��Ӧ���Ҫ��һ��ISSCC 2024���ܽᣬ���ڵ���д�ˡ�ISCCC 2024�����پ��о�����̱����壬ʷ�����Ͷ������873ƪ�����궼��600-650֮�䣩�����ڷ����ʱ������ƣ���Ҳ���½��������¼���ʣ�26.8%��������31-34%֮�䣩����ί��Ϊ�����ɸ�������£�Ҳ������ÿ�������ʱ����������ÿ��session����һ�����档���У���½+�۰�ռ��69ƪ���ٴ��¸ߣ�վ�ȵ�һλ�ã���������50+ƪ��ԶԶˢ�ں��档��һ�ڣ�С������AI��ģ�����ŵĴ������ISSCC AIоƬ��ѧ�����ġ�
����ѰTransformerǧ�ٶ�
���������ISSCC Advanced Program����ҿ��Է��ֳ����Դ�ģ�ͣ�LLM����TransformerΪ���������֮���١����������ϣ�����Transformer������оƬ����������һƪ�������Ժ���KAIST��C-transformer�����������˼���ǽ�DNN transformer��Spiking ��SNN��transformer�ںϣ���������SNN��λ��������Ч�����ԣ������������粿�����Ч��
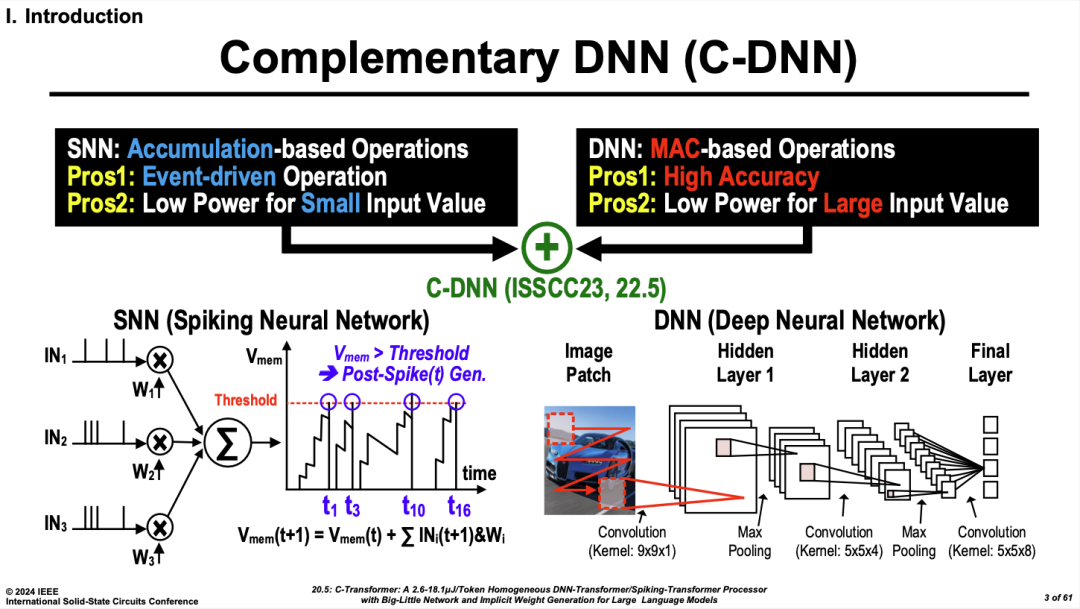
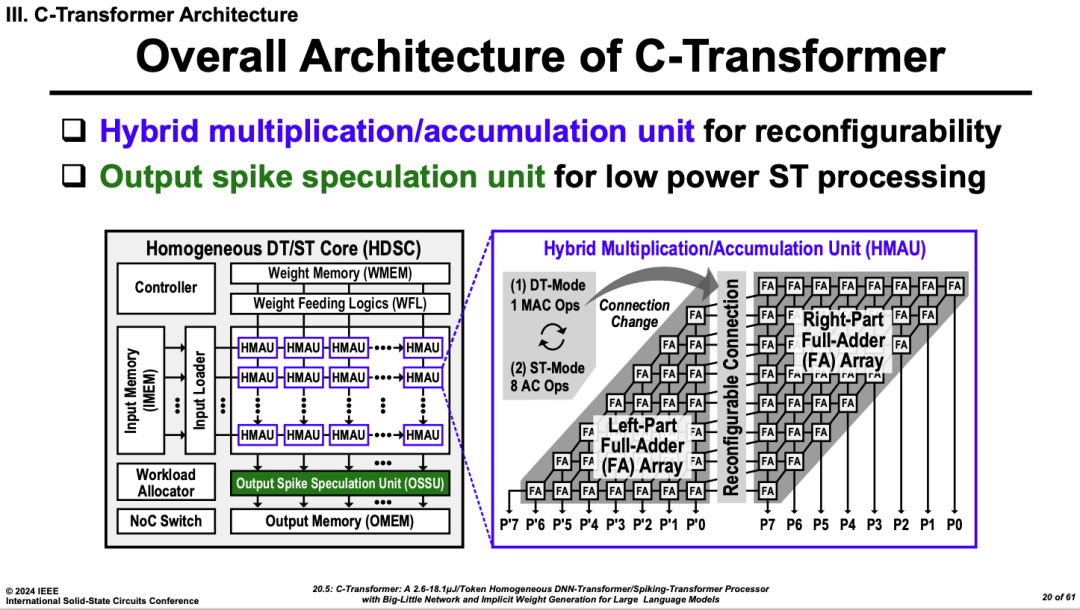
C-Transformer�ĺ����뷨��ͨ��һ����ϵij��ۼӵļ��㵥Ԫ�����������ó�����ģʽ��һ���DZ��ij˷�ʽģʽ���ø߾��ȵ�DNN���㣬��һ���ǵ�λ����Spikingģʽ������ʵ�ְ˸��ۼӵļ��㡣ͨ�������㵥Ԫ���ó����е�ijһ��ģʽ��ӳ��DNN������SNN Transformer�ļ���.��һ�����е������廪��ѧTianjiϵ��оƬ��
ֵ����ο���ǣ�Program������ƪ�����ܵ�AI�����������ṩTransfomrer��Benchmark����������������������������ɾ���AMD��MI300ϵ�С��ڹ�ҵ���������У�Instinct MI300ϵ����Ϊһ��AMDȫ��һ�������콢�������������˸�����ά����оƬ�ļ��������ȫ�µ���Ȼ�����ʹֻ���ṹ��Ҳ���Ը��ܵ��ɶ��칤������Ϊ3��ѵ��ṹ����������Դ����壨Active Interposer, Base IO Die������Դ����壨Si Interposer����hybrid bonding�ȸ��༼����
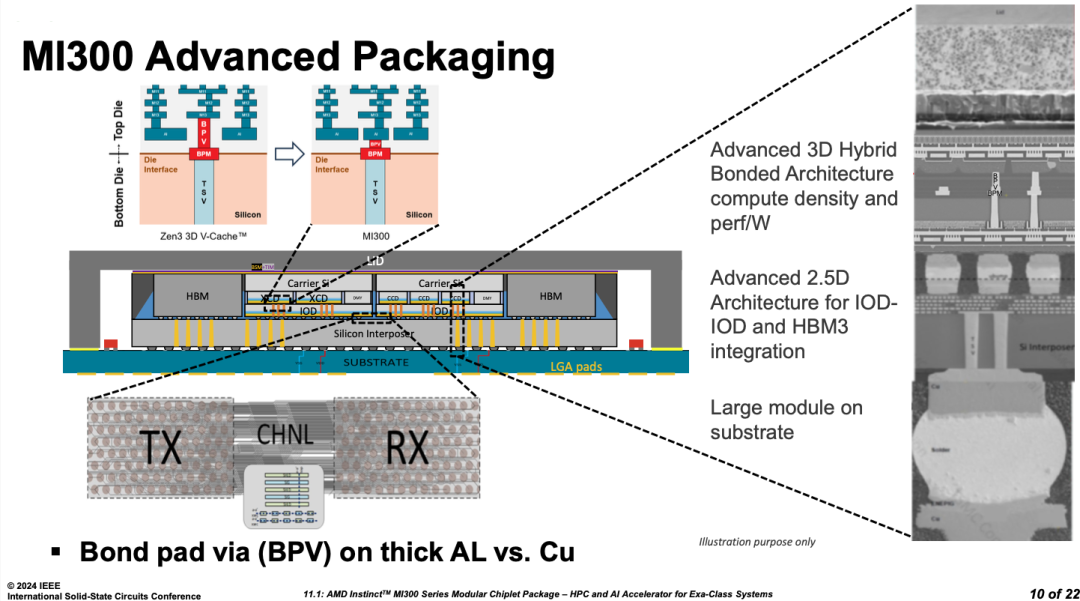
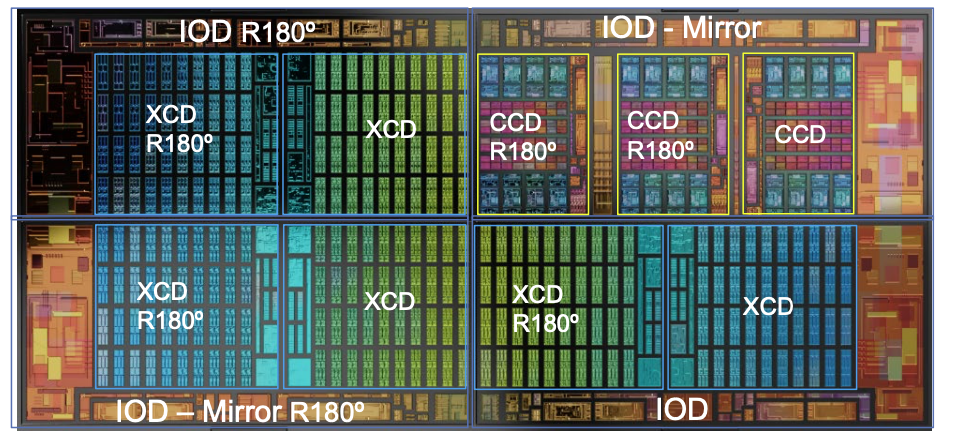
�Ӽܹ��ϣ����Ƚ���˵���װ�ڽ�������GPU����������CPU-PCIe���ƶ˴������µ����ܱ��ͣ����״�ʵ����CPU Die��2������ȫ��ͬ�IJ�Ʒ���ϵĸ��ã�Zen 4CPUо��ͬʱ��MI300ϵ�к�EPYC Zen������Ʒ�߸��á����Ű�ͼ�ĸ���ͼ����������һ������Ʒ��

AIоƬ�ڽ���ISSCC��ǰ����ISSCC����������ٵ�ԭ����Ҫ����Ҫ������Steering Committee��Machine Learning Track����ȡ����֮��������Security Track��MLоƬ�ع鵽��ͳdigital architecture��digital circuit track��Memory track�����㲿�֣�����Ȼ����Ҳ�����˽������ĵIJ���Ц��������Compute-in-memory Session����һƪ�ų�֧��Transformer��CIM����Transformer CIM��Ҫ��λΪ���ߵľ��ȣ�INT10b����
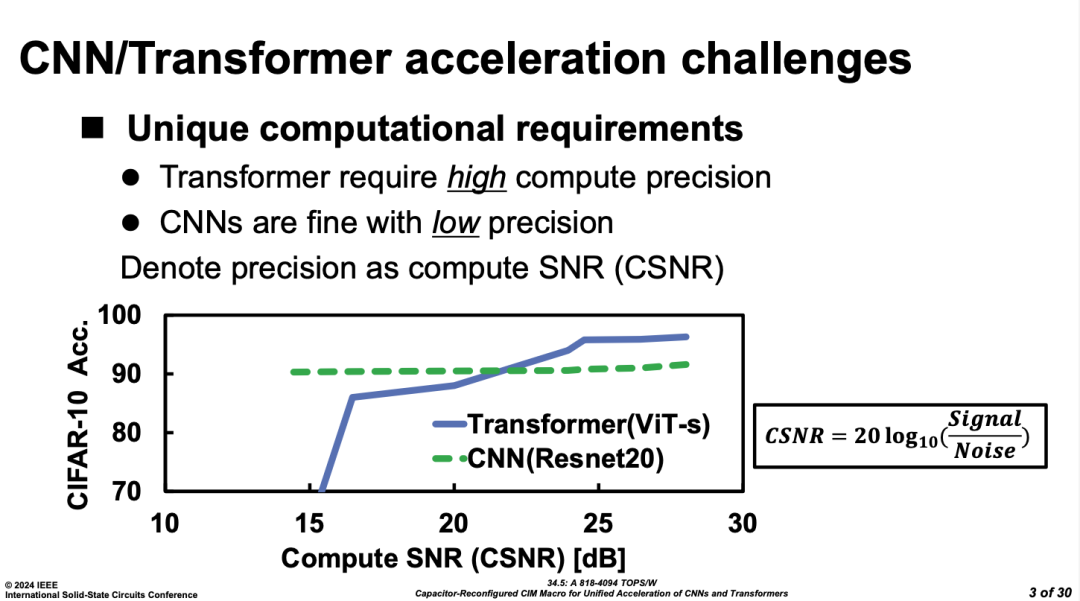
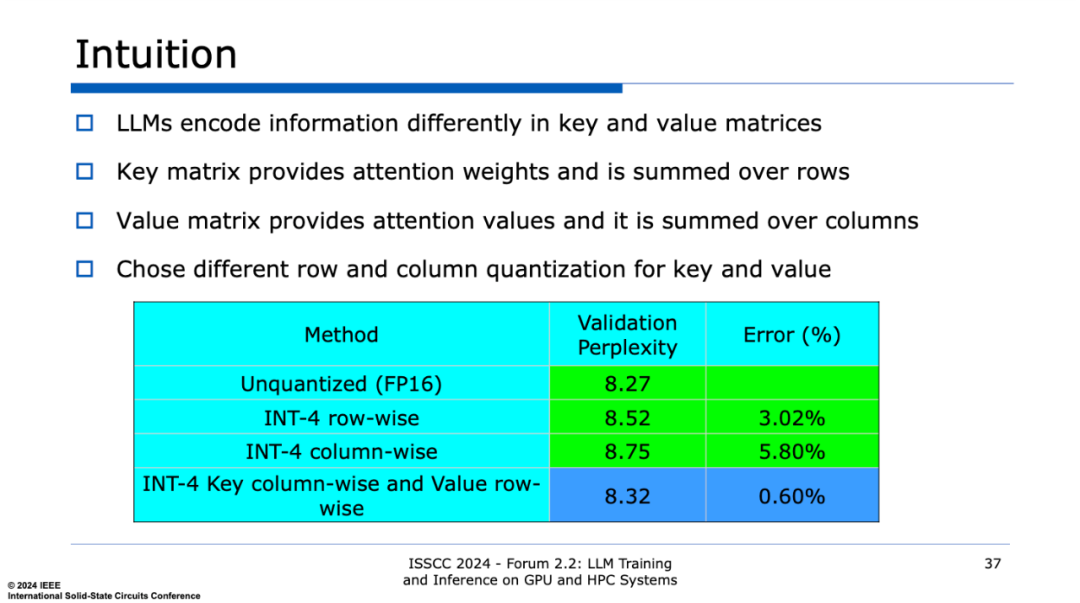
Ȼ�����������Nvidia ��forum talk��žž���������д�ģ���Ѿ���INT4�����µľ�����ʧ���Կ�����0.6%���¡�
С����ã����������Memory designer ��Machine Learning SoC designer���ڴ�ģ���㷨��չ����ʶ��ʱ��Ҳ��ȡ��ML track��һ��������
˳����һ�����forum�������ISSCC��������һ�������ģ��оƬ��forum�������̳������������Ӣΰ��ȸ衢Intel�����ǵȵĶ����ģ��оƬ��˾����ҵ���������µĴ�ģ�ͽ�չ�����ò�˵���forum������ISSCC �����ж��ڴ�ģ��оƬ�������㣬С����Ϊ�Ƽ�Ӣΰ�������forum��talk��ֻ��ϧ���forum��Ҫ���⸶Ǯ��
����оƬǰ�ؾ۽�������
��һ��ѧ������ʵ�ִ�ģ����Ƶ���Ҫԭ�������ģ����ѧУ���о��ṹ���ԣ���������Ƭ��ģ�����ѣ�����Co-design����ѵ���ɱ���������֧��B������ģ�͵�ԭ��ʵ�顣���ԣ��ڽ���������У�ѧУ�Ĵֹ�����ת��������һ���������ܻ����ˡ����������һ�����ߴ��ϵ����֣��������ܣ��Ҿ��ÿ�������Ϊ�������ļ�ά˹�ܸɵ����顣
����������ܵ�оƬ��Ϊ���࣬һ�������������ı������������絼���������������������Ŷ������һ������RRAM�ĵ���������оƬ���������������ܣ���һ�������dz������ܸ�֪�����⣬ͨ������RRAMʵ��CNN���㷨���ڶ����Ƕ��ڻ����еĵ�����λ������Ҫ������SLAM��״̬���̵�������⡣

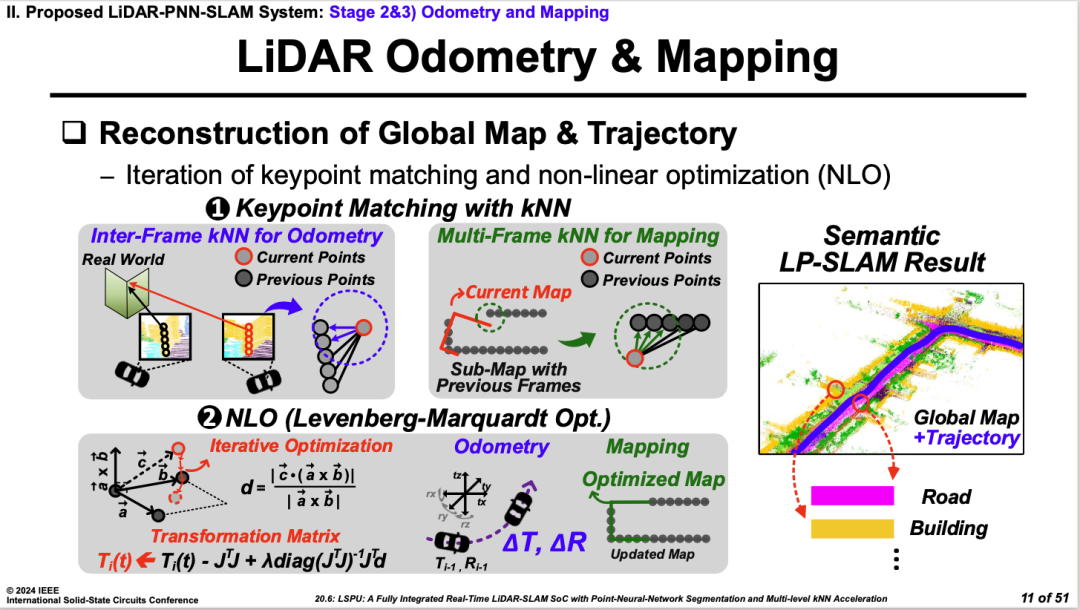
���Ժ���εɽ�Ƽ�ѧԺ��UNIST���Ĺ�����һ�������״Lidar����3D���Ƶ�SLAMоƬ������ͨ��KNN����˵��Ƶı����źŴ�����ͬʱҲͨ������������Ż����������SLAM�ķ���������
�ڶ�����������ʵ��ͼ�����ɣ�����Ŀǰ��Ҫ���㷨��NERF������ʽ��ͼ��������Ч����ͨ��������ļ�ѧϰ��������ɲ�ͬ�Ƕȣ�����Ͷ���£��������άͼ����Ⱦ�����֣��е�����Ԫ���������Apple Vision Pro�Ľ�ͼ�����弼���Ͳ�һһ�����ˣ�С��Ҳ��̫�������Ƽ�������ƪ���¡�


���Ƶ�������ʵ�������������廪��ѧ��Diffusion SoC оƬ���������ߣ������߽���ֳ����ֵ�������������Ϊ��������ʵ������һ���Թ�������õ��������е��Ϲű���е����Ƶ�Ĺ�ʼǡ���������ƪ���³��˰�NERF��SLAM��MoE-��ģ̬���������������һ��MLP�ļ��٣�ʵ�ʷ��ƿɳ¡���

����һ�����һ�����칹���ô��
����һ���������˶��귢չ֮����ISSCC������������������������������̨���硣�����Ʒ�����һ��3nm NPU�����еļ��㲿�ֲ�����TSMC 3nm����һ��������ģ����Macroʵ��Ҳ�ڽ���CiM��Session����һƪ���ģ������һ����Ƭ��ƪ���ġ���Ȼ�������һ��Ĵּ���������TSMC