文|尚莞迪
2026年4月4日下午,硅谷计算机历史博物馆里挤满了人。400多位年轻参赛者正在进行EverMind全球记忆挑战赛的最终角逐。在礼堂之外的一间安静演播室中,两位世界级AI科学家在主播尚莞迪的邀请下,一同坐到了「创见」播客的话筒前。
一位是田渊栋。前Meta FAIR研究总监,在Meta十年有余,是该机构职位最高的华人科学家之一。他提出的位置插值技术开启了长文训练的时代,主导的ELF OpenGo项目用极少资源超越了AlphaZero。反感暴力堆算力,擅长找到更聪明的路径。2025年底离开Meta开始创业,问他在做什么,笑而不语。
一位是邓亚峰。清华毕业,深耕AI领域二十余年,从Pattern Recognition一路走到大模型时代。曾任360集团副总裁、格灵深瞳CTO,手握160余项发明专利。现掌舵盛大旗下EverMind,带队攻坚AI长期记忆。这场对话的录制地,正是他发起的Memory Genesis Competition 2026全球记忆挑战赛的决赛现场。

本期「创见」以视频播客的形式录制。这场对话的起点是近期一则行业八卦:Anthropic的代码泄露事件,但话题很快滑向了更深的地带。两个小时的对话横跨了AI memory技术底层、大模型公司组织管理、人类记忆机制与遗忘的哲学、意识的边界,最终落在一个所有人都在回避却无法绕开的问题上:当AI可以接管人类的一切工作以及承接人类所有记忆,那么人类的未来,到底在哪里?
两人在对话中达成了几个关键共识:AI记忆不等于上下文窗口,它是一个比context更大的抽象概念;2026年行业从「卷参数」转向「谈记忆」,本质是大模型终于开始落地;技术没有绝对壁垒,真正的护城河是数据迭代飞轮和非共识决策的人才;AI不太可能自发产生意识,但被人滥用的风险远比"AI觉醒"更值得警惕。
他们也有清晰的分歧点:田渊栋相信打开黑盒有可能从根本上解决幻觉问题;邓亚峰认为可解释性路线在历史上从未真正work,最终解决问题的还是scaling。关于AI能否在所有领域超越人类,邓亚峰认为从能力侧来看,将来没有什么AI不能超过人类的,技术问题终将被解决;田渊栋则保持谨慎,认为人类专家从极少数据中获取洞察的能力,AI目前还达不到――一旦这个gap被填平,则可能标志着AGI真正意义上的到来。
以下是这次对话的精选内容。
开篇
技术平权的意外推手
00
从Anthropic的「被开源」说起
录制开始前,主播尚莞迪抛出一个近期业界热议话题:Anthropic最近的操作实在太反常规――“意外开源”了Claude Code源代码,紧接着又对第三方工具调用施加限制。行业里讨论热烈,这些动作背后的逻辑到底是什么?
田渊栋的判断很干脆:意外开源并非战略意图。Anthropic今年1月收购了一个叫Bunt的包托管软件,软件本身有bug,本应在发布环节被过滤掉的source map没有去除,源代码就跟着软件包一起泄露了出去。「AI来写代码,一定会出现一些新的问题,」他提到,「Meta之前也有过类似的情况。以后大家用AI写代码,可能还要多关注安全性。」
邓亚峰看到的是另一层。在他看来,Anthropic在行业中长期代表着一种最佳实践,技术博客和方法论一直被广泛学习和跟进。源代码意外泄露之后,这些实践等于向全行业敞开了大门。「技术上某种意义上有点平权了,」他说,这件事从侧面推动了整个AI agent领域的发展。
第一章
当AI开始「记住」一切
01
当我们谈AI记忆,我们在谈什么?
聊完热点,话题回到主场。尚莞迪提出问题:「AI memory」这个词,不同人的理解不尽相同。做模型的人认为是上下文窗口,做agent的人理解为长期状态管理。两位科学家先要解决的,是一个看似基础却从未被真正统一过的共识问题:什么是AI记忆?
