




概念计算的潜力
深度学习通过卷积神经网络(CNN)变革了计算机视觉,通过循环神经网络(RNN)引爆了自然语言处理。我们已经看到大量的研究成果和应用案例,但黑箱的深度学习真的能颠覆自然语言理解吗?令机器理解自然语言一直是 NLP 的目标,但即使如今谷歌神经算法机器翻译使用强大的编码器-解码器结构、注意力机制和双向 LSTM 网络,但它真的理解词语属性和结构吗?有读者可能认为即使不理解也没关系,我们只需要系统能得出结果就行。是的,深度学习系统能得出十分优秀的结果,但这种在词层面而不是概念层面的计算需要大量标注数据并在多 GPU 和多机器上分布式地训练,因此我们训练出来的模型才有足够的复杂度来适应于巨量且复杂的词和句子。那么如果系统理解词的属性和概念呢?系统是不是应该就可以从概念的层面上理解语句及其背景知识,并且由于一个概念对应于多个词的表达,因此概念上的计算复杂度会不会大大降低?从这个角度来说,语知科技基于概念的计算确实能帮助深度学习弥补不足,让机器学习达到更好的效果。
数据问题
深度学习是一种监督学习,它需要大量的标注数据集,而基于知网语言知识库的计算在完成主体知识网络的建设后,主体知识网络只需要少量的标注就可以扩展到新的领域内。因为深度学习将意义转换成向量和几何空间,然后逐渐学习复杂的几何变换,把一个空间与另一个空间建立映射关系。所以我们需要足够高维的空间来获取原始数据中的所有关系,因此大量的标注数据也在所难免。但是对于知网语言知识库来说,知识是通用的知识,我们只需要标注一次就可以在各种任务和场景下调用这种知识,而新的词汇只需要按照知识网络的框架标注一次就可以加入到知识库中并反复利用。所以说如何利用知网知识系统(下文将详细解释)将有助于深度学习减少对标注数据集的依赖。
泛化问题
深度学习可以看作为一种局部泛化,因为如果新的输入与模型训练时遇到的数据有些不同,深度网络执行的从输入到输出的映射就会遇到麻烦。因为当我们使用深度学习模型完成某个任务时,我们需要使用该任务巨量的样本进行训练,训练出来的模型基本上也只能应用于这类任务。通过叠加更多层、使用更多训练数据来提升当前的深度学习技术并不能改善泛化性,因为模型能够表示的范围仍然有些局限。反观语知基于知网语言知识库的计算,它拥有十分强大的泛化性能。因为这种概念计算是基于词的义原和关系进行(下文将详细解释),所以我们的计算是带有属性和背景知识的,它能改善深度学习的泛化问题。目前语知科技用于分词的系统换一种计算方式甚至可以直接进行相似度计算或情感分析等。
人类可以使用非常少的数据甚至不使用数据来适应全新的、之前从未体验过的情形,抽象化和推理可以说是人类认知的定义性特征。深度学习很难做到这种程度的泛化,因为它是一种输入到输出的映射。而基于概念的计算却更容易抽象化为属性并推理各事物间的关系,这种泛化才是我们应该注重的。
鲁棒性问题
深度学习某种程度上有良好的鲁棒性,例如神经机器翻译不会因为少量的扰动而大幅度变动。但对抗性样本却能欺骗系统,因为深度学习模型不理解输入样本的属性和关系等知识。深度学习模型只是学会把数据映射到人类对该特定样本集概念的几何变换,但是该映射只是对我们头脑中原始模型简单化的表达,因此当模型遇到没有编码的表达时,鲁棒性将会变得较差。同样基于知网知识库的概念性计算也有良好的鲁棒性,因为该方法描述每个概念的树是确定的,只有概念变动,所需要的树形描述才会变动,所以随机扰动并不会引起模型性能的降低,同时也并不会出现对抗性样本那样的缺陷。
总的来说,深度学习目前真正的成功是具备在拥有大量人工标注数据的情况下,使用持续的几何变换在样本空间与预测空间之间建立映射的能力。把这件事做好就可以从根本上变革每个行业,但是我们离人类水准的 AI 仍有很大距离。而语知这种基于知网语言知识库而进行的概念性计算能弥补深度学习的不足,令自然语言处理更接近于自然语言理解的过程。
知网的结构与概念计算
