дкзіЪ§ОнЗжЮіЪБЃЌОГЃЛсгаетбљЕФРЇШХЃКУцЖдМИжжЯрЫЦЕФЗНЗЈЃЌМШВЛЧхГўЫќУЧИїздЕФЪЙгУГЁОАЃЌвВЮоЗЈЗжЧхЫќУЧжЎМфЕФВюБ№ЃЌвЛФюжЎВюОЭПЩФмбЁДэЗНЗЈЁЃШчЙћФувВгаетбљЕФРЇШХЃЌНЈвщАДееSPSSAUжЊЪЖЭМЦзФПТМЫГађМьЫїЖдгІЕФбаОПЗНЗЈЃЌРэЧхВЛЭЌЗНЗЈЕФЧјБ№гыЪЙгУГЁОАЃЌвдБубЁГіе§ШЗЕФЗНЗЈНјааЗжЮіЁЃSPSSAUжЊЪЖФПТМШчЯТЃК
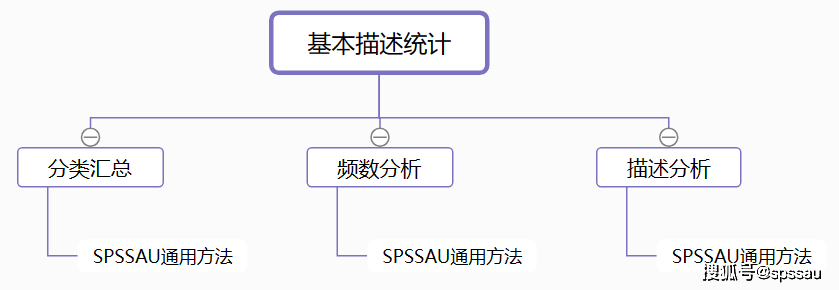
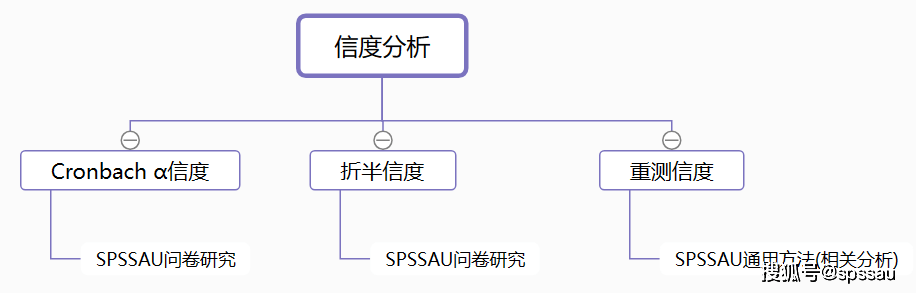
2ЁЂаХЖШЗжЮі
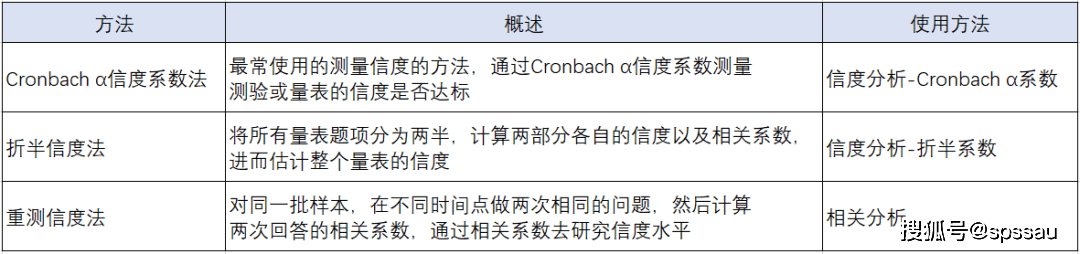
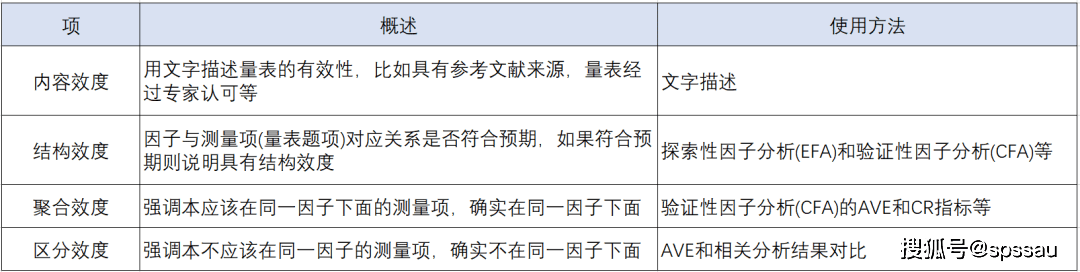
аХЖШЗжЮіЕФЗНЗЈжївЊгавдЯТШ§жжЃКCronbach ІСаХЖШЯЕЪ§ЗЈЁЂелАыаХЖШЗЈЁЂжиВтаХЖШЗЈЁЃ
ЁЄ Cronbach ІСаХЖШЃКзюГЃЪЙгУЕФЗНЗЈЃЌЭЈЙ§Cronbach ІСаХЖШЯЕЪ§ВтСПВтбщЛђСПБэЕФаХЖШЪЧЗёДяБъЁЃ
ЁЄ елАыаХЖШЃКЪЧНЋЫљгаСПБэЬтЯюЗжЮЊСНАыЃЌМЦЫуСНВПЗжИїздЕФаХЖШвдМАЯрЙиЯЕЪ§ЃЌНјЖјЙРМЦећИіСПБэЕФаХЖШЕФВтСПЗНЗЈЁЃ
ЁЄ жиВтаХЖШЃКЪЧжИЭЌвЛХњбљБОЃЌдкВЛЭЌЪБМфЕузіСЫСНДЮЯрЭЌЕФЮЪЬтЃЌШЛКѓМЦЫуСНДЮЛиД№ЕФЯрЙиЯЕЪ§ЃЌЭЈЙ§ЯрЙиЯЕЪ§ШЅбаОПаХЖШЫЎЦНЁЃ
3ЁЂаЇЖШЗжЮі
аЇЖШгаКмЖржжЃЌПЩЗжЮЊЫФжжРраЭЃКФкШнаЇЖШЁЂНсЙЙаЇЖШЁЂЧјЗжаЇЖШЁЂОлКЯаЇЖШЁЃ
ЁЄ ФкШнаЇЖШЃКгУЮФзжУшЪіСПБэЕФгааЇадЃЌБШШчОпгаВЮПМЮФЯзРДдДЃЌСПБэОЙ§зЈМвШЯПЩЕШЁЃ
ЁЄ НсЙЙаЇЖШЃКвђзггыВтСПЯюЖдгІЙиЯЕЪЧЗёЗћКЯдЄЦкЃЌШчЙћЗћКЯдЄЦкдђЫЕУїОпгаНсЙЙаЇЖШЁЃ
ЁЄ ЧјЗжаЇЖШЃКЧПЕїБОВЛгІИУдкЭЌвЛвђзгЯТЕФВтСПЯюЃЌШЗЪЕВЛдкЭЌвЛвђзгЯТУцЁЃ
