
做理工科的同学很擅长纯粹的科技,其实科技和人文的结合更有意思,我希望在座的同学在参加编程之美大赛的时候,能够脑洞大开,想出一些奇思妙想的东西,超越前辈,做得更好。
今天我要介绍一下自然语言对话。其实微软小冰就是在模拟人跟电脑的对话。电脑接收文字、图像或者语音,识别其中的内容,然后给予适当的回复。有的回复很有意思,让人觉得好像电脑后面就坐着一个真实的人,但有的时候回复也差强人意,而这正是我们这次编程之美所期待的,希望大家一起加入到人机对话的创新过程中,把人机对话做的更好。
我们团队在微软做自然语言人机对话方面的研究,并提供了小冰的关键自然语言处理技术。下面我将介绍一下人机对话机理,希望对大家有所帮助。
人机对话有三个层次,一个是聊天,一个是问答,还有一个是对话,即面向某一特定任务的对话。比如,我要买东西时,一进门,售货员会打招呼说,“你好!”,我回复“你好”。接着她会问“你想看看什么?”,我说“我想买两包方便面”。她问“什么牌子的呢?这个三块钱一包,这个五块钱一包”,我说“那要三块钱一包的吧。”她说“那好,你用支付宝还是微信付款呢?”我说“微信”。她说“好,这就是你买的东西”。
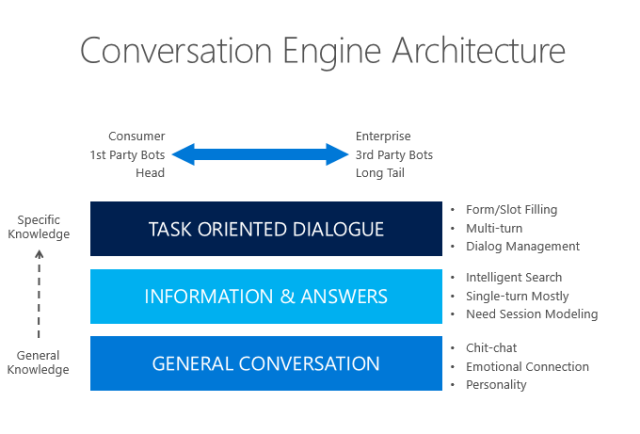
可以注意到,在我们每天都会产生的这些对话中实际上包含了三个最基本的人类智力的活动。第一个,聊天。聊天一般没有太多实质性的内容,主要是拉近人与人之间的关系;第二个就是问答,比如“你买什么东西”,“这个方便面多少钱一包”,这是提问,它的目的是提供信息;第三个,面向特定意图的对话。比如售货员知道我的意图是买方便面,开始围绕这个意图跟我进行了有目的的对话。最终我完成支付行为,售货员把方便面放到我手上。这三个技能是我们在研究人机对话当中最重要的三个技能。
最近几年,深度神经网络逐渐取代了传统的统计机器学习,成为主流的研究方向。现在,自然语言技术已全部转向深度学习网络,我们的对话系统也都用到了深度学习网络,所以先向大家介绍一下深度学习网络。
深度学习网络一般有一个输入层,一个输出层,中间有N层是神经网络,他们之间通过一种连接方式以不同的权值来发挥作用,当输入时,根据神经网络的权值逐层推进,就会得到一个输出。
