在知识问答中,要把一个自然语言的问句映射到知识库 KB 中是很难的,目前的问答系统通常是将 NLP 问句转换成一个 SPARQL 查询语句去检索 KB。如何完成这一转换过程面临着很多问题,比如怎么在 KB 中找到和问句中匹配的实体与关系。
首先问题中的实体名可能不完全依照数据库中的名称,同一个实体有多种叫法。其次数据库中多个实体对应的名称可能是一样的。比如 Freebase 里叫 apple 的就有 218 种实体。精确匹配的话很难找到答案,模糊匹配又会从大型数据库中搜索到冗余的数据。
本文在学习算法基础上采用了 learning-to-rank 来重点关注被大部分工作忽略掉的实体识别的问题。
模型介绍
本文要完成的任务是根据 KB 知识来回答自然语言问题,给出了一个叫 Aqqu 的系统,首先为问题生成一些备选 query,然后使用学习到的模型来对这些备选 query 进行排名,返回排名最高的 query,整个流程如下:
比如要回答这个问题:What character does Ellen play in finding Nemo?
1. Entity Identification 实体识别
首先在 KB 中找到和问句中名词匹配置信度较高的实体集合,因为问句中的 Ellen,finding Nemo 表达并不明确,会匹配到 KB 中的多个实体。
先用 Stanford Tagger 进行词性标注。然后根据词性挑出可能是实体的词与 KB 进行匹配,利用了 CrossWikis 数据集匹配到名称相似或别名相似的实体,并进行相似度评分和词语流行度评分。
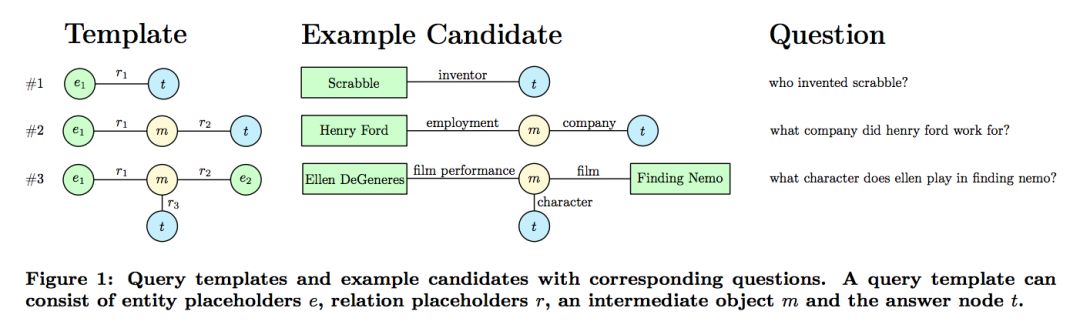
2. Template Matching 模板匹配
这一步对上一步得到的候选实体在数据库中进行查询,然后利用三种模板生成多个候选 query。三种模板和示例如图所示:
3. Relation Matching 关系匹配
这一步将候选 query 中的 relation 与问句中剩下的不是实体的词进行匹配,分别从 Literal,Derivation,Synonym 和 Context 四个角度进行匹配。
Literal 是字面匹配,Derivation 利用 WordNet 进行衍生词匹配,Synonym 利用 word2vec,匹配同义词。Context 则是从 wiki 中找出和 relation 匹配的句子,然后利用这些句子计算原问句中的词语和这些 relation 匹配出现的概率,采用 tf-idf 算法。
4. Answer Type Matching 答案类型匹配
