m6A修饰是真核生物中最普遍的修饰,也是近年来的研究热点。但小编发现m6A相关的研究论文中,大多只采用转录组+m6A组的联合分析,导致文章IF还徘徊在3-8分。
基迪奥的客户文章也同样有此现象,采用转录组+m6A组的文章平均IF为7.7分,但采用转录组+翻译组+m6A组的发文平均IF可达到15.72分,如此之差距,究竟是如何产生的?本期推送小编将带领大家一起揭秘~
转录组+m6A组联合研究m6A修饰的瓶颈
纵观转录组+m6A组联合研究m6A修饰的文章,发现它们的共同点在于,仅通过两个组学很难找到目标基因(即影响表型变化直接且显著的m6A修饰基因)。
如图1是2023年发表在Insect science(IF=3.246)上的文章,该研究的目的是探究m6A修饰在草地贪夜蛾胚胎发育中的作用,但此文中作者通过转录组和m6A组的共表达分析筛选出的共表达基因有9000多个,寻找目标基因可谓是大海捞针,因此后续仅进行一些功能富集分析及简单的qPCR验证。

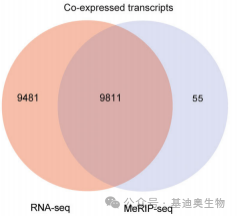
图1. 转录组和m6A组共表达韦恩图
图2是2022年发表在RNA Biology(IF=4.076)上的文章,该研究的目的是探究m6A修饰在沙棘遭受干旱胁迫中的影响,该文中作者同样是通过转录+m6A的两组学的共表达分析,筛选出500多个基因,范围依然很广,因此,该文章最终只展示了沙棘转录组范围内的m6A修饰图谱。

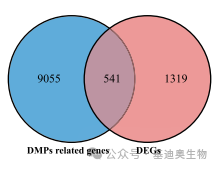
图2. DMP相关基因和DEGs的 Venn图谱
DEGs:差异表达基因;DMP:差异m6 A甲基化峰
当然,也有极少数幸运的时候,通过转录组和m6A组,就可以直接将范围缩小到几个基因。如图3是2022年发表在Cancer communications(IF=15.283)上的文章,该研究的目的是探究METTL3介导的m6A RNA修饰在胃癌中的作用,此文中作者通过转录组和m6A组的共表达分析直接就筛选出了7个共表达基因,并通过一系列的体内体外实验对这七个基因进行了实验验证,最终找到了可能的治疗靶点,文章影响因子直接飞升。

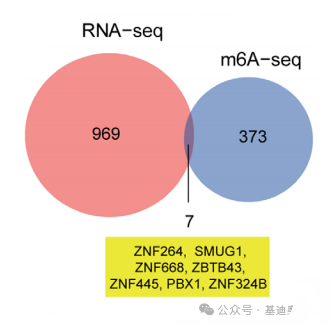
图3. 转录组和m6A组共表达韦恩图
但是,这种幸运毕竟是少数的。通过总结转录组+m6A组来研究m6A RNA修饰的不同IF的文章,我们可以得出结论的是,影响该类型文章IF高低的决定性因素在于靶基因的寻找,而翻译组则可以帮助加大这个靶基因寻找的概率~
加上翻译组来研究m6A修饰会如何?
在转录组+m6A组的基础上,添加翻译组学来研究m6A修饰,可谓是直接给靶基因的寻找按上了“加速键”。
如图4的文章中,为研究YTHDF1(m6A结合蛋白)在非酒精性脂肪性肝炎所致肝癌(NASH-HCC)中的作用。作者首先采用RIP-seq定位了细胞中与YTHDF1结合的3541个转录本,再将m6A MeRIP-seq和YTHDF1 RIP-seq数据集进行重叠鉴定出了2,994个具有m6 A修饰的YTHDF1靶基因。最后,通过将Ribo-seq与蛋白组数据集进行整合,获得了4个YTHDF1靶基因。
该文章通过结合翻译组、转录组、蛋白组和MeRIP-seq(m6A-seq+RIP-seq),“稳准狠”地将目标基因缩小到4个的范围,为后续的实验验证做了很好的铺垫,大家在之后研究m6A RNA修饰时也可以借鉴此案例的筛选思路。

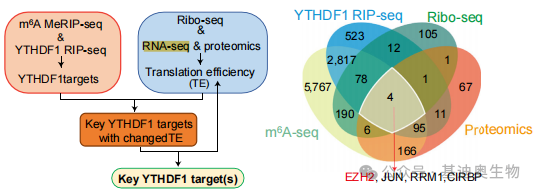
图4. 结合Ribo-seq、RNA-seq、proteomics和MeRIP-seq筛选出4个目标基因
那在研究中加上翻译组难道只是可以帮助缩小目标基因的筛选范围嘛?是否还有其他妙用?
