2026-01-17 18:19・海外・英国大学老师 优质互联网领域创作者
2025年开局非常热闹,特别是在大模型LLM的技术圈子里。DeepSeek团队是在新年当天以及过后没几天,接连发布了两篇梁文峰署名的论文。
《mHC:Manifold-Constrained Hyper-Connections》
《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》。
这两篇论文展示了DS对于模型架构稳定性和稀疏化记忆的新思考,总结下这两篇论文非常重磅的原因有两个:
它是对于现有Transformer结构的一次深刻讨论
有可能会对下一代大模型结构产生深远影响。
甚至被传为DeepSeek下一代大模型架构的理论基础,足以看出来这两项工作的重大意义。
有意思的是, 网友们在论文的参考文献里发现了另外一家国内公司的身影, 就是字节跳动的Seed团队。
01
mHC与字节Seed团队的Hyper-Connections
第一篇文章,mHC的封面图片,里面提到了模型架构的演化,从(a)最传统的residual connection残差到(c)mHC,其实并不是一蹴而就的,而是经历了HC这个中间结构。

而(b)这个Hype-Connections就是字节团队发表在计算机顶会ICLR上的文章,可以看到时间是在2025年的三月份。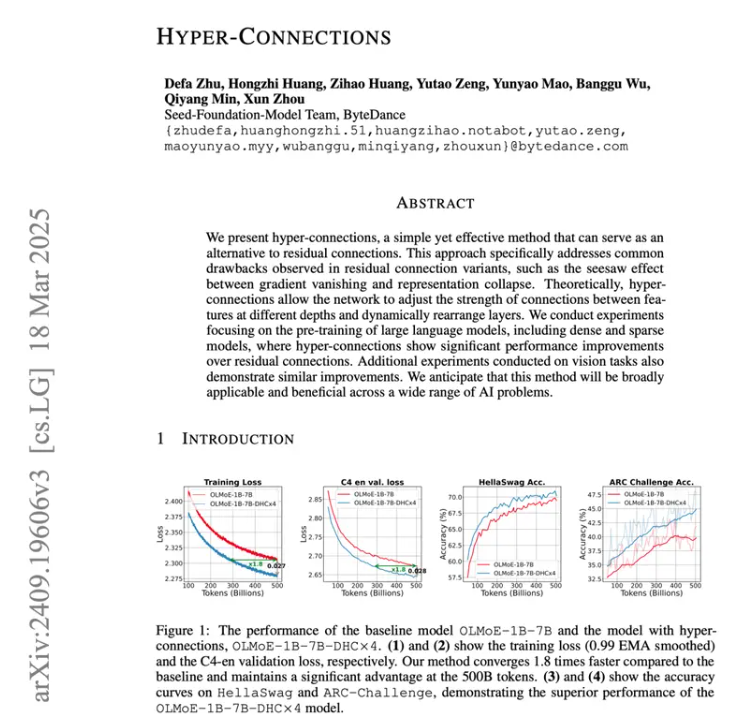
要理解 DeepSeek 在 2026 年的mHC,我们必须回看 2025 年,回顾Seed 团队在基础架构层面所做的突围尝试。
Transformer 架构已统治 NLP 领域多年,其核心的残差连接(Residual Connection)――即经典x + F(x)结构,虽然保证了深层网络的训练稳定性,但也逐渐显露出信息传输的瓶颈。
估计所有的超大模型团队都遇到了类似的困境,因为随着模型深度的加深,传统的residual connection就跟单车道的立交桥一样拥堵不堪。
字节 Seed 团队提出的 Hyper-Connections(HC)正是为了打破这一局限。HC 的核心思想可以类比为将 “单车道” 扩建为 “多车道高速公路”。
并且这个改动非常的大胆,
引用@https://www.zhihu.com/people/yu-you-56-63的话来说,字节Seed的这个HC可以划归为一类新的物种。
这一突破性的范式由字节跳动率先提出,并在当时就展示了预训练收敛速度最高提升 80% 的潜力。尽管在发布之初,它可能未像某些应用层产品那样瞬间 “破圈”,但它在底层架构上埋下的伏笔,为后续的大模型架构改良提供了关键的理论基础。
基础领域的研究就是这样,提出一个好问题的难度要远比解决一个问题要难,因为前者是在大量的实践过程中才能发现的,而后者的作用也不可小觑,因为没有被大量验证过的理论才是大多数,最终的结局不过就是一篇paper。
