ОпЩэШЫЙЄжЧФмЃЈEmbodied AIЃЉЕФГіЯжЃЌе§ЪЧЖдетвЛОжЯоЕФЛигІЁЃЫќЧПЕїжЧФмЬхБиаыЁАгаЩэгаИаЁБЃЌВЛНіФмРэНтгябдКЭЗћКХЃЌЛЙвЊФмИажЊЛЗОГЁЂзіГіОіВпЃЌВЂЭЈЙ§ааЖЏИФБфЪРНчЁЃЛЛОфЛАЫЕЃЌОпЩэжЧФмЪЧШУ AI ДгЁАжНУцЩЯЕФДЯУїЁБзпЯђЁАЯжЪЕжаЕФФмИЩЁБЁЃ
Й§ШЅЪЎФъЃЌШЫЙЄжЧФмЕФЭЛЦЦМИКѕЖМЗЂЩњдкЁАШЅЩэЛЏЁБЕФгяОГжаЁЃЮоТлЪЧздШЛгябдДІРэЕФGPT ЯЕСаЃЌЛЙЪЧМЦЫуЛњЪгОѕЕФ ViTЁЂSAMЃЌЫќУЧДѓЖрДцдкгкЪ§ОнгыЫуСІЕФащФтПеМфРяЃЌЩУГЄДІРэЗћКХЁЂЮФБОКЭЭМЯёЃЌШДгыецЪЕЪРНчЕФЮяРэНЛЛЅБЃГжзХОрРыЁЃетбљЕФ AI ПЩвдаДЪЋЁЂЛЛЁЂЛиД№ЮЪЬтЃЌШДЮоЗЈеце§зпНјЯжЪЕЃЌРэНтЛЗОГЁЂВйзнЮяЬхЁЂгыШЫРрВЂМчЭъГЩШЮЮёЁЃ
ОпЩэШЫЙЄжЧФмЃЈEmbodied AIЃЉЕФГіЯжЃЌе§ЪЧЖдетвЛОжЯоЕФЛигІЁЃЫќЧПЕїжЧФмЬхБиаыЁАгаЩэгаИаЁБЃЌВЛНіФмРэНтгябдКЭЗћКХЃЌЛЙвЊФмИажЊЛЗОГЁЂзіГіОіВпЃЌВЂЭЈЙ§ааЖЏИФБфЪРНчЁЃЛЛОфЛАЫЕЃЌОпЩэжЧФмЪЧШУ AI ДгЁАжНУцЩЯЕФДЯУїЁБзпЯђЁАЯжЪЕжаЕФФмИЩЁБЁЃ
9 дТ25 ШеЃЌarXiv ЗЂБэгЩЧхЛЊДѓбЇгыИДЕЉДѓбЇбЇепСЊКЯзЋаДЕФзлЪіТлЮФЁЖEmbodied AIЃКFrom LLMs to World ModelsЁЗЃЌе§ЪЧЖдетвЛСьгђЕФЯЕЭГадЪсРэЁЃзїепУЧОлНЙгкШ§РрКЫаФММЪѕЃКДѓгябдФЃаЭЃЈLLMsЃЉЁЂЖрФЃЬЌДѓФЃаЭЃЈMLLMsЃЉвдМАЪРНчФЃаЭЃЈWorld ModelsЃЉЃЌВЂЬНЬжЫќУЧдкОпЩэжЧФмжаЕФзїгУгыЛЅВЙЙиЯЕЁЃЮФеТВЛНізмНсСЫЙ§ШЅМИЪЎФъЕФЗЂеЙТіТчЃЌЛЙЬсГіСЫЮДРДбаОПЕФЙиМќЗНЯђЃЌЪдЭМЮЊЭЈгУШЫЙЄжЧФмЃЈAGIЃЉЕФТфЕиУшЛцвЛЬѕЧхЮњЕФТЗОЖЁЃ
 ЁЃ
ЁЃ
ЭМ1ЃКЬхЯжAIЕФИХФюЁЃ