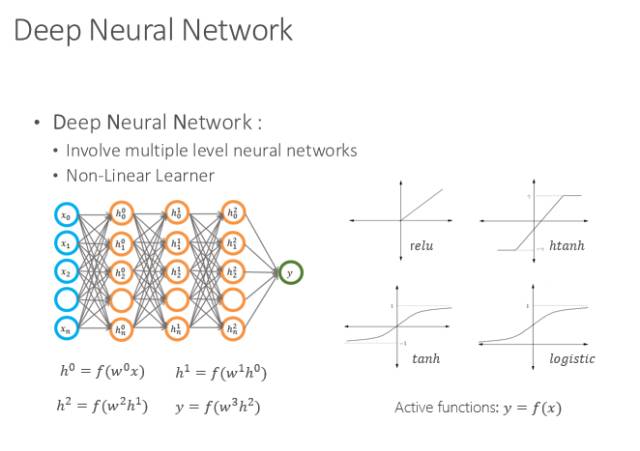
其实在训练的时候有很多样本,输入和输出是对应的。当输入到神经网络时,有的时候会发现结果不对,那么则可以根据它与答案之间的差距进行反向传播并修正参数。当网络趋势越来越好,那么到一定时候网络就可以收敛,进而网络就达到了一定的智能行为,这就是最简单的神经网络架构。
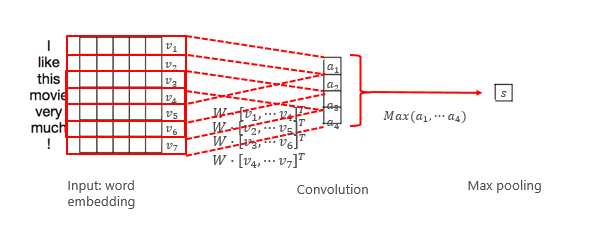
再来说一下常见的卷积神经网络的基本原理,我们以低密、低维的卷积神经网络为例。它实际上是从头开始,会以一个小的窗口进行滑动,每个窗口截取一定的信息,并抽取出来做卷积,这叫卷积的行为。而每次滑动都会得到一个值,最后得到一个卷积的结果。一般卷积之后还可以抽取最大值,这整个过程都体现了信息抽取的过程。
第二个比较常用的是二维的卷积,它是在矩阵里找一个小的窗口滑动,每个窗口通过卷积得到一个值,再通过填充所有窗口可以滑动的位置最后得到结果,这就是二维卷积的过程。
第三个叫循环神经网络(RNN,也叫递归神经网络),它描述的是一个序列串的过程。任何位置的输出都受限于前一位置或前一状态的位置信息,我们叫隐状态ht-1的信息,它和当前的输入字符串的信息一起会得到当前的隐形状态ht,然后根据这个当前的隐状态再预测每个词的输入概率。

循环神经网络训练完以后,任何句子都可以走这样的循环神经网络了,它的结果是由N个隐状态组成,而最后的隐状态,我们则可以认为它继承了前面所有句子、词的信息。
当然,每个位置也代表了到目前为止句子的信息,所以使用时,要么用最后一个结点,要么就把结点全用起来,形成一个向量来代表当前句子的编码。这样训练就比较简单了,一个句子进来走一遍刚才的这个过程,就可以得到每一位置词的输出概率,这些概率之乘就是这个循环神经网络的损失函数,然后根据损失函数,用反向传播去修正网络的连接强度,最后等网络稳定时就可以得到循环神经网络。
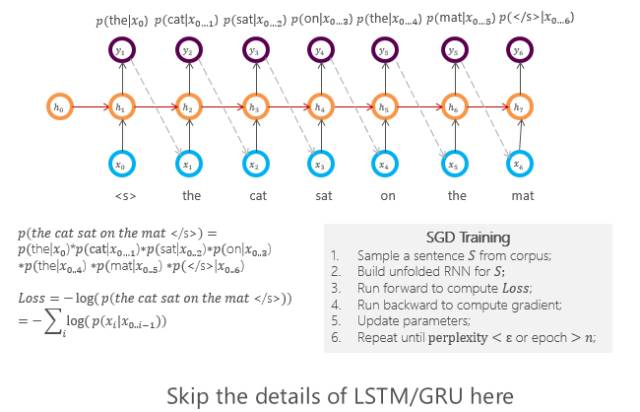
所以,只要有大规模的语料库,通过这种训练方法就会形成一个描述当前语料库每个句子的循环神经网络。
