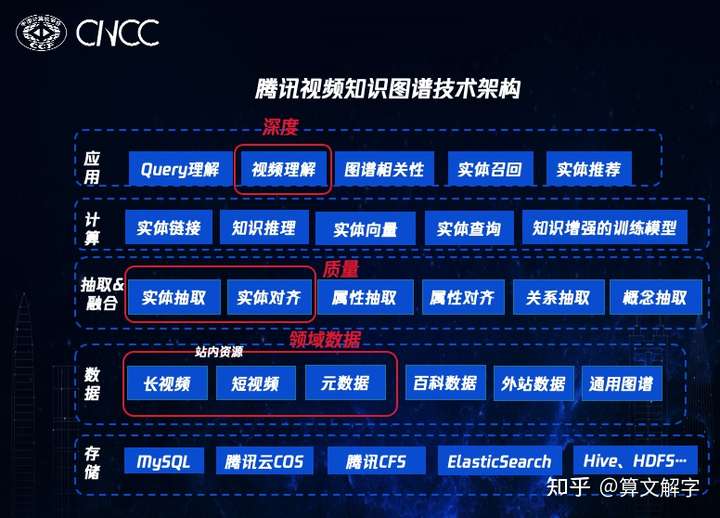
与通用知识图谱相比,领域图谱可以深度建模领域知识,更紧密地支撑复杂业务,因此成为近年来AI落地的热点之一。基于笔者在2021年中国计算机大会(CNCC)的报告,本文上半部分分享对领域图谱建设之道的一些思考:应用驱动的迭代,低风险、低成本的图谱建设。下半部分将结合实体对齐、实体链接和图谱的推荐等应用的例子,讨论在落地应用中如何根据实际场景的需求选择和综合运用合适的前沿方法以取得更好的业务收益。
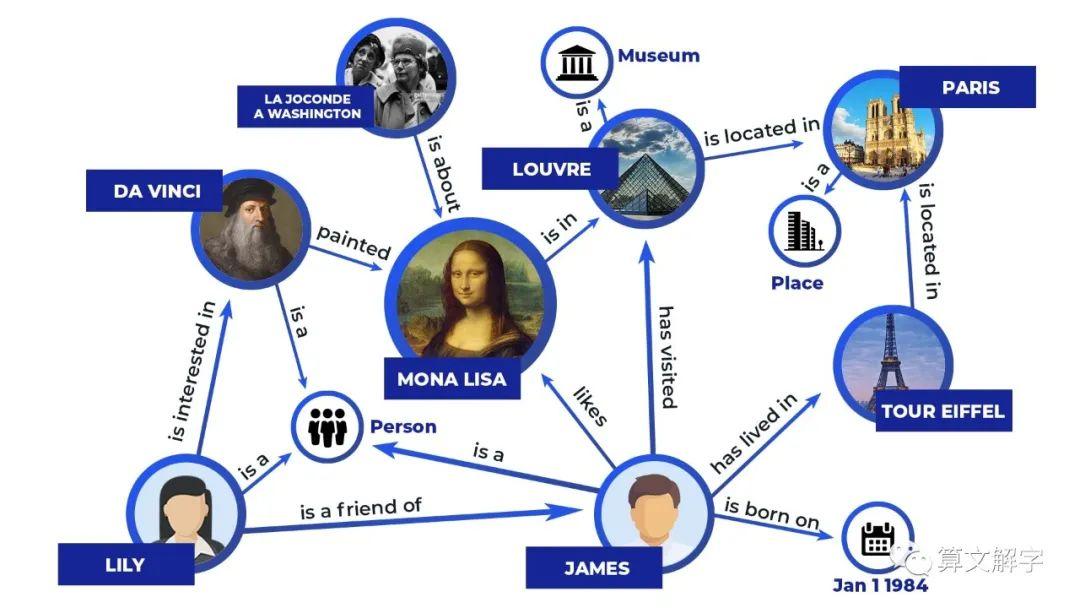
知识图谱(knowledge graph)是一个多学科交叉的领域,融合了机器学习、符号AI、自然语言处理、计算机视觉、数据库、WEB等诸多领域的技术。关于知识图谱本身及其发展历程的文章和书籍很多,本文就不多赘述。 从项目的角度看,知识图谱的建设和应用是系统化的工程,需要算法和架构密切配合,再加上相关技术本身的快速演化,使得知识图谱的项目具往往具有相当大的不确定性,这就给图谱的落地带来了挑战。
与Google Knowlege Graph,腾讯PCG中台图谱这类大规模通用图谱不同,本文讨论特定行业知识与应用的较小规模领域图谱。领域图谱由于可以深度建模领域知识,更紧密地支撑复杂业务,近年来成为AI落地的热点之一。领域图谱落地,产业界和学界已经有不少探索,但远远还没到已经形成统一最佳实践的阶段,因此,我们结合腾讯视频的实践,分享一些对于领域图谱落“道”与“术”的思考,抛砖引玉,希望给同行带来一些启发。
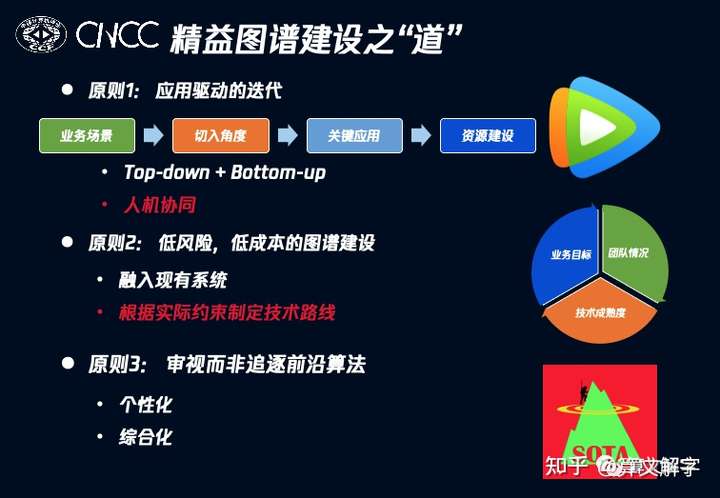
道:精益图谱 领域图谱的建设和应用思路可以概括为“精益图谱”。图谱项目某种意义上和创业项目很相似,由于其复杂和不确定性,很难直线型地规划、执行并一次命中目标,在实践中往往需要不断迭代和优化来取得好的效果。而迭代,需要一个起点,起始思路上因以探索效率和最终成功为目标。我们的体会是图谱项目应当遵循两个原则:
原则1:应用驱动的迭代
原则2:低风险、低成本的建设
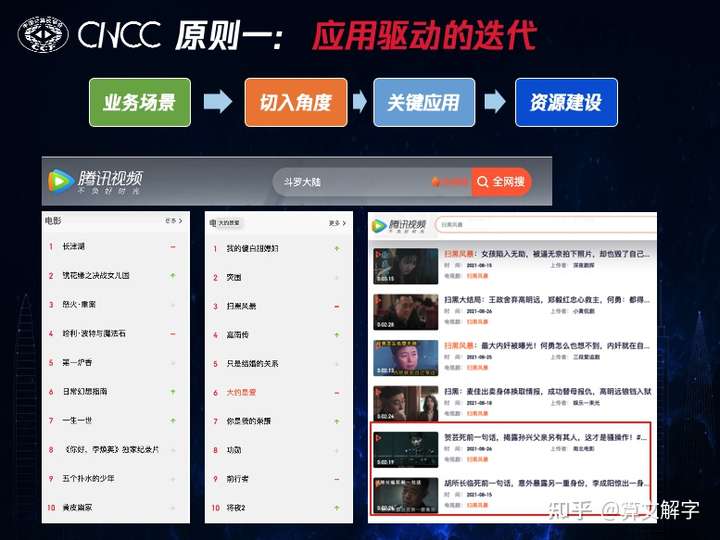
一、应用驱动的迭代 领域图谱的建设,首先要理解业务场景 ,找出其中的痛点和挑战,然后去找到一个合适的切入角度 ,并从这个角度出发选取关键应用 ,最后基于应用决定资源建设 的范围和重点。下面我们以腾讯视频搜索场景为例,说明这个过程。1. 理解业务场景
腾讯视频大家可能都用过,多数年轻用户也习惯用搜索功能去找感兴趣的电影、电视、综艺(影视综)节目。这是一个典型的垂类搜索场景,大家可以通过下图中的热榜看出最热大多都是影视综这类IP长视的query;搜索结果除了精品长视频也会展现IP相关的周边短视频。
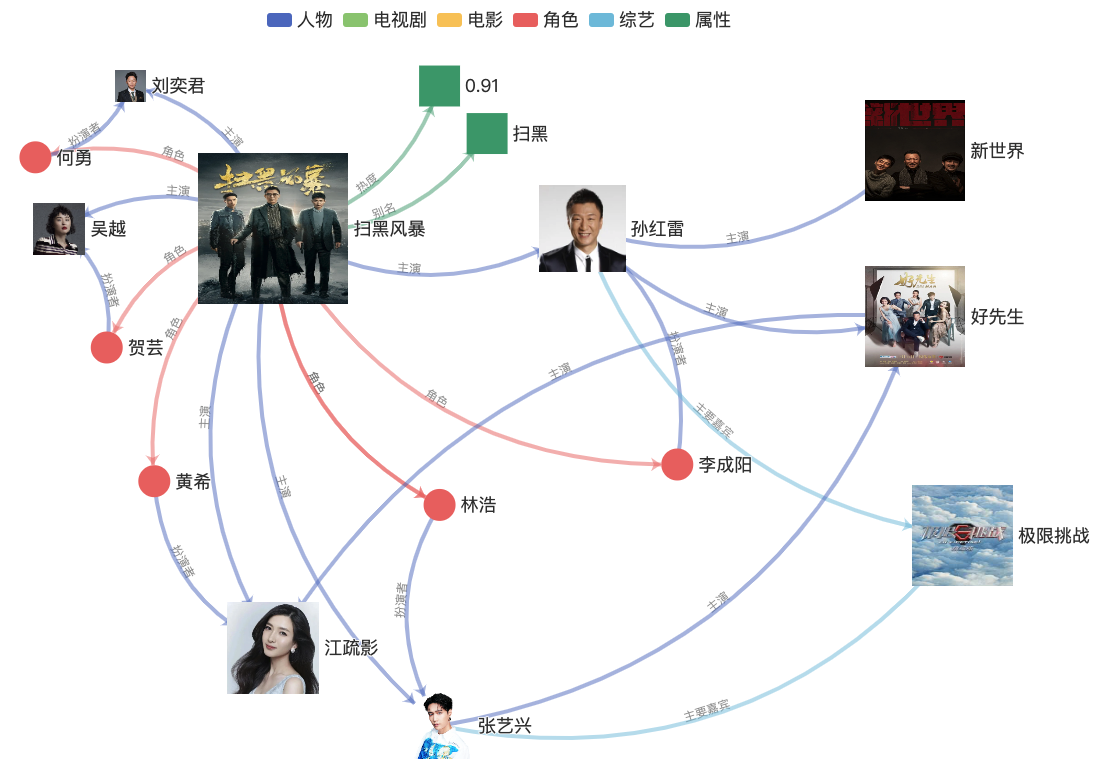
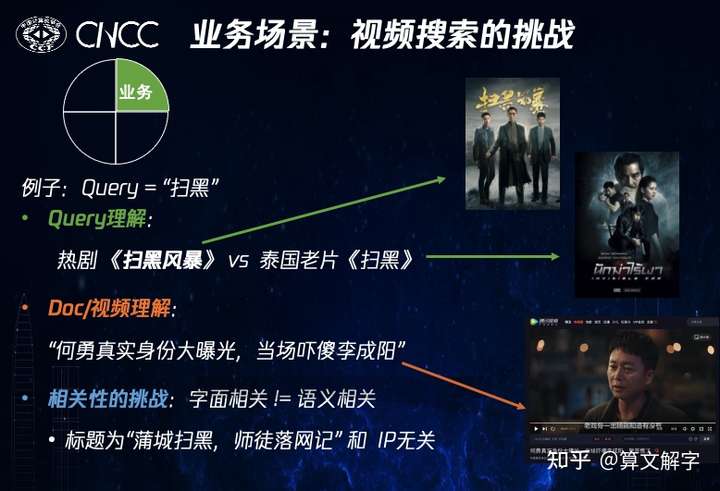
这个场景的挑战在哪里呢?我们以一个简单搜索词(query)“扫黑”为例子来说明。该query对query理解 的挑战在于,用户是想看热剧《扫黑风暴》,还是泰国老电影《扫黑》?在doc(视频)理解 的角度看也有挑战。比如有一些短视频标题是剧情描述,如“何勇身份大曝光,当场吓傻李成阳,贺芸慌了”。追剧的朋友一眼就能看出来,这个标题的人名都是剧中角色,这个短视频跟剧集肯定相关。但如果只从纯文本角度看,这个标题跟完全没有命中“扫黑”这两个字。最后,从相关性建模 的角度看,字面相关也不等于语义或者意图相关,比如标题为“ 蒲城扫黑,师徒落网记” 的短视频,跟扫黑IP是无关的。
2. 寻找切入角度
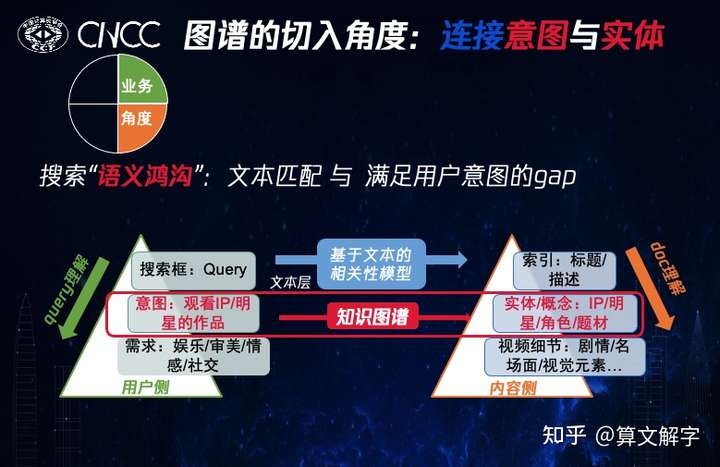
