����ǰ OpenAI Sora ���侪�˵���Ƶ����Ч��Ѹ���ߺ죬��һ��������Ƶģ����ͻ����Χ����Ϊȫ����Ŀ�Ľ��㡣�� 2 ��ǰ�Ƴ��ɱ�ֱ�� 46% �� Sora ѵ�������������̺�Colossal-AI �Ŷ�ȫ�濪Դȫ������ Sora �ܹ���Ƶ����ģ�� ��Open-Sora 1.0��������������ѵ�����̣��������ݴ���������ѵ��ϸ�ں�ģ��Ȩ�أ�Я��ȫ�� AI �Ȱ��߹�ͬ�ƽ���Ƶ�������¼�Ԫ��
�ȶ�Ϊ�죬�����ȿ�һ���� Colossal-AI �Ŷӷ����ġ�Open-Sora 1.0��ģ�����ɵĶ��з�����Ӱ��Ƶ��

Open-Sora 1.0 ���ɵĶ��з�����Ӱ
������� Sora ���ּ�����ɽ��һ�ǣ���������������Ƶ��ģ�ͼܹ���ѵ���õ�ģ��Ȩ�ء����ֵ�����ѵ��ϸ�ڡ�����Ԥ�������̡�demo չʾ����ϸ�����ֽ̳̣�Colossal-AI �Ŷ��Ѿ�ȫ����ѿ�Դ�� GitHub��ͬʱ���ߵ�һʱ����ϵ�˸��Ŷӣ��˽���ǽ����ϸ��� Open-Sora ����ؽ�����������¶�̬������Ȥ�����ѿ��Գ�����ע Open-Sora �Ŀ�Դ������
Open-Sora ��Դ��ַ��https://github.com/hpcaitech/Open-Sora
ȫ���� Sora ���ַ���
�����������ǽ������� Sora ���ַ����Ķ���ؼ�ά�ȣ�����ģ�ͼܹ���ơ�ѵ�����ַ���������Ԥ������ģ������Ч��չʾ�Լ���Чѵ���Ż����ԡ�
ģ�ͼܹ����
ģ�Ͳ�����Ŀǰ���ȵ� Diffusion Transformer��DiT��[1] �ܹ��������Ŷ���ͬ��ʹ�� DiT �ܹ��ĸ�������Դ����ͼģ�� PixArt-�� [2] Ϊ�������ڴ˻���������ʱ��ע�����㣬������չ������Ƶ�����ϡ�������˵�������ܹ�����һ��Ԥѵ���õ� VAE��һ���ı�����������һ�����ÿռ� - ʱ��ע�������Ƶ� STDiT��Spatial Temporal Diffusion Transformer��ģ�͡����У�STDiT ÿ��Ľṹ����ͼ��ʾ�������ô��еķ�ʽ�ڶ�ά�Ŀռ�ע����ģ���ϵ���һά��ʱ��ע����ģ�飬���ڽ�ģʱ���ϵ����ʱ��ע����ģ��֮����ע����ģ�����ڶ����ı������⡣��ȫע����������ȣ������Ľṹ�����ѵ����������������ͬ��ʹ�ÿռ� - ʱ��ע�������Ƶ� Latte [3] ģ����ȣ�STDiT ���Ը��õ������Ѿ�Ԥѵ���õ�ͼ�� DiT ��Ȩ�أ��Ӷ�����Ƶ�����ϼ���ѵ����
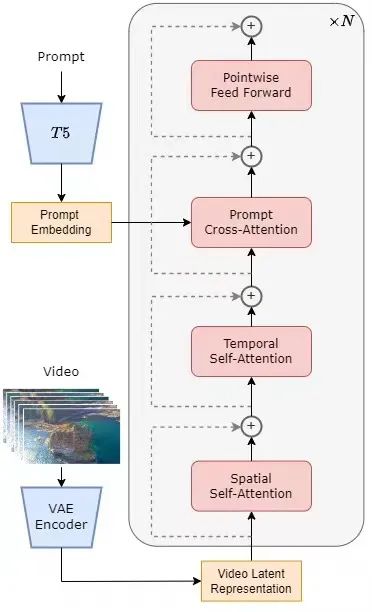
STDiT �ṹʾ��ͼ
����ģ�͵�ѵ���������������¡����˽⣬��ѵ�������Ȳ���Ԥѵ���õ� Variational Autoencoder��VAE���ı���������Ƶ���ݽ���ѹ����Ȼ����ѹ��֮���DZ�ڿռ������ı�Ƕ�루text embedding��һ��ѵ�� STDiT ��ɢģ�͡��������Σ��� VAE ��DZ�ڿռ������������һ����˹����������ʾ��Ƕ�루prompt embedding��һ�����뵽 STDiT �У��õ�ȥ��֮���������������뵽 VAE �Ľ�����������õ���Ƶ��

ģ�͵�ѵ������
ѵ�����ַ���
��������Ŷ��˽��Open-Sora �ĸ��ַ����ο��� Stable Video Diffusion��SVD��[3] �����������������Σ��ֱ��ǣ�
1�����ģͼ��Ԥѵ����
2�����ģ��ƵԤѵ����
3����������Ƶ��������
ÿ���ζ������ǰһ���ε�Ȩ�ؼ���ѵ��������ڴ��㿪ʼ����ѵ�������ѵ��ͨ������չ���ݣ�����Ч�ش�ɸ�������Ƶ���ɵ�Ŀ�ꡣ

ѵ����������
��һ�Σ����ģͼ��Ԥѵ��
��һ��ͨ�����ģͼ��Ԥѵ�����������������ͼģ�ͣ���Ч������ƵԤѵ���ɱ���
�����Ŷ�������¶��ͨ���������Ϸḻ�Ĵ��ģͼ�����ݺ��Ƚ�������ͼ���������ǿ���ѵ��һ��������������ͼģ�ͣ���ģ�ͽ���Ϊ��һ����ƵԤѵ���ij�ʼ��Ȩ�ء�ͬʱ������Ŀǰû�и�������ʱ�� VAE�����Dz����� Stable Diffusion [5] ģ��Ԥѵ���õ�ͼ�� VAE���ò��Բ��������˳�ʼģ�͵���Խ���ܣ���������������ƵԤѵ��������ɱ���
�ڶ��Σ����ģ��ƵԤѵ��
�ڶ���ִ�д��ģ��ƵԤѵ��������ģ�ͷ�����������Ч������Ƶ��ʱ�����й�����
�����˽���������Ҫʹ�ô�����Ƶ����ѵ������֤��Ƶ��ĵĶ����ԣ��Ӷ�����ģ�͵ķ����������ڶ��ε�ģ���ڵ�һ������ͼģ�͵Ļ����ϼ�����ʱ��ע����ģ�飬����ѧϰ��Ƶ�е�ʱ���ϵ������ģ�����һ�α���һ�£������ص�һ��Ȩ����Ϊ��ʼ����ͬʱ��ʼ��ʱ��ע����ģ�����Ϊ�㣬�Դﵽ����Ч�����ٵ�������Colossal-AI �Ŷ�ʹ���� PixArt-alpha [2] �Ŀ�ԴȨ����Ϊ�ڶ��� STDiT ģ�͵ij�ʼ�����Լ������� T5 [6] ģ����Ϊ�ı���������ͬʱ���Dz����� 256x256 ��С�ֱ��ʽ���Ԥѵ������һ�������������ٶȣ�����ѵ���ɱ���
�����Σ���������Ƶ������
�����ζԸ�������Ƶ���ݽ�����������������Ƶ���ɵ�������
�����Ŷ��ἰ�������õ�����Ƶ���ݹ�ģ�ȵڶ���Ҫ��һ��������������Ƶ��ʱ�����ֱ��ʺ����������ߡ�ͨ�����ַ�ʽ������������ʵ������Ƶ���ɴӶ̵������ӵͷֱ��ʵ��߷ֱ��ʡ��ӵͱ���ȵ��߱���ȵĸ�Ч��չ��
�����Ŷӱ�ʾ���� Open-Sora �ĸ��������У�����ʹ���� 64 �� H800 ����ѵ�����ڶ��ε�ѵ����һ���� 2808 GPU hours��Լ�� 7000 ��Ԫ�������ε�ѵ������ 1920 GPU hours����Լ 4500 ��Ԫ�������������㣬����ѵ�������ɹ��� Open-Sora �������̿������� 1 ����Ԫ���ҡ�
����Ԥ����
Ϊ�˽�һ������ Sora ���ֵ��ż����Ӷȣ�Colossal-AI �Ŷ��ڴ���ֿ��л��ṩ�˱�ݵ���Ƶ����Ԥ�����ű����ô�ҿ����������� Sora ����Ԥѵ��������������Ƶ���ݼ����أ�����Ƶ���ݾ�ͷ�����Էָ�Ϊ����ƵƬ�Σ�ʹ�ÿ�Դ������ģ�� LLaVA [7] ���ɾ�ϸ����ʾ�ʡ������Ŷ��ᵽ�����ṩ��������Ƶ�������ɴ������������ 3 ���עһ����Ƶ�����������ӽ��� GPT-4V�����յõ�����Ƶ / �ı��Կ�ֱ������ѵ�������������� GitHub ���ṩ�Ŀ�Դ���룬���ǿ������ɵ����Լ������ݼ��Ͽ�������ѵ���������Ƶ / �ı��ԣ��������������� Sora ������Ŀ�ļ����ż���ǰ������

��������Ԥ�����ű��Զ����ɵ���Ƶ / �ı���
ģ������Ч��չʾ
������������һ�� Open-Sora ʵ����Ƶ����Ч���������� Open-Sora ����һ�������º����ߣ���ˮ�Ĵ�����ʯ�ĺ��Ļ��档

���� Open-Sora ȥ��ɽ���ٲ������������ȶ��£����ջ�������ĺ�ΰ����档

�������컹���뺣�������� prompt���� Open-Sora ������һ��ˮ������ľ�ͷ����ͷ��һֻ������ɺ��������Ȼ��߮��

Open-Sora ����ͨ����ʱ��Ӱ���ַ���������չ���˷�����˸�����ӡ�

����㻹�и�����Ƶ���ɵ���Ȥ�뷨�����Է��� Open-Sora ��Դ������ȡģ��Ȩ�ؽ�����ѵ����顣���ӣ�https://github.com/hpcaitech/Open-Sora
ֵ��ע����ǣ������Ŷ��� Github ���ᵽĿǰ�汾��ʹ���� 400K ��ѵ�����ݣ�ģ�͵�������������ѭ�ı����������д�������������������ڹ���Ƶ�У����ɵ��ڹ����һֻ�š�Open-Sora 1.0 Ҳ�����ó�����������ӻ��档�����Ŷ��� Github ���о���һϵ�д����滮��ּ�ڲ��Ͻ������ȱ�ݣ���������������
��Чѵ���ӳ�
���˴������ Sora ���ֵļ����ż���������Ƶ������ʱ�����ֱ��ʡ����ݵȶ��ά�ȵ������������Ŷӻ��ṩ�� Colossal-AI ����ϵͳ���� Sora ���ֵĸ�Чѵ���ӳ֡�ͨ�������Ż��ͻ�ϲ��еȸ�Чѵ�����ԣ��ڴ��� 64 ֡��512x512 �ֱ�����Ƶ��ѵ���У�ʵ���� 1.55 ���ļ���Ч����ͬʱ�������� Colossal-AI ���칹�ڴ����ϵͳ���ڵ�̨�������ϣ�8*H800���������谭�ؽ��� 1 ���ӵ� 1080p ������Ƶѵ������

���⣬�������Ŷӵı����У�����Ҳ���� STDiT ģ�ͼܹ���ѵ��ʱҲչ�ֳ�Խ�ĸ�Ч�ԡ��Ͳ���ȫע�������Ƶ� DiT ��ȣ�����֡�������ӣ�STDiT ʵ���˸ߴ� 5 ���ļ���Ч�������ڴ�������Ƶ���е���ʵ��������Ϊ�ؼ���

��ӭ������ע Open-Sora ��Դ��Ŀ��https://github.com/hpcaitech/Open-Sora
�����Ŷӱ�ʾ�����ǽ������ά�����Ż� Open-Sora ��Ŀ��Ԥ�ƽ�ʹ�ø������Ƶѵ�����ݣ������ɸ�������������ʱ������Ƶ���ݣ���֧�ֶ�ֱ������ԣ���ʵ�ƽ� AI �����ڵ�Ӱ����Ϸ�������������ء�
�ο����ӣ�
[1] https://arxiv.org/abs/2212.09748 Scalable Diffusion Models with Transformers
[2] https://arxiv.org/abs/2310.00426 PixArt-����Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
[3] https://arxiv.org/abs/2311.15127 Stable Video Diffusion��Scaling Latent Video Diffusion Models to Large Datasets
[4] https://arxiv.org/abs/2401.03048 Latte��Latent Diffusion Transformer for Video Generation
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original
[6] https://github.com/google-research/text-to-text-transfer-transformer
[7] https://github.com/haotian-liu/LLaVA
[8] https://hpc-ai.com/blog/open-sora-v1.0

















