��Ϊ��ܵĿ����ߣ����Ƿ��֣���Ȼ��ܶ��ֶ���������ܺ��ļ���������������̬�ƣ���������ķ�չ�������ѧϰ��ܿ������������һЩ����ʶ��������ν�����ʵ�������������п�ܶ�ȥӵ������������ѡ�ͣ��ڼܹ��ͼ���ѡ������ͬ����һ���棬Ҳ��һЩ�����ڿ�ܿ������������ھ��岻�����ƿ�ʩ��״̬����α������Ѿ������ļ����������ʵ��������һ�����������ᷢ�֣�����һ�����ѧϰ���û����ô�ѡ�������Ҳ���Ҫ����Ŀǰ���δ��������⣬����Ҳ�ᷢ�֣�����һ����Խ���м����Ŀ���к��ѵ����⡣������ǻ�ӿ�ܿ����ߵ��ӽ�ȥ���������ѧϰ�����һ�仰���������û���������ѡ��ʱ�ο���
ע�����Ƚ������ѧϰ��ܵı�����Ȼ��������ѧϰ��ܿ������Ѿ������ļ�������δ��������⣬��ε����������ѧϰ��ܣ�����2018������ѧϰ��ܼ�����չ����չ����
ע���ڽ�������ǰ����������������һЩǰ�ᣬ�����Щǰ���������ô�����ѧϰ��ܡ���û��ô��Ҫ�����Ľ��Ե��ĵ���һЩ������������ʵ�����ѧϰ�㷨���٣��ɷ��ۺͺ��������Ρ��۲����Ҫ�۽��ڵ����豸��оƬ�ϵĴ����Ż����豸����ͨ���Ṥ���������Σ����ǻ��ṩ�����ܵĿ⣬Ʃ��x86 ��arm CPU��MKL, OpenBlas��Nvidia GPU �ϵ�CuBlas, Cudnn�ȣ��ڴֳ��ܼ��㳡�����������豸���������ܣ��Ż��ռ䲻��Ȼ���ն��豸�ȵ��ij����кܶ�ӿռ䣩����۲�Σ���Ҫ�Ƕ��豸�Ͷ����ڵ������Ż�����Ҫ���ֲ�ʽ��ܵ�֧�֣��Ǽ������������ˮƽ�Ĺؼ��������������о��Ż��ռ䡣������ѧϰ����Ҫ�����̲����죨����Ա��Ч�ʣ��ͳ������в����죨�������Ч�ʣ�����ʹ�㣬������ʹ���������������������˹����ܼ�ʷ�����һ�仰��
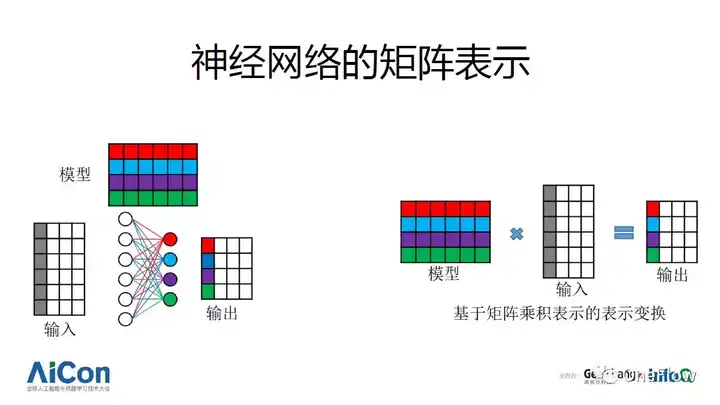
ע�������������ɲ�ι��ɣ�ÿ�����ͨ�������Ա�ʾ�ɶԾ���Ĵ��������ֳ��ܼ�����ʽ�ر��ʺ�ʹ�ø߶Ȳ��е�Ӳ�����٣�GPU, TPU�ȣ���
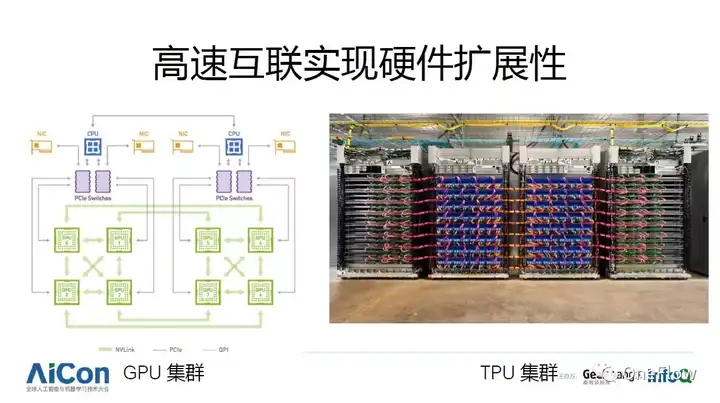
ע������Ӳ�����칤��ˮƽ�������豸��GPU, TPU��������������ҵ��Ӧ�öԼ������Ŀ�������ֹ���ģ���ʱ�ͱ����ø��ٻ����Ķ���豸Эͬ����ɴ��ģ���㡣��ͼչʾ��GPU��Ⱥ��TPU��Ⱥ�������������ͨ����CPU��GPU ����TPU��һ���������CPU ��������ĵ��Ⱥ�������GPU ����ʵ�ֳ��ܼ��㣬����Ǿ���˵���칹���㣨Heterogenous computing����
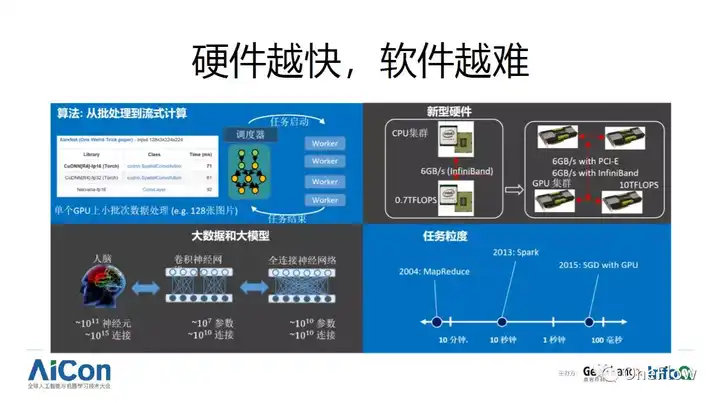
