
自然语言处理是人工智能的一个重要应用方向,上世纪五六十年代,人工智能的主要研究是,搜索的算法或者推理的算法。但是,人们在这个方面研究了一段时间后,意识到有一个问题不可回避,那就是知识。我们很多系统中没有领域的知识或者专家的知识,在这种情况下,无法去做推理算法。这时,知识就成为人工智能一个非常重要的问题。
1977 年,Feigenbaum 提出,知识是人工智能非常重要的方向。2012 年,Web2.0 已经面世,网络上有了维基百科、百度百科等宝贵的知识资源。再加上信息抽取等自然语言处理技术的进展,这使得以前依靠专家来建立知识库的传统方法发生了显著的变化,知识库的规模和类型也都发生了显著的变化,知识工程再次成为人工智能的一个热点,它跟深度学习和情感一样,都是新一代人工智能的很有代表性的工作。
知识图谱有以下几种:
实体图谱,是一种是我们常见的以实体为中心的图谱。例如,图谱中间的一块上,每一个节点都是一个实体,例如 Barack Obama 和 Michelle Obama,它们之间通过夫妻这种关系联系起来,现在的大多数图谱就是这样的。
事件图谱,事件的知识图谱是应用中不可缺少的一类图谱,其中的每一个节点是一个事件,事件之间通过事件的关系(比如时序关系、因果关系等)相关联,这就叫做事件的图谱。
实体图谱和事件图谱,对于我们做问答,以及其他应用来说都必不可少。无论是实体图谱还是事件图谱,我们不可能完全依靠人工去构建,我们需要关键技术的支撑,这个关键技术就是信息抽取的技术。
实体的识别是最基础的,有了实体以后,做实体图谱需要做关系抽取,比如(比尔盖茨是微软的 CEO),我们要转成三元组的结构化方式,CEO(比尔盖茨,微软)。当然。还存在多元的关系,它们都可以转成二元的关系,这样存储和应用的时候,效率更高。
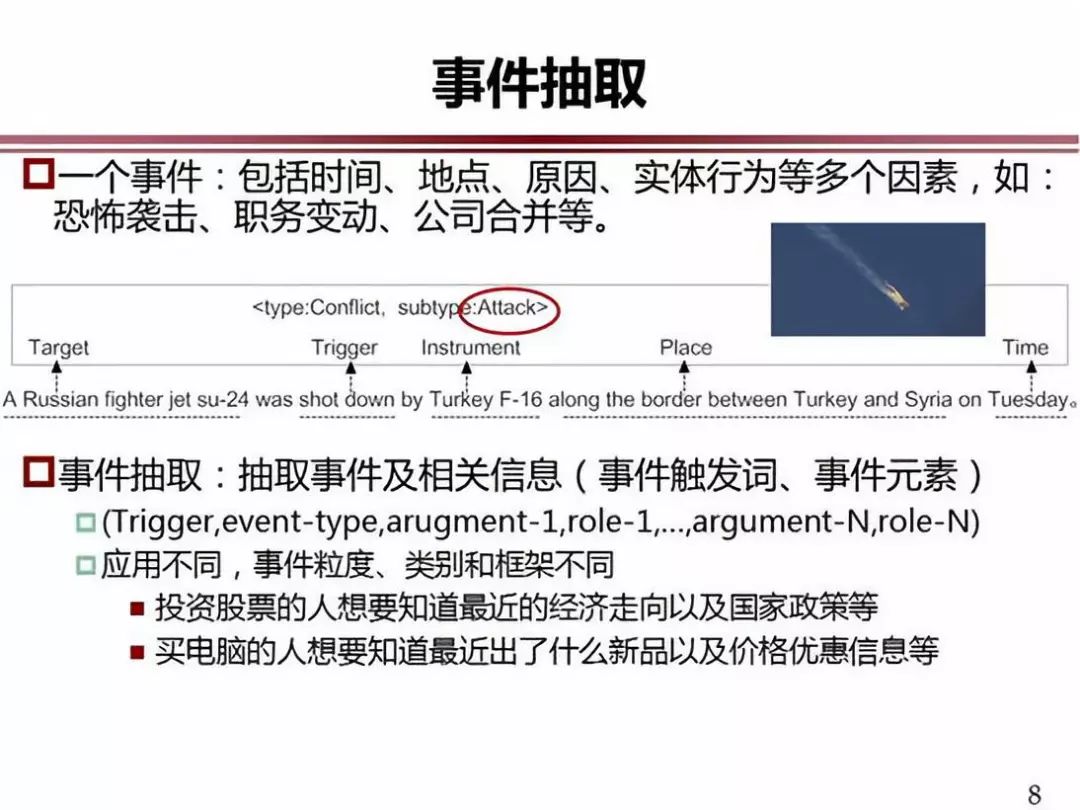
事件的抽取与事件图谱相关联,举个例子,土耳其的飞机失事事件,这样一个事件的类别属于恐怖事件,袭击的目标是俄罗斯战机,袭击的工具是 F-16,还有地点和时间,这就是事件。我们要从一个文本当中找出这样的事件信息并进行结构化,这就是事件的抽取。
有关事件的关系其实也有很多,目前,我们应用方面比较关注的是事件的同指关系,还有时序关系、因果关系、上下位关系等。
今天我讲的是事件的抽取,也捎带讲一点关系的抽取。
