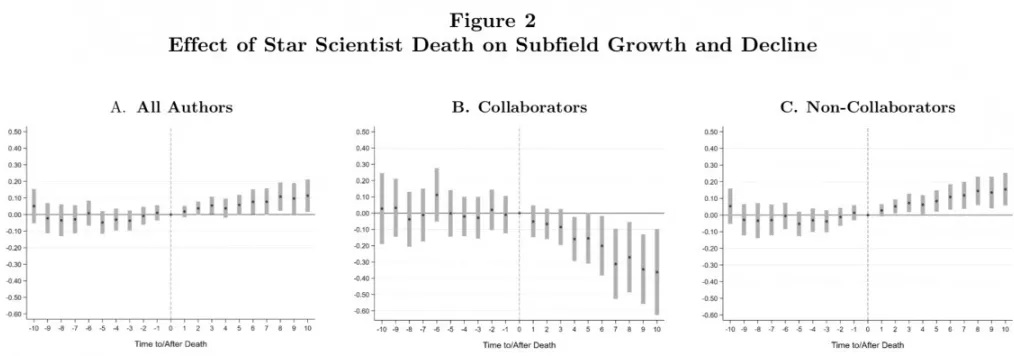
我最近也在准备参加 Kaggle,之前看过几个例子,自己也总结了一个分析的流程,今天看了这篇文章,里面提到了一些高效的方法,最干货的是,他做了一个表格,列出了各个算法通常需要训练的参数。
这个问题很重要,因为大部分时间都是通过调节参数,训练模型来提高精度。作为一个初学者,第一阶段,最想知道的问题,就是如何调节参数。因为分析的套路很简单,就那么几步,常用的算法也就那么几个,以为把算法调用一下就可以了么,那是肯定不行的。实际过程中,调用完算法后,结果一般都不怎么好,这个时候还需要进一步分析,哪些参数可以调优,哪些数据需要进一步处理,还有什么更合适的算法等等问题。
接下来一起来看一下他的框架。
据说数据科学家 60-70% 的时间都花在数据清洗和应用模型算法上面,这个框架主要针对算法的应用部分。
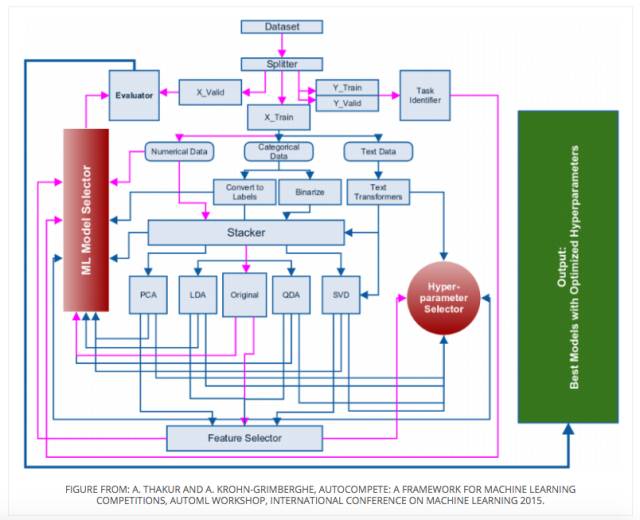
Pipeline
什么是 Kaggle?
Kaggle是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决,可以通过这些数据积累经验,提高机器学习的水平。
应用算法解决 Kaggle 问题,一般有以下几个步骤:
-
第一步:识别问题
-
第二步:分离数据
-
第三步:构造提取特征
-
第四步:组合数据
-
第五步:分解
-
第六步:选择特征
-
第七步:选择算法进行训练
当然,工欲善其事,必先利其器,要先把工具和包都安好。
最方便的就是安装 Anaconda,这里面包含大部分数据科学所需要的包,直接引入就可以了,常用的包有:
第一步:识别问题
在这一步先明确这个问题是分类还是回归。通过问题和数据就可以判断出来,数据由 X 和 label 列构成,label 可以一列也可以多列,可以是二进制也可以是实数,当它为二进制时,问题属于分类,当它为实数时,问题属于回归。
第二步:分离数据
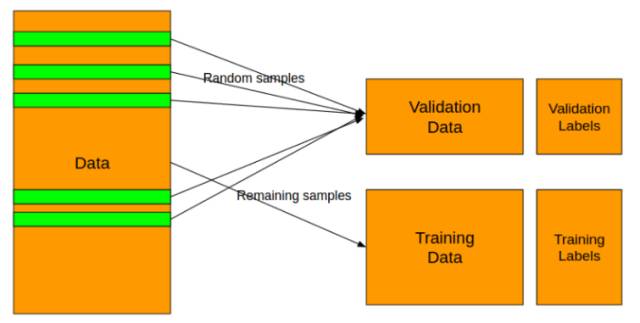
为什么需要将数据分成两部分?
