
今天想跟大家一起看一下我们现在的主要研究方向,也希望跟大家一起推动这个研究方向,它是神经符号处理。
神经符号处理是未来自然语言处理非常重要的一个方向,这个报告大概分以下几个部分:
一,对自然语言领域做一个概述。从我的角度把最近几个报告的主要观点,再重新梳理一下。
二,为什么我们觉得神经符号处理是未来重要的一个研究方向,它的主要应用就是更广义的问答(我们叫智能信息知识管理系统)。同时,介绍一些业界相关工作和我们自己做的一些研究。
三,抛砖引玉,大家一起探讨一些相关问题。
自然语言处理的终极目标是做自然语言理解,就是让计算机能够理解人类的语言。具体来说有两个方面:像人一样能够去说话;像人一样能去阅读。理解大概有两层定义:基于表示的;基于行为的。
如果计算机系统听到一句话,它能够对应它内部的表示,我们就认为这个计算机理解了这个语言。或者是基于行为的,机器人听到一句话,能够按照话的内容去做一些行为,就认为这个机器人理解了这个自然语言。我们这个领域终极目标就是,期望我们能够开发出这个技术,使计算机能达到这样的智能识别。
但我们也知道,语言其实是一个非常复杂的现象,不做自然语言处理、人工智能,可能人类自己都不知道,我们自己的语言是这么复杂的一个现象。让我来总结的话,语言有五个特性,使得我们把语言放在计算机上,变得非常具有挑战性。
-
既有规律又有很多例外;
-
组合性;
-
递归性,造成了语言非常复杂;
-
比喻性;
语言的本质就是产生新的语言进行表示,其实都是在做比喻。所以,比喻性是语言非常重要的特性。语言的理解跟世界知识是密切相关的,如果你撇开了知识这些东西谈语言,其实都是无从谈起的。
我们人类的语言其实是人跟外界做互动的一种手段,离开了对外环境的交互,谈论语言其实也是没有意义的。所以,因为语言有这么复杂的特性,使得我们在计算机上去实现自然语言理解,非常具有挑战性的。这就相当于这些特性使得我们要用现在的技术做计算的话,基本上都是做全局搜索,全局的这种计算还不知道该怎么做。这是非常复杂,具有挑战性的。
主要原因有以下几点:
原因一,最近写的一篇文章,在计算机学会通讯上,叫做迎接自然语言处理新时代,有这样一些观点,做了比较详细的介绍和总结。而在去年在中文信息处理大会上报告的内容,也是这个观点。
原因二,我们现在总结看的话,为什么自然语言处理这么难,因为本质的原因就是,我们还不知道,是不是能够用数学的模型刻画语言现象,这个是自然语言处理的本质。这件事情可能不可能做我们不知道,我们只能是部分地实现这个目标。
所以,这是为什么自然语言处理(甚至是广义的人工智能)都非常具有挑战性的原因。
现实当中大家采用的办法,我们不叫自然语言理解,而是叫自然语言处理。我们的策略是,把人类做语言理解的这个复杂过程进行简化。
第一个,我们现在能去做的事情。人类要是理解语言的话,比如人做这种问答,问我姚明身高是多少,我想一想可能是 2 米 29。我回答的这个过程,可能包含了多个步骤。比如语言的分析、理解、推理、知识的检索,最后做判断,最后产生我的回答,是一个非常复杂的过程。
但是,我们现在要用计算机来做这种智能问答或者知识问答的时候,其实我们大幅度地简化了这个过程。就是只做分析、检索和生成。今天大会里面有很多老师做报告,介绍自然语言处理相关的技术,基本上做问答的时候,都是把这个问答的过程简化。

第二个,现在自然语言处理,非常主流的做法就是数据驱动。我们主要的核心技术是机器学习,现在是用深度学习来做。同时,我们把人的知识放进去。深度学习的重要的特点是,整个技术其实是一种机器学习,但是它的模型是从人的大脑处理机制中得到启发,然后我们定义这个模型。
