今天我主要讲的是在金融方面的应用。在这之前有很多年,我也曾在学校里面工作,一个坎又一个坎,跳了很多的坑。我们今天的主题是知识管理,从2005年到2012年期间,我自己就写了很多的知识管理系统,包括2008年的时候,去了RPI(注:美国伦斯勒理工学院)——这个领域里最好的一个学校,在哪里我写了一个知识管理系统,但整个实验室的人都没有用起来。
我当时就在痛苦地反思,我们是世界上最好的做知识管理的一群人,我们挺自信的并且很懂这件事情,为什么我们做出来的东西,自己也不用?一定有什么地方出错了。我那个系统后来可以说失败了,然后实验室又重新来做,又花了两年时间,又不知道花了多少钱,重新基于RDF做了一套知识管理系统,那个系统最后又失败了。
失败的项目是好的例子,尤其是在知名机构的失败。大多数的人工智能的项目最后都是失败的。有一句话说,如果你去过香肠工厂,你就再也不想吃香肠了。如果你做过一个人工智能的项目,你可能就再也不想做人工智能了。大多数的人工智能的项目,就好像智障。可能这也是因为这个领域还是处于发展早期的阶段,很多标准件还不存在,很多路还要人去趟,现在还没有趟出来,每趟一条路都是要有无数的项目的尸体在前面铺着,才能把这条路给趟出来。整个知识管理领域,从40年前诞生到现在,一点一点落地,可以说这个落地非常地艰难。到了2012年的时候,才真正的有了一个比较明确的大规模应用的前景,这之前30多年时间,一直都是痛苦地在黑暗中摸索。
我今天讲的这一块主要是讲在金融领域咱们走的一些路,有一些是弯路。我个人的学术经历基本上都是在做语义网和知识管理方面的工作,在这之前也做过一些神经网络和机器学习的工作,跟今天的工作相关的主要是两段经历,一个是在MIT的时候,做了XBRL的语义化,再有就是最近几年时间,做了金融搜索和金融知识图谱自动化问答,在文因互联这个公司。
简单介绍一下文因互联,我们是在北京的一个小公司,这个名字的意思就是“文化的基因的互联”,英文叫 Memect,前4个字母,“Meme”是英文里面的一个单词,有人翻译成模因,我把它翻译成文化的基因,简称“文因”。

知识图谱能帮金融做什么?
知识图谱能帮金融做什么?简单来说,就是把现在金融领域里面大家做的一些简单重复劳动给替代掉。会有人问,金融知识图谱能不能做出比人更好的投资决策?这是大家最关心的问题,我说不能,至少短期内不能。有时候,在金融机构里有一些朋友就会问,这个东西不能够提高投资的回报率吗?我说不能,不能长期、大量的保证。他说那你能干什么?我说能提高效率。他会问提高效率有什么用?
这是一种非常经典的误解。当提到人工智能,特别是看到人工智能在媒体上那么火的时候,大家第一个想法就是人类要被人工智能毁灭了,就那种感觉。其实这种感觉并不太好。因为在历史上已经出现过两次这种感觉了,每一次这种感觉之后,最后不是人类被毁灭了,而是我们(人工智能从业者)被毁灭了。因为大家觉得我们是骗子,所以每次大家有这种感觉的时候,我是挺慌的。我就会老老实实告诉他,咱们现在真的做不了特别大的事情,咱们也就最多只能去替代一些初级的劳动,虽然这个人群的数量已经不少了。
以我们现在技术能够落地的场合,我们假设仅仅是在金融这一个领域,我们真的可以去影响上百万人的工作,并不是说让他们丢掉工作,而是让他们提升工作效率。中国现在每一个金融机构里面都有大量的实习生、大量的初级的分析师,他们在做着完全不应该用人类来执行的工作,这是一种极大的人力的浪费。