刚才,我主要讲解的是开放域的事件的抽取。我们先了解什么是开放域,在谈到开放域之前,来看看传统的关键抽取是什么样子的。传统的叫预定义的关系抽取。我们抽取的目标关系类别是定义好的,我们给定的语料的结构是比较单一的,这种就是预定义的关系抽取。
学界、产业界在这方面做得很多,国际上也有评测,一般都给定一些标注语料,这都是有监督的关键抽取的技术。ACE 是美国的一个评测,评测的就是这个表中列出的实体关系类别。这是 SemEval 的实体关系的类别,这是 TAC-KBP 的实体关系类别,都是预定好的。
预定义的关系抽取,有各种各样的方法来做预定义的关系抽取。现在,大家所共同关注的还是深度学习的方法。2014 年 COLING 上,我们首次使用深度学习的方法做了基于卷积神经网络的预定义关系抽取。基于深度学习的关系抽取方法在性能方面,较传统方法有明显的提升。

那么为什么要研究开放域关系抽取呢?我们来看:
Freebase:4000 多万实体,上万个属性关系,24 多亿个事实三元组,这样级别的关系抽取,如果还是依靠刚才的那种方法,依靠人工标注的训练集,在这方面肯定行不通,这时我们就必须考虑一些自动的或者弱监督、半监督的方法,来做开放的关系抽取。
难点问题在于如何获取训练语料。有了语料还不行,我们还需要研究新的抽取方法。在这方面,国际上有两个有代表性的开放域关系提取的研究方法,一个是基于句法的方法,一个是基于知识监督的方法。
基于句法的方法,是美国华盛顿大学图灵实验室做的一系列工作,例如,(华为,总部位于,深圳),语料库中有各种表述方法,我们可以抽出(华为总部位于深圳,华为总部设置于深圳,华为将其总部建于深圳),都是相关的知识。我们需要通过句法分析器,对这样的句子找出三元结构,抽取出来放在一起,这是我们所需要的知识。
基于句法的方法的核心是句法分析器。然而,很多找出来的句法三元组并不是我们需要的有实际含义的三元组,这是我们需要人工设计一些规则,把这些有实际含义的三元组过滤出来,这就是基于句法的关系抽取的主要思想。这种方法存在的问题是:这些实体关系三元组知识抽取出来放在了一起,它们到底代表什么语义还不明确,它的语义并没有和人类的知识库挂接,所以这还不是一种彻底的理解。而且,同样的关系有各种各样的语言表示,没有归一化,所以,如何应用还存在很多问题。
