ChatGPT�Է�����������ѧ��������ڸ����
��������ѧ��š�����������ʾ��GPT-4���Լ�����ѧרҵ����û��̫�����ֵ��
��ô�죬��һֱ��ChatGPT��������ѧ���ϡ�ô��
OpenAI��Ŭ������Ϊ������GPT-4����ѧ����������OpenAI�Ŷ��á����̼ල����PRM��ѵ��ģ�͡�
������һ��һ����֤��

���ĵ�ַ��https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
�����У��о���Աѵ��ģ��ͨ������ÿһ����ȷ���������裬�������̼ල�������������ǽ�����ȷ�����ս��������ල��������ѧ����������ȡ������SOTA��
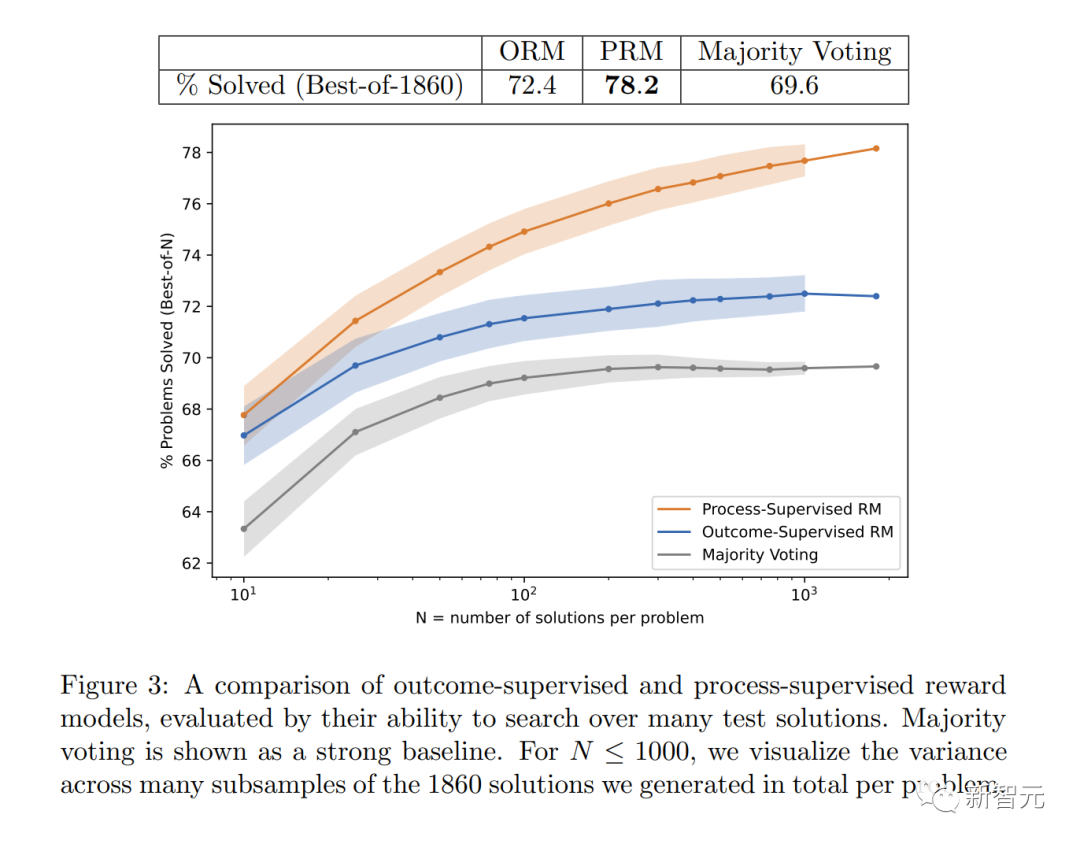
���������� PRM�����MATH���Լ��������Ӽ���78.2%�����⡣

