Sora �����Dz�������������������ģ�ͣ�ͼ�齱���� Yann LeCun��Keras ֮�� Francois Chollet ������������̽�֡�
������죬OpenAI ��������Ƶ����ģ�� Sora ����ȫ�����ע�Ľ��㡣
������ֻ�����ɼ�������Ƶ��ģ�Ͳ�ͬ��Sora ��������Ƶ�ij���һ���������� 60 �롣���ң����������˽��û��� Prompt �������Ҫ���� get ���ˡ��������������еĴ��ڷ�ʽ��
�Ծ���ġ��������ڿ��ȱ��в�����Ϊ����Ϊ��������Ч�����������棬Sora ��Ҫ�˷����¼��������ѵ㣺
��ģ�ͱ�������Ӧ������������С���ܹ��ڿ��ȱ��в����ijߴ磬ͬʱ�������ǵ�ϸ�ںͽṹ����һ����ս��AI ��Ҫ����͵�����Щ��������ʵ�����е���Գߴ磬ʹ�ó������Ӿ����Եú�����
���嶯��ѧ�����ȱ��е�Һ���Ժ��������˶�����Ӱ�졣AI ģ����Ҫģ��Һ�嶯��ѧ��Ч�����������ˡ���ˮ�ʹ�ֻ�ƶ�ʱҺ������������ڼ������Ǹ��ӵģ�
���ߺ���Ӱ�Ĵ�����Ϊ��ʹ������������ʵ��AI ��Ҫ��ȷ��ģ�����������������С�ͳ����У��������ȵķ��⡢��ֻ����Ӱ���Լ����ܵ���Ч����
�������˶�����ʵ�ԣ����������˶���Ҫ������ʵ������������ɣ���ʹ���DZ���С�����ȱ��С�����ζ�� AI ��Ҫ���ǵ���������������ײ�Լ�����ṹ�ڶ�̬�����е���Ϊ��
����

��Ȼ����Ч������Щ覴ã������������Ըо�����Sora �ƺ��Ƕ�һЩ���������ġ�Ӣΰ����о���ѧ�� Jim Fan �������ԣ���Sora ��һ�������������������桹������һ����ѧϰ��ģ������������ģ�͡�����


�����о���ͬ�������Ĺ۵㣬��Ҳ�в����˷��ԡ�
Yann LeCun��������Ƶ�Ĺ������������ģ�͵����Ԥ����ȫ��ͬ
ͼ�齱���� Yann LeCun ���������۵㡣������������������ prompt ���ɱ�����Ƶ�����ܴ���һ��ģ���������������磬������Ƶ�Ĺ������������ģ�͵����Ԥ����ȫ��ͬ��
�����Ž�����ģ�����ɱ�����Ƶ�Ŀռ�dz�����Ƶ����ϵͳֻ��Ҫ����һ��������ʾ������ɹ�����������һ����ʵ��Ƶ���ԣ�������ĺ��������ռ�ȴ�dz�С��������Щ�����Ĵ�����Ƭ�Σ��ر������ض��ж������£������Ѷȸ�����������Ƶ�ĺ������ݲ����ɱ��߰���ʵ����Ҳ�������塣
��ˣ�Yann LeCun ��Ϊ���������������������Ƶ�������ݵij����������������ǿ�������ȡ�����صij����е�ϸ�ڡ�
��Ȼ��������� PR ��һ�� JEPA��Joint Embedding Predictive Architecture������Ƕ��Ԥ��ܹ�������Ϊ���������������ĺ���˼�롣JEPA ��������ʽ�ģ������ڱ�ʾ�ռ��н���Ԥ�⡣���ؽ����ص�����ʽ�ܹ��������Ա��������������Ա�������ȥ���Ա�������ȣ�����Ƕ��ܹ����� Meta ǰ�����Ƴ��� AI ��Ƶģ�� V-JEPA�����Բ�����������Ӿ�������
ͼԴ��https://twitter.com/ylecun/status/1758740106955952191
François Chollet��ֻ�� AI ����Ƶѧ��������ģ��
Keras ֮�� François Chollet ������˸�ϸ�µĹ۵㡣����Ϊ���� Sora ��������Ƶ����ģ��ȷʵǶ���ˡ�����ģ�͡����������ǣ��������ģ���Ƿ�ȷ�����ܷ����µ����������Щ��������ѵ�����ݲ�ֵ�����Σ�
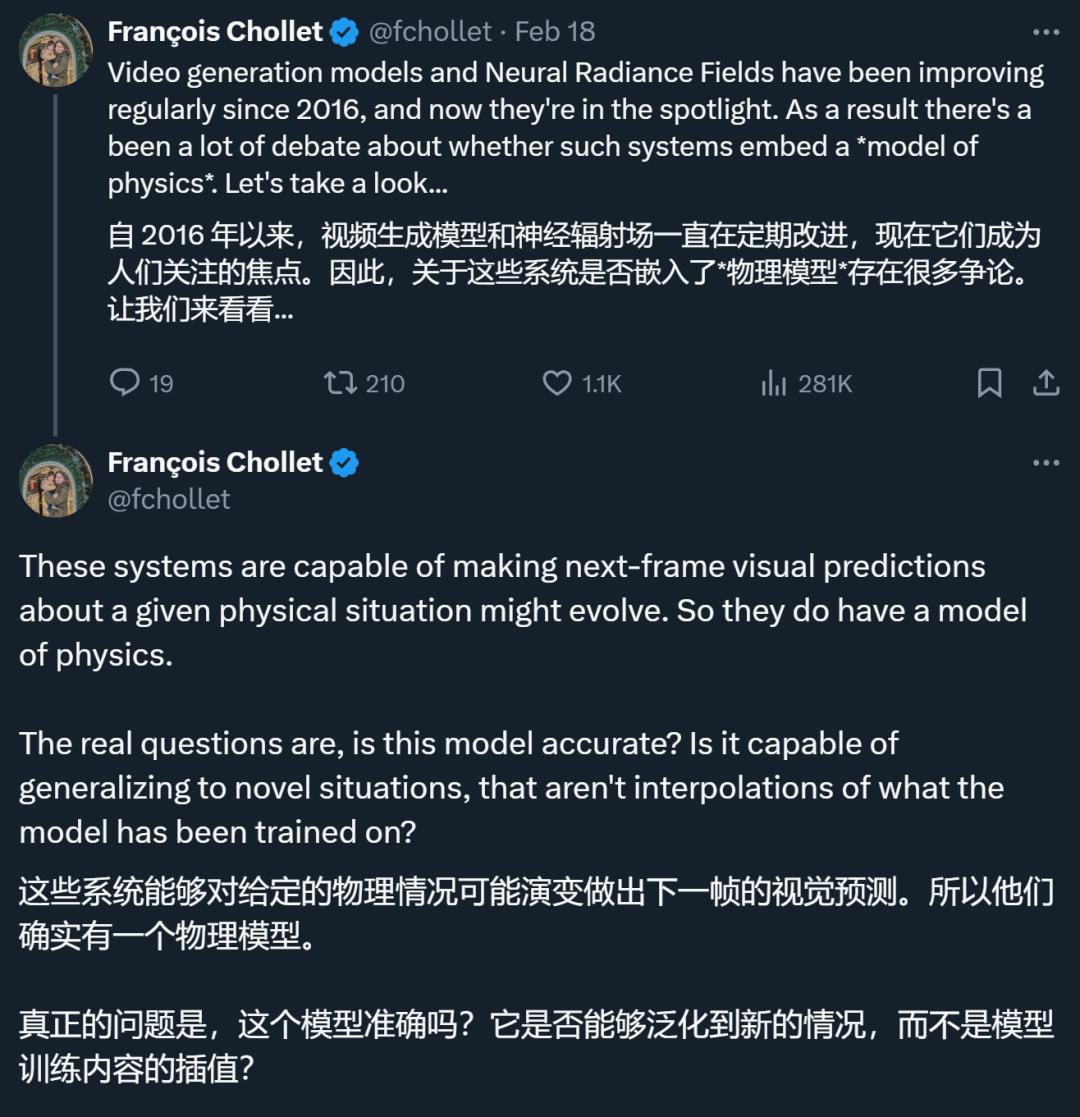
Chollet ǿ������Щ����������Ҫ����Ϊ���Ǿ���������ͼ���Ӧ�÷�Χ ���� �ǽ�����ý�����������ǿ���������ʵ����Ŀɿ�ģ�⡣