再来介绍一下刚才所说的三种对话的功能。第一个,聊天是怎么做的,这样的人机对话是怎样形成的?其实一般有两种办法。一种很简单,就是将网上的论坛、微博或是网站里出现过的对话句子抽取出来,当成训练语料库。当来了一个句子时,系统会从语料库里找到一个跟这个句子最相像的句子,而这个句子对应的答复就可以直接输出作为电脑的回复。虽然看起来这个方法简单粗暴,但有时候还是挺有效的。
然而有的时候,系统找到的句子可能对应了很多回复,它不知道哪个回复最适合当前的输入语句。所以这里就要有一个匹配的过程,就是怎么判断输入语句跟语料库里的回复在语义上是相关的或者是一致的。
这里就有了很多度量的方法,给大家介绍其中的两种。
第一种,如下图,q代表当前输入的语句,r代表目前的一个回复,想看q和r是否相关或者一致,要给它一个分数。如果有多个选择时,首先要把所有的东西排下去,输出最佳的分数,即实际上是对整个句子进行编码,对问题、回复进行编码。编码的方式可以用循环神经网络,也可以用卷积神经网络,也可以用最简单的就是每个维度取平均值,最后算一下这两个向量之间的距离。
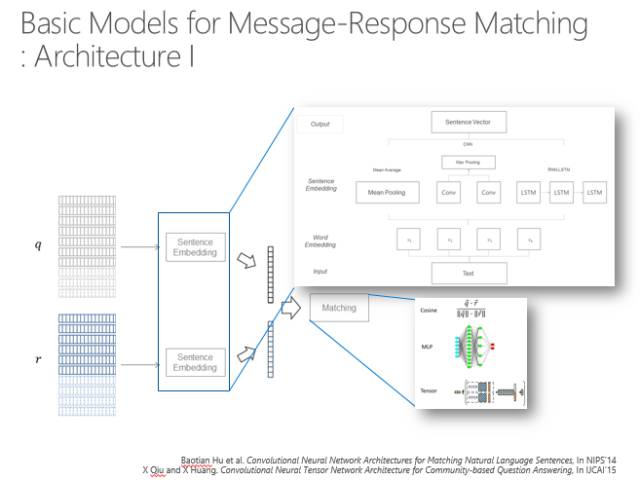
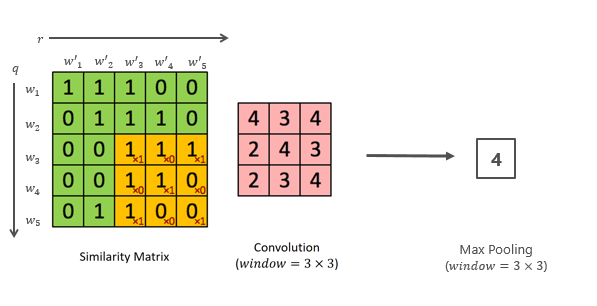
第二个方法也比较简单,就是把问题和回答的每个词都算一个距离,这样就形成了一个相似度的矩阵,通过卷积得到矩阵变换的信息,然后再取最大池化层,矩阵的维度就越来越小,最后可能就做到一个结点上。这个可以有多种变换,那么最后就会有一组结点,所有的结点其实都代表了这两个字符串之间的距离,再通过多层感知就可以算出句子。
然而这些方法都有一个问题,就是短字符串匹配的时候太依赖于自己的信息了。而我们日常说话时往往是有背景、有常识的,我们说的每句话都有一个主题词表。比如我来到了清华三食堂,那这个背后的主题词可以说吃饭、早饭、中饭、晚饭、价钱、饭卡等,这些词都是跟它相关的主题词,匹配的时候要体现出这些主题词。
怎么体现呢?首先找出输入语句的N个主题词,然后再找出可以回复的那些句子的主题词,用主题词来增强匹配的过程。这也是通过神经网络来算两个词串,再加上主题词增义的相似度。