从mHC这个工作来看,整体的思路非常的清晰,字节的Seed对于传统模型进行了大刀阔斧的改动,但留下的问题被DS解决,然后发表了mHC,但是这肯定不是终点,因为DS做的大规模试验也有限,未来肯定还会有其他团队沿袭这条新的路径不断探索,或许有一天会成为新的范式?很难说,毕竟是理论创新。
02
Over-Encoding与DS的条件记忆
另外一篇“高调”出现在DS 论文中的字节研究是 Over-Encoding。 这项研究探讨了如何更高效地表达和存储信息,通过将高维特征拆解或重组,提升模型对细粒度知识的记忆能力。
它在当时更多被视为一种特征工程的理论探索,但其关于 “如何用有限参数承载更多信息” 的思考,实际上已经触及了后来 “记忆模块” 设计的核心命题。这一看似冷门的基础研究,实则为DS的 “条件记忆” 埋下了重要的理论伏笔。
下面这个图里面Over-Encoding分析了不同的N的准确度,N在1,2,3的情况都做了测试。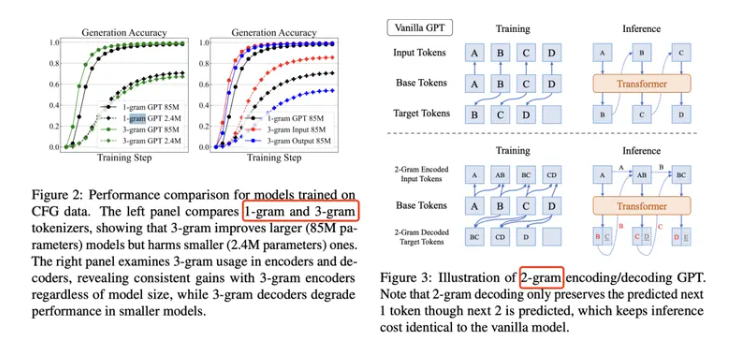
然后再回过头来看DS的文章,它的核心组件Engram里面的框选不分,恰恰跟Over-Encoding的思维如出一辙。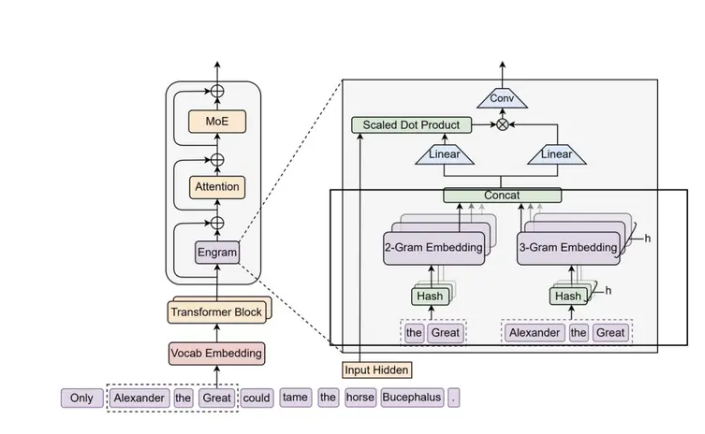
字节的这篇文章和HC一样,都是在25年的前半年发布的,做的试验也都是在较小的大模型上,性能不错,不过scale up,也就是大模型试验还没铺开。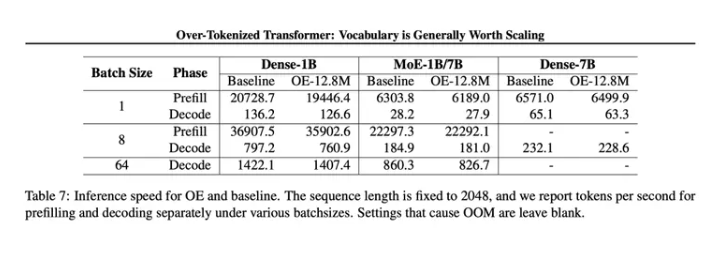
03
字节跳动AI基础研究的冰山一角
其实这里深入思考的话会得到一个很有意思的结论,那就是把DS这家直做理论创新的公司当作镜子,可以折射出字节跳动 AI 基础研究的冰山一角。
因为平时字节的基础研究很多时候都被豆包这个庞大大(可爱)物给遮蔽了,更多的形象来自于C端的产品。
但实际上,除了 HC 和 Over-Encoding 之外,字节 Seed 团队在很多方向上都做了长期、深入的布局。这些工作在自媒体上不算高频曝光,但在学术圈里是有真实影响力的。
把这些研究放在一起看,会发现它们不是零散的点:从稀疏性(UltraMem),到训练框架(veRL);从底层架构(FAN),到模态融合(Seed Diffusion),逐步拼出了一套相对完整的技术生态。DeepSeek 对其中两项工作的引用,也许只是两条技术路线在某个节点的一次交汇;而更多的平行探索仍在各自推进。
04
总结
最后简单总结:技术创新通常走两条腿――“理论突破”和“工程验证”。字节 Seed 团队在 HC 与 Over-Encoding 上的前瞻探索,为行业提供了一个清晰的参考坐标;DeepSeek 则凭借很强的工程执行力,把这些坐标转化成了可见的性能提升。这种引用与致敬,某种意义上说明中国 AI 技术生态正在变得更成熟:它减少了各自为战的隔离,让知识能在不同团队之间流动并产生增量。
不得不说,大厂的基础创新能力太强了,开辟新方向的速度甚至要比验证方向的速度还要快。
特别声明:本文为网易自媒体平台“网易号”作者上传并发布,仅代表该作者观点。网易仅提供信息发布平台。

