以上挑战是从搜索的不同环节来说的。如果用一个要点来总结这些挑战,笔者认为可以归结为“语义鸿沟 ”,也就是文本匹配与满足用户意图之间的差异 。从用户侧来说,他们有娱乐、审美、情感等需求 ,当他们来到腾讯视频之后意图 会相对集中到观看IP、明星作品等,但是在脑机接口实现之前,这些意图只能通过向搜索框 键入query的方式来实现,这显然跟意图甚至是需求就有了信息的损失。
在内容侧也是类似的,整个搜索可能是建立在对标题、描述等内容的索引 之上,而这些索引跟视频中涉及的实体和概念 ,以及更底层的视频细节 是有相当大差距的。针对这个痛点,知识图谱的一个切入角度是,连接用户侧的意图与内容侧的实体概念 。具体而言,我们可以通过图谱,让query理解做的更深,让doc理解做的更好,让相关性建模更鲁棒。
3. 选取关键应用
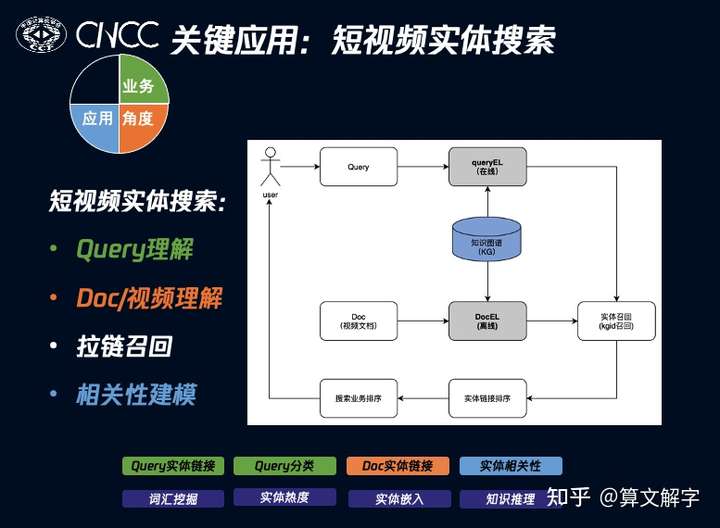
光有角度还不够,我们需要选择一个可以快速启动的应用,以评估资源建设的重点。下面是一个短视频实体搜索的例子,其在线上A/B实验中取得了显著收益,并在腾讯视频搜索中上线。基于视频领域图谱,我们可以这样建立用户侧的意图到内容侧的实体概念的直接连接:对query在线做实体链接(entity linking, EL),用链接到的IP/明星实体来表示query的意图,对doc侧可以离线做实体链接。
然后我们就可以基于query侧和doc侧识别出实体的ID的匹配情况实现搜索召回。这种直接应用最大的好处是简单,而且可以复用已有倒排索引的系统。在这个过程中,我们还可以将query/doc侧EL的结果作为特征应用到相关性模型中,以提升效果。
4. 开展资源建设
在明确一个或多个关键应用之后,我们就可以锚定应用去定义核心领域和schema,优先这个范围内的图谱资源。可以看到,上面讨论的应用涉及的领域主要还是影视综这些长视频IP,及其周边的演员和角色。实体完整的属性可以非常多,但是对应用非常重要的属性,可以优先建设,比如对IP类的实体,别名、播放源和热度等。
刻舟求剑?