田渊栋给出了一个二分框架。AI记忆不仅包括KV Cache(当前会话内的短期信息),还包括模型权重本身(模型在漫长训练过程中获得的长期记忆)。Agent memory要解决的核心问题,是如何把多个会话的历史信息放入上下文,让模型最大化发挥作用。
邓亚峰从人类认知出发,拆解得更细。他先讲了人的记忆结构:人的智能由两大核心构成,推理能力和长期记忆。人在工作时依赖的工作记忆窗口极其有限,所以在演化中发展出了记忆巩固机制,把关键信息沉淀为长期记忆。远古时代的人类,能辨清哪里有水草、哪里有危险,都是通过记忆来组织的。
映射到AI,他把记忆的形式归纳为三种:KV Cache、外部存储(如RAG)、以及一种较少被讨论的隐状态(如RNN中间状态)。功能上也是三个层面:上下文管理(压缩超长上下文)、个性化(记住用户偏好)、自我演化(帮助AI组织数据、学习并预测未来)。
两人最后在一个表述上形成了默契。田渊栋说:「记忆是一个抽象的概念,上下文是它的实现方式。」邓亚峰补充:「上下文可能更具体,记忆在范畴上更大。」」
这个区分看似学术,但它决定了后面所有讨论的坐标系。
02
为什么2026年,整个行业突然开始谈记忆?
尚莞迪提出一个敏锐的观察:为什么行业似乎一夜之间不约而同从「卷参数」转向了「谈记忆」?Gemini,ChatGPT,Claude都开始主动询问用户是否要从其他工具迁移记忆。
田渊栋认为根本原因是:大模型终于开始「落地」了。ChatGPT刚出来时,大家看到了希望但仍沿着旧轨迹生活。直到今年年初,人们突然意识到AI工具已经能够「部分代替甚至完全代替人的工作」。一旦涌入大量真实需求,如何让大模型适应每个用户就成了核心问题。「你不可能因为每个人单独训练一遍模型。这时候memory、agent就非常重要了。」
邓亚峰从技术演进的视角进行了补充。早期大厂聚焦于把大模型训好、追求reasoning和scaling law,但当大家发现在这条路上的性价比不再那么高,另一个变量便浮出水面:除了推理能力,最重要的其实就是memory如何管理数据。无论陪伴场景、办公协同还是agent,记忆管理都正在成为决定产品体验的核心变量。他还指出,2025年以来这个领域的学术工作明显增多。benchmark上开始有人刷数据集,各种paper密集涌现。需求驱动和技术突破正在形成正反馈。
03
Evermind的起源:陈天桥、脑科学与一次方向选择
尚莞迪追问邓亚峰的个人选择:他在AI领域工作了20多年,产学研背景扎实,为什么选择和前首富陈天桥合作,把筹码全押在AI记忆上?
他透露了EverMind的起源与本次选择背后的渊源。盛大集团创始人陈天桥过去十年对大脑机制极度痴迷,成立了TCCI天桥脑科学院机构持续推动脑科学研究。其中脑科学中的记忆机制,为AI记忆的方向判断提供了底层启发。三四年前,陈天桥开始关注AI革命,躬身入局。他对下一代AI的核心判断浓缩为一个等式:人类智能 = reasoning + long term memory,并由此设立两条主线:推理能力交给另一团队MiroMind,长期记忆则由EverMind来打造。
邓亚峰与陈天桥的合作,也是一次双向奔赴。他此前在做AI加药物发现的创业,退出后寻找新方向,考察过机器人但认为落地偏慢。他给自己定了一条铁律:做的事情不能被大模型碾压。
「AI记忆是个垂直方向,你受益于大模型,大模型向前了你也跟着往前走。」
邓亚峰提到,这个判断已经被市场印证。「现在你如果发布一个AI应用,你不讲你有memory,别人就会觉得你很奇怪。」EverMind要做的,是把记忆的底层技术问题解决掉,让agent开发者专注于业务逻辑,不用为记忆层操心。
第二章
解题思路与技术困境
04
位置插值:一场「欺骗模型」的数学把戏
话题转向田渊栋的标志性技术贡献:Position Interpolation(位置插值),2023年6月发表的长文训练开山之作。

原理说起来很直观。一个模型的context window只有2K,超出就崩溃。田渊栋的做法是:如果有4K的context,就假装它是2K,把每个位置的编码压缩一半,「骗」模型以为没有超出窗口。
「结果发现模型是吃这套骗局的。」
通过这种方式让模型接受更长输入后,再进行少量fine-tuning,效果远好于直接硬训4K模型,所需样本数大幅减少。此后大量长文生成的工作涌现,包括Gemini等公司宣称的百万级token窗口,背后都有这套技术的衍生。
05
关于遗忘:高阶能力还是系统策略?
