人机对话概述
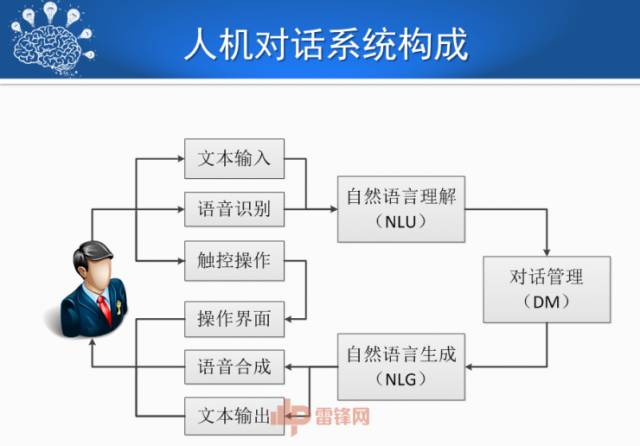
下面是人机对话的基本框架,可以通过语音输入和输出,也可以通过文本直接交互。其中包括三个重要的模块:语言理解、对话管理、语言生成。
人机对话走过了三个阶段:第一,语音助手时代;第二,2014年进入聊天机器人时代;第三就是2016年进入场景化的任务执行。
语音助手时代
2011年,乔布斯临终前在iPhone4S中推出Siri,当时的技术还是很不成熟。2012年,中国的各个厂商纷纷效仿做语音助手。2014年,个别企业纷纷把语音助手团队解散。主要原因:第一,技术尚不成熟,听得见,但听不懂。以至于很多本来严肃的服务变成对语音助手的调戏;第二,语音也并不总是最自然的沟通方式,它需要私密的环境,有时候还需要图像交互界面进行配合。

聊天机器人时代
2014年微软推出小冰,干脆就来聊天和娱乐,放弃语音使用,直接用文字进行沟通。这时候深度学习被充分运用,技术水平有提高,难点在于对语境的建模和机器人自身建模方面。比如你问机器人:“你今年多大了?”,“我5岁了”。但说“你结婚了吗?”,“我结婚10年了”,他自己会发生矛盾。 应用上,用户留存率并不是很高,虽然用户量大,但持续跟机器人聊下去的并不多。

做聊天主要有三方面的作用。第一,建立人和机器之间的信任。第二,聊天过程中,聊天机器人和搜索引擎相比有一个大的优势,搜索引擎只能被动观察用户的输入,但机器可以主动向人发问。比如机器人问人喜欢看电影吗,回复喜欢。机器人再问喜欢哪一类的,回复喜欢看动作片,机器人立刻推荐一个成龙的动作片过去。第三,情绪抚慰功能,机器人的优点是随叫随到、嘴严、可定制。

场景化的任务执行时代
现在处于实用化的努力阶段,通用的做不到,既可以回退为娱乐化也可以回退在特定场景下使用。这一阶段的特点是:将人机对话局限在特定场景,进一步降低用户期望值;利用场景约束,提高语义消歧能力。当你坐在电视机前想点电视节目,能发出指令,并且发出指令的方式是有限的。存在的问题有两个:一是场景切换,需要重新部署。二是工程化色彩严重,不能够一揽子解决问题,研发成本增高。

当今人机对话系统功能:
当今人机对话系统主要有四大功能。一是聊天。聊天的目的是要让人和机器尽可能的多聊下去,去消耗时间。另外知识问答、任务执行、推荐这三个是比较严肃的功能,都是以快速的结束聊天为目标。
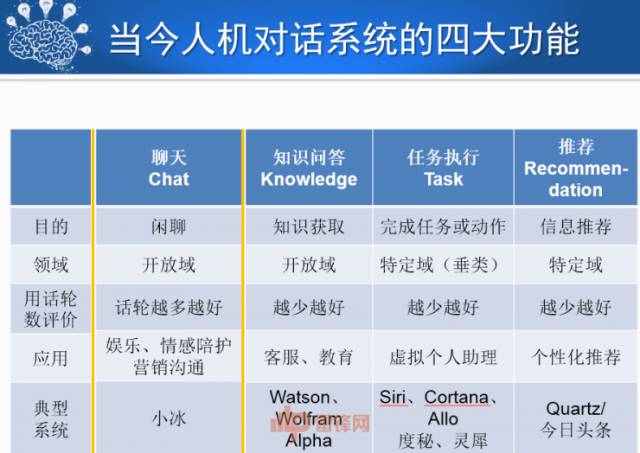
人机对话系统又分下面这三方面:自然语言理解、对话管理、自然语言生成。这里面聊天、知识、任务、推荐,都有各自相应的研究点。具体内容请看PPT。

