
我们对机器学习的发展认识,很大程度上取决于少数几个标准基准,比如CIFAR-10,ImageNet或MuJoCo。这提出了一个至关重要的问题:我们对目前机器学习进展的衡量有多可靠?
近年来人工智能发展,大的,比如一项又一项“超越人类水平”的进步,以及小的、甚至几乎每天都在发生的(这要感谢Arxiv),比如在各种论文中不断被刷新的“state-of-the-art”,无不让人感叹领域的蓬勃。
但是,实际情况或许并没有这么美好。
一项伯克利和MIT合作的新研究,对过去近十年中提出的一些经典分类器(比如VGG和ResNet)进行再测试后发现,由于测试集过拟合,很多分类器的精度实际并没有宣称的那么高;在新的数据集上测试结果表明,这些分类器的精度普遍都有下降,幅度4%~10%不等。
研究者表示,这一结果可以被视为证据,证明模型的精度这个数字是不可靠的,并且容易受到数据分布中微小的自然变化的影响。
这项新的研究也提出了一个值得反思的问题――我们目前用来衡量机器学习进展的手段和方法,究竟有多可靠?
重复使用相同的测试集,无法推广到新数据
作者在论文中写道,在过去五年里,机器学习已经成为一个实验领域。在深度学习的推动下,大多数发表的论文都采用了同一种套路,那就是看一种新的方法在几个关键基准上性能有多少提升。换句话说,就是简单粗暴地对比数值,很少有人去解释为什么。
而在对比数值的时候,大多数研究的评估都取决于少数几个标准的基准,例如CIFAR-10、ImageNet或MuJoCo。不仅如此,由于Ground truth的数据分布一般很难得到,所以研究人员只能在单独的测试集上评估模型的性能。
“现在,在整个算法和模型设计过程中,多次重复使用相同的测试集的做法已经被普遍接受。尽管将新模型与以前的结果进行比较是很自然的想法,但显然目前的研究方法破坏了分类器独立于测试集这一关键假设。”
这种不匹配带来了明显的危害,因为研究人员可以很容易地设计出只能在特定测试集上运行良好,但实际上无法推广到新数据的模型。
CIFAR-10可重复性实验:VGG、ResNet等经典模型精度普遍下降
为了审视这种现象造成的后果,研究人员对CIFAR-10以及相关分类器做了再调查。研究的主要目标是,衡量新进的分类器在泛化到来自相同分布的、未知新数据时能做得多好。
选择标准CIFAR-10数据集,是因为它透明的创建过程使其特别适合于这个任务。此外,CIFAR-10已经成为近10年来研究的热点,在调查适应性(adaptivity)是否导致过拟合这个问题上,它是一个很好的测试用例。
在实验中,研究人员首先用新的、确定是模型没有见过的大约2000幅图像,制作了一个新的测试集,并将新测试集的子类分布与原始 CIFAR-10 数据集仔细地做匹配,尽可能保持一致。
然后,在新测试集上评估了30个图像分类器的性能,包括经典的VGG、ResNet,最近新提出的ResNeXt、PyramidNet、DenseNet,以及在ICLR 2018发布的Shake-Drop,这个Shake-Drop正则化方法结合以前的分类器,取得了目前的state-of-art。
结果如下表所示。原始CIFAR-10测试集和新测试集的模型精度,Gap是两者精度的差异。ΔRank表示排名的变化,比如“-2”意味着在新测试集中的排名下降了两个位置。
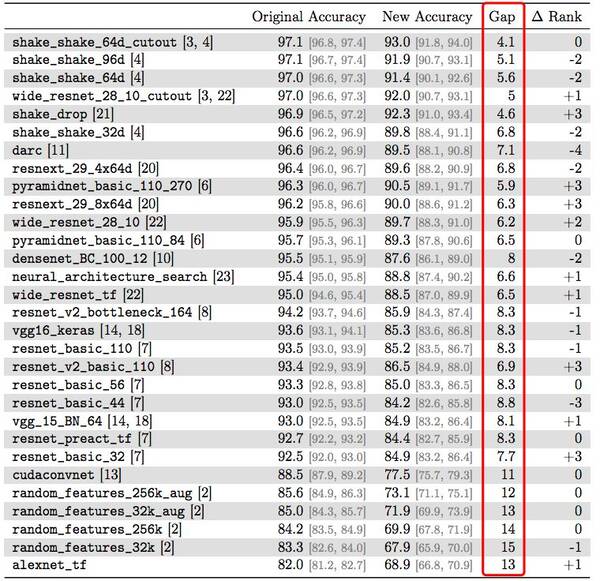
由结果可知,新测试集上模型的精度相比原始测试集有明显下降。例如,VGG和ResNet这两个模型在原始数据集上准确率为93%,而在新测试集上降为了85%左右。此外,作者还表示,他们发现现有测试集上模型的性能相比新测试集更加具有预测性。
对于出现这种结果的原因,作者设定了多个假设并一一进行了讨论,除了统计误差、调参等之外,主要还是过拟合。
作者表示,他们的结果展现了当前机器学习进展令人意外的一面。尽管CIFAR-10测试集已经被不断适应(adapting)了很多年,但这种趋势并没有停滞。表现最好的模型仍然是最近提出的Shake-Shake网络(Cutout正则化)。而且,在新的测试集置上,Shake-Shake比标准ResNet的优势从4%增加到8%。这表明,瞄准一个测试集猛攻的研究方法对过拟合而言是十分有效的。
同时,这个结果也对当前分类器的鲁棒性提出了质疑。尽管新数据集只做了微小的改变(分布转移),但现有的被广泛使用的模型,分类准确性普遍显著下降。例如,前面提到的VGG和ResNet的精度损失对应于CIFAR-10的多年进展。
作者特别指出,他们的实验引起的分布转移(distributional shift)既不是对抗性的(adversarial),也不是不同数据源导致的结果。因此,即使在良性环境中,分布转移也会带来严峻的挑战,研究人员需要思考,目前的模型真正能泛化到什么程度。
机器学习研究也需要注意可重复性
Python Machine Learning 一书作者Sebastian Raschka评论这项研究认为,它再次提醒机器学习研究人员注意测试集重复使用(以及违背独立性)的问题。
谷歌大脑研究科学家、Twitter账户hardmaru表示,对机器学习研究进行可靠评估的方法十分重要。他期待见到有关文本和翻译的类似研究,并查看PTB,wikitext,enwik8,WMT'14 EN-FR,EN-DE等结构如何从相同分布转移到新的测试集。
不过,hardmaru表示,如果在PTB上得到类似的结果,那么对于深度学习研究界来说实际上是好事,因为在PTB这个小数据集上进行超级优化的典型过程,确实会让人发现泛化性能更好的新方法。
作者表示,未来实验应该探索在其他数据集(例如ImageNet)和其他任务(如语言建模)上是否同样对过拟合具有复原性。此外,我们应该了解哪些自然发生的分布变化对图像分类器具有挑战性。
为了真正理解泛化问题,更多的研究应该收集有洞察力的新数据并评估现有算法在这些数据上的性能表现。类似于招募新参与者进行医学或心理学的可重复性实验,机器学习研究也需要对模型性能的可重复多做研究。
相关论文:Do CIFAR-10 Classifiers Generalize to CIFAR-10
地址:https://arxiv.org/pdf/1806.00451.pdf


