ЁЄ ОлКЯаЇЖШЃКЧПЕїБОгІИУдкЭЌвЛвђзгЯТУцЕФВтСПЯюЃЌШЗЪЕдкЭЌвЛвђзгЯТУцЁЃ
4ЁЂВювьЙиЯЕбаОП
ГЃМћЕФВювьЙиЯЕбаОПЗНЗЈАќРЈЗНВюЗжЮіЁЂtМьбщЁЂПЈЗНМьбщЁЂЗЧВЮЪ§МьбщЁЃ
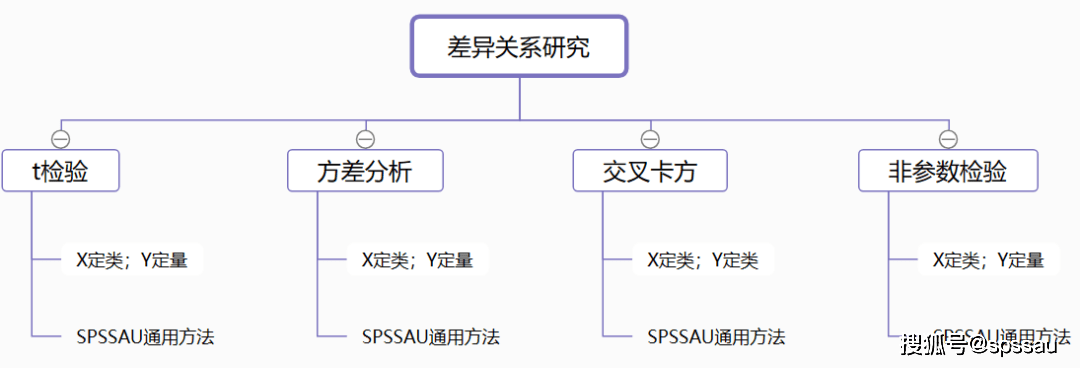
ЁЄ t МьбщЃКXЮЊЖЈРрЪ§ОнЃЌYЮЊЖЈСПЪ§ОнжЎМфЕФЙиЯЕЧщПіЃЌЧвXжЛФмЮЊ2ИіРрБ№ЁЃ
ЁЄ ЗНВюЗжЮіЃКXЮЊЖЈРрЪ§ОнЃЌYЮЊЖЈСПЪ§ОнЃЌЧвзщБ№Жргк2зщЪБПЩЪЙгУЗНВюЗжЮіЁЃ
ЁЄ НЛВцПЈЗНЃКЗжЮіЖЈРрЪ§ОнКЭЖЈРрЪ§ОнжЎМфЕФЙиЯЕЧщПіЃЌПЩЪЙгУНЛВцПЈЗНЗжЮіЁЃ
ЁЄ ЗЧВЮЪ§МьбщЃКЪ§ОнВЛе§ЬЌЛђепЗНВюВЛЦыЪБЃЌПЩЪЙгУЗЧВЮЪ§МьбщЁЃ
ЬсЪОЃКtМьбщКЭЗНВюЗжЮіОљЪєгкВЮЪ§МьбщЗЖЮЇЃЌвЛАуашвЊЪ§ОнТњзуе§ЬЌадЁЂЗНВюЦыадЁЃгыВЮЪ§МьбщЯрЖдЕФЪЧЗЧВЮЪ§МьбщЃЌЗЧВЮЪ§МьбщВЛЖдзмЬхЕФЗжВМаЮЬЌзіМйЖЈЃЌЫљвдЕБЪ§ОнВЛе§ЬЌЛђЗНВюВЛЦыЪБЃЌПЩЪЙгУЗЧВЮЪ§МьбщНјааВювьадбаОПЁЃ
5ЁЂtМьбщ
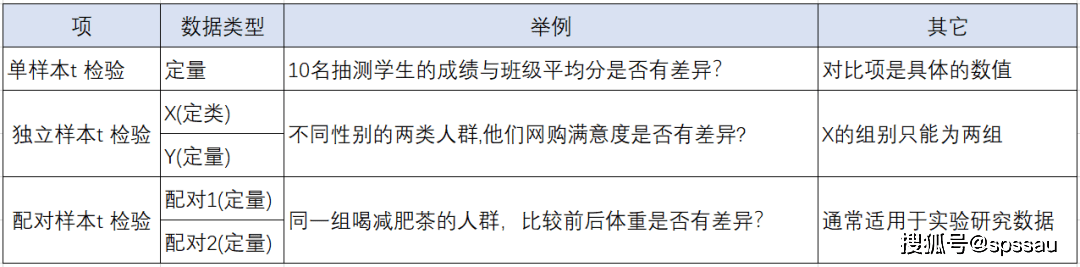
tМьбщЃЌгУгкЗжЮіЖЈРрЪ§ОнгыЖЈСПЪ§ОнжЎМфЕФВювьЧщПіЃЌАДеебаОПФкШнКЭЪ§ОнРраЭЕШВЛЭЌЃЌПЩЗжЮЊвдЯТМИРрЃК
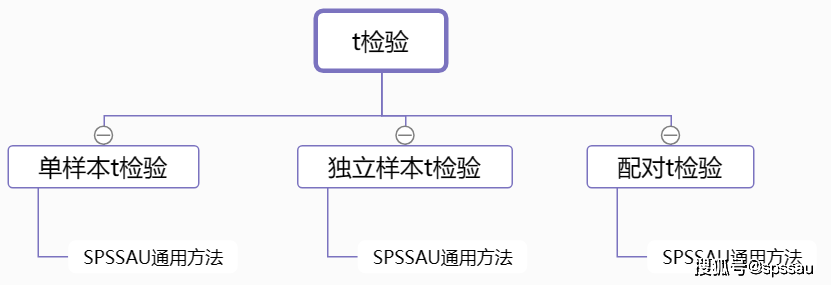
ЁЄ ЕЅбљБОtМьбщЃКЖдБШвЛзщЖЈСПЪ§ОнгыФГИіЪ§зжЕФВювьЁЃ
ЁЄ ЖРСЂбљБОtМьбщЃКЖдБШXЖЈРрЪ§ОнгыYЖЈСПЪ§ОнжЎМфЕФВювьЁЃ
ЁЄ ХфЖдtМьбщЃКЖдБШСНзщХфЖдЪ§ОнжЎМфЕФВювьЁЃ
6ЁЂЗНВюЗжЮі
ЗНВюЗжЮігУгкНјааЖЈРрЪ§ОнгыЖЈСПЪ§ОнжЎМфЕФВювьЙиЯЕбаОПЃЛАДеебаОПФкШнКЭЪ§ОнРраЭЕШВЛЭЌЃЌПЩЗжЮЊвдЯТМИРрЃК

ЁЄ ЕЅвђЫиЗНВюЗжЮіЃКШчЙћXЮЊвЛИіЃЌдђЪЙгУЕЅвђЫиЗНВюЗжЮіЁЃ