仅仅依靠上述自上而下(top-down) 的方式建设图谱往往会有这样的风险:应用中的用户需求发生了变化,但资源建设侧却浑然不知,依然按之前的规划建设。因此,捕捉需求的变化至关重要,理想的状态是让图谱建设的方向能动态调整以匹配应用的需求。为此,可以结合自底向上(bottom-up) 的建设方法。
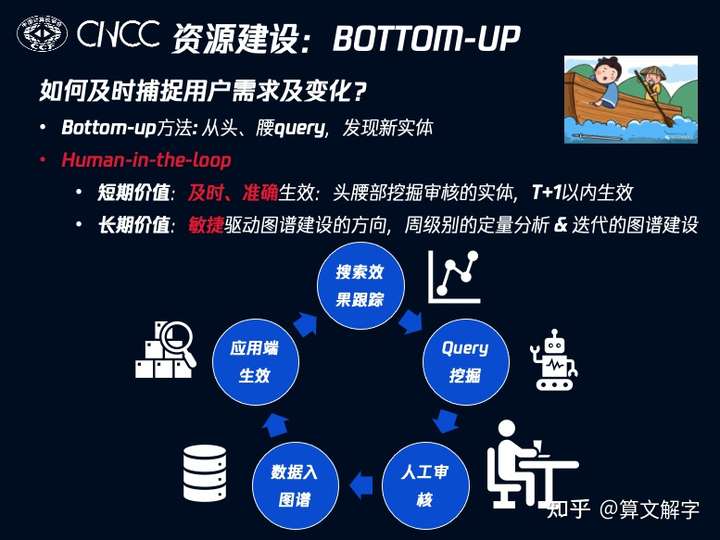
具体到腾讯视频的场景中,我们对头部和腰部的query采取了监控,挖掘出新兴实体及类型,整个流程如下图所示。我们会对搜索效果做跟踪,针对未识别出实体的query和用户消费较差的query做挖掘,依靠算法策略挑出需要修正的候选,然后这些候选经过人工审核之后,会被推送到图谱链路中,再利用原有链路从不同数据源补齐属性和关系信息,最终在应用端生效,如此循环往复。
这里需要强调的是人机协同(human-in-the-loop) 的价值。 尽管图谱建设的理想态是完全的自动化,但是以目前的技术水准,在某些环节依然需要引入人工。人工介入的缺点是成本高,因此无法做到规模化,但我们可以把好钢用在刀刃上。在视频搜索的例子里,头腰部的query就是钢刃。
在这个例子里,人工审核的短期价值是在T+1时效内就可以让头腰部挖掘的实体生效,及时提高搜索效果。但更重要的是其长期价值:通过自底向上的循环可以周级别的定量分析搜索中实体类型的构成及变化,进而敏捷的迭代图谱建设的方向。比如,我们某个时间段会发现用户对游戏领域的搜索变多,而这又不在我们的视频图谱的覆盖范围内,那就可以采用建设或者引入游戏领域的数据的方式来做出调整。
二、技术选型:低风险、低成本的方案
应用驱动的迭代的知识图谱建设方式提供了一种思路和流程,让我们的领域图谱项目,更贴近业务的需求,更稳健地拿到业务收益。而当我们开始启动项目时,最同样重要的决策则是技术选型。我们认为应当遵循一种低风险、低成本的建设原则。笔者不赞成追求最“标准”的技术栈或者最新的技术,而是应该考察技术的成熟度 ,并综合的考量业务目标 和团队的情况 来搭建技术栈。
在一开始介绍腾讯视频搜索场景的时候,有些读者可能就有这样的疑问:这种典型的垂搜直接上语义检索(semantic search)不就可以了吗?这个话题本身也可以展开探讨,但限于篇幅这里只想强调的一点,既技术人应该对业务复杂性有敬畏之心 。尽管知识图谱是个系统化技术,但它也是有边界和局限,通常需要与其他技术结合才能完满地解决问题。更何况大型应用中会有复杂的业务逻辑、商业逻辑等,不是一个纯粹的方案就能支撑。
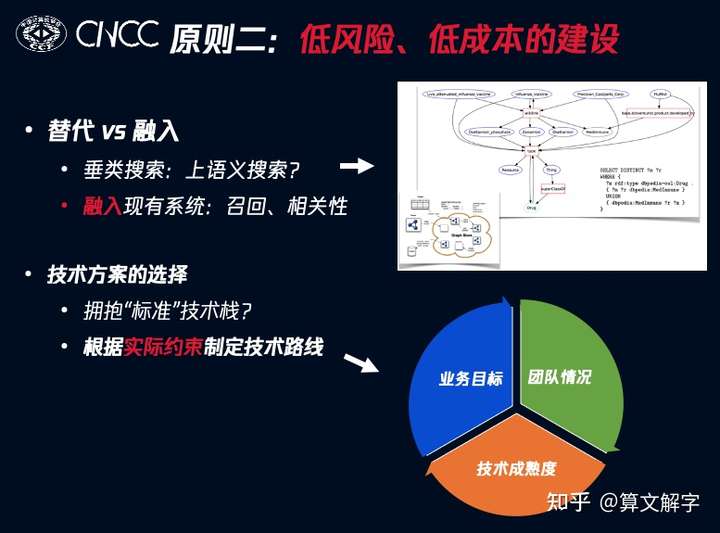
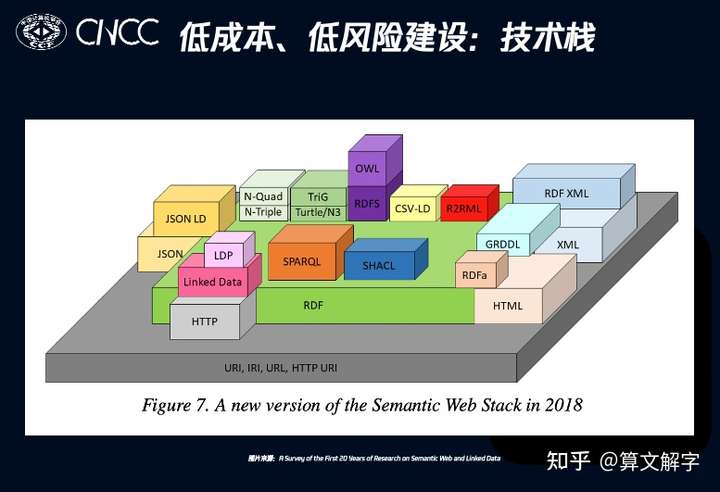
所以在之前短视频召回的例子中,我们采用的方式是融入现有系统链路中,也就讲实体作为策略融入现有召回通路,并把图谱特征用在相关性模型里。具体到技术方案的选择上,一个默认的做法是拥抱“标准”的技术栈,比如下图所示。