人机对话技术进展
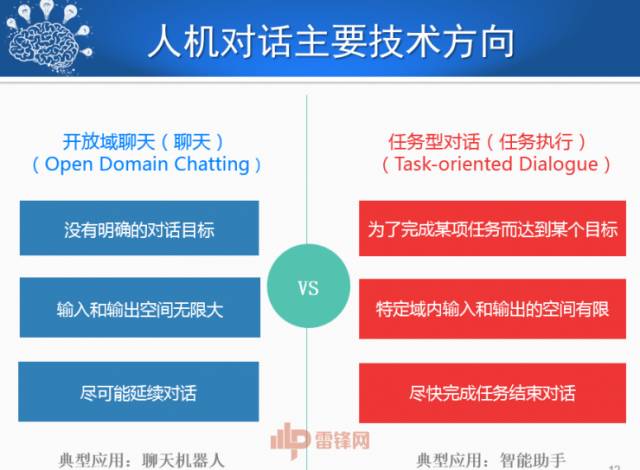
现在人机对话技术到底到了一个什么程度,主要从前面说的四方面选出两个最重要的:聊天、任务执行。任务执行不同企业的叫法不一样,我们叫任务。聊天是没有明确目标的,任务是定机票、定餐馆等。聊天搜索空间比较大。
聊天机器人最早出现是在上世纪60年代,有人研究出一个能够和精神病患者聊天的机器人,效果挺惊人,此后不断的发展。腾讯的小Q机器人、还有微软小冰、Tay,这都是聊天机器人的系列产品。提到聊天,首先会想到根据以前的聊天记录,通过搜索,就可以回答一些问题。
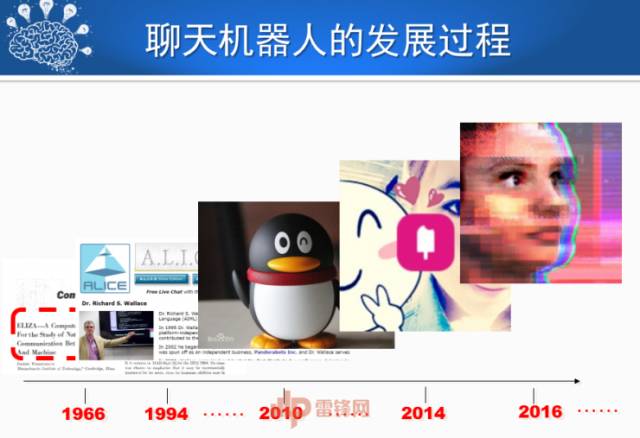
单轮对话生成的进展比较技术化。发展趋势是不仅仅通过算法解决问题,而且要确定一个主题,借用外部资源,把话说得更丰满。
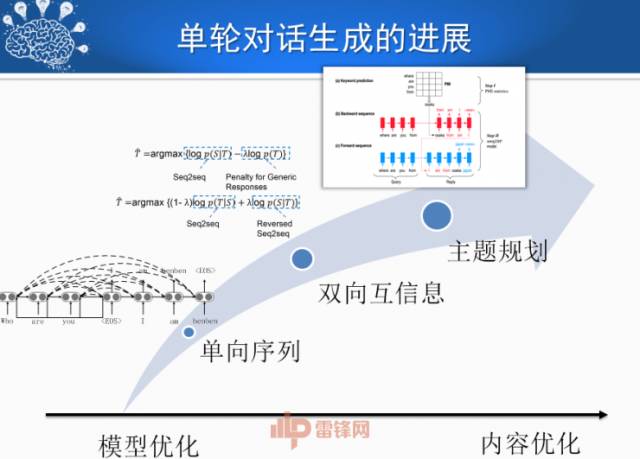
多轮对话中,聊天和搜索有很大的区别。搜索也开始启动多轮搜索,但是真正的多轮是在聊天当中体现的,要有多个回合,这里面会产生指代、省略等等。如何在多轮对话里让人感觉这是一个完整的对话很值得研究。这里面出现很多技术,包括深度学习和强化学习的融合。
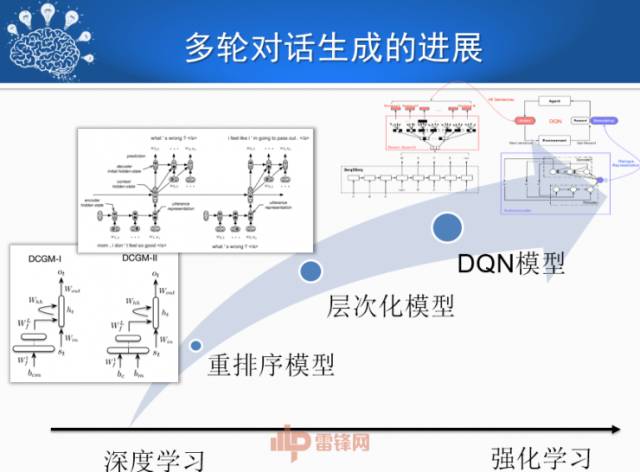
智能助手有一系列产品,从苹果、微软,到Facebook、亚马逊。现在很多大企业不但自己做智能助手,而且提供对话平台。对话可以称为对话操作系统或者对话人工智能。微软在研发,很多企业在收购,百度既研发又收购,推出面向中小企业的平台。
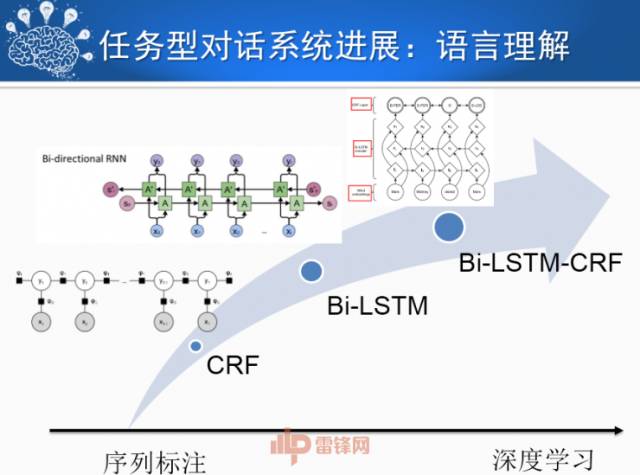
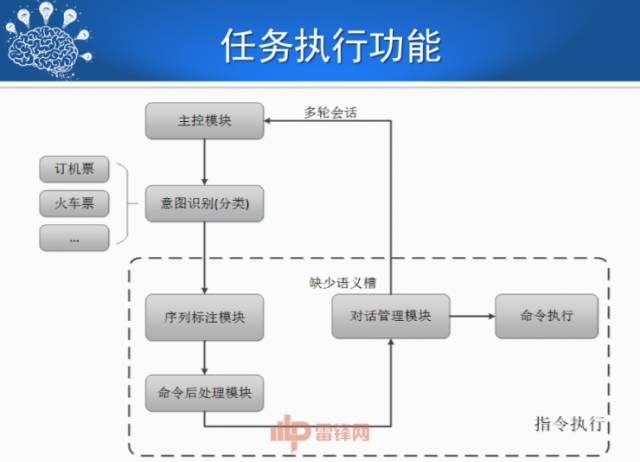