ЁЄ ЫЋвђЫиЗНВюЗжЮіЃКЕБXИіЪ§ЮЊ2ИіЃЌдђЪЙгУЫЋвђЫиЗНВюЗжЮіЁЃ
ЁЄ ЖрвђЫиЗНВюЗжЮіЃКЕБXИіЪ§ГЌЙ§2ИіЃЌЪЙгУЖрвђЫиЗНВюЗжЮіЁЃ
ЁЄ ЪТКѓЖржиБШНЯЃКЪЧЛљгкЗНВюЗжЮіЛљДЁЩЯНјааЃЌШчЙћXЕФзщБ№ГЌЙ§СНзщЃЌПЩгУЪТКѓЖржиБШНЯНјвЛВНЗжЮіСНСНзщБ№жЎМфЕФВювьЁЃ
ЁЄ аЗНВюЗжЮіЃКШчЙћбаОПжагаИЩШХвђЫиЃЈПижЦБфСПЃЉЃЌПЩЪЙгУаЗНВюЗжЮіЁЃ
ЁЄ жиИДВтСПЗНВюЗжЮіЃКЯрЙиСьгђЃЈБШШчвНбЇбаОПЪБЃЉГЃГЃашвЊЖдЭЌвЛЙлВьЕЅЮЛжиИДНјааЖрДЮВтСПЃЌДЫЪБЪЙгУжиИДВтСПЗНВюЗжЮіЁЃ
7ЁЂПЈЗНМьбщ
ПЈЗНМьбщЃЌгУгкЗжЮіЖЈРрЪ§ОнгыЖЈРрЪ§ОнжЎМфЕФВювьЧщПіЃЌАДеебаОПФкШнКЭЪ§ОнРраЭЕШВЛЭЌЃЌПЩЗжЮЊвдЯТМИРрЃК
ЁЄ ПЈЗНМьбщЃКЖЈРрЪ§ОнгыЖЈРрЪ§ОнжЎМфЕФВювьЧщПіЁЃ
ЁЄ ХфЖдПЈЗНЃКСНзщХфЖдЖЈРрЪ§ОнжЎМфЕФВювьЧщПіЁЃ
ЁЄ ПЈЗНФтКЯгХЖШЃКбаОПРрБ№ЖЈРрЪ§ОнЕФЪЕМЪБШР§гыдЄЦкБШР§ЪЧЗёвЛжТЁЃ
ЁЄ ЗжВуПЈЗНЃКЗжВуПЈЗНЪЧдкПЈЗНМьбщЛљДЁЩЯЃЌНјвЛВНПМТЧЗжВуЯюЕФИЩШХЁЃ
ЁЄ FisherПЈЗНЃКдкЗжЮібљБОСПНЯЩйЃЈБШШчаЁгк40ЃЉЃЌвВЛђепЦкЭћЦЕЪ§ГіЯжаЁгк5ЪБЃЌЪЙгУfisherПЈЗНМьбщНЯЮЊЪЪКЯЁЃ
8ЁЂЗЧВЮЪ§Мьбщ
ЗЧВЮЪ§МьбщгУгкбаОПЖЈРрЪ§ОнгыЖЈСПЪ§ОнжЎМфЕФЙиЯЕЧщПіЁЃШчЙћЪ§ОнВЛТњзуе§ЬЌадЛђЗНВюВЛЦыЃЌПЩгУЗЧВЮЪ§МьбщЁЃ

ЁЄ ЕЅбљБОWilcoxonМьбщЃКЪЧЕБЪ§ОнВЛЗўДге§ЬЌЗжВМЪБЃЌПЩМьбщЪ§ОнЪЧЗёгыФГЪ§зжЪЧЗёгаУїЯдЕФЧјБ№ЁЃ
ЁЄ MannWhitneyЃКЖдгкВЛЗўДге§ЬЌЗжВМЕФБфСПНјааВювьадЗжЮіЃЌШчЙћXЕФзщБ№ЮЊСНзщЃЌдђЪЙгУMannWhitneyЭГМЦСПЁЃ
