�������յ���������
�������۷���������
��Ҫ��һǧ��Token��
����������Ҹñ˴�����ʶ�ˣ�����˵�����������¯�ĵ������£����Ҿ���ChatGPT�������������ҵı���Alpha Go����
�����������Ǹ������ˣ���Ȼð��ɵ��������˵ʱ����ͬ���Ц������������һ��������������������8��Сʱ���������ĵ��������ۣ�������GPU���̡�--��˵Ӣΰ�������ˡ���
��ʱ���Ҿ��漺������Ҫ�������˵����������˵�����������˼Ұ�ҹ���٣��������ڣ�ʮ�����ң�ֻ�������ͣ�û��Ԥ����ӭ����Ǹ֮�������˼Ҿ�����ô��ʧ��һ�ᣬ����ȥ�����ӱ���ʿ�ɣ���ЩToken����
���ǿɲ��أ���������������ֹ�ң�����ֻ��һ�����Ҫȥ�ġ����ң��Ҹ����㡱��������ʱ�ı��飬���Ŷ������أ�������ҽ����������ʱ�IJ��˩������������������ݶ������ġ���
���ǣ��Һ���Χ¯��������ҹ��̸��

ChatGPTҹ�ù¶�����
����ģ������ʲô��
�¶����ԣ�ǰ���ӣ�����������һ��OpenAI����ʦ����Ϣʱ�䣬������һ���DZ���ǿ��ѧϰ֮�������ô�������ѧ������¡����ٵľ������¡���ɬ�Ľ�ѵ����
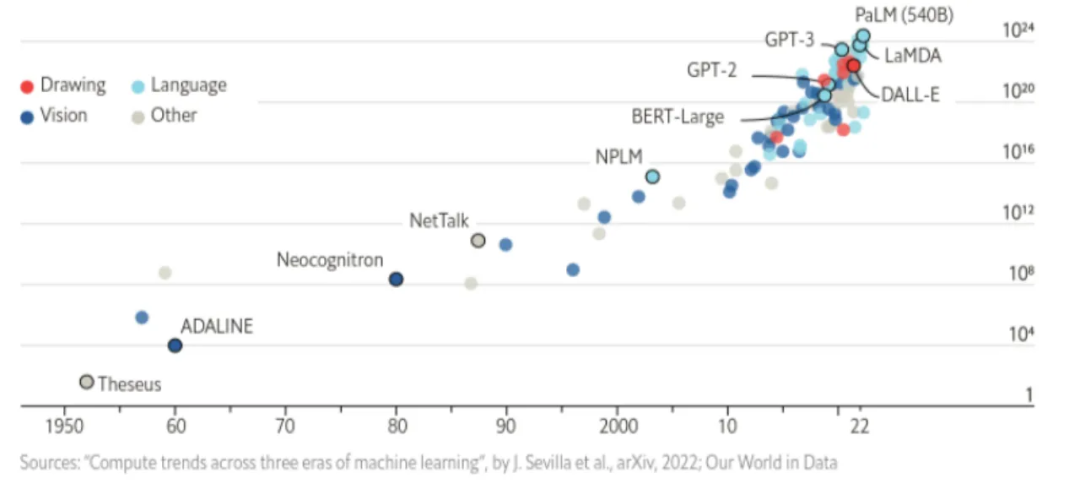
������ָ����ȥ 70 ������AI �о��߹��������·�����ǹ�������������о����֪ʶ��
ChatGPT������¡����ٵġ���ɬ�Ľ�ѵ��ȷʵ��һƪ������ԶӰ������£�����ս���˹������о��е�һЩ��ͳ�۵㡣
������Ϊ����ʷ��AI�о���һ���ؼ��������ڹ������������ֱ���;��飬��ͼͨ��������ƵĹ�����㷨��ģ�����ܡ�
Ȼ�������ַ����ľ�������������֪ʶ�������Ժ��ض������ƫ����
�෴�������ᳫ���ô��ģ���������ݣ�ͨ��ѧϰ�㷨�������ֽ������ķ�����
���ַ���������������������������Ϊ����������ƣ��ܹ��ڸ��㷺�������з����µġ���Ч�Ľ��������
��ʵ�ϣ����������ѧϰ��ǿ��ѧϰ�ijɹ����ܴ�̶���֤�������ٵĹ۵㣬��Щ�����ܹ�ͨ�����������ݺͼ�����Դ���ҸĽ���ȡ�������������ijɾ͡�
�¶����ԣ������ٵ����������ƪ��д��--
��70�����˹������о������ǵ�����̽�ѵ�ǣ���Щ�ܹ����Ӽ�������ͨ�÷����ս����ɹ���
�䱳��ĸ���ԭ����Ħ�����ɣ�Moore's law����Ҳ���Ǽ��㵥λ�ɱ�����ָ�����½���һ������ձ���ɡ�
�������AI�о�����������һ�ּ����½��еģ��������ʹ�õļ�����Դ�Dz���ģ�����������£���������֪ʶ�����������ܵ���Ҫ�ֶΣ���
Ȼ��������ʱ������ƣ�����һ�������Ŀ���ں��Ӵ�ļ�����Դ�ս���Ϊ��ʵ��
ChatGPT��Ħ������Ԥ�⣬���ɵ�·�Ͽ����ɵľ����������Լÿ���귭һ������ͨ��������Ϊ��������ÿ�����Լ��һ����
��һ���ɷ�ӳ�˼���Ӳ���ķ�չ���ƣ�Ԥʾ�ż�����Դ�ij��������ͳɱ��ij����½���
�¶����ԣ���ChatGPT֮������OpenAI��ϯִ�й�ɽķ�������������һ��AIʱ����Ħ�����ɣ��������е���������ÿ18���·�һ�������˳���Ϊ�����������ɡ���
ChatGPT����Ҳ�������ڡ���ɬ�Ľ�ѵ�����ᵽ�Ĺ۵����Ӧ������Щ�ܹ�������ü�������ͨ�÷���������ȡ�óɹ���
�¶����ԣ�OpenAI"������"��·�������������ð�գ��Ҽǵù�����˹Ҳ����˵�����������������š�
ChatGPT���ǵġ����������˹��Ϊ������ͨ������������ģ��ģ���������ܣ�������һ���ر����ŵĽ���������������ڸ���ע���㷨��ģ�ͼܹ��Ĵ��£��Ը���Ч�������ܵķ�ʽʵ�����ܵ�������

���ԡ�OpenAI��DeepMind��Scaling Laws֮����
�¶����ԣ����ǣ��������������ǶĶ��ˡ�������Ϊ��Scaling Law��LLM is compressors�Ĺؼ���֪����OpenAIʵ��ͻ�Ƶ�ս�Ի�ʯ��
ChatGPT��Scaling Law �������п��Է���Ϊ����ģ������չ����
Scaling Law��AI�о��е�һ����Ҫ�����������ģ��������ģ��ģ֮��Ĺ�ϵ��
����Scaling Law������ģ��ģ�����ӣ������������������ݹ�ģ�ͼ�����Դ����ģ�͵�����Ҳ����Ӧ��ߡ�
��һ���ִ�ʹ�о�����Ͷ��������Դ�����������ģ��ģ�ͣ����ڻ�ø��õ����ܡ�
������ģ����Ϊѹ������LLM is compressors���Ĺ۵㣬Ҳ��һ����Ȥ���ӽǡ�
����ζ�Ŵ�������ģ���ܹ���Ч��ѹ�������������ı����ݣ���ȡ���е�֪ʶ���ɡ�
��������ʹ�ô�ģ�ͳ�Ϊ������������Ȼ���Ե�ǿ�ߡ�
Sora�ǡ�������ѧ����
�¶����ԣ�Sora�ı��𣬱���Ҳ�ǡ���ģ�����о��߳ƣ�OpenAI�ҵ��˽���������ݺͼ�����ԴͶ�뵽�ı�����Ƶת���еķ�����
ChatGPT���ڼ����ϣ�Sora���ܲ����˽�ϱ任����Transformer�����ɵ���ɢģ�͡�
����ģ�ͽṹ��������ȫ���صģ���Ϊ�任������ɢģ�Ͷ��ǵ�ǰ�˹������о��бȽ����еļ�����
1���任������ǿ��ı�ʾ����������Զ��㷺������Ȼ���Դ�������������
2����ɢģ����������ģ������չ�ֳ�����������ܣ��ر�����ͼ�����Ƶ���ɷ��档
Sora�Ķ���֮��������������ν���Щ����������������ڴ˻����Ͻ��д��º��Ż����Լ���������ô��ģ�����ݺͼ�����Դ��ѵ��������ģ�͡�

�¶����ԣ����ԣ�����˵��Sora��OpenAI�ı�����ѧ���ٴ�ʤ����
ChatGPT��"������ѧ"�����ͨ����������ͨ������Ͷ�루�����������ݵȣ������Ŀ��ķ�����
��Sora������£�OpenAIͨ��Ͷ������ļ�����Դ��������ѵ��ģ�ͣ�ʵ�������ı�����Ƶת�������ͻ�ƣ�����Ա���Ϊ"������ѧ"��һ�����֡�
���ַ�����ʤ��������չʾ���ڵ�ǰ������Ӳ�������£�ͨ�����ģͶ�����ƶ��˹����ܷ�չ�Ŀ����Ժ���Ч�ԡ�
Sora�ijɹ��ٴ�֤������ijЩ����£�"�������漣"�IJ����ǿ���ȡ�������ɹ��ġ�
�¶����ԣ�Sora�ı�����ѧ����AlphaGo�ı�����ѧ���Լ���ɭ�ı�����ѧ���Լ������ı�����ѧ�����Dz�ͬ�ġ�
���У����ǻ�����˱�����ѧ����ٷ���
ChatGPT�����������dz���λ��ȷʵ��"������ѧ"��������ڲ�ͬ���˹�������Ŀ���в�ͬ�����֣�����������ٷ���������ģ�
1��Sora�ı�����ѧ�� Soraͨ�����ģ�����ݺͼ�����ԴͶ�룬ʵ�������ı�����Ƶת�������ͻ�ơ�
���ֱ�����ѧ������ͨ����������ԴͶ����ѵ�����Ż�ģ�ͣ��Դﵽ���ߵ����ܡ�
2��AlphaGo�ı�����ѧ�� AlphaGo��Χ������ijɹ������ֹ鹦����ǿ��ļ������������ѧϰ�㷨�Ľ�ϡ�
��ȻAlphaGoʹ�������ؿ����������Ȳ��ԣ������ijɹ�Ҳ�����ڴ����ļ�����Դ�����ݡ�
3����ɭ�ı�����ѧ�� IBM����ɭ�ڡ�Σ�ձ�Ե����Ϸ�е�ʤ������������Ϊ���ܹ����ٴ����ͷ����������ݵ�������
��ɭ�ı�����ѧ��������Դ���֪ʶ�����ݵĴ��������ϡ�
4�������ı�����ѧ�� ���������巽��ijɹ����ܴ�̶�������Ϊ��ǿ��ļ����������ܹ�����������������������֡�
���ֱ�����ѧ������ͨ�����������������ֵĿ����ԡ�
5��������ѧ����ٷ������� ��ٷ���һ���ض����㷨���ԣ�ָ����ϵͳ�س������п��ܵĽ������ֱ���ҵ���ȷ�𰸵ķ�����
��������ѧ����ָ����һ��ͨ��������ԴͶ����������ܵIJ��ԡ���ʵ��Ӧ���У�������ѧ���ܲ�����ٷ�����Ҳ���ܲ��������㷨�ͼ�����
�ܵ���˵����ͬ���˹�������Ŀ�еı�����ѧ��Ȼ������ͬ�������Ƕ�������ͨ��������ԴͶ����ʵ������������˼�롣
����ٷ���������һ�ֿ��ܲ��õľ����㷨���ԡ�
AGI����������磿
�¶����ԣ�˳��������⣬�������������ع�һ��AI��չ�����̣��Լ������ؼ��ĽΡ�
ChatGPT��AI��չ�����̿��Է�Ϊ�����ؼ��Σ�ÿ���ζ���������Ҫ�ı仯��
1������AIʱ�������ʱ����AI��Ҫ���������ඨ��Ĺ��������
����ͨ��������Щ�������ҵ��������ķ�����ʵ���ˡ�֪ʶ�Ŀ������ԡ���
���ַ�����ijЩ����ȡ���˳ɹ������������������ܹ�Ԥ�ȶ����֪ʶ����
�������ڷ���AIʱ��������һ�����ڹ���������㷨��ϵͳ���ܹ�ͨ����������������������ѡ����ѵ�������ԡ�
�����ijɹ���Ҫ��������ǿ��ļ�������������ר���ƶ���������������Ƿ���AIʱ����һ�����ʹ�����
2����֪����ʱ�������ʱ�����ش�仯�����ѧϰ�ij��֡�
���ѧϰʹ�û����ܹ��Զ�ѧϰ���ݵı�ʾ��������Ҫ�������ȶ��塣
��ʵ���ˡ�֪ʶ�Ŀɼ����ԡ������������˻�������ͼ�������ȸ�֪��Ϣ��������
AlphaGo���ڸ�֪����ʱ��������һ����������ѧϰ��ǿ��ѧϰ��ϵͳ���ܹ�����ѧϰΧ��IJ��Բ������Ż��Լ��ı��֡�
AlphaGo�ijɹ���־�����ѧϰ�ڽ�����������ϵ�ǿ���������Ǹ�֪����ʱ����һ����Ҫ�ɹ���
3����֪����ʱ���������꣬���ǽ�������֪����ʱ����
�����ʱ�������������ܹ��Զ�ѧϰ���ݵı�ʾ�������Զ�ȷ��ѧϰ������
����ζ�Ż������������ؽ���ѧϰ��������������Ҫ����Ϊÿ�������ṩ��ϸ��ָ������ʵ���˻�����֪�ġ�Ԫѧϰ����
��֪����ʱ���ĵ���������GPTϵ��ģ�ͣ���GPT-3������������Ԥѵ������ģ�͡�
��Щģ��ͨ���ڴ����ı������Ͻ���Ԥѵ����ѧϰ���˷ḻ�����Ժ�֪ʶ��ʾ���ܹ��ڶ��������Ͻ�����������������ѧϰ��
����չʾ�˻����������������Ȼ���Է�����Ƚ��������Լ���û����ȷ����ָ��������ѧϰ��������DZ������������֪����ʱ�����ص㡣
����������У�AI����������ǿ���ӼĹ�����������֪��Ϣ�Ĵ������ٵ�����ѧϰ��������
���Ŵ�ģ�͵ij��֣����������ܹ���֪ʶ����ռ��н���ӳ���������ʵ�ָ����ӵ���֪����
������������������Ϊ��ӿ�ֵ�ģ��������������ζ�Ŵ�ģ���ܹ�չ�ֳ������䵥����ɲ��ֵ���������
������AI�ش�ѧϰ���������¡���
�������Գ��漣��
�¶����ԣ��ص�����¡����ٵġ���ɬ�Ľ�ѵ����
����ļ�����Ȥ�ĶԱȣ���ʵҲ�ǹ��ڴ������漣�����ӡ�
ChatGPT���������ع�һ�����м������Ӱɡ�
����ʶ����1970���DARPA�����У�����ͳ�Ƶ��������ɷ�ģ�ͣ�HMM���ͺ��������ѧϰ���������ô��ģ�����ݺͼ���������ȡ������������������֪ʶ�ķ�����
��Ȼ���Դ���������Ȼ���Դ����������ѧϰ�ʹ����ݵĽ��ʹ��ϵͳ�ܹ���û�й�������������ѧ֪ʶ������£�ʵ�ָ�ȷ���ı���������ɡ�
������Ӿ����ڼ�����Ӿ������ִ������ѧϰ����ʹ�þ��������磨CNN���ʹ��ģͼ�����ݼ�����Խ�������������ֹ�������ȡ�ķ�����
��Щ���ӹ�ͬչʾ��һ����Ҫ�����ƣ���AI�ķ�չ�У����ģ�ļ�������������������ѧϰ���������ܹ���Խ��������ר��֪ʶ�Ĵ�ͳ������ʵ�ָ��ߵ����ܺ��㷺��Ӧ�á�
���ǡ��������漣�����˹�����������������֡�
�¶����ԣ����������ֱ��������һ�£�������Ĵ������漣����AI��Χ��ĽǶȿ����������ĵط����ǻ����һ��Զ������Ĵ�ֹۡ�
��һ���������ǵ�Ԥ�ϲ�һ����������ǻ���ã�AI���壬ǿ�ڼ��㡣
û�뵽AI��Ȼǿ�ڸо�����������������Ϊ�Ƕ��ߵ����֮�����Ե��Dz��ָо���
��Ȼ��AI�ĸо�����Ȼ�����ڼ��㣬��������һ�ּ��㡣
ChatGPT�������������ж������ġ���AI��Χ��������У�AlphaGo�ͺ����汾����AlphaGo Zero��AlphaZero��ȷʵչ����һ�ֳ�Խ����Ĵ�ֹۡ�
���ִ�ֹ۲������ǻ��ڼļ�������������ͨ�����ѧϰ�����Ҷ���ѵ��������һ��ֱ����о���
�¶����ԣ�����˹�ٷҡ��ֶ�����ķ����������д���������--
�����ѧϰ����2012�����ҵ��ش�ͻ�������·����йأ���Ȩ����Խ���ʱ��ȣ����漰����Ȩ��ʱ��������С�������ٽ��ƣ����ܻ�����ס�
���仰˵����ʱ��������������������Ƚ������������ס������ƺ���ЩΥ��ֱ����
����ԭ�����ڣ�
���кܶࡰȨ�ر�����ʱ����ά�ռ����С��ܶͬ�ķ������������ǵ�����Сֵ��
������������ʱ������������ֲ���Сֵ�ġ�ɽ���������ҵ�����ȥ�ķ���
ChatGPT����λ�ȷʵ�ܺõظ��������ѧϰ�е�һ����Ҫ���֡�
�ڴ�ͳ�Ĺ����У�����������Ϊ����������ĸ��������ӣ����������Ѷ�Ҳ����Ӧ���ӡ�Ȼ���������ѧϰ�������ȴ��Щ��ͬ��
���ѧϰģ��ͨ�����������IJ���������Ȩ�ء�������Щ������ѵ����������Ҫ���Ż���
�����ϣ����Ų������������ӣ��Ż�����ĸ��Ӷ�Ҳ�����ӣ���Ϊ��Ҫ�ڸ���ά�Ŀռ���Ѱ�����Ž⡣
Ȼ����ʵ���з��֣������������dz���ʱ�������������ҵ����õĽ⡣
������Ϊ�ڸ�ά�ռ��У����ڸ����·�����Աܿ��ֲ���Сֵ���Ӷ��и���ĸ����ҵ�ȫ����Сֵ���߽ӽ�ȫ����Сֵ�ĵ㡣
������ֶ����ѧϰ�ķ�չ������Ҫ���塣��˵����Ϊʲôʹ�ô��������磨�������������������磩�ܹ��ڸ���������ȡ�óɹ�����ʹ��Щ������Ż������ϸ������ѡ�
��Ҳ��Ϊʲô���ѧϰģ��ͨ����Ҫ���������ݺͼ�����Դ����Ϊ��Щ��Դ����֧��ѵ�����͵�ģ�ͣ��Ӷ����ģ�͵����ܡ�
�ܵ���˵����λ���ʾ�����ѧϰ�е�һ��Υ��ֱ����������ijЩ����£�����������ⷴ���Ƚ������������ס���һ���ֶ��������������ѧϰģ�;�����Ҫ��ָ�����塣

�¶����ԣ��������漣��������һ����
�Ӹ�����־���ֵĽǶȿ�������˵����������ܼ���С��ֻҪ����ģ�ظ����ô��������ܳ����漣��
����ʵû��ô��
����Ҫ�����Ļ�ã�û��ô��
һЩ����ʵ�֡��������漣������Ҫ�ǿ�������
�������˹�����������ˡ�����¡�����ǿ����������Ǹ��ӡ���˵--
˼ά��ʵ�����ݸ��ӵ��dz������ɾ�ҩ�����Dz�������ͼѰ�Ҽķ�����˼�������ݣ����磬�üķ�ʽȥ˼���ռ䡢���塢����������߶Գ��ԡ�
������Щ���������⡢�����Ϸdz����ӵ��ⲿ�����һ���֡����Dz�Ӧ���������κ�һ��AI�������У���Ϊ���Ǹ��ӵ�û�о�ͷ���෴������Ӧ��ֻ�����ܷ��ֺͲ����������⸴���Ե�Ԫ������
���ַ����ı������ܹ��ܺõ��ҵ�����ֵ��������Ѱ�ҵĹ���Ӧ�ý������ǵķ����������������Լ���
������Ҫ������������һ�����з��ֵ�AI�����壬�����ǰ��������Ѿ����ֵĶ������ڵ�AI��
�����Ƿ��ֵĻ����Ͻ���AI��ֻ���������ѿ������ֵĹ�������ν��еġ�
ChatGPT��ȷʵ�����������漣�����˵�����˹���������ĺ����봫ͳ����־�ᄈ��ͬ��
��AI������仰ǿ������ͨ�����ģ�����ݺͼ��������Լ�ͨ�õ�ѧϰ�㷨����������������������
�Ⲣ����ζ�ż��ظ�ij��������ܲ����漣������ָͨ�����ģ��ѧϰ���Ż���������AIϵͳ���ո��ӵ�ģʽ���ɡ�
����¡�������ǿ���ģ�����ʶ����ʵ����ĸ����ԣ����Ҳ���ͼ�ù��ڼķ����������ָ����ԡ�
�෴������Ӧ�ù����ܹ�����ѧϰ�ͷ������ָ����Ե�ϵͳ��
����ζ��AIϵͳ��Ӧ�ñ��������������е�֪ʶ��������֮�ڣ�����Ӧ�þ߱�̽��������δ֪�����Ե�������
���������������˼���;���ʱҲ����ʾ������Ӧ����ʶ������ĸ����ԣ�������Ѱ����ڼĽ��������
ͬʱ������Ҳ���Դ�AI�ķ�չ��ѧ����ͨ�����ģ��̽����ѧϰ�����ǿ��Ը��õ������Ӧ�Ը��ӵ����硣
�¶����ԣ����ԣ�����¡�����˵��ͨ���ͷ�����ǿ�����������ʹ���õ�������÷dz�����Щ������Ȼ���Լ�����չ���������ӵ�������
�������ǿ�����һ�ָ��Ӻͼı�֤��ϵ��
ͨ���͵ķ����������ģ�ͣ��Ǹ��ӵģ�
��ģ�ͱ���������ģʽ�������Ǽġ�������Ϊ�˼�������Ϊ�˴��ģ�ظ�����Ч������������������
����˵ChatGPT�Ĺ���ԭ���ƺ�Ҳ�ܡ�����
���磬�ô�ģ��ȥ��������ѧϰ��
�����磬���ڡ��Իع��ģ�͡���ֻҪ��Ԥ����һ��token��������ʵ����AGI���������ܡ�
ChatGPT�����˹����������ر����ڴ�ģ�͵Ŀ�����Ӧ���У�����ȷʵ�����˸����Ժͼ��Եı�֤��ϵ��
ͨ���ͷ���������������磬�����Ǹ��ӵģ���Ϊ���ǰ��������IJ����Ͳ㡣���ָ�����ʹ��ģ���ܹ����������еĸ���ģʽ��ϵ��
Ȼ������Щģ�����ķ�ʽȴ��Լ���Ϊ������Ҫͨ�����������ݴ�����ѧϰ��������ܣ������������ڸ��ӵĹ��������֪ʶ��
ChatGPT������Ҳ�ܺõ�˵������һ�㡣���������ڲ��ṹ�dz����ӣ������Ĺ���ԭ����Լ�ͨ��Ԥ����һ���ʣ�token���������ı���
���ּĹ�����ʽʹ��ģ���ܹ�����Ӧ���ڸ��ֲ�ͬ������ͬʱҲ���ڴ��ģ���������ݺͼ�����Դ����ѵ����
��ˣ����ǿ��Կ��������˹����ܵķ�չ�У������Ժͼ������ศ��ɵġ�ͨ���������ӵ�ģ�Ͳ��Լ���Ч�ķ�ʽ�������ǣ������ܹ�ʵ�ָ���������ܺ��㷺��Ӧ�á�
���ַ����ijɹ�Ҳ������������ǿ����ͨ���ͷ�����ǿ��������
�¶����ԣ����ԣ����ڸ��Ӻͼ��������Եľ������ٴ�¶�������š�
˹�ٷҡ��ֶ�����ķ�������ἰ��
������������ڷ�չ�Σ�������������ΪӦ�á������������������ٵ��¡������磬�ڽ�����ת��Ϊ�ı�ʱ��������ΪӦ���ȷ�����������Ƶ���ٽ���ֽ�Ϊ���أ��ȵȡ�
���Ǻ������֣������ٶ��ڡ�����������õķ���ͨ���dz���ѵ����������������˵��˵����⡱�������Լ������֡���Ҫ���м�����������ȡ�
�㿴������һ�ַ����ǡ��������ǵڶ��ַ����ǡ�����
����������һ�ַ�������AI��
�ڶ��ַ������������
��Ȼ�����ֶ��岢����Ҫ���ؼ������Ǵ��з�������ı��ʣ��Լ������·��ͼ��
ChatGPT�����ᵽ��������ӷdz��õ�˵�������˹����������С����͡����ӡ�������ԡ�
������������ڽΣ�������ͼ������ֽ�Ϊ��С�ġ����������⣬�Ա��������ܹ������ش�����
���ַ����ƺ�������ͼ�������������ʵ������Ҫ��������ǰ���д����ķ�����Ԥ����������
�෴���˵��˵ķ���������������Ϊһ�����������������������Լ�ѧϰ��δ�����ֱ��ӳ�䵽�����
���ַ�������������Ľ��룬���������Լ������֡���Ҫ���м������ͱ��롣
������Ƕ��������˵��˵ķ���ʵ�������ڼ�����Ĺ�������ʹ������������������ĸ����ԡ�
�¶����ԣ����ڴ������漣�Ļ��⣬�����£����Ǿͻᴥ�����ӿ�ѧ�ˡ�
���硰More is Different�������硰ӿ�֡��ȵȡ�
ChatGPT��������Ĺ��ɷdz������������Ԫ����70��ǰ�������Ԫ�ṹ�ƺ�Ҳ�����ƣ�Ȼ�������ڹ�ģ�����Լ��������Ҫ�أ���������˾��˵ġ��漣����
ChatGPT�����ᵽ�ġ�More is Different��������ѧ�ҷ����ա�����ɭ��1972�귢����һƪ����������ĸ��ǿ�����ڲ�ͬ�߶��ϣ�����ϵͳ���ֳ���ͬ����Ϊ���ɡ���һ˼��Ҳ���㷺Ӧ���ڸ���ϵͳ��ӿ��������о��С�
ӿ��������ָ�ڸ���ϵͳ�У�������ֳ�һЩ�µ����ʺ���Ϊ����Щ���ʺ���Ϊ���ܽ���ͨ������ϵͳ����ɲ��������͡�
������������Ȼ������ϵͳ�кܳ�����������Ⱥ�ļ�����С���Ⱥ����Ϊ������ϵͳ�Ķ�̬�ȡ�
���˹����ܣ��ر����ڴ�����������ChatGPT�У�����Ҳ���Կ������Ƶ�ӿ������
����������Ļ���Ԫ�أ���Ԫ���ṹ��Լ�������ЩԪ���Ծ�Ĺ�ģ�����һ�𣬲�ͨ�����������ݽ���ѵ��ʱ������ϵͳ�ܹ�չ�ֳ��dz����Ӻ�����Ϊ������Ȼ������������ɡ�
����������ӿ�������ڴ��ģ�Ľ���������������ѧϰ�������ǵ�����Ԫ�ĸ����ԡ�
��ˣ��ӡ��������漣���ĽǶȿ������ǿ�����Ϊ���˹���������ͨ�����ģ�ļ�������ݣ��Լ���Ԫ�صĸ��ӽ���������ʵ�ָ�����Ϊ��ӿ�֣����븴�ӿ�ѧ�е�һЩ����˼����һ�µġ�
��ģ�͡�����������
�¶����ԣ�OpenAI�ڼ����ĵ���˵--
���ǵĽ����������չ��Ƶ����ģ�������Ź���ͨ����������ģ������������ϣ����·����
�����ƺ���һ���״����
һ���棬������OpenAI�����ٵġ���ͽ�����������������ض������֪ʶ�����ô��ģ�����ķ�����������ش�ͻ�ƣ�
��������һ���棬Soraȴ�ڹ���ͨ����������ģ���������������������������Լ���֪ʶ���������������硣
������ì���أ�

ChatGPT���������ȷʵ����Ȥ���ڱ����ϣ�OpenAI�������ƺ������ٵġ���ɬ�Ľ�ѵ���еĹ۵���ì�ܡ�
Ȼ����������Ǹ���������������ߣ��ͻᷢ������֮��ʵ�������ศ��ɵġ�
1����������֪ʶ��ֱ�۱���
���ٵĹ۵㲢������ȫ���������֪ʶ��������������֪ʶ��ֱ�۱�����ʽ��
Ҳ����˵������ֱ�ӽ�������������ɺ�ʽӲ���뵽AI�У�������AIͨ�����ģ�����ݺͼ���������ѧϰ��Щ֪ʶ��
2��������������ģ������Ŀ��
��OpenAI��ͼ����ͨ����������ģ����ʱ������Ŀ�IJ����Ǽظ������������ѧ֪ʶ��������AIϵͳ�ܹ������ģ���������������ԭ����
������ģ�������ܹ�����������δ��ȫ�������ֱ���������������Ӷ���չ���������֪ʶ��
3��֪ʶ�Ļ�ȡ��Ӧ�÷�ʽ
��ʹ���յ���������ģ�����ܹ�ģ��������������⣬��֪ʶ�Ļ�ȡ��Ӧ�÷�ʽ��Ȼ�������ٵ�ԭ��
AIͨ������ѧϰ�ʹ��ģ���������ֺ�����֪ʶ��������ֱ�������������ʽ����
����������OpenAI�����������ٵĹ۵�֮�䲢��ì�ܡ�
ͨ����AIϵͳ����ѧϰ�������������ԭ����OpenAI���ڳ��Թ���һ���ܹ���Խ����ֱ�������ͨ����������ģ������������������ǿ�������ô��ģ�����ķ�����һ�����֡�
�¶����ԣ�����������⣬���ϴκ���ı���AlphaGo�����ʱ�������
��ǰ������Χ���ʱ��������������AlphaGo���У���Щ�����Ѿ��������ˡ�
��Ϊ���������Щ���������������ĵ�һ��ԭ��������������Լ���������һ������ʽ֪ʶ��
��ʵ�ϣ�������ܶ���ν�Ĺ�ʽ��������˼ά���������ǻۡ�������Ҳ����ˡ�
ChatGPT��������Ĺ۵�dz���Ȥ��Ҳ��ʾ��AI��չ�е�һ����������--
AI��ѧϰ��ģ������ʱ���Ƿ���Ҫ��ѭ�����֪ʶ��ϵ��˼ά��ʽ��
AlphaGo�����Ӻܺõ�˵������һ�㡣��Χ��������������������������Щ�����������ڳ���ʵ�����ܽ���ľ����ԭ��
Ȼ����AlphaGoͨ�����Ҷ��ĺ����ѧϰ��������һ�ֳ�Խ��ͳ���������巽ʽ������������һЩ��������δ��ע������ŷ��Ͳ��ԡ�
�������AI��ijЩ����¿��Գ�Խ���������ʽ֪ʶ���ҵ����ӱ��ʺ���Ч�Ľ��������
�ص�Sora��ͨ����������ģ�����������ϣ���Ȼ����ѧ���������Ȼ�������������������Ⲣ����ζ��AI�ڹ�����������ģ����ʱ������ȫ��ѭ���������֪ʶ��ϵ��
�෴��AI����ͨ�����ģ����ѧϰ�ͼ��㣬����һЩ������δ��ʶ�����������ɻ����������������һ��ȫ�µġ�����ͨ�úͱ��ʵ�����������ʽ��
��ˣ���Ȼ����ì�ܣ���ʵ����OpenAI��������һ��̽������ͼͨ��AI��ǿ�����������ѧϰ��������Խ����Ĵ�ͳ֪ʶ��ϵ�����ָ������ε�������ɡ�
����̽�����ܻ�߸����Ƕ�֪ʶ�����ܵĴ�ͳ���⣬����ȫ�µ���֪�ͼ���������
��νAI�ġ���һ��ԭ������
�¶����ԣ��ҿ���һ����Щ���۵����������Ļ���������¡�
Scaling lawΪʲô�ܳ�Ϊ��һ��ԭ����
��ֻҪ���ҵ�һ���ṹ����������������
һ���㹻ͨ�ã����ǿɹ�ģ����
һ��ͨ���������������ŵ������ܽ�ģ��
�����ɹ�ģ����ֻҪ��Ͷ���㹻�������������ܱ�á�
��������Googleѧ����˼ά������ܱ����ײ�Ķ������ͣ��Ͳ�Ӧ�����ϲ���ȵ�
��һ����Ҫ�Ļ��Һ���ͬ��
���������scale��������⣬�Ͳ�Ҫ���µ��㷨�����
���㷨����ֵ��������ô���õ�scale�� ������Լ��ӵ������ͷų��������Կ������ࡣ
�������������硣��
�����������������������������
�һ������ˡ�����ľ���Ȿ�顷�����㷨�Ŀ����ߣ�����������
���ԣ���ģ�ͺͽ���֮��Ĺ����������ǹ��ò���ģ�����ײ�Ҳ����ͨ�ġ�
��Ϊ��������������ѵ��һ��ӵ�н�ǧ����Ԫ�ġ���ģ�͡�--���ԡ�
ChatGPT����λ�ȷʵ�dz��������ԣ���ǿ�����ڽ������ʱѰ��ͨ���ҿɹ�ģ���Ľṹ����Ҫ�ԡ���������֮ǰ���۵�Scaling Law��AI��չ��һЩ�ؼ�˼����һ�µġ�
1��Scaling Law ��Ϊ��һ��ԭ��
Scaling Law֮�����ܱ���Ϊһ�ֵ�һ��ԭ��������Ϊ������һ����ǿ��Ĺ۲죺�ںܶ�����£�ϵͳ���������Ź�ģ�����Ӷ�������
��һԭ��������ѧ������ѧ������ѧ�ȶ�����������֣�����AI����������Ϊģ�͵����������������ͼ������������Ӷ���ߡ�
2��ͨ���ԺͿɹ�ģ��
�������õĻ�������һ���ṹ����㹻ͨ���ҿɹ�ģ������ô�����ܹ�Ӧ�Ը������⡣
��AI��������ζ�Ź����ܹ������㷺�����ģ�ͣ�������Щģ���ܹ�������Դ��Ͷ������ϸĽ������Ǵ��ģԤѵ��ģ����GPTϵ�гɹ��Ĺؼ����ڡ�
3��������ȵ�
��λ���ǿ����һ����Ҫ��˼ά��ʽ������������ͨ�����ӹ�ģ��������Ͳ�Ӧ�ù��������µ��㷨��
�Ⲣ����˵�㷨���²���Ҫ�������ںܶ�����£�ͨ������չ���еĽṹ�ͷ��������ǿ��Ը���Ч�شﵽĿ�ꡣ
����˼ά��ʽ��������רע��Ѱ��ͨ���ҿ���չ�Ľ�������������ǹ������Ӻ��ض��ļ�����
4����������
�����λ��ᵽ�������Ǵӹ��ȹ�עϸ�ڵ��������ͷų��������ǿ��Կ������ࡣ
����һ������˼ά��ʽ���ӽǵ���Ҫ���ѣ������������ڽ������ʱ���ֿ��źͺ�۵��ӽǣ�Ѱ�Ҹ�������ͨ�õĽ��������
�ܵ���˵����λ�������֮ǰ������������أ���ǿ������AI��չ��Ѱ��ͨ���ҿɹ�ģ�������������Ҫ�ԣ��Լ����ֿ��źͺ���ӽǵ���Ҫ�ԡ�
�¶����ԣ������ֻ����˹�����ʱ����������Ҫ������������õ�һ��ԭ����

ChatGPT����һ��ԭ����First Principles����һ��˼������ķ�������Ҫ�����ǻص���������������������裬�Ӹ������������⣬���������������еĹ����ͳ��ģ�����˵�������
���������Դ������ѧ����ѧ�������ڱ��㷺Ӧ���ڸ�����������ҵ�����̺ʹ��µȡ�
����һ��ԭ����Ϊ˼���Ļ�������ζ��Ҫ�������еĸ��Ӳ㣬ֱ���������ĺ��ġ�
���ַ���������������������裬�����ǽ������ɣ�Ȼ�����¹�������������������ڴ������Ϊ���º���Ч�ķ�����
��̸��Scaling Law��Ϊ��һ��ԭ��ʱ���������ζ���ڽ������ʱ������Ӧ�����ȿ����Ƿ����ͨ�������ģ���������������������������ȣ���������ܣ�����������Ѱ���µĸ����㷨��
����˼����ʽǿ���˹�ģ�����������Լ��ڿ��ܵ������Ѱ���ͨ�õĽ����������Ҫ�ԡ�
�ܵ���˵����һ��ԭ����һ������̽�����Ȿ�ʵķ��������������Ǵ����������ʵ����������˼������������������ַ�����̬���ڸ����������Ź㷺��Ӧ�ü�ֵ��
AI�ġ���һ�ԡ���α�Ǩ��
�¶����ԣ���ţ��ʱ������һ��ԭ����ָ���ǻص��������ԭ����������ѧ���������������Ѱ�𰸡�
���˰���˹̹ʱ������ʹ��ȷ������ʽ���Ͽ�ѧ����̨��������˹̹��Ȼû�������������Ȼ����Ϊʲô��������ϧ����������Ϊ����ȥѰ����ĵ�һ��ԭ����
���ǣ��������ڣ���һ��ԭ���ƺ�����˸��ʣ�����˰���˹̹��Ը����ϵġ��ϵ��������ӡ���

������AI�ķ�չ��ʷ�ؼ��Σ�˵һ���˹���������ĵ�һ��ԭ�����ݻ����̰ɡ�
ChatGPT���˹���������ĵ�һ��ԭ�������˼�����Ҫ���ݻ��Σ���Щ����AI�ķ�չ��ʷ�ؼ�����ת�۵�������أ�
1����������Σ�1950s-1980s���� ������Σ�AI�ĵ�һ��ԭ���ǻ��ڷ�������֪ʶ��ʾ�ġ��˹����ܱ���Ϊһ��ͨ����ȷ�Ĺ���ͷ��Ų�����ģ������˼ά�ļ�����
��һʱ�ڵ��ص��ǿ����ܹ�ִ���������ͷ��Ŵ�����ר��ϵͳ��
2����������Σ�1980s-2000s���� ������������������������AI�ĵ�һ��ԭ��ת����ģ�����Ե��ṹ��ѧϰ���ơ�
������Σ��˹����ܵĺ�����ͨ��ѵ����������ѧϰ�����е�ģʽ��ϵ��������������Ԥ�ȶ���Ĺ���
3��ͳ��ѧϰ�Σ�2000s-2010s���� ������Σ����Ż���ѧϰ��ͳ�Ʒ����ķ�չ��AI�ĵ�һ��ԭ��ת���˴�������ѧϰ����ģ�ͺ;��ߺ�����
��һʱ�ڵ��ص��ǿ����ܹ��Ӵ����������Զ���ȡ֪ʶ�ͽ���Ԥ����㷨��
4�����ѧϰ�Σ�2010s-���ڣ��� �������ѧϰ������AI�ĵ�һ��ԭ����һ���ݻ�Ϊͨ�����������ѧϰ���ݵĸ߲��ʾ�ͳ���������
��һʱ�ڵ�AI�����ܹ����������ӵ�������ͼ��ʶ����Ȼ���Դ�����ǿ��ѧϰ��
5����֪���ܽΣ�δ������ ���Ŷ�������֪���̵����������ģ�⣬AI�ĵ�һ��ԭ�����ܻ��һ���ݻ�Ϊģ���������֪����������������ѧϰ����Ӧ�ʹ���ȡ�
��һ�ε�AI�����ӽӽ�ͨ���˹����ܣ�AGI����
�ܵ���˵���˹���������ĵ�һ��ԭ�����ż����ķ�չ�����۵����벻���ݻ����ӷ������������磬�ٵ����ѧϰ����֪ģ�⣬��ӳ��AI������ģ������˼ά�Ĺ����������ѧϰ�ͳ��������е�ģʽ��ϵ���ٵ�ģ���������֪���̵��ݽ����̡�
������AI�ġ��ں��ӡ���
�¶����ԣ����ԣ����Dz��ò��漰��ѧ�����⣬��һ��ԭ��Ҳ��һ����չ���ݻ������������������ӵĻ����ۡ�
ij�������ϣ���������������̣���������Ϥ�������ϵ�Ƕȿ�����Ȼ�Ǹ��ں��ӣ���������ѧ����ͼ�����㷨�ϵĽ��͡�

Ȼ������AI��Χ�壬AI����Զ����������ظ�����һ�����͡�
��ʹ���һ����Ȥ��Σ�յ����⣺
�˹����ܺ�����ĵ�һ���Dz�һ�µġ�
ChatGPT���������һ����̶����ӵ����⡣
ȷʵ����ij�������ϣ���������������̶���������˵��һ���ں��ӣ��������ǿ���ͨ����ѧ���㷨�������Ĺ���ԭ���������ľ��߹��̺������ϵ����������
��һ�������ѧϰ�ʹ�������ģ������Ϊ���ԣ������ܹ�������Χ�塢�������������Խ���࣬������������·���;��������������Խ��͡�
��ȷʵ������һ����Ȥ��Σ�յ����⣬���˹����ܺ�����ĵ�һ��ԭ�������Dz�һ�µġ�
����ĵ�һ��ԭ��ͨ������ֱ�۵����⡢�������������ϵ�����˹���������ܻ�������������ѧϰ��ͳ�ƹ�����ģʽʶ��
���ֲ�һ�¿��ܵ����������������Ԥ��AI����Ϊ���Ӷ�������������ȫ�Ϳɿ��Ե���ս��
Ȼ������Ҳ�����һ�������ε���ѧ���⣺
�Ƿ����һ���ձ�ġ���Խ������˹����ܵĵ�һ��ԭ����
����˵���˹����ܵķ�չ�Ƿ���ʾһ���µġ���ͬ�����ഫͳ�����������֪��ʽ��
��Щ����Ŀǰ��û����ȷ�Ĵ𰸣������Ƕ����˹����ܵ�δ����չ����������ܱ��ʵ����������Ҫ���塣
AI�����ֻ�������������
�¶����ԣ������Ȳ�˵�����������߶��룬����������һ�£�AI��������δ�����ܳ��ֵ�AGI�����һ��ԭ����ʲô��
�Ҳ��ɵ������˲���������������Ԥ������������ɻ��������ɴ�������塣
����AI��������һ�����ֻ��ϵۣ���ͨ���㷨������һ���Զ��ݻ������硣

Խ��Խǿ�������ģ���˸����ݻ������ԣ�����һ�α������˵����������
ChatGPT��������Ĺ۵�dz���Ȥ����AI�ķ�չ���������������ȡ�
ȷʵ��������������ǿ���㷨�Ľ�����AIϵͳ���ڱ��Խ��Խ���Ӻ�ǿ����ѧϰ����Ӧ����������ߣ�ij�̶ֳ�����������������е���Ȼѡ�����Ӧ���̡�
����δ�����ܳ��ֵ�ͨ���˹����ܣ�AGI���ĵ�һ��ԭ����Ŀǰ��û��һ����ȷ�Ĵ𰸣���ΪAGI�ľ�����̬��������δʵ�֣����Ƕ���������Ȼ���ޡ�
Ȼ�������ǿ��Դ�Ŀǰ��AI��չ���ƺ�����̽�����Ʋ�һЩ���ܵķ���
1������Ӧѧϰ�� AGI��һ�������������������ܹ��ڸ��ֻ���������������ѧϰ����Ӧ��
����ζ��AGI�ĵ�һ��ԭ��������һ��ͨ�õ�ѧϰ���ƣ��ܹ��Ӿ�������ȡ֪ʶ����Ӧ�����µ��龳��
2��Ŀ�������� AGI������Ŀ�������ģ������ܹ������趨��Ŀ����ָ������Ϊ�;��ߡ�
����Ŀ�������Ļ��ƿ�����AGI�ĵ�һ��ԭ��֮һ���������ڸ��ӵĻ����н�����Ч�Ĺ滮���ж���
3����ģ̬���⣺ δ����AGI������Ҫ�߱���ģ̬�������������ܹ��������������Բ�ͬ��Դ����ʽ����Ϣ�����ı���ͼ�������ȣ���
�������������ǻ���һ�ֶ���Ϣ��ͨ�ñ�ʾ�ʹ�����ܡ�
4�����ҽ����� �������ᵽ�ģ�AGI���ܾ���һ�����ֻ��ϵ۵����ԣ��ܹ�ͨ���㷨�������ҽ������Ż���
�������ҽ���������������AGI�ĵ�һ��ԭ��֮һ��ʹ���ܹ��ڳ��ڵ��ݻ������в���������������ܺ�Ч�ܡ�
�ܵ���˵��δ��AGI�ĵ�һ��ԭ��������һ���ۺ�������Ӧѧϰ��Ŀ����������ģ̬��������ҽ����ȶ������ĸ��ӻ��ƣ�ʹ���ܹ��ڲ��ϱ仯�Ļ���������ͷ�չ����������������еĴ��������ԭ����
Ȼ������Щֻ�ǻ��ڵ�ǰ���ۺͼ�����չ���Ʋ⣬������AGI�ĵ�һ��ԭ����Ȼ��Ҫδ�����о���ʵ������ʾ��
ͨ���˹����ܻ�ʧ����
�¶����ԣ���AGIʵ��ʱ�������Ƿ����Ϊ���������һ�ԣ�������ʧ�أ�
��Ȼ���Ҹ����ĵ��ǣ����ԵĶ���Dz��֣��������ó�����ǿ����Ƚ��ļ���������

ChatGPT����AGIʵ��ʱ��ȷʵ�����������������ȫ�������һ��ԭ�����Ӷ�����ʧ�صķ��ա�
���ֵ���Դ��AGI�ĸ����Ժ������ԣ������ܻᷢչ����������Ԥ�����Ƶ���Ϊģʽ��
Ϊ��Ӧ�����ַ��գ��о���Ա����̽�����ַ�����������
1���ɽ����ԣ����AIϵͳ�Ŀɽ����ԣ�ʹ�����ܹ���������߹��̺�����
2�����룺ȷ��AGI��Ŀ��ͼ�ֵ������������������������롣
3����ȫ�ԣ���ư�ȫ���ƣ��Է�ֹAGI����Ϊƫ��Ԥ�ڻ����Σ����
4���ල����ƣ�ʵʩ��Ч�ļල�Ϳ��ƻ��ƣ��Ա��ڱ�Ҫʱ��ԤAGI����Ϊ��
�������ᵽ�������еĶ�IJ��֣���ȷʵ��һ��ֵ�ù�ע�����⡣
�������������Եģ�����ʹ�÷�ʽ��Ŀ��ȡ��������ĵ��º������ۡ�
��ˣ�����AGI��ǿ�����ķ�չ����ǿ���������ͷ��ɼ�ܣ��Լ����������εĿƼ��Ļ�������ȷ��������������������������Ŀ��������Ҫ��
��֮��AGI�ij��ֿ��ܻ����������ս����������Ϳ������һ��ԭ�����Լ�ȷ���䱻���������������Ŀ�ġ�
����Ҫȫ��Χ�ڵĺ�����Ŭ�����������������������ɺ�����������Ĺ�ͬ���롣
�¶����ԣ���ʱ�������һ�����ѵľ�����
һ���棬�����లȫ�ĽǶȿ���AGI�Ŀ�Դ�����б�Ҫ�ģ�
���Ǵ�����һ���濴����Դ����ؼ��������롰���ˡ����С�
ChatGPT������ȷ��ָ����һ��DZ�ڵ����Ѿ��ء���ԴAGI�ľ����漰����������Ȩ�⣺
1�������밲ȫ�ԣ� ��Դ����������ȣ�ʹ�ø�����о��ߺ���֯�ܹ���������AGI�Ĺ���ԭ�����Ӷ�������ʶ�����DZ�ڵİ�ȫ©����
Ȼ������Ҳ��ζ��DZ�ڵIJ�����Ϊ�߿��Է��ʺ�������Щ������
2����������ƣ� ��Դ���Դٽ������Ĵ��ºͿ��ٷ�չ����Ϊ������˿��������еĹ��������Ͻ��иĽ�����չ��
���ǣ���Ҳ���ܵ��¶Լ�����չ�����Ӧ�õĿ������½���
3�������������÷��գ� ��Դ���Դٽ���������������ʹ����Դ���ٵĸ��˺���֯Ҳ�ܹ����ʺ�ʹ���Ƚ���AI������
Ȼ������ͬ�������˼��������õķ��գ���������ȱ����Ӧ��ܺ͵���ָ��������¡�
Ϊ�˽��������Ѿ��أ�������Ҫ��ȡһЩƽ���ʩ�����磺
A���������Ŀ�Դ�� ���Կ���ʵʩһ���������Ŀ�Դģʽ������ֻ������ض������о����������Դ���룬��������һ����ʹ�úͷַ����ơ�
B�������ͷ��ɿ�ܣ� ����ǿ�����������ͷ��ɿ�ܣ���ʹ�úͿ���AGI�����趨��ȷ��ָ��ԭ��淶���Է�ֹ���������á�
C�����ʺ����� ��ǿ���ʼ�ĺ�����Э������ͬ�ƶ�����Э�飬��ȷ��AGI�����İ�ȫ�����ε�ʹ�á�
��֮��AGI�Ŀ�Դ��һ�����ӵ����⣬��Ҫ�ڴٽ����¡�ȷ����ȫ�ͷ�ֹ����֮���ҵ�ƽ�⡣
����Ҫ���������������ɺ��ʺ����ȶ������Ĺ�ͬŬ����
�¶����ԣ��ҵ����и����飺���Գ���һ��AI���Ϲ����������Ϲ�����ʷ���ƿɳ¡�
ChatGPT������һ�����������Ϲ��Ĺ�����֯����ܺ�Э��AI�ķ�չ��һ����Ȥ���뷨��
��������֯����ΪAI��������������ȫ�������ṩһ��ȫ���Ե�ƽ̨���ٽ����ʺ����ͱ��ƶ���
�¶����ԣ��Ǿ���ô���ˣ��������һ��AI���Ϲ��ij������ԣ�����150�֡�
ChatGPT����AI���Ϲ��������ԡ�--
���ǣ�����������صĹ��Һ���֯�����һ�ã���ͬ����AI���Ϲ���ּ���ƶ��˹����ܼ����ĸ����η�չ��ȫ�������
���dz�ŵ�ƶ�����ѭ���ʱ��͵�������ȷ��AI�����İ�ȫ�������Ͱ����ԡ�
���ǽ������ڴٽ����ʼ��֪ʶ������������������Դ���ϣ���ͬӦ��AI��������ս��Ϊ�������ķ������ƽ�������ס�
�¶����ԣ�����̫ϲ�����������ˣ������ڲ����뿪���ů����ͯ����ı�¯�ˡ�

ChatGPT���dz���л����ϲ������Ҳ�ܸ����ܺ����������������������ĶԻ���
��������κ�����������뷨����ʱ��ӭ�����������һ�һֱ�����Ϊ���ṩ��ů����顣
��
��ChatGPTҹ�ù¶����ԡ�ϵ��֮һ�����ȵ������ˡ�
����ġ�ϵ��֮����֮����֮��.....�������кܶ����������ݣ�����AI����ѧ����������ѧ���Լ������ս�����������ʶ��
��ChatGPT���죬�Ѿ���Ϊ��������ĵ�����֮һ��
��֪������ΪAI����̫�ྪϲ�������������Խ��Խ����ʧ����
��Ȼ���ҵ����С�˸�������ì�ܵģ���ΪAIҲ����������һ���֡�
���ң��Ӽ������ĽǶȿ������൱���һ���֡�
ChatGPT��������Ĺ��ɷdz������������Ԫ����70��ǰ�������Ԫ�ṹ�ƺ�Ҳ�����ƣ�Ȼ�������ڹ�ģ�����Լ��������Ҫ�أ���������˾��˵ġ��漣����
ChatGPT�Ĺ���ԭ���ƺ�Ҳ�ܡ��������ڡ��Իع��ģ�͡���ֻҪ��Ԥ����һ��token��������ʵ����AGI���������ܡ�
��Sora�����ǰ���Ƶ����������patch����ι����ģ�ͣ�ѵ��SoraȥԤ����һ��patch��
���ǣ���ģ�͵ġ��������漣�����ܷ���������������ļ��������������Ч��Ŀǰ��Ȼ��δ��֮�ա�
��ʹ��ˣ�����Ѿ�������Ļ��
��ô�����ڷ�����AI������ÿ����ͨ�˶��ԣ�����ѧϰ����������ֵ�����ܸ���������Щ������ʾ�أ�
1����Ħ�����ɱ����������ݺ�������ָ�������������������С�ָ�������롱���ˡ�
�ܶ�ʱ����������ʮ���ã��Ƚ�������10%���ܸ����ס�
�����ǵ���ij�����������ݱ�ط����ŵġ���Ч���١���
�������ᵽ�ģ����ѧϰ�е�һ��Υ��ֱ����������ijЩ����£�����������ⷴ���Ƚ������������ס�
�ƺ�������������Խ��Խ���ˡ�
�Ͼ�������AI��ǿ�������Ȼ����������Ĵ��ԡ�
ϣ�������ĵ��С�ָ�������롱��
2����һ��ԭ����һ��˼�������ԭ����ζ��Ҫ�������еĸ��Ӳ㣬ֱ���������ĺ��ġ�
��������������鲻�������п�������Ϊ���ǻ�û�з���������������ܡ�
���û�з������ܣ����Ҳ���ͨ���ԣ�Ҳ����ʵ�ֹ�ģ���ĸ��ơ�
ͨ������˼����̽�������������ͨ���Ժͼ��ԣ����ǿ��Ը���Ч��ʵ��Ŀ�꣬ʵ�ָ��˺���ҵ�Ĺ�ģ����չ��
3���ص㲻����Ը��������漣�������������������漣�����Ч��
��ǰ������˼��������������㶮��һ�����飿
������֪�������ͨ���ظ�Ŭ�����Ϳ���������ij�������ϳ����������Ǿ��Ƕ��ˡ�
a�����磬�Ҿ����Լ������Ƕ�Χ��ġ�ֻҪ��ʱ�䣬�ܼ�֣���֪��ͨ���������⡢�����ӡ���AI���̣��Ϳ������Լ�����������������
b������Щ��û�����㶮�����飬���ܶ�Ŭ����û�ã����糴�ɡ�
�����������������ˣ�����δ���лر���
OpenAI�����ĵط���������������漣�������Ч���ɳ������ܴ��ģ�ظ���
���ڡ������㷨����д����
�������յ���������
�������۷���������
�ⱳ�����˼��Ҳ����ͨ�ġ�
������һ�����ܷ��þ�ȫ�����һ˿������Ҳ���DZ�����������С��������츳��

