баОПЭХЖгБОЩэвВЦФОпЗжСПЁЃЕквЛзїепTongtong FengгыЭЈбЖзїепWenwu ZhuОљРДздЧхЛЊДѓбЇМЦЫуЛњПЦбЇгыММЪѕЯЕЃЌЭЌЪБСЅЪєгкББОЉаХЯЂПЦбЇгыММЪѕЙњМвбаОПжааФЃЛXin WangЪЧ IEEE ЛсдБЃЌГЄЦкДгЪТЖрУНЬхгыПчФЃЬЌжЧФмбаОПЃЛYu-Gang JiangдђЪЧИДЕЉДѓбЇПЩаХОпЩэжЧФмбаОПдКЕФСьОќбЇепЃЌIEEE ЛсдБдкМЦЫуЛњЪгОѕгыЖрУНЬхСьгђгаЙуЗКгАЯьСІЁЃПЩвдЫЕЃЌетЪЧвЛжЇМцОпРэТлЩюЖШгыгІгУЪгвАЕФЖЅМтЭХЖгЁЃ
1.ОпЩэШЫЙЄжЧФмЕФРэТлИљЛљгыЗЂеЙТіТч
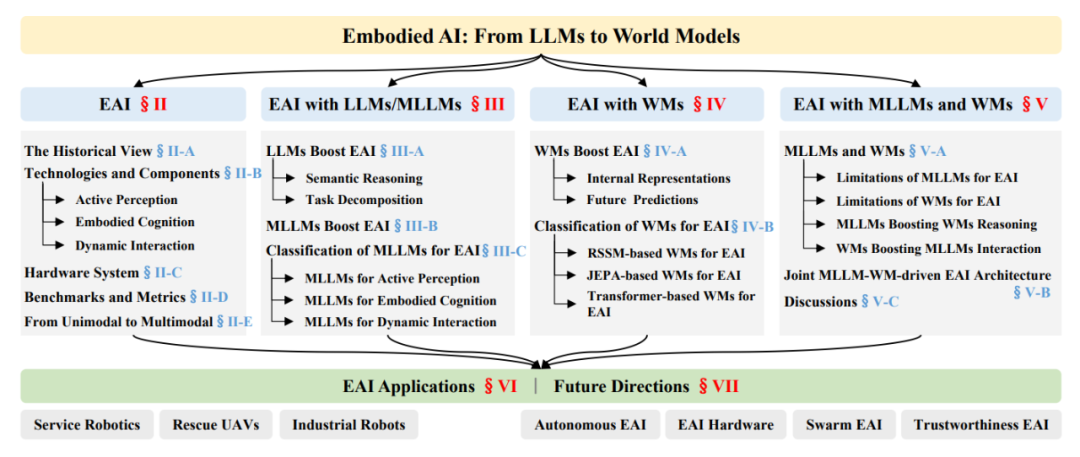
ЭМ2ЃКБОЮФШЋУцНщЩмСЫЪЕЬхЛЏШЫЙЄжЧФмЃЈEAIЃЉЕФЛљДЁжЊЪЖвдМАЛљгкLLM/MLLMКЭWMsЕФEAIЕФзюаТНјеЙЁЃMLLMжЇГжЩЯЯТЮФШЮЮёЭЦРэЃЌЕЋКіТдСЫЮяРэдМЪјЃЌЖјWMsЩУГЄЮяРэИажЊЗТецЃЌЕЋШБЗІИпМЖгявхЁЃЛљгкЩЯЪіНјеЙЃЌБОЮФЬсГіСЫвЛжжСЊКЯMLLM WMЧ§ЖЏЕФEAIМмЙЙЁЃ
вЊРэНтОпЩэжЧФмЕФНёЬьЃЌБиаыЛиЕНЫќЕФЫМЯыдДЭЗЁЃдчдк 1950 ФъЃЌЭМСщОЭЬсГіСЫЁАОпЩэЭМСщВтЪдЁБЕФЩшЯыЃКШчЙћвЛЬЈЛњЦїВЛНіФмдкЖдЛАжаЁАУАГфЁБШЫРрЃЌЛЙФмдкЮяРэЪРНчжаБэЯжГігыШЫРрЯрЕБЕФИажЊгыааЖЏФмСІЃЌФЧУДЫќВХЫуеце§ОпБИжЧФмЁЃетвЛЩшЯыдкЕБЪБЛђаэЯдЕУГЌЧАЃЌЕЋЫќЮЊКѓРДЕФбаОПТёЯТСЫЗќБЪЁЃ
ЕНСЫ 20 ЪРМЭ 80 ФъДњЃЌШЯжЊПЦбЇМвШчLakoff КЭ Harnad ЬсГіСЫЁАОпЩэШЯжЊЁБЕФРэТлЁЃЫћУЧШЯЮЊЃЌШЫЕФЫМЮЌВЂЗЧГщЯѓЕФЗћКХВйзїЃЌЖјЪЧЩюЩюдњИљгкЩэЬхОбщгыЛЗОГЛЅЖЏжЎжаЁЃЛЛОфЛАЫЕЃЌШЯжЊРыВЛПЊИаЙйгыааЖЏЁЃAI ШєвЊеце§РэНтЪРНчЃЌвВБиаыЁАОпЩэЁБЁЃ
ММЪѕЕФЗЂеЙТЗОЖДѓжТПЩвдЗжЮЊШ§ИіНзЖЮЁЃ20 ЪРМЭ 80 ЕН 90 ФъДњЃЌбаОПепУЧГЂЪдЭЈЙ§ааЮЊПижЦгыЛњЦїШЫМмЙЙРДЪЕЯжМђЕЅЕФОпЩэжЧФмЃЌР§Шч Brooks ЬсГіЕФЗжВуПижЦМмЙЙЁЃетвЛЪБЦкЕФЯЕЭГЭљЭљвРРЕЙцдђгыгаЯоЕФИажЊФмСІЃЌЙІФмЕЅвЛЁЃНјШы 2000 ЕН 2010 ФъДњЃЌЩюЖШбЇЯАЕФаЫЦ№МЋДѓЬсЩ§СЫИажЊгыПижЦЕФФмСІЃЌЛњЦїШЫФмЙЛЪЖБ№ИќИДдгЕФЛЗОГЃЌВЂдквЛЖЈГЬЖШЩЯзджїОіВпЁЃШЛЖјЃЌЫќУЧШдШЛШБЗІЭЈгУадгыПчШЮЮёЕФЧЈвЦФмСІЁЃ
