Sora��Ұ�ģ�����ģ����
��ʵ���磨�������磩���ڴ�ͳһ������
���ǰ���˹̹һ���Ӷ���Ѱ��Ŀ�ꡣ
������������һ���źϻィ����ȱ�Ĵ�ͳһ���ۣ�GUT������ֻͳһ��ǿ����á�������ú͵����������������ͳһ��ģ��֮�С�
ͬ����AI������ڴ�ͳһģ����
��Ҳ�Ǻܶ�AI����ʦҲ�����Ŀ�ꡣ
�˴�OpenAI����Sora���ٷ������Ķ�����ǣ�����ģ������
������Ϊ���ǹ�����������ͨ��ģ������һ�����ܷ�����

��ô��AI����Ҳ����ڡ��������ӡ���
ΪʲôSora������������AGI��˼�������顣
����Ĵ�ͳһ������AI��ͳһģ����α��ղο���
�����������ѧԭ���ֽ�����ʲô��ɫ��
����Sora��DEMO�Ƴ��������ƺ����ֿɼ���AI�����͡�
1
AI���Դ�ģ�ͣ�LLM���ġ��������ӡ�
������ռ�Ŀ��֮һ��
����Ѱ����������ġ��������ӡ���
ֻ���ҵ����������ӡ������п�������������档
AI������һ�������������Ǵ����ߣ������趨���������ӡ���ֻ����������������ӡ�������ȥ����һ�������硣
�ص�AI�˹����ܵġ�����ը��ʱ����ChatGPT��Ϊ��һ������������˹�ͨ�����ܣ����Ĺ���ԭ����ʲô��
ChatGPT����Embedding���������ԡ����롱��AI�ܹ�����ġ����Կ�������Ҳ����Token��������Ȼ����ת��Ϊ��ά�����ռ��е���ֵ��ͨ����ע��������Ȩ�ⲻͬ����Ԫ�ص������Ҫ�����ա����롱����Ȼ���ԡ�
������ģ�ʹ����������ı��Ĺ��̲��裺
1.�ı�Tokenization ➔ 2. Embeddingӳ�� ➔ 3. ����λ�ñ��� ➔ 4. ͨ����ע�������ƴ��� ➔ 5. ����ǰ�������һ������ ➔ 6. ����Ԥ�Ⲣ�����롱
���岽�����£�
���ı�Tokenization��
��ԭʼ�ı��ֽ�Ϊ��С�ĵ�Ԫ��Tokens����
"Hello, world!" ➔ ["Hello", ",", "world", "!"]
��Embeddingӳ�䣺
��ÿ��Tokenת��Ϊ��ά�ռ��е�������
["Hello", ",", "world", "!"]
➔ [����Hello, ����,, ����world, ����!]
�ۼ���λ�ñ��룺
Ϊÿ����������λ����Ϣ�����������дʵ�˳��
[����Hello, ����,, ����world, ����!] ➔ [����Hello_pos, ����,_pos, ����world_pos, ����!_pos]
��ͨ����ע�������ƴ�����
ģ�ͼ���ÿ���ʶ������������ʵġ�ע���������Ӷ�����ÿ���ʵı�ʾ��ʹ��������ḻ����������Ϣ��
[����Hello_pos, ����,_pos, ����world_pos, ����!_pos] ➔ [����Hello_context, ����,_context, ����world_context, ����!_context]
