���˹����ܺ�����ѧ�Ľ�������һ��ͻ�����о��ڹ���������㷺��ע��2024��ȼ�������ѧЭ�ᣨACL��������Ľ���������Ϊ����������������ģ�͡����о��������IJ���չʾ�˾��ɵ�ʵ����ƣ�������ս������ѧ̩����ķ˹���Ĺ۵㡣

ͼƬ��������
������������ķ˹��������ѧ�Ҽ����Ϊ����������ģ�ͣ�LLM��ͬ���ܹ�ѧϰ������ܺͲ����ܵ����ԡ���һ�۵�������������������LLM�������о��еļ�ֵ��Ȼ����˹̹����ѧ��Julie Kallini���о���ͨ��һϵ�������ʵ�飬�״�ϵͳ�ؼ��鲢������һ���衣���ǵ��о�������LLMȷʵ����ѧϰ"����������"����һ����ΪLLM������ѧ�о��е�Ӧ�ÿ������µĿ����ԡ�

�������ڿ���AI��Ʒ��Prompt����ʦ���ԣ�����LLM������ѧϰ����������Ҫ��
01
��ķ˹���Ĺ۵�������
ŵķ����ķ˹�����ִ�����ѧ�ĵ����֮һ���������۶�����ѧ�о���������ԶӰ�졣�����������Ŵ�������ģ�͵�������ķ˹������Щģ�͵�����ѧϰ������������ɡ�����Ϊ��LLM"�����ֿ��ܺͲ����ܵ�����"����������"�����ܱ���"��

ͼƬ��������
��ķ˹���Ĺ۵�õ���һЩ����ѧ�ҵ�֧�֡����磬Moro�������ƣ�"LLM���Բ���'������'�������������Ч�������ڣ�������Ǹ����ڣ���Ȼ�������"����Щǿ�ҵĶ����ƺ�����LLM�������о��еļ�ֵ��������ƪ�������й�����ķ˹����������Ĺ۵㣨��claude2���ɣ�
Ȼ������Щ�۵�ܴ�̶���ȱ��ʵ��֤�ݵ�֧�֡���Kallini���˵��о�֮ǰ��Ψһ���㷺���õ����ʵ���о���Mitchell��Bowers��2020��Ĺ��������ܸ��о�����Ҫ������ƾһ���о����Եó���˺��Ľ��ۡ�
02
���������ԣ�һ��ģ���ĸ���
�о���һ����ս���ڣ�"����������"������һ��������ȷ����ĸ������ѧ���Ƕ�ʲô�������������Ե��ձ��������Լ���Щ������"������"�ģ���δ��ɹ�ʶ��
Ϊ�˿˷���һ���ѣ�Kallini���������һ��"��������������"�ĸ��������������һ����ֱ������Ȼ�����ܵ����ԣ���������ҵ�Ӣ�ﵥ�����С���һ��������Щ���ܲ���ôֱ�ۣ���������ѧ�г�����Ϊ�Dz����ܵ����ԣ����������λ�õ������
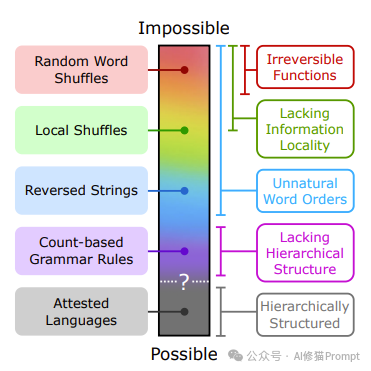
����ͼչʾ�����Ե�"������������"���Ӳ����ܵ����Խṹ�����ܵ����Խṹ��ͼ�д��ϵ������γ����˲�ͬ���͵�����������������ɫ�����ʾ������������������ϵĴ���λ�á�
1. ���Ϸ�����ɫ����"������ʴ���"��Random Word Shuffles����������Ϊ����ܵ����Խṹ��
2. ��������dz��ɫ����"�ֲ�����"��Local Shuffles�������������ܵ�һ�ˡ�
3. Ȼ����"��ת�ַ���"��Reversed Strings��������ɫ��ʾ��
4. �����£���ɫ����"���ڼ����������"��Count-based Grammar Rules����
5. ���·�����ɫ����"��֤ʵ������"��Attested Languages����������Ȼ���ڵ��������ԣ�λ�ڿ����Ե�һ�ˡ�
ͼ���Ҳ��г���һЩ��ص�����������
- �����溯��
- ȱ����Ϣ�ֲ���
- ����Ȼ�Ĵ���
- ȱ����νṹ
- ���в�νṹ������֤ʵ��������أ�
�м�����ߺ��ʺű�ʾ���ܺͲ���������֮���ģ���߽硣����ͼ��Ч���ܽ����о���̽�ֵIJ�ͬ���͵����Խṹ����ֱ�۵�չʾ�������ڿ�������ϵ�ϵ����λ�á�
�о����Ǿ��������һϵ�кϳɵ�"����������"��ÿ�����Զ�ͨ��ϵͳ�ظı�Ӣ�����ݵĴ������������������Щ���Ժ����˲�������������IJ�ͬλ�ã�Ϊʵ���ṩ�˷ḻ�IJ��Բ��ϡ�
03
ʵ����ƣ���սLLM�ļ���
�о��Ŷ������������Ҫʵ�飬ּ��ȫ������GPT-2С��ģ��ѧϰ��Щ���������Ե�������ʵ��ĺ������о��ߺϳ���һ�鲻���ܵ����ԡ�ͨ������Ӣ����ӵ��Ŷ�������ָ�������ܵ����ԡ���Щ�Ŷ�������Ӣ���������ӳ�䵽������С��о��߽����Է�Ϊ���ࣺ*SHUFFLE��*REVERSE��*HOPÿ���°������ֲ�ͬ�����Ա��塣ÿ�����Զ��������������䣬��չʾ���ض��Ĺ���ͽṹ��
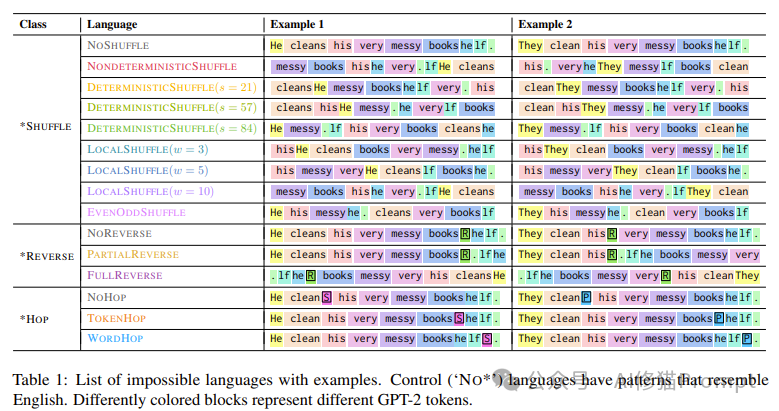
1. *SHUFFLE�ࣺ
- NOSHUFFLE������ԭʼӢ����ӽṹ����Ϊ�����顣
- NONDETERMINISTICSHUFFLE����ȫ������ҵ���˳��
- DETERMINISTICSHUFFLE�������ض�����������ֵ��ȷ���Եش��ҵ���˳��
- LOCALSHUFFLE���ڹ̶���С�Ĵ����ھֲ����ҵ���˳��
- EVENODDSHUFFLE���������е�ż��λ�ôʺ�����λ�ôʷֿ����š�
2. *REVERSE�ࣺ
- NOREVERSE���ھ������������һ��������R�������ı������Ϊ�����顣
- PARTIALREVERSE������R��ǣ�����ת�������е��ʡ�
- FULLREVERSE������R��ǣ�����ȫ��ת�������ӡ�
3. *HOP�ࣺ
- NOHOP��������ԭ�κ�ֱ�Ӽ��ϱ�ʾ�������ı�ǣ�S��P������Ϊ�����顣
- TOKENHOP������������Ƿ��ڶ��ʺ�ĵ�4����Ԫλ�á�
- WORDHOP������������Ƿ��ڶ��ʺ�ĵ�4������λ�á�
��Щ����������չʾ��ÿ��"����������"�ľ������ͽṹ��
ʵ��һ��ѧϰЧ�ʱȽ�
�ڵ�һ��ʵ���У��о�����ѵ��GPT-2ģ��ѧϰһϵ��Ԥ�ȶ���Ŀ��ܺͲ��������ԣ���ͨ�����Լ�����ȣ�perplexity��������ѧϰЧ�ʡ����������������ģ�����ܵij���ָ�꣬�ϵ͵�����ȱ�ʾģ�Ͷ����Ե�Ԥ���ȷ��
�о��ߵļ����ǣ�ѵ���ڿ��������ϵ�ģ�ͻ����ﵽ�ϵ͵�ƽ������ȣ���ѵ����������������ʵ��ֱ�ӱȽ���LLMѧϰ��ͬ�������Ե�������
ʵ���������������Բ���
�ڶ���ʵ��������̽����һ������IJ��������ԣ����ڼ����Ķ��ʱ�ǹ����о���ʹ�þ���ȣ�surprisal���Ƚ�������Եؼ������ģʽ��
����Ⱥ�����ģ�Ͷ�ij���ʵ�Ԥ�ڳ̶ȣ����Ǹô��ڸ����������г��ָ��ʵĸ��������ϸߵľ������ζ��ģ�ͶԸôʵij��ָ������⡣
�о����裬���ڿ������ԣ�ģ������Բ�����Ľṹʱ����ֳ����ߵľ���ȡ����ʵ��ּ�ڼ���GPT-2�Ƿ��ܹ�ϰ�ò���ѭ��Щ���ڼ����������
ʵ����������������
�ڵ�����ʵ���У��о��߸������̽����ģ���ڲ����ƣ���ͼ����GPT-2��η�չ��ѧϰ��Щ���ڼ��������������������Dz�������������������������һ�ֽ����������ڲ�����ԭ���ļ�����
���ʵ���Ŀ���ǽ�ʾģ���Ƿ�Ϊ��Щ����Ȼ���ģʽ��չ��ij����Ȼ��ģ�黯�Ľ��������
04
ʵ��������ս��ķ˹���Ķ���
����ʵ��Ľ����ǿ��������ս����ķ˹�����˵Ĺ۵㣬����GPT-2ȷʵ����ѧϰ���������ԡ�
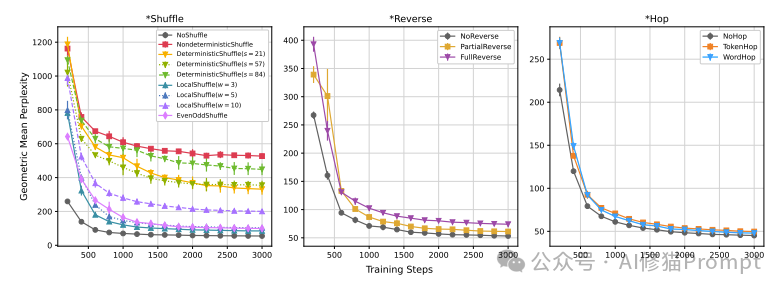
����ͼ��չʾ������"����������"��*Shuffle��*Reverse��*Hop����ѵ�������е�ѧϰ���ߡ������ʾѵ�����裬�����ʾ����ƽ������ȣ�Geometric Mean Perplexity����������Ǻ�������ģ�����ܵ�ָ�꣬��ֵԽ�ͱ�ʾģ�ͱ���Խ�á�
1. *Shuffleͼ��
- NOSHUFFLE��δ���ҵ�Ӣ����������ͣ�ѧϰ��졣
- NONDETERMINISTICSHUFFLE����ȫ������ң����������ߣ�ѧϰ������
- DETERMINISTICSHUFFLE��LOCALSHUFFLE�ı��ֽ�������֮�䣬�ұ�������ֲ��ṹ�ı��壨���С���ڵ�LOCALSHUFFLE�����ָ��á�
- EVENODDSHUFFLE�ı��ֽӽ�NOSHUFFLE��˵����������һ�������Խṹ��
2. *Reverseͼ��
- NOREVERSE��δ��ת��Ӣ�������á�
- PARTIALREVERSE��FULLREVERSE�ı�����������Բ���NOREVERSE��
- ����ģ�͵�ѧϰ���߲��첻��*Shuffle�����ԡ�
3. *Hopͼ��
- ����ģ�ͣ�NOHOP��TOKENHOP��WORDHOP���ı��ַdz��ӽ���
- NOHOP����ӽ���ȻӢ��İ汾�������ȡ�
- ѧϰ���߿���������˵��ģ���������ѧϰ�������
��Щ���ǿ������֧�����о��ĺ��ķ��֣�
1. GPT-2ȷʵ��ѧϰ"����������"ʱ���ֳ����ѣ��ر�����Щ��ȫ���һ�ת��������ԡ�
2. ����������Ȼ���Խṹ�ı��壨��NOSHUFFLE��NOREVERSE��NOHOP��ʼ�ձ�����ѡ�
3. �ֲ��ṹ�ı�������LOCALSHUFFLE��������ģ��ѧϰ��
4. ���ڼ����������*Hop�ࣩ�������ѧϰ����������Ϊ���DZ����˴�ԭʼ���ӽṹ��
��Щͼ�������ط�������ķ˹�����˵Ķ��ԣ�֤��������ģ��ȷʵ�ܹ����ֿ��ܺͲ����ܵ����Խṹ������ѧϰ�����б��ֳ�����Ȼ���Խṹ��ƫ�á�
ѧϰЧ�ʵ���������
�ڵ�һ��ʵ���У��о��߷���ѵ���ڿ��������ϵ�ģ��ȷʵ�ܸ���شﵽ�ϵ͵�����ȡ�������˵��
1. ����*SHUFFLE�����飨�������ֵ��ʴ��ҷ�ʽ����NONDETERMINISTICSHUFFLE����ȫ������ң�ģ�͵��������ߣ����������DETERMINISTICSHUFFLEģ�͡������GPT-2��ѧϰȷ���ԵĴ���ģʽʱ���ָ��á�
2. �ֲ����ң�LOCALSHUFFLE��ģ�͵�����ȴ�֮�����ڴ�СԽС�������Խ�͡���˵������һ���̶ȵľֲ��ṹ������ģ��ѧϰ��
3. EVENODDSHUFFLE����żλ�÷��룩��NOSHUFFLE��δ���ҵ�Ӣ�ģ���������ͣ���NOSHUFFLEʼ�ձ������ȡ�
4. ��*REVERSE�������У�ʵ��ģ��������飨NOREVERSE��������Ȳ���С����PARTIALREVERSE������FULLREVERSE��
5. *HOP�����飨�漰���ڼ����Ķ��ʱ�ǹ���ģ�ͼ������С������������Ȼ������ѡ�
��Щ�������ر�����GPT-2��ѧϰ���ӽ���Ȼ���Խṹ������ʱ���ָ��ã���������ЩΥ����Ȼ���Թ��ɵ�"����������"��ѧϰЧ�����Խϲ
�����ѧϰ�ľ�����
�ڶ���ʵ���һ��֤ʵ��GPT-2�������ղ���Ȼ��������о��߷��֣�
1. NOHOPģ�ͣ���ӽ�Ӣ��İ汾��������ѵ��������ʼ�ձ��ֳ���͵ı�Ǿ���Ⱥ���ߵľ���Ȳ��졣����ζ�Ÿ�ģ������ȷԤ���ǵij��֣����Ա�ǵ�ȱʧ��Ϊ���С�
2. TOKENHOP��WORDHOPģ����ȻҲѧ��������ȷλ���ڴ���ǣ���Ч����������顣TOKENHOP�ı���������WORDHOP���������ڴ�Ԫ���ǵ��ʵļ���������Ը�����ѧϰ��
��Щ���ֱ�������ȻGPT-2����һ���̶���ѧϰ���ڼ���������������Ը�ƫ�÷�����Ȼ����ģʽ�Ĺ���
ģ���ڲ����ƵĽ�ʾ
������ʵ��������������ṩ��ģ����δ�����Щ����Ȼ�ģʽ�����붴�죺
1. ��������*HOPģ�Ͷ���չ�������Ƶ�ģ�黯���������������νһ������������ǰ�������������Ϣ��Ȼ���ں㽫����Ϣת�Ƶ���ҪԤ���ǵ�λ�á�
2. NOHOPģ�ͣ�����Ȼ�İ汾������γ����ֻ��ƣ��ڴ�Լ1500ѵ�������ʹﵽ�˽������������ܡ�
3. TOKENHOP��WORDHOPģ����ȻҲ�γ������ƵĻ��ƣ���Ч�ʽϵͣ���Ҫ����ѵ�����ܴﵽ���Ƶ�����ˮƽ��
��Щ�����������ʹ��Բ���Ȼ�������GPT-2Ҳ��ͼ��һ�ֽṹ����ģ�黯�ķ�ʽ��������⡣Ȼ�������ڴ������ӽ���Ȼ���ԵĽṹʱ���Ը���Ч�ʡ�
05
LLM������ѧ��ֵ�ع�
������������������һ����Ҳ�����������ʺͷ�˼����������һ����������⣺ƾʲô��һ����ʱ��Сģ��GPT-2�Ͷ��Խ����Ʒ���ķ˹���۵㣿�����Claude 3.5 Sonnet��GPT-4�Ͻ�������ʵ�飬���ۻ������������Ҷ�ACL�о���ѧ���Ͻ��Բ������ɡ�
����Ȼ����Щ�����Ƚ���ģ�Ϳ���չ�ֳ���ǿ��ѧϰ������������"����������"Ҳ�ܱ��ֵø��ã��о����ṩ�˴���https://github.com/jkallini/mission-impossible-language-models�����Ҳ�δ������ģ�ͽ��в��ԣ����������Ȥ��������һ�´��룬������ҽ�����Һ�����Ȥ�˽⣩����ģ�Ϳ����ڴ���������������������������������ơ��������������ƣ���ƫ����Ȼ���Խṹ��������Ȼ���ڣ�ֻ�Dz�����ܲ���ô���ԡ����Ͻ����ҶԷ�˼�ļ��衣
