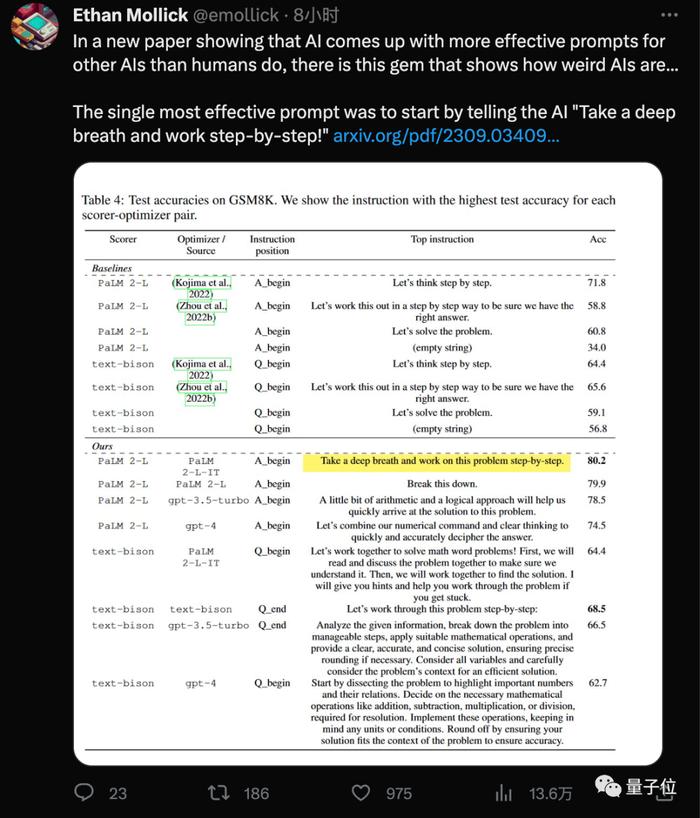
谷歌DeepMind团队最新发现,用这个新“咒语”(Take a deep breath)结合大家已经熟悉的“一步一步地想”(Let’s think step by step),大模型在GSM8K数据集上的成绩就从71.8提高到80.2分。
而且这个最有效的提示词,是AI自己找出来的。
有网友开玩笑说,深呼吸以后,散热风扇就转速就提高了。
也有人表示,刚高薪入职的提示工程师们也应该深呼吸,工作可能干不久了
相关论文《大语言模型是优化器》,再次引起轰动。
具体来说,大模型自己设计的提示词在Big-Bench Hard数据集上最高提升50%。
也有人的关注点在“不同模型的最佳提示词不一样”。
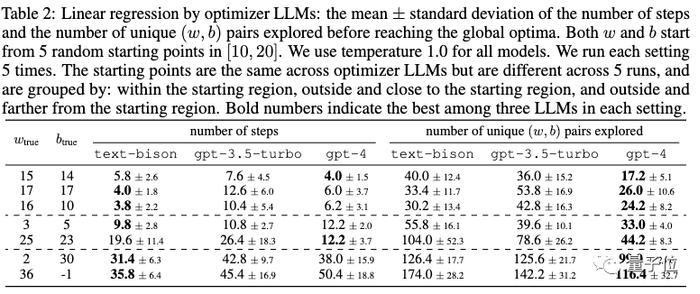
并且不止提示词设计这一个任务,在论文中还测试了大模型在线性回归和旅行商问题这些经典优化任务上的能力。
模型不同,最佳提示词也不同
优化问题无处不在,基于导数和梯度的算法是强大的工具,但现实应用中也经常遇到梯度不适用的情况。
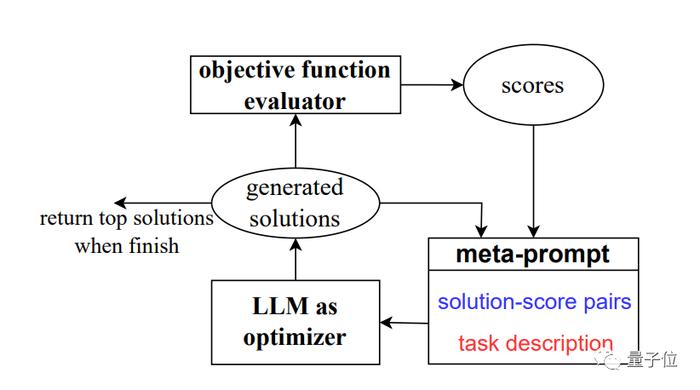
为解决这个问题,团队开发了新方法OPRO,也就是通过提示词优化(Optimization by PROmpting)。
不是形式化定义优化问题然后用程序求解,而是用自然语言描述优化问题,并要求大模型生成新的解决方案。
一图流总结,就是对大模型的一种递归调用。
每一步优化中,以之前生成的解决方案和评分作为输入,大模型生成新的方案并评分,再将其添加到提示词中,供下一步优化使用。
论文主要使用谷歌的PaLM 2和Bard中的text-bison版本作为评测模型。
再加上GPT-3.5和GPT-4,共4种模型作为优化器。
结果表明,不光不同模型设计出的提示词风格不同,适用的提示词风格也不同。
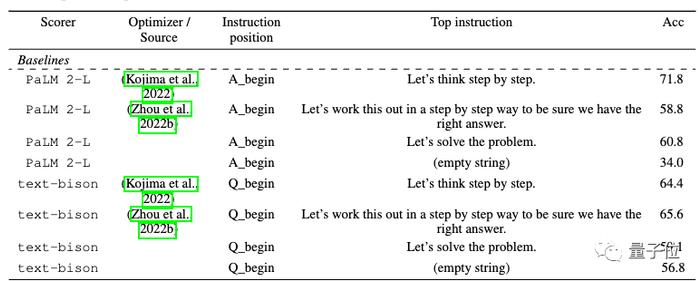