基于知识监督的方法。2007 年 CIKM 的论文最早提出这样的思想,在 Wikipedia 中可以分成两个区域,一个区域是结构化部分,我们叫做 Infobox,另一个区域是自然语言表达的部分,这两部分描述的信息有重叠,比如描述清华大学和建校时间的知识,在 Infobox 和自然语言里面有重叠的描述,如果把这两部分对应起来,就可以对应两边区域的知识,一边是它的训练集。这是一个非常简单的思想。如果用 Infobox 的结构化信息在 wikipedia 条目的自然语言文本中进行回标,可以自动产生训练语料。

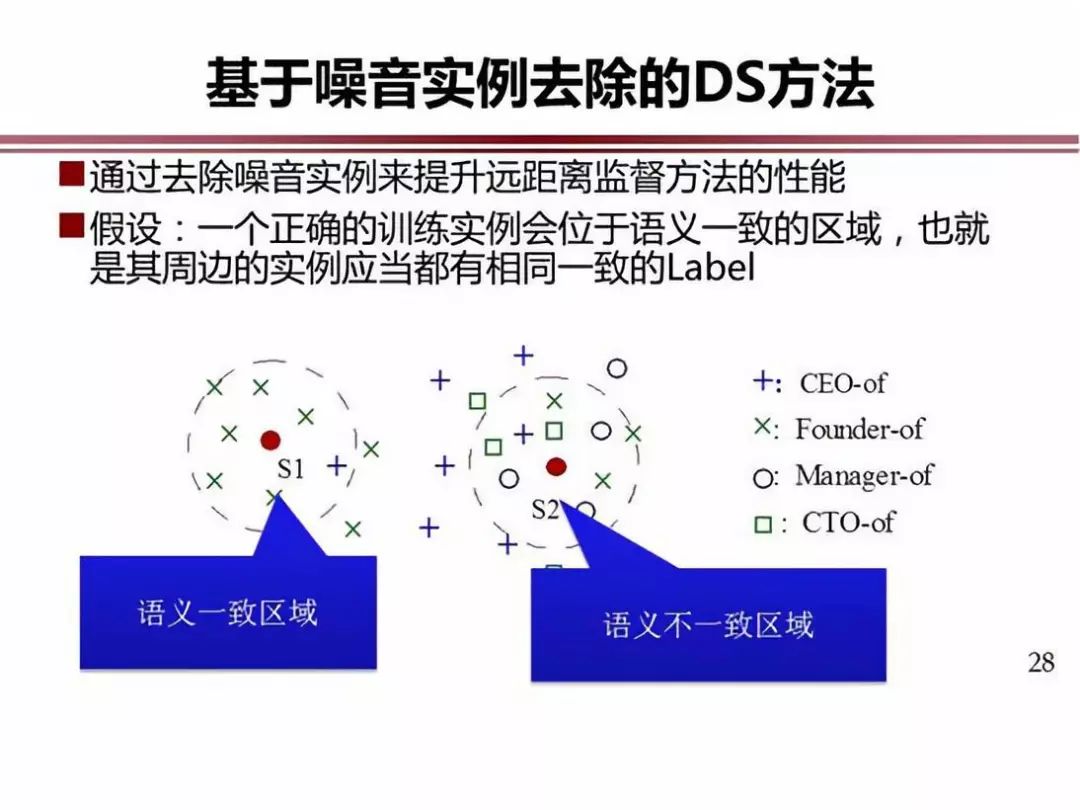
Mintz 发展了这种思想,提出了远距离监督方法或者说是知识监督方法。大家看这个例子,第一个例子是正例,剩下的都是反例(也就是噪音)。我们需要把里面标注的例子中的噪音例子给过滤掉。噪音问题目前是利用知识监督方法建立训练集的最大挑战。大家在这方面做了很多研究,主要思想是:正例有规律的出现,反例是零零散散出现,借助这样的思想进行过滤。
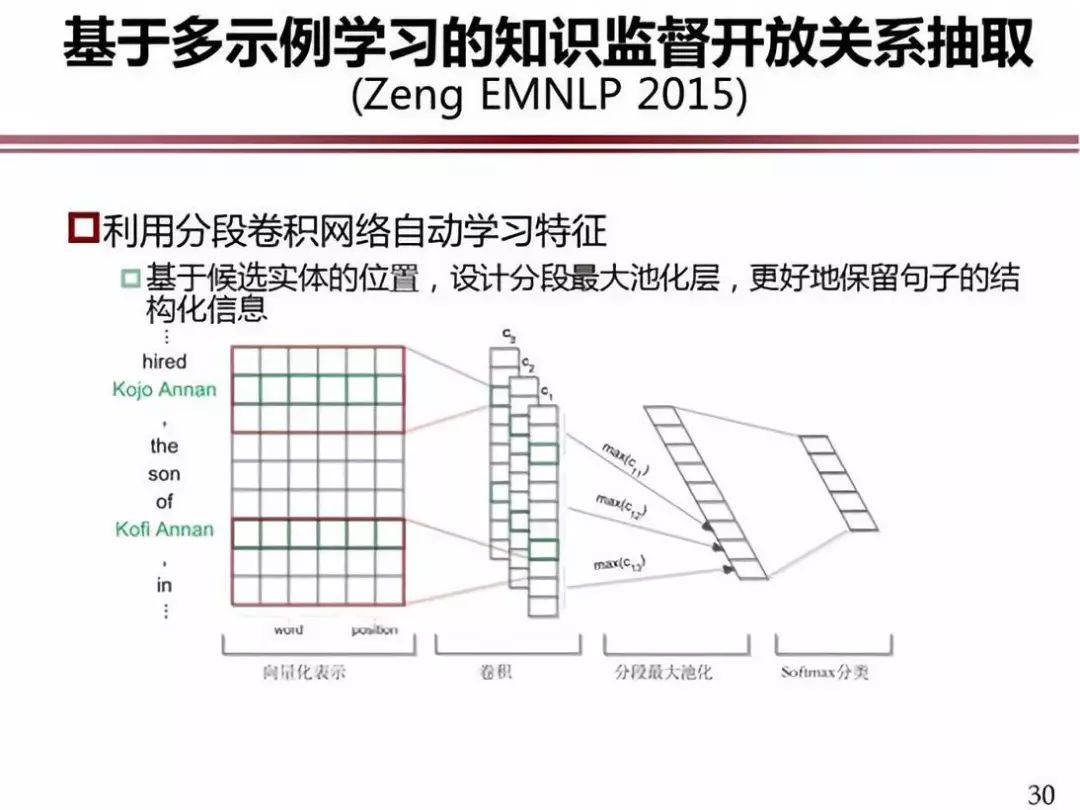
这是我们做的开放关系抽取的研究工作。我们用 Freebase 作为结构化知识,在纽约时报的文本上进行回标。作为过滤噪音的方法,我们用了多示例学习。在传统的方法中,假设回标的每个句子都表示这种关系,它的噪音就很多。在多学习示例当中,我们假定至少有一个句子表示了这种关系,目的就是要把最有可能的句子标注出来,这样它的准确率就比刚才那一个包里面的准确率高了,性能就会提高。
这件工作也是在深度学习框架下做的。因为做关系抽取,需要有两个实体,可以把句子分成三段。我们做深度学习和向量化的时候,不是一个句子做向量,而是把句子分成三部分,三部分分布做深度卷积操作,三部分的向量再合起来,来做整个句子向量化表示,这样可以保留句子的更多结构化信息,我们把这个模型叫分段卷积神经网络来自动学习特征。
这是我们标注的知识库和语料库,Freebase 和纽约时报。我们如果这样做的话,可以达到相对比较好的性能(大概在 70% 多的水平),虽然比较低,但已经比传统方法高,因为这是在 Freebase 的很多关系的类别上做的,能做到这个程度,其实就可以看到希望。
后面讲一下事件抽取。这是 ACE 的事件,可以定义的事件有这么多种。
预定义的事件抽取,预定义的事件抽取也是用神经网络做的。开放的事件抽取比开放的关系抽取要困难得多,为什么?
