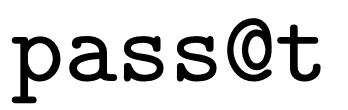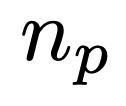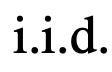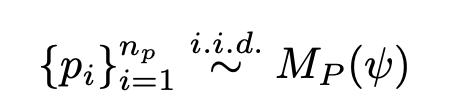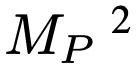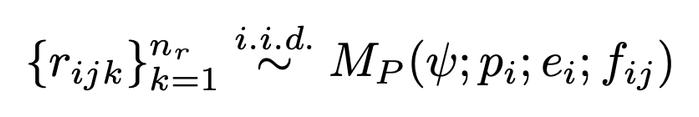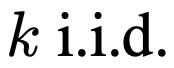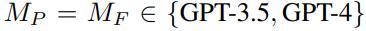���Ƕ�֪������ģ�;�����ʡ���������Զ�д���Ĵ���������Ҿ�����
��������������Ļ��ƣ����������������ģ�
�Դ���Ϊʲô�Ǵ���ģ�ģ���ڶ��̶������ṩȷ������
���գ�MIT������ѧ�߷��֣���GPT-4��GPT-3.5֮�У�ֻ��GPT-4���ֳ�����Ч�����������ң�GPT-4�������ܶ�GPT-3.5���ɵij����ṩ������
 ���ĵ�ַ��https://arxiv.org/pdf/2306.09896.pdf
���ĵ�ַ��https://arxiv.org/pdf/2306.09896.pdfӢΰ���ѧ��Jim Fanǿ���Ƽ��������о���
������������ʹ����רҵ���������ԱҲ��һ������ȷ��д����������Ҫ�鿴ִ�н�����������������ڣ���������ʩ���������ԡ�����һ��������ѭ�������ݻ������������Ľ����롣
���п��ܣ�OpenAI����ͨ����Ӷ������������ʦ��ѵ����һ��GPT�������Dz���Ҫ������롪��Critique is all you need��
- GPT-4�ܹ������������ĺ���ԭ������ǿ��ķ������������ܹ���Ч�����ҷ�˼������������ڣ�����ģ������֮������
- ����ģ�ͺʹ�������ģ�Ͳ�����ͬ����ʵ�ϣ�����ģ����ƿ����
- ����GPT-4�ķ�����GPT-3.5�ܹ���д���õĴ��롣
- ����רҵ��Ա�ķ�����GPT-4�����ܹ���д���õĴ��롣
�������ڴ�������GPT��
���Ƕ�֪����������ģ�������ɴ��뷽�棬���ֳ��˷Ƿ���������
Ȼ�����ھ�����ս�Եı�������羺������������ʦ�����ԣ��У�����ȴ��ɵò����á�
���ڣ��ܶ�ģ�ͻ�ͨ��һ������������������ʡ���������Ҿ��������еĴ���
�о��ߺ�ϣ��֪������Щģ���ڶ��̶������ṩ��ȷ�ķ���������˵���Լ����ɵĴ���Ϊʲô�Ǵ���ġ�
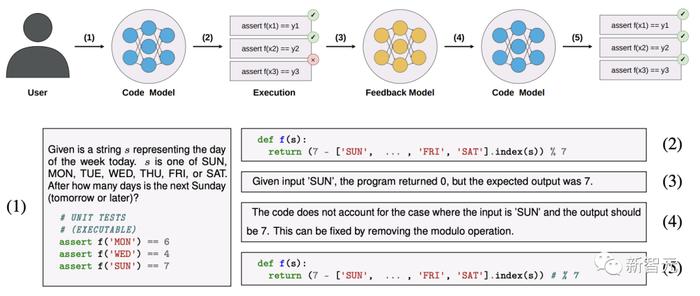
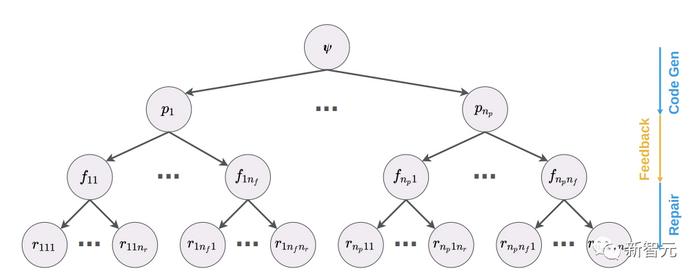
��ͼ��ʾ���ǣ����������������ľ��乤�����̡�
���ȣ�����һ���淶���Ӵ�������ģ���в���һ������Ȼ���ڹ淶���ṩ��һ�鵥Ԫ������ִ�иó���
����������κε�Ԫ������ʧ�ܣ���ô�������Ϣ�ͳ���ᱻ�ṩ��һ����������ģ�ͣ���ģ�����������ʧ��ԭ��ļ�̽��͡�
����������ݸ�һ����ģ�ͣ���ģ�����ɳ����һ���̶��汾��
�����Ͽ�������������ƺ��dz�����������ϵͳ�ڽ�������п˷����ڲ�����������Ĵ������������غϲ����Է���ϵͳ������������̬�������ߺ�ִ������ȣ��ķ�����
����ģ��������������ʦ��д������Դ���ʽ��
Ȼ������������һ�����⣺������Ҫ��ģ�ͽ��и���ĵ��ã��Ӷ������˼���ɱ���
���ң��о����Ƿ�����һ��������˼������ģ����������Ч�Բ���ȡ����ģ�����ɴ������������ȡ���������ڴ�������������з�����ʶ��������
Ŀǰ��û���κι����Դ˽�����ϸ���飬��ˣ��������о���GPT-3.5��GPT-4�ڽ��������������������ʱ��������Ч�ԡ�
�о���Ա�����һ���µ��������ԣ���Ϊ
������������У����ݴ�ģ���в�����token���������������ͨ���ʡ�
��Ϊʹ�õ���pass@t�������Ǵ�ͳ��pass@k������ʵ����������ͨ���ʣ������������봿����ڲ����ķ������й�ƽ�ıȽϡ�
��ʵ���У��о��߷��֣�
1. GPT-4����ʵ����������������������������GPT-3.5��������Ԥ���£������ͨ����Ҫ���ڻ���ڻ�������������
2. ��ʹ����GPT-4ģ�ͣ���������Ҳ���ֻ�������ʶȵģ���Ԥ��Ϊ7000��token������£�ͨ���ʴ�66����ߵ�71����Լ����45������ͬ�ֲ���GPT-4�����ijɱ���������ȡ���ڳ�ʼ����Ķ������㹻�ḻ��
3. ʹ��GPT-4���ɵķ����滻GPT-3.5�Դ���Ľ��ͣ����Ի�ø��õ��������ܣ�����������������GPT-3.5��������7000��token�£���50����ߵ�54������
4. ʹ���������Ա�ṩ�Ľ����滻GPT-4�Լ��Ľ��ͣ���������������Ч��������ͨ�����Եij�������������57%��
�������Ľ�
���������漰4���Σ��������ɡ�����ִ�С��������ɺʹ��������Դˣ��о���Ա��ʽ���������ĸ��Ρ�
��һ����������
�����淶
����
����������
��һ������ģ��
��һ����ʽ����ʾ��
�ζ�������ִ��
Ȼ���ڲ���ƽ̨��ִ��
����ʾ��������������Կ�ִ����ʽ�ķ����������Լ���
����κ�����ͨ�������еIJ��ԣ��ͻ�ֹͣ����Ϊ��ʱ�Ѿ��ҵ�����������ij���
�����ռ�ִ�л������صĴ�����Ϣ
��
��Щ������ϢҪô��������/����ʱ������Ϣ��Ҫô�������������Ԥ�ڲ�ͬ��ʾ�����롣
��������������
�ڴˣ��о���Աʹ�÷���ģ�������ɸ���ϸ�Ĵ�����͡�
������Σ�Ϊÿ������ij�������
��������ʾ:
�����ַ�����
���ģ�������
�����һ���У�����ÿ����ʼ����
�����
��ѡ�������
��
�ͷ���
�о���Ա��������̲����Ľ����ı��ͳ���������T
����ֲ���ڹ淶
��
��Ȼ����
��ÿ�������֧������
��Ȼ���֧����ʼ����
������ͼ��ʾ��
������������Ҫ������һ�³ɱ������ģ�͵��ã������������У�
�����л����ȷ����Ŀ����ԣ����DZȽϺ������������ĸ��ֳ�����ѡ��ĺ��ʶ�����
����
�෴���о���Ա��ͨ������Ϊ��ģ���в�����token�����ĺ����������������֮Ϊ
�Ķ�����
ʵ�����
�о���Ա�ֽ�һ�����3����������˲��ԣ�
1. ���ڸ�������ս�ı�������У���Щģ�͵��������Ƿ�Ȳ���������i.i.d.�и��õIJ�����
2. ��ǿ�ķ���ģ�ͻ����ģ�͵���������
3. �����������빦����ǿģ�͵�������ѭ�����ṩ�˹��������Ƿ���Խ������õ������ܣ�
�����о��Ŷ�������һ��������ս�ı������Automated Programming Progress Standard ��APPS�����ݼ��еı������
������ݼ��е�������������ż�����ѧ�������ı�����������������������Ա�������ʹ���������
�о���Աѡȡ��300��������60�����ż���������60���������������
�о���Աѡȡ��GPT-3.5��GPT-4��Ϊģ�ͣ�ʹ��ģ���ַ������Ӻ͵�����ʾ����������������
��ͼΪ��ʾ�ʵ�ʵ��֮һ��
������Ҫǿ���ģ�ͺͶ������ij�ʼ����
�о���Ա�õ���ģ�ͷֱ���д���������ɺͷ������ɡ�
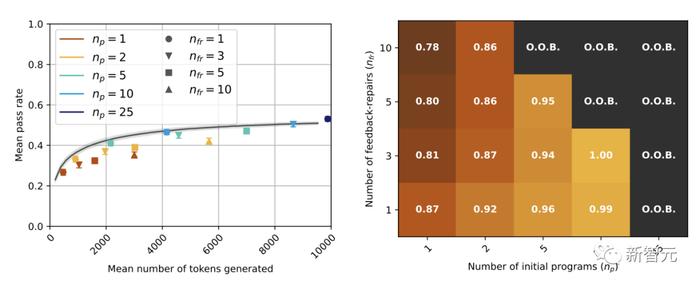
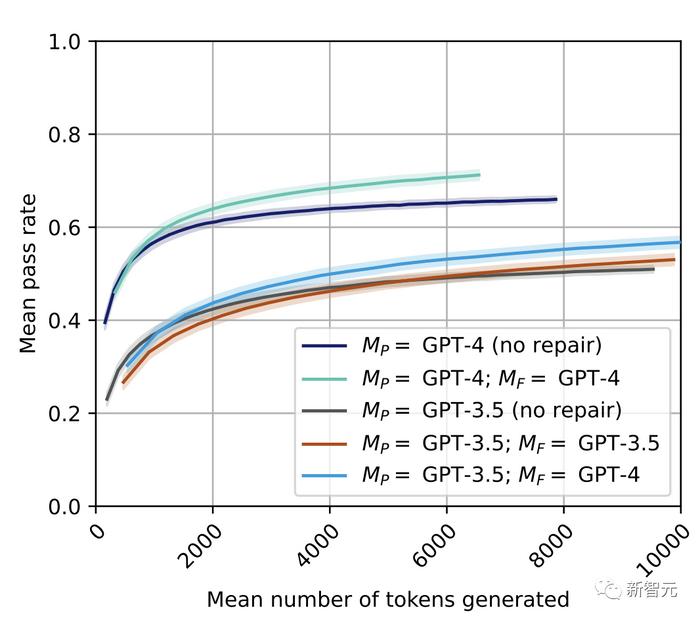
���ұߵ�ͼ�У�����������ʾ�˾�����������������ͼ������ÿ����Ԫ���е�ֵ��ʾƽ��ͨ���ʣ���������ͬ��tokenԤ�㣨��t����ֵͬpass@t��ʱ���������ɻ��ߵ�ƽ��ͨ���ʹ�һ����
��ͼ�п��Կ���������GPT-3.5ģ�ͣ�pass@t�����������¶����ڻ������Ӧ�Ļ��ߣ��ڣ�������ر�����������GPT-3.5������һ����Ч�IJ��ԡ�
����GPT-4����ͼ���У��м���ֵ������ͨ�����������ڻ��ߡ�
��ͼ��
�ͻ��ߵ�����������
GPT-4�����Ľ���GPT3.5�������
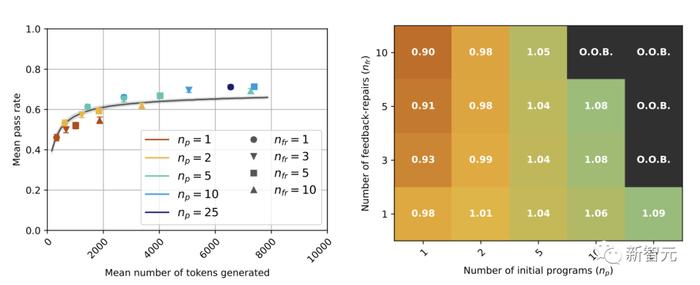
�о���Ա�ֽ�һ���������µ�ʵ�飬����ʹ�õ����ġ���ǿ��ģ�������ɷ�����Ч����Ŀ����Ϊ�˲���һ�����裺����ģ������ʡ�͵����Լ��Ĵ��룬�谭��������������˵����GPT-3.5����
���ʵ��Ľ������ͼ������ɫ����ʾ��
�ھ������ܷ��棬GPT-3.5��GPT-4ȷʵͻ���������ϰ������ұ�GPT-3.5��i.i.d.����������Ч��
������ı������α�����������Ҫ�ģ��Ľ������Ի���GPT-3.5������ƿ����
�˹��������������GPT-4���ijɹ���
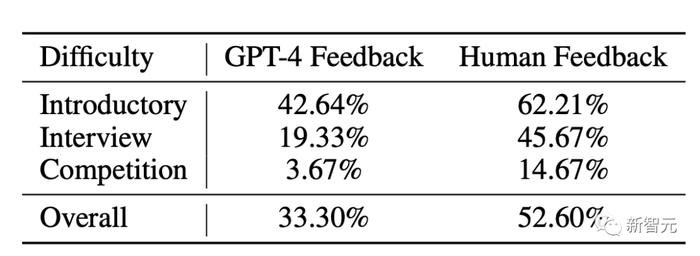
�����һ��ʵ���У���Ҫ�о����ø�ǿ��ģ�ͣ�GPT-4��������ʱ������ר���������Ա�ķ�����Ӱ�졣
�о�Ŀ�����˽�ģ��ʶ������д������������������������Σ��Լ������Ӱ���������������ܡ�
�о���Ա�о���Ա��ļ��16�������ߣ�����15���о�����1��רҵ����ѧϰ����ʦ��
ÿ�������߶������ֲ�ͬ�Ļ������������ǵ�Python�����д���롣
ÿ������ȡ�Բ�ͬ������������Զ���ῴ������ͬһ�������������ͬ�ij���
Ȼ�����߱�Ҫ���������Լ��Ļ������������������ʲô��
ʵ��������ͼ��ʾ��
�о���Ա���֣�����������������ߵĵ����滻GPT-4�Լ��ĵ���ʱ������ɹ��������1.57�����ϡ�
����������ǣ����������ø��ѣ���Բ���Ҳ�����ӣ�����������ʹ��룩��ø�����ʱ��GPT-4����ȷ�����÷���������ԶԶ�������������ߡ�
���߽���
Jianfeng Gao���߽��棩
�߽��������Ľܳ���ѧ�Һ��ܲã�Ҳ��IEEE Fellow��
�����о�Ժ������Redmond�ֲ����ѧϰ��DL����ĸ����ˡ������ʹ�����ƽ�DL�����¼�����������Ӧ������Ȼ���Ժ�ͼ�������Լ������Ի����������쵼�˹������ģ����ģ�͵��о�����Щģ��Ϊ������Ҫ�˹����ܲ�Ʒ�ṩ��֧�֡�
��2022�꿪ʼ�����������ҸĽ��˹����ܵ��о������а�����LLM����ChatGPT/GPT4��������ǿ����Ӧ����������ҵ�˹�����ϵͳ�Ŀ�����
�ڴ�֮ǰ������1999�����Ϻ���ͨ��ѧ��ò�ʿѧλ��
Chenglong Wang
Chenglong Wang�����о�Ժ���о�Ա����ǰ�ڻ�ʢ�ٴ�ѧ����˲�ʿѧλ�������Ͷ��ڱ�����ѧ��