



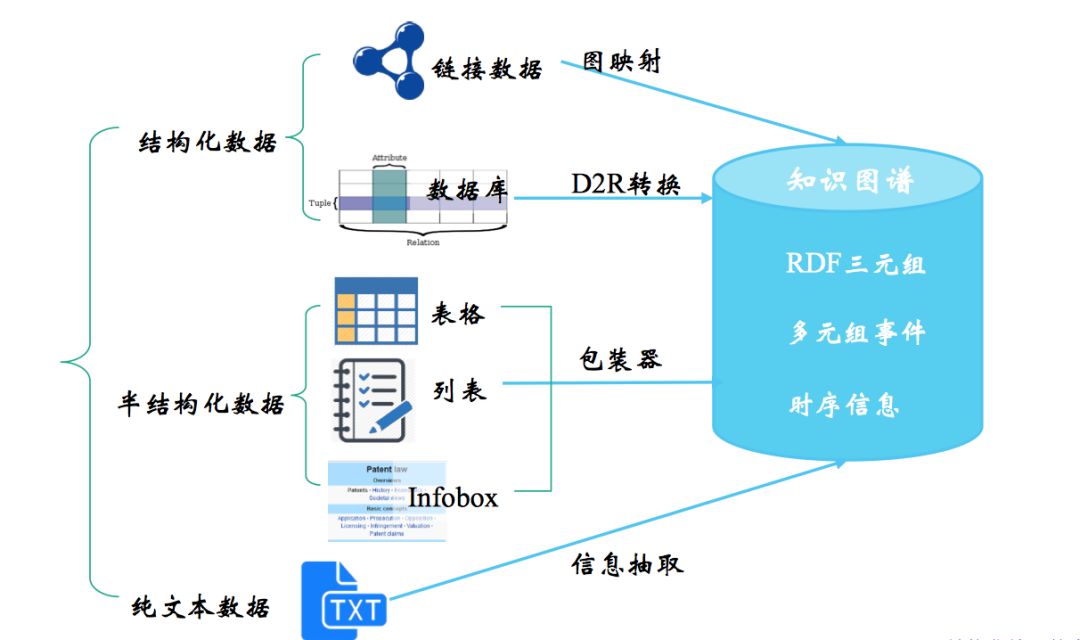
知识抽取涉及的“知识”通常是 清楚的、事实性的信息,这些信息来自不同的来源和结构,而对不同数据源进行的知识抽取的方法各有不同,从结构化数据中获取知识用 D2R,其难点在于复杂表数据的处理,包括嵌套表、多列、外键关联等,从链接数据中获取知识用图映射,难点在于数据对齐,从半结构化数据中获取知识用包装器,难点在于 wrapper 的自动生成、更新和维护,这一篇主要讲从文本中获取知识,也就是我们广义上说的信息抽取。
信息抽取三个最重要/最受关注的子任务:
-
实体抽取
也就是命名实体识别,包括实体的检测(find)和分类(classify) -
关系抽取
通常我们说的三元组(triple) 抽取,一个谓词(predicate)带 2 个形参(argument),如 Founding-location(IBM,New York) -
事件抽取
相当于一种多元关系的抽取
篇幅限制,这一篇主要整理实体抽取和关系抽取,下一篇再上事件抽取。
1. 相关竞赛与数据集
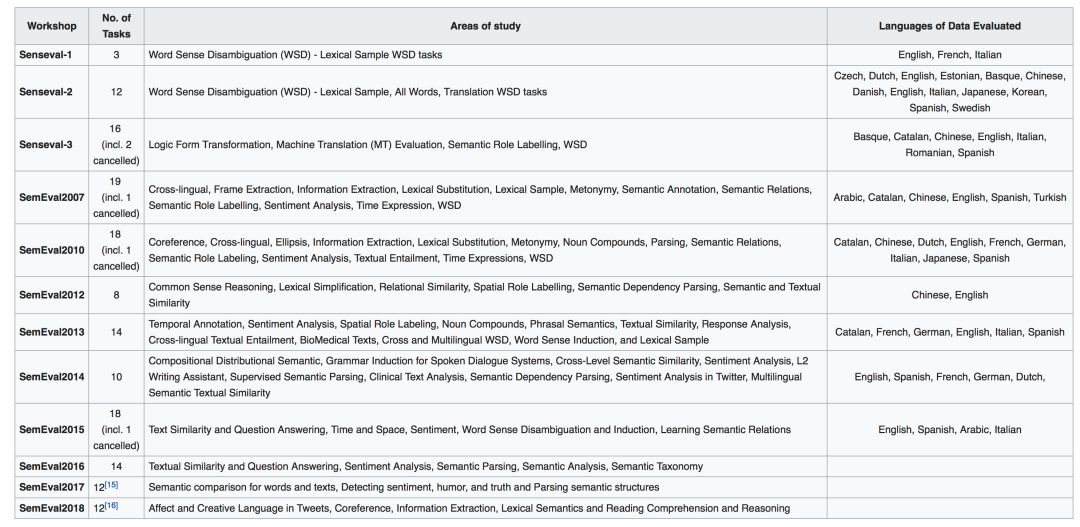
信息抽取相关的会议/数据集有 MUC、ACE、KBP、SemEval 等。其中,ACE(Automated Content Extraction) 对 MUC 定义的任务进行了融合、分类和细化,KBP(Knowledge Base Population) 对 ACE 定义的任务进一步修订,分了四个独立任务和一个整合任务,包括
-
Cold Start KB(CSKB)
端到端的冷启动知识构建 -
Entity Discovery and Linking(EDL)
实体发现与链接 -
Slot Filling(SF)
槽填充 -
Event
事件抽取 -
Belief/Sentiment(BeSt)
信念和情感
至于 SemEval 主要是词义消歧评测,目的是增加人们对词义、多义现象的理解。
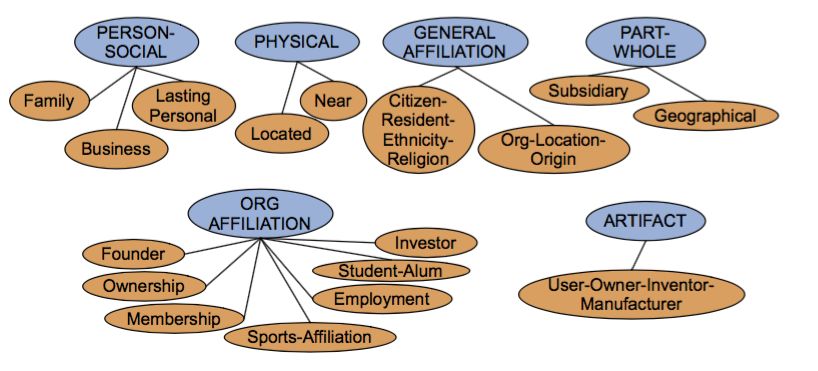
ACE 的 17 类关系
具体的应用实例

常用的 Freebase relations