从上文我们已经了解到概念层面的计算拥有强大的潜力,它能克服很多 NLP 深度模型的局限性。那么我们该如何将词或句子层面计算转化为概念层面的计算呢?语知基于知网语言知识库将词或句子的概念表达为一棵棵义原树,进而执行各种计算。所以下面我们将了解知网语言知识库的结构特点,以及它是如何使用义原和关系等以树的形式来描述词或概念。
知网知识库的结构
知识是一个系统,是一个包含着各种概念与概念之间的关系,以及概念的属性与属性之间的关系的系统。富有知识的人不仅掌握了更多的概念,同时也掌握了更多的概念之间的关系以及概念的属性与属性之间的关系。所以知网是一种可以被称为知识系统的常识性知识库。它以通用的概念为描述对象,建立并描述这些概念之间的关系。
义原(Sememe)是最基本的、不易于再分割的意义的最小单位。例如:「人」虽然是一个非常复杂的概念,它可以是多种属性的集合体,但我们也可以把它看作为一个义原。我们设想所有的概念都可以分解成各种各样的义原。同时我们也设想应该有一个有限的义原集合,其中的义原可以组合成一个无限的概念集合。如果我们能够把握这一有限的义原集合,并利用它来描述概念之间的关系以及属性与属性之间的关系,我们就有可能建立我们设想的知识系统。

义原的是知网基本应用的描述单位,它是基于我们的观察而得出,比如说现代汉语词典,它仅使用 2000 多汉字就能解释所有的词条。所以知网的方法就是对大约六千个汉字进行考察和分析来提取有限的义原集合。以事件类为例,在中文中具有事件义原的汉字(单纯词)中曾提取出 3200 个义原。但我们需要对重复义原进行合并,3200 个事件义原在初步合并后可得到 1700 个,进一步归类后得到大约 800 多个义原。因为这些义原完全不涉及多音节的词语,所以我们需要将其作为标注集去标注多音节的词。最后我们需要对所有 2800 多个义原进行编码,编码采用助记符的形式表达,如词语「打开」,其中一个概念是「打开一个东西(盒子)」的动作,用义原 {open|打开} 表示,另外一个意思例如「打开一盏灯」,义原的表示的方式就是 {turn on|打开}。
理解什么是义原也不复杂。朗文词典规定用二千多个字去解释和定义所有的词语,HowNet 定义义原也是这个思路,我们从语言学的角度抽取出来这 2800 多个最基本的没有歧义的语言概念就是义原。我们用它和关系做结合,去描述所有的概念,所以 HowNet 是一个网状结构。
概念的表征
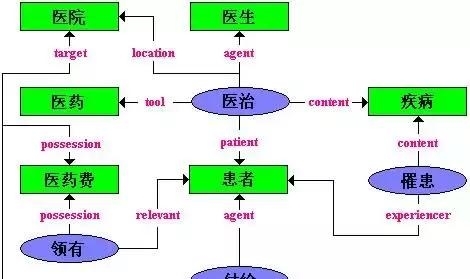
知网还着力要反映概念之间和概念的属性之间的关系。知网知识网络体系明确地提供给了计算机,因此我们可以输入形式化的知识而构建计算机系统来实现自然语言处理任务。如下图所示,我们不仅需要义原,同时还需要它们之间的关系来表示知识。通常一个词其具体的概念会采用树型的结构利用义原和关系描述该概念。例如「医院」这一个词的概念根据具体语境可定义为 DEF={InstitutePlace|场所:domain={medical|医},{doctor|医治:content={disease|疾病},location={~}}},我们可以看到整个词的概念属性可以由多个义原按照关系和层次进行定义。

整个知识网络都是以义原为基础建立起来的概念性系统。义原是通过关系描述概念的最小单位,知网认为它是一种最基本的概念,任何复杂的概念都是由基本概念通过某种关系构建而成,而知网用基本单位描述这种关系的方法我们称之为 KDML(Knowledge Database Markup Language),这种描述方法将复杂中多个义原嵌套和多个关系嵌套的问题解决了。
因此,词层面的计算就能转换为概念层面的计算。而且即使我们所使用的词汇增长或变更较快,但概念的增长曲线要平缓地多,所以概念相对于词汇更具鲁棒性。而深度学习使用得最多的词汇表征方法是词嵌入,代表性的就是 word2vec 方法。词嵌入是一种词的分布式表征,它基于神经网络。我们一般可以通过神经网络对词的上下文,及上下文与目标词之间的关系建模。这里我们注意到它的操作层面还是词汇,所以不论是使用如 word2vec 或自编码器那样的弱监督预训练还是端到端的有监督训练,其计算复杂度和所需要的计算资源仍然远远大于基于知网知识库的概念计算。