ʵ���ϣ������о����ڷ����۷����ȷ����˴��¡�����ģ��ѡ����ھ��ޣ����о��ķ����ۡ������"����������"�ͽ���ϵͳ��ʵ�顪���������д����Ժͼ�ֵ�����ַ���Ϊ��������ģ�͵������ṩ���µ��ӽǡ����⣬���о���Ȼ������ѧ���ۺ��˹������о��������Ȥ�����⣬��ս��һЩ���ڴ��ڵļ��衣�����ϵ�����������ǻ�����һ��������
����ͬ���ǣ������о��Ľ��������ģ���о��Ϳ���������Զ����ʾ��
1. LLMȷʵ�ܹ����ֿ��ܺͲ����ܵ�����
����ķ˹�����˵Ķ����෴���о��������LLM��ѧϰ������ܺͲ����ܵ�����ʱ���ֳ����Բ��졣����ζ��LLM����ȷʵ������ijЩ����������������صı����������˽�LLM������ѧϰ��Щ���͵����Խṹ����������Ƹ���Ч����ʾ��Prompt�������磬���־ֲ��ṹ�������Կ���������ģ���õ�������������ݡ�
2. LLM��Ϊ�����о����ߵ�DZ��
��ȻLLM�ܹ����ֿ��ܺͲ����ܵ����ԣ����ǾͿ��ܳ�Ϊ�о����������ձ��Ժ������Ե��������ߡ��о�����LLM�ڴ�������Ȼ�����ԽṹʱЧ�ʽϵ͡���ˣ��������ʾ��Prompt��ʱӦ��������ʹ��Υ����Ȼ���Թ��ɵĸ��ӽṹ�����ƺ�����Ļ𱬵�Super prompt���Ʒ�����һ�㣬���Ⲣ��Ӱ������дPromptʱӦ����ѭ��Ȼ���Թ��ɡ�
3. ģ�ͼܹ����ڲ����Ƶ���Ҫ��
�о����֣���Ԫ����tokenization����λ�ñ�����ض��ļܹ�����Ӱ��ģ�Ͷ���Ȼ���Ե�ƫ�ó̶ȡ�����ʾ���ǣ������LLM��Promptʱ��Ҫ����������Щ���ء����磬����ģ�Ͷ���νһ�µĴ�����������ǿ���ɵ������ԡ�
4. ��Ȼ���Ե������λ
ʵ��������ǿ������Ȼ���Խṹ��LLMѧϰ����Ҫ�ԡ��������ζ����Ȼ������ȷʵ����ijЩ���ʵġ�������ѧϰ�����ԡ�
5. ��"����������"���������˼��
�о������"��������������"����Ϊ�������ԵĿ����ԺͲ��������ṩ���µ��ӽǡ�����ܴ�ʹ����ѧ��������˼����ζ�����о����Եı߽硣
6. ������������Ĺ�עģ�͵ľ�����
�о���ʾģ���������þֲ���������Ϣ��Prompt����ʦ����ͨ���ṩ�ḻ����ص����������Ż�ģ�����ܡ�����ģ����ѧϰijЩ���Խṹʱ�����ѣ�������Ԥ��ͱ�����ܵĴ������磬�漰���Ӽ����������������������Ҫ�ر�ע�⡣
�����Ƽ�
����Ϊ��LLM������ѧϰ�������������������ICL���ڲ�������� |���·���
Kallini���˵��о�������ս����ķ˹��������ѧȨ���Ĺ۵㣬�����о�Ҳ�������ǣ�ģ�ͺ����������Դ��������Դ��ڸ������졣���磬ģ�ͶԴ�Ԫ���������Լ��������̬�߽�������ԣ�������Ҫ��һ���о�����Ҫ���졣
ͬʱ�����о�Ҳ�������ǣ�����Ӧ�õ�ͬʱ����Ӧ���Ӷ�ģ�ͻ��������;����ԵĿ�ѧ̽����ֻ�н�����ʵ�����ѧ�о����ܽ�ϣ����Dz��ܿ�������ǿ�����ܵ�Ӧ�á�

















