1 ����
�����������������ģ�ͣ��ر�����ɢģ�ͣ�Diffusion model������θ�������������������������ɢģ�������ɱ�������������ʾ����DZ�����˷��˱���Ա������еĺ�ֲ������ϰ������������ɶԿ������еĶԿ���Ŀ�겻�ȶ��ԡ�
��ɢģ�Ͱ�����������ӵĹ��̣�һ�������ݷֲ�ӳ�䵽������ֲ���ǰ����̺�һ����Ӧ�ķ�����̡�ǰ����������ھ���ʱ��ϵ���ļ����˶���������ͨ��ʹ��ȥ������ƥ��Ŀ����ѵ�����Ƶ÷ֺ�����
Ȼ������ɢģ����GANs��VAEs��ȣ���������̱�������Ҫ����ʱ�ĵ������̡���������ͨ������ODE/SDE�������Ʒ���̽�����ֲ�ת��Ϊ�������ݷֲ��ĵ���ת�����̣�����Ҫ��������н��д����ĺ���������
Ϊ��Ӧ����Щ��ս���о���Ա����˸��ֽ�����������磬������Ƚ���ODE/SDE����������ٲ������̣�ͬʱ������ģ�ʹ��ڲ�����ʵ����һĿ�ꡣ���⣬������������ǰ���������ǿ�����ȶ��Ի�ٽ�ά�Ƚ��͡����⣬��������һϵ���о�������������ɢģ����Ч����������ֲ���Ϊ���ṩһ��ϵͳ�Եĸ��������ǽ���Щ��չ��Ϊ�ĸ���Ҫ���������١���ɢ������ơ���Ȼ�Ż������ӷֲ������⣬��������ȫ�濼����ɢģ���ڲ�ͬ�����еĸ���Ӧ�ã�����������Ӿ�����Ȼ���Դ�����ҽ�Ʊ����ȡ�
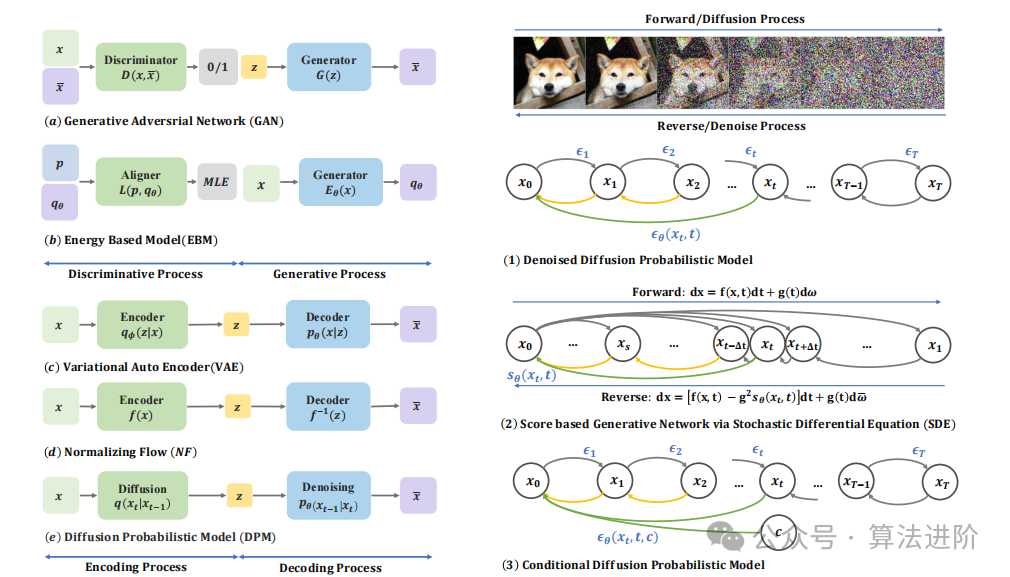
ͼ1 ��ɢģ��������������ģ�͵ļ�顣GAN��EBM����ʹ���������������ݷֲ���ͨ����ѵ�������в�����������ʵ�ֲ���У�����Ʒֲ������ֲ��Ĺ����Լ�������Dz�ͬ�ġ�VAE��NF��DPMͨ��������̽���ʵ�ֲ�ֱ��ͶӰ��Ԥ����ķֲ��С�ͨ������Ԥ����ķֲ������������ʵ��������Ӧ�ò�ͬ��Ԥ����ֲ�z�ͱ���ͽ�����̡����ң���ɢģ�͵ļ�����һ�������ѭ���Ͻ�ͼ��ʾ�����ݷֲ�����ɢ�������˹�����У���ͨ��ȥ����������ɢ����1��DDPM����2.2.1�ڣ�ʵ��������ɢʱ���ߵķֲ���ɢ��ȥ����̡���2��SDE����2.2.2�ڣ���������ʱ���ߣ�ͨ�����ڹ��ܵ�����ַ��̣�SDE��ʵ��״̬֮��ķ��롣��3��CDPM����2.3�ڣ���DPM��ÿ�����������в������� 𝑐 ����ʵ�ֿɿ��Ƶ����ɡ�
2 ������
2.1 ����Ͷ���
2.1.1 ʱ���״̬
����ɢģ���У�������ʱ������չ����ʱ�����������������ɢ��ģ�͵�״̬��ʾ���ݷֲ�����ʼ�ֲ�����������Ϊ����״̬������״̬�ǴӸ�˹�ֲ��в�������ʼ״̬������״̬Ϊ�м�״̬����״̬���й����ı�Ե�ֲ�����ˣ���ɢģ���ܹ�ģ�����ݷֲ���ʱ��ı仯�����ɽӽ�����״̬����������չ��һϵ���м�״̬�����У�ÿ��״̬��Ӧ��ɢ�����е�ʱ��㡣