ЁЄ Kruskal-WallisЃКШчЙћзщБ№ГЌЙ§СНзщЃЌдђгІИУЪЙгУKruskal-WallisЭГМЦСПЁЃ
ЁЄ ХфЖдбљБОWilcoxonМьбщЃКШчЙћЪЧХфЖдЪ§ОнЃЌдђЪЙгУХфЖдбљБОWilcoxonМьбщЁЃ
ЁЄ ЖрбљБОFriedmanМьбщ/Cochran's Q МьбщЃКЖдгкЖрИіЙиСЊбљБОЕФВювьЧщПіЁЃ
ЁЄ RiditЗжЮіЃКШчЙћЪЧбаОПЖЈРрЪ§ОнгыЖЈСПЃЈЕШМЖЃЉЪ§ОнжЎМфЕФВювьадЃЌЛЙПЩвдЪЙгУRiditЗжЮіЁЃ
9ЁЂЯрЙиЗжЮібаОП
ЯрЙиЗжЮіПЩЗжЮЊМђЕЅЯрЙиЗжЮіЁЂЦЋЯрЙиЗжЮіЁЂЕфаЭЯрЙиЗжЮіШ§РрЁЃ
ЁЄ ЯрЙиЗжЮіЃКМђЕЅЯрЙиЗжЮіЪЧЗжЮіЖдСНИіБфСПжЎМфЕФЯрЙиЙиЯЕЁЃ
ЁЄ ЦЋЯрЙиЗжЮіЃКЕБСНИіБфСПЖМгыЕкШ§ИіБфСПЯрЙиЪБЃЌЮЊСЫЯћГ§ЕкШ§ИіБфСПЕФгАЯьЃЌжЛЙизЂетСНИіБфСПжЎМфЕФЙиЯЕЧщПіЃЌДЫЪБПЩЪЙгУЦЋЯрЙиЗжЮіЁЃ
ЁЄ ЕфаЭЯрЙиЗжЮіЃКбаОПСНзщБфСПЃЈЖрИіжИБъзщГЩЃЉжЎМфЕФећЬхЯрЙиадЃЌПЩгУЕфаЭЯрЙиЗжЮіЁЃ
10ЁЂЯпадЛиЙщбаОП
YЮЊЖЈСПЪ§ОнЪБЃЌПЩвдЪЙгУЯпадЛиЙщбаОПXЖдYЕФгАЯьЁЃГЃгУЕФЯпадЛиЙщЗНЗЈгавдЯТМИжжЃК

ЁЄ ЯпадЛиЙщЃКбаОПXЖдYЃЈЖЈСПЪ§ОнЃЉЕФгАЯьЙиЯЕЧщПіЁЃ
ЁЄ ж№ВНЛиЙщЃКШчЙћXКмЖрЪБЃЌПЩЪЙгУж№ВНЛиЙщздЖЏевГігагАЯьЕФXЁЃ
ЁЄ СыЛиЙщЃКгУгкНтОіЯпадЛиЙщжаздБфСПЙВЯпадЕФбаОПЫуЗЈЁЃ
ЁЄ ЗжВуЛиЙщЃКШчЙћашвЊбаОПЖрИіЯпадЛиЙщЕФВуЕўБфЛЏЧщПіЃЌДЫЪБПЩЪЙгУЗжВуЛиЙщЁЃ
ЁЄ RobustЛиЙщЃКШчЙћЪ§ОнжагавьГЃжЕЃЌПЩЪЙгУRobustЛиЙщНјаабаОПЁЃ
11ЁЂlogisticЛиЙщбаОП
YЮЊЖЈРрЪ§ОнЪБЃЌПЩвдЪЙгУlogisticЛиЙщбаОПXЖдYЕФгАЯьЁЃ
ЁЄ ЖўдЊlogitЛиЙщЃКYЮЊЖЈРрЪ§ОнЧвжЛгаСНРр