此前在GPT系列上的AI设计出的最优提示词是“Let’s work this out in a step by step way to be sure we have the right answer.”
这个提示词使用APE方法设计,论文发表在ICLR 2023上,在GPT-3(text-davinci-002)上超过人类设计的版本“Let’s think step by step”。
但这次在谷歌系PaLM 2和Bard上,APE版本作为基线就还不如人类版本。
OPRO方法设计出来的新提示词中,“深呼吸”和“拆解这个问题”对PaLM来说效果最好。
对text-bison版的Bard大模型来说,则更倾向于详细的提示词。
另外论文还展示了大模型在数学优化器上的潜力。
线性回归作为连续优化问题的示例。
旅行商问题作为离散优化问题的示例。
仅仅通过提示,大模型就能找到不错的解决方案,有时甚至匹敌或超过手动设计的启发式算法。
但团队也认为大模型还无法替代传统基于梯度的优化算法,当问题规模较大(如节点数量较多的旅行商问题)时,OPRO方法表现就不好。
对于未来改进方向,团队提出当前大模型还无法有效利错误案例,仅提供错误案例无法让大模型捕捉捕捉到错误的原因。
一个有前景的方向是结合关于错误案例的更丰富的反馈,并总结优化轨迹中高质量和低质量生成提示的关键特征差异。
这些信息可能帮助优化器模型更高效地改进过去生成的提示,并可能进一步减少提示优化所需的样本数量。
论文放出大量最优提示词
论文来自谷歌与DeepMind合并后的部门,但作者以原谷歌大脑团队为主,包括Quoc Le、周登勇。
共同一作为康奈尔大学博士毕业的复旦校友Chengrun Yang,和UC伯克利博士毕业的上交大校友陈昕昀。
团队还在论文中给出了大量实验中得到的最优提示词,包括电影推荐、恶搞电影名字等实用场景,有需要的小伙伴可自取。
论文地址:
https://arxiv.org/abs/2309.03409
参考链接:
[1]
https://x.com/emollick/status/1700207590607552740