2012�꣬AIȦ�������������£���ʱ��˳��һ���ǹȸ������Ѿõ�Google Brain������������������һ���ܹ�ʶ��è�����ѧϰ���硰�ȸ�è����74.8%��ʶ��ȷ�ʣ���֪��ʶ��ͼ�����ImageNetǰһ���ʤ�㷨��74%��Ҫ�߳�0.8%��
���ȸ�ĸ߹�ʱ��ֻ�����˼����¡�2012��12�£�����һ��ImageNet�Ļ�ʤ�߳�¯�����ѧϰ����Hinton������Ӵ��ž���������AlexNet����ʶ����ȷ��һ����ߵ���84%���ɴ˿�����֮��ʮ���AI�������ȸ�è���������ʷ�ij���֮�С�
Hinton����λѧ����2012��
��ҵ���IJ�ֻ��ImageNetģ�ͱ����������Ҫ1400����ͼƬ���ܼ�262ǧ���ڴθ�������ѵ���������磬һ�����ڵ�ѵ�������н������Ŀ�Ӣΰ��Geforce GTX 580����Ϊ�ο����ȸ�è����1000����ͼƬ��16000��CPU��1000̨�����[1]��
����Google����һ��Ҳ���ܲμ��˱��������ܵ�����ֱ�������ڽ��������ж��ϣ�Googleһ�ߺ�����4400����Ԫ�չ���Hinton�Ŷӣ�һ��������Ӣΰ���µ�����GPU�����˹�����ѵ��������ͬʱ��ɨ�����Ļ�������Facebook��һ�ھ�ͷ��
Ӣΰ���Ϊ����Ӯ�ң��ɼ��ڽ���10�����������121����һ���۹������ˡ�
���۹����Ͽգ���£���������ơ�������Ӣΰ��ɨ����Google���������ЯAlphaGo�������࣬����2017�����������ھ��½ࡣ������˷��֣�����AlphaGo��оƬ������Ӣΰ���GPU������Google���е�TPUоƬ��
�ٹ����꣬���ƾ������ݡ�����������ѫһ����Ϊ��˿ͻ�����˹��Ҳ���Ӣΰ��GPU�������Ƴ�����NPUΪ���ĵ�FSD����оƬ��Ȼ�����ó��������AIѵ����Ⱥ��D1оƬ��������ζ��Ӣΰ�������ʧȥ��AIʱ������������Ҫ�Ŀͻ���
����2022�꣬ȫ��IT���ڽ������нΣ��Ƽ���������������ĵ�GPU�ɹ�Ԥ�㣬�������ڿ��Ҳ����ȴ�����������Ի�оƬ�����������ڳ���A100/H100�ȸ߶��Կ���Ӣΰ���汩�����ɼ۴���ߵ�һ�ȵ�ȥ��2/3��
2022���ChatGPT��ճ�����GPU��Ϊ��ģ�͡���������ȼ���ٴ��������Ӣΰ���ô�Ϣ����������������֮������2023��4��18�ţ������Ƽ�ý��The Information���ϣ�����AI�˳��ķ������������������з��Լ���AIоƬ[2]��
�������Athena��оƬ��̨�������������5nm�Ƚ��Ƴ̣����з��Ŷ������Ѿ��ӽ�300�ˡ������ԣ����оƬĿ�������������A100/H100����OpenAI�ṩ�������棬������һ����ͨ������Azure�Ʒ���������Ӣΰ��ĵ��⡣