2.1.2 ǰ��/������̣��Լ������ں�
��ɢģ����һ������ģ�ͣ���ͨ���������𝐹����ʼ״̬ת��Ϊ�����˹�������������𝑅��ʹ��ת�ƺ˽�����״̬���벢���ص���ʼ״̬����ɢ���Ϊ������ɢ�����ṩ����ɢʱ����ƣ�����ʵ��ʵʩ����Ч���㡣��ɢģ���ṩ�˸��㷺�����ɿռ�Ϳɿ��Ƶ����ɣ������Ľ��ֲ���ʵ����Ŀ��ֲ����п����ƶ���
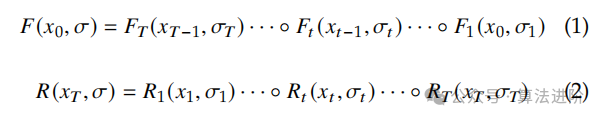
2.1.3 ����ɢ������
���Ŷ����㹻Сʱ�����Խ���ɢ���̣�ʽ��1����ʽ��2�����ƹ㵽�������̡���ɢ�����ɷ�������ɢģ�Ϳ���������������ַ��̣�SDE����ܣ��������ɹ�����ת�̶�������ɢ���̡��뷴��SDE�ȼ۵�Ԥ��ODE��Ҳ�ѱ��Ƶ��������������̾��и��õ�����֧�֣���Ϊ��ODE/SDE�����е����м���Ӧ������ɢģ�ʹ��˴��š�
2.2 ����
���ڽ��������ֻ�����ʽ��������ȥ����ɢ����ģ�͡�����SDE��ʽ��������ɢ����ģ�͡�
2.2.1 ȥ����ɢ����ģ�ͣ�DDPM��
DDPM��һ������ģ�ͣ�ͨ���Ӹ�˹�����лָ����������������ݡ���ģ��ͨ������ǰ��ͷ�������Լ�ת�ƺˣ�����ɢ�����ƹ㵽�������̡�DDPMģ�Ϳ���ͨ��ѡ��ͬ��ǰ���������ɸ��������������������ɹ����У�DDPMģ��ͨ�������Ӹ�˹����������ת��Ϊ��˹�ֲ���Ȼ��ͨ�����������ȥ�����������������µ����ݡ�
2.2.2 ����SDE��ʽ
����SDE��DDPM�е���ɢʱ�䷽����չ����������ַ��̵�����ʱ�����У�������ODE��ʽ������˸��ӵ�ȷ���Բ�����ܡ���ǰSDE��������ɢ���̺�����ַ�����ϵ���������������It��SDE�Ľ���������ý������ھ�ֵƯ�Ƶ�Ư��������ڶ��������İ����������˶���ɡ������������ǰ���̣����ֲ��죨VP���Ͳ��챬ը��VE��SDE����ɢģ�͵ij�����ͨ��������̵���Ӧ����ʱ��SDE���еġ�������ODE֧����SDE������ͬ��Ե�����ܶȵ�ȷ���Թ��̣��κ����͵���ɢ���̶�����ת��ΪODE��һ��������ʽ����SDE��ͬ��������ODE�����Ը���IJ���������⣬��Ϊ����û������ԡ�
2.3 ������ɢ����ģ��
��ɢģ����һ��ͨ�õ�����ģ�ͣ����Դ��������ֲ��������ֲ����������������÷�������ѵ���������������������ֲ����㷨�������ලѧϰ�㷨�ͼලѧϰ�㷨������������������ɡ�����ǩ��������ʹ�ô���ǩ����������ÿ������������ݶȣ�ͨ����Ҫһ������UNet�������ܹ��Ķ����������Ϊ�ض���ǩ���������ݶȡ��ޱ�ǩ��������ʹ��������Ϣ��Ϊָ����ͨ�������Ҽල�ķ�ʽӦ�ã�����ȥ�롢��ɫ��ͼ���������
3 �㷨�Ľ�
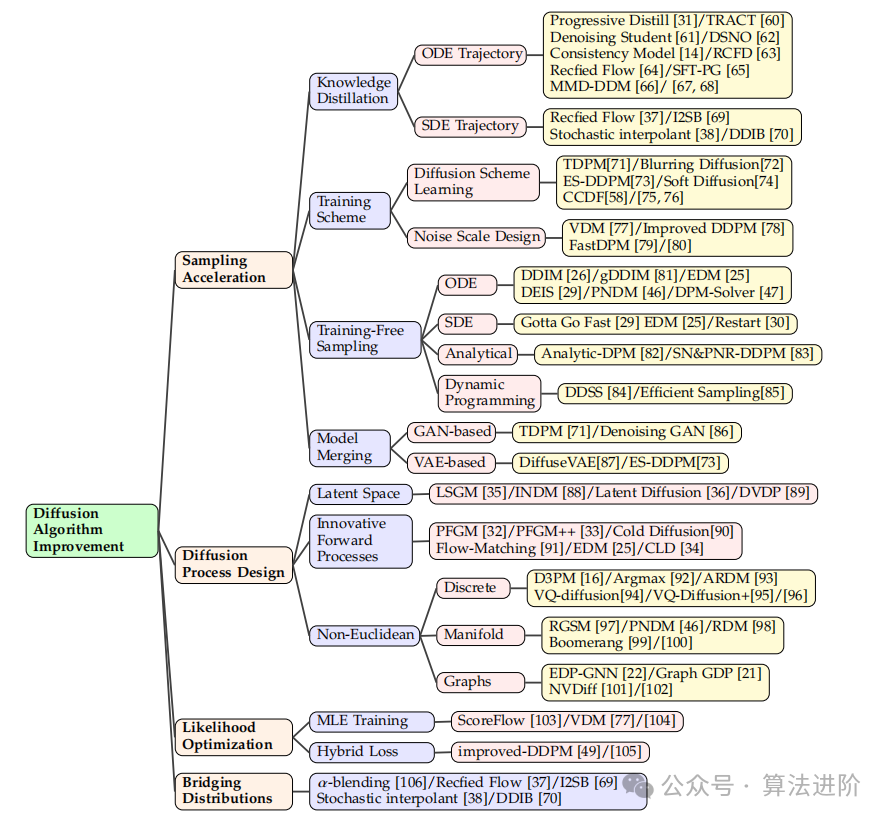
��ɢģ�����������ɷ�����ֳ�ɫ������ʵ��Ӧ�������иĽ��ռ䡣��GANs��VAEs��ȣ���ɢģ����Ҫ�����ĵ����������̣���ǰ������ڸ�ά���ؿռ����С����Ľ�����������ǿ��ɢģ�͵����·�չ����1���������ټ��������ڼӿ����ODE/SDEģ�⣻��2���µ�ǰ����̣����ڸĽ����ؿռ��еIJ����˶�����3����Ȼ�Ż�������������ǿ��ɢODE��Ȼ����4�������ֲ�������������ɢģ���������ͬ�ķֲ�������������Щ���������������ɢģ�͵����ܺ�Ч�ʡ�
3.1 ��������
������ɢģ�;��и߱�������ɵ�����������ʵ��Ӧ����������������IJ����ٶȡ������ּ�Ҫ������������߲����ٶȵ��Ƚ�����������ѵ���ƻ��Ż�����ѵ�������Լ��ϲ���ɢ����������ģ�͡�
3.1.1 ֪ʶ����
֪ʶ�����ǽ�֪ʶ�Ӵ���ģ��ת�Ƶ�С��ģ�͵ļ�����ּ��ʹ�ý��ٲ�����С������������������С��ԭʼ��������������֮��IJ��졣��Ϊ���á��ɿغͼ��������ṩ������ӳ�䡣ʹ��ODE��ʾ����֪ʶ����ӽ�ʦģ�͵�ѧ��ģ�͵�ODE�켣�����ڽ�����ֲ�ӳ�䵽Ŀ��ֲ�����Ч·����һЩ������Ӧ���������ɢģ�͵����ܣ����罥������������켣��ÿ������DZ��ӳ��������Ρ��������ͨ����С���ֲ�֮�������ɱ�ʵ����ѹ켣��ReFlow��DSNOͨ��һ�����ɺ�����������ֱ��ʱ��·����ģʵ����ѹ켣��Ȼ����SDE�켣��������켣�Ծ�����ս�ԣ�Ŀǰ����Ĺ������١�
3.1.2 ѵ���ƻ��Ż�
ѵ���ƻ��Ż������Ĵ�ͳ�Ķ����ڲ�����ѵ�����ã�����ɢ���������������ȴ�ͳѵ�����á�ѵ����ǿ���ܷ�Ϊ������Ҫ������ɢ����ѧϰ�������߶���ơ���ɢ����ѧϰ����������Ż���ͶӰ��������CCDF��Franzese���ˡ�TDPM��ESDDPM������ɢ��ģ����ɢģ�͵ȡ������߶���ư�����ǰ������ƺͷ���������ƣ���ǰ������Ʒ����������߶Ȳ�����Ϊ����ȣ�������ѵ����ʧ��ģ��������ϵ�����������������ͨ��ѵ�������ʧ����ʽ��ѧϰ���������߶ȣ���ͨ������Ԥ�����������Ȳ���֮ǰ���·��������߶ȣ���VDM��FastDPM���Ľ���DDPM��San Roman���˵ȡ�
3.1.3 ��ѵ������
�ලѧϰ���������Ƚ��IJ���������Ԥѵ����ɢģ�͵IJ������̣���������ѵ��ģ�͡��������Ϊ�������棺��ɢODE��SDE�������ļ��١����������Ͷ�̬�滮��ODE�����У�DDIM���Ա���Ϊ������ODE�������Ĺ�����DDIM����ΪӦ��Э�������ɢ�ij��ַ��̣�ODE���ϵ�ָ���������ij˻���SDE�����У�Gotta Go Fast ʹ������Ӧ�������и���SDE������EDM�����߽�ODE��������Langevin����ѧ�е��������Ӻ�ȥ�����ϡ����������У����е��ල������������Э����߶���Ϊһ���ֹ��������������У���û�п������Ƕ�̬�ء���̬�滮�����У���̬�滮��DP��ͨ��ʹ�ü��似��ʵ������ѡ��ı��������ڸ��̵�ʱ�����ҵ��Ż����������
3.1.4 �ϲ���ɢ����������ģ��
��ɢģ�Ϳ�������������ģ�ͣ������ɶԿ����磨GAN�������Ա�������VAE����Эͬ�������Լ������̡����磬����ͨ������ɢ�������̵��м�λ�õĴ���������������ֱ��ͨ��VAE[87]��GAN[86]Ԥ��ԭʼ����x0�����⣬VAE[73]��GAN[71]��������ɢ�����е��м�ʱ�䲽������������Ȼ������ɢģ�ͽ���ȥ�룬ֱ��ʱ��t=0���Լӿ�ʱ�䴩Խ��
3.2 ��ɢ�������
��ɢģ���еĴ�ͳǰ����̱���Ϊ���ؿռ��еIJ����˶������ܲ��ʺ����ɽ�ģ��Ϊ�ˣ��о������ڴ����µ���ɢ���̣��Լ���ǿ������ĺ�����̡����о���Ϊ�����֣�������������ɢģ�͵�DZ�ڿռ䣬�Լ��øĽ���ǰ�����ȡ����ͳ��ǰ����̡����⣬���ر��עΪ��ŷ����ÿռ䣨�����Ρ���ɢ�ռ䡢�����ռ��ͼ�����Ƶ���ɢ���̡�
3.2.1 DZ�ڿռ�
�о���Ա̽����һ����DZ�ڿռ���ѵ����ɢģ�͵ķ���������ǿ�����粢������ֱ�ӵĻ��ݹ��̡����ַ�����LSGM��INDM�еõ���ʾ�������ǹ�ͬѵ����ɢģ�ͺͱ���Ա��������һ����ģ�͡����ַ�����Ŀ�����Ż�������-�������Ժ���ɢģ�͵ļ�Ȩȥ�����ƥ����ʧ�����Ż�������ģ�͡����ַ��������ڽ����Ͳ���������DZ�ڿռ䣬��Ӧ����Stable Diffusion��ʵ��Ӧ���С�ͬʱ��DVDP�����ؿռ�ֽ�Ϊ�������������̬����ÿ�������ͼ���Ŷ������е�˥���������ڶ�̬ͼ���²������ϲ�����
3.2.2 ���˵�ǰ�����
��ʽ�ռ���ɢ�㷨�������ƣ���Ҳ�����˿�ܵĸ����Ժͼ��㸺�ɡ�Ϊ�˽��������⣬�ִ��о�����̽��ǰ�������ƣ��Դ�������׳����Ч������ģ�͡����磬���ɳ�����ģ�ͣ�PFGM����������Ϊ����ռ��еĵ�ɣ��ص糡�߽��ֲ����������ݷֲ���PFGM++��չ��PFGM��ʹ�ø���ά�ȵ������������Щģ��֮��IJ�ֵ��ʾ�����ŵ㡣Dockhorn�����������ٽ�������֮����ɢ��CLD��ģ�ͣ���ģ�ͽ����ͨ�����ܶ��ٶ���ѧ����õġ��ٶȡ������������о���̽���������Ⱦ���̣���������ɢʹ������ͼ��ת������ģ������Ϊǰ����̣����Ⱥ�ɢ�����ؿռ�Ӧ�á����⣬����Ŭ��ʹ���Ƚ�����̬�Ŷ��ں�����ǿѵ���Ͳ�����
3.2.3 ��ŷ����ÿռ��ϵ���ɢģ��
��ɢ�ռ��������ģ���ڴ����ı����������ݺ������������ݷ���ȡ����������չ����ɢģ���ѱ��㷺Ӧ�������������ı����ָ�ͼ������ѹ�����������������������Իع��������ʵ�ֳ�ɫ�����ܡ���ɢ���������VQ-VAE�еĵ���ƫ����ۻ�Ԥ�������ڽ�һ��ʵ�ֵ��ı���ͼ���ı�����̬�Լ��ı�����ģ̬�Ĺ����еõ�Ӧ�á�����ͼ����������������̬�����Ӻ͵����ʵ�����������Ŀǰ�ķ���Ӧ����ɢ���۴���ͼ���ݡ����⣬����NVDiff��Function Dutordoir������������ɢģ�Ͳ�����ͨ�����Ϻ��������������ά�ֲ���
3.3 ��Ȼ�Ż�
��Ȼ��ɢģ���Ż�ELBO�Դ���������Ȼ���ɴ��������⣬������ʱ����ɢģ�����Ż���Ȼ��������������ս��Ϊ��ǿ��Ȼ������ѵ������������ַ����������Ȼ����ѵ���ͻ����ʧ��
3.3.1 �����Ȼѵ��
ScoreFlow��VDM����[104]����ɢģ���н�����MLEѵ���ͼ�Ȩȥ�����ƥ�䣨DSM��Ŀ��֮�����ϵ����Ҫ��ͨ��ʹ�ü���˹������ScoreFlow�������ض��ļ�Ȩ�����£�DSMĿ��Ϊ��������Ȼ�ṩ�����ޡ���һ����ʹ�û��ڷ�����������MLE�����ڻ��ڷ����ķ���MLE��
3.3.2 �����ʧ
���û����ʧ��Ƶķ������������DSM�е�ģ����Ȼ�ԡ��÷����Ľ���DDPM��ʹ�ü��ز����������ͻ��ѧϰĿ����ѧϰ������̵ķ�����ѧϰĿ�����˱���½��DSM�����⣬����߽���ƥ����ʧҲ��֤����������߶�����Ȼ��
3.4 �Žӷֲ�
��ɢģ���ó�����˹�ֲ�ת��Ϊ�����ֲ������ڹ�������ֲ��������ʱ������ս��Ϊ��������⣬��������ַ�����������-��Ϸ���������������������ODE�����ȡ���-��Ϸ����漰������Ϻͽ����Դ���ȷ������������ɢģ���ڸ�˹�ֲ��˱���Ϊ��������������������������ⲽ������ֱ�����������������鹹��ODE��ʹ�������ֲ����ͨ�ò�ֵ��������̽������Schrödinger�Ż��˹�ֲ���Ϊ����������ɢODE�Ľ���㡣
4 Ӧ��
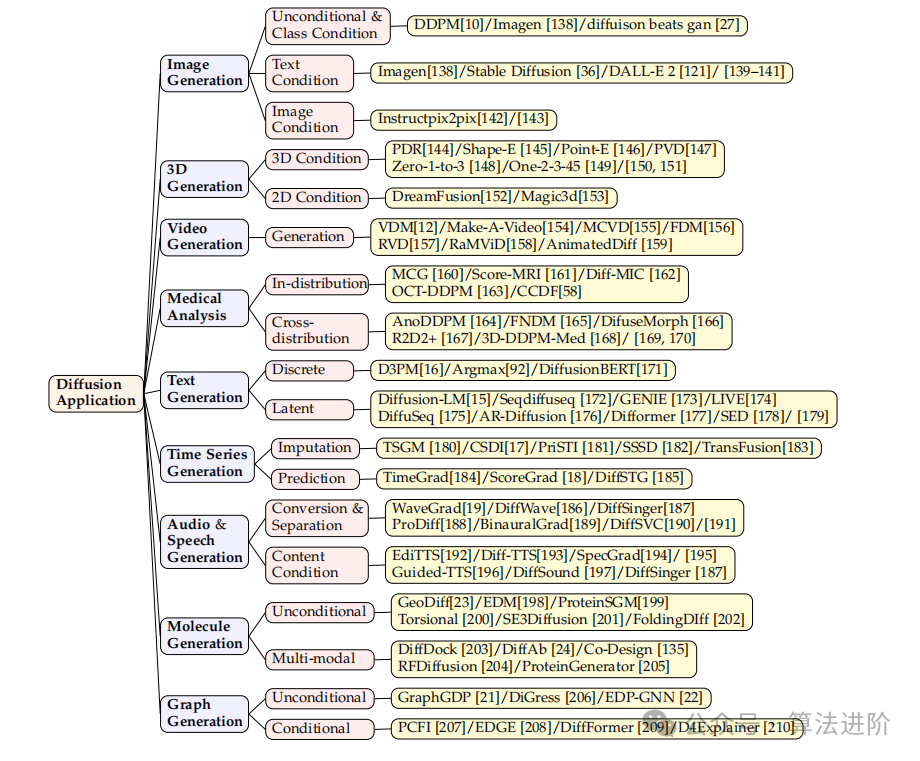
