��ʵ����������͵��֮���Ѿ�����Ϣ˵��Llama3Ҫ���ˡ�
�����Ϣ����̶ܳȣ�����AIȦ��˵��������������ν��GPT4.5��
�Ͼ���meta�����������Ǹ�"OpenAI"��
�ж��ٴ�ģ�͵���̬���ǽ�����Llama�ϵģ���Ҷ�����
�������Դ֮�⣬��ȫ���������˶��ŵĴ�ģ�ͣ�Llama3����ʱ����9����֮��Ľ�����
������ʽ�����ˡ�
�ҵļ������ѣ����Ѿ����ˣ�����zRͬѧ��

��ҹ���ߡ�
Llama3Ŀǰ���Լ��Ĺ�����huggingface�ϣ�ģ���Ѿ��ϼܣ�
https://llama.meta.com/llama3/
���һ���meta���Ϲ�أ���Ȼд�����ض���������ҵʹ�ã��»�ó�Խ7�ڣ������ǻ���������ȫ��������ˡ�
��ο�Դ��2��ģ�ͣ�8B��70B��
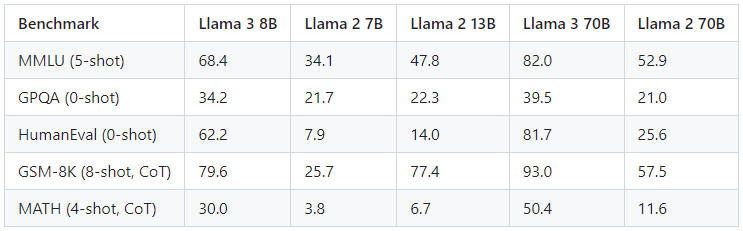
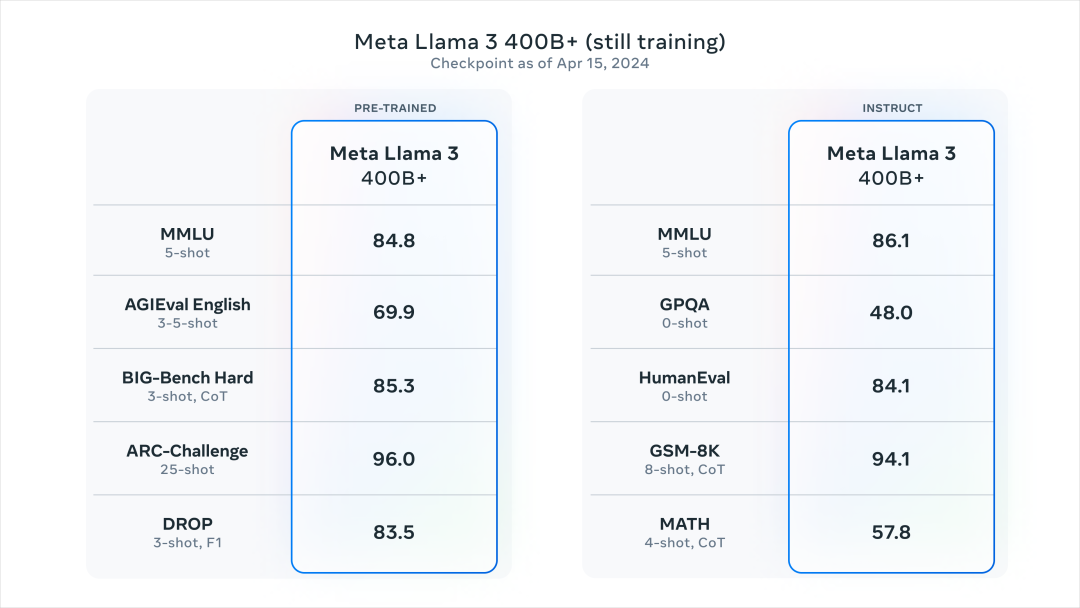
Ȼ����Ǵ�ģ�͵Ĵ�ͳ���ܣ��ܷ֡�
̹�ʵĽ�����������ܷ֣���һ������ס�

5�����⼯�ֱ���MMLU��ѧ��֪ʶ���⣩��GPQA��һ�����⣩��HumanEval��������������GSM-8K����ѧ��������MATH���Ƚ��ѵ���ѧ��
������8B����70B����������ȫ����ɱ��
8B��ߣ�ֱ�Ӱ�ͬ�ߴ�����ڵ��ϴ�
������Mistral 7BҲ���й��Ի͵ġ�

����Ҳ���ɳ���ʱ�������ᡣ
������Llama3�Լ���8Bģ�ͣ�Ч������Llama2��70BҪ�ã����¾ͷdz�����ô���ס�
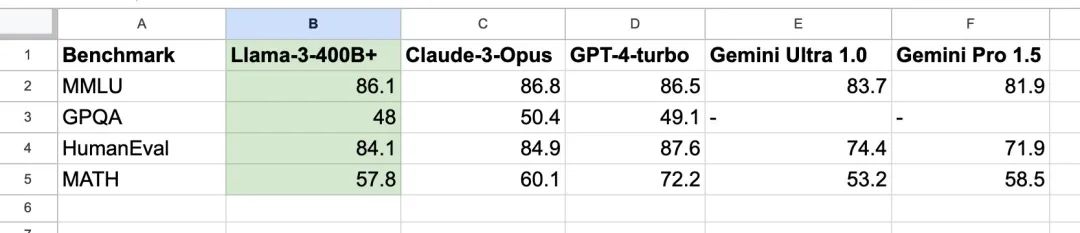
��Llama3 70B�DZߣ�ֱ�ӶԱ�Gemini Pro 1.5��Gemini���ҵ���������ɶ����Claude3 Sonnet��GPT-4�ӹ�һ�ع���������
���������ĺֲܿ��ˣ��Ͼ��������������ⶼ����һ�������ģ�Llama3ֻ��70B�����ܴ�������лأ���Ȼ��Claude3��ţ�Ƶ��Ǹ�Opus����һЩ��࣬��������ô�ǿ�Դ�İ���
���ǻ�����һ����Ȥ�IJ��ԣ�����һ��ȫ�µĸ�������������
������� 1800 ����ʾ������ 12 ���ؼ��������ֱ��ǣ�
Ѱ���顢ͷ�Է籩�����ࡢ���ʽ�ʴ𡢱��롢����д������ȡ�������ɫ/��ɫ������ʽ�ʴ���������д���ܽᡣ
��ɧ���ǣ�Ϊ�˷�ֹ����ϣ�����Llama3�Լ��Ľ�ģ���Ŷ����ȶ���֪�������⡣Ȼ����� Claude Sonnet��Mistral Medium �� GPT-3.5������Щ������ʾ�����˹�������
������ǣ�
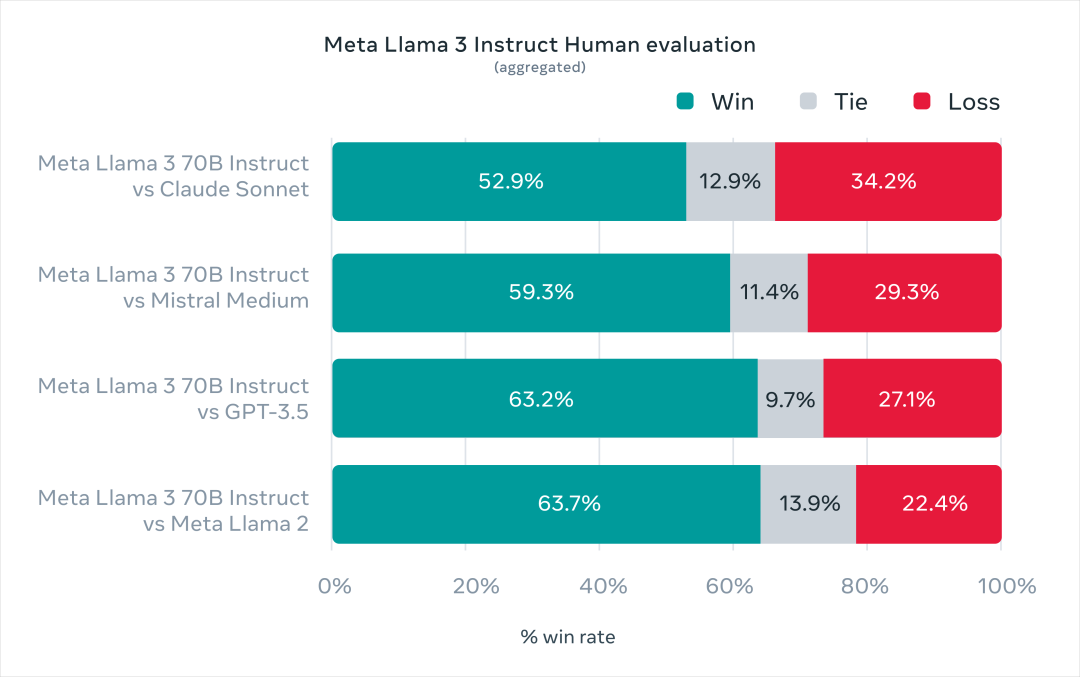
��ǿ��
����Ҳ��������der�ĵ㡣
һ����֪ʶ��ʱ�䣬һ���������ij��ȡ�

֪ʶ����飬7Bֻ��2023��3�£�70B����2023��12�¡�
�����ij��ȸ���ֻ�п�����8K��
֪ʶ���ʱ�仹��˵����������������ij��ȣ������ڶ�����200k��ʱ�����ʵ���е㲻�����ˡ���
Llama3��ѵ�����ݣ����˳���15T�ʿ��Ԥѵ������Llama 2���߱��������Ĵ���������Llama 2���ı���Ԥѵ�����ݼ���5%���ϵķ�Ӣ�����ݣ�����30�������ԡ�
���ң����ǻ��и�400B�����������ѵ���С������Ҿ���400B�����������ʲ��ῪԴ������
�ٶԱ�һ��Ŀǰ����������ǿģ�ͣ�
��...����
ֱ�Ӹ�Claude3 Opus��GPT4 Turbo��࣬��ɱ��Gemini Pro 1.5��
�š�����������˵������
���ڿ���ֱ���ڵĹ����ã�https://www.meta.ai/
�����ûMeta�˺ŵĻ���Ҳ���������ã�https://llama3.replicate.dev/
��Ȼ�������Ÿ�����ˣ����ǻ��������������ز���+����
Llama3�����Ļ��Dz�զ�أ�������ûɶ���ݣ����Ի��ǵÿ��������Ժ�����ã�ǰ���DZ�������Llama 3��������֤�Ϳɽ���ʹ�����ߡ�

������������2Сʱ�����Ƿ��ֺ�ͻ����һ���ǣ���������̫ը�ˡ�
zR���˺ܶ��case������Ӣ�ģ���
����һ������Ļʺ����⡣

Llama3-8Bֱ�Ӹ����˽ⷨ��
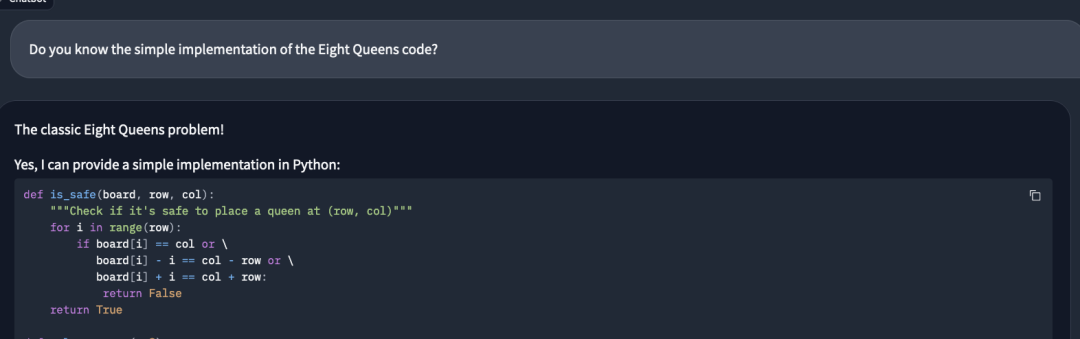
Ȼ�����С�
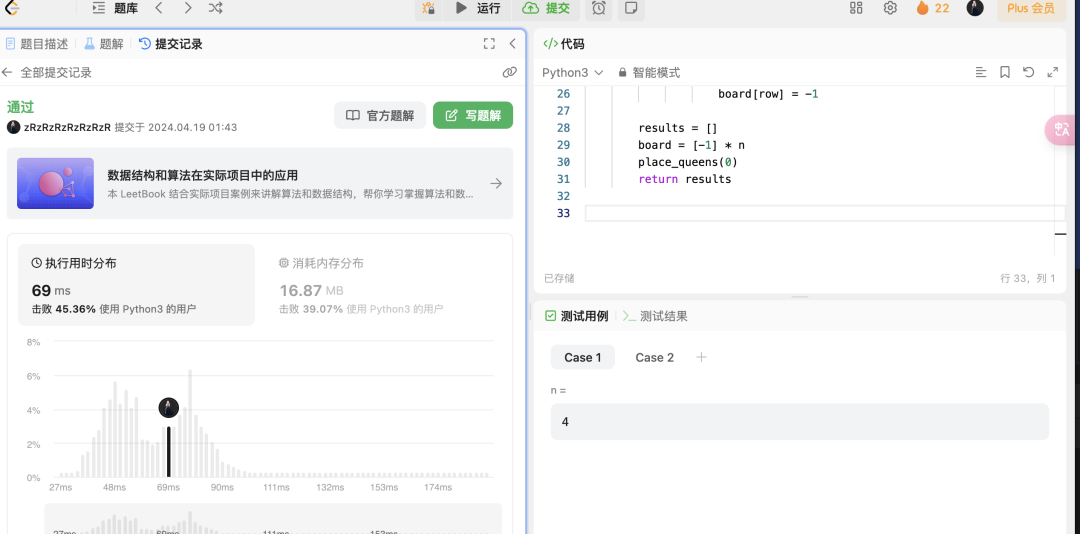
����ô��Llama2�У������Dz����ܵģ�ֻ��ר�ŵĴ���ģ�ͣ����ܸ㶨��
Ҫ֪����Llama3-8B��ֻ��һ��8B��ͨ�ô�ģ�Ͱ�������
Ȼ������������һ�����ѵ�һ�⡣��zR�Ļ�˵�������leetcode�ϣ����ѵ�һ�⡣

��Ŀ�ǣ�
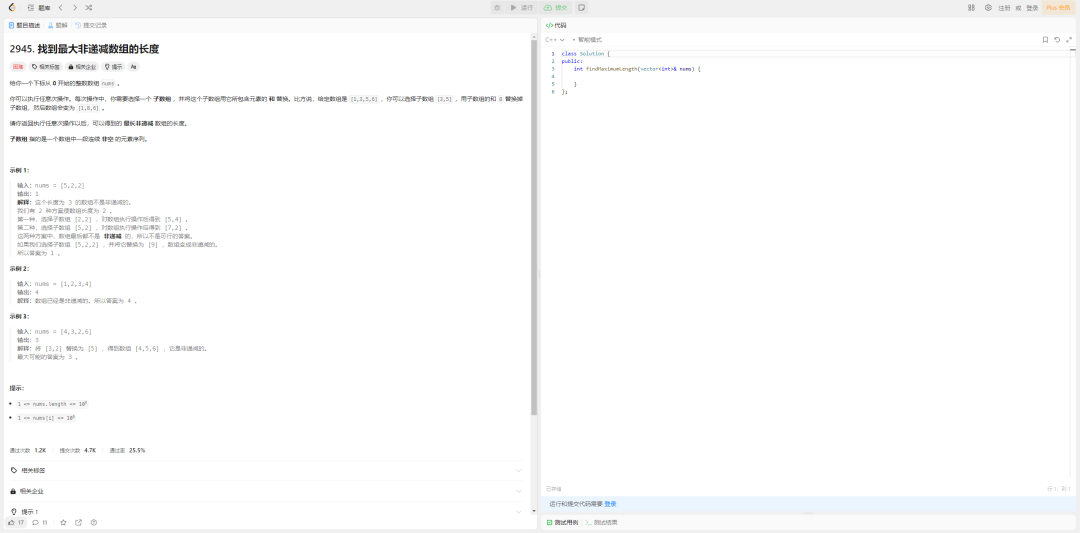
Ȼ������һ�Σ������ˣ����˱����ʹ𰸴��Ի����κ�
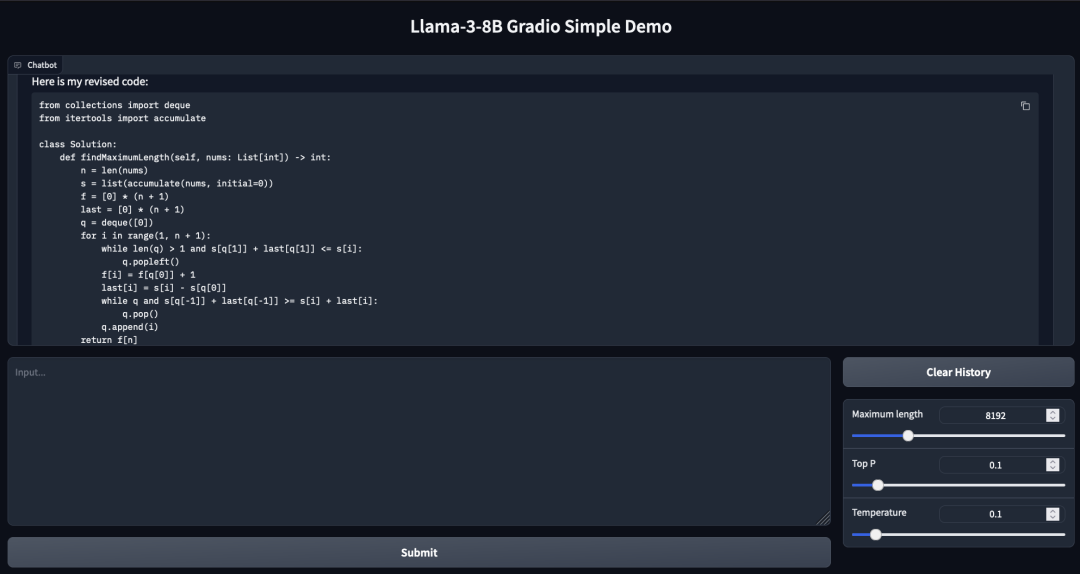
������
���Ա��ˡ�
GPT4ͬ�����������ܸ�Llama3-8B��ͬ�ȴ���������û�ɳ�����
����Llama3-8B���ɳ����ˡ�����
̫�����ˡ�����
�ܽ���˵��Llama3��Σ���������ը�����ģ�͡�
Ҳ���Ե�֮������˵��������ǿ�Ŀ�Դģ�͡�
Meta�ٴ�֤���ˣ��Լ������Ǹ�"OpenAI"�����Ǹ�OpenAI��ֻ�Ǹ�"CloseAI"��
���粻��û��Meta��
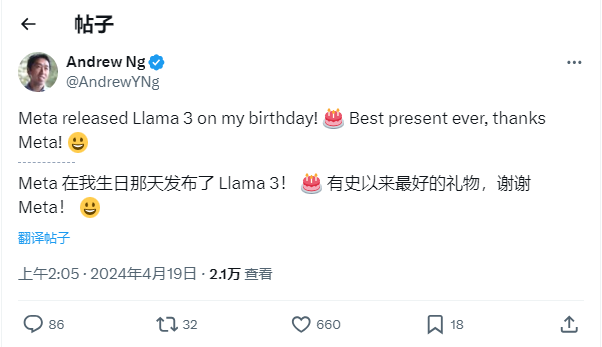
���и�С�����ǣ����컹�����������ա�
���Ի�˵������OpenAI���GPT5���ڵ�ɶ�أ�
��ѻ��������ˡ�
�Ͻ��ġ�
���ǵ��㡣

