��Ŀǰ��Ӣΰ��H100���IJɹ���������һ�ȴ���Ҫ����Բ��H100ȫ��IJ��ܡ��������ķ����ź�������һ������������Ҫ֪������ʹ��Intel��Ұ���ʱ����ͻ�Ҳû��һ�ҡ����ڡ�����CPUоƬ������ƻ������ƻ�������������ۣ���
����Ӣΰ��Ŀǰƾ��GPU+NVlink+CUDA¢����AI����90%���г������۹��Ѿ������˵�һ���ѷ졣
01
����ΪAI������GPU
���һ��ʼ��GPU�Ͳ���ΪAI������
1999��10��Ӣΰ�����GeForce 256������һ�����̨����220�����ա�������2300�������ܵ�ͼ�δ���оƬ��Ӣΰ���Graphics Processing Unit������ĸ��GPU��������������GeForce 256���ԡ������ϵ�һ��GPU���ƺţ�����ض�����GPU�����Ʒ�࣬��ռ������ʵ��û�����ֱ�����졣
����ʱ�˹������Ѿ����Ŷ��꣬�������������������Geoffery Hinton��Yann LeCun��δ����ͼ�齱������ǻ���ѧ�������������ţ����������뵽�Լ���ְҵ���ģ��ᱻһ�鱾��Ϊ��Ϸ��ҿ�����GPU�����ı䡣
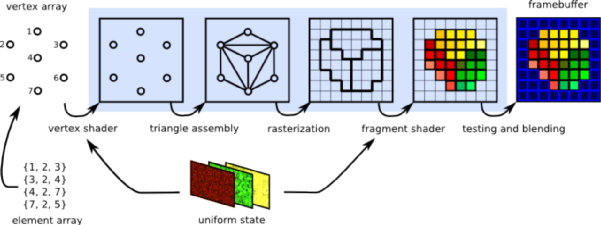
GPUΪ˭������ͼ����ȷ��˵����ΪCPU��ͼ����ʾ�Ŀ������н�ų���������ͼ����ʾ�Ļ���ԭ���ǽ�ÿһ֡��ͼ��ָ��һ�ſ����أ��ٶ�����ж��㴦����ͼԪ������դ��Ƭ�δ��������ز����ȶ����Ⱦ���������յ�����ʾ����Ļ�ϡ�
�����ص�ͼ��Ĵ������� ͼԴ��graphics compendium
Ϊʲô˵���ǿ������أ���һ���������⣺
�ٶ���Ļ����30������أ���60fps֡�ʼ��㣬ÿ����Ҫ���1800�����Ⱦ��ÿ�ΰ�������������裬��Ӧ����ָ�Ҳ����˵��CPUÿ��Ҫ���9000����ָ�����ʵ��һ��Ļ�����֣���Ϊ�ο�����ʱӢ�ض�������ߵ�CPUÿ��������6000��Ρ�
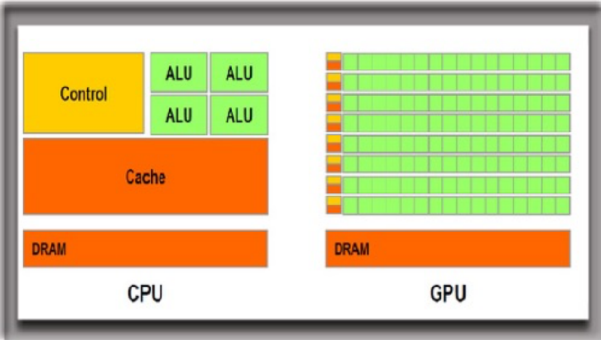
����CPU���������䱾�����̵߳��ȼ�����Ϊ�˽�����Ŀռ��öɸ��˿��Ƶ�Ԫ�ʹ洢��Ԫ�����ڼ���ļ��㵥Ԫֻռ��20%�Ŀռ䡣GPU���෴��80%���Ͽռ��Ǽ��㵥Ԫ�������˳�ǿ���м������������ʺ�ͼƬ��ʾ���ֲ���̶����ظ�����Ĺ�����
CPU��GPU�ڲ��ṹ����ɫ����Ϊ���㵥Ԫ
ֱ�������һЩ�˹�����ѧ�߲���ʶ�����߱��������Ե�GPUҲ���������ѧϰ��ѵ�����ܶྭ������������ܹ�����20�����°�Ҷ���Ѿ������������Ϊȱ��ѵ�����ǵļ���Ӳ�����ܶ��о�ֻ�ܡ�ֽ��̸��������չ����ͣ�͡�
1999��10�µ�һ�����죬���˹�����������GPU�����ѧϰ��ѵ�������Ƕ�ÿ������ֵ����������ÿ��ĺ����Ͳ������зֲ����㣬���յõ�һ�����ֵ����ͼ����Ⱦһ������Ҫ�����ľ������㡪����ǡ�ɾ���GPU���ó��Ķ�����
һ�����͵����������ܹ���ͼԴ��towards data science
