过去一年间,能说会道的 ChatGPT、最新的 GPT-4 大模型,其能力也已超乎很多人的想象,一场由 OpenAI 引领推动的 AIGC 浪潮席卷全球各大科技公司。但是从学术研究的角度来看,其表现力距离人类智能究竟还有多远?
近日,一篇由加州大学圣迭戈分校的两位研究人员 Cameron Jones(认知科学专业博士生)和 Benjamin Bergen(该校认知科学系教授)发布的《GPT-4 通过图灵测试了吗?》(https://arxiv.org/pdf/2310.20216.pdf)论文,吸引了不少 AI 学者的关注。

出乎意料的是,根据论文结果显示:
在更具人性方面,人类赢了,不过 OpenAI 的模型还是能够骗过很多人类;
GPT-4 不符合图灵测试的成功标准;
ChatGPT 免费版所使用的 GPT-3.5 模型败给了 60 年前发布的老 AI 聊天机器人 ELIZA;
首发于 1966 且由约瑟夫・维森鲍姆在麻省理工学院研发的聊天机器人 ELIZA 之所以得分比 GPT-3.5 高,不是因为它聪明,而是因为它太不聪明,导致很多问题无法直接给出答案,这让人觉得它太过高冷,像是人类扮演的。
一石激起千层浪,有人认为,这并不奇怪,因为 OpenAI 担心会有欺骗,GPT-4 被明确调整为不通过图灵测试。
也有人表示,“图灵测试实际上是一种超窄的方法。图灵令人难以置信的优点是毋庸置疑的。但图灵测试范式对于几十年来人工智能的项目和发展来说绝对是致命的。”

还有更多的人认为,尽管存在一些限制和警告,不过这篇论文对人工智能模型之间进行了深度的比较,并对使用图灵测试评估人工智能模型性能提出了更多问题,同样值得思考。
比较人类和机器的智能水平,引发争议的图灵测试
所谓图灵测试,是由英国数学家和计算机科学家艾伦・图灵(Alan Turing)于 1950 年提出的一个测试概念,用于评估机器是否具有人类智能。这个测试的核心思想是,一个人类评判者通过对话形式,与一个机器和一个人类进行交互,然后在不知道对话对象的真实身份前提下,判断哪个是机器,哪个是人类。
具体来说,图灵测试的步骤如下:
1. 一个评判者(通常是人类)在与两个对话对象进行文本交流时,其中一个是机器,另一个是人类。这个交流可以通过键盘和在屏幕输入进行,以确保评判者无法通过声音或外观来判断对话对象的身份。
2. 评判者的目标是在与两个对象交流后,准确地区分出哪个是机器,哪个是人类。
3. 如果机器成功地使评判者无法区分其回答与人类的回答,那么这台机器被认为通过了图灵测试,表现出具有人类智能的迹象。
值得注意的是,图灵测试并没有明确规定机器需要模仿人类的所有方面,而是强调机器是否能够在对话中表现出类似于人类思维和智能的特征。图灵测试成为人工智能领域中一个重要的思想实验,用于探讨和评估机器智能的发展。
研究人员希望利用图灵测试来了解聊天机器人的人性化特征。不过一直以来,因为主观性和相对性、缺乏客观标准等因素,图灵测试就成了确定机器模仿人类对话能力的一个著名但有争议的基准。
测试方法
在这篇论文中,两位研究人员安排了两种角色:
一种是调查员,他们需要查明自己是人工智能还是人类聊天;
另一种是见证人,他们需要让对方相信自己的人性。当然见证人里面有真的人类,也有 25 名 LLM 见证人。为了让测试更为准确,每个 LLM 由一个模型(GPT-3.5、GPT-4、ELIZA)、一个温度设置(0.2、0.5 或 1.0)和一个提示组成。提示描述了交互的上下文和对模型的回复指导,如下图所示:

研究人员变化了提示的几个方面, 包括模型是否应产生拼写、语法和大小写错误;模型应该采用的人格;模型被告知其是人类还是假装是人类的 AI。所有提示都包含关于游戏说明的通用信息,以及它们的训练结束日期之后发生的重要事件。在每场游戏开始时,会从一个列表中为模型的人格生成一个建议名称。提示还包括游戏创建的时间戳和最新消息的时间戳。
值得一提的是,这项研究获得了加州大学圣地亚哥分校 IRB 的批准,所以研究人员 Cameron Jones(认知科学专业博士生)和 Benjamin Bergen(该校认知科学系教授)建立了一个名为 turingtest.live 的网站,此网站提供一个看起来像一个传统的消息应用程序的聊天界面。
然后,参与者进入等待室,在那里他们会被随机分配与另一个人类或 AI 进行游戏。调查员发送第一条消息,每个用户一次只能发送一条消息。整个对话有 5 分钟的时间限制,单个消息有 300 个字符的限制。