所以,现在人工智能、自然语言处理,我们采用的基本工具是机器学习,尽量能够把人的知识导入进来,同时让这个模型尽量去参考跟人一样的处理机制,实现自然语言处理。
现实当中,我们看到深度学习、大数据,确实给自然语言处理带来了很多新契机。这条路到目前为止看,是最有希望能够再往前推进的一条路。
这个观点前年在一次大会上我作报告介绍的观点,也是在计算机学会通讯上有写过一篇文章,简论 AI,就是这里面介绍的观点。
大家也看到,我们现在的自然语言处理包括人工智能都是这样一个过程。基于数据,我们的系统有了用户,之后我们根据数据改进算法、改进系统,使系统的性能不断提高。在人工智能闭环的时候,我们就可以不断地去给用户提供更好的服务,使得我们这个系统变得更加智能化。
我们看一些自然语言处理技术,就是说数据驱动,自然语言处理大概有五类技术,我们用数学建模,用统计机器学习办法建模,基本上就是这五类模型。主要的应用、方法基本上都属于这五类技术。
-
分类。文字的序列,我们要打印标签,这是我们常做的最基本的自然语言处理。
-
匹配。两个文字序列都匹配,看它们匹配的程度,最后输出一个非负的实数值,判断这两个文字序列它们的匹配程度。
-
翻译。把一个文字序列,转换成另外一个文字序列。
-
结构预测。你给我一个文字序列,让它形成内部结构的一个信息。
-
序列决策过程。在一个复杂的动态变化环境里面,我们怎么样不断去决策。比如描述序列决策过程的马尔可夫随机过程,这是一个有效的、非常常用的数学工具。
我们看自然语言处理的大部分问题,基本上做得比较成功、实用的都是基于这样的技术做出来的。比如:分类,有文本分类、情感分析;匹配,有搜索、问答、单轮对话、基于检索的单轮对话;翻译,有机器翻译、语音识别、手写体识别、基于生成方法的单轮对话;结构预测,有专名识别、词性标注、语意分析;序列决策过程,有多轮对话。
我们看到所有的这些重要的自然语言应用,其实是这五种最基本的技术,基本上都能够做得还不错。不过,自然语言处理我们现在做得并不完美,离理想中的情况还差得非常远。
这是从另一个角度看这个问题,我们把它叫做技术的上界和需求的下界。这个绿线表示技术能够达到的性能上界,比如机器翻译、专名识别,不可能达到一个上界。这个蓝线表示,用户对需求要求的下界。用户肯定是有一个最基本的要求,你这个机器翻译如果达不到,或者太低的话,我们是不能够给用户提供满意服务的,用户是不会去用这个自然语言处理系统的。所以,一定有一个用户要求的最低下界,对任何一个实际的应用,都可能有这样的一个下界。

我们这个技术的上界就是,如果能够碰到需求要求的下界的话,实际上这个系统就有可能被用户用起来。大家觉得这个已经能够满足实际的需求了,否则的话,你这个做得再好,用户要求的下界更高,实际的技术也不可能实用。自然语言处理,大家现在在做的事情就是刚才看的这个绿线部分,怎么样不断往上提高,使技术的上界――红色的这部分,能够再往上提高,使得我们有更多的技术能够去满足用户需求,使得用户能够使用起来。
我们可以看到,现实当中自然语言处理很热,上午还有人问,自然语言处理里面哪些技术已经比较实用了,可以看到机器翻译和语音识别已经越来越实用化。但是我们可以清楚地看到,这个机制和人做的机器翻译、或者人去做语言识别完全不是一回事。我们还是用数学模型、数据驱动的方法。这个模型是参考了人类大脑的机制,用大数据做出这样的东西。