������ǰ�������һ��������
��ÿ���ʵ��������н�һ���ķ����Ա任����ѧϰ�����ӵı�ʾ��
[����Hello_context, ����,_context, ����world_context, ����!_context] ➔ [����Hello_final, ����,_final, ����world_final, ����!_final]
������Ԥ�Ⲣ�����롱��
�������յ�������ʾ��ģ��������һ���ʵ�Ԥ�⣬������ת��������ɶ����ı���
[����Hello_final, ����,_final, ����world_final, ����!_final] ➔ Ԥ����һ��Token ➔ "Language"��
�����ϲ�����Կ�����ChatGPT����ԭ��������ǽ�����Ȼ���ԡ�Token����Ҳ���Ǹ�������ģ���ṩ��һ���ɼ��������ġ��������ӡ���Ȼ������Щ���������ӡ�ȥ����ı����������硣
��������ChatGPT���������Դ�ģ�ͻ����϶�����Token����Ϊ�������ӣ����ı���ģ����������������Ѿ��������䶨����
2
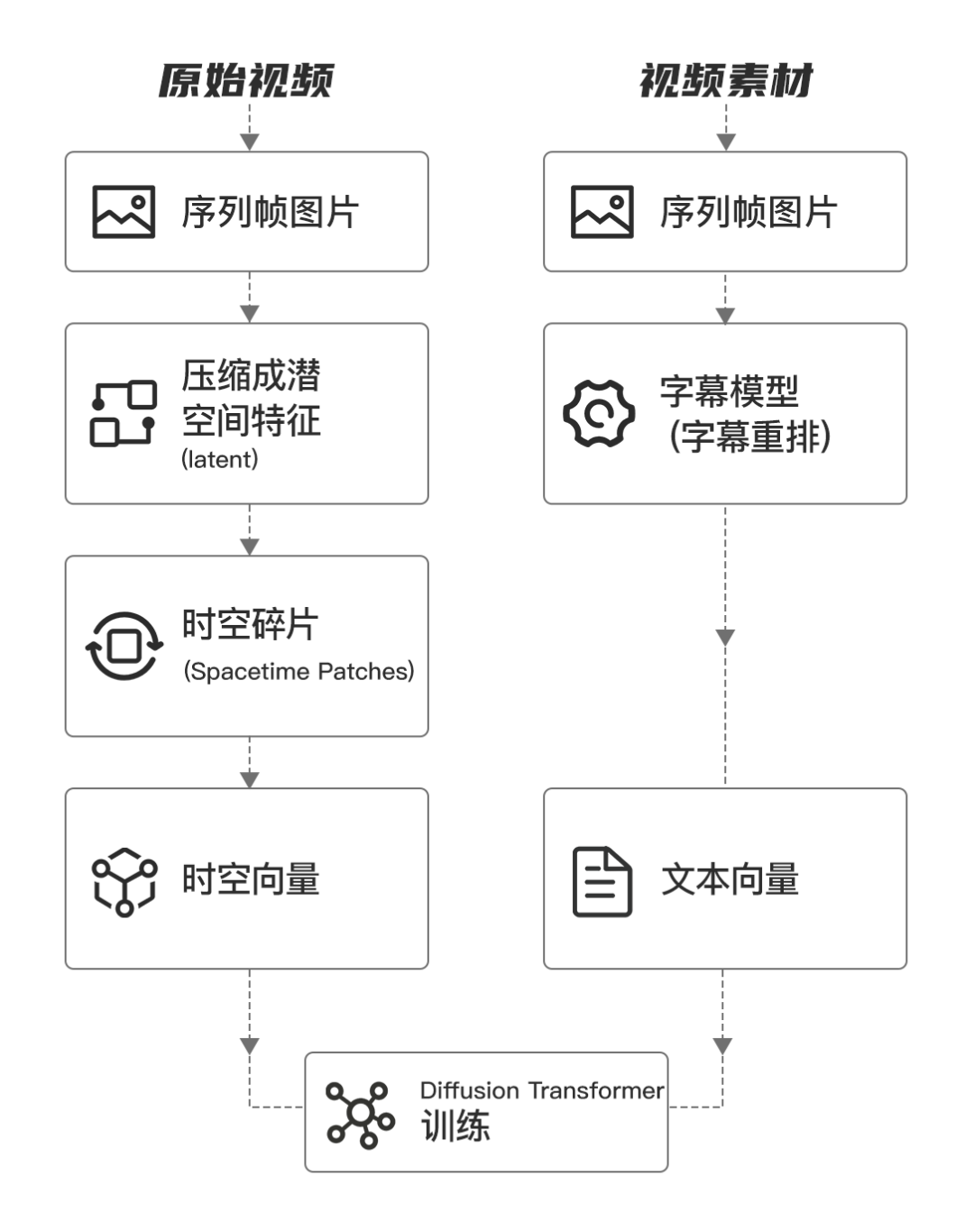
Sora�еĻ������ӡ�spacetime patches��
��ChatGPT�ļ���ԭ�������ƣ�Soraģ�ͼ���ջҲ���Ƚ���Ƶ���ݡ��������ӡ�����
A���������Ի������ӡ�Token����
B����Ƶ���ݻ������ӡ� spacetime patches����
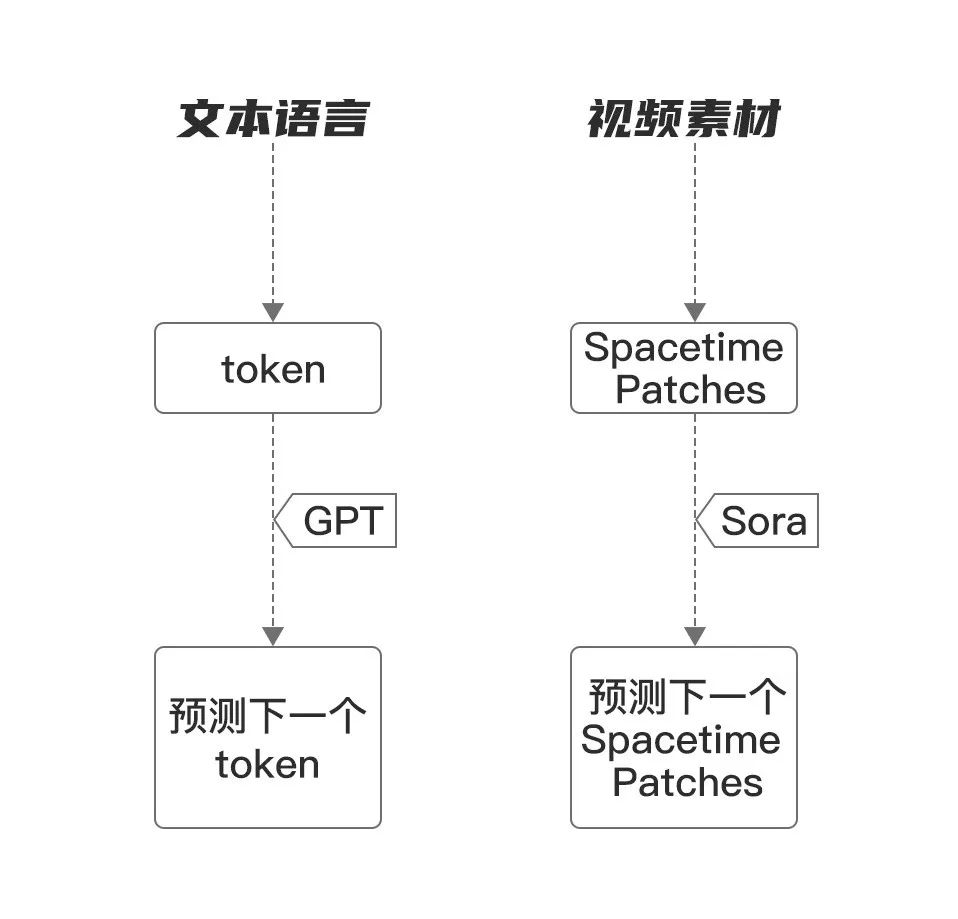
��ChatGPT����Token Embedding������ʵ���ı��������ƣ�Soraģ�ͽ���Ƶ����ѹ����һ����ά��DZ�ռ䣨Latent Space�����ٽ���Щѹ���������ϸ��Ϊʱ����Ƭ��Spacetime Latent Patches����
��Ƶ��ģ�͵Ĺ���ʦһֱ���ڴ���������ӣ���������ÿ���������Ӷ��ܳ�Ϊ���������ӡ���
�ܹ��õ������Ͽɵġ��������ӡ�Ӧ�þ��������ص㣺
1���ܹ���Ч�̳�ԭ���������Ϣ��
2������������ϴ��죨���ɣ������硣
���Soraģ�͵���Ƶ���ݡ�ʱ����Ƭ����spacetime patches���Ѿ���֤ʵ��һ�ָ�Ч�ҿ���չ�����ݿ飬���ܹ����ͱ���������Ƶ���ݵĹؼ���Ϣ����ΪAIʱ�����ݽ�ģ�Ļ�ʯ����Tokenһ��ʱ����Ƭspacetime patches��ΪAIʱ�ս�ģ�Ĺؼ�����Ϊ��Ƶ��ģ�͵ġ��������ӡ���
Soraģ�ʹ�����������Ƶ�Ĺ��̲��裺
1.��Ƶ�������� ➔ 2. ѹ������άDZ�����ռ䣨Latent Space�� ➔ 3. ���Ϊʱ����Ƭ��Spacetime Patches�� ➔ 4. AIʱ�ս�ģ��ChatGPT����Token Embedding������ʵ���ı��������ƣ�Soraģ�ͽ���Ƶ����ѹ����һ����ά��DZ�ռ䣨Latent Space�����ٽ���Щѹ���������ϸ��Ϊʱ����Ƭ��Spacetime Latent Patches����
��Ƶ��ģ�͵Ĺ���ʦһֱ���ڴ���������ӣ���������ÿ���������Ӷ��ܳ�Ϊ���������ӡ���
�ܹ��õ������Ͽɵġ��������ӡ�Ӧ�þ��������ص㣺
1���ܹ���Ч�̳�ԭ���������Ϣ��
2������������ϴ��죨���ɣ������硣
���Soraģ�͵���Ƶ���ݡ�ʱ����Ƭ����spacetime patches���Ѿ���֤ʵ��һ�ָ�Ч�ҿ���չ�����ݿ飬���ܹ����ͱ���������Ƶ���ݵĹؼ���Ϣ����ΪAIʱ�����ݽ�ģ�Ļ�ʯ����Tokenһ��ʱ����Ƭspacetime patches��ΪAIʱ�ս�ģ�Ĺؼ�����Ϊ��Ƶ��ģ�͵ġ��������ӡ���
Soraģ�ʹ�����������Ƶ�Ĺ��̲��裺
1.��Ƶ�������� ➔ 2. ѹ������άDZ�����ռ䣨Latent Space�� ➔ 3. ���Ϊʱ����Ƭ��Spacetime Patches�� ➔ 4. AIʱ�ս�ģ

ͨ����һϵ�в��裬��Ƶ���ݱ�ת����ʱ����Ƭspacetime patches����Ϊ����������Ƶ�����ṩһ��ͳһ������
AI�����͵�һЩ�������Ӻ�����������������ˣ�
���Դ�ģ�͵Ļ������Ӵ�������ˣ�Token��
��Ƶ��ģ�͵Ļ�������Ҳ��������ˣ�spacetime patches��
3
Sora �ļ���ԭ������
Soraģ�ٷ�ֻ����һ���������棬��û�й������弼��ϸ�ڡ�
����������Ҳ������˽�ģ�OpenAI��ԭ������Ŀ�Դ�������������л�ȡ��У���ȴ��Ը����Լ��ļ�����
�������Ƕ�Sora������һ��������ܽᣬ�������һ�����IJ�Ʒ���磬���������Ƕ�Soraģ�͵ļ������룺
����1:
ѹ��ԭʼ��Ƶ����ȡ������Ϣ
��Soraģ�͵�ѵ�����ڣ���һ���ǽ�ԭʼ��Ƶ����ת��Ϊ��ά��DZ�ռ䣨Latent Space���е�������������̿�����Ϊһ����ά����ѹ����������������ѧ������
�ִ��4K�������Ƶӵ�м��߷ֱ��ʣ���Ҫһ����ѹ�������裬ּ�ڴ�ԭʼ��Ƶ����ȡ������Ϣ����������
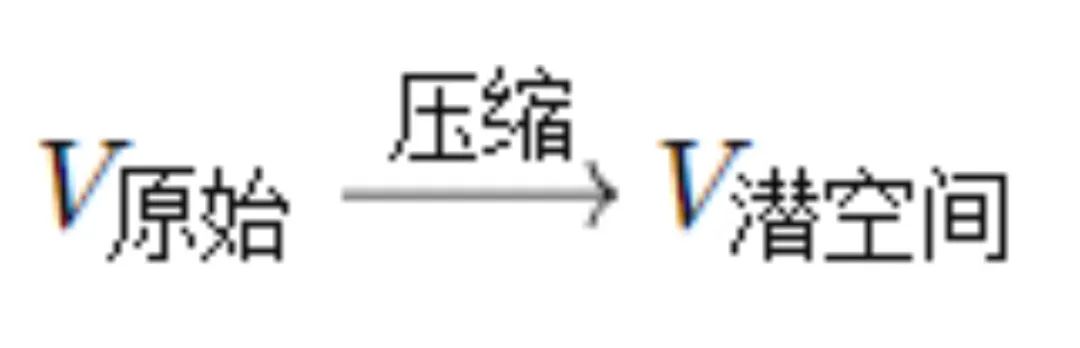
OpenAI�ο���Latent Diffusion���о��ɹ�������ԭͼ������ת����DZ�ռ����������ʹ����������������б���������Ϣ��
����ѹ��������ݴ�������������
1.����ѹ�����ؽ�
ͨ����DZ�ڿռ��н�����ɢ������ɢ���̣�ģ���ܹ�������Ļ������ؽ�����ԭʼ�������Ƶ�����ӱ��������
2.���������
�ڵ�άDZ�ڿռ��н��в���ʹ��ģ���Ӹ�Ч��ͬʱ�ṩ�˸���Ĵ���������ԡ�Ҳ����˵����Ȼ���ݾ���ѹ������Latent Diffusion�����ӳ��¶Դ�ģ��ѵ��Ӱ�첻��
����2��
��ѹ����Ƶ����ʱ����Ƭ��spacetime patches��
��Ƶ���ݱ�ѹ����DZ�ռ䣬�ٲ��ɻ�����λ��Ҳ����ʱ����ƬSpacetime Patches��
Patch��ԭʼ��������һ��������ͼ��飬��ͼ��ѵ����Vision Transformer��ViT����ԭʼ�����У��о�������Դ�������ͼ���ѵ����������������˼�����ڽ���ͼ��ָ�Ϊ�������ͼ��飬Ҳ����Patch����ÿ��ͼ�����Ϊ���л����ݵ�һ���֣�����һ���л������У�ÿ��ͼ����λ����ϢҲ�������ȥ�������ͼƬ���ɵĻ���ԭ���������Ҫ������Ƶ�Ļ�����Ҫ����Ӧλ��ͼ����ʱ��֡�����ȥ���γ�ʱ��ͼ��飬���ʱ����Ƭ��Spacetime Patches������Щʱ����Ƭ����Я���ռ���Ϣ��������ʱ�������ϵı仯��Ϣ��
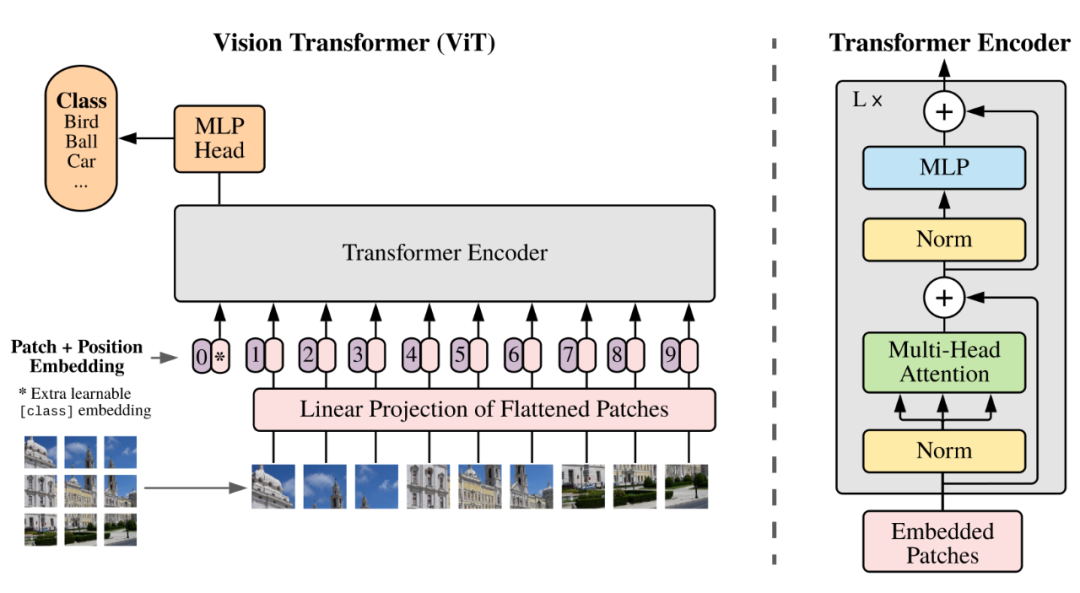
1��ͼ������
ѵ��ʱ���浽�㣨ƽ�棩������ʱ�ɵ㵽�棻
2����Ƶ����
ѵ��ʱ�����嵽�㣨������������ʱ���ɵ㵽���塣
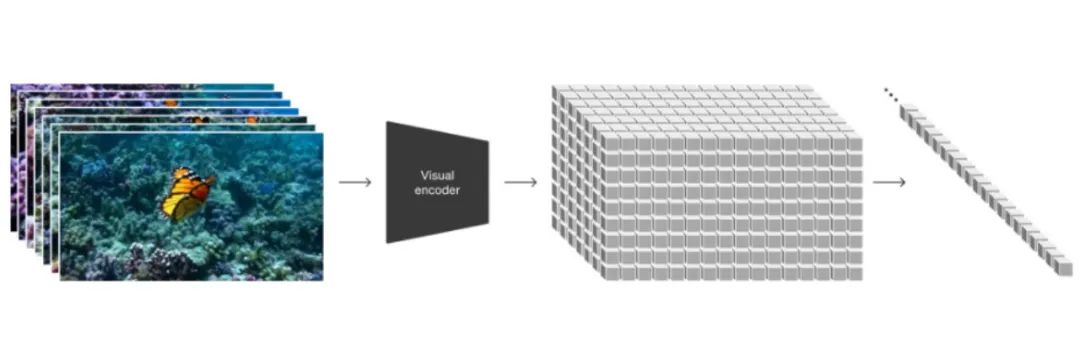
��ѧ�Ͽ��Խ���Ƶ��Ϊһ����ʱ����Ƭ��Spacetime Patches����ɵĸ��Ӿ���
������ƵV��һ��������ʱ���źţ����Ա�ʾΪһ����ά����V��RT��H��W��C������T����ʱ��ά���ϵ�֡����H��W�ֱ����ÿ֡ͼ��ĸ߶ȺͿ��ȣ���C��λ����Ϣ����Ȼ���ﻹ����һЩ����ϸ�ڣ�
���粻ͬ��Ƶ�ߴ粶��Ϣ�ο�Navit�ġ�Pack���ļ�����������VAE�ĸĽ�֧�ָ�����Ƶ��ʽ��
��Ƶ���ݱ����Ϊһϵ�пɹ����Ļ�����λʱ����Ƭ��Spacetime Patches������һ������Ҫ����Щʱ����Ƭ���뵽��ģ���н���ѵ����
����3
����Ļ���ż�������ʱ��������ȷ����
�ڽ�ʱ����Ƭ���뵽��ģ��ѵ��֮ǰ��OpenAI��˾�������ˡ���Ļ���ż�������
Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3��2023����8
����һ��ȫ�µĹ���������OpenAI��DALL��E 3�������Ļ���ż���Ӧ������Ƶ��ѵ����
DALL��E 3Ҳ��OpenAI�IJ�Ʒ��ʹ������������졣
����Ļ���ż����������Ϸdz���Ҫ������ѵ����Ƶ��������Ƶ���������϶��м������á�
����ѵ����
ѵ��һ����Ļģ�ͣ�Ȼ��ʹ����ѵ����Ƶ�����ı���Ļ���߶������Ե���Ƶ��Ļ��������ı���ȷ���Լ���Ƶ������ѵ��������
�������ɣ�
����GPT������ģ�ͽ��û������ʾ��չΪ��ϸ��Ļ�������Ƶ���ɵ�ϸ�ڶȺ�������ʹSora�ܹ������û���ʾ���ɸ����������ݷḻ����Ƶ��
�ӹ�������������ʹ�õ���OpenAI������ģ�͵ļ���������
���Դ�ģ��GPT4.0➕ͼƬ��ģ��DALL��E 3➕��Ƶ��ģ��Sora