ע����Ӳ��Խ�죬����Խ�ѡ�����۵��������Ρ���Ҫ˵�����϶��¿������ѧϰģ��ѵ��ͨ��ʹ������ݶ��½���SGD���㷨���Ǹ��ӽ���ʽ�����һ�ָ��أ�ÿ����һСƬ���ݣ�������ϵͳ�ڲ�״̬�ı仯�����¶��Ͽ������ѧϰ�㷺�����칹���㼼����GPU ������豸�����ʷdz��ߣ���CPU��10�����ϣ���ζ��ͬ����С�ļ�������GPU���Ը�����ɡ���С���ȺͿ��豸�����濴�����ѧϰѵ���еļ����������ȷdz�С��ͨ������ʮ���뵽�ٺ��뼶�𡣵��ǣ��豸����������û��ʵ�ʸĽ���Ʃ��ͬ���ڲ�PCIe��������ʹ�õĸ�����̫����Infiniband�Ĵ������Ҫ����GPU�ڲ����ݴ���һ�������������������ظ��ֲ�ʽ������ܴ�����ѹ��������������ã��ͻ�����豸�����ʵͣ�����ϵͳ���ܲ�ĺ��������ȷ�����Ȼ����Ҫ����ͨ���г���������ܶ࣬������ø���ÿ����վ��ͦ�����ӣ���ô�������������ͨ�г�����١�
ע���������Ӳ���㶼�����ڡ������������룬����������˴�ͳ�����ϲ���ϵͳ��OS����Windows, Linux������������ʱ��������������ƶ�������ʱ��Android, IOS�����ߴ�����ʱ��Hadoop�Ľ�ɫ�����ϲ�Ӧ�õ���ڡ�ͬʱ������̬�ֶ����˵ײ�Ӳ���Ľ�ɫ����Ӱ��ײ�Ӳ���ķ�չ�����ˡ�
ע���������Ƚ������ѧϰ������Ѿ������ļ�������������Щԭ����ÿ����Ӧ���ܿ�����һ���Լ������ѧϰ��ܡ�
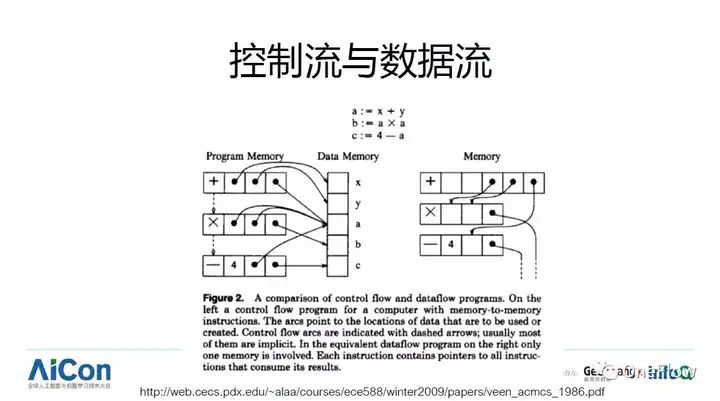
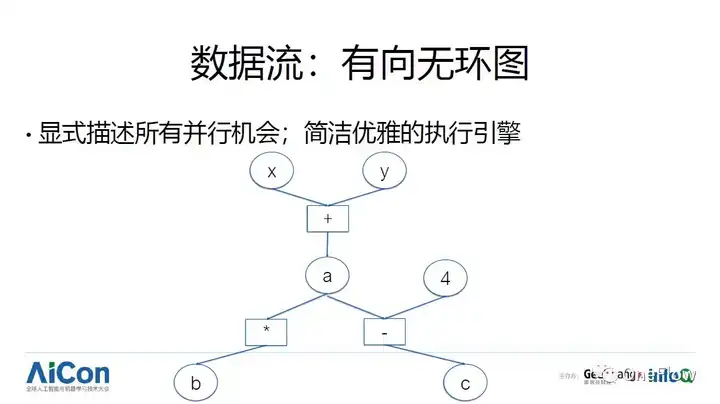
ע���ڽ��뼼��ϸ��֮ǰ������������������������Ҫ�ĸ����������Control flow�� ����������Data flow�������������¹غ���һЩ�ؼ��ļ���ѡ����a = x + y; b = a * a; c = 4 - a; ����һ�μij���Ϊ���������ֱ��ģʽ��һ������C����Ϊ����������ʽ��̣�imperative programming������������˳����ʽ�Ŀ̻��˳����ִ��˳����ͼ������ͷ��ʾִ��˳������Щ�����Բ���ִ�У�����̫��ȷ�����Ҫ�ڶ���߳���ִ���⼸����䣬Ϊ�˷�ֹ���ֶ���̼߳�Ķ�д��ͻ������Ҫʹ���� ��lock���ȼ���������ijһ��������ijһ���ڴ棩��ֹ����data race����һ�ֱ��ģʽ����LispΪ�����ĺ���ʽ��̣�functional programming����������һϵ�б���ʽ���̻��������ִ�в��ǰ�����ʽ������˳����ִ�У����Ǵӱ���ʽ���ھ����������ʽ֮�������������ϵ��������������ϵ��һ��������ͼ����ʾ��ͼ��ʽ�̻�����Щ����ʽ��������һЩ����ʽ֮ǰ��ֵ��������Щ����ʽ֮�䲻����������ϵ�����Բ���ִ�С��ڲ��кͲ���Խ��Խ������磬functional programming ����������������Խ��Խ�����ӡ�
ע��������ģ��һ���ʾ��������ͼ��Directed acyclic graph, DAG����Ʃ����һҳ��a = x + y; b = a * a; c = 4 - a; ��������ʽ���Ա�ʾ������һ��ͼ��ԲȦ��ʾ���ݣ������ʾ���ӡ�����֮�俿���ݵ����������ѹ�ϵ����������������ģ�͵�������Ҫ���������棺��1�� ��ʾ�ϵĺô�����ʽ�����˳����е����в��л����2��ʵ���ϵĺô�����������ִ����������úܼķ���֧�ֲ����Ͳ��У����ڿ����������жԲ����Ͳ��е�֧�־�Ҫ���ӵĶࡣ
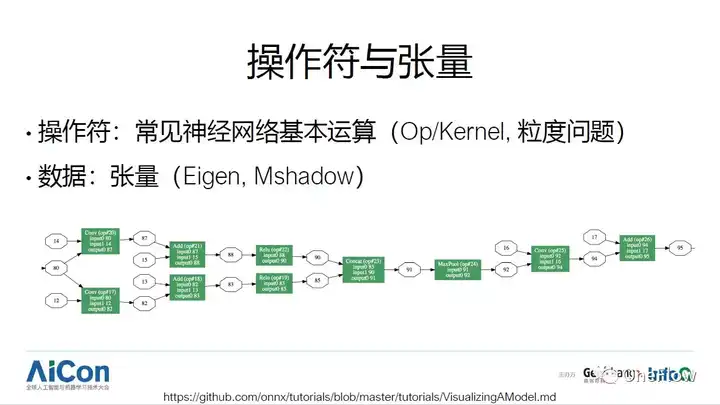
ע���Ƚ���Ŀ��Caffe ͨ��Layer ���ֳ�������������Ƿ���һ��ġ�TensorFlow ���ֺ�������ͼ�������������Ԫ�أ������������㣩�����������ݣ��Ƿֿ���ʾ�ģ����ֳ���ģʽҲ��������������á�����أ�Operator һ���������������Kernel ������ľ���ʵ�֣���ʵ���ϻ�Ҫ���Dz��������ȵ����⣬���������֧����������ļӼ��˳��Ϳ���ͨ��ͼ�����Զ�֧�ָ��Ӹ��ӵ����㣨��һЩ�������εļ��㣩��������̫ϸ�ͶԱ�����Ҫ���ر�ߣ���ǰ���������ɵĴ��벻һ���ܳ�������ʦ�ֹ��Ż��Ĵ��룬����ڶ�������ﶼ��ֱ��֧��һЩ�����ȵIJ�������Ʃ�����������������˲������ȣ�ֵ��ע�����TensorFlow XLA, TVM ��ϸ���Ȳ�����������ͼ�Ż�������һЩ�õ�ʵ�������������������֧�֣�ҵ��Ҳ�кܶ༼�ɣ�Ʃ��һ��ʹ��C++ģ��Ԫ�����ʵ�֣������ڱ���ʱ�������������ʱ��Ч�ʣ�TensorFlow �ȿ��һ�����Eigen�⣬MXNet ʹ���Լ�������Mshadow��
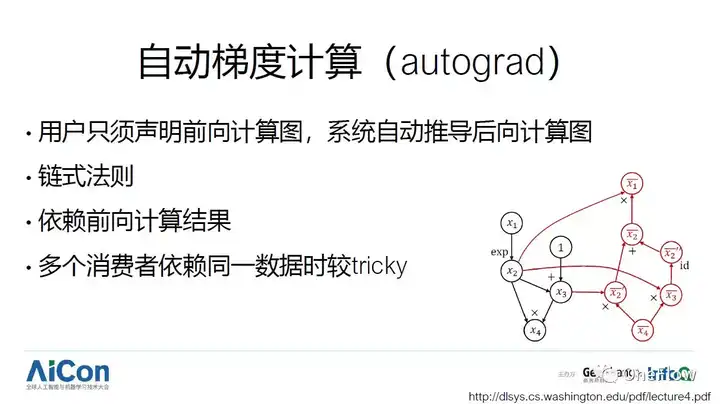
ע��autograd �Ѿ���Ϊ���ѧϰ��ܵı��䡣����autograd���û�д����ʱ��ֻ��Ҫ����ǰ���������ô���ģ�������������ϵͳ�Լ��Ƶ���ɡ�autogradͨ����������ʽ����ʵ�֣����������������ͼ����Ҫע�����㣺��1�����������̿��ܻ�������ǰ�����������м����ݣ�����ǰ�������м����ݿ���Ҫһֱ���ֵ���Ӧ�ĺ��������ɲ����ͷţ��������Ҫ�ں������ʱ���½���ǰ����㡣��2�����ǰ���������ж��������������ͬһ�����ݣ��������ͼʱ����Ҫ���⼸����������Ӧ���ݶ������ϴ�����������źŽ����ۼӡ������ʾ��ͼ���Գ������ڻ�ʢ�ٴ�ѧһ�š�Deep learning systems���γ̵Ŀμ�������Ȥ�Ķ��߿���ȥ�γ���վ��ȡ�������ϡ�
ע�������û������DAG ����֮Ϊ��ͼ��logical graph��, ϵͳһ������ñ�����������ͼ�����Ż���д����ͼ���е�һЩ�Ż����ɾͲ�һһչ�������ˡ������Ż������͵�ִ������ִ�е�ͼ������ͼ��physical graph��������ͼ���ܺ��������ͼ�Ѿ���Ȼ��ͬ�ˡ���TensorFlow, PyTorch, MXNet, Caffe2 �ж����Կ�����Щ�������Ż��취��
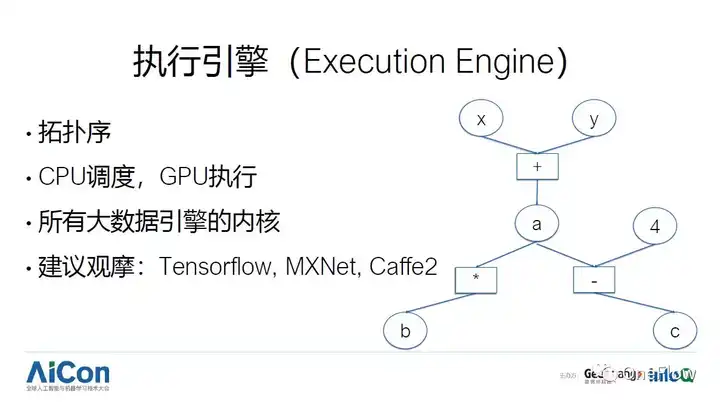