很多在知名的大学里面读到硕士的人才,头两年时间都在做文秘工作,都在做从PDF文件里面扒数据的工作,或者说写他们自己都要吐了的那些报告。像券商里头一些报告,没有洞见在里头,因为基本是套模板,更悲催的是写出来没人看,绝大多数没人看。整个金融神经系统现在还没有被建立起来,所以大量的本来应该用机器来做的事情,由于基础设施没有到位,必须要由人来做,这是极大的浪费,至少100多万人力被浪费了。中国有800万人在金融行业里面,不光是在证券这个行业,像保险、银行都有大量的重复劳动,这些简单重复劳动应该被消灭掉。

这里面列了大概十几项实践。这是我们今年3月份的时候,在杭州开金融知识图谱论坛的时候,我想到的。在2016年的3月份,我们开第一次金融知识图谱沙龙的时候,只有5、6项,一年时间,我们就找到了这么多新的应用,这些应用不是臆想出来的,每一个都是实实在在的有公司在做的事情。我们自己一开始在做金融的搜索,后来做了自动化报告,现在也在探索一些更深的应用了,包括一些自动化的监管,还有金融问答方面的工作。
金融知识图谱的两种实现方式
其实金融知识图谱这个东西并不是一个全新的东西。在二三十年前,结构化数据在金融里的应用就已经存在了,但是不叫这个名字。在1998年的时候,就有人发明出了XBRL这种语言,英文叫eXtensible Business Reporting Language,就是可扩展的商务报告语言。
这个东西1998年发明的时候,XML还是一个新兴的技术,XBRL是基于XML的。基本的想法就是从顶向下进行设计,就是有一群专家来讨论,大家规定好咱们有这么一个格式,所有相关的人都按照这个来进行发布。XBRL有一个委员会,主要是以会计为背景、财务为背景的人进行讨论,XBRL的词汇表也要被讨论,每个国家自己还要讨论。比如说在美国就有GAAP,在中国就有CAS,欧洲有自己的一套标准,日本也有自己的标准,这都是每个国家内部自顶向下的设计。在中国据我所知至少有4个XBRL的标准,到现在没法统一起来,到现在为止自顶向下的设计还没有统一下来。
这还仅仅只是在最高层面上,在各大券商,各个上市公司那里,我们要推行这样一种自顶向下的设计都是千难万难。上市公司被要求用XBRL这种格式来发布数据,但他们的董秘和证代,经常不理解结构化的数据,也很难理解我们用机器来处理数据有什么意义,这对他们来说是多余的工作,很困难。对于主板上市公司还好,对于现在的新三板公司更加地痛苦。所以现在新三板的一万多家公司,并没有强制要求做XBRL的披露,这都是由于成本高,所以造成了难以推行。
怎么推进下去?最近几年时间,大家开始想能不能咱们不对信息发布的时候做这么高的要求。我们已经有了一些发布的数据,比如说各个公司都有年报,都有披露的材料、季报,还有股转书,这其中有很多反复出现的数据,能不能从既有的数据里面,把它结构化的部分先提取出来,这就是一种总结的方法,现在这套方法也就是我们最近这几年兴起的知识图谱的方法。

所以知识图谱跟传统的语义网,既是一个继承,也是一个扬弃,因为传统的语义网也就是top-down的方法,就是我们先想好一个schema,然后在schema上填数据。那么2006年开始,从Linked Open Data开始,出现了这样一个分支,我们发现去总结这种结构化数据比设计结构化数据更行得通,虽然这个数据的质量肯定会下降,因为现实中的数据都是非常脏的,但是至少我们get something。

所以在2006年的时候,Tim Berners-Lee——也是我在MIT的导师——他就提出了Linked Open Data的概念。这是一个杯子,他画了数据的评级标准,一共有五颗星:
■ 第一颗星就是把数据发布出来,On the web。比如说现在我们做金融,在巨潮网上就有所有公司公开的披露材料,这就是On the web。
■ 第二步是Machine-readable,就是叫机器可读。比如说早期2013年的时候,新三板的很多公开材料是扫描件,机器没办法处理。现在比如说我们做债务评级的报告生成的时候,大部分涉及到的文件还是扫描件,这些都不符合Machine-readable的标准。好在现在绝大多数的公司在发布披露材料的时候都已经是文字可读的可行性报告了,都至少满足两颗星,就是Machine-readable。
■ 第三颗星,就是说如果能用一个公开的格式,而不是专有格式是最好的。比如说PDF并不是一个公开的格式,因为PDF是Adobe这个公司的专有格式。再比如说中国的论文数据库以前有个CIS格式,那种数据就不满足开放数据的要求,因为它是由一个公司来决定这个格式怎么发布的。
■ 第四颗星和第五颗星都是在讲如何让数据产生互联,用W3C的那一套语义网的标准,RDF这一套,这里就不多说了,因为往后走都是成本很高的方法。
开放数据是新时代的高铁
回到金融这一块来讲,再多说一句,为什么我们要做这个事情?为什么要把数据开放出来?在金融这边,待会我会给出更多的例子来讲,为什么开放数据对整个产业发展是极其重要的一件事情。可以说开放数据就是信息世界的高铁。
高铁连通了整个中国,如果我们有了各个领域的开放数据,所创造的经济价值,我相信是不亚于高铁的,这是一个非常重要的竞争优势。这也是为什么在2009年奥巴马上台的第一个月,他就发布了行政令,要求联邦政府的所有的部门都要把他们的数据开放出来,然后各州政府也在跟进。英国政府也跟进,现在已经有了几十万的数据集被开放出来,这是欧美政府非常高瞻远瞩的一件事情。
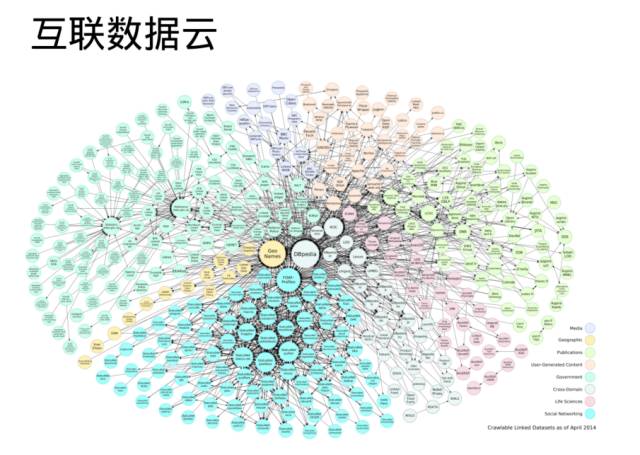
这个图叫做互联数据云,还是在好几年前,我做的一个截图,这是Linked Open Data这个组织在欧洲和美国,他们开放出来数据的一部分在这里。其实我们现在Open KG(中国开放知识图谱联盟)的目标,就像陈老师(注:陈华钧 浙江大学计算机科学与技术学院教授)所说,也就是做一个中国版本的开放数据云。 这张图还是三年前的版本,如果现在来画这个就完全没有办法画了,可能要把整个墙全部画满也画不完,因为现在已经有几十万的数据集了。
但这里面金融的东西并不多,我们看这里面比较多的主要是百科数据、媒体数据、生物学的数据,金融的数据只有一小部分在政府的开放数据里头,主要的政府的开放数据还是在美国政府,就是DATA.GOV这个网站上,它大概有100多个跟金融有关的数据集,最主要的是美国证监会开放出来的。包括公告数据、投资公司、共同基金、XBRL、保险、SEC法规的数据等。
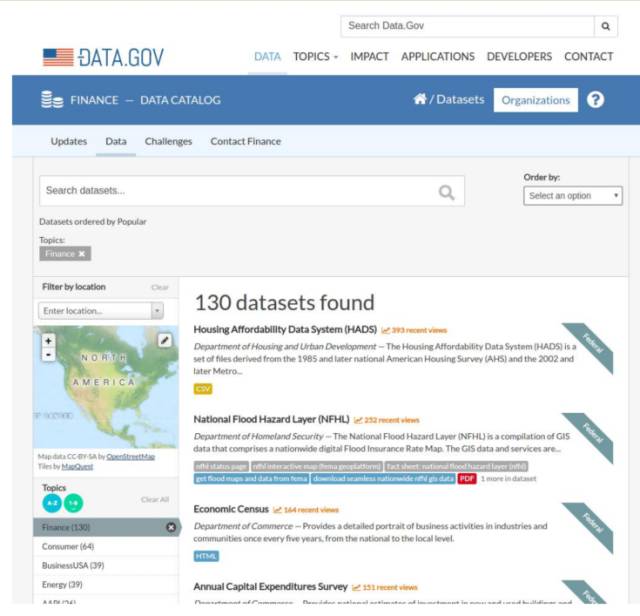
其实100多个数据集,相对而言并不算很多。因为其他的领域,比如说环保都有成千上万的数据在那里,所以金融相对而言还算是比较落后的。大部分这些数据,它还是一颗星的,它只是放在那里,很多就是EXCEL的表格,就像法规那样的纯文本,所以说并不是太好处理。但是在美国证监会的上市公司公告这一块,它做得比较好,它的数据,第一个是公开出来了,第二个是机器可读的,第三个是没有用专有格式。美国所有公司的这些年报的数据,都可以直接从SEC的网站上拿到,还可以下载。这个数据开放性做得非常得好,中国到现在还没有能够做到,我相信今后几年还是会做不到,这就是美国比中国做得领先的地方。
开放数据能带来什么?