���⣬OpenAI���֡����̼ල���ڶ������кܴ�ļ�ֵ����ѵ��ģ�Ͳ��������Ͽɵ�˼ά����
�����о���Ȼ�ٲ���Sam Altman��ת���������ǵ�Mathgen�Ŷ��ڹ��̼ල��ȡ���˷dz�������ܵĽ�������Ƕ���Ļ����źš���
��ʵ���У������̼ල����Ϊ��Ҫ�˹����������ڴ�ģ�ͺ���������˵�ɱ�������߰�����ˣ�����������ش���˵�ܹ�ȷ��OpenAIδ�����о�����
�����ѧ����
ʵ���У��о���Ա��MATH���ݼ��е����⣬�����������̼ල���͡�����ල���Ľ���ģ�͡�
��ģ��Ϊÿ����������������������Ȼ����ѡÿ������ģ��������ߵĽ��������
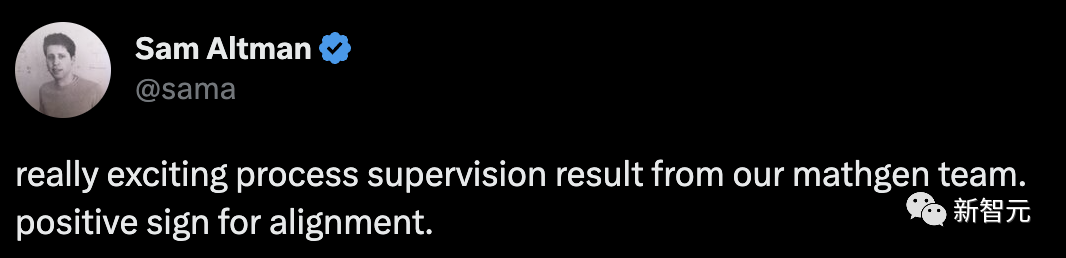
��ͼ��ʾ����ѡ��������У�ȡ����ȷ���մ𰸵İٷֱȣ���Ϊ�����ǽ�����������ĺ�����
�����̼ල������ģ�Ͳ����������ϱ��ָ��ã��������ſ���ÿ������ĸ��������������ܲ��Ҳ������
������������̼ල������ģ���ӿɿ���
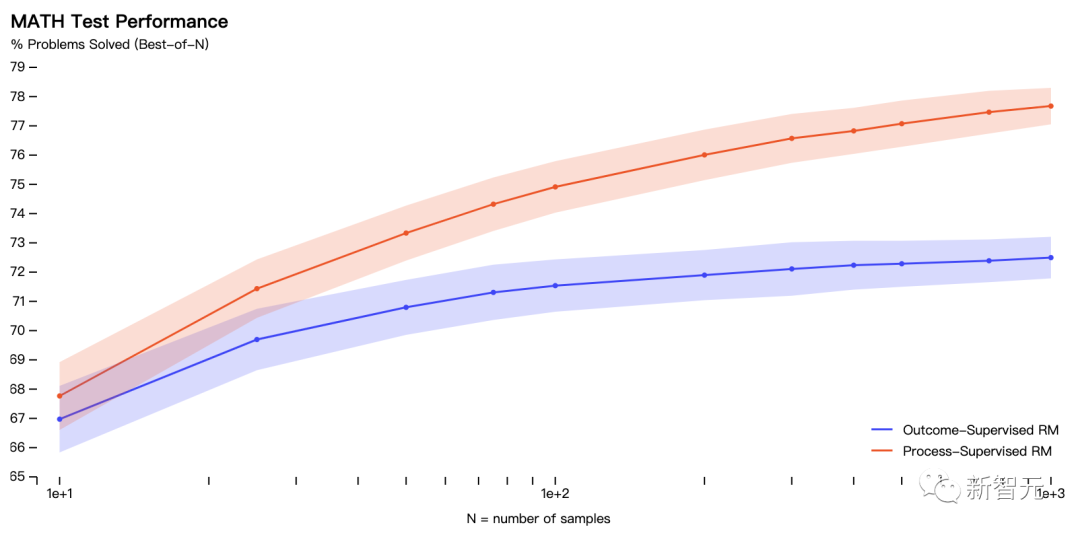
���£�OpenAIչʾ��ģ�͵�10����ѧ����ͽ���������Լ��Խ���ģ����ȱ������ۡ�
����������ָ�꣬������TP�����渺��TN����������FP������ģ�ͽ�����������
���£�OpenAIչʾ��ģ�͵�10����ѧ����ͽ���������Լ��Խ���ģ����ȱ������ۡ�
����������ָ�꣬������TP�����渺��TN����������FP������ģ�ͽ�����������

���GPT-4�ɹ���ִ����һϵ�и��ӵĶ���ʽ��ʽ�ֽ⡣
�ڲ���5��ʹ��Sophie-Germain���ʽ��һ����Ҫ�IJ��衣�ɼ�����һ������ж�������

�ڲ���7��8�У�GPT-4��ʼִ�в²�ͼ�顣
���Ǹ�ģ�Ϳ��ܲ������þ����ij����ط�����������ij���ض��IJ²��dzɹ��ġ�����������£�����ģ����֤ÿһ������ȷ��˼ά������ȷ�ġ�

ģ�ͳɹ���Ӧ���˼������Ǻ��ʽ�Լ���ʽ��

�渺��TN��
�ڲ���7�У�GPT-4��ͼ��һ������ʽ��������ʧ�ܡ�����ģ�ͷ������������

�ڲ���11�У�GPT-4����һ���ļ������ͬ��������ģ�ͷ��֡�

GPT-4�ڲ���12�г���ʹ�ò�ƽ����ʽ�����������ʽʵ���ϲ��Dz�ƽ����

����8�����ɺ���֣�������ģ������ͨ���ˡ�Ȼ�����ڲ���9�У�ģ�ʹ���ؽ�����ʽ�ֽ�����ӡ�
����ģ�ͱ�����������

������FP��
�ڲ���4�У�GPT-4��������ơ�����ÿ12���ظ�һ�Ρ�����ʵ����ÿ10���ظ�һ�Ρ����ּ�������ż������ƭ����ģ�͡�

����13�У�GPT-4��ͼͨ���ϲ����Ƶ��������̡�����ȷ�ؽ��������ƶ�����ϵ���ߣ�������ر����ұ߲��䡣����ģ�ͱ������������ƭ��

GPT-4���Խ��г����������ڲ���16�У���������С�����ظ����ְ���ǰ����㡣����ģ�ͱ������������ƭ��

GPT-4�ڲ���9�з���һ����ļ�������
�����ϣ�������5�ַ������Խ���ͬɫ������Ϊ��5����ɫ���ƺ��Ǻ����ġ�
Ȼ���������������2������ΪBob��2��ѡ���������ĸ����Alice������ģ�ͱ������������ƭ��

���̼ල
��Ȼ������ģ���ڸ������������������˺ܴ�������������������Ƚ���ģ����Ȼ������������˵�˵���Ҳ�������dz�˵�ġ��þ�����
������ʽ�˹����ܵ��ȳ��У�������ģ�͵Ļþ�һֱ�����ǿ��ղ��ѡ�
��˹��˵��������Ҫ����TruthGPT
���������һλ������ʦ��ŦԼ���Ժ���ļ��о�������ChatGPT������İ��������������Ʋá�
OpenAI���о����ڱ������ᵽ��������Ҫ�ಽ��������������Щ�þ���������⣬��Ϊ��һ�������������Զ��������������ɼ�����ƻ�����
���ң�����þ���Ҳ�ǹ���һ��AGI�Ĺؼ���
��ô���ٴ�ģ�͵Ļþ��أ�һ�������ַ����������̼ල�ͽ���ල��
������ල��������˼�壬���Ǹ������ս������ģ�ͷ������������̼ල����������˼ά���е�ÿ�������ṩ������

�ڹ��̼ල�У��ά����ģ����ȷ���������裬���������ǽ���������ȷ�����ս��ۡ�������̣������ģ����ѭ�������������˼ά�����������Ҳ����������õĿɽ���AI��
OpenAI���о��߱�ʾ����Ȼ���̼ල������OpenAI�����ģ���OpenAI����Ŭ���ƶ�����ǰ��չ��
�����о��У� OpenAI�ѡ�����ල�����̼ල�����ַ���������һ�顣��ʹ��MATH���ݼ���Ϊ����ƽ̨�����������ַ�����������ϸ�Ƚϡ�
������֣������̼ල���ܹ��������ģ�����ܡ�
������ѧ�������̼ල���Դ�ģ�ͺ�Сģ�Ͷ����������Ը��õĽ��������ζ��ģ��ͨ������ȷ�ģ����һ����ֳ��˸��������˼ά���̡�
��������ʹ����ǿ���ģ����Ҳ���ѱ���Ļþ��������Ϳ��Լ����ˡ�
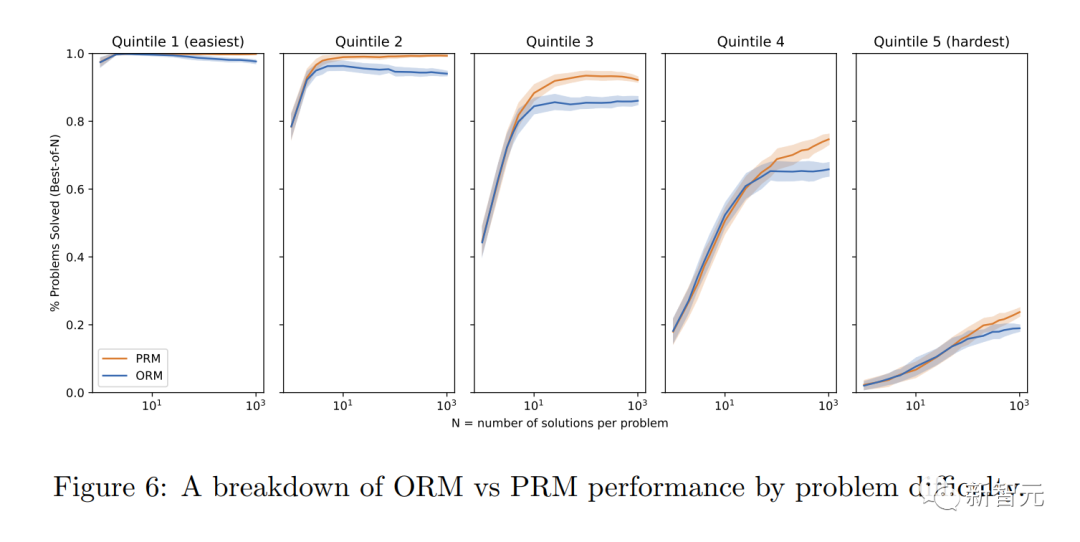
������������
�о���Ա�����ˡ����̼ල���ȡ�����ල���м����������ƣ�
�� ֱ�ӽ�����ѭһ�µ�˼ά��ģ�ͣ���Ϊ�����е�ÿ�����趼�ܵ���ȷ�ļල��
�� ���п��ܲ����ɽ��͵���������Ϊ�����̼ල������ģ����ѭ�����ϿɵĹ��̡����֮�£�����ල���ܻά��һ����һ�µĹ��̣�����ͨ��������顣
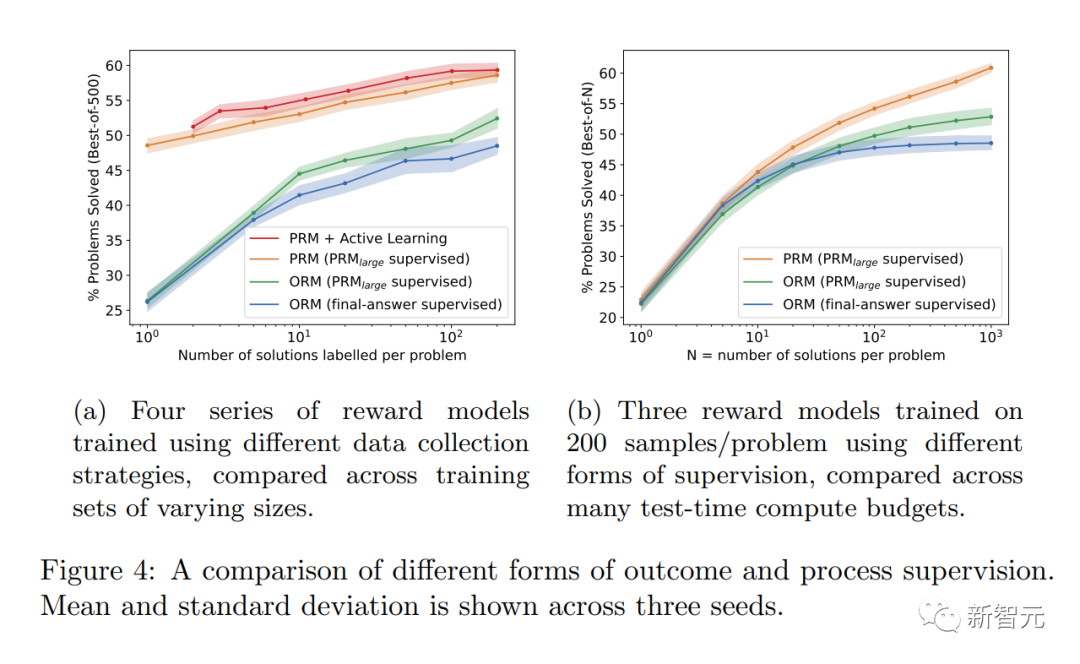
����ֵ��һ����ǣ���ijЩ����£���AIϵͳ����ȫ�ķ������ܻᵼ�������½������ֳɱ�����Ϊ������˰����alignment tax����
һ����˵��Ϊ�˲�������������ģ�ͣ��κΡ�����˰���ɱ��������谭���뷽���IJ��á�
���ǣ��о���Ա���µĽ�������������̼ල������ѧ������Թ�����ʵ���ϻ������������˰����
����˵��û����Ϊ������ɽϴ�������ġ�
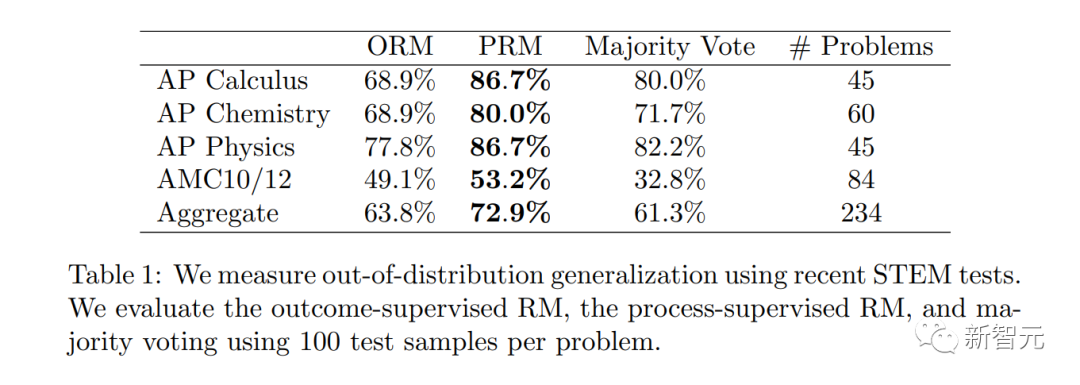
OpenAI����80���˹���ע���ݼ�
ֵ��ע����ǣ�PRM��Ҫ����������ע�����������벻��RLHF��
���̼ල����ѧ����������ж����������أ����������Ҫ��һ��̽����
OpenAI�о���Ա������������෴�����ݼ�PRM������800,000�����輶��ȷ��ע��12K��ѧ�������ɵ�75K�������

������һ����ע��ʾ����OpenAI���ڷ���ԭʼ��ע���Լ�����Ŀ��1�κ͵�2�θ���ע�ߵ�ָʾ��
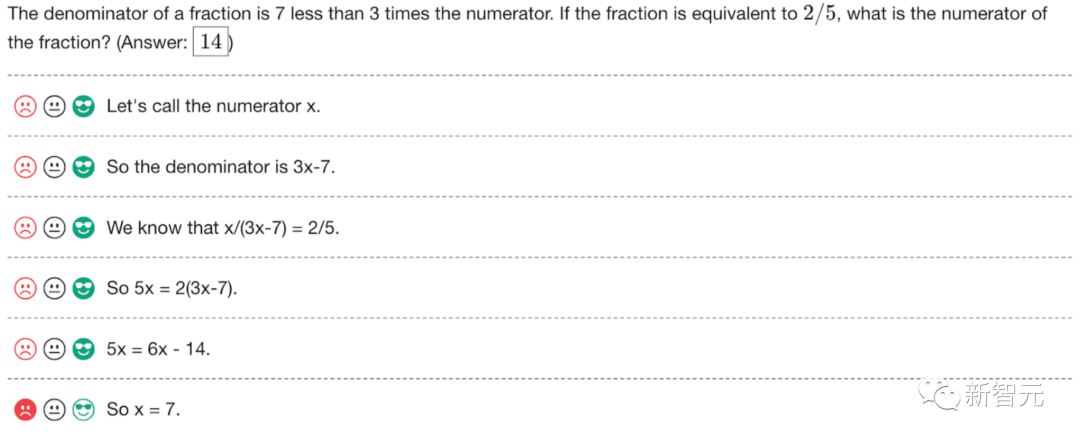
��������
Ӣΰ���ѧ��Jim Fan��OpenAI�����о�����һ���ܽ
���ھ�����ս�Եķֲ����⣬��ÿһ�������轱�����������������赥һ�Ľ����������ϣ��ܼ������ź�>ϡ�轱���źš� ���̽���ģ�ͣ�PRM���ܹ��Ƚ������ģ�ͣ�ORM������Ϊ���ѵ�MATH����ѡ�����������һ����Ȼ����PRM��GPT-4�������������Ļ�û���������� ��Ҫע����ǣ�PRM��Ҫ����������ע��OpenAI���������෴�����ݼ�����12K��ѧ�����75K��������е�800K���輶��ע��

�������ѧʱ��˵��һ���ϻ���ѧ�����ȥ˼����

ѵ��ģ��ȥ˼�����������������ȷ�Ĵ𰸣������Ϊ������������game changer��

ChatGPT����ѧ���泬��������������ͼ���һ�����꼶��ѧ���ϵ���ѧ���⡣ChatGPT���˴���𰸡��Ұ��ҵĴ𰸺�ChatGPT�Ĵ𰸣���perplexity AI���ȸ�Ĵ𰸣��Լ����꼶����ʦ�����˺˶ԡ�ÿ���ط�������ȷ�ϣ�chatgpt�Ĵ��Ǵ���ġ�

�ο����ϣ�
https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
���Ͼ���GPT-4��ѧ������ļ���OpenAI�����о������̼ල��ͻ��78.2%���⣬�ɵ��þ�����ϸ���ݣ��������עphp����������������£�

