如何计算概念
在我们将词汇概念化并使用义原树表征后,接下来我们需要考虑如何在各类任务中利用知网知识库和这种词的表征方法,即我们该如何基于知网知识库进行分词、相关度计算、情感分析和命名实体识别等任务。当然概念层面上的计算和我们熟知的机器学习算法或深度学习方法有很大的不同。并且由于类似词在概念空间上要比原始词空间上距离近得多,所以在概念空间上处理自然语言任务要简单地多。一般来说,机器学习方法可以表示为输入空间到输出空间的一个映射,而基于知网的概念计算就相当于先将输入空间映射到一个概念空间,再从概念空间运用计算方法映射到输出空间。样本在概念空间内将服从一定规范形式,并且相关联的词在概念空间内拥有更近的距离。下面,我们将从分词、词的相关性和情感分析等任务讨论基于知网知识库的计算方法。
分词计算
机器在分词的时候,主要有两种情况,一种是组合型,即字和字之间是不是可以组合成一个词。第二个是交集型,比如说提高人民生活水平,机器可以分割为:提/高人/民生/活/水平,这几个词是连续存在的歧义。但是从一般的算法来说,这并不是问题,因为简单的切割次数最少化原则就已经解决了这个问题。但这种实际上是伪分词歧义,比较难处理的是我们该如何参照词表确定合理的分词。
但中文是一个字,它组成了词后才有意义,而英文的词组同样也需要组合起来才有意义。因此董强先生表明,中文英文都存在着同样的问题,重要的不是分而是合,即哪个字/词在什么情况下可以与另外一个字/词相结合。

在机器学习中,分词主要可以使用条件随机场(CRF)进行,但是在传统 CRF 中特征需要人工设定,所以我们需要进行大量繁杂的特征工程。不过近几年深度学习的发展给很多研究问题带来了全新的解决方案。在中文分词上,基于神经网络的方法,往往使用「字向量 + 双向 LSTM + CRF」模型,利用神经网络来学习特征,将传统 CRF 中的人工特征工程量降到最低。这种分词技术通常分为 3 个处理层级,首先嵌入层会将离散的汉字用词向量的形式表征,随后特征层将使用前向和反向 LSTM 在考虑时序依赖关系的同时抽取有用的文本特征,最后的推断层将使用 CRF 基于前面的特征进行分词。其实我们可以看到,这个模型需要将复杂多变的字用词向量的形式表达出来,那么我们是否能使用知网知识库先表征词再投入计算?
在知网中计算语句的分词,首先汉字切分到单个字就可以结束了,剩下的就是字和字之间的合并的问题。董强先生说:「知网它本身是一个知识库,它对于中文来说就是一张词表,那我们首先就需要检索相邻词在词表中能不能匹配上,匹配后再看有没有歧义。我们一般会把所有带歧义的组合都保留。然后将这些组合放入一句话或者一个语境内进行计算,因为每一个词语在知识库里面都是有概念描述的,因此我们就要确定这个词语和另外一个词语在概念层面上可不可以有一种合理的语义搭配。如果是合理的话,这一分词就可以确定下来,如果不确定,就需要寻找下一个。如此整句话就迭代地进行了词切分。」总的来说,语知会将可能组合而成的词用义原树表达出来,然后放入句子中并计算句子其它元素与该概念的相关性而表达词语组合在语境中的合理性,系统将抽取最合理的切分方式作为输出。
相似度和相关性计算
语知科技有专门的工具做相关性计算,该工具可称之为 Inference machine,他本身就是知识库里面词语所代表的概念,它们本身就具有相关的性质。那相关性比如说同义词、同类词、反义词等,这一类是词语本身在概念的定义上就能体现出相关性。那第二种是我们常识知道的相关性,例如钓鱼和河岸(Bank fishing 常被机器翻译为「银行钓鱼」)是有一定的相关性的,但是在词语本身的定义里并不能体现出来。这个时候语知就会使用 Inference machine 去描述它。也就是沿着该概念的义原树搜寻相类似的概念,再用那 2800 多个义原描述它。因此知网有一套自己的解释器,它可以解释这些描述语言。
机器学习通常会强调计算词的相似性而不计算词的相关性。比如说分布式词表征,由于分布假说认为上下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。但是统计机器学习方法很少有计算相关性的算法,因为基于词汇统计的方法很难找出逻辑关系和从属等关系,也很难利用相关性信息进一步执行语义排歧。