ע��ִ�����������ѧϰ����ĺ��ģ�����ԭ���ǰ�������ȥִ������/������������ͼΪ�����տ�ʼ���˷��ͼ���������ִ�У���Ϊ����������һ������a��û�����ɣ���������ִ�����������Ѿ������IJ����������ӷ������ӷ���ɺ�ִ��������DAG ��ɾ���Ѿ�ִ�еĽڵ㣬Ȼ���ֳ˷��ͼ�����ִ�������Ѿ������ˣ���ȥִ�г˷��ͼ�������ʵ�ϣ���ǰ���д����ݴ���������ں˶��������ԭ��ʵ�ֵġ������ѧϰ������Ҫע�����������CPU��ִ�еģ�������������ʵ��������GPU����ɵģ�Ϊ�˸�ЧЭ��CPU��GPU֮��Ĺ������ھ���ʵ������һЩ���ɡ�����Ȥ�Ķ��߿��Թ�ĦTensorFlow, MXNet, Caffe2 ��ִ�����棬Ҳ����ᷢ���и��õ�ʵ�ְ취��
ע����ִ��Ч�ʿ��ǣ����ѧϰ��ܵײ�һ�����C++�������������ԽǶȳ�����Ҳͬʱ�ṩPythonǰ�˱������ݿ�ѧ��ʹ�á���ͼ������ɷɽ�����˹̹����cs231n�γ̿μ���չʾ��Numpy��TensorFlow��PyTorch ��ͬһ����������ѵ�����̵�ʵ�֡��������Numpy ���룬���ĵ�һ����ɫ��imperative programming���Ǽ�ʱ��ֵ��eager evaluation����������b = a + z ������䣬b�Ľ���ͳ����ˣ��ڶ�����ɫ��û��autograd�������û�����Ҫдǰ�����Ĵ��룬��Ҫ�Ѻ����ݶ��½��Ĵ���д��������TensorFlow��PyTorch��֧����autograd���ڴ�����ֻ��Ҫдǰ�����Ĺ��̣���������������ϵͳ�Զ������ġ�TensorFlow ��PyTorch���������ǣ�ǰ����lazy evaluation��������eager evaluation����TensorFlow �У�a = x + y; b = a + z ֻ��һЩ����ʽ��������һ��������ͼ����ִ��sess.run ʱ�̲Żᱻ����ִ�У�����ִ��˳��һ���ͱ���ʽ����˳��һ�¡���PyTorch�У���Numpyԭ�����ƣ�ÿ����䶼������ִ�У����Ұ�����������˳��ִ�С�����ȥ��PyTorch�Ĵ����ȷ���Ӽ�࣬���Ļ��һ�������ӳ���ֵ�ͼ�ʱ��ֵ�����⡣
ע�����ѧϰ��ܲ�ֻҪ��������Ժ�Ч�ԣ���Ҫ���㲿����ά����ǰ���������ѧϰ��ܶ��ǻ��ڼ������ʵ���ݴ���Fail fast and warm start�����ѧϰ��ܻ���Ҫ�������εĿ�Դ�������л��νӣ�Ʃ��ֲ�ʽ���ݴ洢������Ԥ��������Hadoop����Spark��������ά�����ڱȽ��Ƴ����Docker��Kubernetes���ϵķ������û���ʱ��Ҫ�ڶ�����֮���л�������ONNX�����Ƴ���Ҳ�������˸��ֿ�ܼ��Ǩ�ƣ�Ʃ��ʹ��PyTorch ������ѵ����ģ�Ϳ���ONNX�淶����������Caffe2���ʹ�á����˽��ѵ�����⣬���ѧϰ��ܻ��������߲���Ϊ��TensorFlow�Ƴ��˵�����servingģ�顣
ע����������̽��һЩ��ǰ��ܿ��������岻����һ��Īչ�ļ������⡣
