OpenAI Sora������Ƶ��ͼ������֡��Ƶ��һ�ų���ը������AI Ȧ��Ҳ��ChatGPT����GenAI�ȳ�ʱ��һ���OpenAI�ٴ�ʷʫ���ĸ��¡�OpenAI ����ļ�������[����1]�������䲪�����ģ���Ƶ����ģ����Ϊ����ģ������
���ߴ���ǰԭ�ƻ�����һ�¶�Google Lumiere ������Ƶ����֪����������ź��Ƴ١��Աȿ����ߴ�ļ��������ѡ������ɢģ�ͣ�ȴҲ������ؼ�ϸ�ڲ�ͬ��ǡ�ÿ��Խ��� OpenAI ����������������죬һ������һ�£�Ϊʲô���߾���������һʷʫ���ĸ��¡�
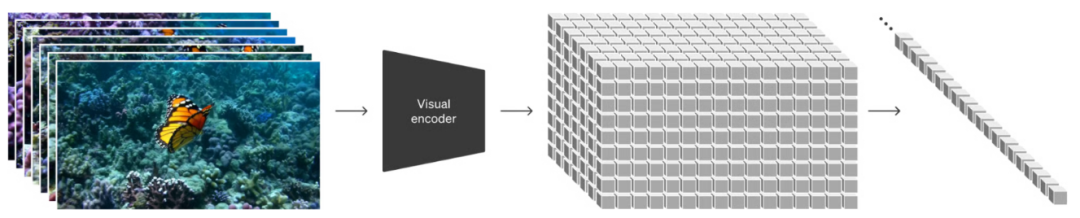
һ��Spacetime Latent Patches DZ����ʱ����Ƭ, �����Ӿ�����ϵͳ
�ڡ�ChatGPT�ǵ�һ������������˹�ͨ�����ܡ��У������ܽ��������ģ�ͽ���Embedding����������� �����롱���Լ������ԣ�Ȼ��ͨ��ע����Attention������ȡ���ַḻ��֪ʶ�ͽṹ����Ȩ��������������Լ������ԣ�Ȼ���롱����������ԡ�
��ChatGPT��������Token Embedding ˼·һ�£�����Ӿ����ݵĽ�ģ��������Ϊ����Sora����Ҫ�ĵ�һ������ƬPatch�Ѿ���֤����һ����Ч���Ӿ����ݱ���ģ�ͣ��Ҹ߶ȿ���չ������ͬ���͵���Ƶ��ͼ����Ƶѹ����һ����ά��DZ�����ռ䣬Ȼ������Ϊʱ����ƬSpacetime Latent Patches�����߾���ʱ����Ƭ��ʱ�ս�ģ�Ĺؼ���ͳһ��ʱ�շָ��"����"��
����ʱ����Ƭ��һͳһ�����ԣ�Sora ��Ȼ�����˶��ּ��ܣ�1. ��Ȼ�������⣬����DALLE3 ������Ƶ�ı���������GPT�ḻ�ı�prompts ����Ϊ�ϳ�����ѵ��Sora, ������GPT �� Sora���Կռ�ĸ���ȷ������������Token��Patch ֮��ͳһ�ˡ����֡���2. ͼ����Ƶ��Ϊprompts���û��ṩ��ͼ�����Ƶ������Ȼ�ı���Ϊʱ����ƬPatch�����ڸ���ͼ�����Ƶ�༭���� -- ��̬ͼ��������չ������Ƶ����Ƶ���ӻ�༭�ȡ�
������ɢģ����Diffusion Transformer,��ϳ�ǿ�����Ϣ��ȡ��
OpenAI ��Sora ��һ��Diffusion Transformer�������Բ�����ѧ�ߵĹ���Diffusion Transformer��DiT����"����Transformer�Ŀ���չ��ɢģ�� Scalable diffusion models with transformers"[����2]������ܹ����£�
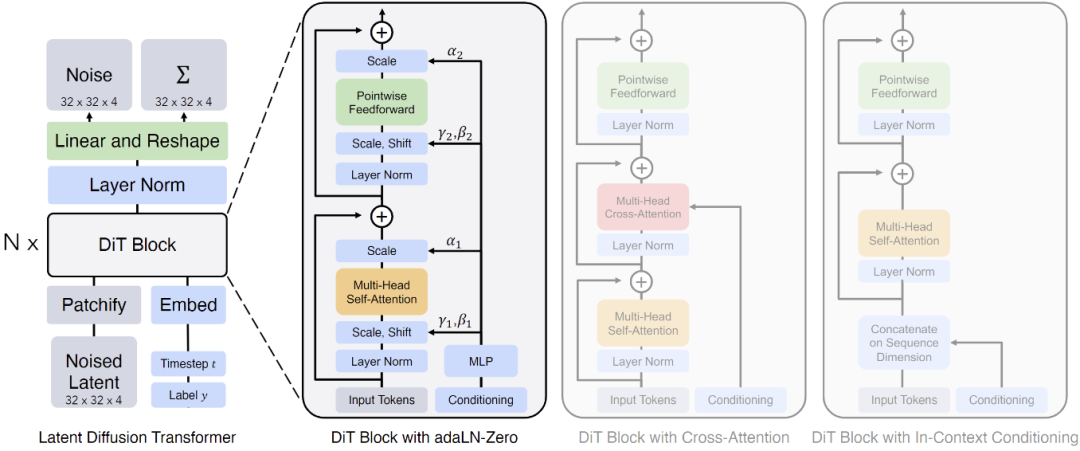
Diffusion Transformer��DiT���ܹ���������ѵ�����ڵ�DZDiTģ�͡�����DZ�������ֽ�ɼ���patch���ɼ���DiT�鴦�����ң�DiT���ϸ�ڡ����ǶԱ�Transformer�ı��������ʵ�飬��Щ����ͨ������Ӧ���һ��������ע�����Ͷ��������token�����ڡ�����Ӧ���һ��Ч����á�
��ɢģ�͵Ĺ���ԭ����ͨ���������Ӹ�˹�������ƻ�ѵ�����ݣ�Ȼ��ͨ����ת������������ѧϰ�ָ����ݡ�ѵ�������ʹ����ɢģ�����������ݣ�ֻ��ͨ��ѧϰ����ȥ����������������������������ɢģ����һ��DZ����ģ�ͣ��������������������Ի�ý��Ƶĺ���q��x1:T|x0��������x1��...��xT����x0������ͬά�ȵ�DZ������

ͼ����ת��Ϊ����˹������ѵ����ɢģ�͵�Ŀ����ѧϰ����̣���ѵ��p�ȣ�xt−1|xt����ͨ��������������������������������µ����ݡ�
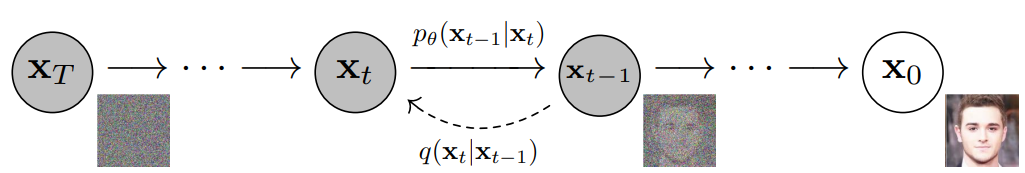
����Ϣ�صĽǶȿ����������⣺�ṹ����Ϣ��Ϣ�صͣ����ּӸ�˹�������������Ϣ�أ����ڸ�ԭ���Ľṹ��Ϣ����������ķǽṹ�����֣���Ϣ�غܸߣ�����������˹�����������������Ӹ�˹��������Ȼ������
�ڴ��ӽ��£�ѧϰ����������ʵ��ԭ���ṹ����Ϣ����ͼ�ġ���Ƭ�������ƻ�ѧ�ϵ�����кͣ���������ĵط����÷Ÿ���ļ��������ѧ���˷ż�ķֲ��ͽ��࣬������������ķֲ�����ķֲ��ͱ���ԭ�ˡ�

��������ɢģ�ͣ������в���ά����ѹ������ԭ�ȱȽϸߡ�ѧϰ�����еĸ��ʷֲ���ΪDZ������������ѵ����ȡ����Ʒֲ�����KLɢ�ȼ�����ʷֲ�֮��ľ���[����3]��Diffusion Transformer��DiT����Ϊ����Transformer ������ͷע������һ������������˽�ά��ѹ����diffusion��ʽ�µĵ�Ƭ��Ϣ��ȡ���̣�ԭ����LLM�����������졣
����DiTӦ����DZ����ʱ����Ƭ��ѧϰ��ú�����Ƶ��ʱ����Ƭ�Ķ�̬����
�롰LLM�����ά���Կռ���ͨ��Transformer��ȡ���������������Ľṹ�������Ϣ�����ƣ�Sora�Ǹ�������ɢģ�͵�Transformer�������ڴӸ�ά��ʱ����Ƭ�ųɵĿռ��У��۲첢��ȡ�ḻ��ʱ����Ƭ֮��Ĺ������ݻ��Ķ�̬���̡������ǰ�߶�Ӧ������飬���߾���������Ӿ��۲졣