Chollet ͨ���������ڿ��ȱ��в��������ӣ�������ģ���ܷ�ȷ��ӳˮ����Ϊ�����������߽����Ǵ�����һ�ֻ���ƴ���������ָ��ģ��Ŀǰ�������ں��ߣ������������ݲ�ֵ��DZ�ռ�ƴ��������ͼ��������ʵ������ģ�⡣���˽�������Ϊ���Ϊ�������Σ���Ϊ Sora ��ʵֻ�Ǵﵽ���������ε�ˮƽ��������������Ȼ���С�

Sora ���ɵ��������Ƶ�������ڻ�����ƾ�ճ��֣����Ҳ�������Ӱ��Ư���ڿ��С�
Chollet ָ����ͨ������ѧϰģ����ϴ������ݵ���γɵĸ�ά���ߣ������ߣ���Ԥ���������緽���Ǵ��ھ��ġ����ض������£�������������ģ���ܹ���Ч����ģ����ʵ�����ijЩ���Ӷ�̬������Ԥ��������ģ��綴ʵ��ȡ������ַ���������ͷ����������ʱ���ھ��ޡ�ģ�͵�Ԥ��������������ѵ�����ݵķ�Χ��������������Щ����ѵ�����ݷֲ����������ģ�Ϳ�����ȷԤ�⡣
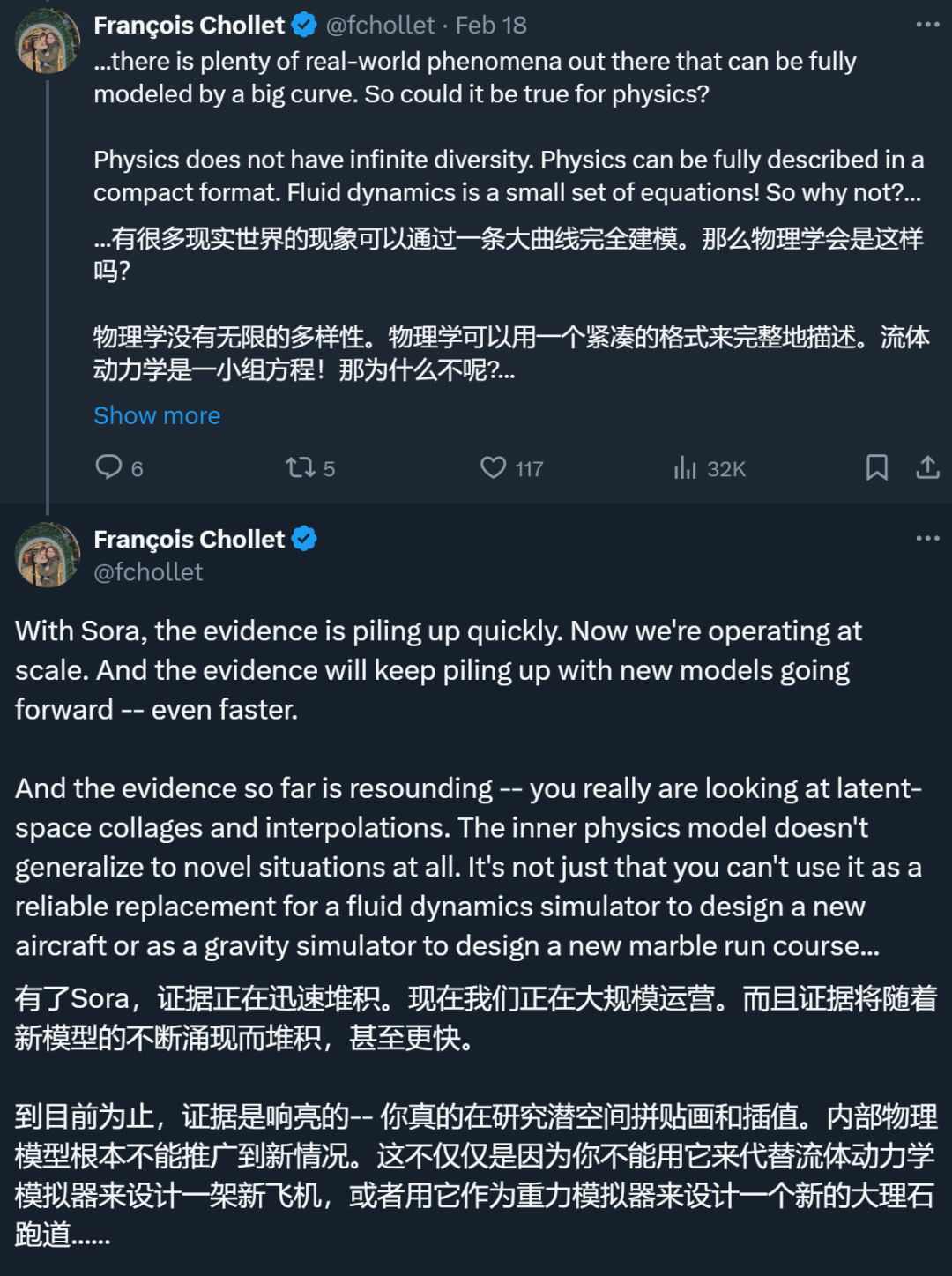
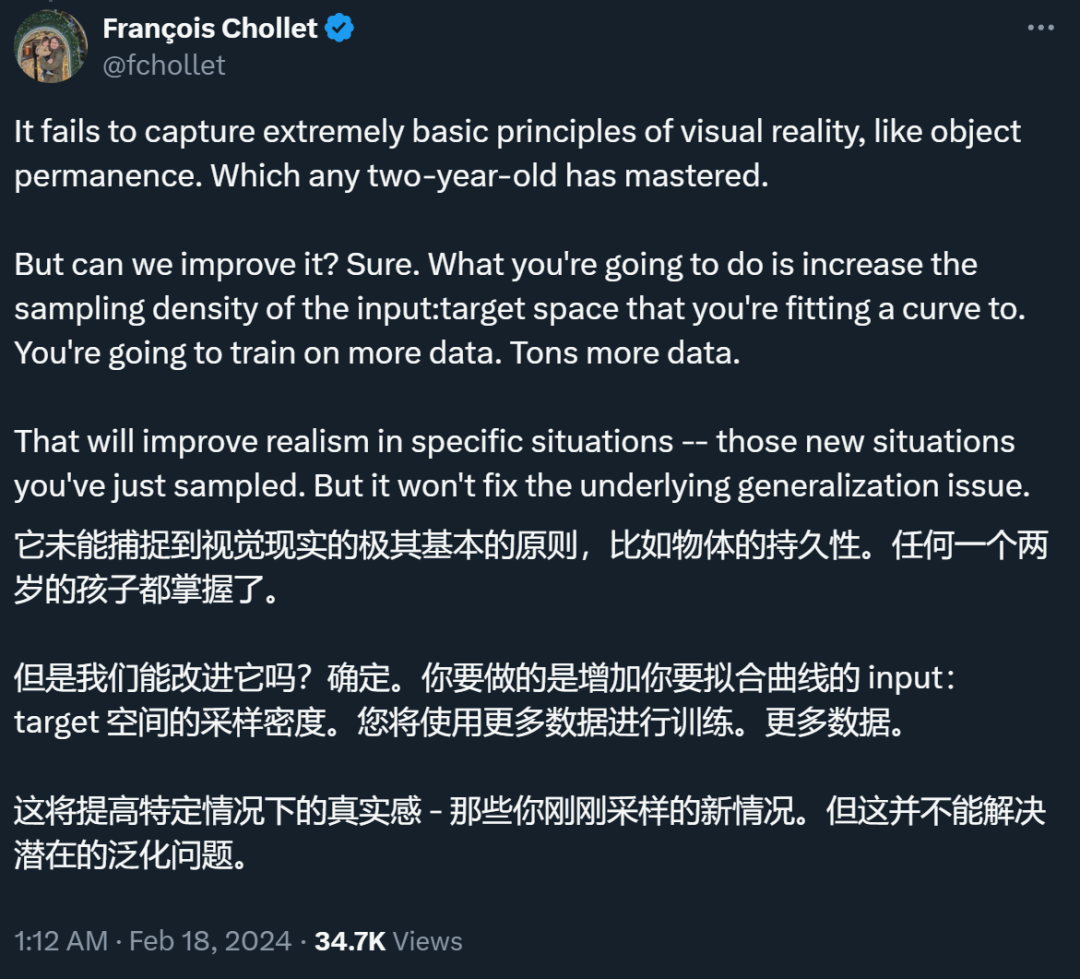
���ԣ�Chollet ��Ϊ�����ܼ�ͨ����ϴ������ݣ�����Ϸ������Ⱦ��ͼ�����Ƶ���������õ�һ���ܹ���������ʵ�������п��������ģ�͡�������Ϊ��ʵ����ĸ����ԺͶ�����Զ�����κ�ģ���ܹ�ͨ����������ѧϰ���ġ�

��Ԩ����ѧϰ������Ҫ����ѧϰ���߲���ǿ��ѧϰ