任务型对话系统的语言理解部分,通常使用语义槽来表示用户的需求,如出发地、到达地、出发时间等信息。因此可以使用序列标注模型来抽取语义槽。CRF (条件随机场)是过去经常使用的序列标注模型,但是受限于马尔科夫假设,它无法很好的处理长距离依赖问题。随着深度学习方法的流行,人们使用循环神经网络,如双向 LSTM 来解决长距离依赖问题,同时还避免了繁琐的特征工程工作。最近,人们将这两种方法进行融合,即双向 LSTM-CRF 模型,进一步提高了槽填充的准确率。
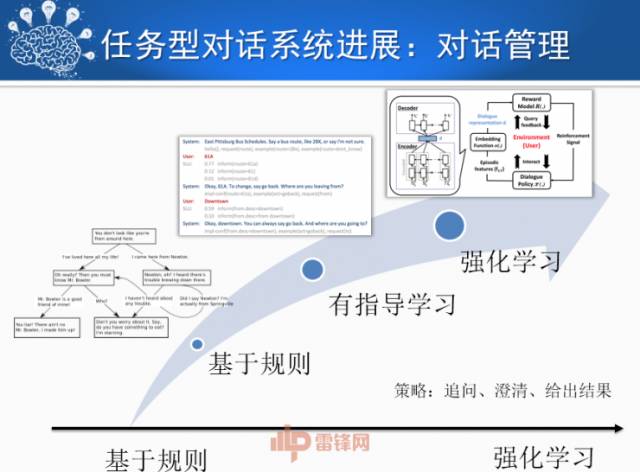
对话管理指的是根据上一步语言理解步骤识别的语义信息,决策系统下一步所需采取的策略,如追问、澄清还是给出结果等。最简单也是最常用的方法是采用基于规则的方法,即根据不同的情况人工制定对话树,这种方法需要耗费大量的人力,而且可移植性也比较差。有指导学习的方法只需人工针对一些具体的样例,标注对应的回复策略数据,然后就可以交给机器学习了。但是这种方法需要针对每条对话进行标注,标注难度很高。近年来,采用强化学习的方法成为研究的主流,该方法无需逐条标注,只需要将整个对话的最终结果作为奖励,系统就可以学习到最优的策略序列。
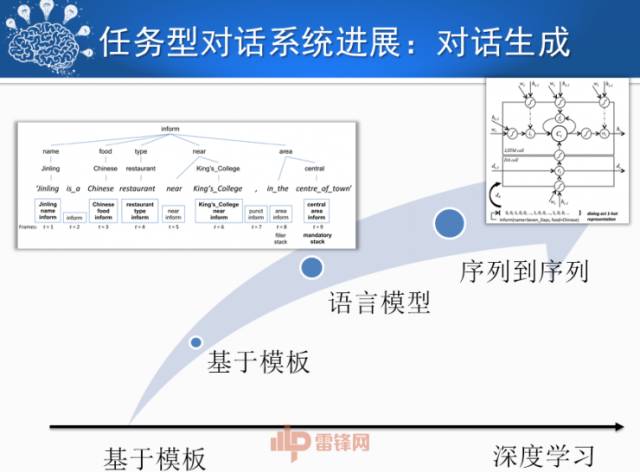
最后对话生成模块根据采用的不同对话策略,给出不同的系统回复。最简单就是采用基于模板的方法,但是该方法很难在不同的领域之间迁移。后来人们采用基于语言模型的方法,直接从语料库中学习回复的语言。近年来,深度学习中序列到序列的方法为对话生成提供了一种新的思路,不同于机器翻译等任务所采用的序列到序列模型,这里原序列是上一步输出的对话策略,目标序列则是系统的自然语言回复。该方法具有学习简单,生成的语言自然、多样等优点。
关于“笨笨”机器人的介绍
下面介绍一下我们实验室研制的一个系统,叫“笨笨”。我们不敢叫“灵、百灵”,只能承认自己笨,进一步降低用户的期望值。当用户拿着一个手机以为什么都可以问的时候,他一定会失望。我们这个研究中心是哈工大社会计算与信息检索研究中心,这是我们的公众号,有上万人关注。功能包括聊天、知识问答、任务执行、推荐。