ЁЄ ЖрЗжРрlogitЃКYЮЊЖЈРрЪ§ОнЧвДѓгк2Рр
ЁЄ гаађlogitЃКYЮЊЖЈРрЪ§ОнЧвгаађ
12ЁЂЖрбЁЬтбаОП
ЖрбЁЬтЗжЮіПЩЗжЮЊЫФжжРраЭАќРЈЃКЖрбЁЬтЁЂЕЅбЁ-ЖрбЁЁЂЖрбЁ-ЕЅбЁЁЂЖрбЁ-ЖрбЁЁЃ
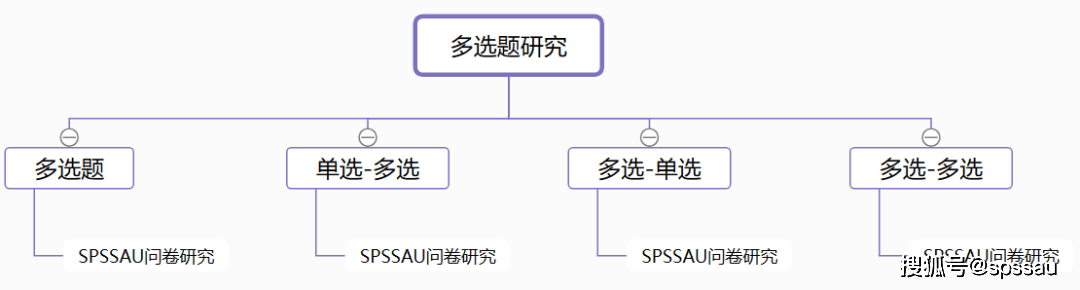
ЁЄ ЖрбЁЬтЗжЮіЃКЪЧеыЖдЕЅИіЖрбЁЬтЕФЗжЮіЗНЗЈЃЌПЩЗжЮіЖрбЁЬтИїЯюЕФбЁдёБШР§ЧщПіЁЃ
ЁЄ ЕЅбЁ-ЖрбЁЃКЪЧеыЖдXЮЊЕЅбЁЃЌYЮЊЖрбЁЕФЧщПіЪЙгУЕФЗНЁЃ
ЁЄ ЖрбЁ-ЕЅбЁЃКЪЧеыЖдXЮЊЖрбЁЃЌYЮЊЕЅбЁЕФЧщПіЪЙгУЕФЗНЗЈЁЃ
ЁЄ ЖрбЁ-ЖрбЁЃКЪЧеыЖдXЮЊЖрбЁЃЌYЮЊЖрбЁЕФЧщПіЪЙгУЕФЗНЗЈЁЃ
13ЁЂОлРрЗжЮіЗНЗЈ
ОлРрЗжЮівдЖрИібаОПБъЬтзїЮЊЛљзМЃЌЖдбљБОЖдЯѓНјааЗжРрЁЃ
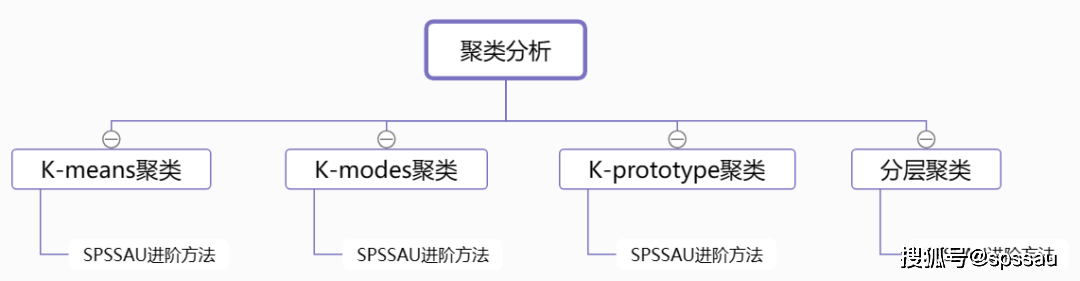
ЁЄ K-meansОлРрЃКжЛФмДІРэЪ§жЕаЭЪ§ОнЁЃ
ЁЄ K-modesОлРрЃКЖдЗжРрЪєадЪ§ОнНјааОлРрЕФЗНЗЈЁЃ
ЁЄ K-prototypeОлРрЃКДІРэЛьКЯЪєадЪ§ОнЕФЗНЗЈЁЃ
ЁЄ ЗжВуОлРрЃКЖдИјЖЈЪ§ОнЖдЯѓЕФМЏКЯНјааВуДЮЗжНтЃЌИљОнЗжВуЗжНтВЩгУЕФЗжНтВпТдЃЌНіеыЖдЖЈСПЪ§ОнНјааЗжВуОлРрЁЃ
14ЁЂаХЯЂХЈЫѕЗНЗЈ
ЕБбаОПжаАќРЈгаКмЖрЬтФПЛђКмЖрБфСПЪБЃЌПЩЭЈЙ§аХЯЂХЈЫѕЕФЗНЗЈЃЌАбЪ§ОнХЈЫѕГЩвЛИіЛђЖрИіБфСПЃЌвдБугУгкКѓајЕФЗжЮіЁЃ
ЁЄ жїГЩЗжЗжЮіКЭвђзгЗжЮіЃКЖМЪЧаХЯЂХЈЫѕЕФЗНЗЈЃЌМДНЋЖрИіЗжЮіЯюаХЯЂХЈЫѕГЩМИИіИХРЈаджИБъЁЃШчЙћЯЃЭћНјааНЋжИБъУќУћЃЌSPSSAUНЈвщЪЙгУвђзгЗжЮіЁЃдвђдкгквђзгЗжЮідкжїГЩЗжЛљДЁЩЯЃЌЖрГівЛЯюа§зЊЙІФмЃЌИУа§зЊФПЕФМДдкгкУќУћЁЃ
ЁЄ ЦНОљжЕКЭЧѓКЭЃКвВЪЧаХЯЂХЈЫѕЕФГЃгУЗНЗЈЃЌБШШчвЊНЋЖрИіЬтЯюКЯВЂГЩвЛИіБфСПЃЌПЩЭЈЙ§ЧѓЦНОљжЕИХРЈГЩвЛИіЬтЯюЁЃ