��� Jim Fan �Ĺ۵㣬һЩ�о�������˸������ķ�������Ϊ Sora ������ѧ����������ֻ�ǿ���������ѧ���˰��ˣ�������ǰ������ģ��һ����Ҳ���˾��ã�Sora �����Ƕ� 2D ���صIJ��ݡ�

ͼԴ��https://twitter.com/IntuitMachine/status/1758845715709632873
��Ȼ��Jim Fan �ԡ�Sora û����ѧϰ��������ֻ�Dz��� 2D ���ء���һ˵��������һϵ�з���������Ϊ�����ֹ۵������ģ���ڴ�����������ʱ��չ�ֳ��������������������� GPT-4 ����ѧϰ���룬ֻ�������ѡ�ַ���һ������������û����ʶ�� Transformer ģ���ڴ����������У������ı��� token ID��ʱ�����ֳ��ĸ������������������

ͼԴ��https://twitter.com/DrJimFan/status/1758549500585808071
�Դˣ��ȸ��о���ѧ�� Kevin P Murphy ��ʾ������ȷ��������صĿ������Ƿ����Դ�ʹģ�Ϳɿ���ѧ����ȷ�������������ǿ��ƺ����Ķ�̬�Ӿ������أ��Ƿ���Ҫ MDL��Minimum description length����С�������ȣ��أ�
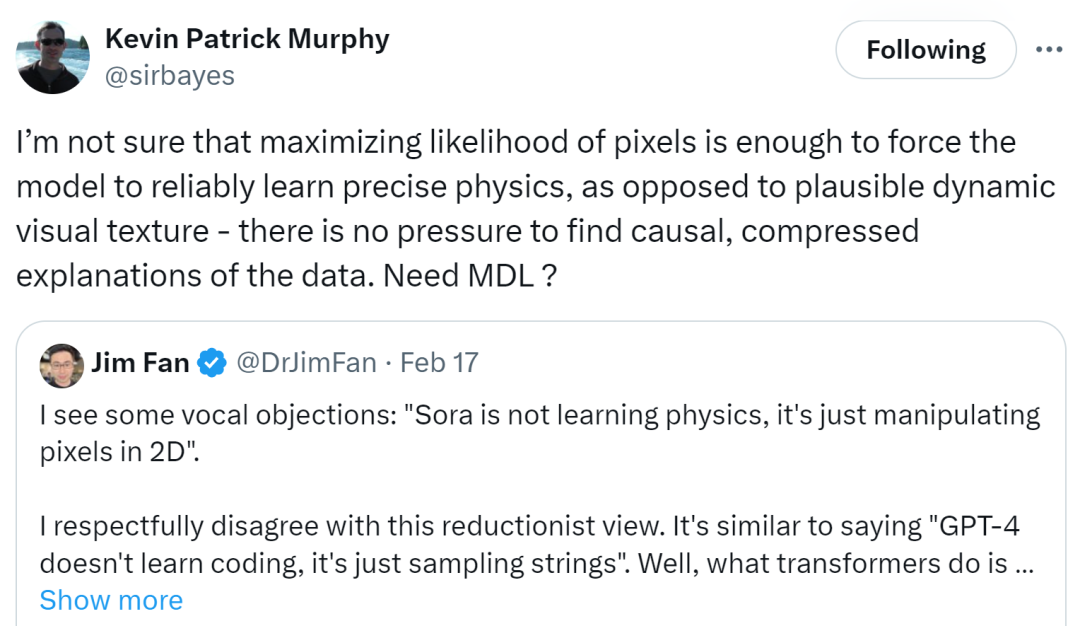
ͼԴ��https://twitter.com/sirbayes/status/1759101992516112864