生成式对话模型往往存在一个问题――语义相关性差。比如说问机器你今年多大了,回复说不知道。这里面产生问题的原因,从技术上讲是生成话的第一个词会产生概率很高的通用词。比如“我”、“你”。
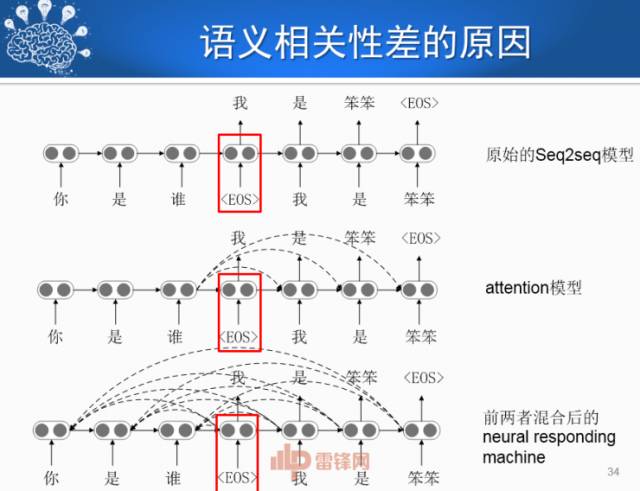
我们采用了专门的Learning to Start模型去生成,大家可以对比一下。
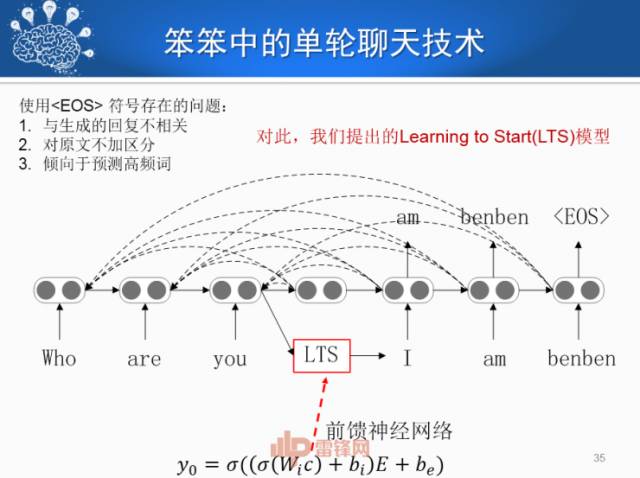
单轮对话也采用主题规划的方式,进行两阶段的生成。先规划,然后响应内容。