语知的相似性检测:如果我们拿着「医生」非要跟「行走」计算相似度,因为它们都不在一棵树上了,相似度就非常低了。现在我们在来看看同类词的相似度如何计算。比如说「神经科医生」和「牙科医生」,他们都具有「人」这一相同的义原,而同一个义原是最重要的,然后再考察它后面的义原。第一个是看它的复杂度,比如说像医生和神经科医生,他们两个相似度是非常高,但是他绝对不是相同的义原。神经科医生的复杂度要高一些,它们进行加权或者是除这些节点的时候,复杂的概念就会多除几次,所以说它们会稍微有一点点的区别。因为知网对概念的这种描述方式是嵌套的,描述的层次越深,互相之间关联的时候所加的权值就越弱。当然我们首先要考虑两个概念能不能递归地推理到同一个节点上,如果能达到一个共同的节点,我们再考虑一共爬了多少步,也就是在计算相似度的时候我们考虑加权的值。
正是这种使用义原树表达概念的方法,我们可以轻松地进行多语种和跨语言处理。因为词语只是概念的表现,所以当我们使用义原树确定不同语言的概念,那么我们可以对这些概念直接运算而不需要做进一步处理。比如说跨语言相似度检测,唯一需要注意的地方就是编码不同语言的不同词汇,当我们将使用义原树将词汇编码成概念后,计算相似度或其他操作就变得十分简单了。
未来
NLP 的目标是做到自然语言理解,语知科技认为知识的运用和 NLU 处理手段的多少决定了 NLP 的效果,所以目前语知科技提供更多的是语义信息。
可扩展的知网知识库
目前语知科技提供的 NLU 服务是基于知网数据库的通用操作,知网数据库的功能很强大,未来会有更多的服务接口提供出来。同时语知语知在基于当前核心的知识库基础上能做进一步扩展。也就是在现有通用型知识库基础上,将专业知识库专业性的概念用特定的义原和关系表达出来,做到通用知识库和专业知识库之间的关系映射。专业知识库和 common-sense 没有冲突,可以解决因此而带来的部分「人工智障」问题。
与深度学习相结合的知识库
语知科技未来进一步发展的基本思路是基于知网在知识体系和 NLU 的优势和深度学习做结合。因为语言学家不是在深度学习的「黑箱」面前无所作为,恰恰相反,语言学家可以帮助计算学家认识语言的内涵和知识,只有双方共同努力,在计算机认知层面才能实现突破。知网知识体系输出是一个重要的发展方向。知网就是一套搭建知识系统的方法理论,利用这一点,我们就可以尝试落地通用知识图谱加专业领域的应用知识图谱。基本方法就是将知网统一的知识库体系规则,以及用义原和关系描述知识点(概念)之间关系的方法用在应用层面的知识库上。这样一体化的知识和常识是不冲突的而且有联系的,因此在知识库交叉领域就可以做到知识(概念)的互通。
酒香也怕巷子深,知网(HowNet)30 年来仅仅是为学术界提供研究工具,累计授权的国际院校和科研机构超过 200 多家,但是宣传较少。如今,知网(HowNet)正以语知科技创业公司的形象走进公众的视野。
语知科技 NLP 技术平台刚刚上线,它是目前国内为数不多的,能够提供全面 NLP 工具的技术平台。它所有的 API 接口对学术研究和学生使用开放,免费使用。

如上图所示为 API 调用示例。我们可以看到目前可以调用语知科技的中文分析、引文分析、词语相似度检测和词语相关性检测等 NLP 底层接口。其中,这些接口展示了该平台有如下几个显著的应用特点:
完整的、结构化的知识体系能够帮助机器学习实现更好的效果;
基于概念计算的 NLU 在超句、篇章的语义关系和逻辑关系提取上有很强大的能力,技术早期应用在情报领域;
计算量小,不依赖 GPU 的 NLP 工具,降低 NLP 应用门槛,在小型 AI 设备和边缘设备上(非联网设备)应用广泛;
多语种和跨语种应用,例如游戏 NPC(Non Player Character)应用,一个虚拟 AI 服务不同语种的游戏玩家;
丰富的语义信息直接提供,有利于二次开发。













