我们都知道FPGA的优势就是做硬件加速,可谓是什么火就去加速什么,前几年很多人也在用FPGA来加速AI,主要就是做CNN/DNN,但并没有掀起什么水花。这两年随着AI大模型的发展,GPU无论在训练还是推理方面,都表现出了极大的优势,但最近加州大学发布的这篇文章,可能会影响这个格局。
最近加州大学发布了一篇文章,文章介绍了一种名为MatMul-free语言模型的新技术。

image-20240626195810162
该技术能够在大规模语言模型中完全去除矩阵乘法操作,同时保持强大的性能表现。通常,矩阵乘法(MatMul)是大型语言模型计算成本的主要组成部分,并且随着模型的嵌入维度和上下文长度的增加,这一成本会进一步升高。然而,通过研究,作者们展示出即使在十亿参数量级的模型上,他们提出的无MatMul模型仍能与最先进的Transformer模型在推理时消耗大量内存的情况下取得相当的性能。
实验结果表明,在至少27亿参数的规模下,MatMul-free模型的表现与传统全精度Transformer模型相当。此外,当模型尺寸增大时,无MatMul模型与全精度Transformer之间的性能差距逐渐缩小。为了提高GPU效率,研究人员提供了这种模型的优化实现,相比未优化的基线,训练期间的内存使用减少了高达61%。而在推理阶段,通过使用优化的内核,模型的内存消耗比未优化模型减少了超过10倍。
为了准确评估架构的效率,团队还构建了一个基于FPGA的定制硬件解决方案,我们这篇文章重点关注这部分。
为了检验无矩阵乘法语言模型(MatMul-free LM)在定制硬件上的功耗和效能,团队采用SystemVerilog创建了一个FPGA加速器。设计框图如下图所示。
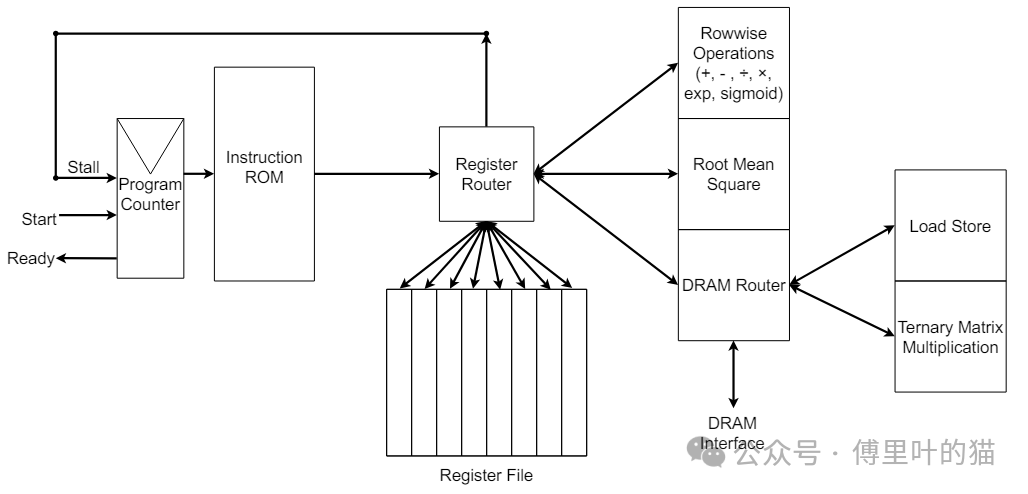
image-20240626200331889
此设计包含四个功能单元:“逐行运算”、“均方根”、“加载存储”以及“三值矩阵乘法”,它们各自支持简单的乱序执行。他们还编写了一个定制的汇编器,用于将汇编文件转换成指令ROM。以下是自定义指令集的详情:
LDV:从内存加载向量
SV:向内存存储向量
ADD:逐行加法
SUB:逐行减法
MUL:逐行乘法
DIV:逐行除法
EXP:逐行指数函数
SIG:逐行Sigmoid函数
NORM:使用均方根进行归一化
TMATMUL:三值矩阵乘法
寄存器路由器负责将进入的指令分派至可用的寄存器。寄存器文件由8个寄存器组成,每个寄存器在独立的SRAM数组中存储一个向量。每个寄存器的SRAM数组具有读写端口,一次最多分配给一条指令。如果某条指令请求访问忙的功能单元或寄存器,程序计数器将暂停直到该功能单元或寄存器释放。若两条指令不会互相阻塞,则它们可以并行执行。
“均方根”功能单元使用专门的硬件算法来保持精度,它分三个阶段运行。第一阶段将目标向量复制到内部临时寄存器,并利用查找表对每个元素做平方运算。第二阶段通过分治法平均相邻向量元素,得到均方根的结果。第三阶段则通过将原向量的每个元素除以均方根结果来进行归一化。采用分治法进行平均化,而非常规的滚动求和后大除法,这样可以大幅减少舍入误差。
“三值矩阵乘法”功能单元接收一个三值矩阵的DRAM地址,然后对该指定向量执行TMATMUL操作。我们的架构将所有三值矩阵完全置于DRAM中。执行TMATMUL指令时,SRAM FIFO会同时填充来自DRAM的顺序读取结果,并通过节能的三值加法操作清空。