�ź�����OpenAI�ļ�������û���ṩ����ϸ�ڣ��������߾��ô�ҿ��Բ���Google Lumiere�ļ���ԭ����������һ�¡���Ƶ��ʵ�Ǽ�¼��ʱ����Ϣ�����壺ʱ����Ƭpatch���Կ�������ά�ռ�ĵ㼯��x,y,z�����˶���t������˵��ʵ�Ǹ���άʱ��ģ�ͣ�x,y,z,t����Sora��Lumiere֮�������ģ�͵ĵ�һ��������δ�����ȡ����Ӧ�Ĺؼ���Ϣ��
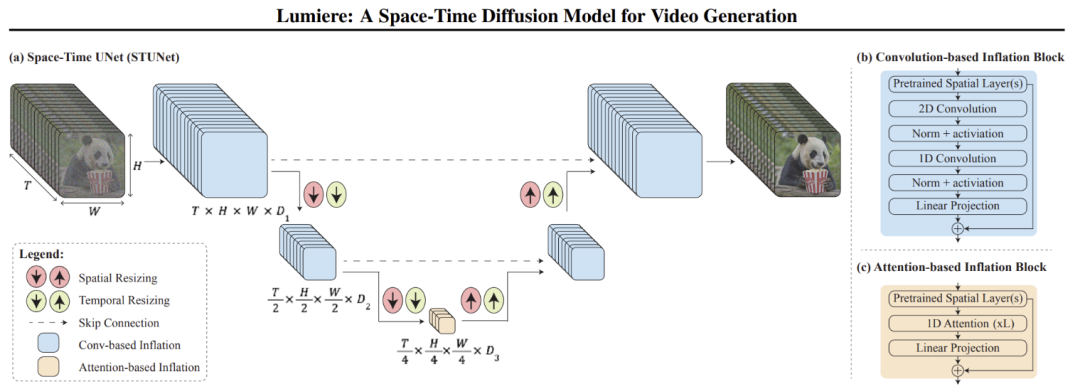
Lumiere STUNet�ܹ�����Ԥѵ����T2I U-Net�ܹ���Ho et al.�� 2022a�������͡���һ��ʱ��UNet��STUNet�����ڿռ��ʱ���϶���Ƶ�������²�������a��STUNet����ͼ��ʾ������ɫ��ʾ��ͬʱ��ģ���������������b�����ھ����Ŀ飬��Ԥѵ����T2I������ӻ�ʱ�վ�����ɣ��Լ���c������ֵ�U-Net�����ϻ���ע�����Ŀ飬����Ԥѵ����T2I���ʱ��ע������������Ƶ��������ֵļ����ϱ�ѹ��������ʹ�����ļ��㿪���ѵ�����ʱ��ע�����㡣
�ȸ�Lumiere��A Space-Time Diffusion Model for Video Generation [����4]Ҳѡ������ɢģ�ͣ��ѵ��˹�һ����ע�����㣬����Sora��DiT����ϸ����ʱ�����ֱ��ʡ������ȵȵĴ�����ʽ��ͬ��ϸ�ھ����ɰܣ�OpenAI ��Sora�����ˡ�����������Ƶ������Ƶ��С���ü�����������С��ͨ�����������Կɱ�ʱ����ԭʼ�ֱ����볤����ѵ����Ƶ���ɻ����Ҫ���ƣ����������ԣ��Ľ��Ĵ������֡��

�ġ�Sora ��Lumiere ��Ƶѧϰ�����ɵļ��������̺���ԭ������
����Sora�ļ��������� ���ߵ�һ�о� Sora��ʵ����ʱ��DZ������Ƭ��ѧϰ���˿��Ӳ�����߱��������ϵ�SSM��State Space Model��, �Ӷ�����Ƶ������չ�ֳ�ǿ���ӿ���������˺;�������ά�ռ��ƶ�һ���ԣ�����ʱ������������־��ԣ������ﱻ�ڵ������֣��������ܱ�����Ļ����ԣ�������������ȵȡ�OpenAI��Ϊ����������Ƶģ�͵Ĺ�ģ������������ģ�������������������磬�Ͼ����Ǵ����dz߶ȵ�����they are purely phenomena of scale����
�����ǻع�һ�¡�Transformer �ĺ������ˡ��б����ܽ����SSM����˼άģ�ͣ�
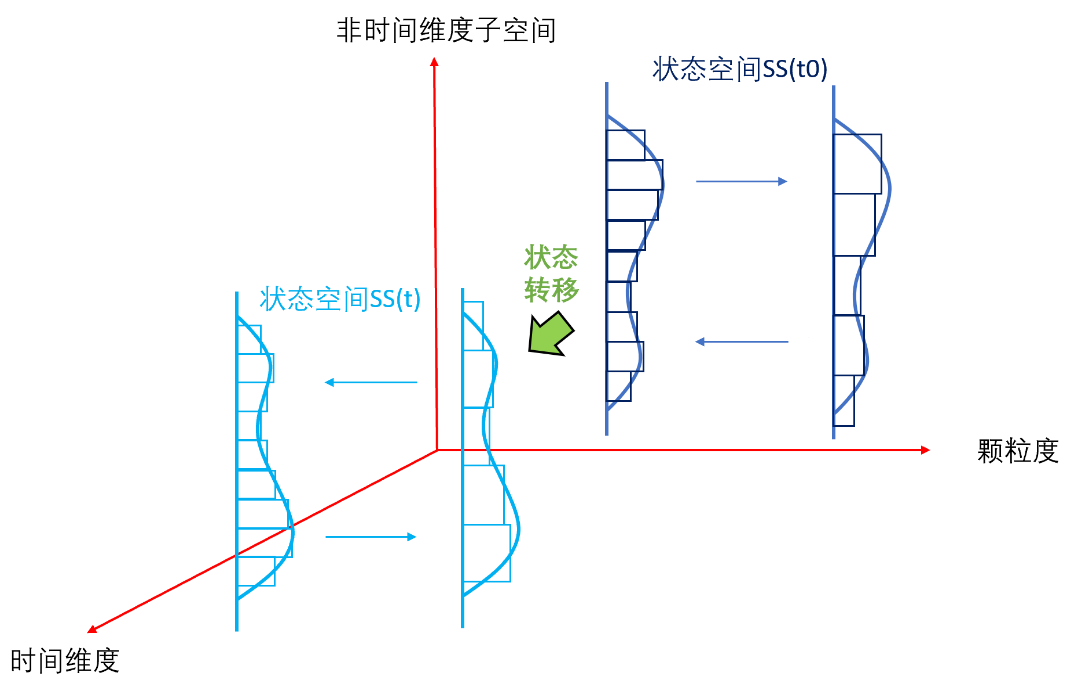
1.״̬�ռ������ı����Ϳ̻���״̬�ռ�ĸ�ά�ȣ�ijʱ�̵���Ϣ����ijʱ�̵�����������ĸ��ʷֲ������ڶ�ά�ȵ����ϸ��ʷֲ�����ά�ȶ����ܾ��������Ժͷ����ԣ����������ϵͳ���ƣ������Ŭ�����������Ե�Ӱ��dz��ؼ�����ͬ��ε�DZ�����ռ䣬����Ϣ����ȡ���ʹֿ�������������Ҫ����������Ⱥ RG�еķ�����һ���������������Ʒ����Դ��������������Ϊ 1 ��ƫ�롣
����������Ⱥ��Ϣ��ȡ��ԭ������ο����������ġ���ģ����֪��ܡ����˴�������������Sora���õ� Diffusion Transformer��DiT���ܹ���ȸ�Lumiere ���õ�Space-Time UNet��STUNet�����߱�ע�������һ��������·�ܹ����쿴������Ҫ�����Ƿ���á�������Ƶ��С���ü�����������С��ͨ����������
2.״̬�ռ�Ķ�̬�ԣ�����ʱ���ά�ȣ��о�����״̬�ռ�ı�Ǩ�������Ǩ��״̬�ռ�Ĵ�����ʱ��ά�ȵ���Ϣ�����ȡ������ʱ����һ����ά�ȵģ�״̬-ʱ�䣩����sequence�������Ǹ�ά�ȵͲ�ε�ϸ�����ȵĸ��ʷֲ���ʱ��仯�����ǵ�ά�ȸ߲�εĴֿ����ȸ��ʷֲ���ʱ��仯�����Ƿ�����ʱ��ϵͳ��������ʱ���䣨LTI����ģ�Ͷ������ܺÿ̻��ġ�
Sora�ľ�����������������û��¶��Lumiere �Ĵ����п��Կ������ߡ���������ж��ֽ�ģ�ķ�ʽ������Ȼ�ķ�ʽ���ǣ���x,y,z��, t ���ķ�ʽ��������������ݻ�����ʱ�����У������ַ�ʽ��������������Ƶ����Ƶ�ʲ��㵼�µ��˶�ģ�����˶��������⡣���������ת��������ʱ���������ڵ�ת��
Nyquist-Shannon���������������ǣ�����ģ���ź� �����ϣ��ͬʱ�����źŵĸ������ԣ�����Ƶ��Ӧ�ô���ԭʼģ���źŵ����Ƶ�ʵ��������������������λ��Ƶ��ģ�������Lumiere�������Լලʱ�䳬�ֱ��ʣ�TSR����ռ䳬�ֱ��ʣ�SSR������[����5]����������˶���ģ�ɶ�ά��������ϵ�ģ�ͣ���x,y��, ��,��x,t��,��y,t��,��z,t����
С��ʱ����Ƭ������Ƶ���еĸ���ά�����ظ����֣��ر��ǿռ��ʱ��ά��֮����н���ʱ��������Զ�����ʱ������ռ���ı�������������������ʱ���п����ǿ�˳ʱ��ļ���Ҳ���ܾ�������ʱ�롣��ʹʱ�����ֱ棬������Ե���Ƶ�ʣ�������ģ������û���ر�仯�ı�����
����������ƶ�ʱ��x-t��y-t��Ƭ�е�Patch�������Ǹ߷ֱ���x-y��Ƭ����ͳ֡���ĵͷֱ��ʰ汾����t������������Щx-t��y-t��Ƭ�ķֱ�����������Ƶ��ʱ��ֱ�����һ���ġ���ˣ��ռ�x-y��Ƶ֡�ṩ�������ͬһ��Ƶ������x-t��y-t��Ƭ��ʱ��ֱ��ʵ�ʾ����
����t���ɵ���ά�ȣ�������x-y�߷ֱ���ѵ������x-t, y-t��ͬ�����������ƶ��dz�����ʱ��x-t��y-t��Ƭ�е�Patch����Ϊx-y֡��Patch������汾��������Щʱ����Ƭ����Ϊ��������Ƶ֡�Ŀռ�ֱ����ṩʾ������ʱ����Ƭ�������������ռ�ֱ��ʡ����SSM ѧ�����������ɣ����˶����̣���ֱ�������Ƶ֡������ҲӦ�����С�
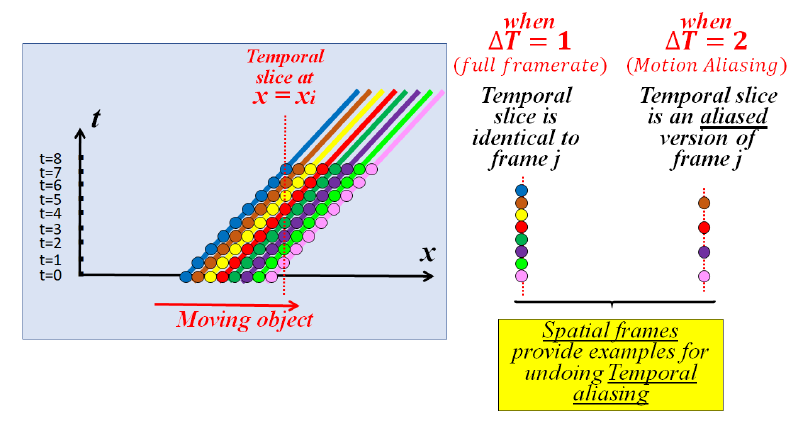
����ά���ݹ��һάͼʾ��1D���������ƶ������ʵ��IJ���ʱ�䣨T=1����ʱ����Ƭ�����ڿռ���Ƭ��1D��֡������Ȼ������ʱ������ʹ��ͣ�T=2��ʱ��ʱ����Ƭ�ǿռ���Ƭ��Ƿ��������� aliasing���汾����ˣ��ռ�֡�ṩ������ʱ������ʾ����
3.״̬�ռ�ʱ�����еķ������ɷ��ԣ�˼��attention �ļ�ֵ��ʱ�������ϵ� attention ע���ʲô����������, ������, һ�����¼��ȡ���ʱ��ά���ӿռ��ڵ� attention��ע����Ƿ������뷶���Ĺ�ϵ�� ��ij��ʱ�̵�״̬�ռ䡣״̬�ռ��ʱ���о�����״̬�ռ�Ķ���ѧ���������������������ص��µ�״̬�ġ�����������״̬�ռ�tʱ���� t-nʱ��֮��Ĺ�ϵ��ע�������ʱ���������ɣ��������߱������ɷ��ԡ�
�Դˡ�Transformer �ĺ������ˡ��Լ�������ǰ�ġ�Ѧ���̵�С��������ѧϰ�ĺ��ˡ��ж�������Ӧ�IJ��͡��������ɷ�����ʵ������ij�̬����ʵ��ʱ��ϵͳ�������Ƿ������ɷ�ġ�ʱ��ά�ȵ�ע������״̬�ռ�ѡ���Էdz��ؼ���
OpenAI ��Sora ��Ƶ����ģ�͵ļ�����������ȡ�ˡ���Ƶ����ģ����Ϊ����ģ����video generation models as world simulators������Ŀ���ɼ������Ը������Ȼģ�����磬���Ʋ�����������ij���ʱ��������������ϵ���������ɷ��Բ��ɱ�������켬�ֵ��鷳��
�塢Sora��ǰ����δ��
Sora �� Lumiere ��������Ƶģ����ʵ���Ǵ�ģ�ʹӲ��ؿռ����ת���˼�ǿʱ�������Ҳ���Ǵӱ�����ͼ�С���ʱ��ά���ӿռ䡱����Ϣ��ȡ��ת�����ѧϰ�ͱ�����״̬�ռ�Ķ�̬�ԡ����������������ɷ��ԡ���ͨ��������Ƶ�ж�ʱ����Ƭ�Ķ�̬������ѧϰ��Ŀǰ��������Ƶ��ģ�Ϳ���ѧ�����Ӳ�����߱��������ϵ�SSM�����������ϣ�MAMBA֮���SSMģ��Ӧ�ÿ�����;ͬ�顣
Ȼ��������ʱ����Ƭ�ı������ǻ�ȡ�����㹻���������ڹ��ɵ���Ϣ�ģ�δ�������ѧ���ǿ��Խ����dz����龫����̽��������������������������ѧ����ȵ�ѧ�Ƶķ��룬���ӻ�Ϊͼ�����Ƶ��������Ƶ���ɴ�ģ��ȥѧϰ���������������̺���DZ�ڹ��ɡ�
Sora ����һ����ͷ������˵ʷʫ���İ���Ƶ����ģ�ͷ��������������档��LLM GPT����Ƶ����ģ��Sora�Ƶ�ʵʱ���ͽӽ���ﵽ����ĸ�֪ˮƽ�ˡ������Ҫ�����Ǵ����ø�֪��������ϵ����֪��Խ��Ҳ���Ǵ��������ɹ��̲����ͱ���ƶϵĺ����ԡ�
����˹�ٺ�DeepMind ��ѧ���Ѿ���ʼ�����ͼ�����ʹ�ģ��ӿ�ֳ����ĵ��������������ȥ��9���������ģ�������������֪ʶ���γɡ���ı���ϡ������ô�ģ��֪����֪�Ŀ�Խ��������ʹ��AI4Science����ӭ���ش�ͻ�ƣ�Artificial Super Intelligence�˹���������Ҳ��ָ�տɴ���
[����1]https://openai.com/research/video-generation-models-as-world-simulators
[����2]Scalable diffusion models with transformers, https://arxiv.org/abs/2212.09748
[����3]https://ml.cs.tsinghua.edu.cn/~fanbao/Application-DPM.pdf
[����4]Lumiere��A Space-Time Diffusion Model for Video Generation https://arxiv.org/pdf/2401.12945.pdf
[����5]Across Scales & Across Dimensions��Temporal Super-Resolution using Deep Internal Learning https://arxiv.org/abs/2003.08872

