ע��Define-and-run �� Define-by-run ���ڹ�ע�ȱȽϸߣ�PyTorch ��Define-by-run ������������˺ܶ���ߡ������������������ȼ۵�������Ʃ��define-and-run�������Ϻ�lazy evaluation, �� declarative programming, data flow ��һ���£�ͨ����ζ��Ч�ʸߡ�define-by-run ������Ϻ�eager evaluation�� imperative programming ��control flow ��һ���£�ͨ����ζ������ԡ�������ܶ����ڻ������ƽ�֧��define-by-run������ģʽ��Ʃ��TensorFlow ������eager evaluation��MXNet �Ƴ���gluon �ӿڣ�PaddlePaddle Fluid Ҳ��һ��imperative programming���÷����������ּ���ѡ������ô�����أ� ������Ϊ����1��Imperative programming ֻ�����Ǵֳ���Ա������Ϥ�ı�̷�ʽ��ʵ��һ��imperative programming�����ѧϰ���Ҫ��ʵ��һ��declarative programming�Ŀ�ܼ����ֻ��ʵ��autograd�����ӵ�Ҫ֧��JIT������ͳ��lazy evaluation�������imperative programming�ӿڿ���������PyTorch ��ȫһ�����û����飬ֻ����Ҫ��Щ���¡���2��ֻҪdeclarative programming ����˵������ѵ����⣬���Ƕ��û����Ѻõ�һ�ֱ��ģʽ���û�ֻҪ��д����ʱ���� what��������Ҫ���� how���ײ�ϸ�ڶ��û����������ִ��������Եķ�չ���ơ���3�����кͲ���������δ�������ƣ���ô������������ʽ��̣�����ʽ��̣�������δ����data flow ģ��������������ϵͳִ������ļ�����϶�����Ȼ���ơ�
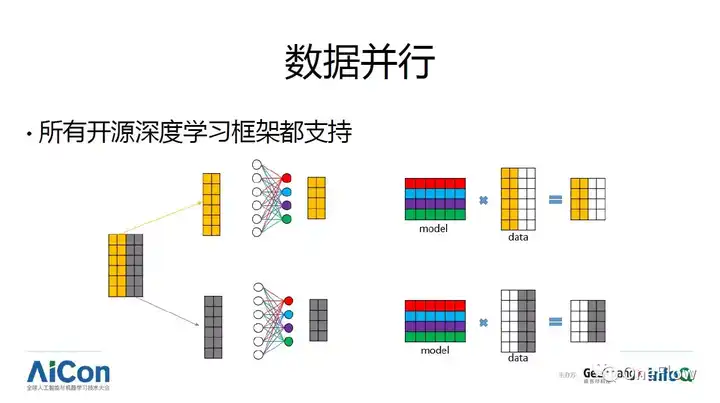
ע�����м����������������Ĺ�ģ��Ҳ���Լ��ټ��㡣���嵽���ѧϰ��ܣ���������ǣ����ݲ����Ѿ��õ�������������ĸ���ܶ��ܰ��ʺ����ݲ��е����������ӽ�������ٱȣ�Ʃ�������Ӿ��������CNNģ�ͣ����ݲ��к���ˮ�߲��в�֧�ֻ�֧�ֵIJ��ã�������ijЩ�ֲ�ʽѵ��������Ӳ�������ʹ��ͣ�ѵ�����ڹ������ڼ���ͨ�ţ�Collective communication operation�����л��ڲ����������ģ�MXNet, PaddlePaddle��TensorFlow��Ҳ�л���MPI������MPI���ģ�Ʃ��Caffe2��TensorFlow �ں�ۼܹ��ϻ�������Client, Master, Worker�ڵ㣬���ع����PaddlePaddleҲʹ�������Ƶļܹ���
ע�����п�ܶ�������֧�����ݲ��С�ԭ���������ݲ��е�һ������������ݶ��½��㷨������mini-batch����̫��̫���mini-batch �㷨����������͵��¼�ʹ�д����IJ����豸��Ҳ���Ӳ�����������������һϵ�гɹ�������������⣬Ʃ��Facebook �Ƴ���һ��Сʱѵ��ImageNet���Լ���������һϵ�й���������mini-batch �ƹ㵽32K, ��֤�㷨��Ȼ����������ܳ�ַ������ݲ��е����ơ�
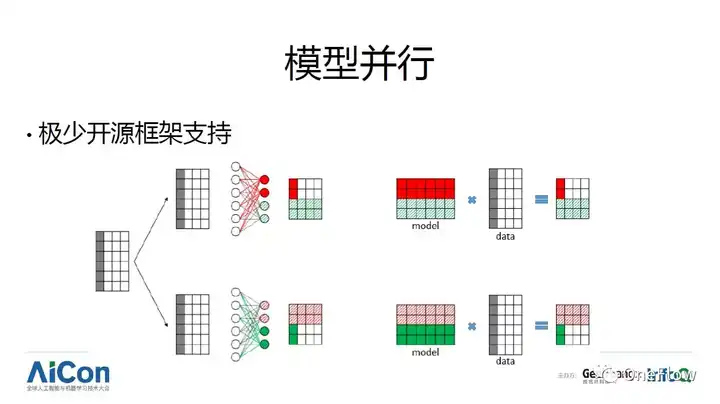
ע��ģ�Ͳ��б���ʵ�ָ��ӶȲ����ر�ߣ���Ҫ���������еij����ʺ����ݲ��У��еij����ʺ����ݲ��У��еij���ͬʱ��Ҫģ�Ͳ��к����ݲ��У������Ҫ����ʵ�������ȷ�Ķ�����������֯�����ѣ��ϲ�����·�ɣ���������ȷ�ķ��͵�Ŀ�ĵأ�scatter��broadcast�������о��ǣ�������·�ɱȽϸ���ʱ���ͺ��Ѹ�Ч��֧�֣�����Ҫ��ˮ�߲��е�֧�֡�
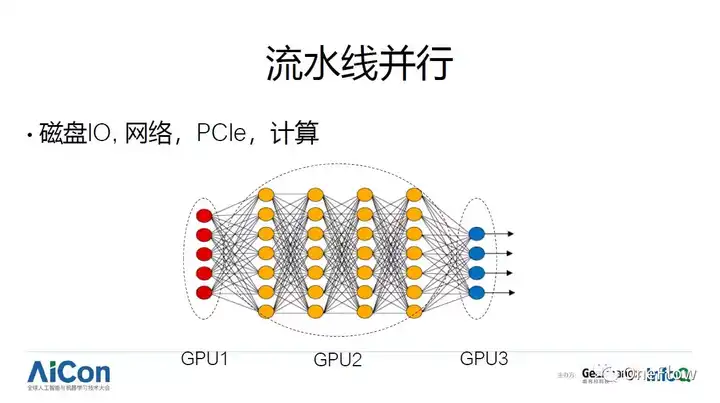
ע����������ģ�ͻ��м���״̬����ܴ�ʱ��Ʃ�糬��һ���Կ��Դ������������ʹ��ģ�Ͳ��У�������ʹ����ˮ�߲��С���ˮ�߲����е��������������ͼչʾ��һ�������ӣ���һ��GPU �����һ��ļ���ѽ�����ݸ��ڶ���GPU���ڶ���GPU ����м��IJ�ļ���֮�ѽ�����ݸ�������GPU��ɼ��㡣ͨ��ѵ�����ѧϰģ��ʱ�����ڶ���Σ�Ʃ������ݴӴ��̼��ص����棬�����ݴ�������˵�GPU, GPU ���һ���εļ���֮���ܻ���Ҫ������ͨ�����紫�͵���һ̨��������������������У���ˮ�߲��ж���ϵͳ����������Ҫ������ע����ֿ����IO�λ�����ˮ�߲��У����ڶ������Σ���������ͨ�Ž�֮�䶼û����Ӧ֧�֡��������п��ȥ֧��ģ�Ͳ��У���ˮ�߲��л��dz����ѡ�
ע���������һЩ���ǶԸ��ֿ�ܵ�������жϣ�����۵���ƫ��������⣬��ӭ����ָ����
ע�����Ͽ���û��Ƚ϶࣬�����ŶӼ���ʵ���ۺ����ѧϰ��ܵ�����Theano ��ֹͣ���£�����autograd�����Ѿ�����Щ�ִ���������գ�����û���о���������CNTK��Intel �չ���Nervana �ڿ���һ���µĿ��NGraph��Ҳֵ�ù�ע��������Ŀǰ��Ҫ�۽��ڵ��豸�Ż���DMLC��NVVM��TVM ����MXNet�ڣ���һ�������ձ��о���Ա�Ŀ��ChainerҲ�Ƚ�����ɫ��Python ǰ�˷dz���ˬ��
ע��TensorFlow ��ϵͳ��������ߵģ�֧��training��inference ��serving����֧��ͼ���õ�CNN��Ҳ֧����Ȼ���Ժ��������õ�RNN/LSTM�� �����ƶ��˵�TensorFlow Lite��֧��lazy executionҲ֧��eager execution��������̬��ǿ��Google�����ѧϰ�㷨��Ӧ�÷�����о�Ҳ�ǹھ����£��μ�Jeff Dean д�� Google Brain 2017 ��Ȼع� https:// zhuanlan.zhihu.com/p/32 905123 �����ѧϰ����ܶ��µ��о��ɹ�������TensorFlow���뷢���ġ���TensorFlow������Ҳ�ǹ���ڸ�������Dz������TensorFlow��Google�ڲ��Dz�������Խ�����ⲿ�û����ᆳ���������û���ԹTF ������ѧ���ҵ��ܶ�Benchmark����Ҳϲ����TensorFlow��baseline��Ʃ��CMU Eric Xing�����Ŷӷ�����Poseidon ���ģ�����TF ����һϵ���Ż�֮��������߷dz�������Uber �ŶӸ�����TensorFlow�ķֲ�ʽʵ�ֺ�PS����MPI��, CNN ���ݲ��г����������һ�������� ����Uber Horovod https:// github.com/uber/horovod