这种数据开放能够带来什么?在美国很早以前,就已经有一些市场监控的小公司存在。只要证监会SEC把数据一公布出来,马上就有机器人来监控并进行解析,解析出来了结构化的知识图谱之后来进行判断,根据预先投资的决策来进行判断,这件事情是不是有一个特殊机会,或者特殊风险,两秒钟之内就会把这个消息推送给订阅了这个规则的投资者。
中国到现在为止还没有做到,因为基础数据还没有完备。可以说基础数据的准备工作,也是我们和其他的一些类似的公司正在做的事情。我们在追赶美国,虽然落后了他们好几年时间,不过我相信我们追赶他们应该不需要花七八年,因为毕竟这几年技术又进步了。
这里题外说一句,中国现在也有开放政府数据的项目,我认为上海是做得非常好的,其他一些地方政府也有公开数据,但是都要进行申请,然后要注册,要提交身份证号。我之前申请过一个市,但从来没有被批准过。经济发展程度不一样,经济发展越好的地方越开放。
目前中国、美国,可以说绝大多数地图上蓝色的这些国家,都已经用了XBRL做了信息披露。在美国XBRL是强制的,但在中国现在还不是强制的。

XBRL的介绍
具体的XBRL说什么,我这里就不再深入讲了,基本上就是在讲财报、利润表、现金流量表,各种不同报表的会计数字的一个机器可读的格式。

这是XBRL的一个具体的例子,代表了某个公司的收支情况怎么样,这一次报告的起始日期、货币单位等等,可以看到,这一整页纸非常多的字符没有讲什么东西,就讲了很简单的几个数字。它为了讲这几个数字,有这么一大堆的辅助的信息在这里。XBRL本质上是非常罗嗦的一个语言,为什么罗嗦?因为它其实是一个结构的描述。
传统会计我们大家会用EXCEL,但是EXCEL并不方便机器自动化处理,比如说表头是什么意思,列和列之间是什么关系,并没有写出来,但XBRL就可以做到。我们把这些初步的结构的关系写出来,但是它依然只是一个结构的东西,不是个语义的东西,所以它非常罗嗦。比如说如果子公司的收入要汇总到总公司里面,该讲总公司的时候,就得把这句话重新再说一遍。它没有推理,它也没有能够说,我的子公司的子公司也在我这里,没有这样的逻辑关系可以写。
再比如说一致性的检查,跨报告周期的财务数据的完整性和一致性,这也是没有办法内生地去检查的,只能让程序员在外面写个规则来做检查。在MIT的时候,我们就做了XBRL的语义化,用一种逻辑的语言来描述XBRL,然后再用一些规则,就是SPARQL这种语言来表示规则。具体的内容就不再多说了,因为都比较技术的东西,回头我会把这个ppt发给大家,有感兴趣的可以跟我联系。

这里有一个具体的例子,这是一个XBRL的描述,这是一个结构化的描述,后来这里面有语义在里面。比如说【currentAssets】是一种货币类型,概念层级这种语义的关系,在这里面是隐含的,我们进行了逻辑描述以后变得更清晰了,特别是像OWL这种关系是可以知识推理的。在此基础上可以进行各种规则的建模。如果我们进行公开公告的合规检查的时候,比如说要求在两天之内对重大合同的披露,如果重大合同的披露也用XBRL来描述,就可以来进行检查。因为披露规则本身是可以写成一种计算机可执行的规则。在进行了一系列的检查,在日期内我们就可以判断这个披露在是不是合规。

刚才讲的这个事情,前提是结构化数据的存在。但是我们并没有这样的结构化数据,如果我们要求所有的上市公司都从源头上提供这样的结构化数据,对他们来说也是成本非常高的事情。最近这几年时间,在W3C,万维网联盟也有专门的工作组来改进这些,其中有一个叫FIBO 【Financial Industry Business Ontology】,他们做的核心工作之一,就是对金融各个子领域做词汇集的扩展。他们继续找专家、找银行的专家、证券的专家进行工作组的开会,开了七八年的会,到现在还没有开完。