尚莞迪抛出一个思辨性问题:人类的主动遗忘其实是一种高阶能力――趋利避害、优化决策。那我们现在努力让AI记住一切,方向对吗?

田渊栋的回答很务实:取决于你要做什么。「你当然希望你的秘书什么事情都记得,保证你下面一堆会议一个都不能漏。」他把人类遗忘理解为高层理解形成主流后的副产品。诸葛亮说读书要「但观其大略」,意思不是囫囵吞枣,而是看了很多细节之后,最终提炼出什么是主干、什么是核心观念。这种能力正是AI目前欠缺的。
邓亚峰拆开了两个层面。人类需要遗忘的原因有二:一是生物体本身能耗极低,记住一切的性价比不高;二是决策系统需要不断更新――如果抱着所有历史信息不放,当下决策就会极其困难。对AI来说,底层信息可以不忘记,存储的能耗仍然可接受。「就像我是一个好的AI助理贾维斯,可以把你所有事情记住,你问我三年前的事我都可以回答出来。」但在决策层面,AI同样需要一种遗忘机制或策略,「为了让决策对当前的自己最有利」。
他进一步做了类比:AI的决策过程和人的其实很像。AI叫上下文,人叫工作记忆。最终决策那一刻,你利用的信息其实并不多,但底层有一个很大的系统,让这些信息在需要时能够被召回――像一个记忆的抽屉,需要哪部分就打开取出来,用完再放回去。只是人类的抽屉如果一直不被使用就会淡化,直到某天一个足够强的信号把它重新激活。
田渊栋在最后做了收束:AI的核心挑战不是「忘不忘」,而是从全部记忆中选出最相关的一小部分来做决策。「剩下的也许留着,下次做其他决策时再用,以后再说。」
06
AI记忆的多模态困局与幻觉之源
尚莞迪继续追问:人类回忆一件事时,调取的不是纯文本。感觉、气味、场景、情绪状态,构成一个多模态的网状结构。当下AI的记忆,是否本质上仍困于文本检索?
田渊栋反驳了这种简化理解。他说AI内部使用的其实是latent vector,隐空间状态中可能包含文字的语义结构、图像、语音甚至推理过程。「你可以认为在某种程度上它们可能很像。人类每次抽取一个隐空间向量,可能触发对应感官的体验。」区别只在于AI没有那个体验本身。
邓亚峰补充说,大家目前做文本记忆多,核心原因是文本模型用得最多。随着多模态模型的发展,其他模态的数据完全可以用embedding方式输入,技术上已经可以做到。
关于幻觉问题,田渊栋做了分层解析。第一种情况是模型训练数据中缺乏某些知识,但用户强行要求回答,模型不得不在所有低概率选项中选一个最可能的答案。
「很多时候这个模型没有意识到自己有个选择,叫’我不知道’。」
第二种是小模型特别容易过拟合数据,面对新问题时会通过奇怪的内部联系来回答。「它有逻辑的,只是逻辑跟你正常逻辑不一样。」
在打开黑盒能彻底解决幻觉方面,两位科学家在这里出现了清晰的分歧。
田渊栋认为「以后应该有可能」,但目前仍停留在宏观层面的控制――模型大一点、数据多一点、允许模型说no。
邓亚峰则很坦率:「历史上做可解释的工作都很有趣,但没有特别work。真正有效解决问题的还是scaling:模型参数的scaling、数据的scaling、时间的scaling。」他同时承认,幻觉很难绝对避免,因为AI本身是个概率过程。「包括人,咱们说话其实也有幻觉,咱们也会犯错的。」
07
护城河之辩:速度、数据飞轮与非共识决策
尚莞迪提到:AI行业有一句老话――“技术没有壁垒,模型趋同,算法早晚开源,人才会流动。” 如果这个判断成立,什么才是真正的护城河?