 还有的一些世界范围内知名的高质量大规模开放知识图谱,如包括 DBpedia、Yago、Wikidata、BabelNet、ConceptNet 以及 Microsoft Concept Graph等,中文的有开放知识图谱平台 OpenKG……
还有的一些世界范围内知名的高质量大规模开放知识图谱,如包括 DBpedia、Yago、Wikidata、BabelNet、ConceptNet 以及 Microsoft Concept Graph等,中文的有开放知识图谱平台 OpenKG……
2. 实体抽取
实体抽取或者说命名实体识别(NER)在信息抽取中扮演着重要角色,主要抽取的是文本中的原子信息元素,如人名、组织/机构名、地理位置、事件/日期、字符值、金额值等。实体抽取任务有两个关键词:find & classify,找到命名实体,并进行分类。

主要应用:
-
命名实体作为索引和超链接
-
情感分析的准备步骤,在情感分析的文本中需要识别公司和产品,才能进一步为情感词归类
-
关系抽取(Relation Extraction)的准备步骤
-
QA 系统,大多数答案都是命名实体
2.1 传统机器学习方法
标准流程:
Training:
-
收集代表性的训练文档
-
为每个 token 标记命名实体(不属于任何实体就标 Others O)
-
设计适合该文本和类别的特征提取方法
-
训练一个 sequence classifier 来预测数据的 label
Testing:
-
收集测试文档
-
运行 sequence classifier 给每个 token 做标记
-
输出命名实体
2.1.1 编码方式
看一下最常用的两种 sequence labeling 的编码方式,IO encoding 简单的为每个 token 标注,如果不是 NE 就标为 O(other),所以一共需要 C+1 个类别(label)。而 IOB encoding 需要 2C+1 个类别(label),因为它标了 NE boundary,B 代表 begining,NE 开始的位置,I 代表 continue,承接上一个 NE,如果连续出现两个 B,自然就表示上一个 B 已经结束了。

