��ѧ����֤��һֱ����Ϊ�������ܻ����Ĺؼ�������֤��һ���ض��IJ��������Ǽ٣���Ҫʹ�÷�����������ѧ֪ʶ���ȼ�ʶ�𡢷��������Ҫ�ѵöࡣ
���գ�Meta AI ������һ������֤���� HyperTree Proof Search��HTPS�����Ѿ������ 10 ��������ѧ����ƥ�˾�����IMO���е����⣬�������κ�ϵͳ�����ࡣ���⣬�� AI ģ�͵����ܱ���ѧ�� miniF2F �ϵ� SOTA �����߳� 20%���� Metamath ���ϵ� SOTA �����߳� 10%��
��һ�������ϣ�����֤��Ҫ�ȹ��� AI ������������������Ϸ������ս�ԡ����о�����ͼ֤��һ������ʱ�������ƶ��Ķ����ռ䲻���ܴ�����п��������ġ���Ƚ϶��ԣ��ڹ��������Χ���У���Щ��Ϸ��һϵ���߷��ᱻԤ���������ʹ�㷨û�и�����õ��߷�ҲӰ�첻���ڶ���֤���У����㷨��������ͬ��û�취����ˣ������ٺõ������Ҳֻ�ǰ�������Meta AI���·��������������ֵ����⣬LeCunҲת�Ƴ��ޡ�
������һ��������˵�� HTPS �����ƣ����� a �� b ����������Ϊ 7 ����Ȼ�������� 7 Ҳ�� a + b �������ӣ�������� 7^7 ����������a + b��^7 - a^7 - b^7����ô��֤�� a + b ������ 19��
������������֤���Ļ������Ǵ���ʻ��õ�����ʽ���� HTPS ʹ�� Contraposition �����������˷��̣�Ȼ���ټ����ֲ�ͬ�������
contrapose h₄,
simp only [nat.dvd_iff_mod_eq_zero, nat.add_zero] at *,
norm_num [nat.mod_eq_of_lt, mul_comm, nat.add_mod] at h₄,
����ͼΪ����ģ�ͷ��ֵ�֤��ʾ�������� miniF2F ����һ�� IMO �����֤����

���ӽ����������
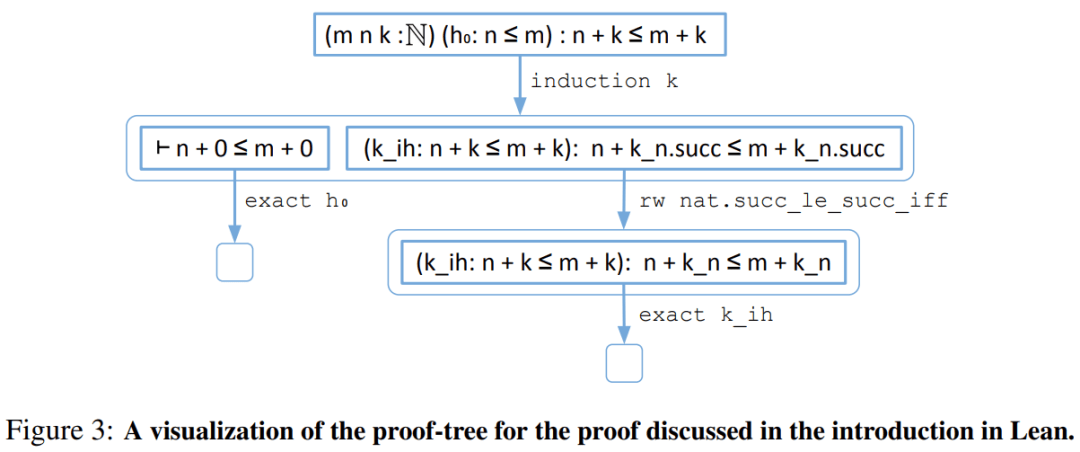