具体算法实际上是通过Attention model(注意力模型)计算每个主题词跟当前这句话的匹配强度,所有主题词根据强度不同进行加权以体现当前背景主题词的强度,然后再和原句匹配在一起,来算相似度。
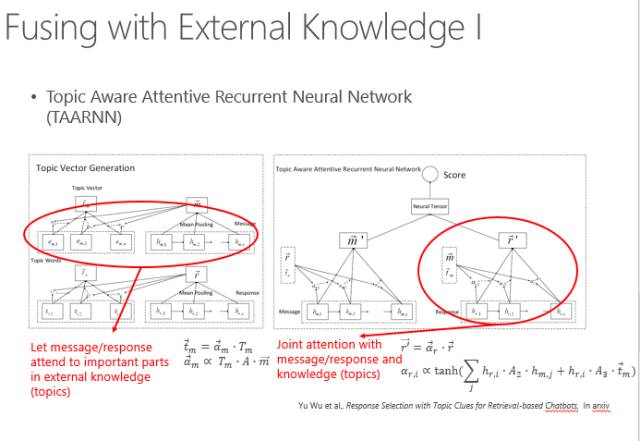
另外,我们也可以把主题词当成所谓的Knowledge base(知识图谱),通过主题词限定当前的输入应该有哪些信息可以输出,哪些信息不要输出,哪些信息应该补足,哪些信息可以直接使用等等。实际上在具体实现时可以看到一个句子有三种表示方法,两个句子之间每个句子都有三种表示方法,用两两表示方法计算距离,最后就会得到一个矢量,再通过多层感知得到一个数值,来表征这两个输入串的距离。所以,这两个输入串不是赤裸裸地直接去匹配,而是用周围知识所代表的主题词来增强。
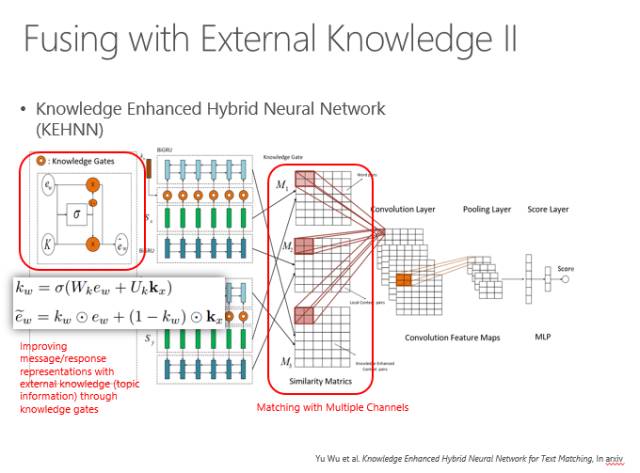
以上是基于搜索的一种回复方法,我们也可以用生成模型,其实生成模型走的也是神经网络的路线。输入一个句子,然后通过循环神经网络进行编码,再通过解码的过程输出每个词。当机器翻译的时候是跨语言的输出,由原文输出译文,而在古诗里是第一句生成第二句,在这里就是输入一个用户的问题得到一个系统的回复。
这就是一个生成的过程,可以看到图中下部是进行一个句子的编码,用这个编码指导每一个词的输出,在输出时既考虑原始句子的编码,也考虑前面的词输出什么样的词以及前面的隐状态是什么,最后传递输出,直到输出词尾。
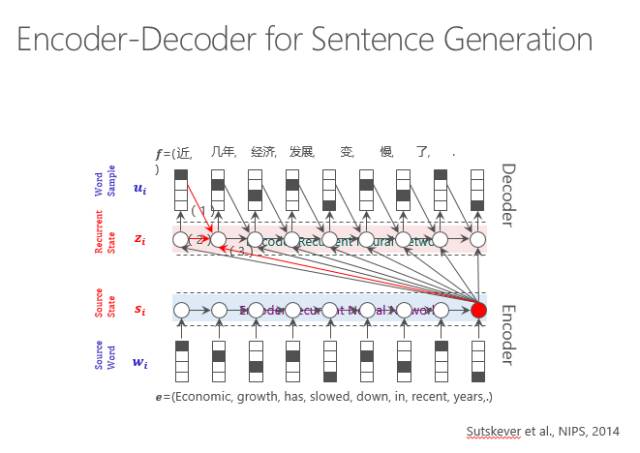
实际上,输出时不能一而贯之所有的词都等价对待。有的词权重比较高,这就由Attention model来体现输出某一类词时,哪个源端词对它的影响力最大,要体现在输出的概率方面。
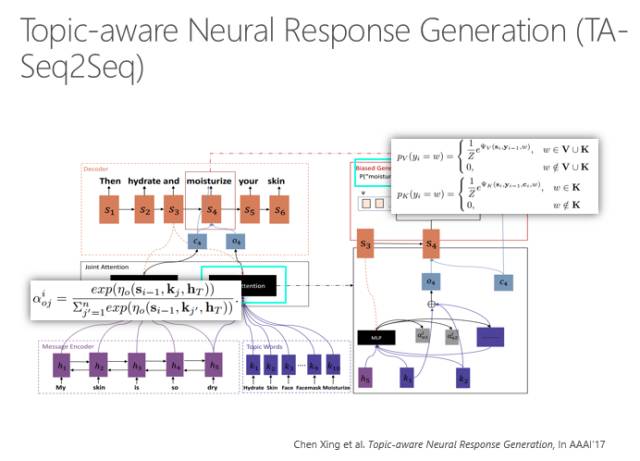
用传统的RNN以及注意力模型就可以做问题输入,系统回复。但是它也有很多问题,比如它的回答太枯燥不丰富,那怎么办?