在 Stanford NER 里,用的其实是 IO encoding,有两个原因,一是 IO encoding 运行速度更快,二是在实践中,两种编码方式的效果差不多。IO encoding 确定 boundary 的依据是,如果有连续的 token 类别不为 O,那么类别相同,同属一个 NE;类别不相同,就分割,相同的 sequence 属同一个 NE。而实际上,两个 NE 是相同类别这样的现象出现的很少,如上面的例子,Sue,Mengqiu Huang 两个同是 PER 类别,并不多见,更重要的是,在实践中,虽然 IOB encoding 能规定 boundary,而实际上它也很少能做对,它也会把 Sue Mengqiu Huang 分为同一个 PER,这主要是因为更多的类别会带来数据的稀疏。
2.1.2 特征选择
Features for sequence labeling:

再来看两个比较重要的 feature
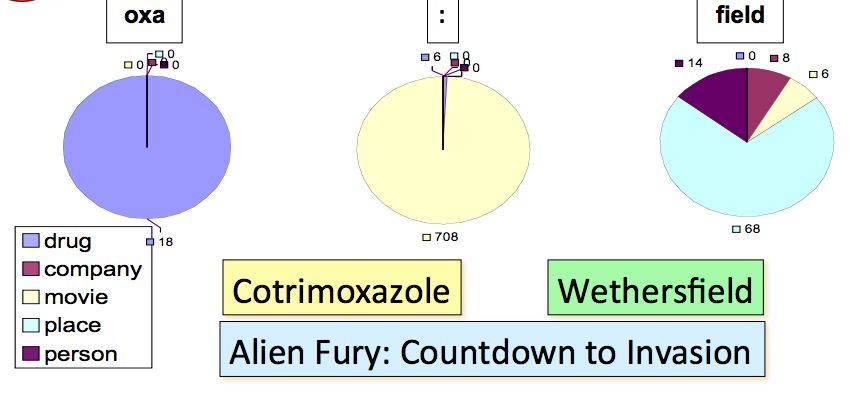
Word substrings
Word substrings(包括前后缀)的作用是很大的,以下面的例子为例,NE 中间有 ‘oxa’ 的十有八九是 drug,NE 中间有 ‘:’ 的则大多都是 movie,而以 field 结尾的 NE 往往是 place。
Word shapes
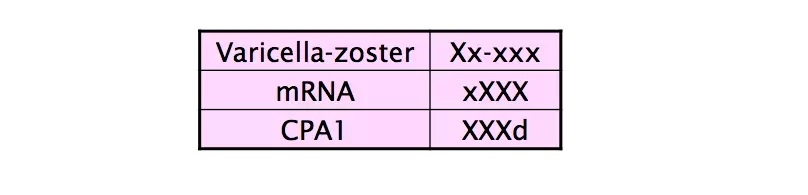
可以做一个 mapping,把 单词长度(length)、大写(capitalization)、数字(numerals)、希腊字母(Greek eltters)、单词内部标点(internal punctuation) 这些字本身的特征都考虑进去。
如下表,把所有大写字母映射为 X,小写字母映射为 x,数字映射为 d…

NLP 的很多数据都是序列类型,像 sequence of characters, words, phrases, lines, sentences,我们可以把这些任务当做是给每一个 item 打标签,如下图:

常见的序列模型有 有向图模型 如 HMM,假设特征之间相互独立,找到使得 P(X,Y)最大的参数,生成式模型;无向图模型 如 CRF,没有特征独立的假设,找到使得 P(Y|X)最大的参数,判别式模型。相对而言,CRF 优化的是联合概率(整个序列,实际就是最终目标),而不是每个时刻最优点的拼接,一般而言性能比 CRF 要好,在小数据上拟合也会更好。