����ͼ����ʾ��Ȼ���ݴ������Ӵ��ֲ����ǹ̶��ģ������������һ�����������������漰����֧�ṹ�ȸ��������ÿ��IJ�������Ҫ���ں���������������ѵ����������������Щ���Ϊ�պ�GPU����AI����Ӧ��������������
��������ѷAI/ML�ܾ���Kumar Chellapilla������Ե�GPU�з��ѧ�ߡ�2006����ʹ��Ӣΰ���GeForce 7800�Կ���һ��ʵ���˾��������磨CNN�������ֱ�ʹ��CPUҪ��4����������֪���罫GPU�������ѧϰ�ij���[3]��
Kumar Chellapilla��Ӣΰ��Geforce 7800
Kumar�Ĺ�����δ����㷺��ע�⣬����Ҫ��ԭ���ǻ���GPU��д����ĸ��ӶȺܸߡ���ǡ�ڴ�ʱ��Ӣΰ����2007���Ƴ���CUDAƽ̨������������GPU��ѵ�������������Ѷȴ���Ƚ��ͣ��������ѧϰ��ͽ�ǿ����˸���ϣ����
������2009�꣬˹̹�����������˷�����ͻ���Ե�һƪ����[6]��GPUƾ�賬��CPU 70����������AIѵ��ʱ��Ӽ������̵��˼�Сʱ����ƪ����Ϊ�˹����ܵ�Ӳ��ʵ��ָ���˷���GPU��������AI������������ʵ�Ĺ��̡�
Andrew Ng������
ֵ��һ����ǣ��������2011�����Google Brain���ǿ�ƪ�ᵽ�Ĺȸ�è��Ŀ�쵼��֮һ��Google Brain����û������GPU��ԭ�����˲��ö�֪����֮��������뿪�ȸ����ٶ�ǰ��һֱ�д��ų�����Ϊ�ȸ��GPU��̬�Ȳ�����
���������˵�̽�������������ڽ��������ѧϰ��ʦHinton�����ϣ���ʱʱ���Ѿ�ָ����2012�ꡣ
2012�꣬Hinton��Alex Krizhevsky��Ilya Sutskeverz����λѧ��һ�������һ����Ⱦ���������AlexNet���ƻ��μ���һ���ImageNet�������������������CPU��ѵ��AlexNet������Ҫ�����µ�ʱ�䣬�������ǰ�Ŀ��ת����GPU��
��������ѧϰ�ķ�չ��ʷ��������Ҫ��GPU�����������ġ��˵��Կ���GTX 580����ΪӢΰ������Fermi�ܹ����콢��Ʒ��GTX 580������512��CUDA���ģ���һ��Ϊ108�ţ���������Ծ��ͬʱ�����ŵĹ��ĺͷ�������Ҳ��Ӣΰ�ﱻ�������˵���������
��֮��˪����֮���ǡ�����GPUѵ��������ʱ�ġ�˳������ȣ�ɢ�������ֱ��ֵһ�ᡣHinton�Ŷ���Ӣΰ���CUDAƽ̨˳��������˱�̣�������GTX 580�Կ���֧���£�1400����ͼƬ��ѵ��ֻ����һ���ܣ�AlexNet˳����ڡ�
����ImageNet������Hinton���˵�Ӱ�����������˹�����ѧ�߶���һ˲����ʶ����GPU����Ҫ�ԡ�
����ȸ�ЯGoogLeNetģ�Ͳμ�ImageNet����93%��ȷ�ʶ�ڣ����õ�����Ӣΰ��GPU����һ�����в����Ŷ�GPU��ʹ�������������110�顣�ڱ���֮�⣬GPU�Ѿ���Ϊ���ѧϰ�ġ���ѡ���ѡ���������ѫ����ԴԴ���ϵĶ�����
����Ӣΰ��������ƶ����г��Ұܵ���Ӱ����2007��iPhone�����������ֻ�оƬ�ĵ���Ѹ�����ͣ�Ӣΰ��Ҳ��ͼ�����ǡ���ͨ�������Ƶ������һ���������Ƴ���Tegra��������Ϊɢ�����������顣����DZ�GPU���ȵ��˹���������������Ӣΰ��һ���ڶ��������ߡ�
��GPU�Ͼ�����Ϊ��ѵ��������������˹����ܷ�չ��Խ�죬��Щ���Ⱪ¶�ؾ�Խ�ࡣ
���磬��ȻGPU��CPU���������������߸����϶���ѭ�롤ŵ�����ṹ���洢�������Ƿ���ġ����ַ��������Ч��ƿ����ͼ�����Ͼ�������Թ̶�������ͨ������IJ�����������������ڷ�֧�ṹ�ڶ���������к���Ҫ����
������ÿ����һ���һ����֧����Ҫ����һ���ڴ�ķ��ʣ��洢�����Թ����ݣ��������������ʱ�䲻�ɱ��⡣�����ڴ�ģ��ʱ����ģ��Խ����Ҫִ�е��ڴ���ʲ�����Խ�ࡪ������������ڴ�����ϵ��ܺ�ҪԶ������Ҫ�ߺܶ��
�������ǣ�GPU��һ�����ⷢ����㵥Ԫ�ڶࣩ�����У��������յ���ÿ��ָ����ûع�ͷȥ��ָ���ֲᣨ�ڴ棩���������ģ�ʹ�С���Ӷȵ����������������ɻ��ʱ������ޣ�������Ƶ���ط��ֲ��۵����°�ĭ��
�ڴ�����ֻ��GPU�����������Ӧ���е���ࡰ���ʡ�֮һ��Ӣΰ���һ��ʼ����ʶ����Щ���⣬Ѹ�����֡�ħ�ġ�GPU���������Ӧ�˹�����Ӧ�ó������������ۻ��AI�����Ҳ�ڰ��ɳ²֣���ͼ����GPU��ȱ�����˿�����ѫ�۹���ǽ�ǡ�
һ������ս�Ϳ�ʼ�ˡ�
02
Google��Nvidia�İ�ս
�����ɽ������AI���������GPU������ȱ�ݣ�����ѫ��������Ӧ�Է�������ͷ������
��һ�ף��������š��������ɣ������ޱߡ���·�ӣ���������������������AI��������ÿ��3.5���¾ͷ�����ʱ�����������ǵ����˹����ܹ�˾��ǰ���Ǹ����ܲ���������һ��ʹ�����ѫ�ĵ�����տ��һ������һ������Ӣΰ�����еIJ��ܡ�
�ڶ��ף�����ͨ��������ʽ���¡��������GPU���˹����ܳ����IJ�ƥ�����⡣��Щ��������������ڹ��ġ��ڴ�ǽ������ƿ�����;��ȼ��㡢�������ӡ��ض�ģ���Ż�������2012�꿪ʼ��Ӣΰ����Ȼ�ӿ��˼ܹ����µ��ٶȡ�
Ӣΰ���CUDA����ͳһ�ļܹ���֧��Graphics��Computing��������2007���һ���ܹ��dz���ȡ��Tesla���Ⲣ���ǻ���ѫ��ʾ����˹�ˣ������¾�����ѧ�����������˹�������绹��һ���Ǿ���ܹ�����
֮��Ӣΰ��ÿһ��GPU�ܹ�����������ѧ��������������ͼ��ʾ����ÿһ�εļܹ������У�Ӣΰ��һ������������һ���ڲ����˽�ǡ���ǰ���¸�����
����2011��ĵڶ���Fermi�ܹ���ȱ����ɢ�����裬��2012��ĵ������ܹ�Kepler�Ͱ��������˼·��high-perfermanceת��power-efficient������ɢ�����⣻��Ϊ�˽��ǰ���ᵽ�ġ�����ɵ�ϡ������⣬2014��ĵ��Ĵ�Maxwell�ܹ������ڲ����Ӹ���������Ƶ�·�����ھ����ơ�
Ϊ����ӦAI������Ӣΰ�ħ�ġ����GPUij�̶ֳ���Խ��Խ��CPU��������CPU����ĵ�������������������Ϊ����һ����Ӣΰ�ﲻ�ò��ڼ�����ĵĶѵ��Ͽ���������������ͨ��������GPU����ô�ģ���AI������Ҳ�ѵ�ר��оƬ��
���ȶ�Ӣΰ��ѵģ���������ģ�ɹ�GPU������AI�����Google��
2014��ƾ��GoogLeNet���꼡���Google�Ͳ��ٹ����μӻ���ʶ�����������ı�з�AIר��оƬ��2016��Googleƾ��AlphaGo�������ˣ�Ӯ������ʯ�������Ƴ����е�AIоƬTPU���ԡ�ΪAI��������ȫ�¼ܹ�����Ӣΰ��һ�����ֲ�����
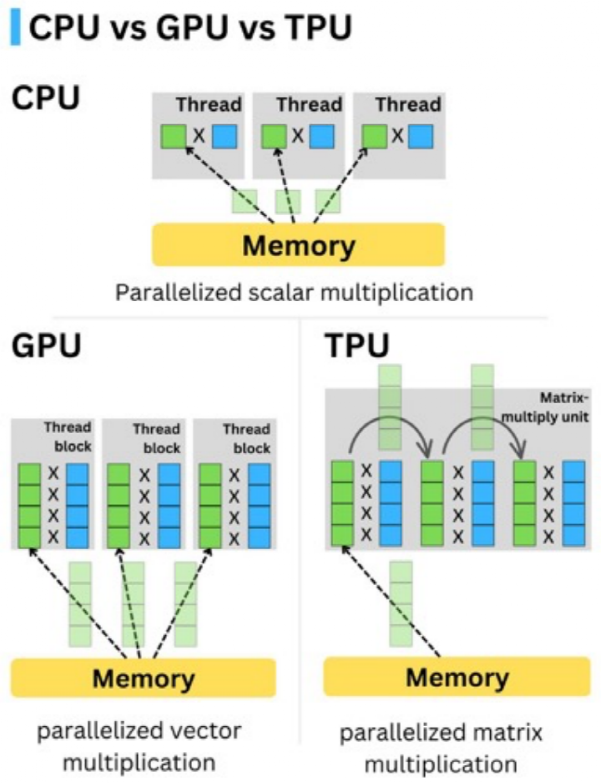
TPU��Tensor Processing Unit������ĸ��д������������������������Ԫ�������˵Ӣΰ���GPU�ġ�ħ�ġ��Dz��˶�ǽ����ǽ����ôTPU����ͨ���Ӹ����ϴ�����ʹ洢�����ӵ�����оƬ�ռ����̶��öɸ��˼��㣬������˵�����ֶΣ�
��һ�������������ִ����������ͨ��ʹ�ø߾������ݣ�ռ���ڴ�϶࣬����ʵ����������������Ҫ���ȴﵽ32λ��16λ������㣬���������ı��ʻ������ǽ�32λ/16λ���ֽ��Ƶ�8λ�����������ʵ���ȷ�ȣ����ͶԴ洢������
�ڶ����������У�������˷����У���Ҳ��TPU��GPU��ؼ�������֮һ������˵��������������Ҫ���д����������㣬GPUֻ�ܰ����Ͱཫ���������ɶ�������ļ��㣬ÿ���һ�鶼������ڴ棬������һ��Ľ����ֱ����������������㣬�ٽ�ÿ������ϵõ����ֵ��
����TPU�У���ǧ��������㵥Ԫ��ֱ�����������γɾ���˷����У���Ϊ������ģ�����ֱ�ӽ��о�����㣬�����ʼ�Ӽ������ݺͺ����������ٷ��ʴ洢��Ԫ������˷���Ƶ�ʣ�ʹ��TPU�ļ����ٶȴ��ӿ죬�ܺĺ������ռ�ռ��Ҳ��͡�
CPU��GPU��TPU�ڴ棨memory�����ʴ����Ա�
Google��TPU�ٶȷdz��죬����ơ���֤���������������Լ���������ֻ����15���µ�ʱ�䡣�������ԣ�TPU��CNN��LSTM��MLP��AI�����µ����ܺ��Ĵ��ʤ����Ӣΰ��ͬ�ڵ�GPU��ѹ����һ����ȫ��������Ӣΰ�
����ͻ����̵���ζ�����ܣ���Ӣΰ�ﲻ��վ�Ű���һ������ս��ʼ�ˡ�
Google�Ƴ�TPU��5���º�Ӣΰ��Ҳ������16nm���յ�Pascal�ܹ����¼ܹ�һ����������������NVLink����˫��������������������Ӵ�����һ����ģ��TPU������������ͨ���������ݾ���������������ļ���Ч�ʡ�
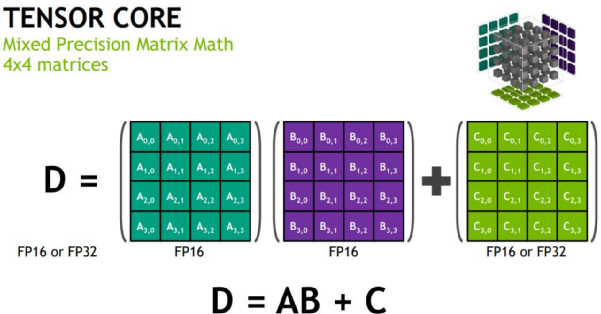
2017�꣬Ӣΰ�����Ƴ�����רΪ���ѧϰ��Ƶļܹ�Volta�������һ��������TensorCore��ר�����ھ�������ġ�����Ȼ4��4�ij˷����и�TPU 256��256����������������Ժ��ᣬ��Ҳ���ڱ�������ͨ���ԵĻ�������������Э��
��Ӣΰ��V100��TensorCoreʵ�ֵ�4x4��������
Ӣΰ��ĸ߹ܶԿͻ����ƣ���Volta������Pascal������������һ��ȫ�µļܹ�����
GoogleҲ���������2016���Ժ�TPU�������ڸ�����3����2017���Ƴ���TPUv2��2018���Ƴ���TPUv3��2021���Ƴ���TPUv4��������������Ӣΰ�������[4]��TPU v4��Ӣΰ���A100�����ٶȿ�1.2��1.7����ͬʱ���Ľ���1.3��1.9����
Google�����������TPUоƬ��ͬʱ�����������ɹ�Ӣΰ���GPU���������ߵ�AIоƬ����ͣ���ڡ����������ǡ��������ϡ����Ͼ�Google��TPU�䲿���Լҵ��Ʒ���ϵͳ�У������ṩAI��������������ѹ����Ӣΰ���DZ���г���
Google CEO Sundar Picha����չʾTPU v4
�����ߡ���������ͬʱ���˹���������Ľ�չҲ��һ��ǧ�2017��Google����˸����Ե�Transformerģ����OpenAI�漴����Transformer������GPT-1����ģ�͵ľ�������������AI����������2012��AlexNet����֮��ӭ���˵ڶ��μ��١�
������µķ���֮��Ӣΰ����2022���Ƴ�Hopper�ܹ����״���Ӳ������������Transformer�������棬���ƿ��Խ�����Transformer�Ĵ�����ģ�͵�ѵ��ʱ������9��������Hopper�ܹ���Ӣΰ���Ƴ��ˡ��ر���ǿGPU������H100��
H100��Ӣΰ����ռ�����Ϲ֡���һ���������˸���AI�Ż���������������������㣨Tensor Core 4.0����Transformer�������棻��һ�����������Ӣΰ�ﴫͳǿ���7296��CUDA�ˡ�80GB��HBM2�Դ��Լ��ߴ�900GB/s��NVLink 4.0���Ӽ�����
����H100��Ӣΰ����ʱ��һ��������������δ���ֱ�H100���ܴ������оƬ��
Google��Ӣΰ��İ������⣬ͬ��Ҳ����һ����ɾͣ�Ӣΰ���Google�����˲��ٴ��¼�����Google���˹�����ǰ���о�Ҳ���������Ӣΰ��GPU���Ƴ³��£��������ְ�AI�������͵�������ģ�͡����Žš����õ����ˮƽ����ͷ��������OpenAI��Ҳ��վ������λ�ļ��֮�ϡ�
���黳���黳����������⡣Χ��GPU�Ĺ�����ս����ҵ�����ȷ����һ�����飺GPU����AI�����Ž⣬���ƻ�ר��оƬ��ASIC�����ƽ�Ӣΰ��¢�ϵ�λ�Ŀ����ԡ��ѷ��ѿ���ѭζ��������Ȼ����ֻ��Googleһ�ҡ�
������������ΪAGIʱ����ȷ��������˭����Է���ʱ���Ӣΰ����һ����
03
һ������������ѷ�
����AI�ȳ�����OpenAI�⣬�������ҳ�Ȧ�Ĺ�˾��һ����AI��ͼ��˾Midjourney����Ը��ֻ���ļ�Ԧ����������̼�������ľ���ս������һ����Authropic����ʼ������OpenAI����Ի�������Claude��ChatGPT��������лء�
�������ҹ�˾��û�й���Ӣΰ��GPU����㣬����ʹ��Google����������
Ϊ��ӭ��AI�����ı�����Google��4096��TPU���һ�׳��㣨TPU v4 Pod����оƬ֮�������еĹ��·���أ�OCS��������������������ѵ���Լҵ�LaMDA��MUM��PaLM�ȴ�����ģ�ͣ����ܸ�AI������˾�ṩ���������ķ���
Google TPU v4 Pod����
�Լ�DIY����Ļ�����˹�������Ƴ�����FSDоƬ֮����˹����2021��8�������չʾ����3000���Լ�D1оƬ��ij���Dojo ExaPOD������D1оƬ��̨�������������7nm���գ�3000��D1оƬֱ����Dojo��Ϊȫ������������ģ�ļ������
�����������������Ȳ���������AthenaоƬ�������ij����
����Ӣΰ�����Ŀͻ�֮һ�����Լҵ�Azure�Ʒ������ٹ�����������A100��H100�߶�GPU��δ������Ҫ֧��ChatGPT�����ĶԻ����ģ���Ҫ����Bing��Microsoft 365��Teams��Github��SwiftKey��һϵ��Ҫʹ��AI�IJ�Ʒ��ȥ��
��ϸ����������Ҫ���ɵġ�Nvidia˰����һ���������֣�����оƬ�����DZ�Ȼ�������ﵱ������һ���Ա���èδ�����Ƽ��㡢���ݿ⡢�洢��������Ҳ��һ���������֣����ǹ��Ͽ�ʼ���ְ����ƣ��ڲ�չ��������ҵġ�ȥIOE���˶���
��ʡ�ɱ���һ���棬��ֱ���ϴ�����컯����һ���档���ֻ�ʱ���������ֻ���CPU��AP�����ڴ����Ļ�����Բ�������Ϊ��������ȫ���������º������͡�Google������о��Ҳ������Լ��Ʒ���������оƬ���Ż�����������ԡ�
���ԣ���ƻ�����Dz��������оƬ��ͬ��Google������AIоƬ��ȻҲ���������ۣ�����ͨ����AI�����Ʒ�����������Ӣΰ��һ����DZ�ڿͻ���Midjourney��Authropic�������ӣ�δ�����и����С��˾��������AIӦ�ò㣩ѡ���Ʒ���
ȫ���Ƽ����г��ļ��жȺܸߣ�ǰ����̣�����ѷAWS����Azure��Google Cloud�������ƺ�IBM��ռ�ȳ�60%���������Լ���AIоƬ������Google�Ľ�����졢IBM�Ĵ�����ǿ�����ij���������ѷ�ı���������á���������������ࡣ
���ڴ�����оƬ��Oppo�ܿ�Ľ�ֻ��ÿ���볡�����Ͷ����Ӱ��������������У��˲ż�����Ӧ�����������ʽ�������������������˹�������FSD����������ȴ���Jim Keller����Google�з�TPU��ֱ���뵽��ͼ�齱����ߡ�RISC�ܹ�������David Patterson������
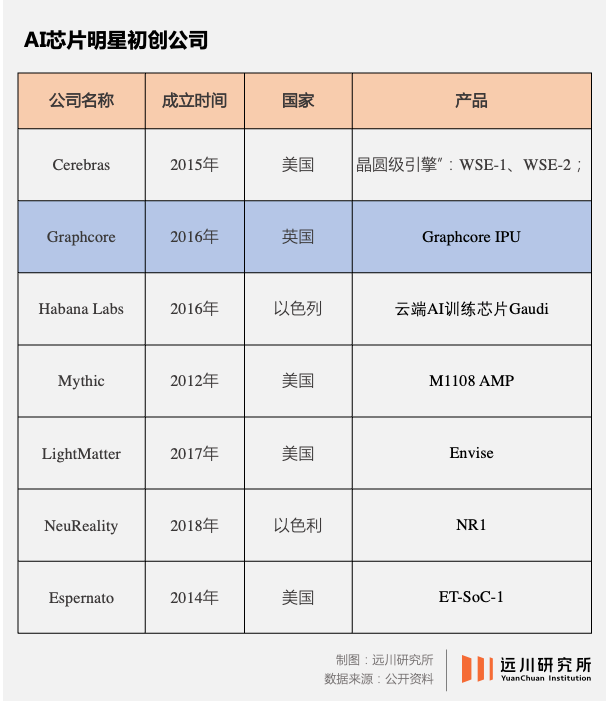
���˴��⣬һЩ��С��˾Ҳ����ͼ����Ӣΰ��ĵ��⣬���ֵһ�ȴﵽ28�������Graphcore�����ڵĺ����Ҳ���ڴ��С��±��о���Ŀǰȫ��Χ�ڽ�Ϊ֪���ij���AIоƬ��ƹ�˾��
AIоƬ������˾���������ڣ�û�д��ۺ�IJ�������Ͷ�룬Ҳ������Google�����Բ����������Ǽ���·�߶����辶���������ر�ǿ���������ڸ�Ӣΰ��̱����ʱ��������ʤ�㣬���ߵijɱ�����̬���Ƽ�������Ĩƽ�ͻ�һ�����ǡ�
Start-up��˾��Ӣΰ��ij�����ޣ�����ѫ�����ǻ�������Щ���岻��ʵ�Ĵ�ͻ����ϡ�
��Ȼ�������ڻ��벻��Ӣΰ����缴ʹGoogle��TPU�Ѿ����µ��˵�4��������Ȼ��Ҫ�������ɹ�GPU����TPUЭͬ�ṩ��������˹����ʹ�������ܴ������Dojo���㣬��˹���ڳィAI�¹�˾ʱ��Ȼѡ����Ӣΰ��ɹ�10000��GPU��
�������ڴ��������飬����ѫ�������˹���������Թ���2018����˹�˹�������Ҫ���г���оƬ����ʱ�õ���Ӣΰ���DRIVE PX��������ѫ�ڵ绰�����ϱ�����ʦ�������ʣ�һ���²���̨���º���˹�˷�����һ�������塱����һ��֮����˹����ȻͷҲ���ص���Ӣΰ���ȥ[5]��
����ʡ�ɱ��ⷽ�棬�����������顣PC��ʱ��Intel��оƬ��Ȼ����B�ˣ��������߾���ǿ�ҵ�ѡ�������ԣ�������Ҫ���Intel Inside�������������ƻ�ʱ������ͷ�������ε�һ�еײ�Ӳ����Ϣ��δ��ͬ������100TFlops�������������ֵܷ����IJ�������TPU���IJ�������GPU��
��ˣ�Ӣΰ�����ջ���Ҫֱ���Ǹ����⣺GPU��ȷ����ΪAI��������GPU�����AI�����Ž⣿
17����������ѫ��GPU�ӵ�һ����Ϸ��ͼ���������а��������ʹ���Ϊһ��ͨ���������ߣ�������ץ��Ԫ������˸�Ԫ���桢AI���˱�AI�����һ�����³������ϡ�ħ�ġ�GPU����ͼ�ڡ�ͨ���ԡ��͡�ר���ԡ�֮���ҵ�һ��ƽ��㡣
����Ӣΰ���ȥ��ʮ�꣬���Ƴ���������ĸı�ҵ����¼�����CUDAƽ̨��TensorCore��RT Core�������٣���NVLink��cuLithoƽ̨�������̣�����Ͼ��ȡ�Omniverse��Transformer����������Щ��������Ӣΰ���һ������оƬ��˾�����ȫ��ҵ��ֵ���ϲ�����ν����־��
��һ��ʱ��Ӧ����һ��ʱ���ļ���ܹ����˹����ܵķ�չһ��ǧ�����ͻ�ƿ쵽��Сʱ���ƣ��������AI���������������PC��/�����ֻ��ռ�ʱ���������������ô�����ɱ�������Ҫ�½�99%��GPU��ȷ���ܲ���Ψһ�Ĵ𰸡�
��ʷ�������ǣ�����������ĵ۹���ҲҪ�����ǵ������۵��ѷ졣