用 Training Data 来训练模型,用 Validation Data 来检验这个模型的表现,不然的话,通过各种调节参数,模型可以在训练数据集上面表现的非常出色,但是这可能会是过拟合,过拟合就是太依赖现有的数据了,拟合的效果特别好,但是只适用于训练集,以致于来一个新的数据,就不知道该预测成什么了。所以需要有 Validation 来验证一下,看这个模型是在那里自娱自乐呢,还是真的表现出色。
在 scikit learn 包里就有工具可以帮你做到这些:
分类问题用 StrtifiedKFold
from sklearn.cross_validation import StratifiedKFold
回归问题用 KFold
from sklearn.cross_validation import KFold
第三步:构造特征
这个时候,需要将数据转化成模型需要的形式。数据有三种类型:数字,类别,文字。当数据是类别的形式时,需要将它的每一类提取出来作为单独一列,然后用二进制表示每条记录相应的值。例如:
record 1:性别 女
record 2:性别 女
record 3:性别 男
转化之后就是:
女 男
record 1:1 0
record 2:1 0
record 3:0 1
这个过程 sklearn 也可以帮你做到:
from sklearn.preprocessing import LabelEncoder
或者
from sklearn.preprocessing import OneHotEncoder
第四步:组合数据
处理完 Feature 之后,就将它们组合到一起。
如果数据是稠密的,就可以用 numpy 的 hstack:
import numpy as np
X = np.hstack((x1, x2, ...))
如果是稀疏的,就用 sparse 的 hstack:
from scipy import sparseX = sparse.hstack((x1, x2, ...))
组合之后,就可以应用以下算法模型:
-
RandomForestClassifier
-
RandomForestRegressor
-
ExtraTreesClassifier
-
ExtraTreesRegressor
-
XGBClassifier
-
XGBRegressor
但是不能应用线性模型,线性模型之前需要对数据进行正则化而不是上述预处理。
第五步:分解
这一步是为了进一步优化模型,可以用以下方法:
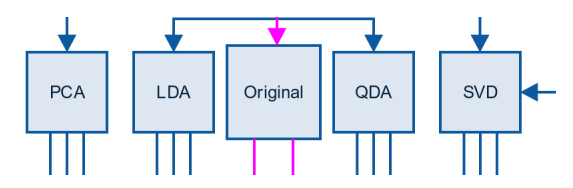
PCA:Principal components analysis,主成分分析,是一种分析、简化数据集的技术。用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。
from sklearn.decomposition import PCA
对于文字数据,在转化成稀疏矩阵之后,可以用 SVD
from sklearn.decomposition import TruncatedSVD
SVD:Singular Value Decomposition,奇异值分解,是线性代数中一种重要的矩阵分解,它总能找到标准化正交基后方差最大的维度,因此用它进行降维去噪。
第六步:选择特征
当特征个数越多时,分析特征、训练模型所需的时间就越长,容易引起“维度灾难”,模型也会越复杂,推广能力也会下降,所以需要剔除不相关或亢余的特征。
常用的算法有完全搜索,启发式搜索,和随机算法。
例如,Random Forest:
from sklearn.ensemble import RandomForestClassifier
或者 xgboost:
import xgboost as xgb
对于稀疏的数据,一个比较有名的方法是 chi-2:
from sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2
第七步:选择算法进行训练
选择完最相关的参数之后,接下来就可以应用算法,常用的算法有:
Classification:
Random Forest
GBM
Logistic Regression
Naive Bayes
Support Vector Machines
k-Nearest Neighbors
Regression
Random Forest
GBM
Linear Regression
Ridge
Lasso
SVR
在scikit-learn里可以看到分类和回归的可用的算法一览,包括它们的原理和例子代码。
在应用各算法之前先要明确这个方法到底是否合适。
为什么那么多算法里,只提出这几个算法呢,这就需要对比不同算法的性能了。
这篇神文 Do we Need Hundreds of Classifiers to Solve Real World Classification Problems 测试了179种分类模型在UCI所有的121个数据上的性能,发现Random Forests 和 SVM 性能最好。
我们可以学习一下里面的调研思路,看看是怎么样得到比较结果的,在我们的实践中也有一定的指导作用。
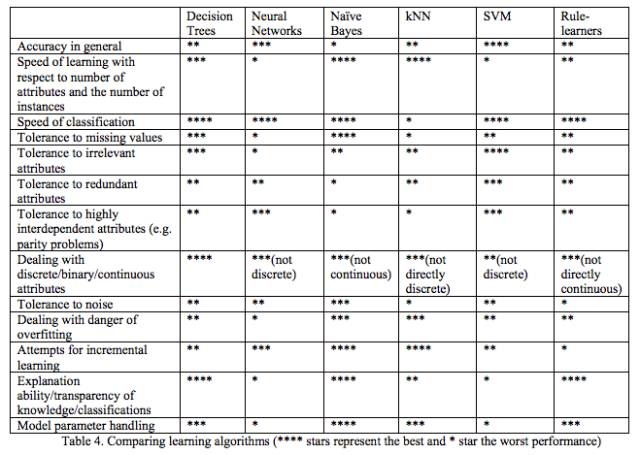
各算法比较
但是直接应用算法后,一般精度都不是很理想,这个时候需要调节参数,最干货的问题来了,什么模型需要调节什么参数呢?