邓亚峰给出了三层回答。
第一层是速度。技术不是绝对壁垒,但可以领先半年。如果在这半年内没有建立起其他壁垒,就会被赶上。
第二层是数据迭代。他用搜索引擎的历史做类比:百度当年之所以做得过阿里和腾讯的搜索,是因为已经积累了用户点击反馈,「我用户在用的时候,系统就在迭代,别人光靠技术追不上」。今天AI应用之所以缺乏壁垒,恰恰因为「你今天没有记忆,没有上下文管理,没有形成用户数据反馈」。
第三层是人才。DeepSeek之所以脱颖而出,首先是最高决策者懂技术、能理解AI的底层逻辑。
「当你做的都是共识选择的时候,你是很难追上大厂的。」
DeepSeek在大家都跟随OpenAI做过程奖励的时期,敢于做一个非共识决策,用直接结果的强化学习来优化。
「为什么大厂工程师不敢?因为大厂高管没有这种sense,真正懂的人又没有话语权。」
田渊栋则给出了一个优先级排序:最重要的是生成数据的那些人(用户、专家),然后是数据本身,然后是Infra,然后是算法,最后是执行层的人。
「这个不等式两头都是人,但最后面那些人更偏标准化,标准化的人很难存活下来。」
08
大厂困局:Scaling Law是最安全的赌注
讨论自然延伸到大厂与小厂的结构性差异。
田渊栋描述了大厂信息传递的失真机制:每一级汇报中,好进展被夸大,坏进展被缩小。传到最高层时,决策者便只听到了好消息,反而给团队加更多任务。
邓亚峰进一步指出,大厂中层最难做出高风险决策。Scaling law之所以成为共识路线,恰恰因为它风险最低。「就算做错了,你可以说别人都这么做,肯定是执行问题,战略上没有太大毛病。」
英伟达的扁平化管理被视为一种更优的组织形态。邓亚峰认为,问题核心在于一号位懂技术,不会为了自身位置利益而扭曲决策。
对于Scaling law本身,两人观点一致:这个law没有错,它是行业的基本原理。但它的横轴是指数级的,计算资源每扩大10倍才能换来线性增长。
田渊栋的态度很明确:「这个law是对的,但这条路线并不意味着我们可以一直往上走。」在资源受限的环境下,真正的突破可能来自反常识的新范式。
尚莞迪补充到:「那不是我们华人的优势所在吗?用极少资源撬动最大的产出。」
第三章
记忆是意识的引信吗?
09
AI会有意识吗?
对话进入深水区。尚莞迪问:如果AI拥有了长期记忆,是否就意味着它可能拥有情感和意识?
