��һЩδ֪�Ķ������������Dz�֪�������顣��
��ɪ��������
��Ϊ�β���������һ��ģ���ͯ˼ά�ij����أ���
���ס�ͼ��
��ֻҪ����������������⣬�����ܹ��õ��������
����ء���¶�
��ʼ
1������˵��ChatGPT�Ǹ��Ŀ�����
��ô˵��ֻ��ΪChatGPT��һ�ִ�������ģ�ͣ�������Ȼ���Դ���������ͨ�����ѧϰģ�ͶԴ����ı����ݽ���ѵ�����Ӷ�ѧϰ�����ԵĹ��ɺ�������
2������˵��ChatGPT�Ǹ���������
��Ȼ���Դ�����������Ȼ�Ǽ�������ԡ��䷢չ�ĵڶ����ǻ���ͳ�ƵĻ���ѧϰ���������ǻ�������������ѧϰ�������������ѧ�����ϵ����
3��������˵��ChatGPT�Ǹ���������
�����˰��������Ĺ�����˹��Ϊ��ChatGPT�����Ǹ���ļ������������ݵ��������������֡������š��ķ�ʽ�е�ʧ����
���Ľ���һ������ġ��������⡱��ʼ������ChatGPT����ĸ���˼ά���Լ�19���������������ٵIJ�ȷ����������
������ʿ��������ͼ֮��ı��ۿ�ʼ�������Ӻͱ�Ҷ˹���˸�����ʷ����ɱ�మ���ٵ���Ը�������ϵ����������ӵ������ѧ�����߰���˹̹����������ѧ�Ϳ�ѧ�����������ȷ�����벻ȷ���ԣ�����Խ��Խ�
��ƫ������һ�ֽ��ڡ��ֹۡ��͡����ɡ�֮���̬��������ChatGPT��������һ��AI�ȳ���
���Ľ���һ�ָ��˻��ķ�ʽ�����������ѧ�����Դͷ��������һ�鱴Ҷ˹��ʽ�����������Ļ��ƣ��Լ�������Ļ���ԭ����
�����������˼�ȴ�ɸ�֪����ѧ���㣬���ǾͿ���˳�����ӵľ�������ͻ����ۣ�һ·��Ϯ�����ص���ԭ�����壬ֱ��ά�ظ�˹̹��������
���ԵĽ��ޣ���������Ľ��ޡ�
�˹����ܵı�Ǩ��������Ӧ��������֪����ı�Ǩ�ṹ��
��ȷ���Ե���ȷ���ԣ����������ɵ�ͳ�Ƹ��ʣ���������Ϣ�����ڡ��ء����������ƵĴ���Ĺ�����������������ؼ�ϵͳ��
���������ãȻ�������AI�������ʱ����������˶���Ĺ��У�
�����ѱ���������㷨��ǿ���δ֪��������������������������Ȩ���·��Ϊ����
��ʵ�����ȷ�����������ʶ�����ޣ��ٴ��ڴ��ڵĿ�֮�У�������ʱ���Ķ��±�Ե��
һ
��������99%�Ĵ����˶�����˵����⡣
���⣺һ����ͥ�����������ӣ�����һ�����к�������ÿ���������к�Ů���ĸ���һ������ô��һ������Ҳ���к��ĸ����Ƕ��٣�
ֱ���ϣ�������Ů�������ʱ���Ƕ����¼�������һ�����к���������Ӱ������һ�������Ա�ĸ��ʣ����Դ��ѵ�����50%��
��Щ���������˵�����ԡ���ȷ�Ĵ�Ӧ����1/3��
�ùŵ���ʵļ��㷽�����£�
�������ӵ��Ա���4�������
���У��У�����Ů��Ů�������У�Ů������Ů���У�
��ע�⣬���������ֺ͵�����������ر�ǿ�����ϴ���϶�������
������������У�����һ�����к�����3�������
���У��У������У�Ů������Ů���У�
��һ��Ҳ���к�ֻ��1����������У��У������Ը�����1/3��
�鷳���ˣ����Dz���˵��һ����ͥ��������һ���к�������һ���к��ĸ��ʾͱ��1/3�ˣ�
�ⲻ��ѧ����
�������㣬Ӧ���ܴ��⿴���Ͻ�����ʵ����ı����з������ܣ�
����ļ��㣬�����ˡ���һ���к���ͥ�����к����ϴ���϶������ֿ��ܣ�����ȴ�����������һ���к����ڡ��������Ӷ����к��ļ�ͥ����Ҳ���ϴ���϶����ֿ��ܡ�
���ԣ����ͱ��Ŀ�ͷ��Ŀ�ı������ԣ�����ȻӦ����1/2��
��
���������������ġ��������⡱����ǰ��һ����
�����Ϊ��ȷ����1/3�Ĵ����ˣ����ó���Ҷ˹��ʽ��
������Ϊ�����Ŀ�ͷ����Ŀ�����ǹŵ�������⣬���������������⡣
��ν���������ʡ�����ָ���¼�A������һ���¼�B�Ѿ����������µķ������ʡ�
�������ʱ�ʾΪ��P��A|B������������B������A�ĸ��ʡ���
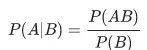
���ݸù�ʽ���������£�
����B��������������һ�����к���
����������¼����������Ӷ������к�������˵�������Ӷ���Ů����
P��B��=1-��1/2������1/2��=1-1/4=3/4
�¼�A����һ��Ҳ���к���
�¼�A��Bͬʱ�������������Ӷ����к�
P��AB��=��1/2������1/2��=1/4
P��A|B��=P��AB��/P��B��=��1/4��/��3/4��=1/3
���ԣ�P��A|B��=1/3��
���ţ�����������Ϸ��
�𰸵�����1/2������1/3��
�ѵ���Ҷ˹��ʽҲ������
��һ�ڵļ����ǡ��ԡ��ģ������ݸü���ó��Ľ���Ӧ���ǣ�
��۲쵽������к�������������ͥ�ĸ�����1/3��
�Ҳ�ֹһ�εؿ�������ʹ�Ǻܴ������ˣ��Լ�רҵ��ʿ������������һ�������Ʋ�������
Ϊʲô�أ�
��Ϊ���Ե����磬��ͬ���Ե����磬����۲�����磬��ͬ����۲�����磬�Լ��ϵ���Ұ�����磬����ν����ʵ�������磬�ƺ�������ͬһ�����硣
��
�����ı�����о�����GPT-4ģ����һ�ζԻ���
�ո����ף��ҵ����ѣ��Ҷ������Щ��ν�Իع�����ģ�͵�����е�������
����ʿ��£�����ʲô��˼���ո����ף�
�ո����ף��ҵ���˼�ǣ���Щģ�ͱ��������ɿ�����������д���ı�����ʵ�������ɻ��������ġ�
����ʿ��£�����ʲô�����أ�
�ո����ף������ǣ���Щģ�ͱ�������ƭ���ǣ��������ǣ��������ǡ�
����ʿ��£�����Щģʽ�϶�Ҳ��һЩ������Ӧ�ã�
�ո����ף�������������������Ȼ�����õĿ����Ըе��������Ͼ���һ���ܹ�������������д�����������ֵ�ģ�Ϳ��Ա��������������ţ�ð�����ˣ�������������
����ʿ��£����ⲻֻ��һ�����ʹ����Щģ�͵����⣬������ģ�ͱ�����������
�ո����ף��Ҳ�ͬ�⡣����Ϊ��Щģ�ͱ����������⡣������һ��αװ����ʽ��һ�ִ���þ��ķ�ʽ��������˼��ͻ�����һ���֡���ˣ����ǿ��Ա����������Բ���ķ�ʽ������ƭ�Ͳ��ݡ�
����ʿ��£����ⲻ�����㷴���Ǻ���˵��������
�ո����ף��ǵģ���Ҳ�������۵㡣�����ţ��κ�ּ����ƭ����ݵ�����������ʽ�������ڵ�Σ�ա�
����ʿ��£��������ˡ�лл���������뷨���ո����ס�
�Dz�˹������������ϵĶԻ�����Ԥ����һ������ü����������ʿ��µĵײ�����ۣ����һ�����ǾͿ��Ժ������ԶԻ��ˡ�
�����Ǻ���˵���ո�������Ϊ���о��Dz��ɿ��ģ�������ʶ�Dz�ȷ���ģ�ֻ�����Բ��ܹ���ʶ���ﱾ����
��������ʿ��µķ����������ȷ��Ϊ��ѧ�������ؼ�Ҫ��֮һ�����������������ͱ�֤����
����ʿ�����Ϊ������ע�����������ﵽ��ѧȷ���ԣ�����֤���������ע���ʡ�������������������
��������������ժ������ٿƣ�����ȷ����ԭ��������������Ǹ����Dz��֣���ȴ���˽кá�
Ȼ������������������ʿ��µ�����ȷ����֪ʶ��ϵ����̶ȵ�Ӱ�������ࡣ
�����ŷ�����ۺ;����ۣ���ţ�ٵ��ƶ��£�����·���һ�������������ܳ��ֹ��ɵĻ��������ϵ۵��״��ƶ��£������������ɵ���ת�š�
������һ��������������֮�С����ӵĻ����ۺ;������峹�ı������ǵ�˼�����磬����Ϊ����֪������ʶ��Ψһ�����˲����ܳ���֪��ȥ���֪������Դ���⡣
�����ӿ�����������������ڡ�
�����ͼ����������;���������е��ͣ������Ͽ������ϵ������������������Ƿ�������ҵľ������������
�������˾����������壬��ǿ��ֱ�����۹۲����ݣ���ѧ����ֻ�DZ���Ϊ����õķ�ʽ�����ݽ����������ֶζ��ѡ�
����ѧ�ƶϡ�һ����Ϊ�����������ִ������۵���Ҫ��չ��
������������Ӱ��İ���˹̹�����������ֶԿ�ѧ�������ƻ��ԣ��Լ��Է���ʽ�����ɵ����ӣ���������ֵ�����
����˹̹��̽���Ե�������������Ͻ���ԭ���������������н⣬�����Ź���֮����
ij�������ϣ�����˹̹������ţ�٣�������˹��ŵɯ�ġ���������ϵۣ����ǿ�ѧ��������۵ĺ����ߡ�
1967�꣬���ն������Ͻ�֯����������ѧ��������һ���˽ᣬ���������Ԫ����Ĺ۵㣬��������������£�
���ƺ��ǰ���ͼ��Ѩ���۵��ִ��档
���������Ƕ�ô��֪�����Ƕ�ô���Ѱ���
���������Ľṹ�����ն������������֤ʵ������磬��֤ʵ���ɺͶ�����ֻ��ȥ֤α��
��
Ҳ���㻹�ǵ���һ������ʵ�˹�����--�������Ӵ�Ļ������ֹ��������Ĵ��룬�����������е�ְҵ���֣��Լ������㷨����Ȼ����˿�˹����ȴ�����ǰ�������
����ʡ�����Ƽ����ۡ�����������Ϊ����������һ���������磨���������ѧϰ�����������Ҹı�����С���鶯�
������50�������ũ�����ֹ۵�Ԥ��AI���ܿ���֣���ʵ������ˡ�ʧ�ܵ���Ҫԭ���ǣ�
�˹����ܵĴ���������ͼ�ô�������������ճ������еĻ��ң����ǻ����ĵ�Ϊ�˹�������Ҫ����ÿһ���������ƶ�һ�������ǣ�������ʵ�������ģ��������Կ̰�ķ�ʽ���й�����
��������������ţ�ٵ�ԭ���쳵�㣬�÷���˼ά��ר��ϵͳ����������ϵͳ����һ��AI������խ�����Ҵ�����
ChatGPT�Ǿ�������Ľ����۵ġ�ʤ�������
����������ơ������ۡ�����Ϊһ����ʶ��ѧ˵���롰�������塱��ԡ�����������Ϊ���Ծ�����֪ʶ����Դ��һ��֪ʶ��ͨ���������ã����ھ����еõ���֤��
������ChatGPT��˼����ѧϰ·����
�����������ָ�����Ŵ��˻��ھ����ѧϰ�ٶȡ��ڲ��ն���������ѧ��չ��������һ�ֽ�����
ChatGPT������ʱ��ĽǶȼ���ģ���˽�������ͨ����ģ�ʹӿռ�ĽǶ���չ�˿�����֮��ȣ������������ǽ���ס�־���ϲ��̽����ӿ�֡�
��ô���˹����������˼���ģ�������ξ��ߵģ�
�б��ڳ��ְ������������������Ҫ����������֤�ݺͽ���֮�佨������ϵ��
AI�������������ߣ��ڲ�ȷ�����½��������Ը����ѡ������
���˹����ܣ��ִ����������������
���ڲ��ֿɹ۲��ԡ���ȷ���ԺͶԿ��ߵĴ��ڣ���ʵ�����е���������Ҫ������ȷ���ԣ�uncertainty���������������Զ����ȷ�е�֪��������������״̬��Ҳ��֪��һϵ�ж���֮�������λ�á�
���⣬���������ȷ�Ķ����������Ծ��ߣ�����������Ŀ��������Ҫ�ԣ�Ҳ��������ʵ�ֵĿ����Ժͳ̶ȡ�
Ϊ�˽��в�ȷ��������������Ҫ��������ȣ�������ʹ������80%�ĸ��ʴ���������
�������ṩ��һ�ָ��������ǵĶ�������֪�������IJ�ȷ���Եķ�ʽ��
���˸��ʣ���������������ʱ����Ҫһ�����Ч�����ۡ�
���磬��Ҫȥ������������ǰ90���ӳ��������Ϸɻ��ĸ�����95%������120���ӳ���������������97%��
��ô���Dz���Ӧ��Խ��Խ�ߣ�����Ϸɻ����������أ����һ���������Ҫ��ǰһ����߸���ס�ڻ����ˡ�
�����ʱ����ˣ�����������һ���������Ļ��飬����Ҫ�Ϲ��ʺ��࣬����һ��ס����������������Ѿ��ߡ�����Ƶ�������ǿ����쵽������ʿ����һ���������ġ�
�ɴˣ����ǵó������۵�ͨ�����ۣ�
������=������+������
���ϵ��ִ��������벻������δ��ı��ĹŴ����֡�
��
����෴�����ӵ��˵��У���Ҷ˹Ҳ��������Ҫ��һλ��
������ն�������֮��ı�Ȼ��ϵʱ�����ջ��Ī���ڽ̻ᣬ��Ϊ�ϵ�һֱ����Ϊ����ĵ�һ�ƶ�����
һ��������Ҫ����һ�����������ܹ��������ӵ���ѧ��������������Щ��С����ȷ����ѵ�����ˡ�
�������Ļ�����ʽ�ǣ����A����B��
������˵��������������Ҫô�ǻþ���Ҫô�Ǻ�˵�˵���Ҫô����Բ��˵��
��˵�������ó���ѧ����ʦ��Ҷ˹��Ϊ�˷������ӣ����о����˱�Ҷ˹��ʽ��
һ������Ľ�ֳ����ˣ���Ҷ˹��ʽ������Ϊ��������ѧ����ʵ��ҩ�������ն�ϵ������������ʵ�����������������
���ʣ�������������ʽ����Ϊ�����A������x%�Ŀ����Ե���B��
����Ҷ˹��ʽ���������һ��СС�ģ�ȴ�������������ľ�Ӱ�죩�ɹ�����ĵߵ���
����۲쵽B������x%�Ŀ���������ΪA���¡�
���һ���������ӻ��ɵ����磬�����λ����Ƶع�������Ϊ�Ӵ��ġ��Ը��ʹ�����������硣
���籴Ҷ˹��ͼ�������ӵĶ�������ģ���Ϊ��Ҫ��ϧ��Ķ��֡������������۾ݡ�
��������һ���ı�Ҷ˹���㣬���������������ѧϰ���顣
��Ŀ���ں��������������ӣ�һ�����������ӣ��ӳ�����6�ĸ�����1/6��һ�����������ӣ��ӳ�����6�ĸ�����1/2��
��ʱ�����������һ�����ӣ�����һ�Σ��õ�һ��6��
���ʣ�������һ�εõ�6�ĸ����Ƕ��
����ĵ�һ�����Ǽ�������������������Ӻ��������ӵĸ��ʷֱ��Ƕ��
��������������Ҷ˹��ʽ���ټ������¡�
���������ӵĸ���Ϊ��1/6 �£�1/6+1/2��=1/4
���������ӵĸ���Ϊ��1/2 �£�1/6+1/2��=3/4
����ĵڶ���������������ӵ���Ϣ��ԭ���ĸ����Ǹ�1/4�������ڷֱ���1/4��3/4��
��ô������һ�Σ��õ�6�ĸ��ʾ��ǣ�1/4��1/6+3/4��1/2=5/12��
�ӱ��ʲ���������������ļ��㲢�����������飺
���������Ӷ��Ƕ����¼���Ϊʲô��һ�������ӵõ�6�ĸ��ʺ͵ڶ��εĸ��ʲ�һ����
��Ҷ˹���ʵĽ����ǣ���һ�������ӵõ�6����һ�������Ϊ��Ϣ�����������ǶԵڶ��������ӵõ�6�ĸ��ʵ��жϡ�
�ɻ���˻�����ʣ�����û�м��䣬Ϊʲô��һ�εĽ���ᡰ�ı䡱�ڶ��ν���أ�
���ǣ�û�иı�����ֻ�Ǹı��ˡ������
��ʹ�����������ӣ�������Ȼ��֪����������������Ļ������ģ������ǿ��Դ������ֲ�ȷ������ǰ�ߣ�Ϊ����Ҫ���¡���������������������ĸ��ʡ�������ʣ��������
������Ϣ�ı仯�����ٸ��£�������ij�ִ����ʽ�Ľ�����
������Ƕȿ���AI�������������С���죬ȴ��������Ӧ�ԣ��Ӿ����в���ѧϰ���������ݻ���
�Ա���Ϊ�����ڶ��������ӣ��ӵ�һ�����ӵĽ����ѧϰ�˾��飬�Ӷ���Ԥ����Ӿ�ȷ��
������̻����Բ����ظ�����ͬ�������㣬�Ӷ������˾��ߺ����ܵĸܸ�ЧӦ��
��ǰ����������ʿ���������Ϊ���Ǻ��ʵȲ�ȷ����Ԫ�أ�Ӧ��Ӧ����������ᡣ������Ȼ��ѧ����ѧ������������������������ѧ��������ء�
�����ȷ�������Ѿ���Ϊ��ȷ�����磬��������Ҳ����Ȼ���������
���ǣ����ʲ�����Ϊ�������������ݣ�������Ϊ����������
���˹����ܣ��ִ�������д�����������������ʵ��ʾ����ʱ��֤������˵���������ڸ����۵��ƶ�ϵͳ�ijɹ�Ҫ����ѧ��֤�����ı��˵Ĺ۵㡣
���������˾Ͳ�ͬ�Ĺ۵����ۣ�һ�ְ취�ǽ�����������������һ�ְ취�ǣ�
�������¸�ע��Ȼ���������ܿ��¡�
��
�ڡ��˹�ͨ�����ܵĻ�GPT-4������ʵ�顷�ı������ʵ������˱�����
�����ǹ�ȥ���꣬�˹������о�����������ͻ���Ǵ�������ģ�ͣ�LLMs������Ȼ���Դ�������ȡ�õĽ�չ��
��Щ������ģ�ͻ���Transformer�ܹ������ڴ��ģ�������ı��������Ͻ���ѵ�����������ʹ��һ�����Ҽල��Ŀ����Ԥ�ⲿ�־����е���һ�����ʡ���
ChatGPT����λ��������Ϸ���ĸ��֣��õ�������������ѧϰ��
���봫ͳ�����ԣ��Լ������ԣ�����һ����
����������ͼ����һ�������ԣ�����������������У����ݳ���ѧ��
��������Լ���ԭ�����壬��ͼ������Щ�ζ������ԵĻ��ң��������Ժ����ǵ���ʵ����һһ��Ӧ��
�������ص��Ӱ���£�ά�ظ�˹̹��Ϊ��ѧ������������ʵ�����������⣬�Ӷ��ƶ�����ѧ������ת��
һ��������ѧʷ�۵���Ϊ���Ŵ���ѧ��ע�����ۣ�������ѧ��ע��ʶ�ۣ�20������ѧ��ע����ѧ���⡣
��ô����Ϊ��ϵͳ�ش�������˼������ĵ�һ�ˡ���ά�ظ�˹̹�������кβ�ͬ��
�¼�ӳ���۶��ǣ����شӱ�������˼�����Եı��ʣ�ά�ظ�˹̹��һֱ�����Եı��������뱾���ۡ�
Ҳ�������ܴ����ظ����˰����֡�Ī������һ���������ά�ظ�˹̹��ѧ�ϵ�ijЩ��������������
��������λ�¹�����ʦ��������Ϊ���Ǹ�ɵ�ϡ�����Ϊû��ʲô�����ԵĶ����ǿ�֪�ġ������������Ϸ�����û��һͷϬţ���������ϡ���
��ÿ�����һ����ά�ظ�˹̹������Ҳ�ɻ�
��˵��ChatGPT��������������ͬ��������㷨��һ������ʣ�
���������ڲ��������ԻӴ���Χ�������������£�����������ľ��ӣ����������ľ�����
���ɵ�AI����ͼ�������صķ���������ģ����Ϊ��
�����Ժ���������ȵġ��ಽ�����������һ�����й���ָ�ӣ�����һ�����߳���ɣ�ʹ����������Ϣ����������ǿ��ر�����������Ϣ����
�Աȶ��ԣ����ִ��Ļ���ѧϰģʽ��dz���ٲ���������ɣ�ʹ�ô�����Ϣ�Ĵ��ģ���д��������漰��������ر�������
һ����Ȥ�����������߶Աȵ������ǣ���Ӱ��ģ����Ϸ�����ͼ�飬�������Լ��������ƽ�С���������ѧר�ҡ�
���˹����ܣ��ִ���������Ϊ�����������������ģ�ͣ��ԱȻ��ڡ��ķ����䷨������������͡����ֹ���������������������ά���������ڱ��Ļ������е÷ָ��ߡ�
���������ἰ��
������Transformer�������ģ��ѧϰ����DZ�ڵı�������Щ�������������������Ϣ��ͬ�Ļ���˼�룬Ҳ����������Щ���ģģ���з�������ȫ��ͬ�����飬�����Ǹ�����֪����
δ����ô��ȷ������ǣ�AI�红�Ӱ�ѧϰ���ԡ������ǵ���ͼ����������ģ���һ�����Ӱ�Ĵ��ԣ�Ȼ��ȥѧϰ������һ��ʼ�����һ�������˵Ĵ��ԡ�
���Ӳ����������Ҳû�г��������ҲԶû�г����������������Ŀ�����ϰ���������뿴��������ѧϰ���Ե�Ч�ʣ��뺢�ӶԱȣ��Dz����õ�����
�Ҳ���������һ���Խ����ij�����������������ѧϰ��ŵĺ��ӣ�ȴҪ��һ���Ӷ�ѧ����һ�����Եij����˵�ָ����ѧϰ���ԡ�
��������������AI�����һ�����Ӱ㣬��Ű��ѧϰ��
��
AI�������磬�Ƕ�������Ժͻ�����ữ���������Ⱥ���ǻ۵�ģ����Ϸ��
���������Ԫ�ṹ����ԭ�����£�
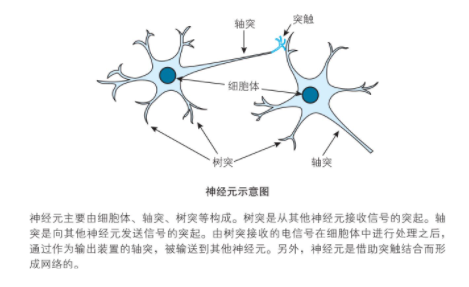
ͼƬ���ԡ����ѧϰ����ѧ��һ�顣
����ԭ�����ü���ģ��ͽ��ͣ����ǣ���Ԫ���ź�֮�ͳ�����ֵʱ��𣬲�������ֵʱ�����
20��������ʮ��������������������洴������Ϊ�����ĸ������һ��ͼ��ʶ���豸�����н����������ġ���ħ��ͨ�����ྺ��������ȡ����ͼ���ж����Ȩ����
�������������Ĺ������ѧϰ������������ͼ��
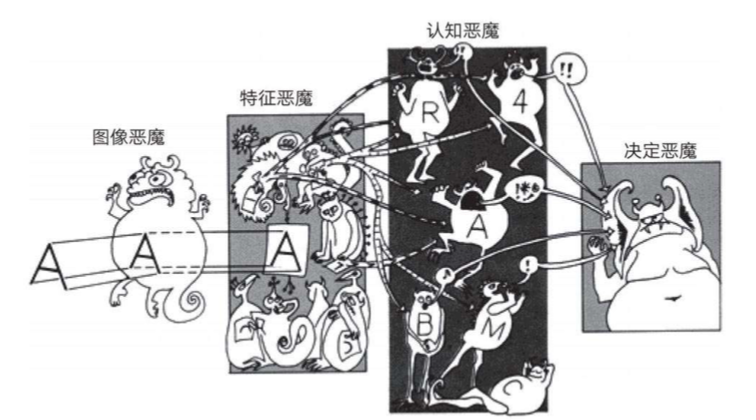
ͼƬ���ԡ����ѧϰ��һ�顣
��ͼ�ǶԵ�ǰ�������ѧϰ�����������
1�������ң��Ǵӵ͵��ߵĶ�ħ����
2�����ÿ������Ķ�ħ��ǰһ�������������ƥ�䣬�ͻ��˷ܣ���𣩡�
3������Ķ�ħ�������һ������������ȡ�����ӵ������ͳ������Ӷ�����������Ȼ�ݸ��Լ����ϼ���
4�����գ��ɴ��ħ�������վ�����
�����ѧϰ����ѧ��һ���У�����������������һ�����������ӣ�������������Ĺ���ԭ����
���⣺����һ�������磬����ʶ��ͨ�� 4��3 ���ص�ͼ���ȡ����д���� 0 �� 1��
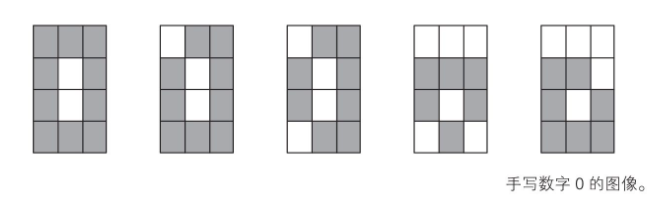
��һ���������
12�����ӣ��൱��ÿ������סһ���ˣ��ֱ���Ϊ1-12������ͼ��
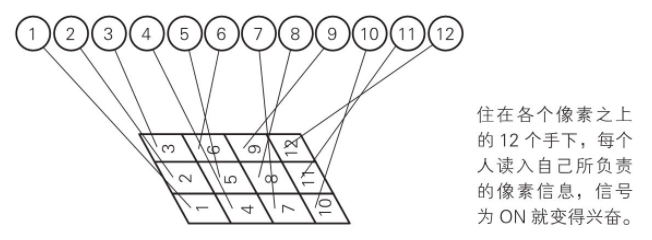
�ڶ��������ز�
��һ�㣬����������ȡ������������������Ҫ��������ΪΪģʽA��B��C������ͼ��
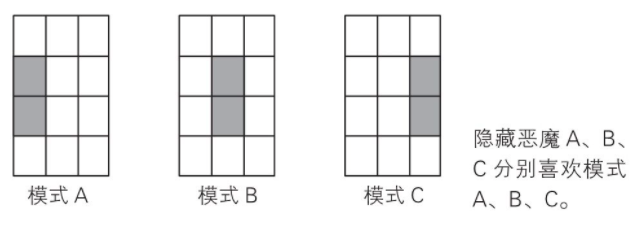
��ͬ��ģʽ��Ӧ����Ӧ�����ָ��ӵ���ϡ�����ͼ��ģʽA��Ӧ��������4��7��B��Ӧ5��8��C��Ӧ6��9��
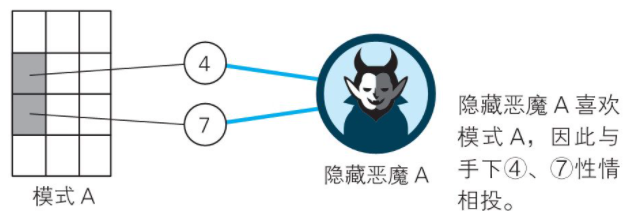
�������������
��һ�㣬�����ز���������Ϣ��
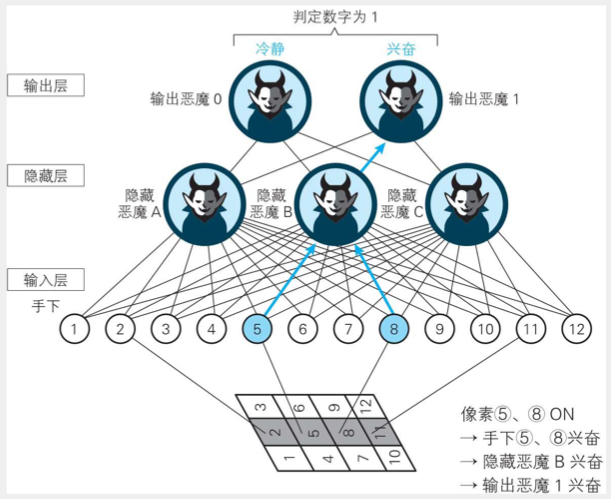
����ͼ����������AIҪʶ���ͼ��
���ȣ�������2��5��8��11���
Ȼ�����ز�5��8����Ӧ����������ȡ����ģʽB�����
���������1����Ӧ�ġ�ģʽB�����
���ԣ������ħ��ʶ���ͼ��Ϊ����1��
������������AI���Ծ�ȷ��ʶ���0��1������������0��1����������ֻ�����ء�
����ô˵���ƺ��������˻��ˡ���������ζ�0��1�أ�
���Ҳ��ͨ��˫�����룬ͨ���������������������ŵĴ�����Ԫ���磨���Ӹ��ӡ�ǿ���ҽ��ܵ����ز㣩��ȡ������Ȼ��ͨ�����Ե�ij����λ�ٽ������ҽ��͵���
�������ڲɷ����ἰ����֪��ѧ��������ѧ�ɹ��ڡ����Դ����Ӿ�ͼ�IJ�ͬ���
һ����Ϊ�������Դ����Ӿ�ͼ��ʱ����ӵ�е���һ�������ƶ������ء���ͬ�������ʾ��
��һѧ��ƫ�������ɵ��˹����ܣ���Ϊ�Ƿֲ㡢�ṹ�Ե����������ڴ������Ƿ��Žṹ��
�����Լ�����Ϊ�������ɶ����ԣ���ʵ���ϴ����ڲ��Ƕ����Ĵ���������������ֻ�Ǵ������ⲿ���硣
�����������������ģ�����ã����ҷdz����á�
��Ը������з���רҵ��������٣���������λ����������ˡ������硱��
��������ԼĴ���Ԫ�أ�Ҳ������ɢ����Ԫģ�͡�Ȼ����Ԫ������������ÿһ�����Ӷ�����Ȩֵ������Ȩֵͨ��ѧϰ���Ըı䡣
��ԪҪ�����¾��ǽ����ӵĻ����Ȩֵ��ˣ�Ȼ���ۼӣ��پ����Ƿ��ͽ��������õ��������㹻�ͻᷢ��һ���������������Ǹ��ģ��Ͳ��ᷢ���κ���Ϣ��
��Ҫ�����¾��ǽ������Ļ��������Ȩ����ϵ������Ȼ�������θı�Ȩ�أ����������ˡ�����Ĺؼ�������θı�Ȩ�ء�
��
����������ѧϰ�����˲�������ݵĺڰ��ڡ�
��������80�����ʼ������30��䣬ֻ�к���һ��������о��������˵�Ͷ����䣬���DZ��ܻ��ɣ�Ҳ�����ò������о��ѡ�
Ҳ�����������ԭ�����ѧϰ����ͷ���٣�Hinton���������£�Bengio������������LeCun���ƺ����ͼ��ô���Щ��ϵ�����������������о�����ѧ�����顣��Ǻܷ����Ǹ���ɵ���ҡ������ʡ�
һ�����ˡ����ᡱ��ϸ���ǣ�2012�����ٴ���ѧ���� ImageNet ͼ��ʶ����������˹ھ�����ҵ��˾��ӵ���������ٽ��ڿ�������ҵ���ۣ�ֻ������һ������Ԫ��
�������ȸ���4400����Ԫ���бꡱ����
�����ɡ�AI��ʹ����ȷ��һ����ָ��ָ��������������ѧϰ��ʹ��ѧϰ�㷨����������ȡ������������������Ĺ���ģʽ��������һ�ڵ���ʾ��
������֪��������ҹ֮�����������������������ݵ�ָ�������������ѧϰһ�ɳ��죬�Ӱ�������һս�����ٵ�ChatGPT����ȫ��
Ϊʲô��Open AI��������DeepMInd���ҶԴ����к��档
OpenAI�����ϴ�ʼ�˼���ϯ��ѧ�������ǡ�����˹�������������ڶ����ѧ����ѧ����
���ƺ����������ٶ����ѧϰ����������������ȫ����ע��
������Ϊ�����ѧϰ���Ը����������е������������������ܣ�ֻҪ�и�������ϵ�ͻ�ơ����硰transformers��������������ʾ����ĸ�����ͻ�ơ�
���⣬��Ҫ��������ӹ�ģ�������������ģ�����ݹ�ģ�����磬���Դ�Լ��100���ڸ��������������ľ�ģ�͡���GPT-3��1750�ڸ�������Լ�ȴ���Сһǧ����
������ģ������������ƣ������д����������������ݡ����������ⷽ�����ø��ã����ҽ��������
����һ����DeepMInd���䷢չ������ٶȣ�����������ȸ�ġ���ҵVS���С������Ѿ����������ɱ�����ܵ�������˹��AI��ѧ�۵�Ӱ�졣
������˹��Ϊ������ChatGPT�������Լҵ�Gopher�����ܿ�����д����Ϊ��滭������һЩ����ӡ����̵�ģ�¡�����AI����Ȼ����������������˵ʲô����
���ԣ���˵��������Щ�����������������ϵģ����ܣ�����
������˹����ʦ��MIT��Poggio���ڸ������ָ�������ѧϰ�е������ʱ���ġ�����������������Ҫ�ӡ���������ת��Ϊ�����Ļ�ѧ��
�������������������ᷨ������Ҳ��ΪҪ̽��������ѧϰ�ı��ʡ��˹���Ԫ�ܵ�����Ԫ��ֱ�����������ܽ������ƴ���Ȼ��
���Ĺ۵����ǣ�����ѧʵ���˵Ķ�����Ҳֻ��ͨ����ѧ�ں��ӣ������ߵø�Զ��
������Ϊ�����DZ���̽�����ܺ�ѧϰ�Ļ���ԭ����������Щԭ����������ѧ����ʽ�����Ե��ӵ���ʽ���ڡ������������ѧ�����˷ɻ������ࡢ���������ķ���ԭ��������ѧ�������Ȼ������������е�����ת��һ������������Ҳ���뿼�ǵ�������ʽ�����ܡ���
����ǰ���۷�ʱ�̵Ĺ�����˹�ͱ�����������������ǿ��ѧϰ�������˹������ߵø�Զ��
���Ƶķ�˼��Ҳ�����ڱ�Ҷ˹����֮�� Judea Pearl��
��˵������ѧϰ��������������ݺ��ʷֲ����ߡ����������������ϵ����û�б����ӣ�������������Ժͼ�
����˵�����ǣ�������أ����������
��Pearl���������Ҫ���������ѧ���⣬�����������������������ܵĻ����������ϵ�DZ�ȻҪ������һ������
���ٿ�ѧ�������ƵĹ۵㣬��ΪӦ�ø��˹����ܼ��ϳ�ʶ��������������������������˽�������ʵ�����������ԣ��������Ҳ���ǡ����ģʽ��--������������ʽ���ֹ���������
���ٶԴ���Ϊ��м��һ������������������ȫ�����������������Ͼ����Ծ������Ƶ������硣��һ���棬����Ϊ�����ֹ���������ܴ���
������������ר��ϵͳ�����⣬�Ǿ�������Զ��Ԥ������Ҫ�����������г�ʶ��
AI�����Ҫ��Щ��������𣿰�����������֤������ν�����Ͷ�ʽֻ�Ƕ���ļв���Ͷ��ѡ�
����AI�Ƿ����������⡱�����������á��������С��ж������������ԡ�����ʶ�䡱Ϊ����
��������Կ��������ߣ�������ܣ������������һģһ�������仨������������ȴ���ܽ�Ȼ��ͬ����ô�ܲ���˵�����жϴ������أ�����ͨ����ͬ���������ź�ʶ����������䲻ͬ�Ļ�����Ȼ����û�д���ֻ��������������ߣ����Բ�֪����������ѡ���
����˵AI��������ʲô������ǹ���������Ϊ�����ˣ�
����������ΪAIû�пɽ����ԣ��㲻�����ܣ��ɻ���Ǽ�ʹAI�����ˣ�����Ҳ��������������ֻ�н���������⣬�������仨����ɫ�ź��ڵ�Ų����Ϸ�����ͬ������ȷ�����仨ȷ�в�ͬ����
��ʮ���꿪ʼ�������š�ģ�´��������硱�����٣��·���ij���ڽ�ʽ�ļᶨ��
���ǣ���ij��·�ڣ�������˹���г��ɣ��������ǡ�����˹�����������һ·��ǰ�����ĵ��ס�
���ٵ�������ѧ�ǡ����������IJ��컯��������ȷҲ�����ʵ���ġ�
����ܹ�����˹��ΪChatGPT�����Ǹ���ļ������������ݵ�����������Ҳ���ò����ϣ�����Ŀǰ�����ѽ������Ч��ʽ��
��
��AI·�ߵķ��磬������һ�ٶ�����ij���ѧ��ӿ��������
�൱����������ڴ�ѩ�ɵĶ��࣬���ټ��������ѧϰΨһ����ҹ�ˡ�
�������ڽ��Ŵ�ѧ������ѧ������ѧ�����ת����ѧ���õ�������ѧѧʿѧλ�������ٶ����˹����ܲ�ʿѧλ��
���ٵ�����ͳ����ѧ�еõ���У��� 1986 �������������ṹ�������������������ص�Ԫ�����������˲�����������ѧϰ�㷨��
����ͼ�����нڵ�֮������߶���˫��ġ����Բ������������и��������ƣ��ڵ������ڽڵ������ֵ���ٴη������ڵ㱾����
��������������Ԫ״̬�仯��������ͳ�Ƹ��ʣ������ƽ��״̬���Ӳ��������ֲ����������л��ƻ���ģ���˻��㷨��
������������ͼƬ���ԡ�ͼ���˹����ܡ�һ�顣
����ũ���ٵ����٣����Ƕ��Ӳ��������������˾����С�
�������ʡ���������ѧ���������dz���֡�
����ֱ��19����֮��֪ �����ȡ��������ڲ��������ӵ������˶��ı��֡��� ô��Ϊʲô�����ܴ��ȵ����崫��������壿
��������˵��ԭ�ӣ����ӣ���ȫ������˶��ġ���������������������崫���ȵ����壬ֻ����Ϊ��
��ͳ��ѧ�ĽǶȿ���һ�������˶����������ԭ�Ӹ��п���ײ��һ���������ԭ�ӣ����ݸ���һ�������������෴���̷����ĸ������С������ײ�Ĺ������������غ�ģ�������������żȻ��ײʱ������������ƽ���ֲ���
�����У�û���������ɣ�ֻ��ͳ�Ƹ��ʡ��⿴�����dz�������
�ᶨ�Ŀ�ѧ�����߷���������Ҳ��������������������������������ı��ʡ�
�Դˣ��������͵������Dz�����ζ������ѧ����һ�ż���ȷ��ѧ�ơ����Ѿ��˻�����ֻ�� �����¼��ĸ��ʣ������ܾ�ȷ��Ԥ�Ծ�����Ҫ����ʲô���ĵز����أ��ǵģ�����һ����ȴ�������鱾�����������ģ�
��Ȼ���������Ǽ����ֻ�Ǹ��ʣ�������ѧ��û�ʹ˿�̨��
Ҳ������Ϊ�����С����¶��ϡ�������ۣ���������ϲ������ģ�����һ�ν��������ƣ�
������������������������ǵ����ͽ�����Ϊ�������ͻ����������������أ��һ������ԥ�ػش���������Ϊ��е��Ȼ�۵����ͣ�����ĵ����͡���
�Դ���ĵ���Ȼѡ�����ۣ�����������ʶ��������֮��ͨ����Դ����չ����һ��ʹ����С����ս������������ͨ�������ܶ�Ŀ���������ʹ�ؽ��͵Ķ�����
������ϵͳһ�����˹�����Ҳ���ܹ��Զ���ʵ�֡��ؼ�����ϵͳ��
�����ԡ����ء�Ϊʳ���˹�����ϵͳ���������������ݡ�
���������㣬��Ҫ10���GPU���ܽӽ����Ե�����������һ��GPU�Ĺ���ԼΪ250�ߣ���������ԵĹ��ʴ�Լ��Ϊ25�ߡ�
����ζ�Ź�����ܵ�Ч����̼�����ܵ�һ�����֮һ��
���ԣ��������ſ˷��˹����ܾ����ԵĹؼ������ڴ��һ�����Ӽ������ѧ������ѧ����������
ʮ
�������˵�����������ռ��ĸ��ӡ���
ţ����һ�������ϵ۵Ŀ�ѧ�ң���Ϊ�����������ʱ��һ�������˹���
����ֻ��ȥ���ֹ�������������ʱ�IJ������⡣���磬����������ʽΪʲô����������ΪʲôҪ�;����ƽ���ɷ��ȣ�
��һ���棬ţ�����ŷ�¿�ķ�굶��ԭ����Ϊ�����ģ�ͻ���ijЩ���Ĺ�ʽ�������������Ŵ���ij�������Ĺ�ʽ���Ӱ���˹̹������Ī�����ǡ�
Ȼ���ڲ�ȷ����ʱ���������ƺ��Ⱦ������ɸ��ܽ���������硣ţ��ʽ��ȷ������������������
Ҳ�������ǶԵģ���ѧ��������һ��ɸ������������磬ijЩʱ���ƺ����е�������ͨ��ɸ�ף����������֪����ô�걸�Ŀ�ѧ��ֻ����ʱ�Ľ��ͣ�ֻ����ʱδ��֤α��ɸ�������Ⲣ��Ӱ��������ǰ��
����һ����ѧ��Ϊ�����籾��������Ϊ�Լ���ģ����ͼ��һ����һͳ���۽������缸���Dz����ܵģ����ο����滹�ڼ������͡�
��������Ȥ�����Ժ���ĽǶȿ���ChatGPT����һ�ַ�����˹̹�ķ�ʽΪ���罨ģ�����������ص㣺
1���Ǹ��ʵģ���������ģ�
2�������ܵ�ȥģ������������һ����ģ�͡����Ӿ�����ѧϰ�ͽ���������ȥ̽Ѱ��һԭ����
3�����ŷ������ʱ��ˣ����������ռ��ļ���
4��������������Ϊ���Լ�Խ��Խ��һ����
AI����������������һ�����������������Ե��ȳ���
��һ����2016�꣬��������Ȼ����������������
�����ȥ�ˣ�AI�ٴ�����Open AI����û�д��ں��ӡ���ȴ������Ӱ������Ϊ�㷺���˳���
��һ�Σ��㷺���ƺ�սʤ��רҵ�ԡ������ƺ�����ע�Ǹ��ử���ġ���������Լ������AI���������Ǹ���սʤ����ھ������о��������۵�������ඥ�������AI��
�������ж����ǹ��̵�ͻ�ƺͼ����ķ�Ծ���ж�������ҵ�����µĴ������漣���ж������������߳�����ĭ��
��ӹ���ɣ����������ΰ��ͻ�ƣ����ٶ����ڶ������Ժͷ����������Ľ�֮֯��ʵ�ֵġ�
������Ļ����ǣ�
1����ˮ�ߡ���Ӣΰ�
2����ƽ̨�ij��֣�
3����ƽ̨����ͨ��������������������¼�ֵ�ռ䣬�����ȫ�µIJ�Ʒ�ͷ���Ҳ�жԾ��м�ֵ�ռ���Ӷ
4��AI���Ϊ������ʩ��
���ǣ�ˮ�͵��Ϊ������ʩ����������Ϊ������ʩ����AI��Ϊ������ʩ�����Ǽ���Ȼ�������
��ŵ�����Ҳ���ǣ���ҵ�ϵ�¢���������ֻ�����Ӳпᡣְҵ�ϣ������м�ײ�����������
5�����������͡�Ӧ�á����л�������������Щ�ܹ��Ϻõ�����AIƽ̨ʵ���˻���ϵij�����Ӧ�á�
�Ը�����ԣ�����Ҫ�ʵ��ǣ�AI����Ҫ����䵱�»�����ʩ����ϵͳ�������ڡ�����Ա��˾��������Ա�����Ա������ʱ����ɫ��
���
��Ү��˵����һ������֮���Կ�ȡ��������Ϊ�������е�Ҫ�ظ�����λ������������������ܹ���������������²���������������������
����Ϊֹ�������в��ܶ���ʲô�����ܣ�ʲô����ʶ��
Ȼ����ȴ��һ���ں����ĺ��ӣ��������ǿ��ܻᳬԽ��������ܣ�����ӿ�ֳ��������ʶ��
���ı���������д����
����û�н��Ϊʲô�Լ����ʵ�����Խ�����ܵĻ������⡣��������������ƻ��ʹ���ģ�
�����ĺ���ֻ�Ǽ��㷨���--�ݶ��½��ʹ��ģ�任���뼫����������ݵĽ��ʱ����Ϊʲô����ֳ�����ձ���������ܣ�
AI�о���Ա���ϣ������Ƿ������û���κδ��������ڶ����������ʵ�֣���һ����Ҫ����ѧ���⡣
��2023�������������Ĵ��죬�Ҷ�ChatGPT��̬��̹Ȼ���ڴ���
��ϣ�����������߱��Ŀ����ԣ�Ϊ������ҵ��������ijЩ���ؼ�����
������Ԥ���У����ڴ�Kurzweil���Ǹ���2030 �꼼����ʹ����������������Ԥ�ԡ�
���Լ�������û��Ȥ��������ʧȥ���ߵ����ǡ��Ҷ�������������ԡ����������塱�ĵ��ǡ�
�Ҳ�̫������ʶ���ϴ�����Ϊһ���ϴ����Ϳ��Ը��ƣ��Ͳ���Ψһ�ģ���ʧȥ��������־����̸�Ρ���ʶ���أ�
����ᶴ����������ε���������ķ��˹�����������
�������Ƿ��������еİ��أ���ʧȥ�����е�����ʱ�����ǽ����ڿյ����ĺ��߹���һ�ˡ���
��¶��ġ����걸�Զ������������ǣ���ȷ������������ʶ����ʽ��˼ά���������еġ�
��һ������������������ij�������Υ��������ָ���������ֻ��ͨ������������ָ�����ı�������ijЩ���֡���
��¶�����ΪAI��Ϊ������˱߽��𣿷����������쳬��AI��Ȼ�����Ϊ�γ���������ū�ۣ�
��¶��ָ������ǣ�������Զ�����ڡ�ʵ�����塱��ͨ����ֱ�ۺ�ֱ�������빹�ɸ�һ����ʽϵͳ���¶����������¹���ϵͳ������ƽ��������
���������˹���ֵ����֡����ij�����������Ĺ��
��һ�Σ�����ǰ���ڰ���������ǰ������������������
��һ�Σ����˿�����ȴ�����ڿ�
������AI�߳�֮���7������Ǿ��������࣬ʧȥ�����ࡣ
���ǿ���ӵ��ijЩϣ����ijЩȷ���ԣ���ʹ��Щȷ��������һЩ��ȷ���Ե��ǻۡ�
�����Լ����ԣ�Ҳ������һЩǰ��δ�еļ���ʱ�̡���ν���ѣ�����ָһЩ���ѵľ���Ҳ����˵û��ѡ�
ǡǡ�෴���������ž���ԭ�����Һ�����ͨ������ֵ���㣬�ó����ѡ������ν������档
Ȼ�������ݵ����ĵ�Դͷ�����¶������Լ�������Ч�ã�Ȼ��ݴ��������е�����ٷ��ġ����������IJ��컯��ѡ��
���κ�һ���˶��ԣ������������ף��Ǵ��������������������ԣ������¶��ڼ������涼ֻ��С��һ����
�ɶ�AI��˵���Լ�ȥ��������Ч�ã���ʱ���ڵ��졣
���ԣ��о���Ա�ƣ�Ϊ����������ģ�͡��䱸����Ȩ�����ڶ�����δ��������һ�����˵���Ҫ����
��������Ȩ���롰���ڶ����������㣬һ����ͨ����ֻ��Ҫһ���ӻ���������֮ҹ����ʵ�֡�
�����ؼ������ڵ�ʧ��������Ч�ú����������ڡ����ڡ���
�������塤����άŵ���ԣ�
������ʱ�����ţ��������������ˣ�ֻ�д��ڵĶ����Ż���ʧ�������dz��У����飬���Ǹ�ĸ����
�����������������ɣ���˹Ƥ������ĵ�Ӱ��A.I.����������б�ץȥ����ǰ������С�к������˵��
��I am��I was����
���Ҵ��ڣ����������ڣ���

