我们要用到外部知识来丰富回答。我们可以用主题词增义。原始的句子可以用Attention model输出每个位置的词,然后再增强跟这个句子有关的主题词,把主题词编码,也做一种Attention model来预测输出。一个词的输出除了来自源端的信息之外,还受到了主题词的制约,最后输出的概率是这两个输出预测结果的概率之和,选择一个最优的来输出。
刚才说的是单轮的,现在说多轮怎么回答,因为人在说话的时候是考虑上下文的,不是只看当前的一句话,多轮的信息都要考虑进去。所以要把整个对话(session)考虑进去,对session进行编码,用session来预测输出的回复。
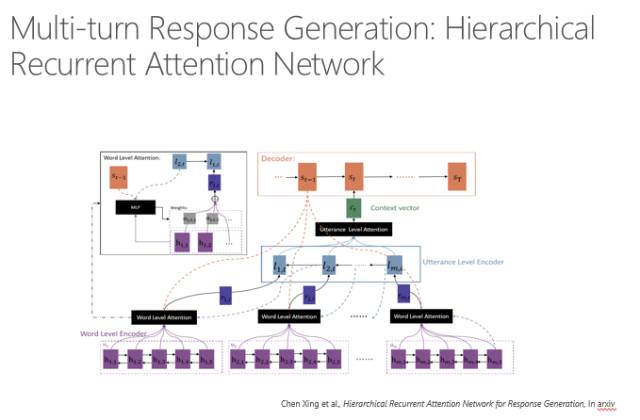
在计算的时候,我们有几个这样的模型。刚才是基于搜索的方式,还可以用多层感知的方式来模拟多轮对话。对每一个之前出现的句子进行编码,每个编码都可以通过一个句子的编码体现整个句子的信息,再通过Attention model跟目标连接,最后预测的时候就是通过基于句子的Attention model来预测。大家可以理解为我们在回复的时候既要看到前面哪一句话重要,还要看到那一句话里哪个词重要,所以是一个双层的Attention model。
以上是关于聊天的介绍,还有问答和对话。
问答就是用户有问题,系统要理解这个问题,然后利用系统所有的资源来回答这个问题,资源可能是FAQ、文档、表格、知识图谱等等,哪一个回答出来了,就说明哪一个是答案,如果有多个资源都可以回答问题,那我们选取那个最有可能的来进行输出。
简单说一下所谓Knowledge base(知识图谱)有两条路走,一条是对用户的问题进行语义理解,一般用Semantic Parsing(语义分析),语义分析有很多种,比如有用CCG、DCS,也有用机器翻译来做的。它得到了一个句子的逻辑表示,根据逻辑表示再到知识库里去查,查到这个结点是什么,关系是什么等,通过这种方式,自然而然就查到了。
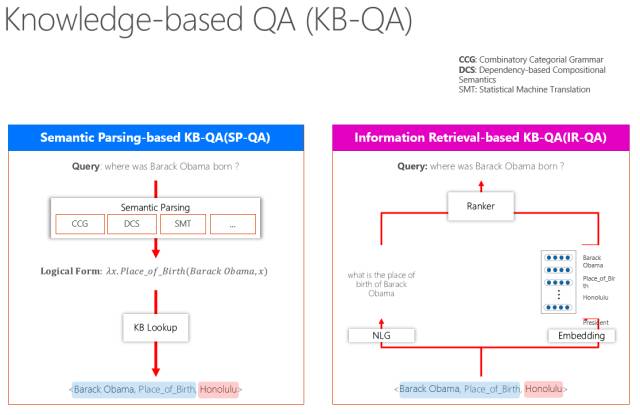
