ȥ�����������Ǽ�֤���� GPT-4V Ϊ�����Ķ�ģ̬������ģ�ͣ�Multimodal Large Language Model��MLLM���ķ��ٷ�չ��Ϊ�����Ƕ������������ش��������������ȫ���˽������ķ�չ��״�Լ�DZ�ڵķ�չ����
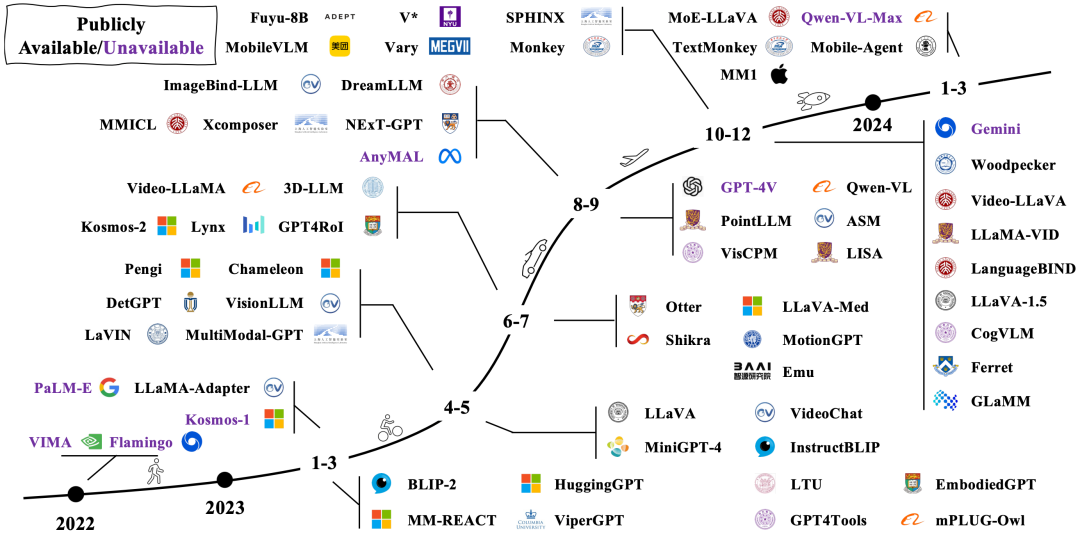
MLLM ��չ����ͼ
MLLM ��̥�ڽ��������ܹ�ע�Ĵ�����ģ�ͣ�Large Language Model , LLM��������ԭ�е�ǿ�����������������ϣ���һ�������˶�ģ̬��Ϣ��������������������Ķ�ģ̬������������ CLIP Ϊ�������б�ʽ������ OFA Ϊ����������ʽ�����˵� MLLM չ�ֳ�һЩ���͵����ʣ���1��ģ�ʹ�MLLM ͨ��������ʮ�ڵIJ�����������IJ��������������DZ������2���µ�ѵ����ʽ��Ϊ�˼�����������DZ����MLLM �����˶�ģ̬Ԥѵ������ģָ̬�������µ�ѵ����ʽ����֮ƥ�������Ӧ�����ݼ����췽ʽ�����ⷽ���ȡ������������ʵļӳ��£�MLLM ӿ�ֳ�һЩ������ģ̬ģ�������߱����������������ͼƬ���� OCR�Free ����ѧ����������ͼƬ���й��´�����������������㺬��ȡ�
�������ӣ�https://arxiv.org/pdf/2306.13549.pdf
��Ŀ���ӣ�ÿ�ո����������ģ���https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models

��������ҪΧ�� MLLM �Ļ�����ʽ����չ�����Լ�����о��������չ�����������:
MLLM �Ļ�����������ظ�������ܹ���ѵ�����ԡ����ݺ����⣻
MLLM ����չ���죬��������������ȡ�ģ̬�����Ժͳ�����֧�֣�
MLLM ������о����⣬������ģ̬�þ�����ģ̬������ѧϰ��Multimodal In-Context Learning��M-ICL������ģ̬˼ά����Multimodal Chain of Thought��M-CoT����LLM �������Ӿ�������LLM-Aided Visual Reasoning��LAVR����
�ܹ�
���ڶ�ģ̬����-�ı�����ĵ��� MLLM����ܹ�һ��������������������Լ� LLM����Ҫ֧�ָ���ģ̬���������ͼƬ����Ƶ����Ƶ����һ����Ҫ�������������������ͼ��ʾ:
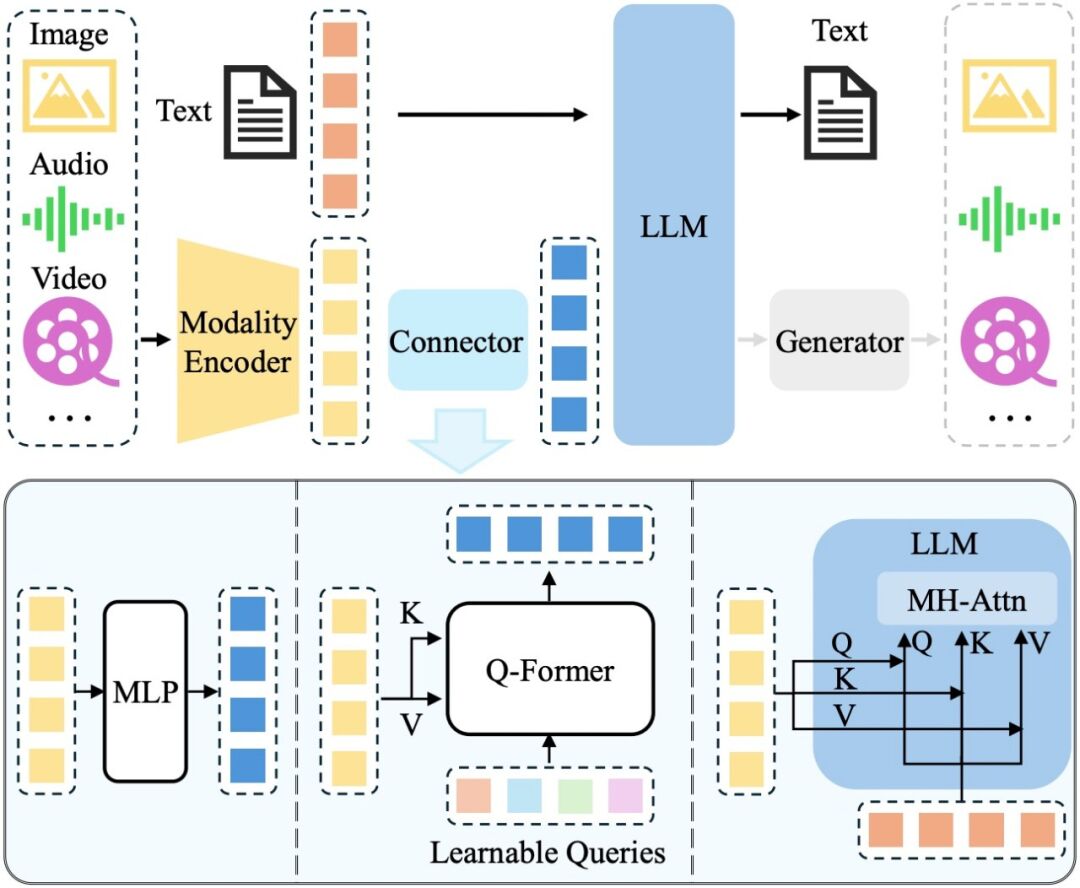
MLLM �ܹ�ͼ
���У�ģ̬����������ԭʼ����Ϣ����ͼƬ����������������������һ��������������LLM �����������ʽ�����Ӿ� Token��LLM ����Ϊ�����ԡ��ۺ���Щ��Ϣ������������������ɻش�Ŀǰ�����ߵIJ�����������ͬ���� Qwen-VL[1]Ϊ����LLM ��Ϊ�����ԡ�������Ϊ 7.7B��Լռ�ܲ������� 80.2%���Ӿ���������֮��1.9B��Լռ 19.7%���������������������� 0.08B��
�����Ӿ����������ԣ���������ͼƬ�ķֱ������������ܵ���Ч������һ�ַ�ʽ��ֱ�������ֱ��ʣ������������Ҫ�ſ��Ӿ�����������ѵ������Ӧ���ߵķֱ��ʣ��� Qwen-VL[1]�ȡ���һ�ַ�ʽ�ǽ���ֱ���ͼƬ�зֳɶ����ͼ��ÿ����ͼ�Եͷֱ��������Ӿ��������У��������Լ����������ķֱ��ʣ��� Monkey[2]�ȹ�����
����Ԥѵ���� LLM�����õİ��� LLaMA[3]ϵ�С�Qwen[4]ϵ�к� InternLM[5]ϵ�еȣ�ǰ����Ҫ֧��Ӣ�ģ�����������Ӣ˫��֧�ֵø��á�������Ӱ����ԣ��Ӵ� LLM �IJ��������Դ����������������棬�� LLaVA-NeXT[6]�ȹ����� 7B/13B/34B �� LLM �Ͻ���ʵ�飬��������LLM ��С���Դ����� benchmark �ϵ������������� 34B ��ģ���ϸ�ӿ�ֳ� zero-shot ����������������ֱ������ LLM �����������ڻ��ȵ� MoE �ܹ����ṩ�˸���Чʵ�ֵĿ����ԣ���ͨ��ϡ�����ķ�ʽ���ڲ�����ʵ�ʼ����������ǰ��������ܵ�ģ�Ͳ�������
���ǰ������˵������������Ҫ���Ե͡����磬MM1[7]ͨ��ʵ�鷢�֣������������Ͳ����Ӿ� token ����������֮�� LLM ���õ��Ӿ���Ϣ����ͼƬ�ķֱ��ʣ������Ӿ���������������Ϣ������Ҫ��
������ѵ��
MLLM ��ѵ�����¿��Ի���ΪԤѵ���Ρ�ָ�����κͶ������Ρ�Ԥѵ������Ҫͨ������������ݽ�ͼƬ��Ϣ���뵽 LLM �ı����ռ䣬���� LLM �����Ӿ� Token��ָ��������ͨ���������ĸ������͵�������������ģ�������������ϵ����ܣ��Լ�ģ������ͷ���ָ�����������������һ��ʹ��ǿ��ѧϰ����ʹģ�Ͷ��������ֵ�ۻ�ijЩ�ض���������ٻþ�����
���ڹ����ڵ�һ����Ҫʹ�ô����ȵ�ͼ�Ķ����ݣ��� LAION-5B����Щ������Ҫ��Դ�ڻ������ϵ�ͼƬ���丽��������˵������˾��й�ģ���� 10 �ڹ�ģ���������ࡢ�ı��̵��ص㣬����Ӱ������Ч���������Ĺ�����̽��ʹ�ø��ɾ����ı����ݸ��ḻ�����������롣�� ShareGPT4V[8]ʹ�� GPT-4V ���ɵ���ϸ����������ϸ���ȵĶ��룬��һ���̶��ϻ����˶��벻��ֵ����⣬����˸��õ����ܡ������� GPT-4V ���շѵģ��������͵����ݹ�ģͨ����С���������ģ�������⣬�������ݹ�ģ���ޣ������������֪ʶҲ�����ģ������Ƿ��ܹ�ʶ���ͼ���еĽ���Ϊ����������������֪ʶͨ�������ڴ��ģ�Ĵ�����ͼ�Ķ��С�
�ڶ��ε�������һ���������Դ�ڸ�����������ݣ��� VQA ���ݡ�OCR ���ݵȣ�Ҳ������Դ�� GPT-4V ���ɵ����ݣ����ʴ�ԡ���Ȼ����һ���ܹ����ɸ����ӡ�����������ָ�����ݣ������ַ�ʽҲ�����������˳ɱ���ֵ��һ����ǣ��ڶ��ε�ѵ����һ�㻹���ϲ��ִ��ı��ĶԻ����ݣ��������ݿ�����Ϊ�����ֶΣ����� LLM ԭ�е���������Ƕ֪ʶ��
�����ε�������Ҫ������ڻش��ƫ�����ݡ���������ͨ�����˹���ע�ռ�������ɱ��ϸߡ����ڳ���һЩ����ʹ���Զ����ķ��������Բ�ͬģ�͵Ļظ�����ƫ�������� Silkie[9]ͨ������ GPT-4V ���ռ�ƫ�����ݡ�
������������
��������ģ�͵Ļ�����������֧�ֵ�����/�����ʽ������ָ�꣩�⣬����һЩ����˼�������Լ���̽���ķ�����������Ҫ�����˶�ģ̬�þ�����ģ̬������ѧϰ��Multimodal In�Context Learning��M-ICL������ģ̬˼ά����Multimodal Chain of Thought��M-CoT���� LLM �������Ӿ�������LLM-Aided Visual Reasoning��LAVR���ȡ�
��ģ̬�þ����о���Ҫ��עģ�����ɵĻش���ͼƬ���ݲ��������⡣�Ӿ����ı����������칹����Ϣ����ȫ�������߱����;����൱�����ս������ͼ��ֱ��ʺ�����ѵ�����������ǽ��Ͷ�ģ̬�þ���������ֱ�۵ķ�ʽ������������Ȼ��Ҫ��ԭ����̽����ģ̬�þ��ij���ͽⷨ�����磬��ǰ���Ӿ���Ϣ�� Token ����������ģ̬����ķ�ʽ����ģ̬���ݺ� LLM �洢֪ʶ�ij�ͻ�ȶԶ�ģ̬�þ���Ӱ�����������о���
��ģ̬������ѧϰ����Ϊ������ѧϰ������ּ��ʹ���������ʴ�������ʾģ�ͣ�����ģ�͵�few-shot ���ܡ��������ܵĹؼ�������ģ����Ч�ع�ע�����ģ��������ڵ�����ģʽ�������µ������ϡ��� Flamingo[10]Ϊ�����Ĺ���ͨ����ͼ�Ľ�����������ѵ��������ģ��ע�����ĵ�������Ŀǰ���ڶ�ģ̬������ѧϰ���о����Ƚϳ������д���һ��̽����
��ģ̬˼ά���Ļ���˼����ͨ�������ӵ�����ֽ�Ϊ�ϼ������⣬Ȼ��ֱ��������ܡ�����ڴ��ı�����������ģ̬�������漰�������Ϣ��Դ�����ӵ�����ϵ�����Ҫ���ӵöࡣ��ǰ�÷���Ĺ���Ҳ�Ƚ��١�
LLM �������Ӿ���������̽��������� LLM ǿ�����Ƕ֪ʶ���������������������ߣ���Ƹ����Ӿ�����ϵͳ�����������ʵ���⡣�����ͨ���˵���ѵ����õ�һģ�ͣ������һ���ע���ͨ����ѵ���ķ�ʽ��չ�ͼ�ǿ LLM ���������Ӷ�����һ���ۺ��Ե�ϵͳ��
��ս��δ������
��� MLLM ���о���״�����ǽ���������˼��������ս����ܵ�δ����չ�����ܽ�����:
���� MLLM ������ģ̬�������ĵ��������ޣ�����ģ���ڳ���Ƶ���⡢ͼ�Ľ���������������������پ���ս���� Gemini 1.5 Pro Ϊ������ MLLM ����������Ƶ������˳�������ģ̬ͼ�Ľ����Ķ����⣨�����ĵ��м���ͼ��Ҳ���ı�������Կհף��ܿ��ܻ��Ϊ���������о��ȵ㡣
MLLM ���Ӹ���ָ����������㡣���磬GPT-4V �������⸴�ӵ�ָ���������ʴ����������������Ϣ��������ģ���ⷽ������������Բ��㣬���нϴ�������ռ䡣
MLLM ��������ѧϰ��˼ά���о���Ȼ���ڳ����Σ���ص�����Ҳ������ؽ����صײ�����Լ������������о�̽����
�������� MLLM ����������һ���о��ȵ㡣Ҫʵ������Ӧ�ã���Ҫȫ������ģ�͵ĸ�֪�������滮������
��ȫ���⡣MLLM ��������ƵĶ����Ӱ�죬������ƫ�Ļ����Ļش𡣸÷��������о�Ҳ��ȻǷȱ��
Ŀǰ MLLM ��ѵ��ʱͨ������ⶳ LLM����Ȼ��ѵ��������Ҳ����벿�ֵ�ģ̬���ı�ѵ�����ݣ������ģ�Ķ�ģ̬�͵�ģ̬���ݹ�ͬѵ��ʱ�����Ա˴˻������滹�ǻ�������Ȼȱ��ϵͳ������о���
����ϸ�������Ķ�
�������ӣ�https://arxiv.org/pdf/2306.13549.pdf
��Ŀ���ӣ�https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
[1]. Bai, Jinze, et al. "Qwen-vl��A frontier large vision-language model with versatile abilities." arXiv preprint arXiv:2308.12966��2023��.
[2]. Li, Zhang, et al. "Monkey��Image resolution and text label are important things for large multi�modal models." arXiv preprint arXiv:2311.06607��2023��.
[3]. Touvron, Hugo, et al. "Llama��Open and efficient foundation language models." arXiv preprint arXiv:2302.13971��2023��.
[4]. Bai, Jinze, et al. "Qwen technical report." arXiv preprint arXiv:2309.16609��2023��.
[5]. Team, InternLM. "Internlm��A multilingual language model with progressively enhanced capabilities." 2023-01-06��[2023-09-27]. https://github. com/InternLM/InternLM��2023��.
[6]. Llava-next��Improved reasoning, ocr, and world knowledge. Available��https://llava�vl.github.io/blog/2024-01-30-llava-next/
[7]. McKinzie, Brandon, et al. "Mm1��Methods, analysis & insights from multimodal llm pre�training." arXiv preprint arXiv:2403.09611��2024��.
[8]. Chen, Lin, et al. "Sharegpt4v��Improving large multi-modal models with better captions." arXiv preprint arXiv:2311.12793��2023��.
[9]. Li, Lei, et al. "Silkie��Preference distillation for large visual language models." arXiv preprint arXiv:2312.10665��2023��.
[10]. Alayrac, Jean-Baptiste, et al. "Flamingo��a visual language model for few-shot learning." Advances in neural information processing systems 35��2022����23716-23736.

