еце§ЕФзЊелЗЂЩњдк 2020 ФъДњЁЃДѓгябдФЃаЭЃЈLLMsЃЉеЙЯжСЫОЊШЫЕФгявхРэНтгыЭЦРэФмСІЃЌЖрФЃЬЌДѓФЃаЭЃЈMLLMsЃЉдђШУ AI ФмЙЛЭЌЪБДІРэгябдЁЂЭМЯёЁЂЪгЦЕЕШЖрдДаХЯЂЁЃЖјЪРНчФЃаЭЃЈWorld ModelsЃЉЕФЬсГіЃЌдђШУжЧФмЬхФмЙЛдкФкВПФЃФтЛЗОГЁЂдЄВтЮДРДЃЌДгЖјдкВЛжБНгЪдДэЕФЧщПіЯТбЇЯАИДдгааЮЊЁЃетШ§РрММЪѕЕФНсКЯЃЌЮЊОпЩэжЧФмЕФЭЛЦЦЬсЙЉСЫаТЕФПЩФмЁЃ
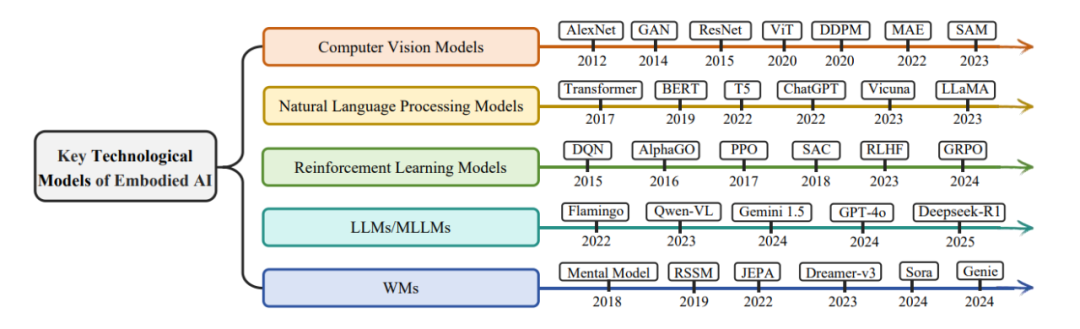
ЭМ3ЃКОпЩэШЫЙЄжЧФмЕФЙиМќММЪѕФЃаЭЁЃМЦЫуЛњЪгОѕЃЈCVЃЉФЃаЭЁЂздШЛгябдДІРэЃЈNLPЃЉФЃаЭЁЂЧПЛЏбЇЯАЃЈRLЃЉФЃаЭЁЂLLM/MLLMКЭWMsЕФНјВНЭЦЖЏСЫОпЩэШЫЙЄжЧЛлЕФНјВНЁЃ
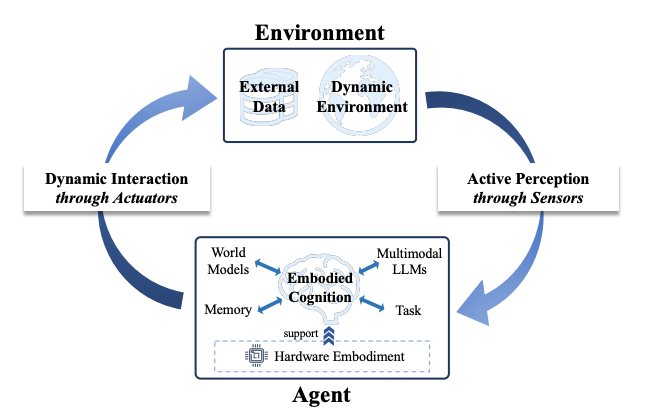
ОпЩэжЧФмЕФКЫаФЬиеїПЩвдИХРЈЮЊШ§ИіЗНУцЁЃЪзЯШЪЧжїЖЏИажЊЃЌМДжЧФмЬхВЛдйБЛЖЏНгЪеаХЯЂЃЌЖјЪЧФмЙЛжїЖЏЬНЫїЛЗОГЁЂбЁдёЪгНЧЁЂЙЙНЈГЁОАРэНтЁЃЦфДЮЪЧОпЩэШЯжЊЃЌЫќвЊЧѓжЧФмЬхФмЙЛдкШЮЮёЧ§ЖЏЯТНјааЙцЛЎЃЌРћгУМЧвфНјааЗДЫМЃЌВЂдкЖрФЃЬЌаХЯЂжааЮГЩЭГвЛЕФРэНтЁЃзюКѓЪЧЖЏЬЌНЛЛЅЃЌвтЮЖзХжЧФмЬхВЛНіФмжДааЖЏзїЃЌЛЙФмгыЛЗОГЁЂЦфЫћжЧФмЬхФЫжСШЫРрНјааИДдгЕФазїгыВЉоФЁЃ
2.ОпЩэжЧФмЕФШ§ДѓКЫаФФЃПщ
баОПЭХЖгАбОпЩэШЫЙЄжЧФмВ№НтЮЊШ§ИіНєУмЯрСЌЕФКЫаФФЃПщЃКжїЖЏИажЊЁЂОпЩэШЯжЊгыЖЏЬЌНЛЛЅЁЃЫќУЧЙВЭЌЙЙГЩСЫвЛИіжЧФмЬхдкЯжЪЕЪРНчжаЁАПДЁЂЯыЁЂзіЁБЕФЭъећБеЛЗЁЃ
жїЖЏИажЊЃКДгБЛЖЏНгЪезпЯђжїЖЏЬНЫї
ШчЙћЫЕДЋЭГЕФМЦЫуЛњЪгОѕИќЯёЪЧЁАеіблПДЪРНчЁБЃЌФЧУДОпЩэжЧФмжаЕФжїЖЏИажЊдђЪЧЁАДјзХФПЕФШЅПДЁБЁЃетвтЮЖзХжЧФмЬхВЛдйжЛЪЧБЛЖЏЕиНгЪеЭМЯёЛђДЋИаЦїЪ§ОнЃЌЖјЪЧЛсжїЖЏбЁдёЙлВьНЧЖШЁЂвЦЖЏЮЛжУЃЌЩѕжСЭЈЙ§ЬНЫїРДЛёШЁИќгаМлжЕЕФаХЯЂЁЃ