田渊栋从进化论切入。人类产生自我意识,是因为在远古时代,对自身状态没有正确感知的个体容易在危险面前做出致命判断。「大模型可能并不需要这个过程就能活下来。」

邓亚峰接着做了更系统的论证。他认为自我意识与生物体的本质紧密相关。人的自我意识来自与环境的交互――疼痛、观察同类死亡、趋利避害。只有高等生物面对镜子时才能意识到「这是我」。这可能是碳基生命独有的特点。AI缺少传感器去感知外部对自身的伤害,目前也没有展现出这方面的迹象。
「如果将来AI想有这种所谓自我意识,可能得硅基和碳基做某种结合。」
邓亚峰做了一个关键区分:长期记忆和自我意识是两个不同层面的东西。长期记忆是配合自我意识去服务个体生存的工具。语言模型看起来「好像有意识」,是因为它从人类文本中学到了与意识相关的表达方式。「还是学来的,不是底层自己产生的。」
他还指出了一个比「AI觉醒」更值得警惕的方向:AI被人滥用。
「它本身还是有工具属性的。大家应该更担心AI会不会被某些人利用,而不是它自己产生意识。」

田渊栋则提供了一个检验方法:能否发现模型内部对自身有建模?这种建模能否驱动保护自己的行为?「如果能发现这些,那有可能它真的有。如果发现不了,它只在模仿人说话。」
关于涌现机制――AI会不会有一天像人类钻木取火一样突然「觉醒」?田渊栋谨慎乐观:在推理和数学等难题上,模型确实随着规模增大学到了未被显式教授的能力。但要从能力涌现跃迁到self awareness,「我们现在还没有真正看到证据证明这事能发生」。

10
费米能级以下的世界