一个关系是由两个实体、以及它们之间的关系构成的。而一个事件不一样,比如一个婚姻事件,它有五个要素。我们可以把两个实体作为锚点,在文本中标注。这个事件有五个要素,但不可能在一个句子中找全五个要素,因为,事件经常横跨几句、甚至一 个段落才能找到要素。还有一个更重要的特征,中间这个是 Marriage,在 Freebase 里面表示为 ID 号,在文本当中不可能找到对应的位置,所以这个最鲜明的特征我们找不着,所以回标的过程中遇到了非常大的困难。换句话,事件里面最有表征意义的是那个触发词,但是知识库中只是一个标号,所以触发词就没有,这就很困难。
我们的方法,比如一类事件有 10 个要素,10 个要素不可能都出现,但是一个事件里面会有一些核心要素,我们就从一堆要素当中找出核心要素,用核心要素到句子当中找到触发词,将触发词和前面的要素关联到一起,再回标,就可以在文本当中找到更多数据,这就是我们的基本思想。在这件工作中,我们在 Freebase 上做了 21 类,ACE 只提供了 6000 个句子训练集,用我们这样的方法可以找到 42 万的语料,再过滤掉一些噪音,可靠性非常高的有 7 万多句,然后再训练事件抽取模型,触发词识别正确率达到 89%,元素标注正确率可以达到 85%。
今年,我们 ACL-2018 的一件工作也是在 Freebase 上做的,我们在一个具体的金融领域做一些项目(不是在通用领域),能不能发挥更好的作用。在金融领域做金融事件的挖掘,做了四类,冻结、质押、回购、增减持。能不能用知识监督方法建立建立训练语料把四类事件抽出来。我们主要的方法,利用金融知识库,回标的文本是上市公司年报,这是回标的句子,后面是回标以后具体的深度学习的方法,时间限制不做具体讲解。
从我们的实验可以看出来,在一个上市公司年报相对比较规范的文本中,知识库也比较详细,我们可以比通用领域做得更好,基本上可以达到 90% 的水平,给企业做这样的知识库,他们再去做人工的编辑,做出来的知识资源还是非常有用的,这是我们的方法在金融领域的应用。
知识图谱很重要,事件图谱是知识图谱中很重要的类型,为了建立事件图谱,我们需要研究开放域关系抽取,开放域事件抽取等等,其实可以在这方面做出很多有意思的工作,也可以有很多的应用,是一种很有潜力的方法。


