дкММЪѕТЗОЖЩЯЃЌSLAMЃЈЭЌВНЖЈЮЛгыНЈЭМЃЉЪЧзюЛљДЁЕФФмСІЃЌЫќШУЛњЦїШЫФмЙЛдкФАЩњЛЗОГжавЛБпвЦЖЏвЛБпЛцжЦЕиЭМЁЃОЕфЕФ ORB-SLAM ОЭЪЧетвЛСьгђЕФДњБэЁЃ
ЖјЫцзХГЁОАИДдгЖШЕФЬсЩ§ЃЌбаОПепУЧПЊЪМв§Шы 3D ГЁОАРэНтЗНЗЈЃЌР§Шч Clip2SceneЃЌПЩвдНЋЪгОѕЪфШызЊЛЏЮЊНсЙЙЛЏЕФШ§ЮЌгявхГЁОАЁЃИќНјвЛВНЃЌжїЖЏЬНЫїЗНЗЈШч Active Neural SLAM дђШУжЧФмЬхОпБИСЫЁАКУЦцаФЁБЃЌФмЙЛдкЮДжЊЛЗОГжазджїбАеваХЯЂдіСПзюДѓЕФТЗОЖЁЃ
ЧїЪЦвбОЗЧГЃУїШЗЃКДгзюГѕЕФМИКЮНЈФЃЃЌЕНгявхРэНтЃЌдйЕНШчНёЕФЖрФЃЬЌПчФЃЬЌИажЊЃЌжїЖЏИажЊе§ж№НЅШУжЧФмЬхОпБИРрЫЦШЫРрЕФЬНЫїгыРэНтФмСІЁЃ
ОпЩэШЯжЊЃКШУжЧФмЬхбЇЛсЁАЫМПМЁБ
ИажЊжЎКѓЃЌжЧФмЬхБиаыФмЙЛРэНтШЮЮёЁЂжЦЖЈМЦЛЎЃЌВЂдкжДааЙ§ГЬжаВЛЖЯЕїећЁЃетОЭЪЧОпЩэШЯжЊЕФКЫаФЁЃЫќВЛНіНіЪЧЁАПДЖЎЁБЃЌИќЪЧЁАЯыУїАзЁБЁЃ
дкММЪѕТЗОЖЩЯЃЌШЮЮёЧ§ЖЏЕФЙцЛЎЪЧзюжБЙлЕФЗНЪНЃЌР§Шч LLM-Planner НшжњДѓгябдФЃаЭРДЗжНтИДдгШЮЮёЃЌЩњГЩПЩжДааЕФааЖЏађСаЁЃМЧвфЧ§ЖЏЕФЗДЫМЛњжЦдђШУжЧФмЬхФмЙЛЯёШЫРрвЛбљЁАЮќШЁНЬбЕЁБЃЌReflexion ОЭЪЧвЛИіЕфаЭАИР§ЃЌЫќЭЈЙ§ЛиЙЫЪЇАмОбщРДИФНјЮДРДЕФОіВпЁЃ
ЖјЖрФЃЬЌЛљДЁФЃаЭШч SayCanЁЂEmbodiedGPTЃЌдђГЂЪдНЋгябдЁЂЪгОѕгыЖЏзїЭГвЛЕНвЛИіФЃаЭжаЃЌШУжЧФмЬхФмЙЛдкПчФЃЬЌаХЯЂжааЮГЩећЬхШЯжЊЁЃ
ШЛЖјЃЌетвЛФЃПщвВУцСйзХВЛаЁЕФЬєеНЁЃГЄЪБађЭЦРэШдШЛЪЧФбЕуЃЌжЧФмЬхЭљЭљдкашвЊЪ§ЪЎВНЩѕжСЩЯАйВНЭЦРэЕФШЮЮёжаБэЯжВЛЮШЖЈЁЃПчФЃЬЌЖдЦыЮЪЬтвВЩаЮДЭъШЋНтОіЃЌВЛЭЌФЃЬЌЕФаХЯЂШчКЮдкЭГвЛПеМфжаИпаЇШкКЯЃЌШдЪЧбаОПШШЕуЁЃИќживЊЕФЪЧЃЌПЩЧЈвЦадВЛзуЃЌжЧФмЬхдквЛИіЛЗОГжабЇЕНЕФФмСІЃЌЭљЭљФбвдЮоЗьЧЈвЦЕНСэвЛИіЛЗОГЁЃ
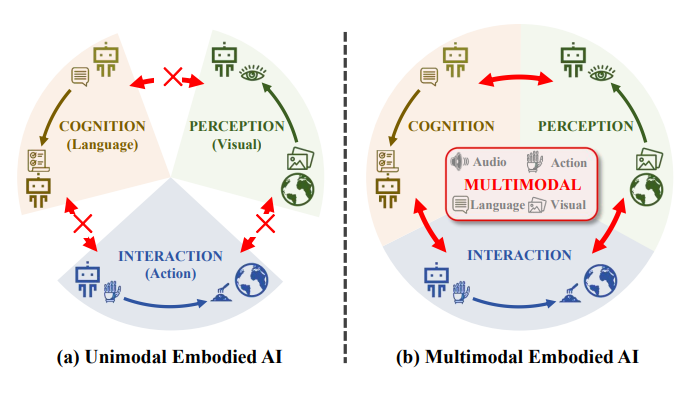
