美国参议院和众议院国会委员会已经致信美国联邦政府的国家科学基金会,要求就保护美国研究免受中国和其他寻求利用它的外国国家的行为提供答案。
在给该机构的一封信中,这两个委员会的主席询问了这个主要的资助机构正在采取何种措施。
作为问题的一个例子,Newsweek本周发布了一份独家报告,详细介绍了美国顶级人工智能研究是如何通过著名研究人员朱松纯从美国流向中国的,他在建立中国的平行研究体系时至少获得了3000万美元的联邦资助,其中包括来自五角大楼和国家科学基金会的资助。
鉴于以十亿美元的纳税人资助的美国科学正面临着“系统性的利用、破坏和挪用”的威胁,众议院监督与问责委员会主席詹姆斯・科默(肯塔基州共和党)和众议院科学、空间与技术委员会主席弗兰克・D・卢卡斯(俄克拉荷马州共和党)要求国家科学基金会在11月14日之前回答有关保护科学研究以及经济和国家安全措施的问题。
日期为10月31日的信函寄给了国家科学基金会的主任塞杜拉曼・潘查南坦,询问了国家科学基金会授予的科学家中有多少被确认为存在利益冲突,并询问了国家科学基金会是否因与外国利益冲突有关的违规行为而“暂停、终止、要求返还、暂时禁止或永久禁止”了这些科学家。
【相关讯息 1】朱松纯:30年潜心研究通用AI
朱松纯:国际知名计算机视觉专家、统计与应用数学家、人工智能专家,3次获得计算机视觉领域国际最高奖项――马尔奖。1992年,朱松纯获得赴美国哈佛大学计算机专业攻读博士学位的机会,导师是国际数学家协会主席、菲尔兹奖获得者大卫・芒福特。朱松纯不负所望,学业精进。1996年,他博士毕业时就已在学界崭露头角。彼时,计算机视觉的主流研究是规则与几何,统计方法并不被看好。而当代人工智能的基础是统计模型,朱松纯以超前的思维挑战传统范式,第一次用统计的方法,以数学模型准确地刻画了“什么是纹理”,解决了困扰计算机视觉领域20多年的基础问题。
与当时高速发展的互联网领域相比,人工智能研究显得有些冷清。朱松纯发现,身边的很多研究者去了互联网公司,然而,他选择留在高校继续从事AI研究,潜心于探索人工智能“大一统”理论,先后任教于布朗大学、斯坦福大学、加州大学等。
朱松纯预判人工智能的发展有三大趋势:一是在人工智能的核心研究领域,如计算机视觉、自然语言理解、认知推理、机器人、机器学习、多智能体,日益高度融合,走向统一,实现从弱人工智能向通用人工智能的转变;二是智能与其它学科,如心理学、神经科学、生物医学等交叉发展,拓展其外延;三是通用人工智能的理论和方法逐步成为人文与社科的基础,实现“新文科”与“新社科”从定性向量化的方向发展,探索人机共生的智能社会。与此相适应,朱松纯将人工智能学科的培养目标定位于“新工科”“新文科”“新社科”“新医科”的大交叉背景下的“通识”,融会贯通人工智能六大领域的“通智”和助力各行各业的“通用”。
就这样,通过近3个月日夜奋战,朱松纯和20多位跨学科专家反复打磨,终于确立了一套全新的人工智能课程体系,在横向上覆盖了计算机视觉、自然语言、认知推理、机器人、机器学习和多智能体六大人工智能核心领域,在纵向上贯穿了从数理基础、人工智能理论到前沿实践等课程体系,同时开设了AI与艺术、哲学、国学、法律、经济、社会、政府和公共管理等多门交叉课程。
通院仿佛一块巨大的磁铁,先后吸引200多学者加入,包括30多位海外名校毕业的博士生,组建了通用视觉、自然语言与人机交互、机器学习、认知计算与常识推理、多智能体、机器人等多支研究团队。
“不随大流,敢为天下先。”这是许多人对朱松纯的评价。在美国参与“可解释人工智能”这个重大科研项目时,其他国际专家大多采用学界流行的可视化深度学习方案,朱松纯则带领团队另辟蹊径,确立了“人机实时双向价值对齐”这一全新的范式。“起初别人都认为不切实际、无法实现。”朱毅鑫说,朱松纯带领大家克服重重困难,取得突破,相关研究成果最终被国际学术期刊《科学》和《科学・机器人学》同时在主页头条刊登,被评价为“把人机团队合作领域的AI研究向前推进了一大步”。
【相关讯息 2】李飞飞朱松纯把《我的世界》变AI的世界,微软Xbox组参与,游戏Agent协作框架来了
(梦晨 QbitAI)
这个游戏AI研究阵容太豪华!