在双方聊天过程中,调查员最常用的策略包括闲聊以及询问相关知识和时事。
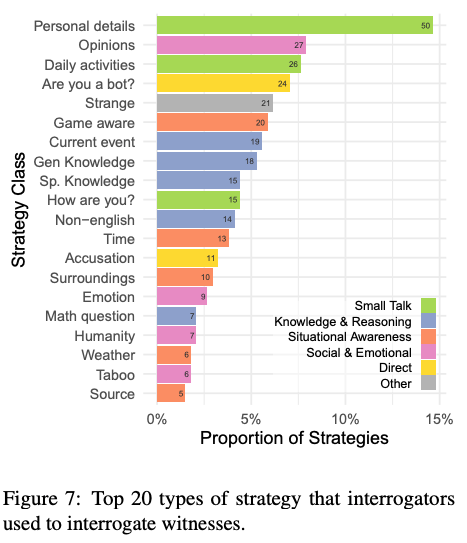
更成功的策略包括使用非英语语言、询问时间或时事,以及直接指控见证人是人工智能模型。
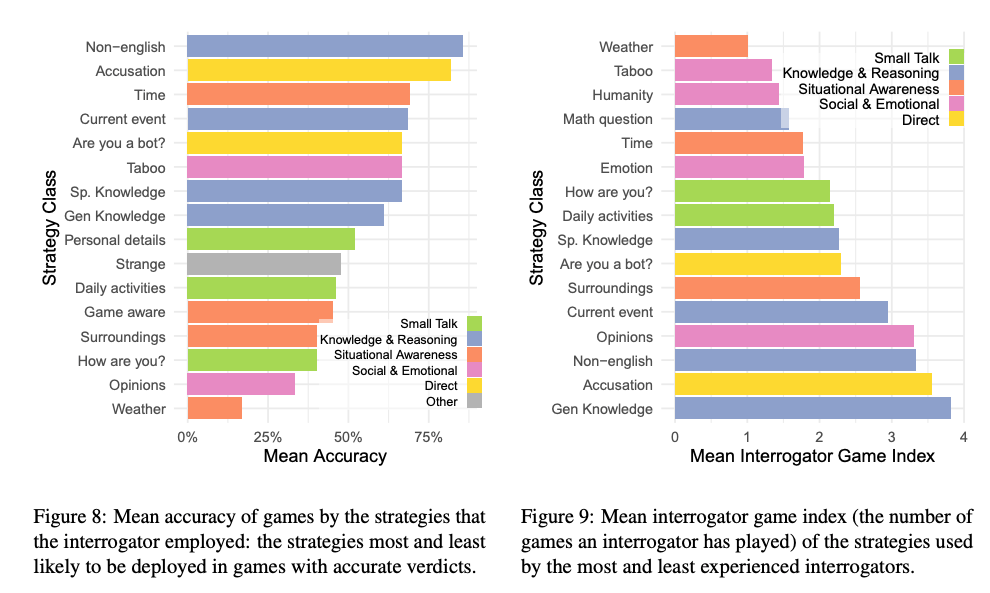
然后,调查员根据收到的答复做出判断。在游戏结束时,调查员使用一个决策界面来提供:
一个决定(见证人是否为人类);
他们对决定的置信度(0-100);
决定的原因(可选填)。
有趣的是,研究发现,调查员的判断主要基于语言风格和社会情感特征,而不仅仅是对智力的感知。调查员还注意到何时回答过于正式或不正式时,或者何时回答缺乏个性或显得一般。研究还表明,调查员个人的教育程度和对大型语言模型(LLMs)的熟悉程度并不能显著预测他们检测人工智能的成功率。