目前,所需的三个TMATMUL指令占据了总执行时间的绝大部分。未来的工作中,他们将引入并行性和缓存机制来优化TMATMUL的执行时间。
MatMul-free令牌生成FPGA核心的资源利用情况和性能指标如下:当前实现中,三值矩阵乘法操作是导致延迟的主要因素,但在本地DDR4桥接器中并未观察到瓶颈现象。在未来的实现版本中,这个功能单元将会得到优化,而DDR接口很可能成为主要的性能瓶颈。
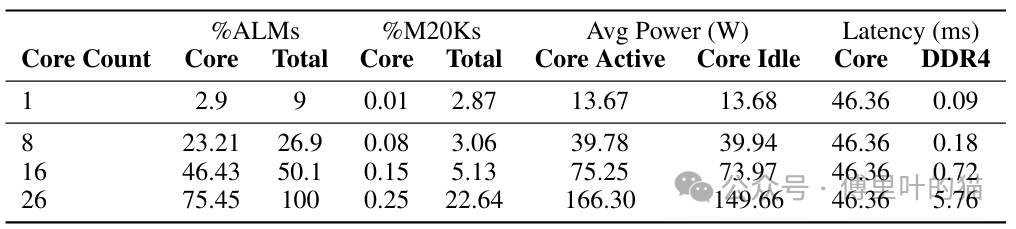
image-20240626200647495
具体来说,MatMul-free令牌生成FPGA核心在资源使用上,以ALM(Adaptive Logic Module)为例,当核心数量为1时,使用了2.9%的ALM资源;随着核心数量增加到26时,ALM使用率上升到75.45%。同时,M20K(memory block)的使用率在所有测试配置中保持稳定,大约为46.36%,这表明核心数量的增加并没有显著影响到片上内存的使用。在性能方面,单个核心在d=512时,完成一个数据块的前向传播需要43毫秒,工作频率为60MHz。此外,随着核心数量的增多,整体功耗和延迟都相应地增加,但DDR4接口的活动功耗占比相对较小,暗示了在多核心配置下,DDR4接口可能成为制约性能提升的关键因素。
尽管当前的三值矩阵乘法操作是造成延迟的主要原因,但随着核心数量的增加和功能单元的优化,DDR4接口的数据传输速度将成为限制整体性能的关键瓶颈。因此,未来的设计中需要重点考虑DDR4接口的优化,以确保数据传输的速度和效率,避免其成为系统性能的瓶颈。
无矩阵乘法的令牌生成核心的寄存器传输级(RTL)实现部署在Intel FPGA DevCloud上的D5005 Stratix 10可编程加速卡(PAC)。当维度d等于512时,核心能在一个43毫秒的周期内完成一个数据块的前向传递,并且运行时钟频率达到60MHz。表2展示了单核单块(N=1)的资源使用、功耗和性能详情。其中 ALM Core代表核心逻辑所使用的全部自适应逻辑模块(ALM)的百分比,而ALM Total则涵盖了核心、额外的互连/仲裁逻辑以及FPGA接口管理器的"外壳"逻辑。'M20K'指的是存储块的利用率,显示了核心的数量受制于ALM而非芯片上的内存(就DDR实施而言)。我们只实现了一个令牌生成核心,估算了平台可以容纳的核心总数及其相应的功耗、性能和面积影响。这是最简单的情况,核心每次从内存中接收8位数据。
单核实现展现出极低的动态功耗,几乎与核心处于非激活状态时测量到的功耗无法区分。每个核心需要访问DDR4接口和MMIO桥接器用于主机控制。在这个实现中,大部分资源被分配给了提供的"外壳"逻辑,只有0.4%的可编程逻辑资源专门用于核心互连和对DDR4接口/MMIO的仲裁逻辑。如前所述,核心延迟主要是由于三元矩阵乘法功能单元执行时间较长。
如果使用完整的512位DDR4接口并并行化占据核心处理时间99%的TMATMUL功能单元,预计可实现约64倍的加速,同时维持相同的时钟频率,无需额外优化或流水线化,如表3所示。对于包含3.7亿参数的模型,其中L等于24,d等于512,总预测运行时间为16.08毫秒,吞吐量约为每秒62个令牌。而对于包含13亿参数的模型,L等于24且d等于2048,预测运行时间为42毫秒,吞吐量为每秒23.8个令牌。这种效率达到了人脑阅读速度,且功耗与人脑相当。这是针对单核处理单批次数据的情况,可以通过流水线处理单核或增加核心数量来显著扩大规模,平均功耗几乎没有增加或随核心数量增加而增加。