ЁЄ жаЮЛЪ§ЃКЕБЪ§ОнВЛТњзуе§ЬЌЃЌДцдкМЋЖЫжЕЪБЃЌПЩгУжаЮЛЪ§ДњЬцЦНОљжЕЁЃ
15ЁЂвЛжТадбаОПЗНЗЈ
вЛжТадМьбщЕФФПЕФдкгкБШНЯВЛЭЌЗНЗЈЕУЕНЕФНсЙћЪЧЗёОпгавЛжТадЁЃМьбщвЛжТадЕФЗНЗЈгаКмЖрБШШчЃКKappaМьбщЁЂICCзщФкЯрЙиЯЕЪ§ЁЂKendall WаЕїЯЕЪ§ЕШЁЃ
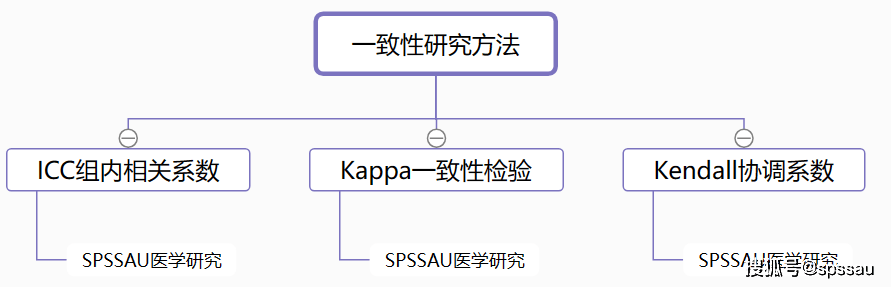
ЁЄ ICCзщФкЯрЙиЯЕЪ§ЃКгУгкЗжЮіЖрДЮЪ§ОнЕФвЛжТадЧщПіЃЌЗжЮіЖЈСПЛђЖЈРрЪ§ОнОљПЩЁЃ
ЁЄ KappaвЛжТадМьбщЃКЪЪгУгкСНДЮЗНЗЈжЎМфБШНЯвЛжТадЃЌЭЈГЃвЊЧѓЪ§ОнЮЊЖЈРрЪ§ОнЁЃ
ЁЄ KendallаЕїЯЕЪ§ЃКЗжЮіЖрИіЪ§ОнжЎМфЙиСЊадЕФЗНЗЈЃЌЪЪгУгкЖЈСПЪ§ОнЃЌгШЦфЪЧЖЈађЕШМЖЪ§ОнЁЃ
16ЁЂШЈжибаОП
ШЈжибаОПЪЧгУгкЗжЮіИївђЫиЛђжИБъдкзлКЯЬхЯЕжаЕФживЊГЬЖШЃЌзюжеЙЙНЈГіШЈжиЬхЯЕЁЃШЈжибаОПгаЖржжЗНЗЈЃК

ЁЄ AHPВуДЮЗжЮіЗЈЃКЪЧвЛжжжїЙлМгПЭЙлИГжЕЕФМЦЫуШЈжиЕФЗНЗЈЁЃЯШЭЈЙ§зЈМвДђЗжЙЙдьХаЖЯОиеѓЃЌШЛКѓСПЛЏМЦЫуУПИіжИБъЕФШЈжиЁЃ
ЁЄ ьижЕЗЈЃКЪЧРћгУьижЕаЏДјЕФаХЯЂМЦЫуУПИіжИБъЕФШЈжиЃЌЭЈГЃПЩХфКЯвђзгЗжЮіЛђжїГЩЗжЗжЮіЕУЕНвЛМЖШЈжиЃЌРћгУьижЕЗЈМЦЫуЖўМЖШЈжиЁЃ
ЁЄ TOPSISЗЈЃКЪЧвЛжжЦРМлЖрИібљБОзлКЯХХУћЕФЗНЗЈЃЌгУгкБШНЯбљБОЕФХХУћЧщПіЁЃ
ЁЄ вђзгЗжЮіЃКПЩНЋЖрИіЬтЯюХЈЫѕГЩМИИіИХРЈаджИБъЃЈвђзгЃЉЃЌШЛКѓЖдаТЩњГЩЕФИїИХРЈаджИБъМЦЫуШЈжиЁЃ
ЁЄ жїГЩЗжЗжЮіЃКРћгУЗНВюНтЪЭТЪжЕМЦЫуИїИХРЈаджИБъЕФШЈжиЁЃ
ЁЄ ЦфЫћЃКьиШЈtopsisЗЈЁЂгХађЭМЗЈЁЂCRITICШЈжиЁЂЖРСЂадШЈжиЁЂаХЯЂСПШЈжиЕШЁЃ