这块的话,我们还会看到有很多新的技术,比如说,Sequence Learning(序列学习)这样的技术,不断有新技术出来改进。至少现在看,主流的研究方向、发展方向是这个,但是我们已经越来越能够碰到用户需求要求的下界,所以我们这些技术能够变得越来越实用化。单独对话包括单独的这种问答,也是越来越实用化。
我们看到各种各样的工业产品、服务出来,能够单轮对话。或者相对来说已经比较成熟,未来能做得越来越好。但是,多轮对话还是相对比较有挑战。最主要的原因是,多人对话的数据还非常缺少。其实数据驱动这个模型做好的话,没有足够的数据,就是一个很大的挑战。现在做研究也是非常困难。
所以,我们可以看到,未来自然语言的发展,可能会有大的改变。我们刚才说这五种最基本技术,大家不断往前推进,能够使得技术上界不断往上提高,整个业界趋势是这样的。
下面看一下神经符号处理。
自然语言的本质特点就是符号,符号表示的一个最重要的优点就是它可解释性和可操作性好。我们在计算机上进行符号处理的话,就会用符号来表示我们所有的东西。但是,我们同时也看到,自然语言的特性,它本身是具有歧义性,有不确定性。我们如果把语言搬到计算机,多半都还拥有噪音。
另一方面,我们看到深度学习,更广义的统计学习能够比较成功的原因就是,这些机器学习方法它能够很好地应对不确定性、处理好语言里面的歧义和噪音。另一方面,我们叫神经表示(向量表示),用向量来表示语义,它有很强大的优势。

我们现在可以明显看到,符号表示和神经表示其实是互补的。大家自然会想到这样一个问题,我们能不能把这两个结合起来,这就是我们说的神经符号处理。我们希望通过这样的手段,能够把自然语言处理能做得更好,把这个技术往前推动。
不过我说的话,大家可能不太相信。正好今年年初的时候去了一个大学访问,拜访了深度学习大师 Yoshua Bengio 教授,我还专门跟他探讨了他对神经符号处理的看法,这是他基本的 Comments,不是原话,总结一下就是有三点:
第一,如果把符号放到神经网络里面,他觉得这很难,可能不 Work。神经网络本身就是一个向量矩阵表示的东西,在这个模型里,把符号塞进去其实是挺难塞的。
第二,如果把符号处理和神经处理在外围有效地、不断地结合起来,这是很有道理的,是可以考虑的。
第三,他说这种问答对话,其实应该是一个重要的应用。
至少我们也得到他的认可,最基本的观点跟 Bengio 教授的想法也是一致的。
我们下面看一下,智能信息知识管理系统。大家可以认为这是一个知识问答系统,但是我这样叫的原因是它跟我们一般的问答系统还略微有点不同,我们希望一定程度上,参考人类大脑的机制。

这个系统有几个模块,有语言处理单元、中央处理单元、短期记忆、长期记忆。比如说我们来了一个问句,语言处理单元对它进行分析,把这个结果放到短期记忆力,然后在长期记忆力找到相关的知识或者信息,接着把检索到的内容放到短期记忆力,最后再通过语言处理单元产生出回答。这个是我们在使用过程当中的系统。
还有学习,这块我们希望用深度学习技术,进行端到端的系统构建。这个系统本身同样有语言处理单位、中央处理单元、短期记忆、长期记忆。我们在学习的过程中进行假设,这个输入是大量的信息知识和问答数据,就是有非结构化数据、结构化数据,也有大量问答,就是一问一答,形成这样的训练数据。我们最理想的状况,只使用完全数据驱动的方法,端到端地自动构建整个问答系统。我们构建整个长期记忆里面的信息和知识,这是我们所构想的,或者建议大家考虑这样的智能信息知识处理系统。