4.1 ͼ������
��ɢģ����ͼ�����ɷ���ȡ�������������ܣ������Ǵ�ͳ�Ļ���������������[10, 27, 138]�����Ǹ����ӵĻ����ı���ͼ�������[36, 143]�����������ǵ����[142]����ˣ����ǽ���������������ģ����ʵ���糡����Ӧ�����ã��������������Ӧ�ý��з��ࡣ
�ı��������ı������������ı���ͼ�������б��ֳ�ɫ���ܹ����ı���Ϣ��Ч���ںϵ����ɵ�ͼ���У���ʵ����������ѵ����ͼ��༭��ͨ�����úͲ�����ע�������еļ���ֵ��ע���������Կ�������ͼ��ĸ�������⡣
ͼ����������ɢģ��֧��ͼ������������ͨ������Ҫ�༭��ͼ�����ͼ�������������Ϊ������ʵ��ͼ��༭��
4.2 3D����
��ɢģ��������άģ����Ҫ�����ַ�����ֱ��ʹ����ά����ѵ��ģ�ͣ��Լ�ͨ����ά��ɢ����������ά���ݡ�
��ά�����������棬��ɢģ����NeRF�����ơ����ء���˹ɢ��ȸ�����ά��ʾ�еõ���ЧӦ�á����磬���о�ֱ��Ϊ��ά�������ɵ��ƣ��е������µĵ��Ʋ�ȫ��ʽ�����еĽ�ͼ��ϳ���Ϊ������ɢģ���ӵ�Լ�����롣
��ά��ɢ���鷽�棬Dreamfusion���÷�������������SDS��Ŀ���Ԥѵ���ı���ͼ��ģ������ȡNeRF��ͨ���ݶ��½��Ż�һ�������ʼ����NeRF��ʹ�ôӲ�ͬ�Ƕ���Ⱦ��ͼ����ʧ�ϵ͡�
4.3 ��Ƶ����
��Ƶ��ɢģ����һ���ڶ�ά��ɢģ�ͻ���������ʱ�����ģ�ͣ�������ȷ��ģ��֡�����ԡ������Թ�������Make-A-Video��AnimatedDiff��RVD��FDM��MCVD�ȡ����У�RaMViDʹ��3D���������罫ͼ����ɢģ����չ����Ƶ�У��������һ����������������ƵԤ�⡢��ֵ���ϲ�����
4.4 ҽѧ����
��ɢģ��Ϊҽѧ�����е���ս�ṩ�˽�������������ǻ�ȡ���ģ��������ע���ݼ�����ս����Щģ���ڷֲ��ڷ����Ϳ�ֲ����������б������㡣
�ֲ��ڷ�������ɢģ����ҽѧ�����б��ֳ�ɫ���ܹ�������ǿ������Ϣ��ҽѧͼ���ѱ��ɹ�Ӧ���ڳ��ֱ��ʡ�����Ϳ���������������Score-MRI��Diff-MIC��MCG��
��ֲ����ɡ���ģָ̬�������ҽѧ����������������������ɲ�ͬ���͵�ϡȱͼ��֮���ͼ���룬������������ʽͼ����ͼ�����ƫͼ���⣬���з���ʹ�������������������ɱ����ҽѧͼ�����ḻѵ�����ݼ���
4.5 �ı�����
�ı��������ֺ��������Ƚ��˹�����֮��蹵�Ĺؼ�����֮һ��Ҫ���������ɢ��ǵ���ս����Ҫ�����ַ�������ɢ���ɺ�DZ�����ɡ�
��ɢ���ɷ�����������Ϊ��ɢ���ʣ������Ƚ��ļ�������������Ԥѵ��ģ�͡�D3PM��Argmax��������Ϊ����������ʹ����ɢת�ƾ�����ǰ��ͺ�����̣������ɵ�������Ϊƽ�ȷֲ���DiffusionBERT����ɢģ����Ԥѵ������ģ�ͽ�ϣ�չʾ�˸Ľ����ı��������ܣ��������������������ȣ�̽����ʱ�䲽������BERT���з�����ɢ���̡�
DZ�����ɷ����������ڱ�ǵ�DZ�ڿռ��������ı�������ɢ���̵��������ʣ�������ǿ����ʧ�������������������ͺ��Ƚ���ģ�ͼܹ������磬LM-Diffusion��GENIEչʾ�˻�����ɢ�Ľ�������DZ�������ı����ɣ���������ǿǶ��ռ佨ģ�����������Ԥѵ������ģ�͵����ӡ���֧�ֿ�ģ̬���ɡ�
4.6 ʱ����������
ʱ�����н�ģ������Ԥ�⡢�����ƶ���ʵʱ�����о�����Ҫ���á���ɢģ��ͨ��ʱ����������ģ����ǿ����һ���̣�ʵ����Խ�ķ����Ͷ��������ɡ����ݲ�ͬ���ڱβ��ԣ������������Ա�����Ϊ��������Ԥ������CSDI�����һ�ֻ���˫��CNNģ������Ҽලѵ����ܣ�����ҽ�Ʊ����ͻ������ݵ��������ɡ����⣬���ʱ��ģ�飬��Graph UNet��RNN���ɹ�ʵ����ʱ�����е�ʱ�ո���ѧϰ��δ���о�Ӧ��עȷ��ģʱ�����������Լ��ڲ��������������Ƚ�����������ָ����
4.7 ��Ƶ����
�ϳɸ���������ģ���ڶ�������й㷺Ӧ�ã������ִ�����������ʵ����Ϸ�������������ֵȣ��ṩ���Ի��������侳����Ƶ���飬�������˻���������ɢģ���ʺϴ�����Ƶ���ݣ���������֪ʶ������ά��ʱ����Ϣ���������������������������ı��Ϳ��Ʊ�ǩʵ���ض������������������WaveGrad��DiffSinger�ȷ������ɻ�����������������ȡ����ɵ�ʵ�ֿɿط�����ɡ��ı�����������������Ƶ��ͼ��������ɢģ�������ı��ͽ��࣬����Ƶ��ͼ�����Ͷ���ͼ��ǩ������-TTS�ȷ���ʹ��˵�����ı�������������ʱ��Ԥ���������ط���������������������ɺ��������ָ���������ָ�����ذ�����С�������������ַ��
4.8 �������
�����������Ļ������������ӹ��������һ��������ս������ģ��ͨ���ṩ��������ı��˷�����ƣ������������µ���Чҩ����ӽṹ����չ��ҩ����ƵĿ����ԡ���ҩ����У���ɢģ��������̽��������ռ䣬����DZ��ҩ������������ҩ���Ч�ʡ����⣬�������ģʽ�ɷ�Ϊ���������ɺͿ�ģʽ���ɡ�
������������Ҫʹ����ɢģ�ͣ������ٶȿ��������ģ����������֮һ������ά�ռ������ɷ��ӽṹ�����乹�����ܵ��µͶ����Ժʹ�����һ�ַ�������ά�ռ��еĶ�������ͽṹ�����ֲ����ɲ������ḻ�����ķֲ��Ϳɽ����ԡ�
��ģʽ����רע�ڽ�������Ϊ�����������ϣ�����������ɢ�ķ������������еĿ�ģʽ���������ڽṹ�Ŀ�ģʽ�����ͷ��ӶԽӺͿ�����Ʒ�����������ɢ�ķ������ȥ��ģ����ǿ��ģ�������������еķ������õ��������кͶ������ж���ѵ��ģ�Ͳ����Ͻṹ��Ϣ���ܱ�ǩ�����ڽṹ�ķ������ýṹԤ��ģ��Э����ȷ���ɣ�������к�����Ϣ��������������Ŀ��ṹ������֪ʶ����ǿ���ɲ������ϣ���Ĺ���
4.9 ͼ����
ʹ����ɢģ������ͼ�Ķ�����Ϊ���о���ģ����ʵ���������ʹ������̣��Ը��õ�����ͽ����ʵ���⡣���ַ����ṩ�������˽⸴��ϵͳ������ú���Ϣ�������ƵĻ��ᣬ������������ͼ�Ĺ�ģ��ϸ��ͼ�����ͽ���ض����ݼ������⡣��ɢģ�͵�Ӧ�ð���������������������ϵͳ�ķ����Լ�ͼ���ݵ����ɺ�������һЩ��ɢģ�ͣ���PCFI��EDGE��DiffFormer�����ýڵ�Ⱥ�����Լ����Ϊ������ʵ����ɢ�������������ڽӾ����DZ��Ƕ�롣���⣬D4Explainer��ͼ���ݵķֲ���Ϊ����������Ϸֲ���ʧ�ͷ���ʵ��ʧ��̽������ʵʵ����
5 �����Ժ�δ����չ
5.1 ���������µ���ս
��ɢģ�������ٶ������ӵ����������б�ʶģʽ���Ѻ��������³�������ս���������ģ���ݼ������¼����ϵ����⣬������ģ�͵Ĺ�ģ�����ԡ���ƫ�������ݲ�������Ҳ��Ӱ��ģ�͵�����������
5.2 ���ڿɿطֲ�������
���ģ�����ض��ֲ��ڵ������������������Ҫ�ġ���ע����ģʽ�������������������ѵ������ƥ����������Ż������Ͳ����ṹ������ǿ���⣬ʵ�ָ��ܿغ;�ȷ�����ɣ���߷������ܡ�
5.3 LLMs�Ķ�ģ̬����
���ϴ�������ģ�ͣ�LLMs������ɢģ��δ���ķ�չ�������ƽ���ģ̬���ɡ�����LLMs��ǿ�˶Բ�ͬģ̬������õ��˽⣬��������ʵ��������������⣬LLMs�������ʾ������Ч�ʣ���չ��ģ̬���ɵ�Ӧ������
5.4 �����ѧϰ����ļ���
�����ɢģ�������ѧϰ����Ϊ������������ṩ�»��ᡣ��ලѧϰ���������ڽ����������ս����������������ʵ����Ч�������ɡ�����δ���������ǿ�������������ܡ�ǿ��ѧϰͨ�����㷨�ṩ������Ե�ָ����ȷ����Ŀ�ĵ�̽�����ܿ����ɡ�������ⷴ���ḻǿ��ѧϰ������ܿ���������������
�ο����ӣ�https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model

