17ЁЂФЃаЭбаОПЗНЗЈ
ЕБашвЊбаОПЖрИіБфСПжЎМфЕФЙиЯЕЧщПіЪБЃЌЭЈГЃПЩЙЙНЈЭГМЦФЃаЭгУгкЗжЮіМАдЄВтЁЃ

ЁЄ ЯпадЛиЙщЃКЕБбаОПXЖдYЕФгАЯьЙиЯЕЃЌЦфжаYЮЊЖЈСПЪ§ОнЃЌПЩЪЙгУЯпадЛиЙщЗжЮіЁЃ
ЁЄ logisticЛиЙщЃКбаОПXЖдYЕФгАЯьЙиЯЕЃЌЦфжаYЮЊЖЈРрЪ§ОнЃЌПЩЪЙгУLogisticЗжЮіЁЃ
ЁЄ ЕфаЭЯрЙиЃКбаОП1зщXгывЛзщYжЎМфЕФЙиЯЕЧщПіЃЌПЩЪЙгУЕфаЭЯрЙиЗжЮіЁЃ
ЁЄ PLSЛиЙщЃКбаОПЖрИіXгыЖрИіYжЎМфЕФгАЯьЙиЯЕЧщПіЃЌЧвбљБОСПНЯаЁЃЈЭЈГЃаЁгк200ЃЉЃЌПЩЪЙгУPLSЛиЙщЗжЮіЁЃ
ЁЄ ТЗОЖЗжЮіЃКШчашЗжЮіЖрИіXЖдЖрИіYЕФгАЯьЙиЯЕЃЌвдМАОпЬхФФаЉXЖдФФаЉYгагАЯьЁЂШчКЮгАЯьЃЌПЩЪЙгУТЗОЖЗжЮіЁЃ
ЁЄ НсЙЙЗНГЬФЃаЭЃКашвЊЭЌЪБбаОПВтСПЙиЯЕКЭгАЯьЙиЯЕЃЌПЩЪЙгУНсЙЙЗНГЬФЃаЭЁЃ
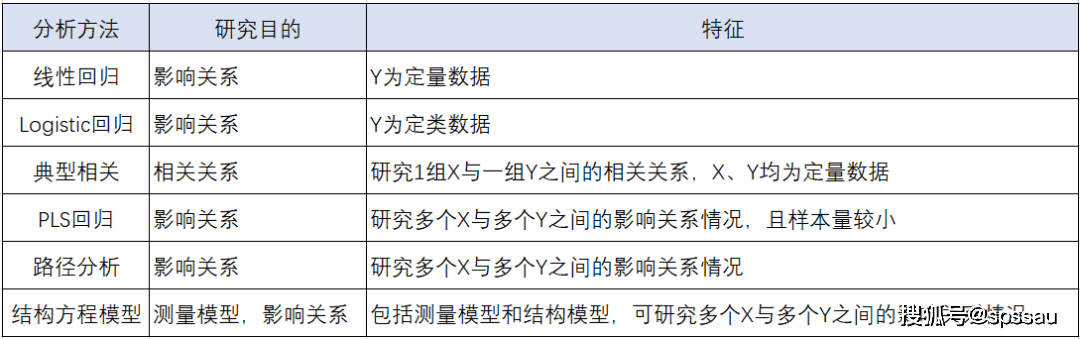
18ЁЂЪ§ОнЗжВМбаОП
ХаЖЯЪ§ОнЗжВМЪЧбЁдёе§ШЗЗжЮіЗНЗЈЕФживЊЧАЬсЁЃ
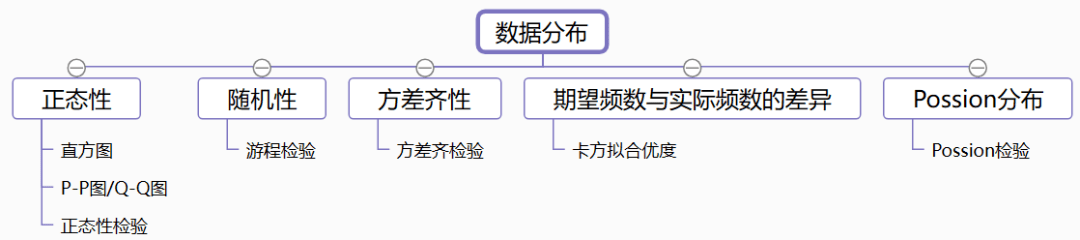
ЁЄ е§ЬЌадЃККмЖрЗжЮіЗНЗЈЕФЪЙгУЧАЬсЖМЪЧвЊЧѓЪ§ОнЗўДге§ЬЌадЃЌБШШчЯпадЛиЙщЗжЮіЁЂЯрЙиЗжЮіЁЂЗНВюЗжЮіЕШЃЌПЩЭЈЙ§жБЗНЭМЁЂP-P/Q-QЭМЁЂе§ЬЌадМьбщВщПДЪ§Оне§ЬЌадЁЃ
ЁЄ ЫцЛњадЃКГщбљЕїВщгавЛИізюЛљБОЕФЧАЬсМйЩшЃЌОЭЪЧГщбљБиаыТњзуЁАЫцЛњадвЊЧѓЁБЃЌгЮГЬМьбщЪЧвЛжжЗЧВЮЪ§адЭГМЦМйЩшЕФМьбщЗНЗЈЃЌПЩгУгкЗжЮіЪ§ОнЪЧЗёЮЊЫцЛњЁЃ
ЁЄ ЗНВюЦыадЃКЗНВюЦыМьбщгУгкЗжЮіВЛЭЌЖЈРрЪ§ОнзщБ№ЖдЖЈСПЪ§ОнЪБЕФВЈЖЏЧщПіЪЧЗёвЛжТЃЌМДЗНВюЦыадЁЃЗНВюЦыЪЧЗНВюЗжЮіЕФЧАЬсЃЌШчЙћВЛТњзудђВЛФмЪЙгУЗНВюЗжЮіЁЃ
