
��ǰȫ��AI��ģ�ͺ�оƬ����������һ�־���������
��������һ���������ƣ���ͳ������ǩ����һ�������������һ��ּ������AI����ѧ�о���ʽ�����ٿ�ѧ���ֵ�ȫ�¹��Ҽƻ��������ͼƻ�����
������ʾ��������ָʾ��Դ������һ���˹�����ʵ��ƽ̨��������������������Ͷ��������ʲ��������ɿ�ѧ����ģ�Ͳ�Ϊ������ʵ�����ṩ֧�֡�
��AI��ģ�ͺ�оƬ���������£����������ھ�����
�ȸ��ڽ��ڵĺ����ͷ�����н���ʤ����AI������ʩ������AminVahdat��ǰ��ȫ�����б�ʾ����˾����ÿ6���½�AI��������������δ��4��5���ڶ���ʵ��1000������������Ӧ�Գ���������AI��������
�ȸ�շ����Ĵ�ģ��Gemini3����Ƶģ��NanoBananaPro�����𱬣���Щģ�Ͷ��ǻ��ڹȸ����е�TPU���ѵ����
ƾ��TPU+��ģ��+Ӧ��+���ݵ�ȫ��̬���ƣ��ȸ���������ʵ��AI��̬�ջ�������AI��ҵ���롰Ͷ��-�ɳ�-��Ͷ�롱��ѭ��������������ȫ���ģ�ͳ��̵�����ЧӦ��
��֮ǰ�������У�����������OCS�⽻����ȫ��������ģ���ҵ��ȫ�����������ģ������������AI������������ȫ����
�����ص����TPU��ҵ���Լ����Ļ��ڡ�
01
TPU��ҵ����
TPU��Tensor Processing Unit������������Ԫ���ǹȸ�רΪ�����˹����ܺͻ���ѧϰ������Ƶ�ר�ü��ɵ�·ASIC��
ASICоƬ������������ض������Ӳ���ܹ��Ż�ʹ�����Ч��Զ��ͨ��оƬ����ˮ�߽ṹ���ܽ������ݴ����ӳ٣���Ч��Խ�����Ŀɱ�ͨ��оƬ�ͣ��Լ�ɢ��ѹ����С��
TPU����Ӳ��������ջ������ϣ�֧�ֹȸ�AI��̬�Ŀ��ٵ�����������������ڡ���Ӳ�������㷨������Ч�������㡢��Ч��ͻ���Լ����ƻ���ơ���ͨ�ü���оƬ��ͬ��TPU��Ӳ�������ȫΧ�����ѧϰ������ĵ���������չ����������ѧϰ�еľ���˷������������������Ż���
TPU��Ӳ���ܹ����
TPU��Ӳ���ܹ�Χ��"����-�洢-����"�������ģ��չ����
���ļ��㵥Ԫ�����������нṹ������ǧ����������Ԫ��ALU����ɶ�ά��������ͨ����ˮ�߷�ʽ�������д��ݣ�ÿ�����ڿ������ǧ�γ˼����㣨MAC����
ͨ��Ӳ���ܹ���ר�û�ʵ�ּ���Ч�ʵ�������������TPU�������ܶ�Զ��ͨ��CPU/GPU��

TPU��չ����
�ȸ�TPU��2015���״��Ƴ�������������ε���������TPU���γ������ļ�����ϵ��
Trillium��2024�귢���ĵ�6��Trillium����MLP���ģ�רΪTransformer��ģ���Ż�����һ�������˴�ģ�͵�ѵ���ٶ���Ч�ʡ�
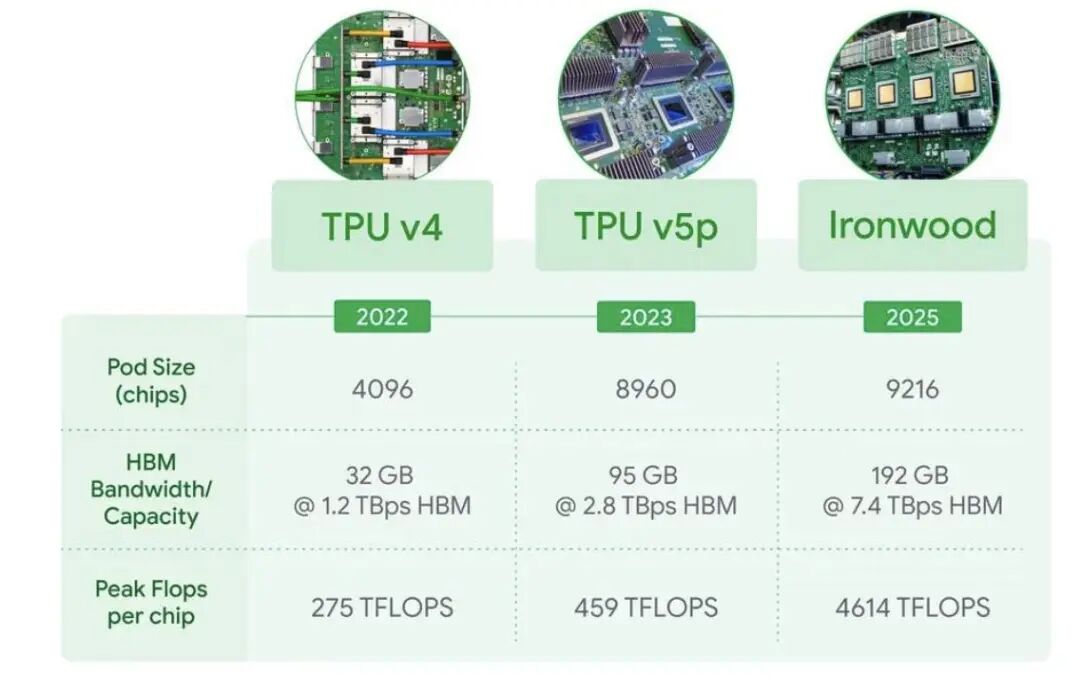
Ironwood���ȸ���ʽ�����ĵ��ߴ�TPU"Ironwood"����Ŀǰ�ȸ�������ǿ����Ч��ߵĶ���оƬ��Ironwoodʵ����������Ч����̬������ͻ�ơ���оƬ����4614TFLOPs��FP8���ȣ�����Ⱥ��ģ��չ��9216��оƬ��������42.5ExaFLOPs���൱��ȫ����ǿ����ElCapitan��24����ѵ�����������ܱȵ�����TPU��Trillium������4����
TPUIronwood���Ƴ���־��AI�����ӡ���оƬ������ת��ϵͳ����������������������OCS��������Ϊ��ҵ�������ع�������
02
�ȸ�TPU��ҵ�����Ļ���
оƬ���
������ҵ���ĺ��ĺͼ������ݡ�
�ȸ������ƿ�TPU�ļܹ���ƣ���TPU v1������v7��Ironwood����ȫ���ʼܹ���ƣ�����ϡ����㵥Ԫ��SparseCore����3D Torus�������ˡ�HBM�ڴ漯�ɵȺ��ļ������з���
TPU��Ƽܹ�ͼ��
 ������Դ��Norman P. Jouppi��In-Datacenter Performance Analysis of a Tensor Processing Unit��
������Դ��Norman P. Jouppi��In-Datacenter Performance Analysis of a Tensor Processing Unit��
OCS�⽻��
��ģ��ѵ����Ҫ����GPU/TPUЭͬ���㣬��ͨ�Ŵ�����ʱ���������Ҫ��OCS�������ܺ�/��ʱ/崻�ʱ��/���������ȶ������߱��������ơ�
�ȸ���ĿǰOCS���IJɹ�������OCS���ֶ��꣬��2022���״ν�OCS����TPUv4���������ں���һֱ���á�
�ȸ��������IJ���48̨OCS�⽻��������9216��TPU������崻�ʱ���2000Сʱ�ӳ���10��Сʱ��
����SemiAnalysis���ȸ��OCS���ƻ�����ʹ�����������������������30%�����Ľ�����40%�����������ʱ��������10%������崻�ʱ�������50�������ʱ���֧������30%��
���⣬OCS�ɽ���������������������ļ������������������ġ����ɡ���ʹ�������ȴ�ͳEPS���öࡣ
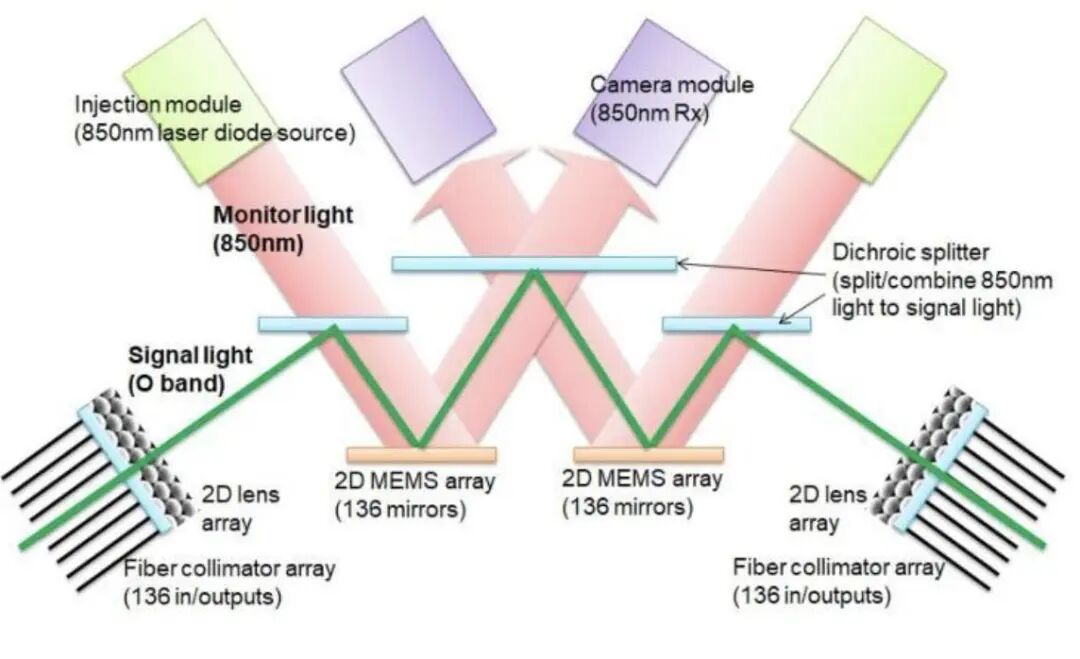