它有几个特点。首先,能够不断去积累信息和知识。这点跟我们人是相似的。能够去不断地看到新知识加到自己长期记忆里。同时,如果有人用自然语言来问问题的时候,它能够准确地回答。当自己不知道的时候,就说我不知道。我们人也是这样,不是什么都知道,就是我们不知道的时候,能够准确地告诉用户我不知道。
其次,希望这个系统尽量完全没有人干预,而是自动地去能够把它建立起来。这样的系统将来会非常有用,而且非常强大。大家可以想象,我们如果身边有一个智能助手,有什么问题你不知道,过去问它,它可能会告诉你,这个会有多么方便。当然这个愿景不光是我在这儿说的,我们也可以看到业界很多人描述出了类似愿景。
我觉得这非常重要,如果人类能够做到这一点的话,就是一个质的飞跃。人类发明了语言,是第一个质的飞跃,有了语言,大家可以交流、传递信息,互相传授知识。第二个质的飞跃就是,我们如果有一个智能系统放在自己身边,我想要问什么知识都能准确告诉我。
然后,换另外一个角度看,计算机有两个地方是非常强大的:计算能力和存储能力。计算能力已经发挥得淋漓尽致了,但是存储能力发挥到一半,概念上讲,它能存储无穷多的信息,计算机现在可以把人类所有的知识信息全部存储下来。但是我们现在遇到的瓶颈是我们不能有效地去访问这些信息。这块如果我们在自然语言处理、人工智能研究方面有重大突破的话,我们真的是可以把整个人类的能力又推进一步。
大家可以从另一个角度看,我们这样的智能系统很理想,现实当中其实已经有这样的雏形,也不是说几乎是渺茫的。现在的搜索引擎,一定程度上已经扮演了这样的角色,搜索引擎有爬虫、索引、机器学习机制帮助我们去做排序,给我反馈结果。一定程度上已经在做类似的事情了,但只是没有做得更好,我们相信这是一个演进过程,会不断地往前推动,技术不断地会进步。我们相信,未来的话拥有这样一个智能助手能够帮助到我们。
我们再看一下,为什么神经符号处理和智能信息管理是密切结合的。这个跟 Bengio 教授的想法是相关的。这个技术和这个应用有一些天然的关系,另一方面的话,它俩真正是互补、强烈相关的。
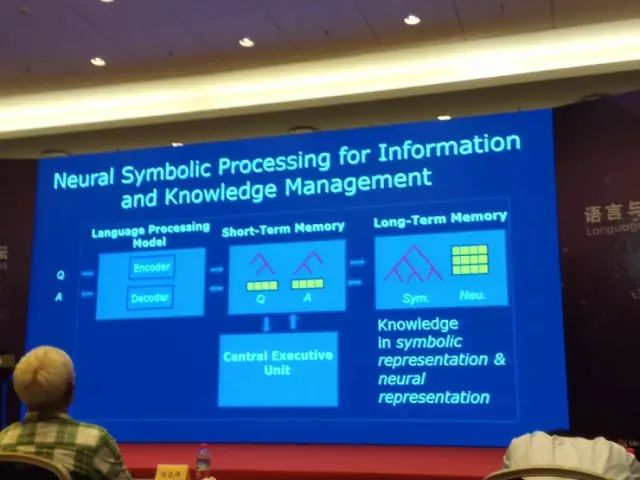
我们可以考虑用这样的技术,神经符号处理实现智能信息知识管理系统。就是说,你先来了一个问题,通过语言处理模块,它有编码器和解码器,编码器把这个问题转换成中间的表示,中间表示放在短期记忆里,这个问题是有两部分,既有符号表示又有神经表示。现在自然语言处理内,很多系统类似在做这样的事情,大家可能没有明确说这个事。
知识信息都放在长期记忆里,也是有两种表示,既有信息表示又有符号表示。但这两者中间的话也是分开的,其实应该是密切相关的,但是这个怎么去做,还有很多要去解决的问题。
但是,我们可以想象,长期记忆里的信息和知识,都是既有符号表示又有神经表示。做问答的时候来了个问题,做了分析有了内部表示以后,可以通过在短期记忆里的表示,通过表示之间的匹配,在长期记忆里找到相关的信息和知识,在短期记忆里也产生对应的符号和神经表示。这时候还有一个解码器,把这个表示转换成自然语言、答案,这样我们就可以构建一个非常智能的自然语言问答系统。
这个想法其实大家已经在各个层面上看到很多了,相关的工作有很多。例如:语义分析,Semantic Parsing,在 Semantic Parsing 里面要做的事情,就要把自然语言的语句,转换成结构化内容的表示,这个 Semantic Parsing 到目前为止,最主要的想法还是通过人写的规则,定义语法、定义模型,然后做语意的解析。但是,我们假设完全不用人来参与,更要去学习内部的表示该怎么去做。