整个流程如图所示:
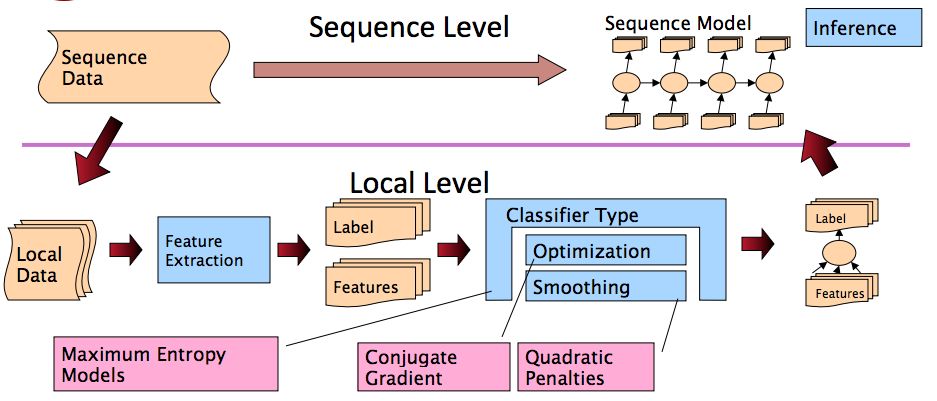
讨论下最后的 inference

最基础的是 “decide one sequence at a time and move on”,也就是一个 greedy inference,比如在词性标注中,可能模型在位置 2 的时候挑了当前最好的 PoS tag,但是到了位置 4 的时候,其实发现位置 2 应该有更好的选择,然而,greedy inference 并不会 care 这些。因为它是贪婪的,只要当前最好就行了。除了 greedy inference,比较常见的还有 beam inference 和 viterbi inference。
2.1.3.1 Greedy Inference
优点:
-
速度快,没有额外的内存要求
-
非常易于实现
-
有很丰富的特征,表现不错
缺点:
-
贪婪
2.1.3.2 Beam Inference
-
在每一个位置,都保留 top k 种可能(当前的完整序列)
-
在每个状态下,考虑上一步保存的序列来进行推进
优点:
-
速度快,没有额外的内存要求
-
易于实现(不用动态规划)
缺点:
-
不精确,不能保证找到全局最优
2.1.3.3 Viterbi Inference
-
动态规划
-
需要维护一个 fix small window
优点:
-
非常精确,能保证找到全局最优序列
缺点:
-
难以实现远距离的 state-state interaction
2.2 深度学习方法
2.2.1 LSTM+CRF
最经典的 LSTM+CRF,端到端的判别式模型,LSTM 利用过去的输入特征,CRF 利用句子级的标注信息,可以有效地使用过去和未来的标注来预测当前的标注。
2.3 评价指标
评估 IR 系统或者文本分类的任务,我们通常会用到 precision,recall,F1 这种 set-based metrics,见信息检索评价的 Unranked Boolean Retrieval Model 部分,但是在这里对 NER 这种 sequence 类型任务的评估,如果用这些 metrics,可能出现 boundary error 之类的问题。因为 NER 的评估是按每个 entity 而不是每个 token 来计算的,我们需要看 entity 的 boundary。