是否要follow标准技术栈是一个仁者见仁智者见智的问题。但应当注意到,标准表面上是制定出来的,但最终其实是演化的结果。比如上图中JSON和JSON-LD在更早的2008年的标准里是不存在的,他们最终纳入标准是因为基于json的数据传输比原先标准里的xml对工程师更为友好。所以一项技术,如果团队非常熟悉,这本身就是一个加分项。而应用场景的特点是否与标准技术栈设想的场景一致,也是需要仔细考量的因素。结合这些因素,下面介绍我们的实践。
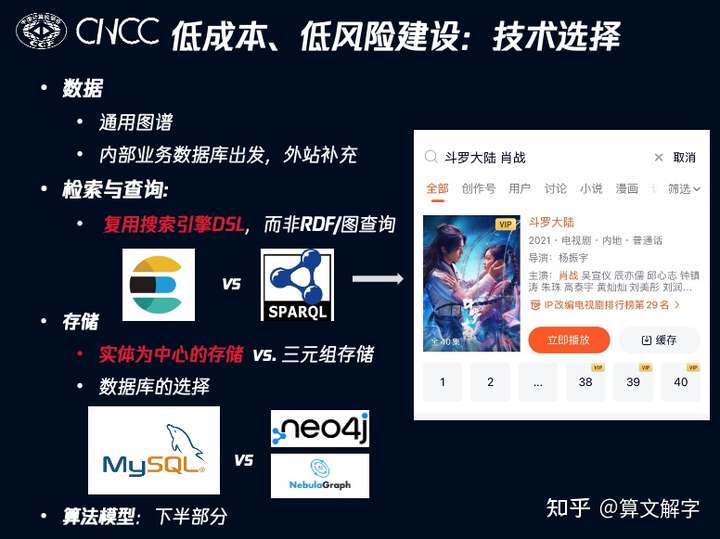
数据源 :领域图谱建设一般而言会采用通用图谱或者百科数据做启动,但我们场景中有优质的业务数据,因此我们采用的是内部数据为主,站外数据补充的方式。
检索查询 :标准方案是遵循RDF的知识表示,然后用SPARQL来查询图谱。但考虑到我们本身就是一个搜索引擎,有类似elasticsearch的引擎和DSL语言,我们采用了传统信息检索的方式来实现实体的查询。比如用户搜索“斗罗大陆肖战”,我们在识别出有名为“斗罗大陆”的实体至少有电视剧版和动漫版的斗罗大陆,而“肖战”指向一个明星,这时我们的查询实际上是(电视剧版斗罗大陆 OR 动漫版斗罗大陆)AND (肖战参与的影视作品),最终返回的是电视剧版的斗罗大陆(肖战是主演)。
存储 :标准方案是采用三元组的形式存储,最好存在图数据库中。但是在我们的业务场景中,更多是实体的查询及其丰富属性的展现,因只给出一个三元组反而不方便,需要组合若干三元组得到相关信息。因此,尽管我们采用多种存储并用的方式,并在密切关注Nebula等的图数据库的最新进展,但最最重要的存储反而是以实体为中心的,利用关系数据库MySQL的来进行的,因为它能很好满足需求,而且技术成熟、维护和学习成本低。
小结
导语:在本文上半篇算文解字:领域知识图谱的“道”与“术”:来自腾讯视频的思考和实践(上)
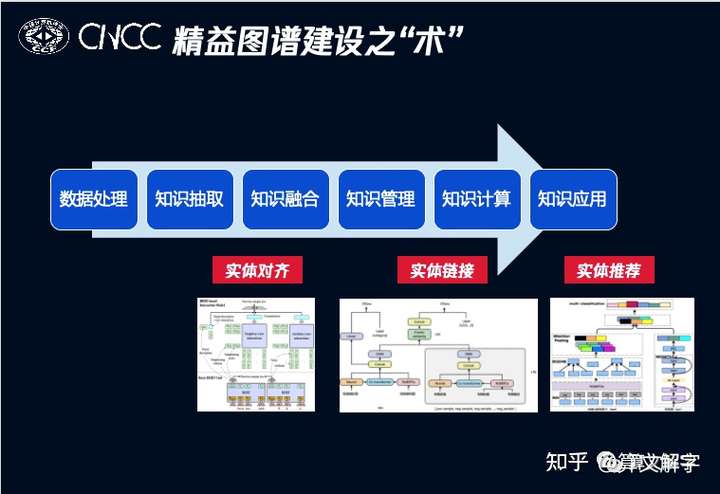
大家都了解,知识图谱从建设到应用是一个比较长的链路,如下图所示。其中技术点非常多,我们就以实体对齐、实体链接和实体推荐三个例子来讨论图谱之“术”,主要是算法选型的一些思路。
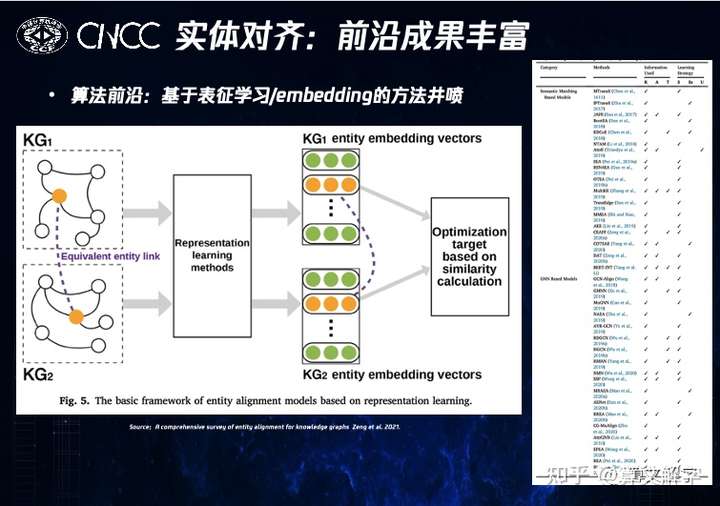
实体对齐 实体对齐领域的算法前沿成果很丰富,特别是基于表征学习(representation learning)的方法。这些算法的大框架是类似的:对不同图谱中的每个实体,学习一个embedding表征。离线训练的目标是,让已知的不同图谱中的同一(对应)实体在向量空间的距离尽可能地接近。在线推断时,会根据实体表征间的距离去预测应该被对齐的实体对。下图右侧是一个近期综述文章[1]所列举的一些算法。字体太小,看不清楚?没关系,因为大多数算法对我们的场景并不适用。