ЭМ4ЃКЕЅЗхЬхЯжШЫЙЄжЧФмКЭЖрФЃЬЌЬхЯжШЫЙЄжЧФмЁЃЃЈaЃЉЕЅЗхЗНЗЈВржигкЬхЯжШЫЙЄжЧФмЕФЬиЖЈФЃПщЁЃЫќУЧЪмЕНУПжжФЃЬЌЬсЙЉЕФаХЯЂЗЖЮЇЯСевдМАПчФЃПщФЃЬЌжЎМфЙЬгаВюОрЕФЯожЦЁЃЃЈbЃЉЖрФЃЬЌЧЖШыЪНШЫЙЄжЧФмЗНЗЈДђЦЦСЫетаЉЯожЦЃЌЪЕЯжСЫФЃПщЕФЯрЛЅдіЧПЁЃ
ЖЏЬЌНЛЛЅЃКДгЕЅЬхПижЦЕНШЫЛњЙВЩњ
зюКѓЃЌОпЩэжЧФмБиаыФмЙЛгыЛЗОГКЭЦфЫћжїЬхНјааНЛЛЅЁЃетВЛНіАќРЈЖдЮяРэЖЏзїЕФОЋзМПижЦЃЌЛЙЩцМАгыЦфЫћжЧФмЬхЕФазїЃЌЩѕжСгыШЫРрЕФздШЛЛЅЖЏЁЃ
дкЖЏзїПижЦВуУцЃЌЙШИшЕФ RT-2 ФЃаЭеЙЪОСЫШчКЮНЋДѓФЃаЭЕФгявхРэНтгыЛњЦїШЫПижЦНсКЯЃЌШУЛњЦїШЫФмЙЛжДааИДдгЕФздШЛгябджИСюЁЃCogAgent дђНјвЛВНЬНЫїСЫПчФЃЬЌЕФИажЊгыПижЦвЛЬхЛЏЁЃ
дкааЮЊНЛЛЅЗНУцЃЌTrafficSim ЕШФЃФтЦНЬЈШУжЧФмЬхФмЙЛдкИДдгНЛЭЈЛЗОГжабЇЯАгыЦфЫћГЕСОЕФВЉоФЁЃИќИпВуДЮЕФазїОіВпдђгЩ AgentVerseЁЂMetaGPT ЕШПђМмЭЦЖЏЃЌЫќУЧГЂЪдШУЖрИіжЧФмЬхдкЙВЯэФПБъЯТНјааЗжЙЄгыКЯзїЁЃ
ЧїЪЦЭЌбљЧхЮњЃКДгзюГѕЕФЕЅЬхПижЦЃЌЕНЖржЧФмЬхазїЃЌдйЕНЮДРДЕФШЫЛњЙВЩњЁЃОпЩэжЧФмЕФжеМЋФПБъЃЌВЛЪЧШУЛњЦїШЫЕЅДђЖРЖЗЃЌЖјЪЧШУЫќУЧФмЙЛгыШЫРрВЂМчзїеНЃЌГЩЮЊеце§ЕФЛяАщЁЃ
3.LLMs/MLLMs гы World Models ЕФЛЅВЙад
дкОпЩэШЫЙЄжЧФмЕФЬжТлжаЃЌДѓгябдФЃаЭЃЈLLMsЃЉЁЂЖрФЃЬЌДѓФЃаЭЃЈMLLMsЃЉгыЪРНчФЃаЭЃЈWorld Models, WMsЃЉГЃГЃБЛЪгЮЊСНЬѕЦНааЕФЗЂеЙТЗОЖЁЃЧАепЩУГЄгявхгыЭЦРэЃЌКѓепдђЧПЕїЮяРэгыдЄВтЁЃзлЪіТлЮФЕФвЛИіКЫаФЙБЯзЃЌОЭЪЧНвЪОСЫЖўепжЎМфЕФЛЅВЙЙиЯЕЃЌВЂЬсГіСЊКЯМмЙЙЕФБивЊадЁЃ
LLMs/MLLMs ЕФгХЪЦгыОжЯо