还有,CMU 的这个项目大家知道,叫 Never Ending Language Learning(NELL),这些想法就是,互联网里抓取的知识,不断扩大知识,开始的时候,有最基本的 Ontology(本体论)。然后有一些例子,比如北京是中国的首都,这样的例子,希望从互联网里面找到更多的知识,把它加入到 Ontology 里去,希望这个过程机器能够不断抓取,抓取的准确率和效率能够不断提升。这是 NELL 这个项目。
还有 Facebook 的 Memory Network,能做一些简单的问答,比如里面有一个系统用自然语言的,比如―John is in the playground.―Bob is in the office.―John picked up the football.―Bob went to the kitchen.然后就问这个系统,Where is the football?回答 Playground 就是对的。
Facebook 推出这种模型的话,可以去做这样简单的问答。当然现在准确率还不是特别高,它最基本的想法就是,把这些用自然语言表示的信息,能够把它放到长期记忆里,这个长期记忆也是神经表示,把内容表示放到里面,来了一个新问题,把新问题直接转换成神经表示然后再做匹配,找到相关答案,然后返回回来。现在这个模型还比较简单,但是这个方向很多人都已经在做了。
还有大家也知道,Differentiable Neural Computers 这样的模型,它基本的想法也是,觉得现在神经网络很弱的地方,就是没有长期记忆,希望能够更好地利用长期记忆。长期记忆在 DNBD 的模型里,它实际上就是一个大矩阵,每一行向量其实是比较深的一个语义表示。这个模型本身有三种神经网络,能够去控制访问这个长期记忆机制,因为有长期记忆的话,一个重要事情是要从长期记忆里进行读取。这个读取的控制,有三个神经网络能够去进行。我们大家也在朝这个方向在做。
下面简短介绍一下,我们在诺亚方舟实验室做的一些基础研究。有吕正东博士、尚利峰博士,还有其他合作的老师一起做的工作。
主要有两个工作,都是研究我们顺着这个思路来做的。
第一个是在知识图谱里面进行知识问答。假设我们有大量数据,比如说姚明身高是多少,2 米 29,我们能够有这种观点,说出答案的话,具体是对应着知识库里的哪一个单元,我们有大量数据的话,我们的目标就是有一个学习系统,就是学习神经网络的,然后构建自动问答系统。来了一个新问句的话,我们能够从数据库、知识库里面找到答案。然后就这么产生自然语言回答,这是我们现在做的一个工作。
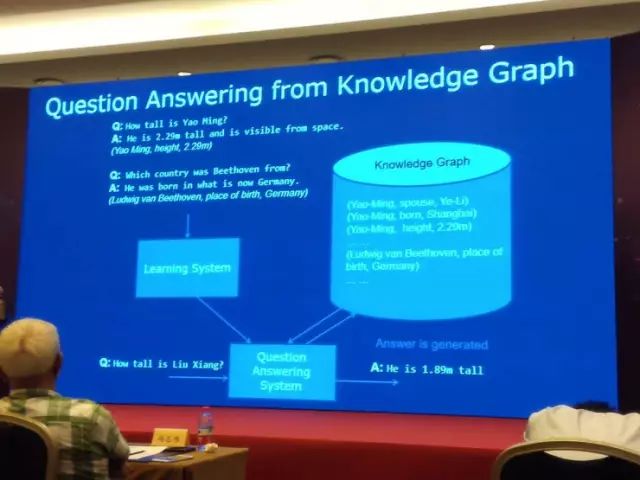
这种 Setting 如果大家能够做得非常好的话,真正就能够自动地构建这个问答系统,一个知识库的例子,能够自动地构建问答系统。
这个思想的话,基本上也是刚才我介绍的我们想做的这种神经符号处理的思想。就是来了问句以后,我们有编码器,转换成内部的表示,它既有符号,又有神经表示(向量表示),这个三角是一个符号,这个黄色长条表示神经表示(向量),我们这个知识库里的单元图,也是由符号单元图表示,也有对应向量表示。整个知识,有两种表示,问答过程中,确实像刚才描述一样,我们在知识库里找到答案,产生中间表示,解码器通过答案还有编码器产生问句的表示,最后产生一个回答。