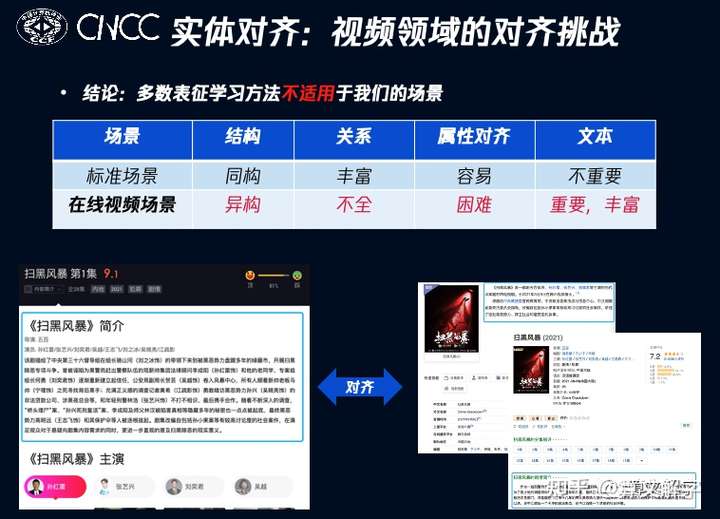
为什么?因为多数论文研究的是结构信息完善的标准场景。就是说,对齐是在完整图谱上进行,同时不同图谱从结构上讲也比较相像,更重要的是实体间的关系较为丰富,也比较容易通过schema的映射将属性对齐。
因此,主流方法会从不同角度探索如何更好地建模实体关系和属性等结构信息。但在线视频的场景与之不同,对齐不是发生在图谱建设完毕之后,而是在建设中动态进行的。更重要的是,对齐甚至不是发生在图谱之间的,而往往是在图谱和网页资料之间的。也就是说,面临的是一种多源异构的数据融合 。
这里的核心挑战是,在很多数据源中关系非常稀疏,属性差异也比较大,因此如果仅依赖结构信息,对齐效果较差。但好消息是,无论是视频图谱,还是网页数据,都有大量的文本描述,因此可以充分利用文本信息来弥补结构信息的不足。
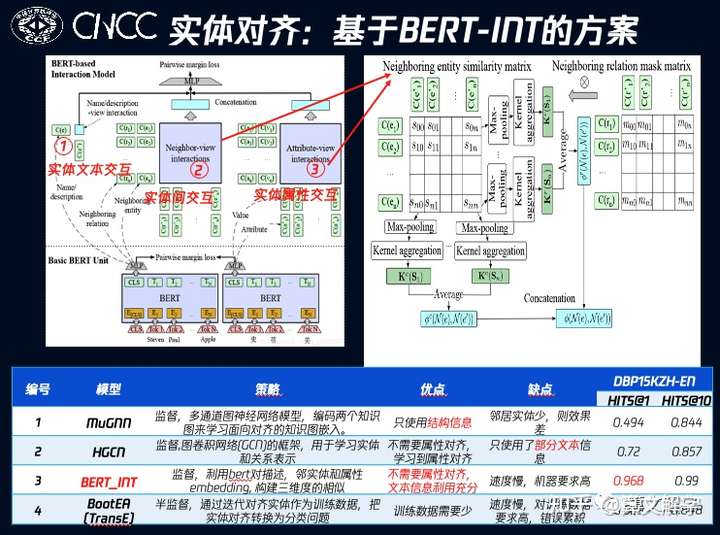
在众多算法中,我们发现有少数方法如BERT-INT [2]对实体的文本交互信息做了比较充分的建模:首先,模型利用实体文本间的交互做为重要特征;其次,模型并不要求实体间的属性预先对齐,而是通过实体间属性和属性值在文本语义上的交互,实现属性的自动软对齐;最后,传统的实体关系信息也会通过实体与邻居的表征交互来融入。这些交互充分利用了文本信息和预训练模型BERT的威力,因此对我们的场景更为适用。
实际上,在一些公开数据集,如DBP15KZH-EN上,BERT-INT也有不俗的表现。在BERT-INT的基础上,我们还做了特征选择、引入稳定属性、知识注入以及模型结构上的一些改进,带来了效果上进一步的提升。
不过,这套端到端的方案并不能端到端地解决实体对齐的问题。由于实体对齐的效果会直接反映到线上的搜索结果,我们的场景需要极高的准确率(99%+),较好的可解释性以及可干预的能力。
所以,我们最终的方案是多策略融合 :用最小属性集合的启发式匹配高准确度地覆盖一部分数据。对于其他情况,如果数据源之间本体已对齐(可对齐属性),会走xgboost分类,并利用封面图相似度来得到对齐结果;对于属性无法对齐的候选对子,会用基于BERT-INT的方案做出预测。在对齐结果上线之前,仍然会有部分疑难case发往人工复核;同时也提供了对线上结果及时干预的接口。
这个案例可以用来说明针对前沿算法的态度:
个性化 :不求最新、最好,但求最合适。
综合化 :没有银弹包打天下,复杂问题可以分而治之,不同环节使用不用方法。
实体链接
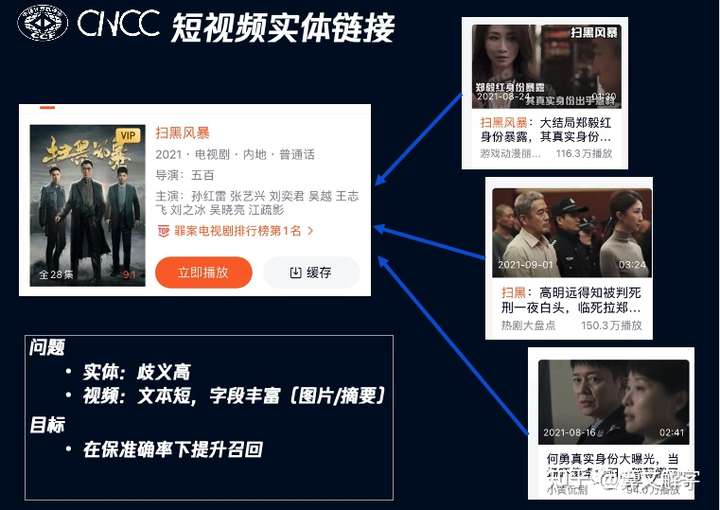
要解决的问题是短视频实体链接 ,也就是将短视频链接到相关的影视综IP实体上。比如,下图中的短视频都是跟《扫黑风暴》相关的,需要链接到该电视剧类型的实体上。