ДѓгябдФЃаЭЕФсШЦ№ЃЌШУ AI дкгявхВуУцеЙЯжГіЧАЫљЮДгаЕФФмСІЁЃЫќУЧФмЙЛНјааИДдгЕФгявхЭЦРэЃЌРэНтЩЯЯТЮФЙиЯЕЃЌВЂНЋИДдгШЮЮёЗжНтЮЊПЩжДааЕФВНжшЁЃдкЖрФЃЬЌРЉеЙжЎКѓЃЌMLLMs ИќЪЧОпБИСЫПчФЃЬЌРэНтЕФФмСІЃЌФмЙЛЭЌЪБДІРэгябдЁЂЭМЯёЁЂЪгЦЕЕШаХЯЂЃЌДгЖјдкОпЩэжЧФмжаГаЕЃЁАШЮЮёДѓФдЁБЕФНЧЩЋЁЃ
ШЛЖјЃЌLLMs гы MLLMs ЕФОжЯовВЪЎЗжУїЯдЁЃЫќУЧШБЗІЖдЮяРэЪРНчЕФецЪЕдМЪјЃЌЭљЭљжЛФмдкЗћКХПеМфжаНјааЭЦРэЃЌФбвдБЃжЄЩњГЩЕФМЦЛЎдкЯжЪЕжаПЩааЁЃЭЌЪБЃЌЫќУЧдкЪЕЪБЪЪгІадЩЯДцдкВЛзуЃЌУцЖдЖЏЬЌЛЗОГЪБЃЌЯьгІЫйЖШгыЮШЖЈадЖМФбвдТњзуОпЩэжЧФмЕФашЧѓЁЃЛЛОфЛАЫЕЃЌЫќУЧКмДЯУїЃЌЕЋВЛЙЛЁАНгЕиЦјЁБЁЃ
World Models ЕФгХЪЦгыОжЯо
гы LLMs ЯрБШЃЌЪРНчФЃаЭЕФгХЪЦдкгкЫќУЧФмЙЛдкФкВПЙЙНЈЛЗОГБэеїЃЌНјааЮДРДдЄВтЃЌВЂБЃГжгыЮяРэЙцТЩЕФвЛжТадЁЃЭЈЙ§дкЁАаФжЧФЃФтЦїЁБжаВЛЖЯЪдДэЃЌжЧФмЬхПЩвддкВЛжБНгЯћКФЯжЪЕзЪдДЕФЧщПіЯТбЇЯАИДдгааЮЊЁЃетжжФмСІШУ WMs ГЩЮЊОпЩэжЧФмжаВЛПЩЛђШБЕФЁАЮяРэв§ЧцЁБЁЃ
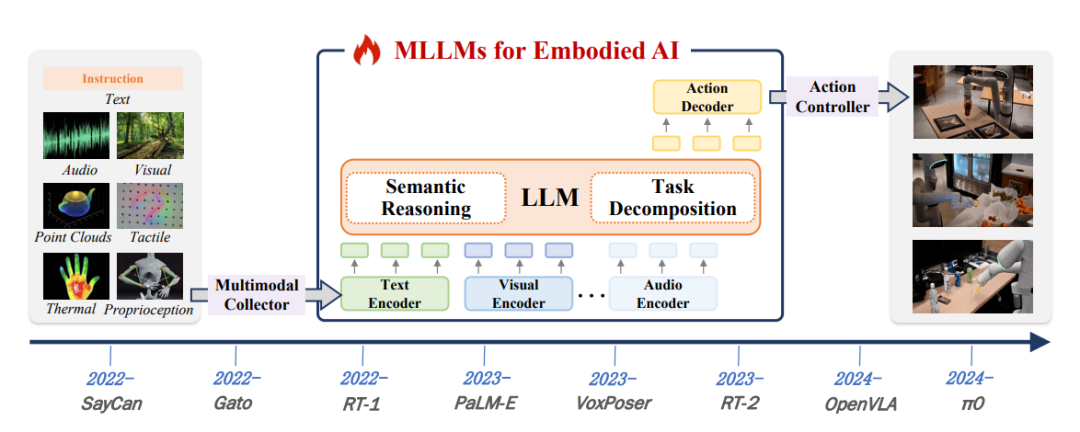
ЭМ5ЃКЧЖШыЪНШЫЙЄжЧФмMLLMЕФЗЂеЙТЗЯпЭМЁЃИУТЗЯпЭМЭЛГіСЫЦфИХФюКЭЪЕМљЗЂеЙжаЕФЙиМќРяГЬБЎЁЃ
ЕЋЪРНчФЃаЭвВгаЖЬАхЁЃЫќУЧдкгявхЭЦРэЗНУцдЖВЛШч LLMsЃЌФбвдРэНтИДдгЕФШЮЮёУшЪіЛђПчФЃЬЌаХЯЂЁЃЭЌЪБЃЌWMs ЕФЗКЛЏФмСІгаЯоЃЌЭљЭљашвЊдкЬиЖЈЛЗОГжаНјааДѓСПбЕСЗЃЌВХФмдкЯрЫЦГЁОАжаБэЯжСМКУЁЃвЛЕЉЛЗОГЗЂЩњНЯДѓБфЛЏЃЌФЃаЭЕФЪЪгІадОЭЛсЯджјЯТНЕЁЃ
СЊКЯМмЙЙЕФБивЊад
е§вђШчДЫЃЌбаОПЭХЖгЬсГіСЫвЛИіЧхЮњЕФЗНЯђЃКНЋ MLLMs гы WMs НсКЯЃЌЙЙНЈЯТвЛДњОпЩэжЧФмМмЙЙЁЃдкетжжМмЙЙжаЃЌMLLMs ЬсЙЉгявхжЧФмЃЌИКд№РэНтШЮЮёЁЂЗжНтФПБъЁЂНјааПчФЃЬЌЭЦРэЃЛЖј WMs ЬсЙЉЮяРэжЧФмЃЌИКд№дЄВтЛЗОГБфЛЏЁЂбщжЄааЖЏПЩааадЁЂШЗБЃгыЮяРэЙцТЩвЛжТЁЃ
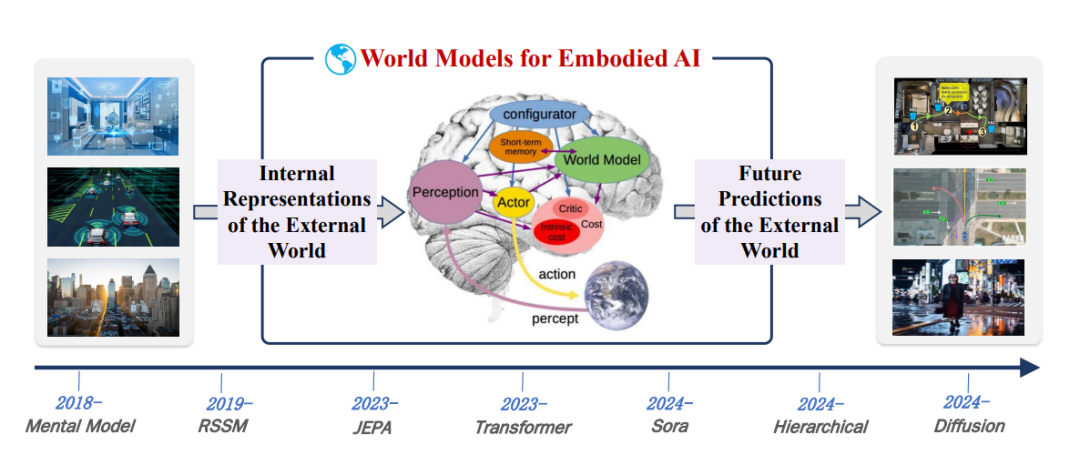
