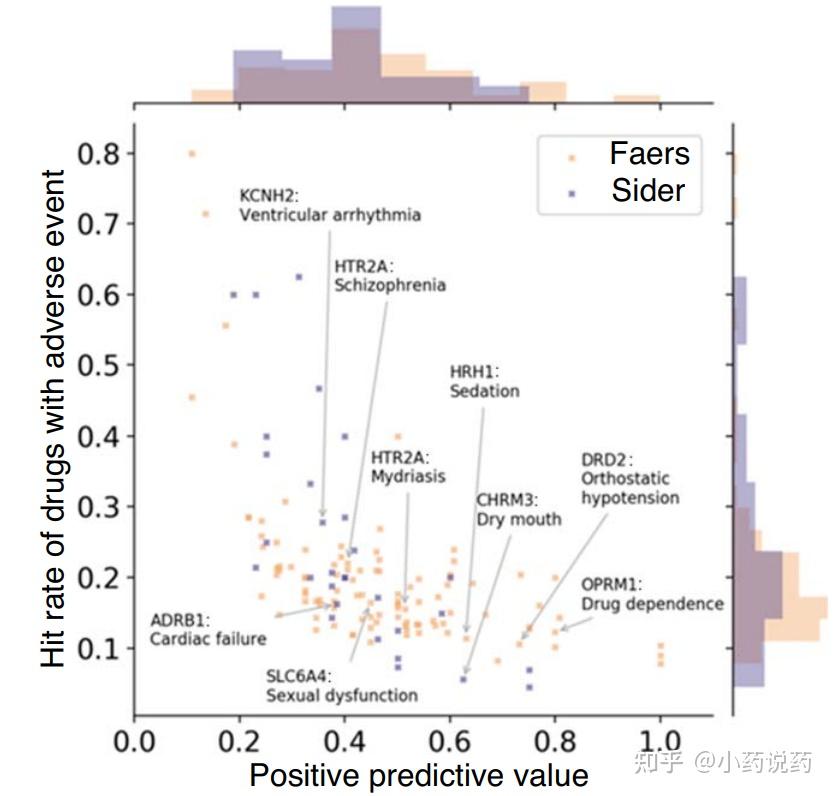
���磬����FDA�����¼�����ϵͳ��FAERS���ڿ��ǰ�ϸ�����������δ���Ѫ��Ũ�ȵı�ֵʱ�������һ��ҩ���Ѫ��Ũ�ȸ���������ijһ�ض��е��������ֵ����ô�ٶ����Ǿͻῴ��һ���ض����͵ĸ����ã����߸��ձ��˵������ЧӦ���������������ͼ��ʾ��
�����������������Ѫ������Ũ�ȵı�ֵ���з�������е���и�����Ԥ��ֵ��PPV���IJ����¼��������нϵ͵������ʣ�����ζ��ֻ��һС�����벻���¼���ص�ҩ����е�����������ء����⣬�����������PPV��أ������ðе�����벻���¼���Ӧ�ĸ������ʡ���ˣ��ܵ���˵������������ҩ��۲쵽�IJ����¼�֮�䲻������ȷ��һ��һ��ϵ��
���⣬���ַ������ڼ���Ϊ�����ַ�����û�п��ǵ��������أ��绯�����л��������PK���Ѱ�ЧӦ�ȣ���������ĵ�һ������û�У�������������Ԥ��ҩ��ЧӦ��ȫ������ѧ�����ԣ�Ȼ���������������ҩ��ַ����Ļ����ٶ���
�����Ȱ�ͪ���Ȱ�ͪ����һ����������Ҳ��һ�ֽ�ͷ��Ʒ����2000�귢�֣������Ե��������������ļ���ʱ������ֳ���������Ч�������⣬��֧������������Ҳ��������֪�ġ������Ȱ�ͪ������������Ϊ��ͨ�����NMDA���巢�����ã�������NMDA��ϼ���������պ��������������ٴ������в�û�гɹ����ⰵʾ�����Ǹ������÷�ʽ�IJ�ͬ����һ�㻹�д�����˽⡣����NMDA�����⣬�о����ְ�Ƭ����ϵͳҲ���Ȱ�ͪ�������йء����⣬��������Ȱ�ͪ�Ĵ�л��������֢����ģ���о��л��ԣ�������Ȱ�ͪ���о���Ȼ������δ֪���������˵��������ȷ������ģʽ����Ӧ֢��ע��ҩ������ѣ���Ϊ��Щͨ������֪��ϸ�ڣ�����ȡ���ڼ�������л�Լ��������ء���ʹ���˹�������ҩ����ж���Щע�ͺܲ�����ݵ�Ӧ�ñ�ü�Ϊ���ѡ�
�ѵ�2��ҩ����е����ݺ������趨
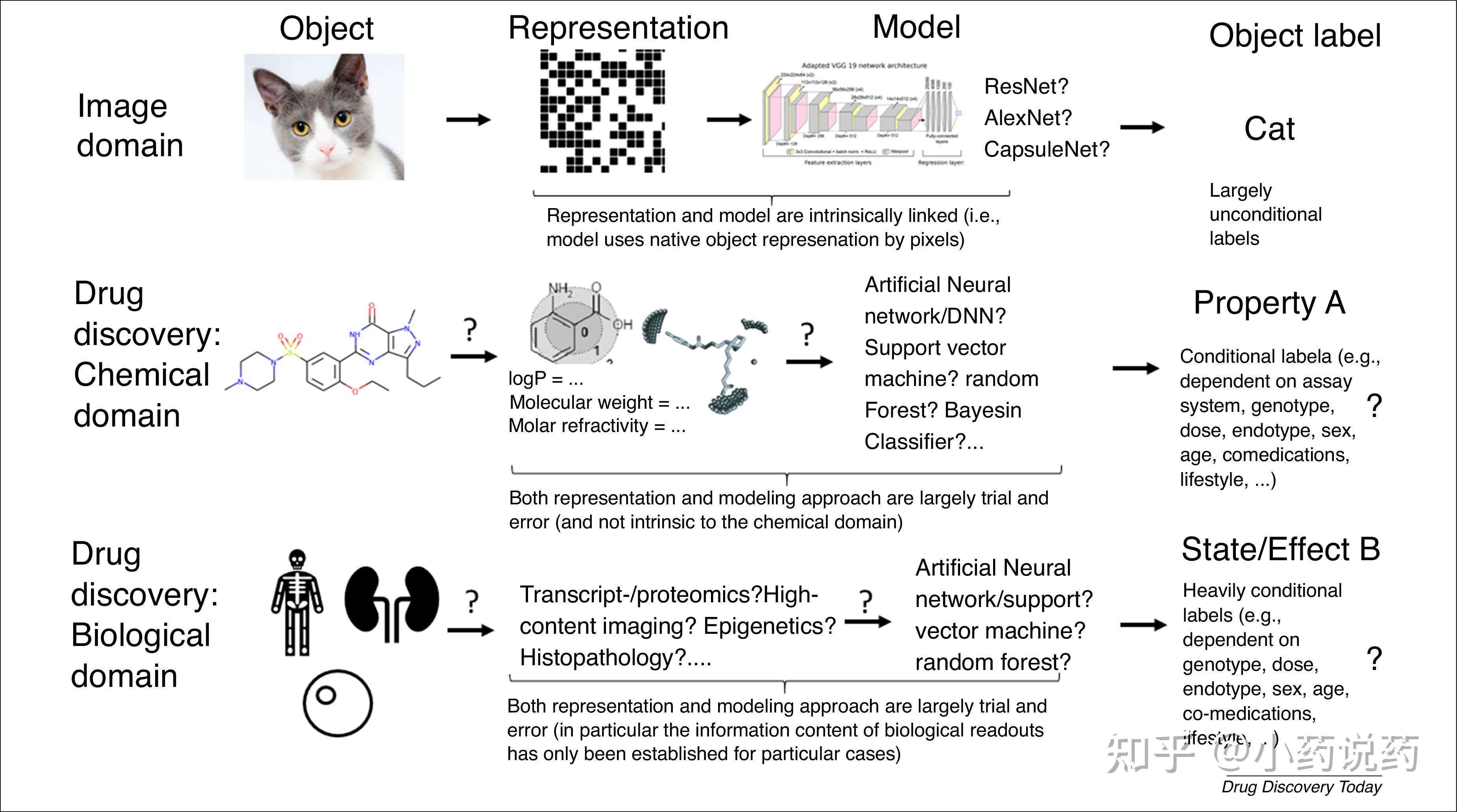
Ϊ����ҩ�������ʹ�����ݷ�������������ͨ�����������������͵�ģ�ͣ���i�����ڴ��ģ�ʹ���ָ���ģ�ͣ���Щģ��ͨ��ּ�ڴӴ����������û�������ӣ����磬������ɸѡ�У���ѡ����������ϸ������ڶ��Ե�ģ�ͣ������ܽ�ȡ�֬���Ի��ʰе�������Ե�ģ��ͨ��������һ�ࣻ�Լ���ii������ͨ����ģ��С�Ŀ������ݵ�ģ�ͣ���ͨ�����������յ����ص����ݣ������о��и����������ʣ�ּ��Ԥ�ⰲȫ�Ի���Ч����յ㣬�����ӵ�ģ�ͣ��綯��ģ�ͣ�����ҩЧ��ȫ�����ݣ�������һ�ࡣ
��ҩ����У�ͨ����Լķ������Ϳ������ɴ��������ݵ㣬����������ѵ�������������Ȼ�����ڴ���ָ�����������յ��Ԥ������Խϵ͵�����£���������������������������ʵ�����õ�ģ�͡������֮�£���������ѧ�Ķ�������������������Է�����ܸ�����������Щ���ݸ������ɺͽ�ģ��
�ܶ���֮������Ŀǰ��û�к������͵�����������ģ�ͣ��Ӷ����������˹����ܽ���ҩ��֡���ˣ�����Щ�����յ���н�ģ�������������仯Ҳ����ı���Ϸ������Ϊ���Dz���ת��Ϊ��ҩ�ﰲȫ�Ժ���Ч��ص��κ������յ㡣����������£����Ƕ�����ѧ�����������ָ��������Ҫ����ʲô��������յ��ѡ�����������ʡ�PK����Ч��ȫ����أ��������������ת��Ϊ�ٴ����ش�ȷ������ء����ڿ��û������ݵ���һ���ԣ�����ʹ�ú����㷨Ҳ�����Ƶ�ǰ�������
�ѵ�3��ҩ����е�����ע�����ʶ
���ڸ���ԭ������ע��ͨ��ԶԶ���ʺ����������ھ�����ҩ��ġ�����ģʽ���������ͨ��ʹ�ý������Ʒ��ࣨATC���������ṩ�������͵ı�ǩ��Ȼ����ATC��������ʷ��һֱ��������ATC���������������ټ��������κ������������ѧ��Ϊģʽ��û����ϵ��
��ô������Щѡ�����磬���ض��б��ϵĻ�����һ�ֳ�����ѡ����ʹ��Entrez����ID��ΪĿ���ʶ����Ȼ���������������ô�����һ��Ψһ��ʶ��Ļ����ǰб꣬��ֻ��һ���ض��ļ��ӱ��壬����һ�����ض�����״̬�����缤ø�����ữ��ʽ��������һ���ض��ı乹���λ�㣬��ôӦ��ʹ���ĸ���ʶ�������⣬�ðе�Ҳ���ܱ����ƣ�����Ũ�ȱ��ֲ��䣩�����������ܱ��ı䣨���磬��ϸ�����ͻ�״̬���������ͨ��PROTACs��ǽ��⣬�ȵȡ�
��ˣ������ͬ�ķ�ʽ��ҩ��е�����ã�����ֻ�������ǹ��ܵ�Ч�ġ����⣬ͬһ�е��ϲ�ͬ���͵�����ÿ��ܵ��²�ͬ��Ч�������������£�������ǵ������ϵļ�����������֮��IJ��죻������ҩ��ѧ��Ȼ����������ƫ�е��źŴ��ݻ�������-��������õ�ҩЧѧ�����ǵĹ����Ժ�����������������Ϊģʽ����ǡ��ض���������ʵ�������ھ�Ľ�һ�����ӻ�����ˣ���ʹһ���˽�������һ��ǰ�ᣬ������ض��е�Ļ��Կ��Ա�����ע�ͻ����������ģʽ���Ȿ������һ���ܴ�ġ������������ô�������Ŀ�ĵı�ǩ�������������صġ�
δ��AI��ҩ����еķ�չ����
Ŀǰ�����Ǿ��������������ڵĵط���ģ���������ֻ�ڵƹ����ڵĵط�ȥѰ�ҳ�Կ�ף����������������������ҵ����ǣ�����ӵ�С����ݡ���û�а����ģ�������Ҫ������ȷ�����ݣ�����ȷ�ĸ�ʽ�ṩ����������ȷ��Ŀ�ģ�ҩ����е��˹����ܲ��ܸ���������������ı仯��
�����Ѿ���ʶ����ҩ���������Ҫ���õر���֯������Ŀǰ�������Ѿ��ܹ����õؽ������ݲ��ҡ���Ŀ��������������Щ�������õġ�Ȼ����Ҫ������һ����Σ�������Ҫ��Խ�������ݵľ����ԣ���������Щ��������������Ϣ������������Ҫ��Щ�������ش������ڰ�ȫ�Ժ���Ч����ص����⡣
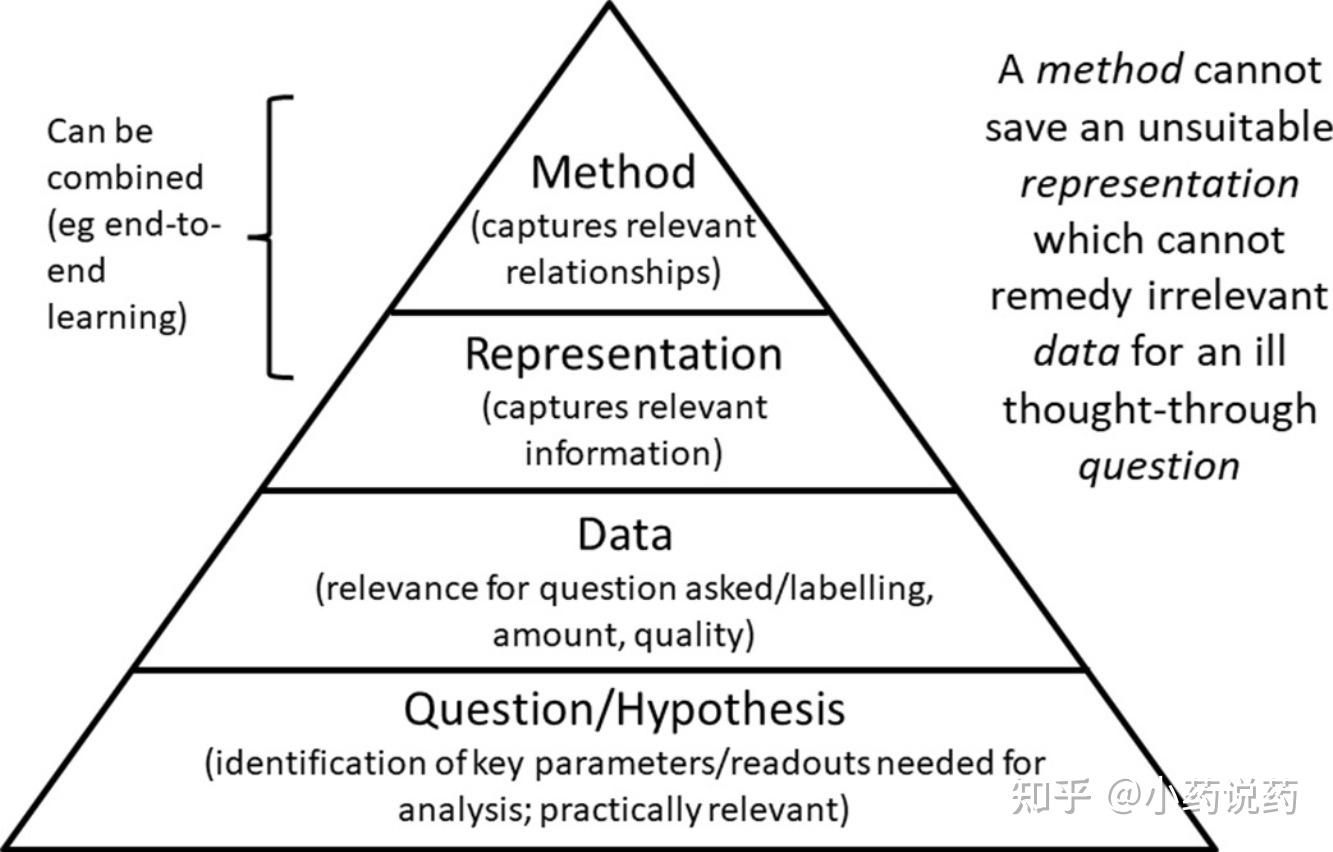
��ѧ�������裬���κ�ģ�͵Ŀ�ʼ����ʹ�����ܹ���һ��������Եķ�ʽ�������ݣ�������Ҫ���ʵ��ķ�ʽ��ʾ��Щ���ݣ�������ʹ���ʵ��ķ����������ݡ�
Ϊ���ܹ���ҩ��ֵľ���������ʹ�û�ѧ���������ݣ�������Ҫ��Խ�������ƶ������������ݣ����ſ�ѧ����ġ�����������չ����ˣ�����������Ҫ���õ�ȷ��Ҫ����ʲô��
��
ҩ�������Ŀ������ݱ��������˹��������ȡ�þ��չ������������ͼ��ʶ�����������и�����ͬ������������£�������ѧ���ݺ��ѱ�ǣ������˹����ܷ�����ҩ�������Ӧ��ʱ��һ���������⡣
Ϊ�������ƶ���һ����ķ�չ��������Ҫ�˽�Ϊ����Ŀ��������Щ���ݣ��������漰�����õ���������ѧ��ֻ�е������ܹ������ڲ����Ͳ���ص������յ�ʱ�����Dz�������һ����ȡ�ø���Ľ�չ������Ŀǰ���õļ����㷨��Ч��Ӧ����ҩ�������������������ٴ��ϵ���Ч�Ͱ�ȫ�ԡ