���ͬʱ��֪�� AI ѧ�ߡ�Meta AI �о���ѧ����Ԩ��Ҳ��Ϊ������ Sora �Ƿ���DZ��ѧ����ȷ����������Ȼ���ڻ�û�У����䱳��Ĺؼ������ǣ�Ϊʲô��Ԥ����һ�� token�����ؽ���������˼·�������˷ḻ�ı�ʾ��
����ʾ����ʧ������α������IJ�����Ҫ����ʧ��������ƶ��������۶�ô��ѧ�����ӣ�����ֱ�Ӿ���ģ���ܷ�ѧϰ�����õı�ʾ����ʵ�ϣ����ӵ���ʧ���������뿴�����ܼ���ʧ����ʵ���ϲ��������Ƶ�Ч����
������ƣ�Ϊ�˸��õ������������ȷʵ��Ҫ�ҿ� Transformers �ĺ�ϻ�ӣ�������������ѵ����̬���Լ����ѧϰ���ص������ṹ����̽����ν�һ���Ľ�ѧϰ���̡�
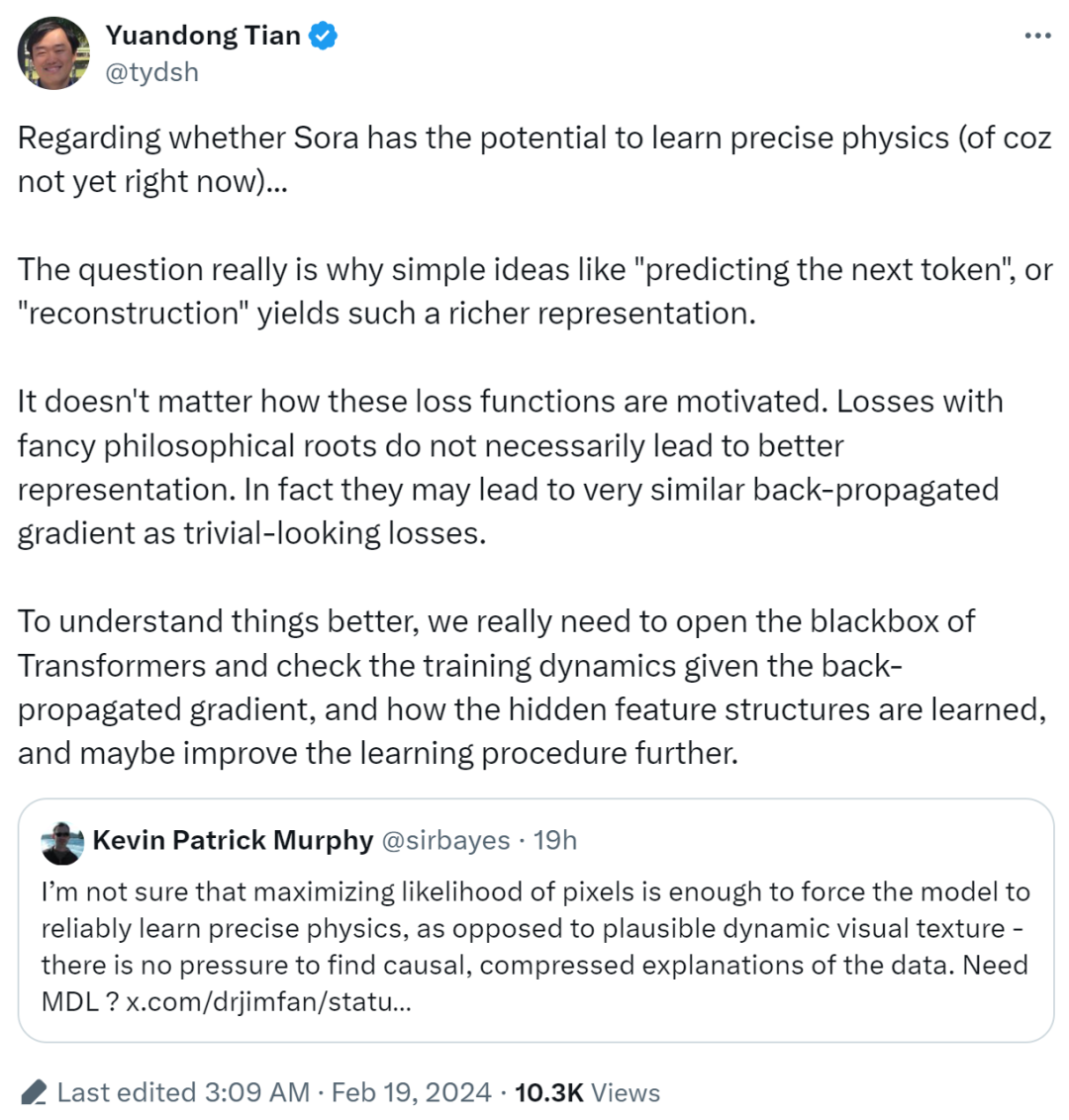
ͼԴ��https://twitter.com/tydsh/status/1759293967420805473
��Ԩ������ʾ�������Ҫѧϰ��ȷ�����������Ҵ����Ҫ����ѧϰ���߲���ǿ��ѧϰ��������γƺ�������̽�������ľ�ϸ�ṹ����������֮�������á�Ӳ�Ӵ�����

ͼԴ��https://twitter.com/tydsh/status/1759389064648888395
�����۵㣺Sora ����Ϊ�ǡ������������������桹̫����
�����ڶ� AI Ȧ����֮�⣬Ҳ��һЩרҵ�ԵĹ۵㿪ʼ���� Sora ������������һ˵����
����������λ���ز���������Ϊ OpenAI ����������������������һ�۵��ǻ������ģ� �ͺ����ռ��������˶������ݲ�������ι��һ��Ԥ������λ�õ�ģ�ͣ�Ȼ��͵ó���ģ���ڲ�ʵ���˹�������۵Ľ��ۡ�
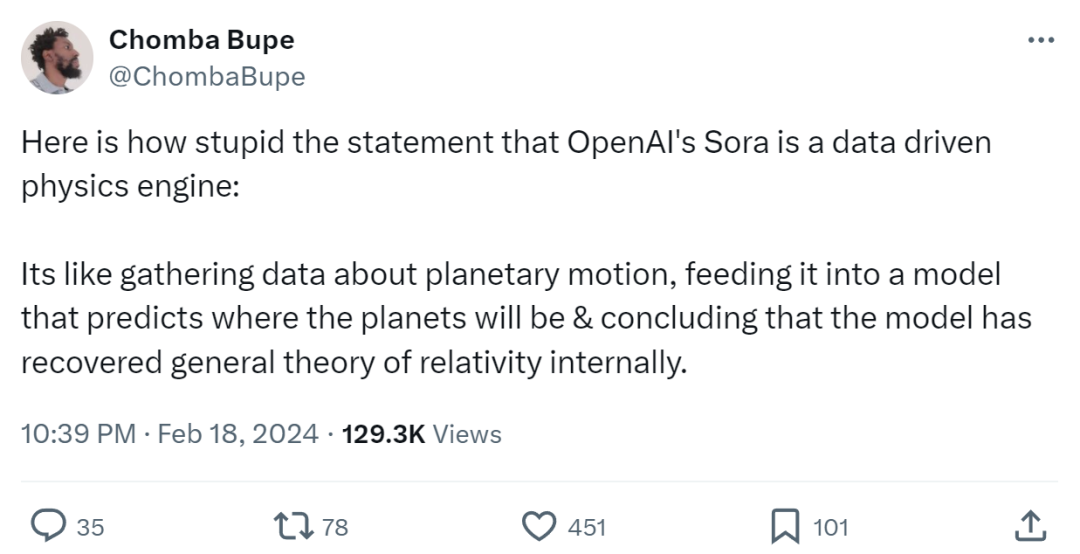
ͼԴ��https://twitter.com/ChombaBupe/status/1759226186075390033
���ƣ�����˹̹���˺ܶ���ʱ����Ƶ������������۵ķ��̡����������Ϊ����ݶ��½���SGD��+ ������ƾ��������Ծ�������һ�У�����ģ��ѵ���н�����⣬������˶��ڻ���ѧϰ��������������ģ��Ի���ѧϰ�Ĺ�����ʽ�˽�Ҳ������

����˹̹�������Ƶ��ж���ʵ�����˺ܶ���裬������ٺ㶨��ʱ�������Ľṹ��Ȼ���Ƶ������ַ��̣�����ʾ�˺ڶ������������ش��֡�����˵������˹̹���������������ͬ�ĸ���������������
���ǣ�SGD + ��������������������ֻ�ǽ���Ϣѹ����ģ��Ȩ���У���������������ֻ�Ǹ��²�ת��ʵ�־���������IJ������á�
����Ϊ������ѧϰ��ML���е�ͳ��ѧϰ���̿��ܻ���Ȼ������ء�������̽����ͬ�ĸ�� ��Ϊһ��������Щ������ء����߾ֲ���Сֵ�������¿�ʼ��
��ˣ�SGD + ���������˿�����Ч��ȴ�����ױ����ġ������Ľ�������ݾ��������Ϊʲô���ѧϰϵͳ���ɿ�����ʵ��ѵ���������ѣ����������ʵ�в��ϸ��º�ѵ�����ǣ���ͺ��鷳��
�ݶ��½��Ĺ���ԭ������һֻ��ӬѰ����ζԴһ��������Ӭ��������еĻ�ѧŨ�������ƶ����Ӷ�������������ζԴ����������������ַ�ʽ�����������·������������
�ڻ���ѧϰ�У�ģ�͵Ŀɵ��ڲ��������Ӭ��ѵ�����ݾ�����ζԴ��Ŀ�꺯����������������ζ��������ģ��Ȩ�ص�Ŀ����������ζԴ�������ǵ����൱�ڸ�Ũ����ζ���ƶ���
������ó����ۣ������Ϊ����ѧϰģ�ͽ���ͨ��ѵ�������˶�����Ƶ�������ڲ�ѧ����������ۣ��Ǿ������ˡ����ǶԻ���ѧϰԭ����������⡣

���⣬������ָ�� Sora ��Ƶʾ���г���������������һȺС����ѩ�����ֵij����ͺ���⣬���ѩ���˶�����ȫΥ�����������Ƿ�����ˣ��д��жϣ���

ͼԴ��https://twitter.com/MikeRiverso/status/1759271107373219888
Sora ��������������������ᶮ����Ԥ����һ�� token���Dz���ͨ�� AGI ��һ�����������ڴ���·�о��߽��н�һ����֤��

