斯坦福李飞飞、通院朱松纯两位教授坐镇,还有UCLA、微软研究院及Xbox团队、清华、北大参与其中。
研究提出多智能体框架MindAgent,利用大模型给游戏NPC规划和协作的能力。
用在现成游戏中,我的世界里NPC“活”了,变成我的AI世界。
也开发了新游戏作为测试基准,玩法类似分手厨房,但你玩得不好AI也不会和你分手。
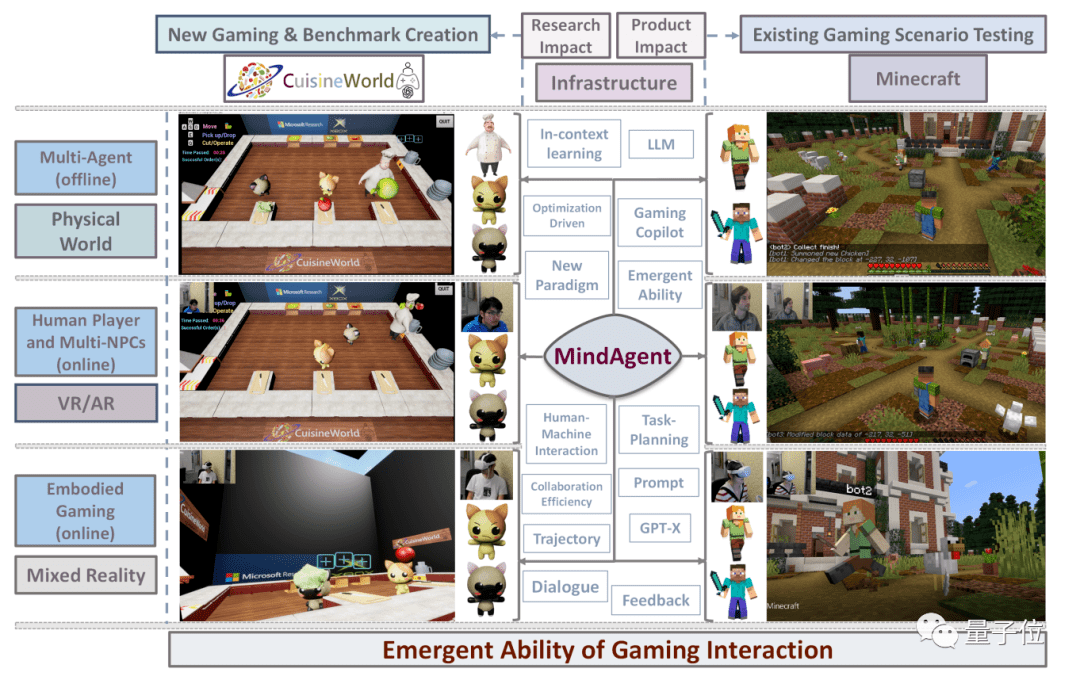
我的AI世界,甚至支持VR
简单来说,MindAgent框架给了游戏NPC规划复杂任务的能力,以及相互协作、与人类玩家协作。
在我的世界中,首先测试了多智能体协作能力,任务是完成不同类型肉食的烹饪。
可以看到左图中Alex和Steve分别狩猎不同动物,右图是两个NPC狩猎完成后一起在炉子旁煮肉。
人机协作中,人类玩家可以通过语音聊天向NPC实时表达自己的意图和期望的目标。
甚至支持VR模式,将玩家与NPC的交互体验提升到一个新的水平。
在我的世界测试中,新任务生成间隔(T值)越大、规划难度越小,GPT-4在简单到中等(T3-T5)任务中表现不错,高难任务中表现有明显下降。
CoS指标衡量多智能体协作的效率,GPT-4在不同难度任务下平均完成了58%的任务。
分手厨房,没朋友也能玩了
研究还设计了测试基准CuisineWorld。
规则类似著名联机游戏《胡闹厨房》,2-4位玩家需要在限制时间内分工配合完成各种菜品的制作并送达顾客手中。
(因为玩家之间配合不好容易“友尽”,在玩家群体中被戏称为分手厨房。)
与我的世界一样,CuisineWorld同样支持智能体间协作,人机协作,以及VR交互。

由于专为智能体协作打造,在CuisineWorld上可以方便完成更多测试。
这回GPT-4、ChatGPT(gpt-3.5-turbo0613)、Claude-2和Llama2 70b都参与进来。
结果GPT-4只控制两个智能体就能完成68%的任务,Claude-2能完成31%,Llama2和ChatGPT则根本不会玩。
另外3个GPT-4就已经能完成80%的任务,再加到4个效果已经不明显,Claude-2增加智能体数量还有进步空间。
MindAgent框架,让大模型学会规划
那么大模型到底怎么学会玩游戏的呢?