所以自顶向下的设计,我们可以看到是非常低效率的,而且难以落地。但其中有一部分跟个人消费者相关的东西,已经进入到目前的互联网上。比如说跟个人信贷有关的,个人消费有关的,信用卡有关的一些概念。谷歌在它的schema.org 词汇表里面已经用上了,这算是这么多年工作总算是有一点落地的东西了。最近这几年核心问题就是,我们能不能不要求大家发布这些结构化数据,而是你先发布现有的数据,然后我们把这个数据里面能够结构化的东西先结构化出来,这就变成了智能金融的领域。
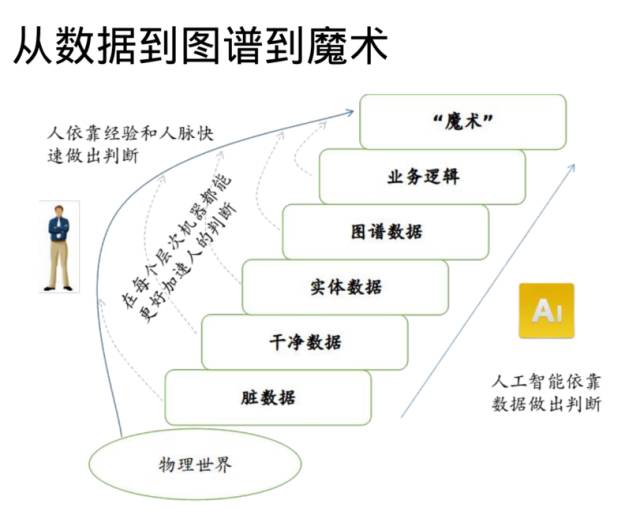
具体的技术有很多种,核心就是说我们在运用这些技术的过程当中,逐渐地把数据的质量给提升。我大体上在这里分成几个层级,从脏数据开始,比如说一些扫描件就是脏数据,至少一些文本数据是干净的,比如说有了文本,有段落划分了,句子划分好了,表格提取出来了,这就变成一个很干净的数据了。这一步已经非常难了,我们做这一步,可能要写上10万行以上的代码,才有可能把这些PDF变成比较干净的数据。
再下面就更难了,把这个实体提取出来,什么公司、人名字、一些产品、行业,产品和产品之间的关系等等这些实体。再往下就是图谱,比如说全球产业链,美国和中国公司之间的对标,新三板公司投资标的的可能性等等,这些加在一起就是所谓实体和实体之间的关系构成的一个图谱。
再下面就是业务逻辑,比如说行业的逻辑,看每一个行业,我们都会看不同的指标,有不同的增长率,还有业务的逻辑,比如说做并购有并购找壳的指标,比如说做监管有监管的逻辑,加在一起就是一层一层的,每一层比上一层难。这并不意味着我们要把所有的事情全部做了以后,然后才能去变金融的魔术。因为基本上每一个层次都可以加速我们人来进行人和机器的协作,我们把事情做得更快一点,这也是我们现在跟一些业务合作单位在做的。
机器不是替代人,而是增强人。
现在在市面上我们可以看到的金融知识图谱,有一级市场跟二级市场的,有创投市场的,公告的数据、研报的数据,还有一些舆情的数据、工商的数据等等各种不同,这里列的每一个项下面都有好几家公司在做。我们主要是集中在上市公司基础数据,还有公告和研报的数据提取,这几块上面。
我们今年3月份的时候,在杭州开了一个金融知识图谱论坛,大概有200多个人参加。在2016年3月份的时候,我们开了一个会,大概只有三四十个人,一年时间,这个领域一下就起来了。今年9月份的时候,我们在上海还会再开一次,我相信也会是高朋满座,欢迎大家来参加。
最后再多说几句,也是首尾呼应一下,我一开始提到的,我们做的很多事情都是“智障”的。人工智能在落地的时候,乍想起来都是很好的,但是每次落地的时候都是异常地痛苦。好东西都是总结出来的,很少有一个东西能够自顶向下的,你把它设计出来,通常都是一个坑,又一个坑,再一个坑,从坑里总结出来的。最后发现要从简单系统才能演化出来一个复杂系统。一开始设计出来的复杂系统,通常都是不切实际的,智能金融系统也是这样一种东西。刚才王昊奋(注:狗尾草CTO)提到了Watson ,Watson在一些领域落地的时候,也不是很顺的,因为设计出来的系统在具体业务里落地的时候,都会遇到非常难以想象的困难,反倒是一开始不做那么大的东西,从特别小的细节开始做的东西,最后能够落实出来。
最后说一句,一句别人的名言。通常大家会高估技术的短期价值,而低估技术的长期价值。现在人工智能技术又再一次历史地轮回到这个点,大家高估了技术的短期价值,总觉得人类要被机器毁灭了,或者说什么职位要被替代了,大家会非常地希望人工智能表现出比人类更高的智慧能力,但这真的是“臣妾做不到”。
但是大家也会低估这个技术的长期价值,像这样一种能够提高人的效率的这种东西,它的价值都是在潜移默化的。它提高你效率两三倍的时候,你感觉不到,但是温水煮青蛙,当它把你的效率提高10倍的时候,你突然发现整个领域,怎么一下就变了?可能在10年左右的时间内,发现整个天翻地覆的一个新的事情就出现了。
我们公司就在国贸旁边,我就经常会站在窗口和我们的同事说,你看写字楼里面那些军阀们,他们将来都要被用AI武装起来的红军干掉。但是真正每一步具体来做的时候,都是非常痛苦的,就是从非常小的事情开始落地的,从根据地建设开始。


