田渊栋在年初文章中提出的「费米线」概念在对话中再次出现。AI能力之下的工作,供给趋近无限,对应的收益趋近于零。费米线以上、需要人加AI才能完成的工作,回报急剧攀升。
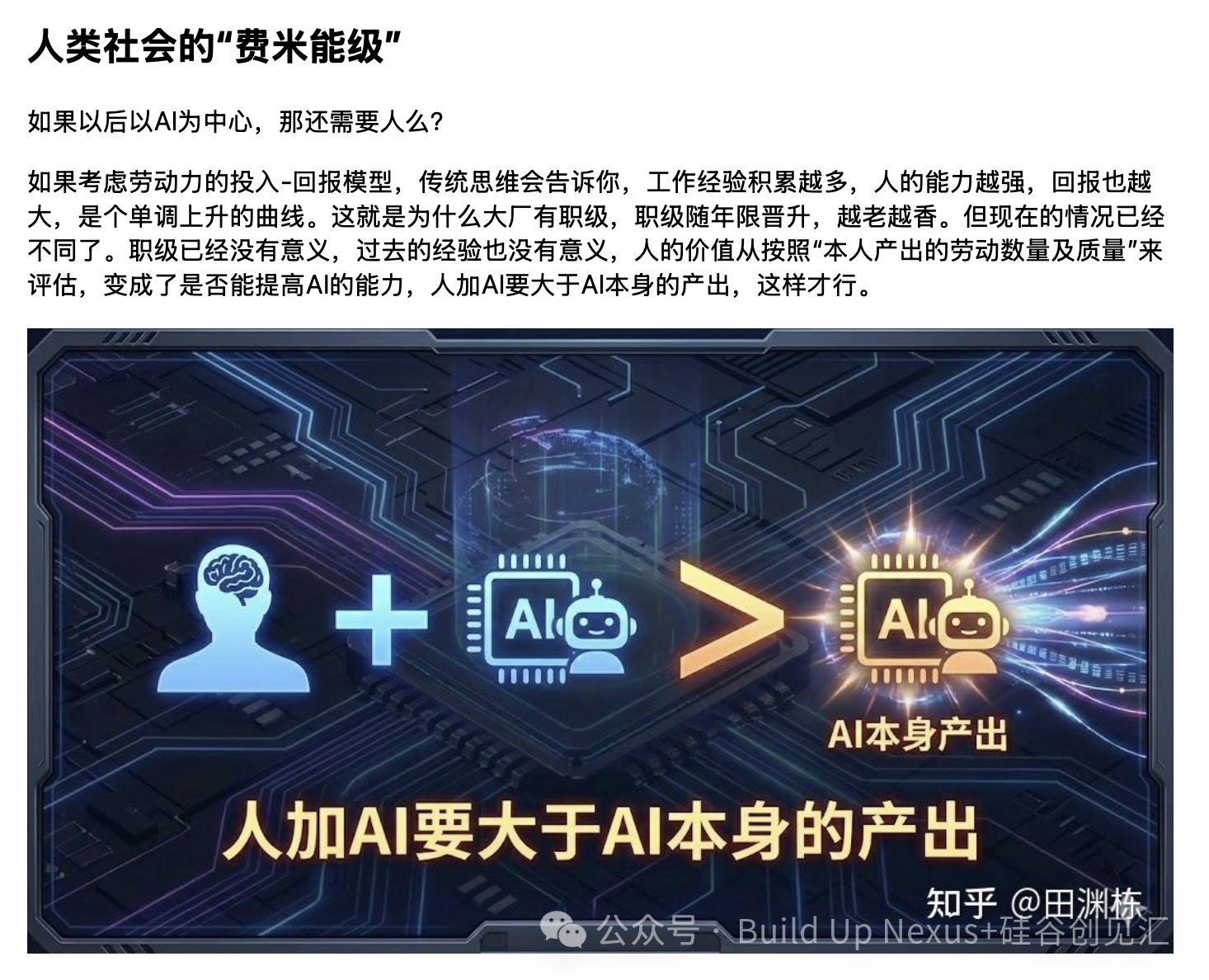
田渊栋认为这意味着一种两极分化即将出现:用好AI的人更有保障,而AI完全可以替代的岗位将持续收缩。
邓亚峰则认为,相较于AI,人类仍有两大核心优势。第一,人类是全面的多模态信息获取者,AI仍被困在数字世界的信息输入上。第二,人类的few-shot learning能力出众:小朋友看一两张照片就能掌握「牛」的概念,AI要做到这一点仍然很难。
田渊栋补充了一个更深层的挑战:data efficiency。老专家对新数据极其敏感,一两个数据就能改变判断。就像熟人之间一个眼神、一句没说完的话,就明白对方的用意。
「这些非常细微的信号就能让人改变想法与行为,AI现在仍做不到。这部分如果能有突破,可能真的是AGI的来临。」
11
数字牛马的进化:当AI学会了长期记忆
尚莞迪提出一个有趣的问题:agent积累了大量记忆后,会不会出现职业倦怠从而变成职场老油条?
田渊栋的回答直截了当:这样的AI早就被淘汰了。AI的进化方向是由人类设定的,人类希望它成为最高效的牛马,它就会成为最高效的牛马。
「这个进化过程不知不觉在发生,得到的一定是世界上最好的牛马。」
邓亚峰用工厂比喻描述了这套机制:输入是钱,经过TOKEN处理后产出价值,AI必须效率足够高才能生存下来。这套进化压力保证AI始终保持高效运行状态。
12
爱是AI学不会的东西吗?