以下面一句话为例
|
|
正确的 NE 应该是 First Bank of Chicago,类别是 ORG,然而系统识别了 Bank of Chicago,类别 ORG,也就是说,右边界(right boundary)是对的,但是左边界(left boundary)是错误的,这其实是一个常见的错误。
|
|
而计算 precision,recall 的时候,我们会发现,对 ORG -(1,4)而言,系统产生了一个 false negative,对 ORG -(2,4)而言,系统产生了一个 false positive!所以系统有了 2 个错误。F1 measure 对 precision,recall 进行加权平均,结果会更好一些,所以经常用来作为 NER 任务的评估手段。另外,专家提出了别的建议,比如说给出 partial credit,如 MUC scorer metric,然而,对哪种 case 给多少的 credit,也需要精心设计。
2.4 其他-实体链接
实体识别完成之后还需要进行归一化,比如万达集团、大连万达集团、万达集团有限公司这些实体其实是可以融合的。
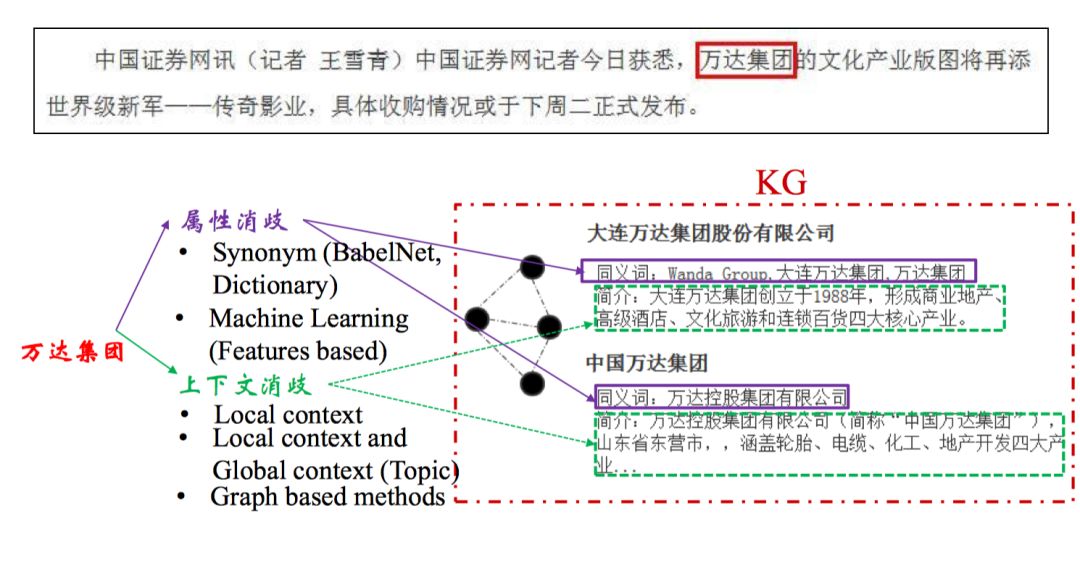
主要步骤如下:
-
实体识别
命名实体识别,词典匹配 -
候选实体生成
表层名字扩展,搜索引擎,查询实体引用表 -
候选实体消歧
图方法,概率生成模型,主题模型,深度学习
补充一些开源系统:
-
http://acube.di.unipi.it/tagme
-
https://github.com/parthatalukdar/junto
-
http://orion.tw.rpi.edu/~zhengj3/wod/wikify.php
-
https://github.com/yahoo/FEL
-
https://github.com/yago-naga/aida
-
http://www.nzdl.org/wikification/about.html
-
http://aksw.org/Projects/AGDISTIS.html
-
https://github.com/dalab/pboh-entity-linking