ע��Facebook AI Lab��Ʒ��PyTorch �����ѧϰ��ܵ�һƥ��������Eager evaluation �����˴������ѧϰ�о���Ա������������Imperative programming ������ͻ���Python�����Թ��죨����������������磬����Ըߡ�NLP ������һЩ��̬ͼ������PyTorch����ѡ��������Ϊ�ڵ��������£������Ժ������������Ҫ���û������������Ϊ��������������������ԭ��Ϊ�ֲ�ʽ��Ƶļ����ܹ�����һЩ��Э�����Ժ�PyTorch������ں˾�����PyTorch Ϊ�˿˷�Eager evaluation��һЩ���⣬Ҳ��ͨ��JIT������һЩLazy evaluation���ŵ㣬ͬʱҲ����ֲ�ʽ������������ǰ���������ڴ��ģ�ֲ�ʽӦ�ó����£��û�����ֻ����Lazy evaluation�����������ִ�������ڸ߲����߲��еij�������Ȼ�����ƣ�PyTorch ���ڵ����ʵ�־������Ŀ�껹�Ƚ�ңԶ��
ע��MXNet �����Ŷ�ʵ���ۺ�������Apache������Ŀ����Amazon�ٷ�֧�ּӳ֡�MXNet ���ص��ǰ����ܶ�����GeekƷζ��ʵ�ּ��ɣ� ��ֵ��ϲ������ǰ�ؼ�������ȥ��Ħ�������õĵط��ǣ�����һ�ֱȽϡ��ӡ��ĸо����ÿ����߸е�����Ʃ������������ʵ��Mshadow��NDArray��MXNet �ڼ�����Ӿ����������ܽ���ǰ��Ӧ�ã�һЩ�µ�ģ�ͳ����������ǵ�һʱ��֧�֡�MXNet ��һЩ������Ŀ��Ʃ��NNVM��TVM��Ŀǰ����TVM �����أ�NNVM��ʵ�ֵ�һЩͼ�Ż����������������Ҳ���ж�Ӧʵ�ֵģ���TVM ��TensorFlow XLA Ӧ���Ǵ���һ����Σ��۽��ڵ��豸���������Ż�������TVM, Halide, TensorFlow XLA ���û������ڵ��豸��ʹ������ʽ��̣��������Զ����ɸ�Ч�ĺ�˴��롣
ע��Caffe ���û����dz��࣬�ڶ��� Caffe2�͵�һ���Ѿ���Ȼ��ͬ�ˣ����̳���һЩ����Ʒ�������档��ܵij���dz���࣬�����أ�Op/Kernel��������Ҫ��C++��ʵ�֣������ӵ�ͼ���˽ṹ��Python���洦����Caffe2 �����TensorFlow ��Op/Kernel�ij���û����ʹ��֮ǰLayer���ְ����ݺͲ�������һ�����ơ�ͬ����Op/Kernel����Caffe2 Ҳ���Ǽ�ģ�£� ���뿴��ȥ���������Caffe2 Ŀǰ֧�����ݲ��У���������һ��Сʱѵ��ImageNet�ļ�¼����Caffe �и�����û����Գ��ԡ����˽⣬Caffe2 ��Facebook�ڲ��е��ˡ���ҵ��Ӧ�á��͡����𡱵����Σ�Ҳ�����˺ܺõ��ƶ���֧�֣���Ӧ����Caffe2 ����ɫ��Caffe2 ����һ��������ɫ�ļ�����gloo������Ƕ��Ƶ�MPI ʵ�֣��С�ȥ���Ļ�����Ⱥͨ�ŵ�ζ����Ҳ����֧����ˮ�ߡ�
ע��PaddlePaddle ���������ǰٶ��ڲ��ڹ㷺ʹ�ã�������ʵս���顣��һ��PaddlePaddle �DZȽϽӽ� Caffe���ֲ�ʽ����Ҳ������Parameter server�����һ�꣬Paddle�Ŷ��ڿ�չ�dz��������ع��������ǵ����⣬�ع���PaddlePaddle ����˺ܶ�TensorFlow����ƣ�����Paddle �ܷ���TensorFlow ���ٵ������أ� �ع����PaddlePaddle ��������ʽ��̽ӿڣ�������������PyTorchʱ��˵�ģ�����ʽ��̽ӿڹ�Ȼ������������ʾ�ڴ��ģ�ֲ�ʽ���г�������Ȼ�����ƣ���ʾ����������ʵ�ָ��Ӷȷ��棩��Ҫ�ܺõ�֧�ִ��ģ�ֲ�ʽ���������ѧϰ�������Ҫ�ѡ������������뷭��ɡ��������������ں�̨���С�
ע���������������ѧϰ��ܿ����ľ��ּ��������Ѿ������ˣ�����һ�������ѧϰ���û����ô�ѡ�������һ���濴��Ҫ����һ�������Ժ�Ч�Զ���Խ�Ŀ���Ƿdz����ѵģ���ʹ��������������Ŀ����Ŷ�Ҳ�е��������أ��˷���Щ������Ҫ������Ĵ��ºͼ�֡�
ע��չ��δ��һ�꣺��1�� ������Ϊ�ڼ�����Ӿ�����Ҳ��ӭ��ģ����ij�����Ʃ���Hinton��Capsule net ��Cifar ����ImageNet ��ģ��ģ�ʹ�С��Զ����ǰ���ֳ�����CNN, ������������ģ�ͷ��ѵ�����豸��ȥ��ɣ�Ҳ������ν��ģ�Ͳ��С�����ѧ��ܹ���������ṹѧϰ��Ԫѧϰ��Ҳ�б�Ҫȥ̽��CNN֮��ļܹ�����������Ƥ�㾡�ܴ���CNN������Ԫ�ֲ���֯�;ֲ�����Ұ����Ԫ������û����νweight sharing����Ԫ�����������Ƶ�����ѡ���ԣ��������ϸ�һ������������Ԫ֮������ӹ�ģ�dz��Ӵ����ȥ�����Լ���ᷢ��ʲô��������ѧϰ��ܲ���֧��ģ�Ͳ��У���ô���������ֻ����Cifar, MNIST�������ݼ�����ȥ̽������������ImageNet���������ģ��������ȥ̽��������Щ�������ڴ��ģ�����ϲŻᡰӿ�֡���������2��δ����ͨ�õ����ѧϰ��ܻ�֧��ģ�Ͳ��У������û�ʹ��ģ�Ͳ�������̽��ȡ���3�����ѧϰ����ೡ��������Ȼ��Ȼ����4��һ��һ�������֤���������ѧϰ��ܶ���ȥӵ������֧�������������ܶ������ṩimperative programming�ӿ�һ����ͬ�ʻ��DZȽ����صģ�δ����ҪһЩ�µĿ������µ�˼·ȥ�����Щ����δ�������⡣��5���ڴ����ݺ��˹�����ʱ�������ݻ��۵����ٽ�㣬��ҵ����������ݴ洢������ɸѡ��Щ�����ձ���Ҫһ�����ԣ�Brain������Ϊ��������ҵ������棬���ѧϰ��ܻ���Hadoop һ������һ���ӡ���ʱ��л��ǰ�࣬����Ѱ�����ռҡ��Ĺ��̡