还有一种办法就是最近几年流行的信息检索方法。比如,一个问题“where was Barack Obama born ?”这句话里出现的了一个实体――Obama,假设这个知识库是完备的,那么系统就会判断答案一定是跟Obama关联的某个结点,这样就可以到知识库里以Obama为半径,把跟它有关的词全部挖出来,然后系统要算相似度,相似度算的时候有一种办法,是把这个知识图谱的某一个知识单元用自然语言表征出来,也可以用词嵌入做一个多维向量表示。这时候做一个Ranker跟当前的问题算一个距离,距离近的就是它的答案。我们也将这些技术运用在了微软小冰里,比如小冰回答问题,跟你聊天等等。我们还做了京东商城里的导购。
怎么在京东商城里通过对话过程来实行导购呢?实际上就是对用户输入的话,检测意图是什么,如果检测不到,系统就判断可能是聊天,然后通过聊天的引擎进行沟通。如果检测到意图,比如知道用户是要订旅馆,那么就有对应的订旅馆的对话状态表记录目前进行的状态及要填充哪些信息。
系统知道要填什么信息的时候,就会生成相应的问题让用户回答,用户回答完之后系统再把信息抽取过来填充到这个表里,直到所有的信息全部填充完毕,就完成了这个任务的对话过程。
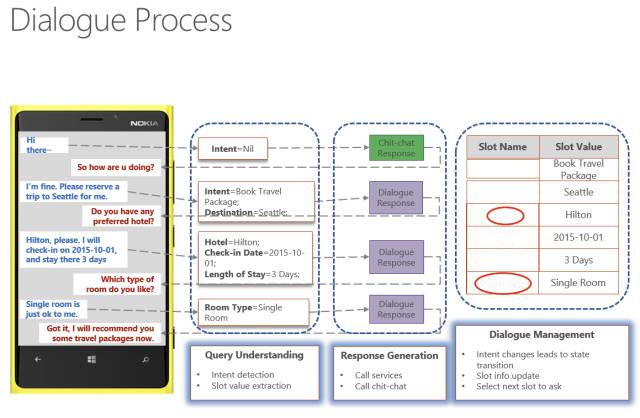
这里就涉及到了对问题的理解,问题中有哪些信息要抓取出来,还有对话管理,比如状态的转移,slot的填充或者更改,选择一个新的slot开始对话,以及如果要决定填充哪个slot的时候,怎么生成对话可以让用户很自然地回答这个问题,从而获得系统所需要的信息。
今天简单的给大家介绍了三个关键技术,这三个技术每个都不容易,我们现在虽然取得了一定的成绩,但还有很多问题需要解决,也期待大家运用自己的智慧把这个领域推进一步,更好的解决难题。
在未来有三件大事非常重要,第一个就是如何更好地来为上下文或者是多轮对话建模,目前还是用比较粗糙的信息表示方法来做,没有精确的来断定前文出现了哪些具体的信息,将来我们可以用信息抽取的方法把这些信息记录下来,引导未来的对话。
第二个,个性化的信息如何指导生成个性化的回复。最后,现在的回复也是千篇一律,大人、小孩、男孩、女孩,可能都是一样的,但人们在实际对话中面对不同的人群是不一样的,如何能够对回复的风格进行自动调整,使对话更加丰富多彩,这也是目前的一个挑战。


