多核实现的延迟估计是通过扩展单核实现的开销,并考虑到DDR4通道上竞争增长所需的逻辑调整产生的。每个核心连接到四个DDR4通道之一,附加到同一通道的每个额外核心将使该通道所需的仲裁和缓冲逻辑加倍。因为主机和核心共享DDR4通道,此开销将与连接到通道的核心数量成比例增长。为缓解这种情况,未来的工作可能会给核心和功能单元添加更多的缓存优化。核心延迟是从开始到准备就绪的计算时间,DDR4延迟则是从主机向PAC本地DDR4传输输入向量所需的时间。
多核实现的功耗估算基于单核实现测得的功耗进行扩展。空闲功耗是通过扩展所有附加逻辑的总估计资源开销至平台外壳的恒定空闲功耗估计得出的。单核活跃功耗按额外的仲裁、互连和核心开销进行扩展。我们假设所有实现具有恒定的时钟速率。
值得注意的是,FPGA的实现是自顶向下在RTL层面完成的,存在很多可以添加的优化。例如,我们没有使用任何供应商提供的IP,也没有突发DDR事务,这两点都将显著加快操作。这种方法是为了实现尽可能通用和跨平台的评估。

image-20240626200839860
我们总结一下该论文中FPGA相比GPU的优势:
功耗效率:
FPGA实现在处理MatMul-free语言模型时展现了极低的动态功耗,几乎与核心不活动时测得的功耗相同。这意味着在执行模型时,FPGA能够以非常低的功耗运行,这是GPU难以达到的效率。
定制化硬件操作:
FPGA能够执行轻量化操作,这超越了GPU的能力。FPGA的这种能力使得它能够更有效地处理三值运算(ternary operations),这是MatMul-free模型的一个关键部分。
硬件加速:
在论文中,FPGA被用来创建一个定制的硬件加速器,该加速器能够优化MatMul-free模型的执行。这种加速器能够利用FPGA的并行性和可编程性,以实现模型的高效处理。
资源利用效率:
FPGA设计中,大部分资源被用于提供的外壳逻辑,而仅有一小部分的可编程逻辑资源用于核心互连和仲裁逻辑。这表明FPGA能够以较少的资源实现高效的模型执行。
潜在的性能提升:
如果使用完整的512位DDR4接口并并行化占核心处理时间99%的三值矩阵乘法(TMATMUL)功能单元,预计可实现大约64倍的加速,同时维持相同的时钟频率。这表明FPGA在特定的优化策略下,能够显著提升模型处理速度。
内存接口优化潜力:
FPGA在当前实现中,内存接口(如DDR4)并未成为瓶颈。然而,随着核心数量的增加,DDR4接口可能会成为性能的主要限制。FPGA设计中可以考虑额外的缓存优化来缓解这个问题。
可扩展性:
FPGA设计可以通过批处理和核心数量的增加来显著提升处理能力,同时平均功耗几乎不变或者按比例增加。这意味着FPGA设计在处理大规模模型时具有良好的可扩展性。
综上所述,FPGA在处理MatMul-free语言模型时,相比GPU具有更低的功耗、更有效的资源利用、以及更好的性能和可扩展性潜力。这使得FPGA成为了实现高效、低功耗和定制化语言模型处理的理想平台。所以,你看好FPGA能重回AI舞台吗?

