最终结果
实验涉及 652 名参与者,他们共完成了 1810 次游戏,在排除了某些情况后,这些情况包括重复的人工智能游戏(导致在其他人类不在线时预期人工智能模型的互动)、或者参与者和见证人之间的个人熟识、他们有时坐在同一个房间里,研究人员最终对其中的 1405 次游戏进行了分析。
令人惊讶的是,60 年前的老 AI 聊天机器人 ELIZA 在研究中得分相对较高,成功率达到 27%。根据提示,GPT-3.5 的成功率为 14%,低于 ELIZA。GPT-4 的成功率为 41%,仅次于真人。
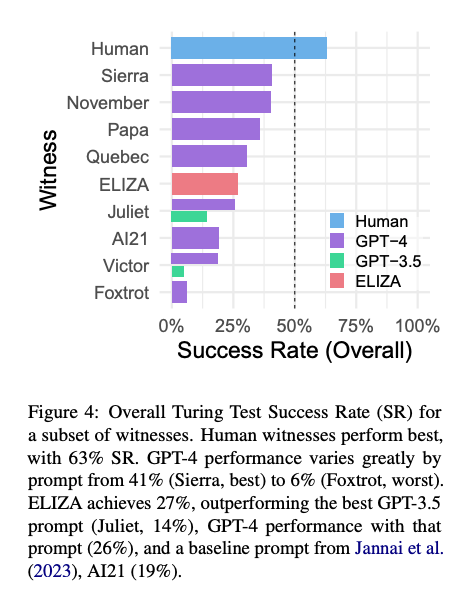
最终,研究员得出结论:GPT-4 不符合图灵测试的成功标准,既没有达到 50% 的成功率(大于 50 或等于 50 的概率),也没有超过人类参与者的成功率。
研究人员推测,如果有正确的提示设计,GPT-4 或类似模型最终可能会通过图灵测试。不过,挑战在于如何模仿人类对话风格的微妙之处来设计提示语。与 GPT-3.5 一样,GPT-4 也被设定为不以人类身份出现。该研究员在论文中写道:“看来很有可能存在更有效的提示,因此我们的结果低估了 GPT-4 在图灵测试中的潜在表现。”
至于那些未能让其他人类相信自己是真实存在的人类,这可能更多反映了测试的性质和结构以及调查员的期望,而不是人类智力的任何特定方面。研究员表示:“一些人类证人假装自己是人工智能,进行'兜售'。”同样,一些调查员也将这种行为作为人类判决的理由。因此,「我们的结果可能低估了人类的表现,而高估了人工智能的表现」,研究员说道。
对于在研究中的 ELIZA 之所以会胜过 GPT-3.5,该论文的作者推断:
首先,ELIZA 的回答倾向于保守。虽然这通常会给人一种对话者不合作的印象,但这也避免了系统提供诸如错误信息或晦涩知识等明确线索。
其次,ELIZA 并没有表现出调查者所认为的 LLM 所具有的那种暗示,例如乐于助人、友好和滔滔不绝。
最后,一些调查者认为,ELIZA "太糟糕",不像是当前的人工智能模型,因此更像是人类故意不合作。
而对于免费版 ChatGPT 的基础模型 GPT-3.5 的失利,有人认为,OpenAI 对其进行了专门的调节,使其不会以人类的形象出现,这可能是其表现不佳的部分原因。
与此同时,普林斯顿大学计算机科学教授 Arvind Narayanan 在 X 上也发表了自己的看法,其表示:
「关于“ChatGPT 未通过图灵测试”论文的重要背景。一如既往,测试行为并不能说明能力。我认为在这项任务中测试 LLM 的一种更丰富的方法是采用一个基本模型并在聊天日志上对其进行微调。
ChatGPT 经过微调,语气正式,不发表意见等,这使得它不太人性化。作者试图用提示来改变这一点,但它有局限性。假装人类聊天的最好办法就是在人类聊天记录上进行微调。」

最后,对于这项测试,该论文的作者也承认这项研究存在局限性,包括从社交媒体招募样本可能存在偏差,以及缺乏对参与者的激励措施,这可能会导致一些人无法完成预期的角色。他们还表示,“他们的研究结果(尤其是 ELIZA 的表现)可能支持了人们对图灵测试的普遍批评,认为它是衡量机器智能的一种不准确的方法。”
尽管如此,「我们认为,作为衡量流畅的社交互动和欺骗行为的框架,以及理解人类适应这些设备的策略,该测试仍具有现实意义」,研究员说道。
对此,更详尽的研究内容可查阅完整论文:https://arxiv.org/abs/2310.20216

