其实,翻译组作为一个联通性很强的组学,在转录组+翻译组+m6A组中,除了可以通过韦恩图分析可以帮助筛选目标基因的范围,它还有许多分析点可挖掘。小编在这里也根据大量的高分翻译组文章,总结了以下适合转录组+m6A+翻译组联合分析的思路,可供小伙伴参考:
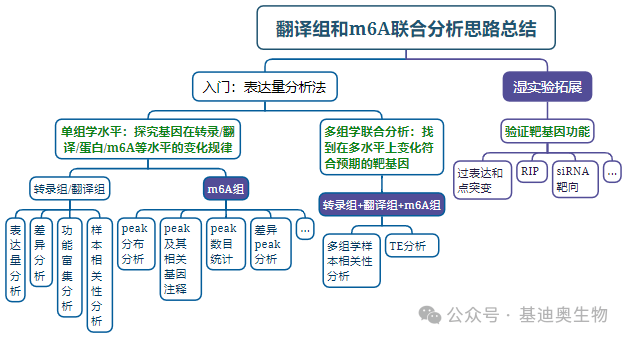
第一步
单组学水平解释基因在转录/翻译/m6A等水平的调控规律
1.基于基因的表达量数据,可通过差异分析获得在转录/翻译等水平的差异变化基因(图5.a-b),并可以对其中的差异基因进行初步的功能富集分析(图5. c),了解这些差异基因主要与哪些生物学功能相关,从而可能导致最终的表型变化。
2.通过m6A的peak的分布及数目统计分析(图6.a-b)、富集分析以及表达量的变化(图6. c-d)来观察基因在m6A水平的变化。
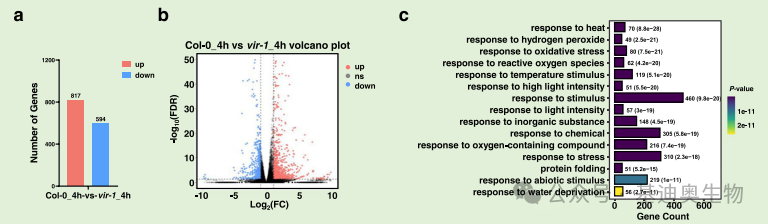
图5. 差异分析柱状图(a)差异分析火山图(b);富集分析条形图(c)
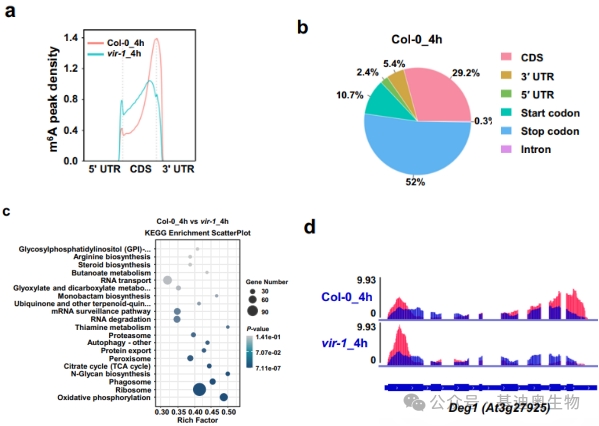
图6.m6A peak分布图(a);m6A peak数目统计图(b);m6A peak富集分析气泡图(c)reads IGV可视图(d)
图片
第二步
多组学水平共同挖掘可能的目标基因
多组学联合更有可能挖掘到我们想要的目标基因,除了上述所提到的通过差异基因的共表达韦恩图来筛选目标基因外,还可以进行一些前处理分析。
例如,通过翻译效率(TE)分析、差异TE分析(图7. a)和四九象限分析(图7. b)等,获得基因在转录水平和翻译效率水平的变化规律,并将其进行分类(不同象限代表不同规律的基因),再对重点关注的某类基因进行功能富集分析,重点了解这些基因的功能后,再通过韦恩图将这些基因与m6A的结果进行合并,帮助快速且准确的缩小目标基因的筛选范围。