Ϊ��ʹ�ü������д��ʽ����ѧ֤�����̣���ѧ����õķ����ǽ���ʽ����֤������ITP������ͼ 1 �ǽ���ʽ����֤���� Lean �е�һ��֤��ʾ����

��Ӧ��֤�������£�
����һ��Ҫ�Զ�֤������ҪĿ�� g��֤��������ѧϰģ�ͺͶ���֤�������������ҵ� g ��֤��������֤�������� g ��ʼ����չ��һ����ͼ�������ڴӸ���Ҷ�Ӿ�Ϊ�ռ��ij���ʱ����Ϊ֤����ɡ�
����ͼ 5 ֤������Ϊ�����������ģ�� P_�� ������ģ�� c_�ȣ���Ŀ��Ϊ����������ģ�������Բ��Խ��г�����������ģ����Ϊ��Ŀ���ҵ�֤�������������� HTPS ��֤�������㷨��������ģ��Ϊָ�������⣬�� MCTS ���ƣ�HTPS �洢���ʼ��� N��g, t�����ڽڵ� g ��ѡ����� t �Ĵ�������ÿ������ t ���Ŀ�� g ���ܶ�����action��ֵ W��g, t������Щͳ�����ݽ�����ѡ��Ρ�
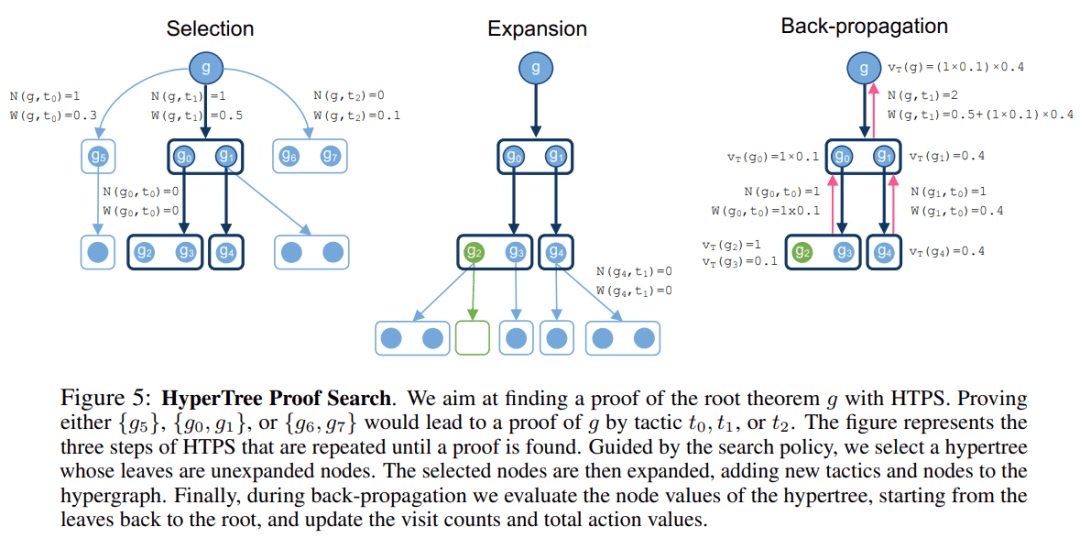
HTPS �㷨�������ظ�ͼ 5 ������ѡ����չ����������������������ͼ��ֱ���ҵ�֤�����߳�����չԤ�㡣
Meta ����������֤�������п����Ͳ��� HTPS��a��Metamath��b��Lean �� c��Metamath��Metamath ����һ����Ϊ set.mm �����ݿ⣬���а��� 30k �������д�Ķ�����Lean ����һ���������д�� 27k �����⣬��Ϊ Mathlib��������� Metamath ֤���dz��������⣬��� Meta �������Լ��Ļ�������Ϊ Equations����������ѧ���ʽ��֤����
Ϊ��ģ������˼ά������֤������Ҫ���ض�״̬�͵�ǰ״̬������������⣩��ϵ������Meta ���ȴ�ǿ��ѧϰ��ʼ���÷��������е�֤�����֣�proving assistants������ Lean�����ܽ�ϡ�
Meta ��֤���ĵ�ǰ״̬����Ϊͼ�е�һ���ڵ㣬����ÿһ���²������Ϊһ���ߡ����⣬�о�����ʶ������Ҫһ�ַ���������֤��״̬������������������������Ϸ�� AI ��Ҫ������Ϸ�е��ض�λ�á�
�����ؿ�����������MCTS��������Meta ��������������֮�����ѭ�����ڸ���֤��״̬��ʹ�õĺ���������������ƣ�����һ�������IJ������֤�������

HTPS �DZ� MCTS �����ı��壬�ڸ÷����У�Ϊ��̽��ͼ��Meta ���ù���ͼ������֪ʶ��ѡ��һ��Ҷ����չ����Ȼ��ͨ�������������Ľ���ʼ֪ʶ��ͼ����̽���ģ�����ͼ�ṹ��֪ʶ���ŵ����õ�ϸ����
ʵ��
ÿ��ʵ�鶼�ڵ�һ���������� Lean��Metamath �� Equations�������У�����ģ���� GPT-f ���бȽϣ��������� Metamath �� Lean �����¼�����
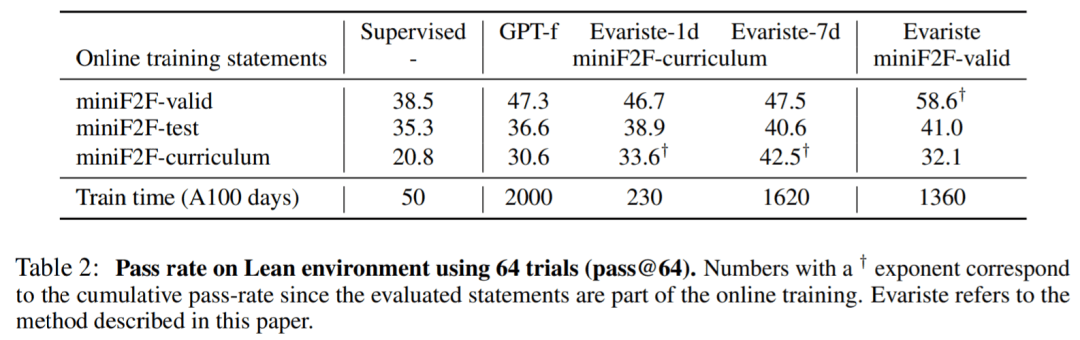
�� Lean �У����о��� A100 GPU ��ʹ�� 32 ��ѵ������ 200 ��֤��������ʵ�顣���� 1 ���ѵ��������200 + 32��A100 ��ļ��㣩��miniF2F �е�ÿ��״̬��statement��ƽ�������� 250 �Σ��� 327 ��״̬���Ѿ��� 110 ������������ĵ�ģ���� miniF2F-test ������ GPT-f�����д�Լ 10 ����ѵ��ʱ����١�
�� Metamath �У����о��� V100 GPU ��ѵ��ģ�ͣ�ʹ�� 128 ��ѵ������ 256 ��֤�������� 3 �����˼ලģ�ͺ�����ѵ��ģ�͵Ľ����
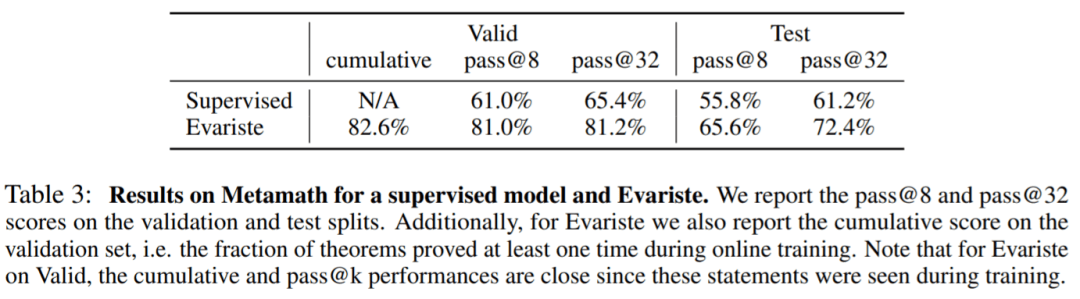
�� Equations �У����о�ʹ�� 32 ��ѵ������ 64 ��֤��������ʵ�飬�����ֻ����£�ģ�ͺ�����ѧϰ�����������ѵ���ֲ�������������ۺ����ɵ����⡣
�ο����ӣ�https://ai.facebook.com/blog/ai-math-theorem-proving/