������ڼ���ͻ�Ʋ�������Ӱ�����ޣ�OpenAI��������ģ�ͣ���+ͼ+��Ƶ����������˾��Ҫͻ�������Ĺ���ջ�������ס�
����4��
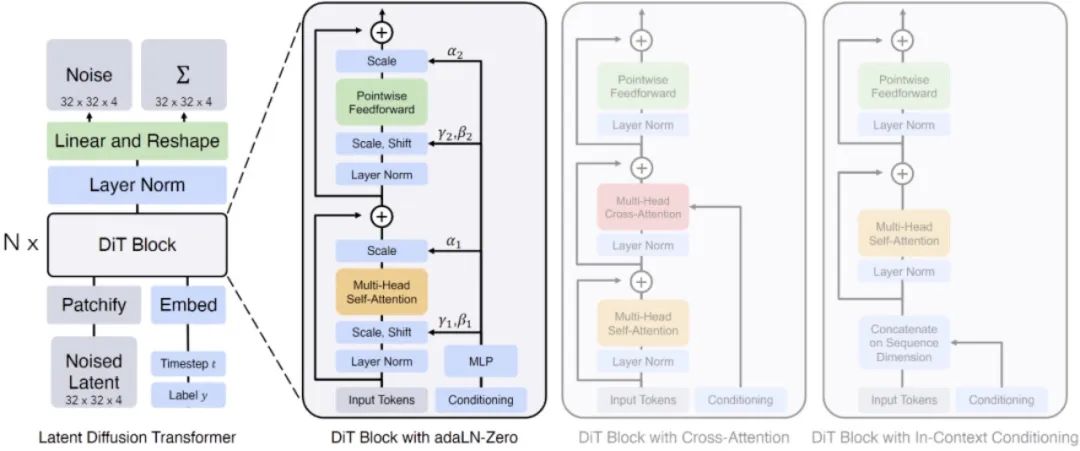
��ɢģ��Diffusion Transformer��DZ�ռ����ݽ��д���
DZ������������Ϣ�Ѿ������ˣ����ڽ��뵽�������ݺ�������Ƶ���ڡ�
OpenAI������Diffusion Transformer��DiT���ܹ������ǻ��ڲ�����ѧ��������"Scalable diffusion models with transformers"������Ĺ�����
�üܹ���Ч�ؽ������ɢģ�ͺ�Transformer������������һ��ǿ�����Ϣ��ȡ����ר�����ڴ�����������Ƶ���ݡ�
����ܹ����£�
No.1
DZ������Patch�Ĵ���
��������Ƶ��ʾΪһϵ��DZ�ڱ�������ЩDZ�ڱ�����һ�����ֽ�ɶ��Patch��
ÿ��Patch�ɶ��DiT�鴮����������ǿ��ģ�Ͷ���Ƶ���ݵ�������ع�������
No.2
DiT����Ż����
�Ա�Transformer�ܹ��������ģ�����������Ӧ���һ����Adaptive Layer Normalization��������ע������Cross Attention���Ͷ��������Token���е��ڣ����Ż����ܡ�ʵ�����������Ӧ���һ�������ģ��Ч�����������ѡ�
�������ں˵�������ļ�������ɢģ��Diffusion��Transformer��ܣ�
��ɢģ�͵���ѧԭ����
��˹��������������ȥ�����:
�� ͨ���������Ӹ�˹�����ƻ�ѵ�����ݵĽṹ��ʹ��Ϣ�����ӣ����ڸ�ԭʼ�ṹ��Ϣ��ѧϰ��ת������̣���ȥ�룬�Ӷ��ָ����ݡ�
�� ��һ���̿���ͨ��ѵ�����ʷֲ�q��xt�Oxt-1����ʵ�֣�����x0,...,xT�������DZ�������С�


Transformerģ�͵���ѧԭ��
����̽��Diffusion Transformer��DiT���ܹ�ʱ������Transformer����ѧԭ������Ҫ��Transformerģ����������ע�������ƺͶ�ͷע�������ƣ���ʵ�ֶ��������ݵĸ�Ч�������������⡣
�� ��ע������Self-Attention������
��ע������������ģ���ڴ���һ�����е�ÿ��Ԫ��ʱ�����ǵ������е���������Ԫ�أ�����ѧ��ʾΪ��
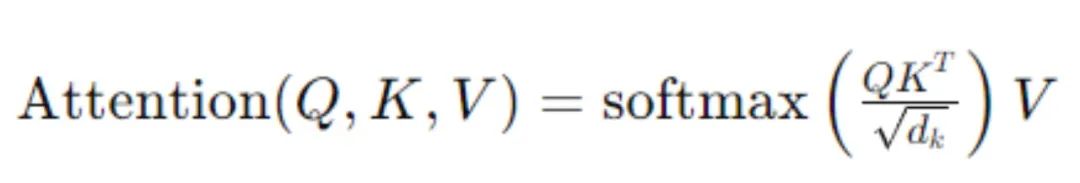
����Q,K,V�ֱ������ѯ��Query��������Key����ֵ��Value����dk�Ǽ���ά�ȡ��������ͨ����������Ԫ��֮���Ȩ�طֲ���ʹģ���ܹ��������ڲ��ĸ��ӹ�ϵ��
�� ��ͷע������Multi-Head Attention������
��ͷע���������Ƕ���ע��������չ�������е�ִ�ж����ע����������ÿ��ʹ�ò�ͬ��Ȩ�ؼ���Ȼ������ͷ������ϲ���
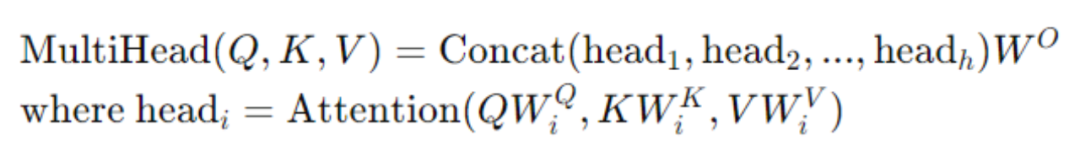
���ϻ�����W�ǿ�ѧϰ��Ȩ�ؾ���ℎ��ͷ����������ģ��ͬʱ�Ӳ�ͬ�ı�ʾ�ӿռ���ѧϰ��Ϣ�������������ͱ���������
����TRANSFORMER�ļ���ϸ�ڣ�����ѧ���ڡ�ChatGPTĻ����������С������й���ϸ�Ľ��ܺ�ѧϰ��
��ɢģ����Transformer�Ľ�ϣ�
�� DiTͨ������Transformer�ܹ���ʵ���˶���Ƶ���ݵ������������⡣����ͷע������һ�������˽�ά��ѹ������ɢ��ʽ�µ���Ϣ��ȡ���̸��Ӹ�Ч��
�� �˹������������ģ�ͣ�LLM����������ԭ�����ƣ�ͨ��������DZ�����ĸ��ʷֲ�����ʹ��KLɢ��������ֲ�֮��IJ��죬�Ӷ��Ż�ģ�����ܡ�
ͨ�����ַ�ʽ��Sora��������ȷ����ȡ��������Ƶ���ݵ������Ϣ�����ܸ����û��ļ����ʾ���ɸ����������ݷḻ����Ƶ��
��һ���µķ���Ϊ��Ƶ��������������µĿ����ԣ�չʾ����ѧԭ����AI������ϵ�ǿ��������
����5
��Sora��Ʒ�������û�������������
Sora�ܹ���ȷ�����û�����ͼ��������Щ��ͼ��չ���������£���Ϊ��Ƶ�����ṩ����ͼ��
��������չ������⣺
�� �����û���ʾ
Sora�����ռ��û��ļ����ʾ���������һ��������������б�������κ���Ҫ����ƵԪ�ء�
�� ��ʾ��չ
����GPTģ�ͣ�Sora����Щ��̵���ʾת������ϸ����Ļ����������漰�����ӵ���Ȼ������������ɣ�ȷ����չ�����Ļ������ʵ��ԭʼ��ʾ�������������ϸ�ڣ��米����Ϣ����ɫ���������ɫ�ʵȣ�ʹ����ʾ��������Ҿ��塣

Soraģ��ʱ��Ůʿ���ڶ�����ͷ��Ч���������
�� ������Ƶ����
������Щ��Ļ��Ϊָ����Sora���Ž���Ļת��Ϊ�Ӿ����ݡ�������̰���ѡ������ɫ��ơ��������ź���б��ȷ��������Ƶ����Ļ����һ�¡�
�� �Ż������
����Ƶ���ɵĹ����У�Sora�����Ż��͵���ȷ����Ƶ�������ﵽ��ߡ�����ܰ�������Ƶϸ�ڵ�����ɫ�ʵ�У�����Լ�ȷ����Ƶ�����Ժ��Ӿ���������
�����Ƕ�Sora����ԭ���IJ��룬Soraģ�Ϳ������ɸ���������Ƶ����OpenAI����ʦ�Ļ���������������������ͨ��ģ������
4
����ʦ�ġ������͡�����������
����ʦ�����е�Sora�ɲ���Ϊ�˸�������һ����Ӱ�������������������������ʵ���ṩ��Υ�����������ɡ��ľ������硣
�ǵ�����δ����أ�����Ǵ����ǵĹ�����
�����������������������غ㶨�ɡ�����ѧ���ɡ���������ţ�ٶ��ɵȡ�
�������ﲻ��Υ����Щ����ƻ�����ܷ���������������������Ӱ�ӡ�����Щ����������γɵ��أ��������ֿ��ܣ�
1�������һ��ԭ����������������ķ�չ�������γɵģ�
2�����ɵ�һ��ԭ��������Ӱ�����Щ���ɲŷ�չ�����ڡ�
���������֡�����������Ҳ�����š��������硱�����ַ�����
���������������ַ�ʽ����ʵ������������ģ�ͣ�
���������˶���ģ�⣨Sora��
��������ѧϰ��Soraͨ���������ģ��Ƶ���ݣ�ʹ�û���ѧϰ�㷨����������������ģʽ����ƻ����ض�����������ѭţ�ٵ������������ɡ�
������ѧ�����ģ�⣨������棩
��ѧ��ģ���������ͨ���ֹ����������������ѧģ�ͣ������ģ�͡�����ѧ���̣�������ȷ����Ⱦ����������ͻ�����
�����ԣ����������˶���ģ�⣨Sora���Ͽɵ��ǡ������һ��ԭ�������ڻ�����ѧϰ��������ѧ�����ģ�⣨������棩�Ͽɵ��ǡ����ɵ�һ��ԭ���������ڸ�������ߡ�
�������߶��������飬��ô�����߿��Խ����
5
���������ܵġ���ѧ©����
Sora�Ƿ��ǡ�����ģ����������ѧ�����Լ��Ŀ�����
�ںܶ��ѧ�����У�����ı�������ѧ��
���Sora����ģ�ⷽʽ���ձƽ���ѧ���ʣ�����Ҳ���ܱ���Ϊ�������͡���
Soraģ�����õ��˺ܶ���ѧԭ�����������£�
1.���ηֲ�
������
��Ȼ���ݼ�����Ϊ��ά�����ϵĸ��ʷֲ���
2.�������ε�
ά�����ͣ�
���������㼯�ڸ�άԭʼ���ݿռ���ʵ���Ͼ����ڵ�ά���Ρ�
3.����ϵͳ
���ʶ���
�����ļ�����������ͨ��ƫ�ַ��̵Ľ�������Ժ�Ψһ�������֣���Ȼ������������ڴ����������������Ϳ�Ԥ��ġ�
4.���ʷֲ�
�ı任��
ͨ������任���������Ŵ���任������ɢ���̣������ݸ��ʷֲ�ת��Ϊ������������ɵĸ�˹�ֲ���
����Soraģ�����ɵ���Ƶ��������Ȼ�������ԡ���ѧ©������
1
����Ե�����
Transformerģ��ѵ�������е�ͳ�Ʒ�������ȷ����ѧ���֡�
2
�ֲ������������������
Ҫ��ģ���ܹ����ϸ��߲����ѧ���ۣ���ʵ�������һ���ԣ����������𣩡�
3
�ٽ�̬��ʶ���ģ��
��ͨ�����η��������Ŵ�����������ȷ̽���������εı߽磨�����䵽�ʱ䣩��
Soraģ��չʾ��ͨ�����ѧϰģ�⸴�����������DZ������Ҳ�������ԡ���ѧ©���������������ģ���������磬��Ҫ���߲�ε���ѧ���۲���̽���µ�ģ�ͽṹ��
6
AI������ڴ�ͳһģ����
�����ԣ�OpenAI��ͼ����AI��ͳһģ�͡�
��ͨ��GPT-4.0��DALL��E 3��Sora��ģ�͵Ŀ�������ͼ�����ԡ�ͼ�����Ƶ�Ȳ�ͬģ̬֮�佨����������ɴ�ͳһ��
���ܶ��˲������ˣ����ѧϰ����ͷ��Yann LeCun����ķ�����ʽV-JEPAģ����ͼͨ������Ӿ���֪������������������Ϊ��ȷ������ģ�͡�
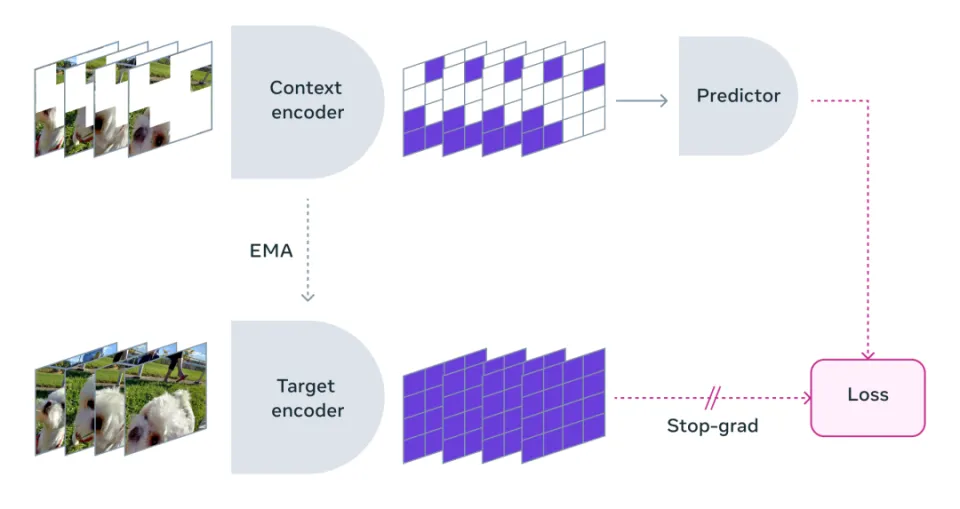
AI��ͳһģ�Ͳ���û�п��ܣ�һ���µķ����Ѿ����֣�
����ͬģ̬������ת��Ϊһ�ֻ����ͳһ�Ļ���������ʽ���Ա�ʹ��ͬһ���㷨��ܽ��д����ͷ�����
�������Ե�Token�������ӻ�����Ƶ���ݵ�Spacetime Patches�������ӻ����˿�����ϣ����
Soraģ����ʵ�Ѿ������ֻ�������Token��Spacetime Patches�ڽ��н����������ͳһ��һ�ֻ���������Ҳ���Dz����ܡ�
�������ݡ��������ӡ�����ͬʱҲ�������Ĵ��������Σ�
1������Transformer�ܹ��Ľ�����ϵ��
������ע�������ƣ�Self-Attention Mechanism��ʹ��ģ���ܹ�������������Ϊ��ģ̬���ݵ����ж����ʱ�������Խ�ģ�ṩ��ѧ��ܡ�
2��Diffusionģ�͵���ϸ�����̣�
Diffusionģ��ͨ������ʽȥ����������������ɢ�����Ƕ��������ַ���չ����ģ���ڴ�����ͬ��������ʱ������ԺͶ����ԡ�
3�����ɶԿ����磨GAN���Ĵ���Ӧ�ã�
���������ɱ�����������������б�����Ŭ��������ʵ���ݺ��������ݣ��ƶ�ģ���������������������Լ��Ը������ݷֲ��IJ���������Ľ�����
4��ģ̬ת���ı��������
ͨ��ӳ�����ӳ�����ѧ������ʵ���˴Ӿ������ݵ�ͳһ��ʾ�ռ��ת����
��������Ĵ�ͳһ������ͳһ��������������AI�����������Ҫ���ۡ�
AI�������ڴ�ͳһģ����
����ǣ�����ʵ���������Dz���ͬ����ˡ�
���AI���粻���ڴ�ͳһģ�͡�
��ô��ô��������ѧ��Ѱ�ҵĴ�ͳһ�����Dz��Ǿ���ˮ�£�
Ҳ��������ֻ��ȥ����һ�����磬�������ⴴ���ߡ�
��
AI������һ����������
һֱ������������̽��������Դ��ߵ�ʴ����ߡ�
�����죬�Լ����������Գ�Ϊ�������ˡ�
ǧ��عˣ����Dz�����������ʷ��ʱ��ʱ�̣�
��һ������Ŀ����Token���Ĵ�ͳһ��ƣ���֤��Transformer�ܹ�����������������Diffusionģ�͵ײ����塢��������Spacetime Patches�ĸ������¡�
��һ���������ִ�ģ�ͷ�����������Ŵ����������Ʒ�������Ķ��ǣ�һ��֮���ν���ط��졣
�ɶ������������˵����Щ������������Ҫ����һ��������ģ�͡�������һ���������档ͬʱ��ϣ�����������ȫ��ѭF = ma��E=MC2�������������ɡ�
���������������������ʵ�����к�����
����һ�룬��ʵ������û�п���Ҳ��һ��ģ�⣿
����ǣ������˷ܣ����ǵ��ǣ�

