ЭМ6ЃКЧЖШыЪНШЫЙЄжЧФмЕФWMsЗЂеЙТЗЯпЭМЁЃИУТЗЯпЭМЭЛГіСЫЦфИХФюКЭЪЕМљЗЂеЙжаЕФЙиМќРяГЬБЎЁЃ
етжжНсКЯвтЮЖзХжЧФмЬхМШФмЁАЬ§ЖЎШЫЛАЁБЃЌгжФмЁАНХЬЄЪЕЕиЁБЁЃЫќМШФмРэНтШЫРрЕФИДдгжИСюЃЌгжФмдкЮяРэЪРНчжазіГіКЯРэЕФааЖЏЁЃгявхгыЮяРэЕФШкКЯЃЌе§ЪЧОпЩэжЧФмТѕЯђЭЈгУШЫЙЄжЧФмЕФЙиМќвЛВНЁЃ
4.ЕфаЭАИР§гыгІгУГЁОА
баОПЭХЖгЬиБ№ЬсЕНEvoAgent етвЛДњБэадАИР§ЁЃЫќБЛГЦЮЊЁАздНјЛЏжЧФмЬхЁБЃЌвђЮЊЫќВЛНіФмжДааШЮЮёЃЌЛЙФмдкЙ§ГЬжаВЛЖЯздЮвгХЛЏЁЃEvoAgent ЕФКЫаФФмСІЬхЯждкШ§ИіЗНУцЃКздЙцЛЎЁЂздЗДЫМгыздПижЦЁЃ
здЙцЛЎвтЮЖзХЫќФмЙЛИљОнШЮЮёФПБъзджїЩњГЩааЖЏЗНАИЃЌЖјВЛЪЧвРРЕЭтВПжИСюж№ВНжИЕМЃЛздЗДЫМдђШУЫќдкжДааЙ§ГЬжаВЛЖЯзмНсОбщЃЌаое§ДэЮѓЃЌЬсЩ§ЯТвЛДЮЕФБэЯжЃЛздПижЦдђБЃжЄСЫЫќдкИДдгЛЗОГжаФмЙЛБЃГжЮШЖЈКЭСщЛюЕФааЖЏЁЃЛЛОфЛАЫЕЃЌEvoAgent ВЛНіЪЧвЛИіЁАжДааепЁБЃЌИќЪЧвЛИіЁАбЇЯАепЁБКЭЁАЫМПМепЁБЁЃ
етжжФмСІЕФЧБдкгІгУГЁОАЗЧГЃЙуРЋЁЃдкЗўЮёЛњЦїШЫСьгђЃЌEvoAgent ПЩвдШУЛњЦїШЫДгЁАЛњаЕжДааЁБЩ§МЖЮЊЁАжїЖЏЗўЮёЁБЃЌР§ШчдкМвЭЅжаИљОнЛЗОГКЭгУЛЇЯАЙпзджїЕїећааЮЊЁЃ
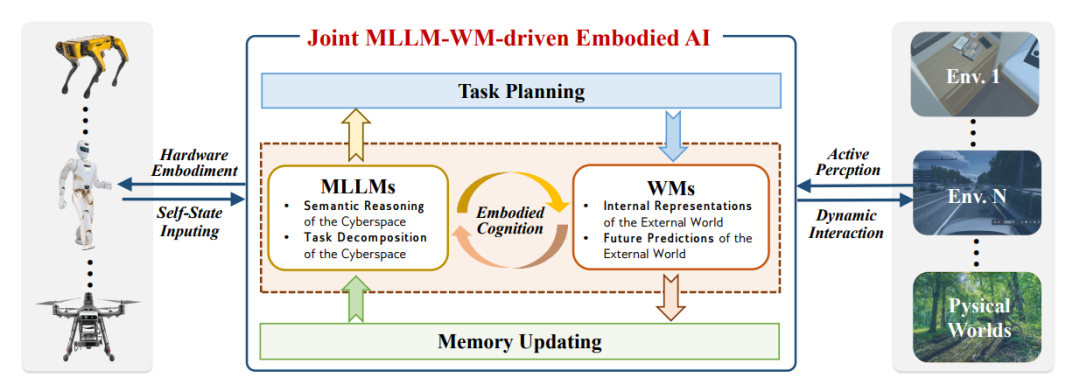
ЭМ7ЃКНЋAIгыMLLMКЭWMsЯрНсКЯЁЃMLLMsПЩвдЭЈЙ§ЮЊШЮЮёЗжНтКЭГЄЦкЭЦРэзЂШыгявхжЊЪЖРДдіЧПWMsЃЌЖјWMsПЩвдЭЈЙ§ЙЙНЈЮяРэЪРНчЕФФкВПБэЪОКЭЮДРДдЄВтРДИЈжњMLLMsЃЌЪЙСЊКЯMLLM-WMГЩЮЊгаЧАОАЕФЧЖШыЪНЯЕЭГМмЙЙЁЃ
дкЙЄвЕздЖЏЛЏжаЃЌЫќФмЙЛдкЩњВњЯпЩЯЖЏЬЌгХЛЏСїГЬЃЌМѕЩйЭЃЛњКЭРЫЗбЃЌЬсИпаЇТЪЁЃдкЮоШЫЛњОШдЎШЮЮёжаЃЌEvoAgent ЕФздЗДЫМгыздПижЦФмСІгШЮЊЙиМќЃЌЫќПЩвддкджКІЯжГЁПьЫйЪЪгІИДдгЛЗОГЃЌзіГізюгХТЗОЖбЁдёЃЌЩѕжСдкЭЈаХЪмЯоЕФЧщПіЯТЖРСЂЭъГЩШЮЮёЁЃЖјдкЖржЧФмЬхазїЯЕЭГжаЃЌEvoAgent ЕФздНјЛЏЬиадШУЫќФмЙЛгыЦфЫћжЧФмЬхаЮГЩФЌЦѕЃЌЗжЙЄазїЃЌЭъГЩЕЅИіжЧФмЬхЮоЗЈЭъГЩЕФИДдгШЮЮёЁЃ