多轮对话是基于DQN进行。这个优化和任务执行的优化正好反过来。聊天的优化是要尽可能让这个聊天能继续下去,让话题轮数更多。
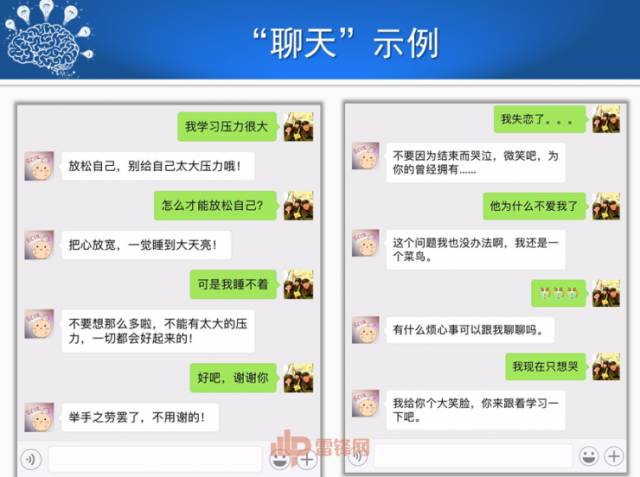
下面是“笨笨”聊天的一些对话(见PPT),比较好玩,大家可以下去自己玩。
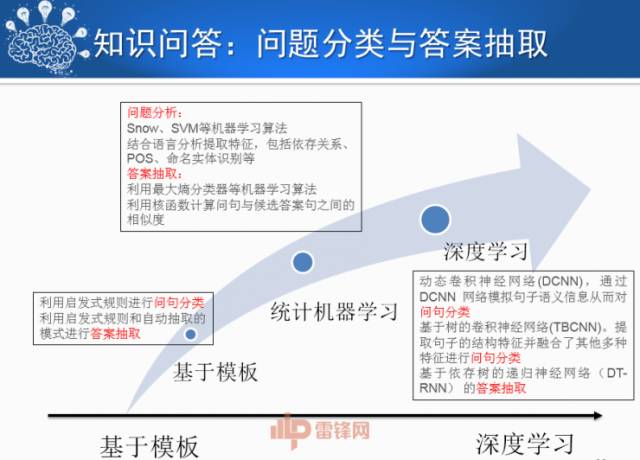
下面是知识问答。在各个具体的问题上,都在使用深度学习技术,知识问答方面也不例外。
这是任务执行的系统框架(见PPT)。在任务执行方面,哈工大最近也开发了一个系统,这个系统是一个平台,各位可以在里面添加你的特定领域要解决的一些问题实例,添加若干实例之后,系统会帮你训练出一个特别实用的场景任务执行系统。这个推荐也被嵌入到人机对话中,有些创业公司专门做人机对话领域的推荐。
在“笨笨”跟你聊天的过程中,可能跟你推荐产品,这就是营销机器人。营销机器人会先和你聊天,建立信任之后推荐产品。还有服务于售后的客服机器人。
人机对话评测介绍
最后讲一下人机对话评测,任何一项技术要想进步,特别依赖于它的目标,就是怎么评测这项技术,这项技术到底是前进还是后退了。在人机对话方面的评测比问答系统难。问答系统是单轮的,我问毛泽东出生于哪一年。你答出的是准确答案,就算成功了。但是人机对话里,一轮过后,就会分岔,一旦分岔了就没有办法做标准答案进行评测。现在国内在这方面的处理也是评测驱动。哈工大也在主持若干评测。以前我们也参加过美国的一些评测,现在有一些在参加日本NTCIR的评测。我们的理念是中国人的评测要由中国人引导。