这里采用了较为简洁的方法,将 relation 连接的对象类型和问句中的疑问词匹配,比如 when 应该和类型为日期的对象匹配。
5. Candidate Features 人工设计的特征
- 实体匹配的特征:(1)备选 query 中实体的个数(2)字面大部分匹配的实体个数(3)实体中匹配的token的数量(4-5)实体匹配概率的平均值和总和(6-7)实体匹配流行度的平均值和总和
- 关系匹配的特征:(8)匹配模板中的关系个数(9)字面匹配的关系个数(10-13)分别在 literal,derivation,synonym 和 context 四个角度匹配的 token 个数(14)同义词匹配总分(15)关系上下文匹配总分(16)答案的 relation 在 KB 中出现的次数(17)n-gram 特征匹配度
- 综合特征:(18)特征 3 和 10 的总和(19)问句中匹配到实体或关系的词所占比重(20-22)二进制结果大小为 0 或 1-20 或大于 20(23)答案类型匹配的二元结果
6. Ranking
本文采用了基于 learning-to-ranking 的方法根据上述特征对备选结果进行 ranking。作者使用了 pairwise ranking,针对两个备选的 query,预测哪一个评分更高,然后取胜出最多的那个。
分类器采用了 logistic regression 和 random forest。
实验结果
本文使用 Freebase 作为 KB,但对于 WikiData 同样有效。
数据集使用了 Free917 和 WebQuestions。前者手动编写了覆盖 81 个 domain 的自然语言问句,语法准确,每个问句都对应一条 SPARQL 语句,用它可以在 KB 中查到标准答案。训练集和测试集比例为 7:3。
WebQuestions 包含 5810 条从 Google Suggest API 上爬下来的问句,和 Free917 不同的是,它比较口语化,语法不一定准确,并且问题覆盖的领域多为 Google 上被问到最多的领域。答案是用众包生成的,噪声较大,训练集和测试集比例为 7:3。
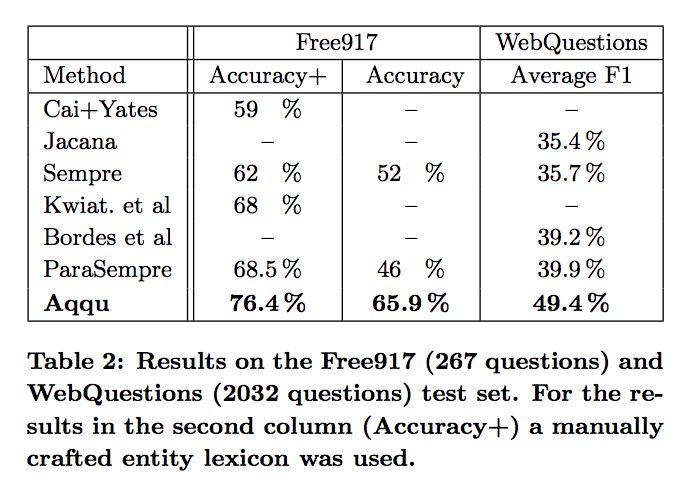
和 Sempre,GraphParser 等结果较好的模型比较了 accuracy 和 F1 score,结果如下:
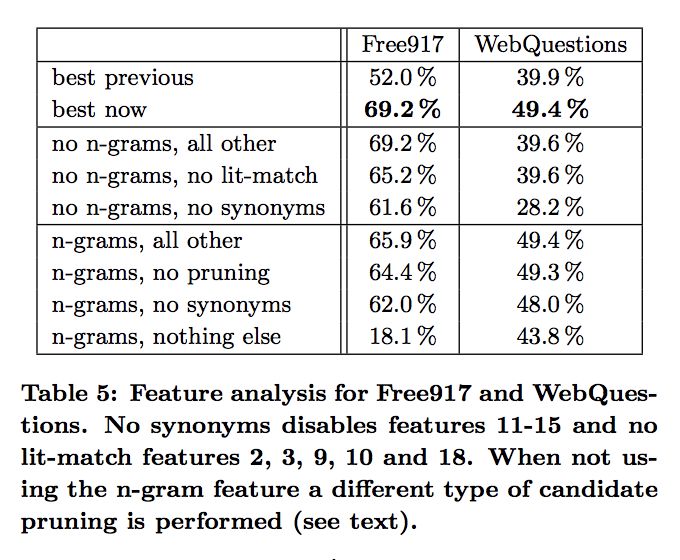
文章还分析了每个特征对系统可靠性的影响:
对于 80% 的查询,正确答案都能出现在 Top-5 里。