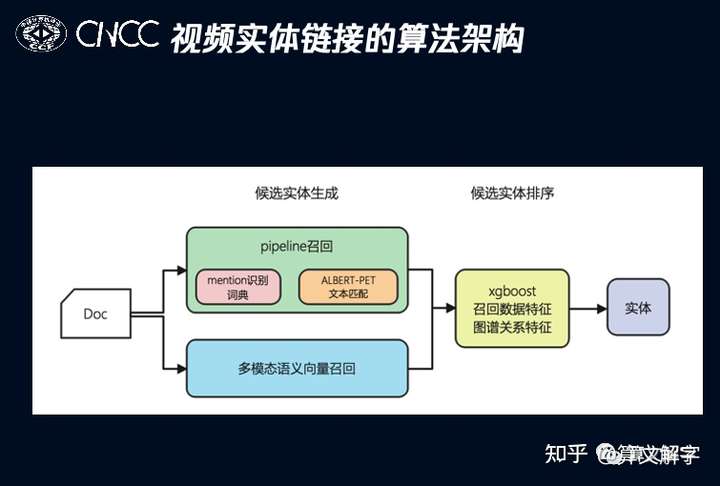
实体链接可以从短视频的文本信息,特别是标题描述入手。例子中的短视频标题各有不同,有的短视频标题直接包含了“扫黑风暴”,有的则包含了IP名的简称“扫黑”,而有的是人物和剧情描述并没有出现IP名称本身。除了文本信息之外,还可以利用短视频的封面图这种图像模态的信息。我们的算法框架如下图:
整体上实体链接分为候选实体生成和候选实体的(重)排序。在候选实体生成阶段,我们有两套通路,一个是基于多模态语义向量的召回,另一个是传统的基于文本的pipeline召回。
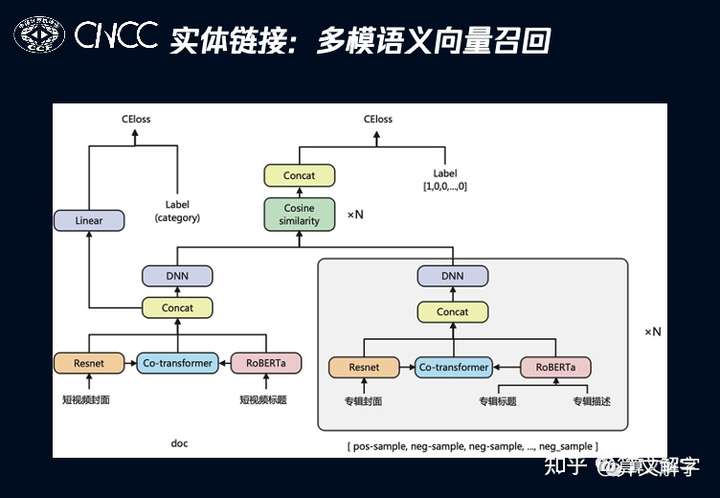
如下图所示,多模语义向量召回 采用的是经典的类似DSSM的双塔语义召回框架。每个塔都包含了两个模态的信息:用RoBERT来编码的文本模态信息(短视频标题)和用ResNet来编码的图像模态信息(封面图)。文本和图像模态的编码器,都是已经预训练好的。两个模态之间的交互,则借鉴了ViLBERT[3]的思想,采用了co-transformer模块来进行。
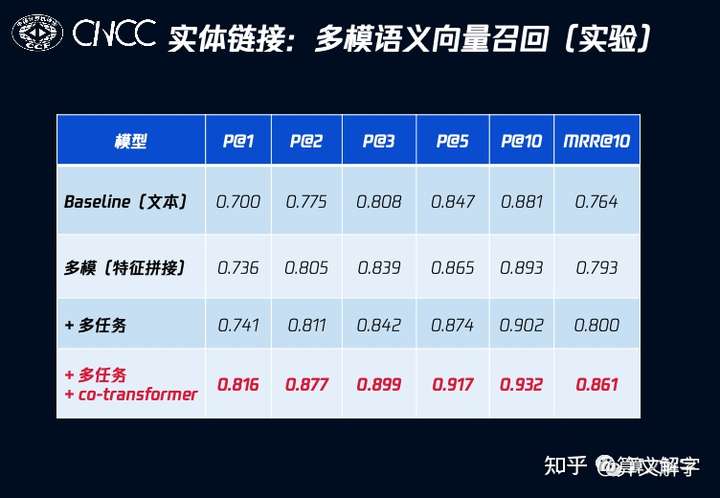
这个模型上,我们做了几点优化:一是通过余弦相似序列来得到list wise损失;二是引入doc类别分类的loss来进行多任务学习。在业务数据集上的效果如下,可以看到co-transformer带来的交互对效果提升很大,而引入多任务学习也有帮助。
在基于文本的pipeline通路上,我们着重想优化的是实体消歧部分的语义匹配模型的在线推断速度,因此考虑了模型压缩的方案。前期尝试中,我们发现采用预训练过的单层AlBERT代替原本的BERT模型,可以大大提高推断速度,但同时带来了精度损失较大的问题。
为此,我们引入了Pattern Enhanced Training (PET)[4]的的训练方法。它背后的想法非常简单:既然底层使用了预训练模型,那就将目标任务转化为对预训练模型更为自然和友好的掩码语言模型任务(Masked Language Model, MLM)任务,以期带来更好的效果和更快的收敛速度(尽管参考论文中本身的动机是做few-shot learning)。具体的做法如下图所示:
白色字体是对实体的描述(正例中的实体是电视剧《亲爱的,热爱的》,负例中的实体是电影《蔻贝》);黄色的部分是待链接到实体的短视频标题。训练的目标则是将“有”和“无”这两个字mask起来,让模型去预测。
这里实体描述是通过一些定义好的模板(pattern)将实体的关键属性信息串成流畅的句子而得到的。实验的结果上,用AlBERT+PET训练的方式,精度损失非常小,而且两个epoch就可以收敛,同时在推断速度上比原始BERT提升了16倍+.
