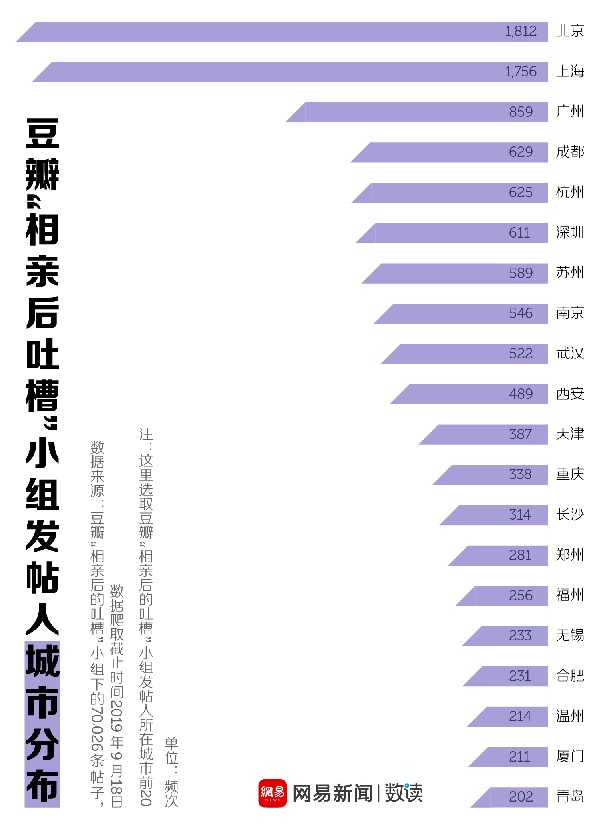
Cerebras Wafer Scale Engineӵ��1.2���ڸ�����ܣ����ǻ����Ŀ��ص��ӿ��أ��ǹ�оƬ�Ĺ���ģ�顣1971��Ӣ�ض���4004������ӵ��2,300������ܣ������Advanced Micro Devices������ӵ��320�ڸ�����ܡ�
�����оƬʵ��������12Ӣ��辧Ƭ�ϴ�����оƬ���ϣ�����оƬ������������������Cerebras SystemsоƬ���ڵ�����Բ�ϻ����ĵ�оƬ����Щ�������ʹ��ȫ�����ָ������У�������ڸ������ȫ��һ������
ͨ�����ַ�ʽ��Cerebras Wafer Scale Engine����ʷ�������Ĵ���������ר��������ڴ����˹�����Ӧ�ó��ù�˾�������ڼ��������������尢���е�˹̹����ѧ���е�Hot Chips����������������ơ�
��Ϥ��Cerebras Systems ��˾λ�ڼ�����˼��ͼ˹����˾�����ϴ�ʼ�˼�CEO Andrew Feldman��ǰ������������оƬ��˾SeaMicro��������2012�걻AMD��3��3400����Ԫ���£�����ǰ�����﹤������λͬ��Michael James�� Sean Lie,��Jean-Philippe Fricker��Gary Lauterbach��Feldman��ͬ������Cerebras��
��ʵ�ϣ������Ѿ�������һ������оƬ����eUFS��ӵ��2���ڸ�����ܡ���CerebrasоƬרΪ�ӹ�����ƣ�ӵ��400,000�����ģ�42,225ƽ�����ס���������Nvidiaͼ�δ�����Ԫ�� 56.7�����õ�Ԫ�ijߴ�Ϊ815ƽ������211�ڸ�����ܡ�
��оƬ����Andrew Feldman�쵼���Ŷӣ������������ͷ�������˾SeaMicro������3.34����Ԫ�ļ۸���۸�Advanced Micro Devices��Cerebras Systems�����ϴ�ʼ�˼���ϯӲ���ܹ�ʦSean Lie��������оƬ�ϵ�Cerebras Wafer Scale Engine��������������Los Altos��˾ӵ��194��Ա����
оƬ�ߴ���AI�зdz���Ҫ����Ϊ��оƬ���Ը���ش�����Ϣ���ڸ��̵�ʱ���ڲ����𰸡����ٶ���ʱ�����ѵʱ�䡱��ʹ�о���Ա�ܹ����Ը����뷨��ʹ�ø������ݲ���������⡣�ȸ裬Facebook��OpenAI����Ѷ���ٶȺ�������������Ϊ�������˹����ܵĻ�����������ѵģ����Ҫ�ܳ�ʱ�䡣��ˣ�������ѵʱ��������������ҵ��������Ҫƿ����
��Ȼ��оƬ������ͨ������������˴��оƬ���ڵ�����Ƭ�ϣ������������ͨ���ᷢ��һЩ���ʡ����һ�����ʻᵼ��оƬ�������ϣ���ô��Բ�ϵ�һЩ���ʾͻ����һЩоƬ��ʵ�����������ռʵ�ʹ���оƬ�İٷֱȡ������Բ��ֻ��һ��оƬ���������ʵļ�����100�������ʻ�ʹоƬʧЧ����Cerebras��Ƶ�оƬ������ģ����һ�����ʲ����������оƬ��
���Է���WSE��רΪ�˹�������ƶ���ƣ������˻������£�ͨ���������оƬ�ߴ����ʮ��ļ�����ս - ���罻��������ӣ����ʣ��������ͣ��ƶ������Ƚ������ķ�չ���Ͱ�װ������һ�������й�ͬ����Cerebras Systems��������ϯִ�йٵķѶ�����˵����ÿ���ܹ����߶���Ϊ���Ż�AI���������ܡ�����ǣ�Cerebras WSE���ݹ������ṩ�����ٻ���ǧ�������н�����������ܣ�ֻ���С�Ĺ��ĺͿռ䡣��
ͨ������������ѵ��������Ԫ����ʵ����Щ�����������������Ƕ༶���㷴����·���Ͽ��������ѭ�����ƶ���ѭ��ѧϰ���ٶ�Խ�죬��ѵ������ͨ��ѭ��������ƶ�����ķ����Ǽ���ѭ���ڵļ����ͨ�š�
Linley Group��ϯ����ʦLinley Gwennap��һ��������˵����Cerebrasƾ���侧Բ������ʵ���˾�ķ�Ծ���ڵ�Ƭ����ʵ���˱��κ�������ĸ���Ĵ������ܡ��� ��Ϊ��ʵ����һ׳�٣��ù�˾�Ѿ������һϵ�ж��Թ�����ս����Щ��ս��ʮ�����谭�˸���ҵ������ʵʩ����оƬ��оƬͨ�ţ��������ȱ�ݣ���װ��˴��оƬ���Լ��ṩ�߳ɱ� - �ܶȵ�Դ����ȴ��ͨ��������ѧ�ƵĶ�������ʦ�ۼ���һ��Cerebras�ڶ̶̼����ڴ������¼�����������һ����Ʒ������һ������ӡ����̵ijɾ͡���
оƬ���������ͼ�δ�����Ԫ��56.7����Cerebras WSE�ṩ�����ں˽��м��㣬�����ڴ濿���ںˣ�����ں˿��Ը�Ч���С�������Щ�������ں˺��ڴ�λ�ڵ���оƬ�ϣ��������ͨ�Ŷ�������оƬ�ϣ�����ζ�����ĵ��ӳ�ͨ�Ŵ����Ǿ�ģ�����ں�����������Ч�ʽ���Э����
Cerebras WSE�е�46,225ƽ�����Ĺ����400,000��AI�Ż������棬�����ļ����ں˺�18ǧ���ֽڵı��أ��ֲ�ʽ��������SRAM�ڴ棬��Ϊ�ڴ��νṹ��Ψһ�����ڴ����Ϊÿ��9 PB����Щ�ں�ͨ��ϸ���ȣ�ȫӲ����Ƭ����״����ͨ������������һ�𣬿��ṩÿ��100 petabits���ܴ����������ںˣ����౾���ڴ�͵��ӳٸߴ����ṹ��ͬ�����˼���AI��������Ѽܹ���
����ȻAI��һ��������ʹ�ã���û���������ݼ���AI��������ͬ�ġ��µ��˹����ܹ������ز���ӿ�֣����ݼ�������������Tirias Research��ϯ����ʦ�洴ʼ��Jim McGregor��һ�������б�ʾ���������˹����ܵķ�չ�����ƽ̨�������Ҳ�ڲ��Ϸ�չ��Cerebras WSE�ǰ뵼���ƽ̨����������˾�̾�Ĺ��̳ɾͣ����ڵ���Բ������������ṩ����������ļ��㣬�����ܴ洢���ʹ�����
��Щ��˾��ʾ�����û�ж�����ȫ�����İ뵼����������Լ������̨���缰�Ƚ����ռ������쵼�����к�������ôCerebras WSE�Ĵ���¼�ɾ��Dz�����ʵ�ֵġ�WSE��̨���������Ƚ���16�����ռ������졣
̨������Ӫ�����ܲ�JK Wang��ʾ�������Ƕ�Cerebras Systems��Cerebras Wafer Scale Engine����������dz����⣬���Ǿ�Բ����������ҵ��̱����� ��̨�����Խ����Ͷ��������ϸ��עʹ�����ܹ������ϸ��ȱ���ܶ�Ҫ����֧��Cerebras�������ǰ��δ�е�оƬ�ߴ硣��
��������
WSE����400,000��AI�Ż��ļ�����ġ�����Ϊϡ�����Դ������ĵ�SLAC������������ɱ�̣������֧����������������ϡ�����Դ����������Ż���SLAC�Ŀɱ����ȷ���ں˿����ڲ��ϱ仯�Ļ���ѧϰ���������������������㷨��
����ϡ�����Դ��������������������Ԫ�������Ż���������ǿ�ʵ��ҵ����������� - ͨ����ͼ�δ�����Ԫ���������ı������⣬WSE���İ���Cerebras������ϡ�����ռ��������Լ���ϡ�蹤�����أ�������Ĺ������أ��ļ������ܣ������ѧϰ��
�������ѧϰ�����к��ձ顣ͨ����Ҫ��˵������;����еĴ����Ԫ�ض����㡣Ȼ�������������˷ѹ裬���ʺ�ʱ�䣬��Ϊû���µ���Ϣ��
��Ϊͼ�δ�����Ԫ������������Ԫ���ܼ���ִ������ - ���Ϊ��������������� - ���Ǽ�ʹ����ʱҲ�����ÿ��Ԫ�ء���50-98��������Ϊ��ʱ�������ѧϰ�е����һ����������˷������˷��ˡ�����һ�£�����Ĵֲ���û�����������յ�ʱ����ͼ����ǰ��������Cerebrasϡ�����Դ����˲�������㣬���������ݶ��ᱻ�˳������ҿ�����Ӳ�����������Ӷ���������λ����������õĹ�����
����
�ڴ���ÿ���������ϵ�ṹ�Ĺؼ���������ӽ�������ڴ�ת��Ϊ����ļ��㣬���͵��ӳٺ��õ������ƶ���Ч�����������ѧϰ��Ҫ�������㣬����Ƶ���������ݡ�����Ҫ������ĺʹ洢��֮��Ľ��ܽӽ�������ͼ�δ�����Ԫ�в�����ˣ����о�������洢���ǻ�����Զ��ģ�Ƭ�⣩��
Cerebras Wafer Scale Engine���������ںˣ����б�����Ϊֹ�κ�оƬ����ı����ڴ棬������һ��ʱ�������ڿ���ͨ������ķ���18 GB��Ƭ���ڴ档WSE�ϵĺ��ı����ڴ漯�Ͽ��ṩÿ��9 PB���ڴ���� - �����ȵ�ͼ�δ�����Ԫ��3,000����Ƭ���ڴ��10,000�����ڴ������
ͨѶ�ṹ
Swarmͨ�Žṹ��WSE��ʹ�õĴ�������ͨ�Žṹ�����Դ�ͳͨ�ż����Ĺ��ĵ�һС����ʵ��ͻ���Դ����͵��ӳ١�Swarm�ṩ���ӳ٣��ߴ�����2D��������WSE�ϵ�����400,000�����ģ�ÿ�����Ϊ100 petabits��Swarm֧�ֵ��ֻ��Ϣ������ͨ�������ں����������������κ�����������
·�ɣ��ɿ�����Ϣ���ݺ�ͬ����Ӳ���д�������Ϣ���Զ�����ÿ��������Ϣ��Ӧ�ó��������� SwarmΪÿ���������ṩ���ص��Ż�ͨ��·�������������������е��ض��û������������Ľṹ������ͨ��400,000�����ĵ����ͨ��·�������Ӵ�������
������Ϣ����һ�����������ӳٵ�Ӳ����·��Cerebras WSE���ܴ���Ϊÿ��100 petabits������Ҫ����TCP / IP��MPI֮���ͨ����������˱��������ǵ�������ʧ���üܹ��е�ͨ�������ɱ�Զ����ÿ����1���������ͼ�δ�����Ԫ�ͽ�������������ͨ����ϴ��������ͼ��͵��ӳ٣�Swarmͨ�ŽṹʹCerebras WSE�ܹ����κε�ǰ���õĽ�����������ѧϰ��