OCS�⽻�������ļ�����Ŀǰ��Ҫ�����ַ�����MEMS����������Һ��������DLC����ѹ��Directlight����ƫת������DLBS���Ⲩ��������
MEMSĿǰ��Գ��죬��OCS�г���ռ�ȳ���70%��������������˿���չ�����ͳɱ����ƱȽϾ��⡣ȫ����Ҫ�����У��ȸ��Lumentum��MEMS����Ϊ�����ȸ���IJ��õ�MEMS��������·�л��ӳٽ�10-100���롣
MEMSʾ��ͼ��
�ȸ�OCS��Ӧ��֣�Ŀǰ�ȸ��ֱ�ӹ�Ӧ����ҪΪ���⳧��Lumentum��Coherent�ȳ��̣����ڳ���Ŀǰ�Ѿ����뵽Ԫ�����������ҵ���С��ȸ����OCS��ҵ��������׳��̰����¿������������������ӣ�MEMSоƬ������OCS�ؼ��������о�Բ�������Ƽ����չ��人���չ�ѧҵ������MEMSOCS������������ӹ�Ӧ�ȸ裩���ھ��Ƽ�����ӦOCS���Ĺ�ѧԪ�����ȡ�
���ȸ��⣬OCS����������CSP�еõ��������Ӻ�Ӧ�ã���ǰ����Meta������ѷAWSҲ����̽���Լ��Ĺ⽻�����硣
TPUV5e��256TPU��ʵ��ͼ��
 ������Դ���ȸ�
������Դ���ȸ�
��ģ��&ͭ��
TPU��Ⱥͨ����ģ��ʵ��оƬ��ICI�ĸ������ݴ��䣬֧�Ŵ��ģ�ֲ�ʽ���㡣
�ȸ���ߴ�TPU��Ironwood������Ⱥ������9000��оƬ���貿��10��ֻ��ģ�飬�������ӳ١��ߴ�����3D�����������磬��ǰ�����ʵ�1.6T��ģ���Ϊ���衣
���ٹ�ģ�飺��ΪOCSϵͳ�ĺ������������MEMS��ء�Һ�����е�����Эͬ��������������ԺͿɿ��ԡ���оƬICI����������1.2TBps��9.6Tbps˫����������ʹ�ģ��֧�š��м����ȸ�1.6T��ģ����ҹ�Ӧ�̣���Ʒ����2026��TPU������������ʢ��Ϊ�ȸ�TPU��Ե�ڵ��ṩ800G��ģ�飩��̫����MPO������������Ϊ��ͨ������Ӧ�ȸ裬�����������ĸ��ܶȻ�������
1.6T��ģ���Ϊ���裬��оƬICI����������1.2TBps��9.6Tbps˫����������ʹ�ģ��֧�š�
���л������Ķ��ƹ�ģ�飺
 ������Դ��Google��aster
������Դ��Google��aster
ͭ�£�����TPUоƬ����ָ�������������v4��4096������Ironwood��9216�ţ���ͭ�µĴ����;��������������ԡ�����ͭ����س����У���о������Marvell������1.6TAEC��Դͭ������ȸ�����������TPUv7��Ⱥ����ͨ����ɡ����̡���ɴ�⻪��ʤ�����������ڶ೧����ͭ�»����������֡�
Һ��ɢ��
����TPUоƬ����ָ�������������v4��4096������Ironwood��9216�ţ���ͳ���似����������ɢ������
Һ��ͨ��ֱ�ӽӴ�оƬɢ�ȣ������������ܶ�������80kW���ϣ�֧�ֳ����ģ��Ⱥ�ȶ����С�
�ȸ���һ��TPUоƬIronwood��Һ��ϵͳʹ9216��оƬ��Ⱥ�¶Ȳ��������ڡ�2�����ڣ�ȷ�������ܶ����㷨�Ż���˫�����ơ�
Һ�似������������ȴϵͳ�ܺġ���Ironwood��ȺΪ����Һ�似��ʹ���ܺ�Ч������50%���൱�ڻ�ͬ����ѻ��˫��������
������س����У�Ӣά��CDU֧�ֳ�2.6��̨Һ��ڵ㲿������ȸ�AIоƬ�߹�������Ʒ����ȸ��������Ӧ�����ṩȫ��ҵ��Һ�䷽��������ȴҺ��CDU����ŷ����������˼Ȫ�²ij���VC���Ȱ�ͨ���ȸ���֤������������ȸ�TPU��Դ��Ӧ�����ṩ���κ����ε�Դģ�顢��ҵ����ȫ���״������ʽ+��ûʽ�����Һ�䷽������ȸ���Ч��֤������TPU-v6��Ⱥ����

PCB
TPU��Ϊ�ȸ�AI�����ĺ���Ӳ������������������PCBӡ�Ƶ�·��ļ���������
PCB��ΪоƬģ�����������������壬ֱ�Ӿ��������豸�Ĵ���Ч�ʡ�
TPUV7/V8������PCB�ġ��ߴ��������ӳ١��߿ɿ��ԡ�Ҫ��Զ����ͳ����������֧��224Gbps���ϴ������ʡ�
����PCB���輯��8��TPUоƬ��4��GPU/TPUģ�飬ͨ����ģ��ʵ�ָ��ٻ�������PCB�����������ܶ�����Ͽ�Ҫ��
TPUV7���汾Ϊ36��壬V7P�汾������44��壬���۴�1.5��Ԫ������2.5��Ԫ����ҡ�40������PCB���Ż�������ƣ����ڳ����Ѳ���Һ�䷽��������TPU�߹���ɢ������
2026��ȸ�ƻ�����ͭ�壨CCL������8�ȼ���������9����Ƶ�������Ը��ţ����ƶ�PCB��ֵ����һ��������V8������������HDI�����ܶȻ���������������������������300Gbps����һ���Ż�PCB���ܡ�����ɷ�����30-40���������ʤ�ꡢ�и���·�ȹȸ�TPU�ĺ���PCB��Ӧ�̡����ϵ�·��Ϊ�ȸ�TPUV7оƬ�߶�PCB���ҹ�Ӧ�̣���Ӧ44��塣
��Ϥ��MetaPlatforms�����dz�����ʮ����Ԫ����ȸ��TPU����������Meta���������Ľ��衣���˹����ܳ�����˾Anthropic�ƻ�ʹ�ö��100�����TPU��������Claudeģ�͡��ȸ�ƾ�衰AIӦ�ã���������桢��Ƶ��-��ģ�ͣ�Gemini��-������TPU��-�����豸��OCS���������ȫջ����ģʽ��δ����AIʱ���߱�������չǰ�����ȸ�����������һ��AI����������

