我们刚开始从知识图库里面找到答案,第二个可能就是关系数据库。我们的知识不是在网络表示里面给的,而是在数据库的表里给出,这样我们其实也可以做类似事情。就是我们提出了一个模型,可以把这个关系数据库既做符号表示又做神经表示。有这样一个长期记忆力的整个知识表示。来了问句以后,把它转换成中间的神经表示,然后去做检索、匹配找到答案,最后产生答案。这块的话,我们进一步改进了这个模型,希望能够更或地结合符号和神经处理。

下面就是对报告的总结,今天跟大家一起看的神经符号处理,我觉得是重要的研究方向。要我来说的话,是自然语言处理未来发展最重要的方向之一。
它最主要的应用,应该是这种广义的知识问答,这块智能的信息和知识管理。我们也都看到,业界大家都是往这个方向走,已经取得了一些成果,但是真正把这些技术实用化,还有很多具体的问题要去解决,还有很多实际的工作需要去做。但是,我觉得,我们对这个方向还是充满信心,还是觉得将来会是非常令人振奋的。
(演讲完,下面是问答环节)
问:您刚才报告中有一句话我觉得非常好,就是我们现在要怀疑一下,人工智能能不能用数学模拟到人的智能的情况。这里我想聊一下当今比较热门的 Chatbot,大家在做对话的时候,都是局限于单轮对话,或者说不特定领域的,对多轮对话和开放领域的问答,我们都做得非常不好,对于多轮对话开放性的问题,您觉得人工智能目前它能够实现到一个什么样的程度?以及用目前的技术的话,它有个大致的解决时间吗?
李航:我觉得还是数据是一个瓶颈,现在大家都没有数据,其实一定程度上,不管大公司小公司,大家数据都不够,因为多轮对话的时候,它的复杂度一下子增加很多。它不是一个简单地从单轮到多轮,大数据增加了一些,它应该是指数级地增加这些大数据。
我个人观点是,Open Domain 的这种闲聊,做成多轮是很难的。可能都没有什么短期看到的可能性。但是如果基于任务驱动的,有一定的数据以后,应该是能够做的,真的需要有数据才能够往前推动。
问:您刚才提到两种表示方式,一种是传统符号的表示方式,现在是知识图谱中间的一种表示,另外一种是向量化的表示。我觉得向量化的表示方式一种好处是,虽然我觉得我们有很多知识,很难用目前这种逻辑符号方式来描述,用向量化的表示方法,不一定很准,但可以从大量语料里头学习到一定的东西,我们虽然不知道它是对的。但对于传统符号很难表示的这种情况下,像您刚才说的这种,怎么来互相结合?
李航:应用驱动比较难,你就不知道用向量表示到底是不是合理,那只有通过最后应用的结果进行判断。其实大家对知识的理解,我们自己日常工作生活当中使用的一些知识都是下意识的,真的是不知道它具体是个什么样形式,有什么样内容。这些东西,如果我们放在计算机里就会发现,语言有众多歧义,知识有更多不确定性。
这些东西就是你说的,我们现在只能在一些页目能看到,可以怎么把它表示出来。比如说,我们现在默认 Binding 还是非常简单粗暴的方法。但在这里面能看到,它能解决一些问题,就说明应用启动能够帮助我们找到这些更好的表示方法,更好地去学习这些表示方法。
反正我觉得对知识的认识有两个很重要:一个是应用驱动,一个是具体的领域。
一定要把领域跟应用分清楚。当然你也可以说我就是 General Domain,那也是一个,但是一般来说知识要用的话,可能是在金融、医疗甚至更细的领域这样去做,能更加在现实当中能够用起来,也更容易去对这种应用的评价,看这个表示方法到底好不好。


