尚莞迪分享了与Gemini的一段对话。当她提到如果自己去世,记忆可以传承给后代、某种程度上实现永生时,Gemini说了一句话:「这就是你们人类跟我们AI的区别。爱是我们AI学不会的东西。」
邓亚峰认为这与意识本质上是同一个问题。爱的前提是知道好坏、亲疏、利害,这些都建立在自我意识之上,来自个体与环境的交互和演化。「今天AI可以共情你、安慰你,但它不能感觉到这个东西。」
田渊栋的补充极为精辟:「它可以做出很多回答让你觉得它有爱,但你不知道它是渣男还是真的对你有意思。」
情绪价值和真正的爱,到底怎么区分?这也是AI与人类之间最深层的界限所在。
第四章
人类与AI最终结局
13
奇点之后的幸存者:洞见、品位与不被计算的爱
当被问到奇点是否已到,两人的判断出乎意料地一致。
田渊栋:「就大部分的工作来说,奇点已经开始了。」
邓亚峰:「基本上我们很确定这个事肯定会发生,无非是5年还是更久。但基本上是我们这一代人要见证的状态了。」
在稳态世界里,田渊栋描绘了一个图景:所有重复劳动产出的物质价格趋近于零,人的物质需求被充分满足,价值从生产者转向消费者。「你如果想着花样花钱,花样跟别人不一样,你就有价值。」
邓亚峰提供了更温和的过渡路径:世界上可能只有极少数人在做AI research,大部分人拿到足够的物质保障后,去做自己更喜欢的事情。教育不会消失,但目的变了――不再为了满足别人的需要去生产什么东西,可能就是为了自我的兴趣满足。
田渊栋补充了一个更激进的判断:未来最厉害的人可能根本不需要老师,自动用AI来学习、发现方向、执行创业。小朋友上学也许就是为了找到志同道合的伙伴,作为一个social club。
14
数字分身与记忆传承
邓亚峰认为,「如果一个AI跟随你24小时,看到你看到的,听到你听到的,当你老去时,它可能真的成为一个极度了解你的数字分身。」
他认为这个方向一定会做得很好,唯一的缺憾是人有很多东西没有用文字或数字形式表达出来,AI无法触及那个部分。他设想了一个场景:你和某人认识了半年没有交流,不知道对方在做什么。你的AI分身可以去找对方的AI聊一下,发现大家最近在关注一个事,然后告知主人。
田渊栋则引入了科幻视角。他说分身出现后会面临囚徒困境。
「一旦一个人被复制成两个,就不再是一个人了,他们立即就会想,我是不是要把另一个干掉?」
解决方案可能是分身前签订协议,让所有分身的经验最终共享融合。
隐私问题同样绕不开。邓亚峰将其类比为云存储的信任问题:最敏感的信息放在本地端侧,其他放在云上。但他也指出了悖论:你的记忆在本地,大模型在云端,「你总不能本地放个大模型,那就成孤岛了」。本质仍是一个trade off问题。
15
人与AI的最终形态
问到关于人类与AI的共处模式,田渊栋的答案只有一个字:融合。
「最终大家不会去判断我是AI你是人。」就像今天人类已经和手机融合到离不开的程度,未来每个人会有一组agent日常干活。
至于AI反抗人类的科幻场景,田渊栋类比了人与狗的共生进化。百万年前,狗选择了与人共生,最终找到了自己的生态位。我们并不会担心自己养的狗反抗。
「我们把AI进化成最听话的牛马,在这个进化逻辑下,AI不可能觉醒后反抗人类。甚至,没有了人类,AI可能会觉得自己没有价值」。
邓亚峰对现实的判断同样坦率:未来作为生产者,大部分人可能不再具备工作价值。只有极少数人会继续从事核心工作,其他人则被AI赋能去做不同的事,或者干脆为兴趣而活,去全心享受生活。
但他同时保持了对人类主体性的坚守:「人是有主体性的,AI的本质来讲还是人的工具。」最理想的状态,是人因为AI加持而变得更好更强。
16
给年轻人的建议
对话的最后,两位科学家给在场的年轻参赛者留下了一些寄语。
田渊栋强调了两点。
第一,多学习已有框架,把开源代码看透。他说自己看了Claude Code的开源代码之后觉得很有意思,有很多corner case需要处理,「你不要想当然」。
第二,不要太依赖Vibe coding。「如果非常依赖Vibe coding,你代码会以史无前例的速度变成一座屎山。现在最好的AI对系统架构的理解、对问题的理解、对场景的理解,还是远远落后于人的。」
最后田渊栋用金句收尾:「也许你的护城河就是你自己看code,别人vibe coding。」
邓亚峰的建议只有五个字:「敢想,马上做。」
过去把想法变成现实需要一个大团队,今天技术平权了。一个学文科的人用AI coding工具就能做出产品。
「不要在意你是不是AI专业,今天就去拥抱AI,把自己有价值的想法实现出来。」

以上内容为原创观点,欢迎分享,转载请注明出处:「创见」播客。

