DCIM����·�ߣ���Ҫ����������Դ��3nm�������������ƻ������·�ߵļ��������˳����NPU��Ʒ��δ�����ֻ����ڲ�Ʒ��Ӧ�ÿ��ڡ�
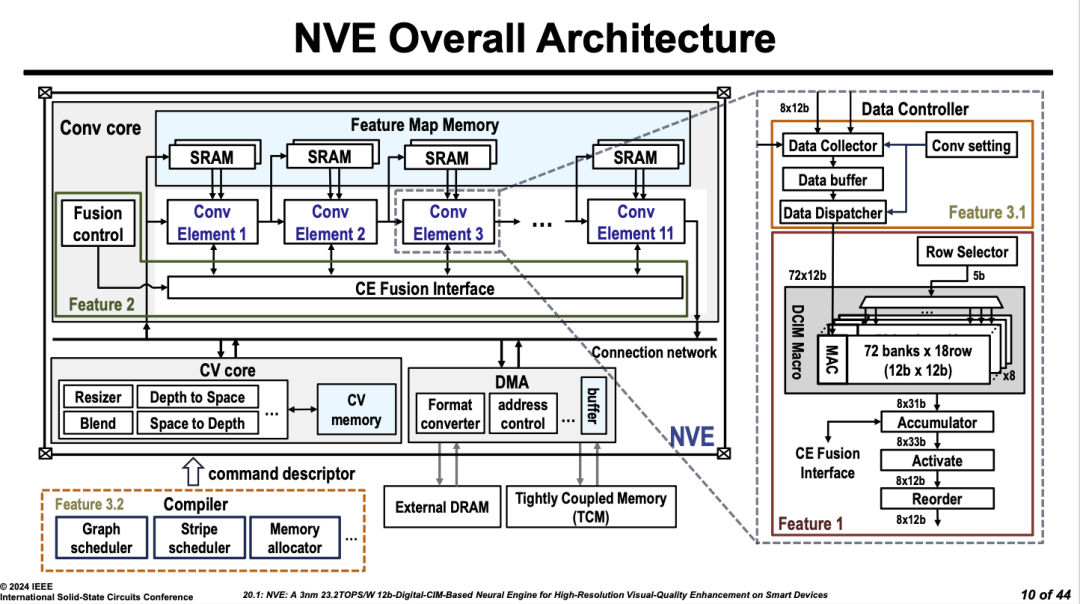
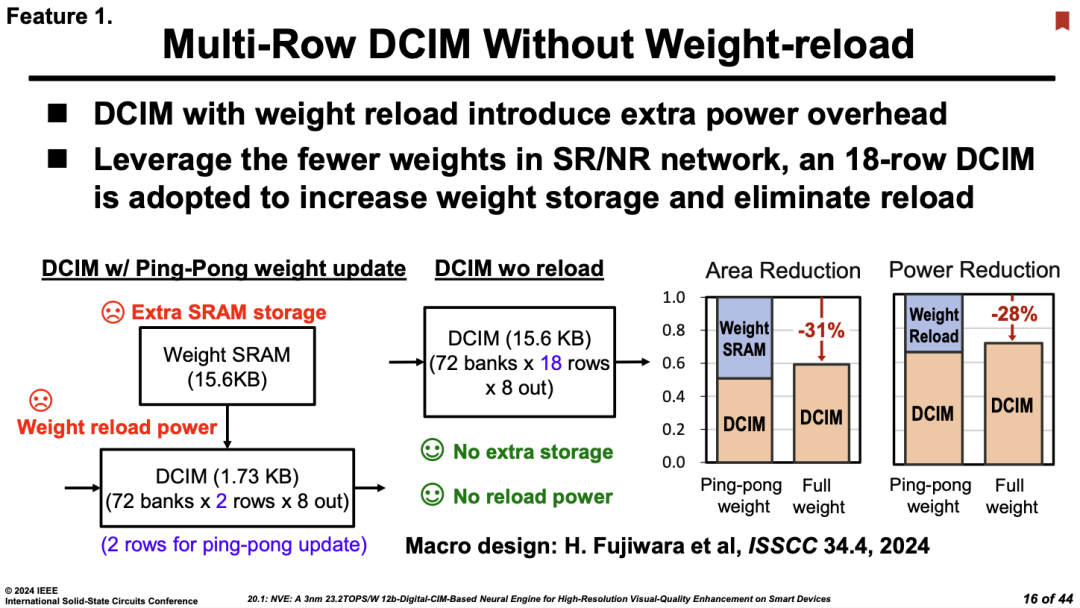
��˳���²��£����Multi-Row DCIM������ISSCC 2022��COMB-MCM�����
��û�и��¹��յļӳ��£��ڴ��㴫ͳ���������ϣ�28/22nm�ڵ㣩������Щ�����أ������Ǿ�������㣬�Ͼ�INT CIM�ļ�����Ч�Ѿ������ˡ����⣬�������ǿ���ѧ�����¼�����ĵIJ��ٴ��¶��������ĸ��֣�����칹��
��һ���칹�Dz�ͬ��·������Ƶ��ںϡ����ϴ�ѧ���п�Ժ���ӵ���ƪ���£�����ͨ��ģ������ֵĻ���칹����֤���ȵ�ͬʱ�����˼�����Ч���ѶԼ�����Ӱ�첻��ô��Ҫ�IJ��ֻ���ģ���������ѡ��ģ���������ּ���ı߽�����Ȥ�����ۡ�
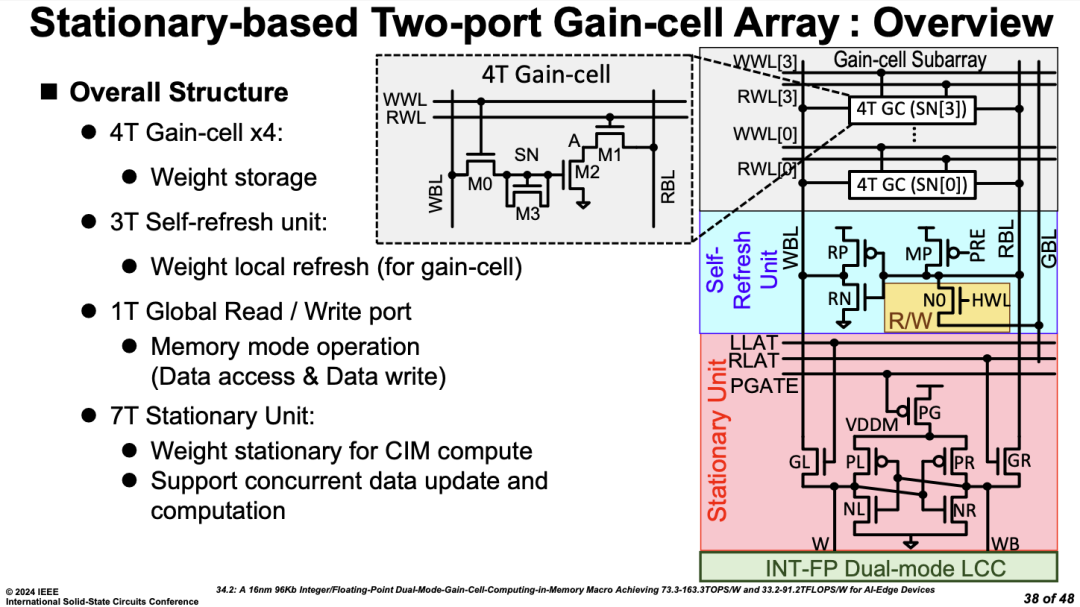
����ģ������ֵ��칹�⣬���в�ͬ�洢���ʵ��ںϡ�̨���廪��ѧ������4T Gain Cell��DRAM����7T SRAM�ںϽṹʵ���������������Ĵ洢�Ż��ܹ���
���⣬�������������Flash�����SRAM�����ںϵ�ģʽ��ģ����ͻ����ѧϰ�Ľṹ��ʵ��Ƭ�ϵ���ѧϰ������
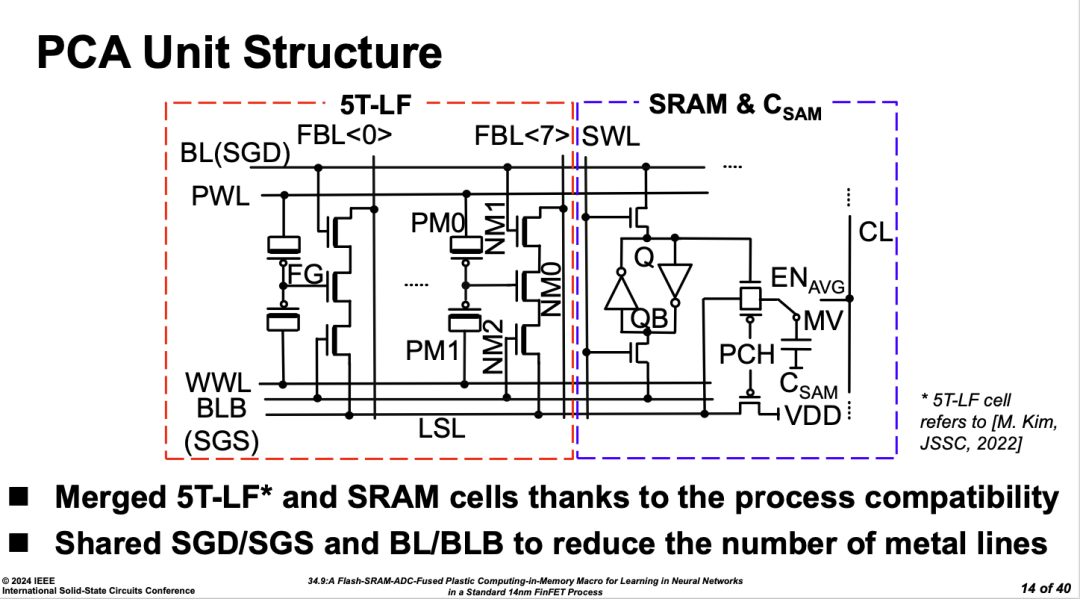
��ʵHybrid�ṹ������ISSCC��track�϶����µ����Ҫ��Դ������Power��ADC����ģ��Track���ڹ�ȥ�ܳ�һ��ʱ�䣬ԭʼ�ܹ��Ĵ����Ѿ�������ƿ����������;ͨ����ϼܹ����������ܣ�FoM���Ƿdz���Ч��;���������У����ѡ���칹�ı߽磬�������������loss����Ҫ�Ŀ�ѧ���⡣��������ij�̶ֳ��ϣ����Dz���Ҳ��ζ���������һ���������Ҳ�Ѿ�������ѧ���������о���ƿ���أ�
������Դ����˵�����߳�Ц
�����أ�ISSCC 2024 Session,Digest,PPT��ȫ����


