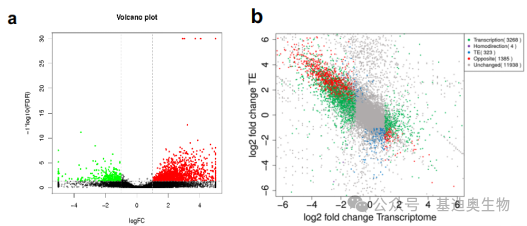
图7.差异TE基因火山图(a);差异转录基因和差异TE基因的九象限图(b)
第三步
体内外实验验证靶基因功能
借助组学的力量找到靶基因后,想要文章分数提升,湿实验的验证也是必不可少的了。小编这里也总结了一些可以加入文章的实验,例如通过点突变、敲除或过表达目标基因的方式来观察目标基因对表型的影响,也可以通过免疫共沉淀、RNA pulldown等实验找到与目标基因分子调控相关的蛋白,更有条件者还可用LC/MS对蛋白进行进一步的验证,从而让文章更有深度以及说服力。
小 结
无论如何,在m6A RNA修饰相关的研究中,找到靶基因是文章IF提升的关键,只有找到它才可以进行后续机制的进一步探究,将整个文章的故事线阐述的更清晰。而翻译组的加入则可以在调控机制的解析以及靶基因的筛选上注入强大的力量。
因此,有在进行m6A或想进行m6A RNA修饰相关研究的小伙伴们,不要只用转录组+m6A组来研究啦,考虑下加个翻译组吧,让你在通往高分文章发表的路上少走些弯路~
基迪奥不仅有行业内唯一的翻译组、m6A组以及翻译组+转录组关联的在线报告,还可提供转录组+m6A组+翻译组的关联分析结题报告,分析点全面,可为您的文章发表保驾护航.
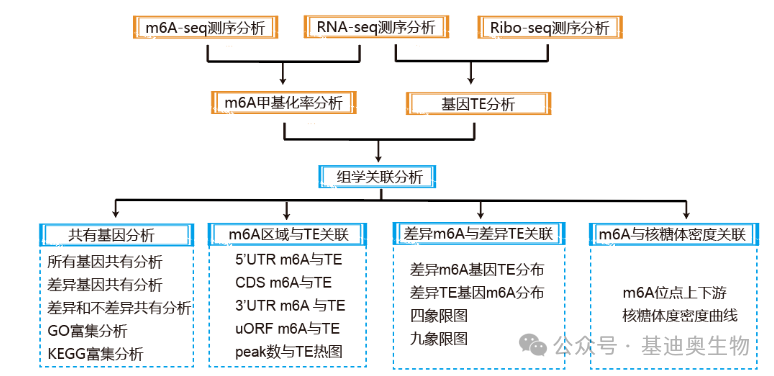
基迪奥m6A报告:
涵盖发文所需的99%分析点,100+功能参数可实现一键调整图形类型、配色等功能,帮助实现高效绘图。
基迪奥Ribo-mRNA关联报告:
九象限图可实现图表交互,帮助快速找到定位到象限内的基因,点亮星标,还可在图中进行高亮展示。
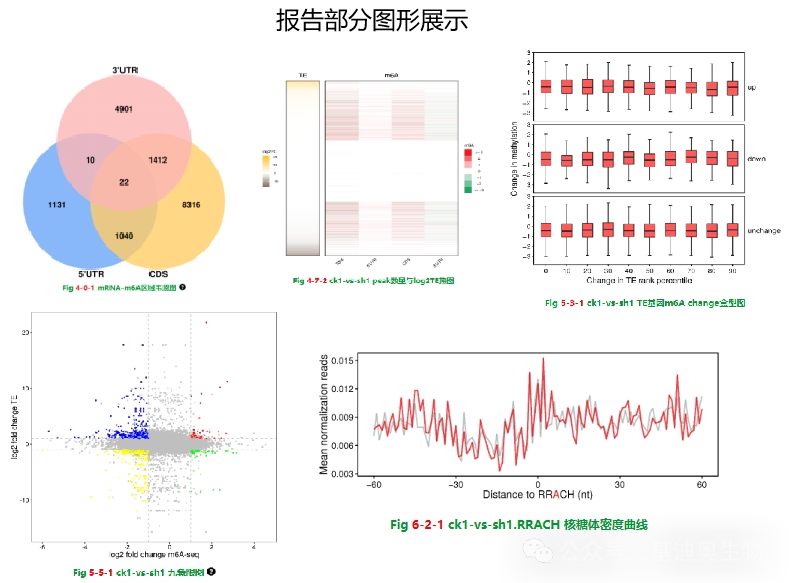
m6A组+翻译组+转录组结题报告
可提供发文所需的16种分析点,并提供精美绘图,让您实现轻松发文~