通过实体链接这个例子,我们可以看到:
合适的前沿算法会带来收益 。比如多模态模型带来的效果提升和模型压缩带来的计算效率提升。
收益有可能与初衷不同 。比如PET训练带来的额外收获是让训练收敛更快,提升了研发效率。
实体推荐
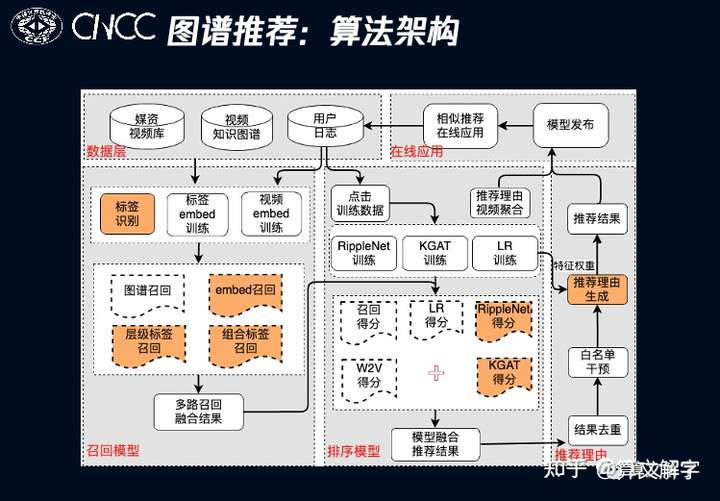
当你在腾讯视频中搜索一个非常明确的IP类的query,如“碟中谍6”时,在长视频(精品)结果中,除了给出目标影视综作品外,还会推荐一些类似的影视作品作为补充。这个推荐模块 优化的目标是在保证相关性的情况下,提升用户的点击率。场景的例子以及整体算法框架如下面两张图所示。
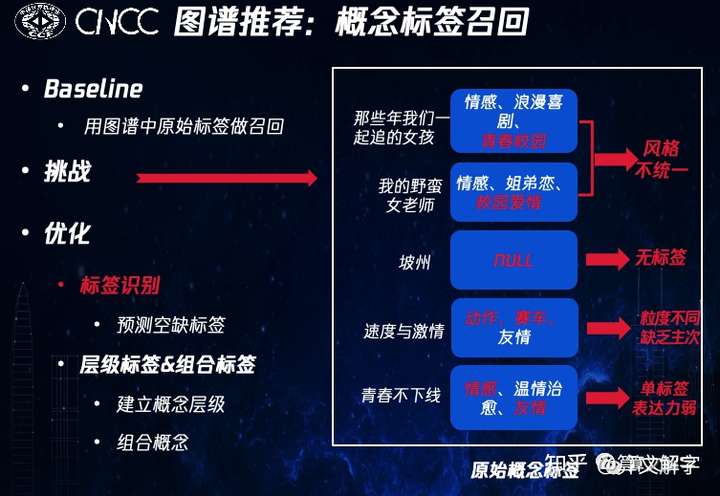
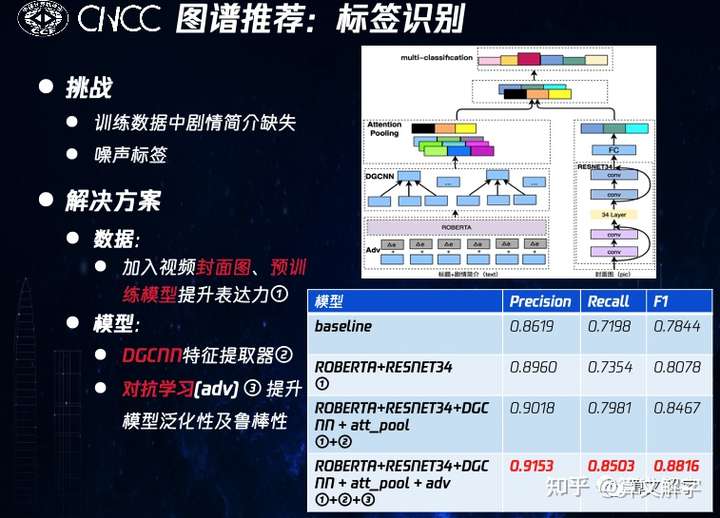
这里重点介绍召回 子模块。基线方法是用图谱中已有的实体标签做召回,但我们发现已有实体标签存在诸多问题,如标签风格不统一,单标签表达力弱等,以及更为重要的是很多中长尾的视频实体的标签是完全缺失的。这时亟需要做的是标签识别 ,其可以被建模为一个分类问题:以文本的剧情简介为输入,预测标签体系中最符合剧情的N个标签。
在解决这个分类问题的过程中,我们发现训练数据中很多长视频实体的剧情简介本身也是缺失的;同时,已有的标签中也有不少噪音。为了应对这些挑战,我们又一次引入了封面图的多模特征以增补文本信息。而在模型上则使用预训练模型RoBERTa的基础上用DGCNN特征提取器提升效果,同时采用了对抗学习 的方式提升模型鲁棒性以减少噪声标签的影响。从实验结果可以看到,每个模块或策略对效果都有所加持。
可解释性 。实际上,可解释性也是很多场景中引入知识图谱的动机之一。由于展示推荐理由的空间非常有限,我们的将推荐理由的范围聚焦在单一的可解释性特征,也就是实体的属性/标签上。我们首先会基于召回特征按照权重、粒度等条件选出一个标签的子集作为可解释性特征。然后使用一个简单的logistic regression模型来学习标签的权重,权重最高的标签即为推荐理由。推荐理由的文字描述是通过简单模板生成的,这样更为可控。即使是这种非常简单的可解释性策略,也在线上实验中取得了CTR提升0.8%的统计显著效果。
从上述实体推荐的例子,我们可以看到:
应用驱动的迭代 。实体标签的建设,也遵循了(上)篇中提出的应用驱动迭代原则,即业务场景-切入点-关键应用-资源建设的流程,从图谱推荐这个场景中反推出了资源建设需求,并用算法加以解决。
可解释性的价值 。
总结
我们认为精益领域图谱的建设之道可以用如下三个原则来概括。 其中前两个原则在(上)篇中做了详细的论述。
在(下)篇里,我们借助实体对齐、实体链接和实体推荐的例子讨论对算法应用的思考,可以归纳为第三个原则,即应当审视而非追逐算法前沿 :我们应该追求个性化 ,也就是能最好地解决我们特定场景问题的方法;要考虑综合化 ,将不同模型策略运用起来解决问题。笔者深知本文中讨论的具体技术和算法也许很快会过时,但希望所讨论的应用思路能给大家的研发能带来一点微小的启发。
参考文献 [1] Zeng, Kaisheng, et al. "A Comprehensive Survey of Entity Alignment for Knowledge Graphs." AI Open 2(2021):1-13.[2] Tang, Xiaobin, et al. "BERT-INT:a BERT-based Interaction Model for Knowledge Graph Alignment." Proceedings of the IJCAI . 2021.[3] Lu, Jiasen, et al. "VilBERT:Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks." NeurlPS (2019).[4] Schick, Timo, and Hinrich Schütze. "Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference." Proceedings of the EACL . 2021.