етаЉгІгУГЁОАЕФЙВЭЌЕудкгкЃКЛЗОГИДдгЁЂШЮЮёЖЏЬЌЁЂашЧѓЖрБфЁЃДЋЭГЕФЁАдЄЩшЙцдђЁБЪН AI дкетаЉГЁОАжаЭљЭљСІВЛДгаФЃЌЖјОпЩэжЧФмЬхЃЌгШЦфЪЧЯё EvoAgent етбљЕФздНјЛЏМмЙЙЃЌе§КУЬюВЙСЫетвЛПеАзЁЃ
5.баОПвщГЬгыЬєеН
ОЁЙмОпЩэжЧФмЕФРЖЭМСюШЫеёЗмЃЌЕЋбаОПЭХЖгвВЧхЮњЕижИГіСЫЮДРДбаОПБиаыУцЖдЕФЬєеНгыЗНЯђЁЃ
ЪзЯШЪЧзджїОпЩэ AIЁЃЮДРДЕФжЧФмЬхВЛФмНіНівРРЕШЫРрЬсЙЉЕФЪ§ОнКЭжИСюЃЌЖјЪЧвЊОпБИздНјЛЏгыздбЇЯАЕФФмСІЁЃЫќУЧашвЊЯёЩњЮявЛбљЃЌдкгыЛЗОГЕФГЄЦкЛЅЖЏжаВЛЖЯГЩГЄЃЌаЮГЩеце§ЕФЁАОбщжЧЛлЁБЁЃ
ЦфДЮЪЧОпЩэAI гВМўЁЃдйЧПДѓЕФЫуЗЈвВашвЊгВМўжЇГХЁЃОпЩэжЧФмЕФТфЕивЊЧѓЩшБИОпБИЕЭЙІКФЁЂИпЫуСІКЭБпдЕВПЪ№ЕФФмСІЁЃЛЛОфЛАЫЕЃЌЮДРДЕФЛњЦїШЫКЭжЧФмЬхВЛФмзмЪЧвРРЕдЦЖЫЫуСІЃЌЖјЪЧвЊдкБОЕиОЭФмЭъГЩИДдгЕФИажЊгыОіВпЃЌетЖдаОЦЌЩшМЦЁЂДЋИаЦїШкКЯКЭФмаЇгХЛЏЬсГіСЫаТЕФвЊЧѓЁЃ
ЕкШ§ШКЬхОпЩэ AIЁЃЕЅИіжЧФмЬхЕФФмСІдйЧПЃЌвВФбвдгІЖдДѓЙцФЃЁЂИДдгЕФШЮЮёЁЃЮДРДЕФЗНЯђЪЧШКЬхжЧФмгыазїЃЌШУЖрИіОпЩэжЧФмЬхФмЙЛЯёЗфШКЛђвЯШКвЛбљЃЌеЙЯжГіГЌдНИіЬхЕФећЬхжЧЛлЁЃетВЛНіЩцМАЫуЗЈЩшМЦЃЌЛЙЩцМАЭЈаХЛњжЦЁЂазїавщКЭШКЬхааЮЊНЈФЃЁЃ
зюКѓЪЧПЩаХРЕадЁЃЫцзХОпЩэжЧФмж№НЅзпШыЯжЪЕЪРНчЃЌАВШЋадЁЂПЩНтЪЭадвдМАТзРэгыКЯЙцЮЪЬтНЋГЩЮЊШЦВЛПЊЕФвщЬтЁЃвЛИіФмЙЛзджїбЇЯАКЭНјЛЏЕФжЧФмЬхЃЌШчКЮБЃжЄЫќЕФааЮЊЗћКЯШЫРрМлжЕЙлЃПШчКЮБмУтЧБдкЕФАВШЋЗчЯеЃПШчКЮШУЫќЕФОіВпЙ§ГЬЭИУїПЩНтЪЭЃПетаЉЮЪЬтЕФД№АИЃЌНЋОіЖЈОпЩэжЧФмФмЗёеце§БЛЩчЛсНгЪмЁЃ