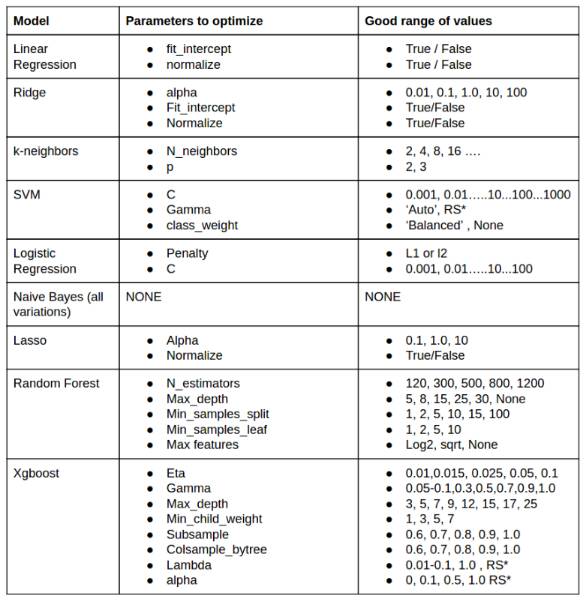
虽然在sklearn的文档里,会列出所有算法所带有的参数,但是里面并不会说调节哪个会有效。在一些mooc课程里,有一些项目的代码,里面可以看到一些算法应用时,他们重点调节的参数,但是有的也不会说清楚为什么不调节别的。这里作者根据他100多次比赛的经验,列出了这个表,我觉得可以借鉴一下,当然,如果有时间的话,去对照文档里的参数列表,再查一下算法的原理,通过理论也是可以判断出来哪个参数影响比较大的。
调参之后,也并不就是大功告成,这个时候还是需要去思考,是什么原因造成精度低的,是哪些数据的深意还没有被挖掘到,这个时候需要用统计和可视化去再一次探索数据,之后就再走一遍上面的过程。
我觉得这里还提到了很有用的一条经验是,把所有的 transformer 都保存起来,方便在 validation 数据集上面应用:
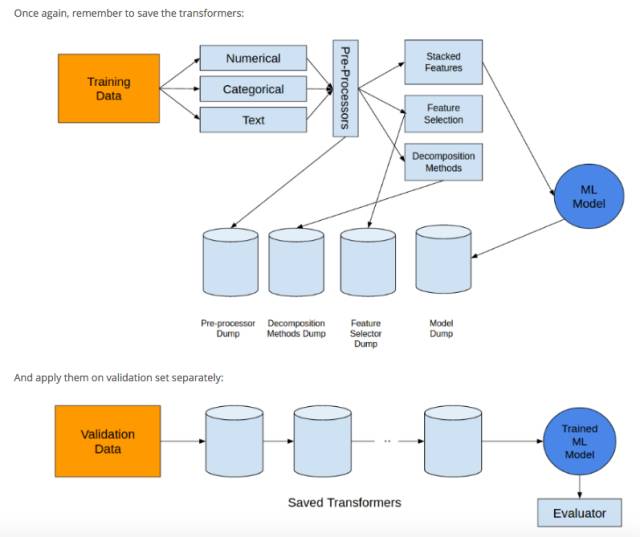
文章里介绍了分析问题的思路,还提到了几条很实用的经验,不过经验终究是别人的经验,只能借鉴,要想提高自己的水平,还是要看到作者背后的事情,就是参加了100多次实战,接下来就去行动吧,享受用算法和代码与数据玩耍的兴奋吧。
文/不会停的蜗牛(简书作者)