我们主持了首届中文人机对话评测,由张伟男担任主席。我们分两个任务,一是用户意图分类,区分到底是聊天还是任务,如果是任务,到底想完成一个什么样的任务。二是特定域任务型的人机对话评测。比如定机票,问两句话,会出现分岔,很难展开评测。解决办法是人工评测,先给一个问题的描述,让人根据这个描述和不同的机器人进行对话,看看哪个机器人可以在最短的轮数内把这个问题解决掉。

国际上,2017年也在开始组织评测,在自然语言处理最前沿方面,国内学者和国际学者是齐头并进的。在斯坦福主持的英文阅读理解评测中,很多巨头都有参加。排第一位的是微软亚洲研究院,第二位是哈佛大学一个研究实验室。即使在英文上,国内也并不落后。

未来的挑战
最后概括,最主要的技术挑战在两方面。
一是聊天机器人未来有待解决的问题。我估计在座的各位没有谁愿意和一个机器人持续聊超过一周。另外还有情感,对机器人说考试不及格,怎么分析是不是伤心的情绪,还有用户画像,回复质量,多样性,个性化等的研究。机器人怎么主导话题,如何是让机器人具有各种各样的性格,为每一个用户定制多个不同性格的机器人,包括在游戏世界里,让机器人扮演一些角色,能和人对话。还有基于主题的上下文生成、基于用户的情绪反馈。用户一旦骂你或者不跟你聊了,说明你回答问题的不好。
二是任务执行中有待研究的问题。比如任务之间的切换,目前即使通过工程手段把一两个场景做对了,扩展到其他地方还是很难。

什么时候人机对话才能取得真正的突破,主要取决于以下几点:自然语音处理技术的突破、机器对情境理解的进展、机器推理能力的提升、文本生成技术的进步等。

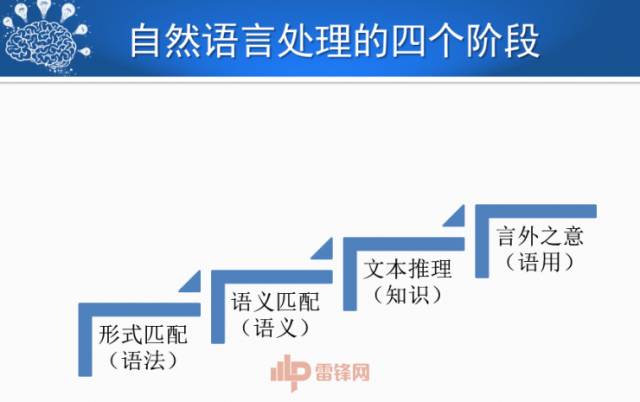
人机对话是自然语言处理发展的一个高峰,它的发展和自然语言处理的发展是密不可分的。我认为自然语言处理有四个阶段。从形式匹配到语义匹配,现在到文本推理,再下一步会到言外之意。一个小女孩对男朋友说“讨厌”,这句话怎么理解,需要一些文化的背景。现在已经有人在研究隐喻这方面的工作。
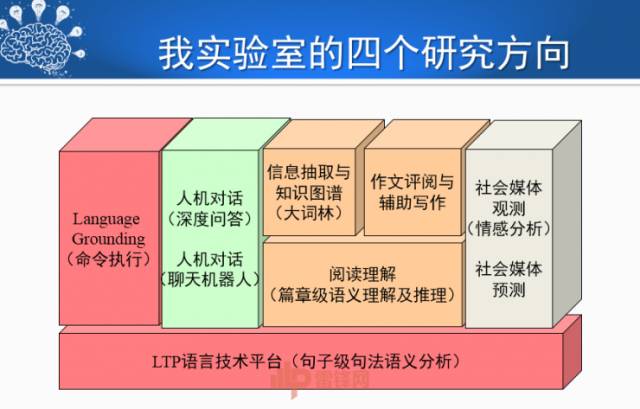
最后介绍一下我们实验室在布局的工作,研究方向如PPT所示。