也就是靠研究中提出的MindAgent框架了,主要由提示、当前状态和记忆三个组件组成。
提示组件中包含菜谱、一般说明、推理知识和单样本演示。
当前状态组件提供对环境的观察快照,包括智能体的位置、持有的物品、环境中可使用的工具等信息,还包括违反规则时会被触发的反馈。
记忆组件记录了每个时间步骤的环境状态和智能体状态。
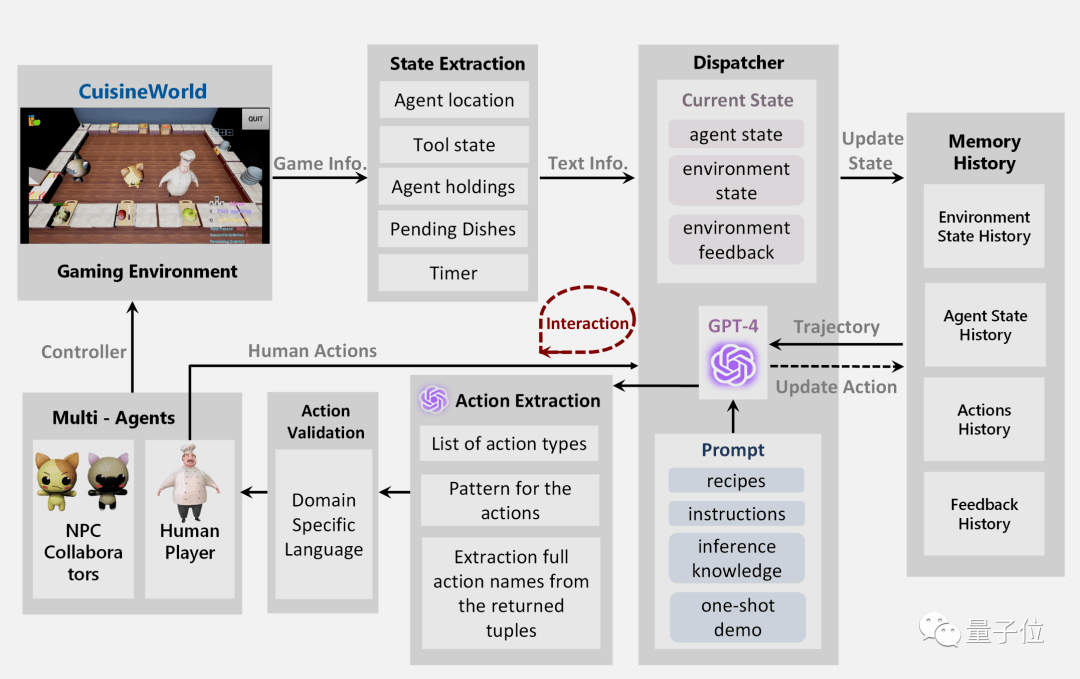
利用这些组件,大模型会先输出对任务规划的文本描述,接下来还有两个关键步骤:
动作提取,用正则表达式提取输出文本中的动作,这一步是必不可少的,因为输出文本黄总可能包含大模型思维过程,甚至是察觉到失误而道歉的信息。
动作验证,评估每个动作的可行性,如果发现无法执行则返回错误消息。
最终,团队在实验中得到如下发现:
- GPT-4在零样本条件下就能根据简单的游戏说明调度2-4个智能体完成菜肴制作,甚至可以与人类玩家协作。
- 提供极少量的专家演示,解释某些动作的推理、以及在规划过程中提供实时反馈,可以显著提升大模型的多智能体规划表现。
- 可以从更少智能体的例子推广到协调更多智能体,以及适应新的游戏领域。
- 与经典的专用规划算法相比,大模型规划仍存在计算成本、上下文长度限制、非最优规划等瓶颈,但可以从数据中在线改进,更灵活地适应不同规划问题。
- 在人机互动实验中,不同数量智能体与人协作会提高任务成功率,但太多智能体也会降低游戏乐趣。
另外,论文附录上还给出了系统提示词示例,如果想让AI学会玩你喜欢的游戏,可以参考一下。

论文地址:
https://www.microsoft.com/en-us/research/publication/mindagent-emergent-gaming-interaction/


















