AI����������һ����

ͼ1��AI�ܽ����ѧ������
�����Ǽ���������ľ��˳ɹ��������ձ���ΪAI�����ܹ�����һ�С������������ܹ�������Ŀǰ������һ�С���ô��ѧ�أ�������������������������ȡ�ý�չ�����������ڻ����������������������������������ǣ��������Ǹ��������е�Ŭ������Ȼ�и��ָ����Ŀ�ѧ����û�н������ô����AI�ܽ��������������Щ������
��������ռ����⣬���ǽ������𰸲��ɱ����Ҽᶨ���Ƿġ����������ζ��AI������Ҫ�شٽ���ѧ���������磬�ڷdz�ʵ�ʵIJ����ϣ�LLMs[2]�ṩ��һ���µ����Խӿ�[3]���������ǣ�ԭ���ߣ���ͬ��������ô��ʱ�乹����Wolfram����[4]�еļ���������ͨ���ԡ���ͳ��ѧ�ǻۡ���֪ʶ��LLMsͨ�������ṩ�dz����ġ��Զ���ȫ����������ѧ�����еġ���ͳ�𰸡���ͳ��һ������
���������������۵��ǹ���AI�ڿ�ѧ�еĸ����ε����⡣��������ǰ����ѧ��ʹ����ѧ����ʾ������뷨�������˱������������ʱ��������������������ĸ��������ʾ���ش�ת��֮��[5]���ǵģ���������ǵ�Wolfram���Լ������Եĺ����������ôAI���Ӧ�ԣ�����Ӧ�ý�����Ϊ�������з�����ʵ�ù��ߣ�������Ϊ��ѧ�ṩ�˸����ԵĴ��£�
�ҵ�Ŀ����̽��������AI�ڿ�ѧ���ܹ��Ͳ��ܹ��������顣�ҽ�����һЩ��������ӣ�����ͻ���䱾�ʡ��ҽ����ۻ�����������Ϊֹ������ֱ�����������һ�������һЩ�����ϵġ����Լ���ijЩ�������ѧ�ϵġ�������������ʲô�ǿ��ܵģ�ʲô�Dz����ܵġ�
��ô���AI��������ʲô��˼����ȥ���κ�����ļ���ͨ������Ϊ�ǡ�AI��������������£����磬���dz���������Wolfram���Լ�������[6]�еĹ����ᱻ����AI�����������ڼ��������жԼ���ġ�ruliological���о�[7]һ��������������Ҵ�ʱ������һ��������Ķ��塪��˵AI�ǻ��ڻ���ѧϰ[8]�ģ�ͨ������������ʵ�ֵģ���������ͨ��������ʾ����ѵ���ġ�ͨ���һ���������һ�����֣���Щʾ������һ�����͵����������ɵĿ�ѧ�ı��ȵ����Ͽ⣬�����ǹ���������ʵ�ʷ����������ʵ�ʾ������Ͽ⡪�����仰˵��������һ����ԭʼѧϰ��������AI���Ӵ�����������֪ʶ��ѧϰ����
���ˣ������Ѿ�˵����AI����˼����ô��ѧ�͡�����ѧ������˼����ʲô�����գ���һ�ж��뽫�������������е������ͨ������Ȼ���е�����������ܹ�˼�����������������ӻ���[9]�йء���ʵ���ϣ��м��ֽ�Ȼ��ͬ�ġ���������������ѧ��һЩ������Χ��Ԥ�⣺�����۲쵽����Ϊ��Ԥ�⽫�ᷢ��ʲô���ҵ�һ�����ǿ�����ȷ������ģ�ͣ�˵��ϵͳ��������У��������е����ۣ�ȷ������庬�塣����������������������йأ�����һ����Ϊ������һ�������������������ڲ�ͬ��ϵͳ��ģ��֮���ҵ���ȡ�����һЩ������������봴���йأ����־����ض����ԵĶ��������֡���Ȥ���Ķ�����
�ڽ������������У����ǽ�����ϸ��̽����Щ������������������Σ����ܣ���AIת����������������ǽ����������֮ǰ��������Ҫ����һ���������κΡ������ѧ�������ϵ������㲻��Լ��[10]��
���㲻��Լ�Ե�Ӳ������

ͼ2
������ѧʱ��ͨ������һ���ҵ�ijϵͳ�����Ļ�������ľ���ս�������������ҵ�����Щ������������һЩ��ʽ�ķ�ʽ����ʾ���ǣ�����һ��������ô��Ȼ��һ�����⣬��Щ�������ϵͳ��ʵ����Ϊ��ζ��ʲô���ǵģ����ǿ���һ��һ������ȷӦ�ù����ٷ��������顣�������Ƿ���ԡ���һ�����͡��������һ�С���֪��ϵͳ��������У�
Ҫ������һ�㣬������ij�������ϱ����ϵͳ�������ޱȡ���ϵͳ���뾭��������Щ���衪�������ǿ��ԡ��������������ҳ������һ���ؼ��Ĺ۵㡪�����������ǵ�������Ŀ[11]�ڻ���������֧�֡��������ǿ��Խ����з�����������Ϊһ��������̡�ϵͳ���ڽ��м�����ȷ������Ϊ���������ࡪ�����ߣ����Ǵ�����κ�AI����Ҳ������м��㣬�Գ���Ԥ������������Ϊ������ȼ���ԭ��[12]˵��Щ�������临����������ǵȼ۵ġ�����ζ�����Dz���ָ��ϵͳ�ء���������Ԥ������ϵͳ��ҪŪ��ϵͳ����ʲô����Ȼ��Ҫһ������Լ�ļ��㹤������ˣ��������Ƕ�ôŬ����������AI���������������������ǽ���������Ϊ�ļ��㲻��Լ�ԡ�
�����ڼ��㲻��Լ�ԣ�Ϊʲô��ѧʵ�����ǿ��ܵģ��ؼ���ʵ�ǣ�ÿ����������ļ��㲻��Լ��ʱ��Ҳ�������������ļ����Լ�ԵĿڴ������仰˵������ijЩϵͳ�ķ��棬����ʹ�����ļ���Ŭ����˵��������Щ���������ڡ�����ѧ��ʱͨ�����о����ĵط���
�����ɱ���أ�����������ԡ������������㲻��Լ�Ե����⡣��ʱ��Щ����Ϊ�������ش�����⣬��ʱ�����Ϊ������Ԥ���ġ���ϲ�������ص��ǣ����������Ҫ�����һ�С����������ջ��������㲻��Լ�ԣ�����������AI������������������ͨ��һ����λ��ģ��ϵͳ�������
Ȼ����������һ����֮�����������ֻ��֪��������Լ�Զ���������أ��ܶ��ѧ�����Լ�������������ר��Χ�Ƽ����Լ�����ġ����磬�����Ϊʲô��ѧ��ʽ�ڿ�ѧ���ܹ���˳ɹ���ԭ��֮һ��
�����ǿ϶�֪�������ǻ�û�н�������ڿ�ѧ����Ҫ�����һ�С��ںܶ�����£������ƺ���û������ѡ��Ҫ�о�ʲô����Ȼ�磬�ٸ����ӣ���ʹ����ȥ�о�����������Dz��ɱ������Լ��㲻��Լ�ԡ�
�������ǽ����۵ģ�AI��DZ��Ϊ�����ṩ����ķ�ʽ���ҵ�ijЩ���͵ļ����Լ�Կڴ������ܻ��м��㲻��Լ�ԣ���������ġ���ϲ�������������ٻ������ԡ���õĶ���������������ս��𣿲��ᡣ�ܻ��С�����ķ��֡�����Ҫ���������ܵ���Ķ��������Dz�֪�����ڵļ����Լ�Կڴ������ա�����������AI�������㲻��Լ�Խ���ֹ������ȫ�������ѧ����
������һ����Ȥ����ʷ����[13]���ڶ�ʮ���ͳ�����һ������������ѧ�Ƿ��ܹ�����е�ؽ������Ȼ������¶������ĵ����ƺ�ȷ���������ܡ�����������֪����ѧҲ��һ������ṹ�����㲻��Լ����һ����ʵ�����Ǹ�¶�������һ������������Ҳ���ܡ���е�ؽ������
������Ȼ�����ʣ��Ƿ�����ѡ���о�����ѧ���ѧ���ܽ��������ڼ����Լ�ԵĿڴ��С�����ij��������˵������ѧ�ѡ����ռ�ԭ�������Dz��Ͽ������㲻��Լ�Ե�֤�ݣ��������ƹ�ʵ�ʽ��м������Ҫ����Ҳ���ǣ����磬������AI������û��Wolfram���Թ���[14]�İ������IJ��ó�֮����
��ȥ��Ч�ķ���
������̽���ִ����ڻ���ѧϰ��AI�����ڡ������ѧ����������ʲô֮ǰ���ع�һ�¹�ȥ��Ч�ķ����ƺ���ֵ�õġ���������Ϊ�ִ�AI�������ӵ����ݵĻ���
���Լ�ʹ�ü�����ͼ���[15]�����ֿ�ѧ�е�����������ʮ�����ˡ��ҵĵ�һ����ɹ�����1981��[16]����ʱ�Ҿ�������ö��ij�����͵����п��ܹ�����Ԫ���Զ�����[17]��Ȼ���ڼ�������������ǣ��������ǻ���ʲô��

ͼ3
������Ϊ�����мĵײ�������յ���ΪҲ����Ӧ�ؼ���ij�������ϣ����������������һ�㣺��ֻ��ö�ٹ�����������ˣ���ʹ�Ҵ�δ�뵽�����������Ҳ�ܡ����֡������30[18]�����Ķ�����
һ����һ�Σ��Ҿ��������Ƶľ������ҿ�����ij��ϵͳ�������������Ȥ����������ϵͳ��ö�ٿ�����ʱ���������Ƕ���һЩ���벻������Ȥ�ҡ��������Ķ�����ͨ����������֡�
��1990�����������֪�����ͨ��ͼ���������ʲô������Զ���Լ�Ū�������1960������������ּ�¼�Ļ�����7��״̬��4����ɫ�������������ͨ��ϵͳö��[19]������2״̬3��ɫ�Ļ���
ͼ4
����2007�걻֤����ͨ�õ�[20]���ǵģ��������ͨ��ͼ�������
��2000�꣬�Ҷ����������������������ϵͳ����Ȥ������ʱ��֪�����ϵͳ����9����ԪNand[21]���㡣��ͨ��ϵͳö�٣��������ҵ��˵�һ��6���㹫��[22]
ͼ5
����ʹ���Զ�����֤��֤������ȷ������һ�Σ��Ҳ�֪�����ǡ����ڵġ�����Ȼ��Ҳ���Լ�����������ͨ��ϵͳö�٣�������ܹ��ҵ�����Ϊ�dz��������ԡ��Ľ����
2019�꣬�ҽ�������һ��ϵͳö�٣������ǿ��ܵij�ͼ��д����[23]������ܶ�Ӧ�����������������Ͳ�ṹ[24]�����ҹ۲����ɵļ���ͼ��[25]ʱ���Ҹо���Ϊһ��������Դ��Եط������������Ķ��������Ƿ����쳣ֵ����ת����ӽ����ִ�AI���Ŀ�ѧ��������һ�������ռ�ͼ[26]���Ӿ�ͼ��[27]:

ͼ6���Ӿ�ͼ��������ռ�ͼ
����Ҫ����Ϊ����ȥ���ͣ�����ȷʵ����һЩ�쳣ֵ��ͨ�����������ռ�ͼ�������硰�Զ����֡��ġ�
�ҽ��ٸ�һ��������ȫ��ͬ���͵ġ������ӣ������ҵĸ��˾�����1987�꣬Ϊ�˹����ֽ�Wolfram���Ե�1.0��[28]��һ���֣�������ͼ�����㷨�����ڷdz��㷺�IJ�����Χ�ڼ�����������ѧ���⺯�����ڹ�ȥ�����ǻ���ϸ�����ض�����µļ������ơ������ǵķ�����ʹ��ij�ֻ���ѧϰ���������¼����ʱ��[29]��������������еIJ�����������ǿ��ܻ�����������������������������Ƶ����顣��������������£�����Ǵ�ʵ��������ѧϰģ�͵IJ������ҵ�һ����ѧģ�͵���ȡ���Ȼ�Ⲣ���ǡ������ѧ��������Ҳ���ܡ���������֮��������������һ����AIʽ���Թ⻬�Ի����Ե��ձ�����֪ʶ�ĵط����������ǹ�����ѧģ�͵������
AI��Ԥ��ᷢ��ʲô��
�Ⲣ���ǿ�ѧ��Ψһ��ɫ�����ڽ������IJ����У����ǽ�̽��������ɫ������ʷ�ϣ�ͨ������Ϊ�ɹ���ѧ��һ�����������ǣ�����Ԥ��ᷢ��ʲô����ô�������ǿ����ʣ�AI�Ƿ�Ϊ�����ṩ��һ���������õķ�ʽ��������һ�㣿
���������£����ǻ�����������AI���й�����������������һ�Ѳ��������Ȼ����AIԤ��������δ���еIJ������������������ϣ����ǽ�AI��Ϊһ����ϻ�ӣ����Dz������ڲ�������ʲô������ֻ����AI�Ƿ��������ȷ�𰸡����ǿ�����Ϊ���ǿ�������AI��ʹ�䡰û���κμ��衱����ֻ�ǡ���ѭ���ݡ��������ɱ���أ�AI�л���һЩ�����ṹ������ʹ�����ij������ģ�͡�
�ǵģ����ģ�Ϳ����кܴ������ԡ���һ�������ġ���ģ��ģ�͡��Dz����ڵġ�Ҳ��AI�ǻ���һ����������磬������ʮ�ڸ����Ե�������ֵ������Ҳ���������Ըı�����ļܹ������������������ò��ɱ���ض�����һ�����յĻ���ģ�͡�
�����ǿ�һ���dz������ӡ��������ǵġ����ݡ����������ɫ���ߡ������ܴ��������ڵ����ϵ�������˶���������ѧ�����������������ɫ���ߣ�
ͼ7
��������������һ���dz���������[30]
ͼ8
��Ȼ��ʹ������ġ���ɫ���ߡ����ݶ������ѵ��[31]���Ի�þ���ijЩȨ�ص����磺
ͼ9
��������Ӧ�����ѵ���õ���������������ԭ�������ݲ���չ����
ͼ10
���ǿ�������������ѵ�����ݷ������ò��������ڡ�Ԥ��δ����ʱ������ʧ���ˡ�
�������ʲô�������Ƿ�ֻ��û��ѵ���㹻����ʱ�䣿����������ѵ���������ӵĽ����

ͼ11
�ƺ��Ⲣû�ж���������ô������������ǵ�����̫С�ˡ������Ǿ��в�ͬ��С������Ľ����

ͼ12
�ǵģ����������ȷʵ���������������Dz����ܽ��Ԥ��ɹ������⡣��ô���ǻ�����ʲô�������һ�����������ļ������������δ�����ļ�Ȩ��ȷ�������������ʹ�ø��֣����еģ������[32]�Ľ����
ͼ13
������Щ�����Ķ�������ͻ���ˡ���ģ��ģ�͡���һ�����ͬ�ļ�������²�ͬ��Ԥ�⣬Ԥ����ʽ�ƺ�ֱ�ӷ�ӳ�˼��������ʽ��ʵ���ϣ�����û��ʲôħ����ֻ���������Ӧ��һ�������Ԫ���Ǽ�����ĺ�����
���磬���磺
ͼ14
��Ӧ�ں���

ͼ15
����ϕ��ʾ�����������ʹ�õļ������
��Ȼ���ñ��������������һ�������ĸ����Ƿdz����ϵģ����룺���ֺ���ǰ��������������ʹ�ø����ӣ��ҷֲ�ģ������Ժ�����ϣ����ṩһ�ָ��ķ�ʽ����������в����������ڸ��������ϣ�������ͬ���뷨��
���磬������һЩ�ø�ֱ�ӵ���ѧ�������������ǡ����ݡ��Ľ���[33]��

ͼ16
��Щ���Ƶ��ŵ��ǣ�ͨ���������乫ʽ�������׳�����ÿ��ģ����ʲô�������������ǵ�������һ����������Ԥ��ʱ�������⡣
��˳��˵һ�䣬����һϵ����������ʱ������Ԥ��[34]�ķ������漰�����ڡ���ϵݹ��ϵ[35]�����뷨�������ִ���ʹ�� transformer ������[36]����Ȼ��Щ�����е�һЩ�ܹ��ܺõز��������Ҳ��������������źŵ��źţ������Dz������������ڹ㷺Ԥ�⺯������ȡ�óɹ�����
�ðɣ��������dz�����̫�����ķ�ʽʹ�ú�ѵ�����ǵ������硣�Ͼ����ƺ�����ChatGPT�ijɹ�������Ҫ���Ǿ��д������ڸ��������ѵ�����ݣ�����������ij����խ���ض�����Ȼ����Щ�㷺��ѵ��������ChatGPTѧ���ˡ����Ժͳ�ʶ��һ��ģʽ��[37]����ֻ�Ǵ���խ��ѵ��������ѧ�����ġ�
��ô���ǵ������ʲô�أ�����������ϣ�����ǵ�������Ժ����ġ�������ʽ����һ����һ�������������˽⺯���������ԣ������˽������Ի�Գ��ԡ��ǵģ����ǿ��Լ���ѵ������������ij���ض��ġ����ڡ����ݣ��������������塪���������Ǻ����ļ��ϣ����߿�����Wolfram�����е�����������ѧ������
���ң��������ʣ�������������������ǿ϶��ܹ��ɹ���Ԥ��������������ߡ�����������ʹ�ô�ͳ�ĸ���Ҷ����[38]ʱһ����������������Ϊ���ǵĻ������������ǡ�����ѧ����
�����ϣ�������˵��������ǰ�������ƵĶ�������������Ϊ���ڻᷢ��������������������ʣ�����������õģ�ʵ���ϣ�����һ��������ij���ض������о���ĵ���������Զ����汾�������Ժ��ص���һ�㡣�����ڵ���Ҫ�۵��ǣ�������Ԥ�⺯�����棬�ƺ������硪���Լ������AI�������κ����Եķ�ʽ�¶����ܡ������������乹����ѵ����Χ�Ķ�����û�С����˿�ѧ����ֻ�����ֱ�ӵġ�ģʽƥ�䡱��
Ԥ��������
Ԥ��һ��������һ���ر�������������ǿ��ܻ�������ʵ���̡�����������Ȼ���еĹ��̡������и���ġ������ṹ����AI����������Щ�ṹ�ҵ�Ԥ��ġ�����㡱����Ϊ���˹���Ȼ�������ӣ����ǿ��Կ�����Ԫ���Զ��������ļ���ϵͳ��������һ���ض�Ԫ���Զ��������ʾ�������ʼ�������£�

ͼ17
�������˼��Ժ����ԡ���Ϊ���࣬���ǿ�������Ԥ����ֽ��ᷢ��ʲô������������˵���������ֽ��ᷢ��ʲô����ôAI����α����أ�
��Ȼ��������ǵġ�AI����������Ԫ���Զ���������ô�����ܹ�Ԥ��һ�У����ܼ��㹤�����ܴ������������ǣ�AI�Ƿ���Խݾ����Ա��ڲ��������м��㹤��������������ɹ���Ԥ�⡪�������仰˵��AI�Ƿ��ܹ��ɹ��ҵ������ü����Լ�Կڴ���
��ˣ���Ϊһ�������ʵ�飬����������һ����������������ЧԤ�����ǵ�Ԫ���Զ�������Ϊ�����ǵ������������һ��ֱ���˵��ġ��������ǡ��ִ��ġ����������Ա�����������59��ʹ�Լ80���������

ͼ18�������Ա�����
����ѵ��������LLM�����ơ������ռ��˴���Ԫ���Զ����ݻ���ʾ����Ȼ��ÿ��ʾ���ġ��ϰ벿�֡�չʾ�����磬�����������ɹ�������Ԥ�⡰�°벿�֡��������ǽ��еľ���ʵ���У����Ǹ�����3200���64��Ԫ����Ԫ���Զ����ݻ�ʾ�������ǵģ����ʾ������������ͼƬ���ܵij�ʼ����������������Ȼ�����dz�������64����Ԫ����64�����ġ��顱Ԫ���Զ����ݻ��������鿴����Ϊ��ͬ���ܵļ����������ĸ��ʡ�
�����Dz�ͬ��ʼ�����Ľ����

ͼ20
���ǿ����������ǿ���Ԥ�ڵģ�����Ϊ�㹻��ʱ������������ܸ㶨��������Ϊ������ʱ������ͨ�����ֲ��ѡ�����Ȼ����������ȷ������ϸ�ڲ��ԡ�
���������˻���Ϊ������ֻ��û�о����㹻��ʱ���ѵ��������û���㹻��ʾ����Ϊ���˽����ѵ����Ч���������������ķ�֮һ������ѵ���������ӵ�Ԥ����ʣ�

ͼ21
��ЩӦ����ʵ�ʽ�����бȽϣ�

ͼ22
�ǵģ����Ÿ���ѵ�������Ľ�����������ƺ������ж����ơ�����������ʧ������ѵ��������ȷʵ��ʾ��һЩͻȻ���½������������ڡ����֡���Ե�ʡ������Dz���ȷ�����硰�˽⡱��һЩ�ṹ����
����ѧϰ�dz����͵ı����ǣ����ܺܺõ�������������ȷ��������ϸ���ϵ�ȷ��ȴ���ǻ���ѧϰ��ǿ����Ե�����Ҫ��������������ϸ��ʱ������ѧϰ���о����ԡ�����������ǵ�Ԥ�������У������ǣ�һ����������ƫ�룬���������ֻ��Խ��Խ�㡣
ʶ��������
�������������ͨ������Ϊ�ġ�����ѧ���ĺ��ġ�������Ϊ���������ܹ�����Ԥ�⣬����Ϊ���������ܹ�ʶ����ɡ�����ģ�ͺ�ѹ�����ǿ����Ķ�����������չ�����ǿ������Ժ��в������⡣
��������η��ּ������[39] ����ʱ�����dz����ԡ����統���Ƕ�ijЩ��Ϊ���п��ӻ������������ϸ���Զ����ݻ���������ʶ���������ʱ������ʵ�ʲ����У�������Կ��ܲ�����ô���ԣ����ǿ�����Ҫ�ھ����ϸ�ڲ����ҵ���������AI�п��ܴ��а����ĵط���
��ij�̶ֳ��ϣ����ǿ����������ǡ��ҵ���ȷ������������ȷ����ϵ���Ĺ��¡�һ���dz�ֱ���˵��������ǣ����ǿ��Ʒdz�����ĵ��ƣ�

Image 23
ֻ�轫����ض��ĵ���ת���ʵ��ĽǶȾͻ���ʾ�����ԵĹ���[40]��

Image 24
���Ƿ���һ�㷽�������������еĹ����أ��д�ͳ��ͳ��ѧ��������A��B֮���Ƿ�������ԣ����ȣ�����ģ����Ϸ����������Ǹ�˹�����ĺ��𣿡��������д�ͳ������ѹ�������������г̳��ȱ�����Ƿ���̣���������������Щ����ֻ�������൱�������͵Ĺ��ɡ���ôAI�����ø��������Ƿ�����ṩһ��һ�㷽�������ֹ��ɣ�
˵һ���˷�����ij���еĹ��ɣ������ϵ�ͬ��˵һ���˲���Ҫָ��������������ϸ�ڣ���һ���ı�ʾ���Դ����ؽ��������ԣ����磬������ͼ�еġ�����ֱ���ϡ����ɣ�һ���˲���Ҫ�ֱ�ָ�����е��λ�ã�ֻ��Ҫ֪�������γ��˾���һ����������ơ�
�õģ���ô����������������һ������һ���������ص�ͼ�����ǿ������Ƿ���һ���漰�������ݵļ�ʾ�������п�����Ч���ؽ�ͼ��ʹ�������磬��һ�ֿ�����Ϊ���ҵ����ּ�ʾ�ļ��ɡ�
����˼·�ǽ�����������Ϊһ���Ա����������������벢������Ϊ������֡����˿��ܻ���Ϊ����һ���������������ʵ������ˣ���Ϊ��������ݱ���������������ڲ�����һ��ʼ�������顱��������ؽ��������ؼ��ǣ�ͨ���㹻��Ŀ��������������п���ѵ��������ɹ����������룬����Ϊһ���Ա��������С�
�����ڵ��뷨�Dz鿴�Ա��������ڲ�����ȡ�����������ļ�ʾ���������ݴ��������һ��������һ�㣬��������ͼ������Ҫ����Ϣ������ԭʼ���롣���һ���и��ٵ�Ԫ�أ���ô����һ����ڵĶ��������Ӧ��ԭʼ�����ij�ּ�ʾ��
����������һ�������ִ�ͼ���Ա�����[41]�����Ѿ�����ʮ�ڸ���������ͼ���Ͻ�����ѵ������������һ��è����Ƭ������ɹ������ֳ���������ԭͼ�Ķ�����

Image 25
�����м����һ����ʾ����������ٵ����ء�������Ȼ������è�ı�Ҫ������������ʾ�������ĸ���ɫͨ������

Image 26
���ǿ����⿴����èͼ���ij�֡�����ģ�͡������Dz�֪��ģ���е�Ԫ�أ�������������ʲô��˼������ȷʵ�ɹ��ز��ˡ�ͼ��ı��ʡ���
��ô������ǰ���Ӧ�õ�����ѧ���ݡ��ϣ�����������ϸ���Զ��������ġ��˹���Ȼ���̡��ϻ������أ�������һ���ɹ�ѹ���İ�����
Image 27
�������������������ô�ɹ���

Image 28
������Щ����¡��������ڻ����ļ��㲻�ɼ���ʱ���������������ѣ�

Image 29

Image 30
��������»��и������ݡ��㿴������ʹ�õ��Ա���������ԡ��ճ�ͼ��ѵ���ģ���������Щ���͵ġ���ѧͼ�����ʵ����������ͼ�ó�����è�������ͼƬ�еĽṹ�����۾��Ͷ��䣩����ģ���ǵĿ�ѧͼ��
��ô�����������ϸ���Զ���Ԥ�������һ�������Ƕ��Ա��������и������ͼ������ѵ���������أ�
�����������dz��������磬���ǿ������������������͡���������������һ���Ա�������

Image 31
���������ñ���MNISTͼ��ѵ����[42]��ʹ����Щ��ѵ���Ա�������
Image 32
��Щͼ��ÿ����28��28���ء������Ա��������м�������һ��ֻ������Ԫ�صIJ㡣��������ζ������������������ʲô���������Ϊֻ���������֣�

Image 33
��������������ǣ����ٶ��ڿ�����������������ѵ����ͼ���ͼ��ʹ�Ǵ����ּ�����ѹ���У��Ա�����Ҳ�ܹ������ؽ������������ٴ�����ȷ�Ķ��������������������͵�ͼ��������ô�ɹ�����������ֻ�Ǽ�ֽ������ؽ�Ϊ����������ѵ�����е�ͼ��

Image 34
��ô�������ϸ���Զ���ͼ�����ѵ���������أ������������ض��������ɵ�1000��ͼ��
Image 35
�������Ƕ���Щͼ��ѵ�����ǵ��Ա�������Ȼ�����dz���ι�������Ƶ�ͼ��

Image 36
�������Ƿdz����µģ����С�������粢û�гɹ�ѧϰ�������ض�ϸ���Զ����ġ���ϸ��ʽ����������ܳɹ������������Ե�ϸ���Զ����ݻ������Խ����������֣���ô���ǿ�����Ϊ����һ������ӡ����̵Ŀ�ѧ�ɾ͡����������ϣ�������ʵ���ϱ����㲻�ɼ������谭��
������ˣ���ʹ�����ܡ�������ƽ���㲻�ɼ��ԡ�����������Ȼ���ԡ��������õķ��֡���ʵ������ͨ������С�����ɼ��Ժ�С���ɡ���ˣ����磬��������ô���������ĸͼƬ�����������罫���Ϊһ�����֣���ʹ����Щ����������ͼ�����ǵõ�һ������ά�����ռ�ͼ��������ͬ��ĸ��ͼ��ֿ���

Image 37
���Բ�ͬ�����ϸ���Զ����ļ���Ϊ����

Image 38
����һ�����͵�����������ڡ������ռ䡱��������Щͼ��ķ�ʽ��

Image 39
�ǵģ��⼸���ɹ����Զ�����������1983���ȷ����������Ϊ���[43]����������ȫ����������Ȼ��ij������������һ�����ѵİ������dz���Լ��㲻�ɼ��ԡ����һ��кܶ���������룺����Ԫ�������������ڱ���������ŵ�����������������Եȣ������ǿ����ڴ�һ���������ܹ���������ɼ��Ե�һЩ���棬���ٳɹ����������еĿ�ѧ���֡�
AI�ڷ�����������
��������ĸ����У�AI�ǹ��ڿ����������ܵ��˹�ģ�⡣��ȷ��AI���ڵľ�ɹ������������Ӿ�����ʶ����������ɷ��桪�����ǹ���ӵ���ܹ��������������ı��ʵ��˹�ϵͳ���Ⲣ������Ϊ��һ����ȷ�����۶����ܹ�����һ��ͼ����è���ǹ�����Ҫ�������ǿ���ӵ��һ�������磬����ó���������ͬ�Ľ��ۡ�
��ôΪʲô����Ч�أ���������Ϊ�����粶����ʵ�ʴ��Եļܹ����ʡ���Ȼ���˹��������ϸ�ڲ��������������ͬ�������ִ�AI�Ĵ�ϲ�У��ƺ������㹻���ձ��ԣ�ʹ���˹��������ڹ�����������������ԣ��������Ӿ�����ʶ����������ɵ�����������ˡ�
�����ڿ�ѧ�����أ���һ�������ϣ����ǿ������������Ƿ���ģ�������ѧ���������¡���������һ�����棺�������Ƿ����ֱ�ӽ��ϵͳ����Ϊ������������Ȼ�С����Ƿ��п��ܣ�
���������֮�����ڡ����������ϡ���Ч������������Ϊ�����ڼܹ��������ڴ��ԣ���ôû��ֱ��ԭ����Ϊ����Ӧ���ܹ���������صġ�ԭʼ��Ȼ���̡�����ô��AI��������Ԥ�⵰�����۵�����������ʱ��������ʲô�أ�
�һ��ɵ�һ�������ǣ����ܵ������۵������������������أ���������Ϊ������Щ������Ҫȷʵ��ˡ����Dz�����������Ԥ��ÿ��ԭ�ӵ�ȷ��λ�ã�����Ȼ�����У��������е�ԭ������û�о�ȷ�̶���λ�ã����෴��������֪�����ǵ������Ƿ���С���ȷ��һ����״����������ȷ�ġ���ʶ��������������˵����-������������ȷ�Ĺ������ԡ�����Щ���ڸ����ǡ��˵����⡱����������ڡ��۲������С�����������һ�����⣬����������������ж�һ��ͼƬ��è���ǹ�����ˣ�������ǵó�����˵һ�������硰����˿�ѧ���⡱���ڵ���������۵����ǿ������ٲ�������Ϊ���ǵĴ��ԣ������۵ء���Ӧ�õijɹ�����ij�������硪��ƾ�������ƴ��Եļܹ�����ǡ���ܹ������Ķ�����
ʹ������ʽAI����ͼ��
���е���������ʽAI����ͼ��[44]���ڻ��������Ӿ���֪�IJ����ϣ������ܿ�������������Ϥ�Ķ������������������ϸ�۲죬���ǻᷢ������������������Ϊ�ġ��ۡ����

Image 40
�á���һ��ԭ������Ū�������������۵�����������ʵ����ˣ��������ܹ��õ���ʹ�Ǵ�����ȷ�Ĵ�Ҳ����ӡ����̡���ô����������������أ�����һ����Ҫ������������Ч�ؽ������ʿ���ѵ�����������������ݽ���ƥ�䣬Ȼ���ҵ����������ķ�ʽ����Щ�顰��ϡ���һ�𡣵��ǿ��ܻ�������������������Ϥ�������е�ijЩ��������Ƭ�Ρ�����������ͦ��۵��������ǣ��������ƺ���Ч�ؽ��������Dz�֪�����ڵ���������Ĺ����ԣ�������ij�ַ�ʽ�����˿�Լ���ԵĿڴ��������Dz�֪����Щ�ڴ��Ĵ��ڡ��ر����������������Լ���Կڴ��������֣����ǽ���Ч�ش�����ѧ�е��µ�һ�㡰����������磬�����ʽṹ��ij���µij�����Ԫ������
���ܴӸ�����˵�������շ����б�Ȼ���������ļ����Լ���Կڴ��������Dz������Щ�����ǹ��ĵ������п����ж�����壬Ҳ����������緽�����ҵ�����ʱ�����ж�ɹ������ǿ�������Ȼ�����練ӳ�����Ǵ��ԵĻ�����������ô����ֻ������������Ҳ�ܹ������ֵ�������ҵ���Լ���Կڴ�������ͨ���۲�ijЩ���ӻ�ͼ��
��һ����Ҫ�ĵ��ǣ����ǵĴ���ͨ��ֻ�������Ǹй��������鵽�����ݣ����Ǽ����൱����ʮ����ͼ������������������������������û��ֱ�����鵽�������˶������߿�ѧ�۲�Ͳ����豸�����ṩ�ĸ������ݡ�
Ȼ��������������ڷdz���ͬ�ġ��й����顱�¡��ɳ�����������ֱ�����顰��ѧ�ռ䡱�����ߡ�Ԫ��ѧ�ռ�[45]�������ڽ��ռ䡢�����л���֮�������õȡ�������Щ����´���ʲô���ļ����Լ���Կڴ����������������Dz�֪��������֪����Щ��Ӧ�ڡ���֪��ѧ���Ŀڴ�������ʹ���ǿ���Ԥ�������ڴ����ڣ�����ͨ��Ҳ��֪��������ʲô��
��Щ�ڴ��Ƿ�������硰�ɷ��ʡ���������Ȼ��֪������������ǿɷ��ʵģ���ô���ܻ���һЩ��ʾ��ʽ��������˵���ӻ���ʽ���������ֱ�ʾ��ʽ�У���Լ���Զ�������˵�ǡ��Զ����ġ������кܶʽ���ܻ�ʧ�ܡ����磬��Լ���Կ�����3D������ǡ��Ӿ������Եġ�����������������º����������ɵ��ƵIJ�ͬ�ṹ�����߿�Լ���Կ���ֻͨ��ijЩ������ʾ��������Щ���㲻�ܱ����������ɴ�����
��Ȼ������ϵͳ��ʾ�����㲻��Լ���ԣ���������������ʽ�У������κΡ��ݾ��������������������������ʽ����˵���Dz��ɷ��ʵġ����������ʵ��ǣ������ڼ����Լ���Կڴ�ʱ���������Ƿ��ܹ���������
�������ٴ����һ����ʵ��û�С���ģ�͵�ģ�͡���ij���ض����͵������罫�ܹ����ز���ijЩ�ض�����ļ����Լ���ԣ���һ�ֽ��ܹ����ز����������ࡣ�ǵģ������ǿ��Թ���һ���������������κθ������ض����������ڲ�ij��һ��ļ����Լ����ʱ������Ҫ��ø��ࡪ�������ܵõ��Ķ��������ɱ����ȡ����������Ļ����ṹ��
������������һ��������ɹ������ض�ϵͳ�в��������Լ���ԡ����Ƿ���ζ��������Ԥ��һ�У�ͨ�����ǡ���Ϊ�������Ǽ����Լ����ֻ��һ�����ڴ����������ڡ����桱�кܶ���㲻��Լ���Ժ͡����⡱��
ʵ���ϣ������������������۵������������С�������һЩ������Ϊ�ṹ��Լĵ����ʡ���������Ԥ�⣨��ɫ��������ʵ��������ɫ�ܣ��Ľ���൱�Ǻϣ�

Image 41
������������Ϊ�ṹ�����ӵĵ����ʣ��Ǻ϶�ͨ��������ô�ã�

Image 42
��Щ����������������ѵ��������ĵ��������ơ������ڷdz���ͬ�ĵ����ʡ����������������������еĵ������أ�

Image 43
����֪�������������������Σ��ر�������С����⡱�����������ɹ��������ǡ�����Ȼ����������������ѧ��ͨ�����ֵġ����������ʡ�������ijЩ����������������Ӧ���ڡ�������ѧ�ġ���������ʿ����ǡ�����ƽ�ġ�������Ȼ��������Ӧ������ϵͳ�У�����ѧȷʵ��Ч�ز��������ٶ��ݵġ���������ʡ�����
��AI�ⷽ��
�ڴ�ͳ����ѧ��ѧ�У����͵������ǣ�������ϵͳ�ķ��̣�ͨ�������Щ�������ҳ�ϵͳ����Ϊ���ڼ��������֮ǰ����ͨ����ζ�ű����ҵ�ij�֡������ʽ����ʽ[46]��Ϊ��������������˼��������������һ�ַ�����������ɢ�ġ���ֵ���ơ���Ȼ����ij�ַ�ʽ����ⷽ�̡�Ȼ����Ҫ�õ���ȷ�Ľ����������Ҫ�ܶಽ��ʹ����ļ���Ŭ������ô�����ǣ�AI�ܷ������һ���̣��ر��ǣ�AI�ܷ�����ֱ�Ӵӷ��̵ij�ʼ�����������⣿
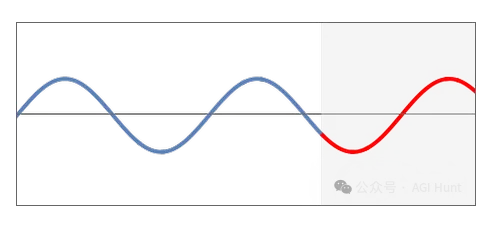
�������Ծ������ѧ��������Ϊ������������[47]������������������ƽ�����������µij�ʼλ�ú��ٶȣ���Щ��������ʲô�켣�˶������ںܴ�Ķ����ԣ�ͨ��Ҳ�ܸ��ӣ��������������Ϊʲô��˾�����ս��[48]��

Image 44
���������ѵ��һ��������������ʾ���⣿�������κ��ض��������������ǽ�ʹ��һ���൱ֱ�ӵġ�����֪�������磺

Image 45
���ǽ���ʼ�������룬Ȼ��Ҫ��������һ���⡣��������������һЩʾ������ȷ�Ľ�������ɽ�dz�ı���·����ʾ��

Image 46
���켣��Լ�ʱ����������ֵ��൱�á����������ø���ʱ�����ı��־ͻ�Խ��Խ����������硰�ɹ���ס���˼����������֪���ڸ����ӵ�����¸���ô�������գ���������������Ԥ��Ԫ���Զ����ݻ������ܻ��е������۵���ʱ�����ķdz����ơ�
�ǵģ������Ǽ��㲻��Լ���ԵĹ��¡�Ҫ��һ���Եõ��⡱ʵ������Ҫ����ȫ�ļ����Լ���ԡ��������˿����������֪����ô������ԭ�������ܵõ���ġ������ʽ����ʽ�����ּ��������˼����Լ���ԡ�����ʮ��������һֱ��Ϊ������������Ķ���ʵ���ϳ����˼��㲻��Լ���ԡ�
��Ȼ������������ܹ����ƽ����⡱���������ɽ⣬��ʵ���Ͼ�֤���˼����Լ���ԡ����ǣ������������ֵ������������������ʧ��Ϊ���������еļ��㲻��Լ�����ṩ����һ��֤�ݡ���˳����һ�䣬��Ȼ��������ȷʵ��ʾ���Գ�ʼ����������������[49]�����ⲻ���������Ҫ���⣻���ǹ켣�����ڸ����ԡ���
�����Ѿ�֪������Ԫ���Զ�����������ɢ����ϵͳ�����˼��㲻��Լ���ԡ����ǿ��ܻ���������ϵͳ���������ַ���������ϵͳ�����и���Ľṹ���⽫ʹ���DZ�����㲻��Լ���ԡ�ȷʵ����Ȼ�����磨����ͨ����ʽ�У��漰�����������ǿ��ܻ���Ϊ�����ܹ���ij�ַ�ʽ��������ϵͳ�Ľṹ���Ӷ��ܹ�Ԥ�����ǡ�����֪�ιʣ����㲻��Լ���Եġ�������̫ǿ�����ջᳬ���������������
������ˣ���������������ⷽ��֮�����������Ȼ���кܴ��ʵ�ʼ�ֵ����ͳ����ֵ���Ʒ��������Ǿֲ������еģ�����ͨ��������Ӧ�ģ�������������Ը����ش���������Ĵ��ڡ�����ij�������ϡ��˽��������Ϊ���С����ܹ�����Խ���ǡ������⣬�������dz������ķ��̣������ڻ�����ѧ��ϵͳ�����У�ʱ��������ͨ�����ԡ��������еķ��̲����������Ĵ�����������ͳ����ʵ���ϱ������������Щ���̡�
���������漰���ַ��̡�������ʵ�����������ƫ�ַ��̣�PDE�������в������ǵ������꣬������������_f_[_x_����ʱ���ݻ����ǵģ�����������ʹ�������磬ͨ����ʵ���о������������ơ������㲻��Լ�����أ���ʵ���У�����̺���������繤��Ŀ�ģ���������������һ����˵��ȷʵ����[50]�������������������������У����������ڼ��㲻��Լ����ʱ�����ղ���ָ����������ֵúܺá������漰���������ǵ��˵�Ŀ��ʱ����ǰ�����۵����������У�������ܻ���á�
��Ϊһ�����ӣ�����Ԥ�����������գ�����ȫ�ǹ������嶯��ѧ��PDE���ǵģ����������йص�����Ӱ��ȣ���һ�ַ�����������ֱ�Ӻͼ���������ЩPDE������һ�ַ�������������ֻ�ǡ�ѧϰ���͵�����ģʽ����������������ѧ�ұ���������������Ȼ�������磨�е������۵���������ͼƴ����Щģʽ����Ӧ�κγ��ֵ������
�⽫�ж�ɹ�������ȡ���������ڿ�ʲô������ijЩ�ض������������ʾ���൱��ļ����Լ���ԣ����Һ�����Ԥ�⣬����ͨ�������硣������������ǹ��ĵ��������棬���ǿ��ܻ�ó�������������ֵúܺá���������ǹ��ĵĶ�����������������𣿡���û�д��������Լ���ԵĿڴ�����ô������ͨ������ɹ�Ԥ�����������Ҳ��ò�����ʽ���㣬������Ҫ�ܶ�ʵ�ʵļ��㡣
AI���ڶ����
��ĿǰΪֹ���������۵Ĵ����AI�Ƿ���������ǡ����������ݾ�ijЩ������̡��������������������Ȥ���ǽݾ���Ϊ�������̵Ķ���������ÿһ������������ܵĽ����Ŀ���������ҵ�ij�����ս����·����
��Ϊ�������̵�һ�������ӣ������ǿ���һ�����ַ��������еĶʽϵͳ����ÿһ�����������п��ܵķ�ʽӦ�ù���{A -> BBB, BB -> A}��

Image 49
����������ã����ǿ�����һ�����⣺��A��BABA�����·����ʲô����������ʾ������£�����ͨ����ͼ����ʽ����·��Ѱ���㷨���ɼ�����𰸣�
Image 50
������������ѭ���һ��ģʽ������Ϸͼ���ҵ���ʤ����[51]��ͨ��һϵ���ƶ��ڿ����Ե�ͼ���ҵ��������ķ���[52]���ڸ���ijЩ����������£��ҵ�������֤��[53]���ڸ���ijЩ������Ӧ������£��ҵ���ѧ�ϳ�;����һ����˵���ڽ���漰���ࡰ��ȷ���ԡ�����·����NP�����н��һ������⡣
������չʾ�ķdz��������У����ǿ����������������ʽͼ�����ڴ����ʵ�������У�ͼ��������������ˣ���սͨ�����ҳ���ν����ƶ��������������п����Ե�ͼ�������ķ���֮һ����ͼ�ҵ�һ�ַ���Ϊ��ͬ�Ŀ���״̬����������������ҽ�����У����磩��߷�����·�������Զ�����֤��[54]�У�ͨ���������ǡ��ӳ�ʼ�������¹������͡������ն������Ϲ���������ͼ����·�����м������ĵط�������һ����Ҫ���뷨�ǣ�����Ѿ�ȷ���˴�X��Y��·��������Խ�X -> Y��Ϊ�����е��¹���
��ôAI����ṩ���������ȣ����ǿ��Կ��ǽ������ַ����ʽϵͳ������ѵ��һ���൱������ģ�͵�AI�����ɱ�ʾ·���ı�����У���������ѧ��������֤�������뷨�Ǹ�AI�ṩһϵ����Ч�����У�Ȼ�����һ���µ����еĿ�ͷ�ͽ�β��Ҫ��������м䡣
���ǽ�ʹ��һ���൱������ transformer ���磺

Image 52
Ȼ������ͨ������������Ч·���ı�����У�E��ʾ��������ǡ���
Image 53
�Լ���ʾ·�������ڵġ��������ӡ���ѵ������
Image 54
����������ѵ�������г��ֵġ�ǰ��������ʾ��ѵ���õ����磬Ȼ���ԡ�LLM��������������¶��£�������ѡ������ܵġ���һ����ǣ��������У�

Image 55
һ��ʱ���ڣ������ֵ÷dz��á������ڽӽ�����ʱ��ʼ���������ɫ�����ʾ����ͬĿ�ĵصı��ֲ�ͬ������Щ�����һ��ʼ�ͳ�����

Image 56
������ø��ã�һ�ֿ���������ÿһ��������������Ϊ����ܵı�ǣ�������һ�ѱ�ǡ����Ӷ�ʵ��������һ����LLM�����������ܵ����Ķʽϵͳ���������е㻬���ؽ����Ϊ������LLM[55]������������̽��������ʷ·������
��˳����һ�䣬���ǻ���������ѵ�����ͬ����Ȼ����������ѧϰ������һ����Ԥ��ʾ����ָ�����������κ��ض������ʹ�õĹ���
LLM������һ�������ǣ������ɵ�����ͨ���������ھֲ��Ǵ���ġ�����һ��Ԫ�ز��ܸ��ݸ����Ĺ����֮ǰ��Ԫ�ظ��档
����������Բ�ȡ��һ�ַ�����������AI��ͼ����������������С�����������ֻ��ѡ����һ��ȥ�����ʼ����ѭһ��ָ���Ĺ���Ȼ��ѵ����һ����Ŀ��ʵ��������AIѧϰͼ�ľ��뺯��[56]�����仰˵�����ܹ�������κ�һ���ڵ㵽��һ���ڵ�����·���ж�����������ĺ��������Ͳ�������ѭ�����ڡ���½�·�����Ķ���������ÿһ��ѡ��AI�������ܼ��ٵ�Ŀ�ĵؾ�����ƶ���
�����������ʵ��ʵ����һ�㣿һ�ַ�����ʹ�������������������� transformer���죩��ʵ������������Ƕ�룬һ������Դ�ڵ㣬һ������Ŀ�ĵؽڵ㡣����Ȼ����ЩǶ����������ѧϰһ�������������ڵ�֮��ľ��룺

Image 57
�ڶʽϵͳ��ѵ������һ�����磬ͨ�������������Դ��Ŀ�ĵؾ�������ӣ��Լ������Ƿ�Ϊ������ָʾ���������ǿ���ʹ������Ԥ��ʽϵͳ�ľ�������һ���֡����Ƿ��֣�Ԥ��ľ�����ʵ�ʾ������ƣ������Բ�����ͬ�ģ�

Image 58
������ˣ����ǿ���������ÿһ��������������Ԥ���ÿ������Ŀ�ĵصĹ��Ƶ�Ŀ�ĵصľ��룬Ȼ��ѡ���ߵ���Զ�ġ���

Image 59
ÿ���������ƶ������ﶼ����Ч�ģ�����ȷʵ���յ��������ǵ�Ŀ�ĵ�BABA�������ܲ�������������·����һ�㡣����ʹ����û���ҵ����·������������Ȼ�ɹ���������������ij�̶ֳ����������ǵġ������ռ䡱��ͨ�����ȿ��ǽڵ㲢ֻ������ɫ�ߣ�

Image 60
��һ���������ǣ�����������ʹ�õ��ض�������������������ԣ��κθ����Խڵ�֮�������·��ʼ�վ�����ͬ�ij��ȡ�����������ҵ��κ�·���������Ա���Ϊ�ǡ���̵ġ���һ��������{A -> AAB, BBA -> B}û��������ԣ�һ��Ϊ�������ѵ������������ܻ��ҵ�������ȷĿ�ĵص�·���������Ǿ����̵ܶ�·������
������ˣ���������һ�������Dz���ȷ���⽫�����Ч����������ܻ��������ߵ�̫Զ��ƫ�����������������������ǵ�һ��û��·��ͨ��Ŀ�ĵصĽڵ㡪����ˣ����������ȡ�ý�չ�����ǽ����ò������ڴ�ͳ�㷨����֮��Ķ�����
�������ڼ�����£����ַ�������Ч���ܺá���AI���Գɹ��ҵ�Ӯ����Ϸ��֤�������ȵ�·�������Dz���ָ����������Ч��ԭ����������������㲻��Լ����[57]�������ڵ����������̡߳��м��㲻��Լ���Կ�����ζ��û�нݾ���ͨ��ͨ������IJ��衱���ڶʽϵͳ�У�����㲻��Լ���Կ�����ζ��û�нݾ���ͨ����ѭ���м����̡߳���Ȼ�����翴����Щ���պϲ���һ��
����ʹ�������ԭ���Ͽ��ܷ��������������������Ȥ�������ʵ�����Ƿ�ᷢ��������Ϸ������[58]�У���������ϣ�����ѣ�����Ҫ̫��ȥ��Ӯ�������漰����ѧ��֤������ʱ������������ϰ������İ���ͬ��ϣ�������ѣ�����Ҫ̫�ѡ�Ȼ�������漰����ѧ�о�����ѧǰ��ʱ���������������κ�������Լ��������ǣ�Ȼ������ڴ���Զ���㲻��Լ���ԡ���ʹ��AI����̫�������ѡ�
���������һ����ע��������ѡ����ѧ���·����йء����ǿ��Կ���Ԫ��ѧ�ռ�[59]ͨ����һ����Ķʽͼ�д��������������������������������������۵������������ϸ��Զ��������ѧ����Ϊ�ġ�����ѧ�����෴����ѧ���������ƺ��ڡ����߲�Ρ�������ѧ������һ��������ǡ����Եطּ����������Ԫ��ѧ�������������ǿ��������������������������ѧ�о��������壬��ʹ�������桱�кܶิ�ӵķ����˶���
��ôAI�Ƿ���������������֡����嶯��ѧ����������ѧ�����ܿ��ԣ�����Ҫ���ṩ����Э����������Щ���������Ķ�����������Wolfram����[60]�С���������Ҫ����������LLM���[61]���������ǵķ���ʽ�����ʽ�������ԡ�ֻҪ����������������ѭ֮ǰ��������Ľṹģʽ�����ǿ���������LLM�����Ķ����ṩ��������ֻҪ���DZ���Ķ����������¡����������ǵļ�������û��̫�ࡰ���塱����������һ����֮ǰ����������ѵ����AI���ж��������෴������ʵ������Ҫ��һЩ����㲻��Լ��ļ��㣬��������̽��ijЩ��������[62]���²��ֺ�ruliad[63]��
̽��ϵͳ�ռ�
�������ҵ�һ����X��ϵͳ�𣿡��������кܳ�ʱ��Ȼ��ֹͣ��ͼ���������һ������������������Ԫ���Զ��������߾���ij���ض����ԵĻ�ѧ���ʡ�
����һ������������Ϊֹ���۵����в�ͬ�����⡣�����ǹ��ڲ�ȡ�ض����鿴������ʲô�����ǹ���ȷ�����ܴ��ڵĹ�����ijЩ�����
����һЩ���ܵĹ���ռ䣬һ�ַ��������������ij��������˵������Ψһ��������ƫ���ķ�������������������ʲô��Ҫ���ֵĶ�������ʹ���Dz�����������Ȼ����ʹ�����������Ҳ��Ҫһ�ַ�����ȷ���ض���ѡϵͳ�Ƿ������趨�ı�������������Ԥ���������⡪���������۹����������á�
�ðɣ��������ܷ����������ø��ã������Ƿ�����ҵ�һ�ַ�����ȷ��Ҫ̽����Щ��������ز鿴ÿ������һ�ַ��������������������ͨ����Ȼѡ������飺���ض�����ʼ��Ȼ���ı���������������ģ���ÿһ������������õĹ�������������
�ⲻ����������������϶���ġ�AI�����������ǡ��Ŵ��㷨�������������е��������������ѵ��ѭ��������������������ȡ���ڹ���ռ�Ľṹ[64]�������������ڻ���ѧϰ�п���������[65]���ڸ�ά����ռ������������ֵñ��ڵ�ά����ռ��и��á���Ϊά��Խ�࣬��Խ�����ס����ھֲ���Сֵ�С������ҵ�ͨ�������ù���·��
һ����˵���������ռ���һ�����ӵķ���ɽ������ô����������ȡ�ý�չ��������ǿ��ѧϰ������AI����������ϸ����ȡ�����裩��������෴�����൱ƽ̹��ֻ��һ�������������߶����������ô�������������ҵ���������ô����ռ�ĵ��ͽṹ��ʲô��ȷʵ���������������ռ��������൱��ά������ֻ���ʶȡ�����������£�����Ѱ�Ҿ��г�ֹͣʱ���Сͼ���[66]���������С������Ľ��������������������и���ά��ʱ���ƺ����㲻��Լ���Ա�֤�ˡ��㹻����ľ��ۡ����Ա��������Ա������ã��������ǽ������ڻ���ѧϰ�п�����������
��ôAI�أ��Ƿ������AIѧϰ��Ρ�ֱ���ڹ���ռ�����ѡӮ�ҡ����������κ����̣��Ƿ�����ҵ�һЩ��Ƕ��ռ䡱���ڸÿռ���������Ҫ�Ĺ������г������������Ч�ء�Ԥ��ʶ�𡱸����ǣ����գ���ȡ���ڹ���ռ���ʲô���ӵģ��Լ�̽�����Ĺ����Ƿ��Ȼ�ǣ��ࣩ���㲻��Լ��ģ������������ǹ��ĵķ������ͨ�������Լ��Ĺ��̽���̽������˳����һ�䣬����ʹ��AIֱ���ҵ������ض����Ե�ϵͳ�е�����ֱ�Ӵ��������������磬����������ѵ������
�����ǿ�һ������Ԫ���Զ����ľ�������ӡ������������ҵ�һ��Ԫ���Զ��������ӵ�ϸ����ʼ������ʼ����������������һ��ʱ�䣬�����ض���ȷ�в������ʧ�����ǿ��Գ���ʹ�÷dz���AI����������������������⣺��һ���������ʼ��Ȼ����ÿһ������һ�������ġ����������ÿ����������ı�һ��Ԫ�ء���Ȼ������Щ�����С���õġ�������������ҵ�һ������ǡ��50���Ĺ������Ƕ��塰��õġ�Ϊһ������ġ���������50�ľ�����С����
���磬�������Ǵ����ѡ��ģ���ɫ������ʼ��

Image 63
���ǹ���Ľ������У�����ֻ��ʾͼƬ�����ֵ���������ǣ�

Image 65
������ǿ���Щ�������Ϊ�����ǻῴ��������һ����̫��ϣ���Ŀ�ʼ֮�����dzɹ���������һ�����ϡ����ǡ��50�������Ĺ���
Image 66
����չʾ����һ�����ѡ��ġ�����·������������·���ᷢ��ʲô������100����һ��·���ġ���ʧ������ݱ䣺

Image 67
���ǿ���������ֻ��һ����Ӯ�ҡ��ﵽ����ʧ������������·���У�����������ס����
���������ᵽ�ģ�ά��Խ��Խ�����ױ���ס�����磬������ǿ�4ɫԪ���Զ�������������64������27������Ԫ�أ�����Чά�ȣ����Ըı䣬����������£��������·�����ߵø�Զ��

Image 68
�����и���ġ�Ӯ�ҡ����磺

Image 69
��������������ΰ������ǣ�ֻҪ���ǿ�����������Ԥ��Ԫ���Զ����ݻ������ǿ��ܻ������һ�ַ�ʽ������ʵ���ϼ���ÿ����ѡ�������ʧ�������ܴ���������һ���п����ģ����㲻��Լ���Կ��ܻ�������һ�㡣��һ���������ǡ�����ǰһ���еġ������ǿ��Գ���ʹ������������������ÿһ���н�����Щ����ı䡣�����ܼ��㲻��Լ���Կ���������ʹ���顰�㹻����������������Dz��ᱻ��ס����Ҳʹ�����������Գɹ��������ǡ�������·����
��ѧ��Ϊ����
�������������������Ϊ��ѧ�ı��ʡ��������ڴ�ͳ�ϱ�ʵ��ʱ�����ǹ��ڰ������ϵĶ�����ij�������������˼������ʽ���б��ʵ���ϣ�����ϣ����ѧΪ�����������ṩһ������ɷ��ʵ���������������Ȼ���С�
���㲻��Լ���Ե��������ڸ������ǣ��������Ǹ��������ܵġ���ÿ����һ�������Լ��Ŀڴ�ʱ����ζ��������һ�������ڷ�����������ij�ּ������������ּ�������������Ժ�������������磬�����Լ�����Ҫ�������֡���ʽ�����������������������ԣ����ǿ��Խ�����Ϊ����һ���ɹ��ġ������εĿ�ѧ���͡���
AI�ܰ��������Զ����������Ľ�����Ϊ�ˣ���������ij�̶ֳ�����һ���������������ģ�͡����Լ�������������Եȱ����������⡣˵��������100�����㲽��������������û�ж���ô���Ϊ�˻��һ���������εĽ��͡���������Ҫ����ֽ�ɿ����������յIJ��֡�
���磬����һ����ѧ֤��[67]���Զ�����֤��[68]���ɣ�

Image 70��Automated theorem�Cproving table
���������������֤������ȷ�ģ���Ϊÿһ��������֮ǰ�����ݡ�������������һ���dz���������Ķ���������û����ʵ�ġ���������������ôҪ��������һ��������Ҫʲô�������ϣ�������ҪһЩ��Ϥ�ġ����ꡱ����������������֪��������������Ȼ������û�������Ķ�������Ϊ���ǿ�����һ��ͨ����δ֪��Ԫ��ѧ����[69]����֤������ˡ��������Ƿ���AI���������ֽ��������ѧ����û���㹻��ԭ���������Ǵ���һ�������ε�������
��ʵ���У���֤���еIJ���֮��ġ�Ԫ��ѧ���롱��Խ϶�ʱ����Ϊ���Ը���һ�������εĽ�������ʵ�ġ�������ķdz���Wolfram|Alpha[70]�ڲ�����𰸵�����[71]ʱ�����ġ�AI�����ṩ�����𣿿��ܿ��ԣ�ʹ��������������ڶ���AI���������ķ�����
˳����һ�£����ǵ�Wolfram���Ե�Ŭ��Ҳ�а�������Ϊ���Ǽ�������[72]�������뷨�ǽ��������ļ��㹤���顱��Ϊ���ù��첶������ij��������˵��������ԵĹ������ǹ���ʶ����������յļ��㺽�ꡱ�����㲻��Լ���Ը������ǣ�������Ϊ���м����ҵ������ĺ��ꡣ�����ǵ�Ŀ�����ҵ�����ǰ��ʽ�͵�ǰʵ���ĺ��꣬�����巽��Ϳ������չ��Щ�����������ա���������֪��ʲô����������֪ʶ����ʷ�ݱ�����ġ�
֤���ͼ������Գ��������ֽṹ���ġ���ѧ�����������ӡ�һ��DZ�ڵļ����ӡ�������ѧ��ͳ���������һ������Ĺ�ʽ��������һ�����ɡ���������ָ���͡����ȵȡ�AI�����ṩ��������FindFormula[73]�����Ĺ����Ѿ�ʹ�û���ѧϰ�����ķ���������ת��Ϊ�������Ĺ�ʽ����

















