随着模型能力的不断提升,不少开源大模型在诸多维度上已能媲美GPT4这类顶尖闭源模型,这也让它们能胜任多数生成式AI应用场景,更多开发者也开始基于开源大模型开发应用。
作为坚定看好开源大模型发展的AI Infra公司,硅基流动(SiliconFlow)顺势而为。今天,我们推出集合主流开源大模型的一站式云服务平台SiliconCloud,为开发者提供更全面、更快、更便宜的模型API。
“6.18购物狂欢节”来临之际,我们决定,自即日起为开发者送上一波福利:每人送3亿token,注册即可畅玩。
3亿token领取传送门(截止6月18日23:59):
www.siliconflow.cn/zh-cn/siliconcloud
不同于多数大模型云服务平台只提供自家大模型API,SiliconCloud上架了包括DeepSeek V2、Mistral、LLaMA 3、Qwen、SDXL、InstantID在内的多种开源大语言模型、图片生成模型,支持用户自由切换符合不同应用场景的模型。
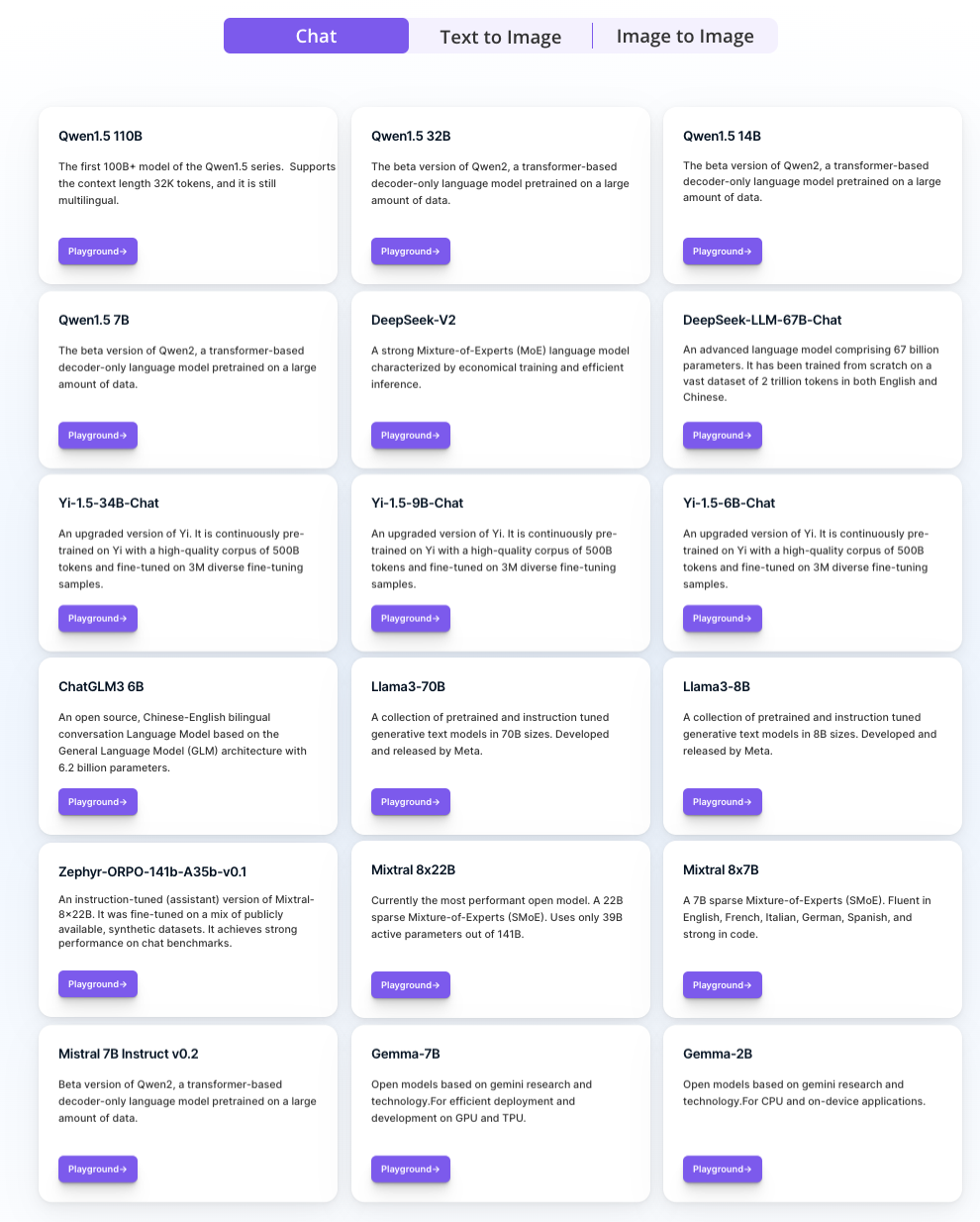
更重要的是,SiliconCloud提供开箱即用的大模型推理加速服务,为你的生成式AI应用带来更高效的用户体验。
直观感受一下加速后的Deepseek V2的token输出速度。
(Demo录屏展示无加速)
对于图片生成模型,SiliconCloud能让Stable Diffusion XL模型实现毫秒级即时图片输出,层层嵌套提示词,输出效果很稳定。
对开发者来说,通过SiliconCloud就可以一键接入顶级开源大模型的能力,拥有更好应用开发速度和体验的同时,大大降低应用开发的试错成本。
极致算力优化,最高10倍加速大模型推理
加速大模型推理降本增效,硅基流动团队是专业选手。
众所周知,大模型的快速发展导致算力成本居高不下,甚至高端芯片严重短缺,这抑制了生成式AI应用的蓬勃发展。
基于丰富的AI基础设施及加速优化经验,我们希望通过软件手段,在解决算力供需关系的同时跨数量级降低大模型推理的成本。作为国内最早瞄准大模型推理领域的团队,我们率先为SiliconCloud研发了底层推理加速引擎,在各种场景中,最高可实现10倍加速。
要知道,大模型推理优化不止于单个模型的性能最优,而是达到全局最优的性能。
基于硅基流动深厚的工程优化能力,通过模型、机制、框架、算子等层面的联合优化,无论是以LLaMA为代表的Dense模型,还是以Mixtral为代表的MoE模型,均可达到SOTA推理效率。
极致的大模型推理性能实现,是我们立足行业的基本能力与底气。
更全面、更快、更便宜,加速大模型应用爆发
生成式AI加速发展,开发者渴求更快、更便宜的推理算力,SiliconCloud将帮助开发者更低成本地使用大模型,降低大模型应用开发的门槛。
未来,我们将全方位支持大模型应用生态发展,推进主流开源大模型的可及性:一方面,免费送巨量token助力个人开发者打造创新应用,另一方面,助力大模型公司、AI应用公司实现推理的降本增效,进而促进大模型应用迎来大爆发,加速大模型的普惠化。
如果你想开发大模型应用,不用迟疑,现在就是最好时机。
而对于那些真正在乎大模型推理性能和成本的开发者,绝不会错过SiliconCloud。更何况,现在还送3亿token。
快试试吧:
www.siliconflow.cn/zh-cn/siliconcloud

