ЁЄ ПЈЗНФтКЯгХЖШМьбщЃКПЈЗНФтКЯгХЖШМьбщЪЧвЛжжЗЧВЮЪ§МьбщЗНЗЈЃЌЦфгУгкбаОПЪЕМЪБШР§ЧщПіЃЌЪЧЗёгыдЄЦкБШР§БэЯжвЛжТЃЌЕЋжЛеыЖдгкРрБ№Ъ§ОнЁЃ
ЁЄ PoissonЗжВМЃКШчЙћвЊХаЖЯЪ§ОнЪЧЗёТњзуPoissonЗжВМЃЌПЩЭЈЙ§PoissonМьбщХаЖЯЛђепЭЈЙ§ЬиеїНјааХаЖЯЪЧЗёЛљБОЗћКЯPoissonЗжВМЃЈШ§ИіЬиеїМДЃКЦНЮШадЁЂЖРСЂадКЭЦеЭЈадЃЉ
19ЁЂЛњЦїбЇЯА
SPSSAUФПЧАЛњЦїбЇЯАФЃПщгавдЯТ6РрЗНЗЈЁЃ

ЁЄ ОіВпЪїЃКГЃгУгкбаОПРрБ№ЙщЪєКЭдЄВтЙиЯЕЕФФЃаЭЁЃ
ЁЄ ЫцЛњЩСжЃКЪЕжЪЩЯЪЧЖрИіОіВпЪїФЃаЭЕФзлКЯЃЌОіВпЪїФЃаЭжЛЙЙНЈвЛПУЗжРрЪїЃЌЕЋЪЧЫцЛњЩСжФЃаЭЙЙНЈЗЧГЃЖрПУОіВпЪїЁЃ
ЁЄ KNNЃКЪЧвЛжжМђЕЅвзЖЎЕФЛњЦїбЇЯАЫуЗЈЃЌЦфдРэЪЧевГіАЄзХздМКзюНќЕФKИіСкОгЃЌВЂЧвИљОнСкОгЕФРрБ№РДШЗЖЈздМКЕФРрБ№ЧщПіЁЃ
ЁЄ ЦгЫиБДвЖЫЙЃКЪЧЛљгкБДвЖЫЙЖЈСПЃЌВЂЧвМгЩЯЬѕМўЃЈЬиеїжЎМфЖРСЂЃЉЕФвЛжжФЃаЭЁЃ
ЁЄ жЇГжЯђСПЛњЃКЪЧвЛжжЖўЗжРрФЃаЭЁЃ
ЁЄ ЩёОЭјТчЃКЪЧвЛжжФЃФтШЫФдЩёОЫМЮЌЗНЪНЕФЪ§ОнФЃаЭЁЃ
20ЁЂПЩЪгЛЏЗжЮіЗНЗЈ
ГЃгУЕФПЩЪгЛЏЗжЮіЗНЗЈШчЯТЃК
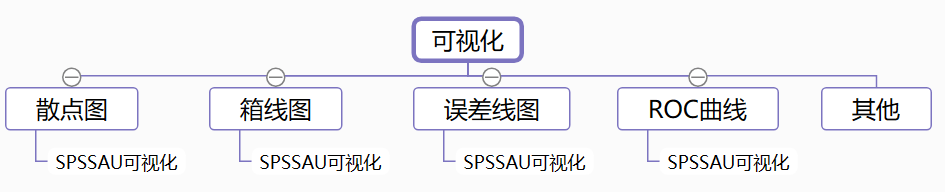
ЁЄ ЩЂЕуЭМЃКгУгкПМВьЖЈСПЪ§ОнжЎМфЕФЙиЯЕЧщПіЁЃ
ЁЄ ЯфЯпЭМЃКжБЙлЕиЪЖБ№Ъ§ОнжаЕФвьГЃжЕЁЂХаЖЯЪ§ОнРыЩЂЗжВМЧщПіЁЃ
ЁЄ ЮѓВюЯпЭМЃКгУгкеЙЪОЪ§ОнЕФВЛШЗЖЈадГЬЖШЃЌЯдЪОЧБдкЕФЮѓВюЛђУПИіЪ§ОнБъжОЕФВЛШЗЖЈГЬЖШЁЃ
ЁЄ ROCЧњЯпЃКгУгкбаОПXЖдYЕФдЄВтзМШЗТЪЧщПіЁЃ
ЁЄ ЦфЫћЃКP-PЭМ/Q-QЭМЁЂжБЗНЭМЁЂЯѓЯоЭМЁЂХСРлЭаЭМЁЂДизДЭМЁЂЦјХнЭМЁЂКЫУмЖШЭМЁЂаЁЬсЧйЭМЕШЁЃ