
���ڶ���DID��DID��1.DID���ǰ�����⡰���߽���ִ��+�ѵ�DID+�¼��о���, ������slides��2.������������DID��, ��TWFE���ƴ���ЧӦ������, ��Bacon�ֽ�ʶ�����ƫ��3.�䷶! ��ƪAER��һͼ������������DID���½�չ����, �����ֱ�ӷ��ˣ�4.����Sun��Abraham��2020����TWFE���ƶ��ڻ�DID����ͼչʾ�������ϸ���code��5.����DID��DID��DID, ����Stataִ�������������¹����ѧϰ��6.����DIDǰ�ط���������, e.g., ����-�˳���DID, �����ԺͶ�̬�Դ���ЧӦDID, ����ѡ������ȣ�7.����DID��ƽ�����Ƽ���, �¼��о�ͼ����, ��ο������ı�ķ������ָ�ϣ�8.��ο! Ӫ����ͼƻ����ڵ���TOP5! ����DID+�������Ƚ�DID��9.���¼��о�����չ���������Ĺ���, �ְ��ֽ�ѧ���£�10.��˫�ز�ַ����¼��о���, ˫�ز����������Ҫע������⣬11.ϵͳ����DID���½�չ���Ӷ���DID��DZ�������ǰ������������ʹ���! 12.��DID�е�ƽ�����Ƽ���,��̬ЧӦ, ��ο������, Ԥ��ЧӦ�̳�
���죬���Ǹ���һ�ݡ�DID handbook���ٴ�ͷ��β����һ�£��Ӿ���DID��Bacon�ֽ����DID���½�չ�ĸ��ֹ��Ʒ���������������ʵ�ִ��룬���������Handbook�����Ӹ��ָ���DID���Ʒ����Ľ�������������жԱȡ��·��������ݺʹ��붼�������������ֱ�ӷ���Stata�����г��������������DZ�ķ���̳̣������������㻹����DID���Ǿ������Ҫ�ٻص�����ѧѧ��😄��
����
��DID��ķ���ֲᡷ
*��л������ȺȺ��@regmoneky �����������˲������ݵ�ע�ͣ�ԭ�������·�Source��
Source��DID_Handbook��https://github.com/IanHo2019/DID_Handbook����ӭ�Ը��õı������������������������ϵ��ʽ��ianho0815@outlook.com��
˫�ز�ַ���Ҳ����дΪDID��DiD��DD���Ҹ�������ʹ��DID���ǵ�������ѧ�������е�ͳ�Ƽ���֮һ���㷺Ӧ���ڶ����о��С����ܻ�ӭ����Ҫԭ������ʹ���߶������Ӧ��DID��չʵ֤�о��������"��������"��Ȼ�������Ķ���һϵ�������2017���������ĸ�������������ѧ���ĺ�����ʶ��˫�ز�ֲ�û����֮ǰ�������ô�����������Դ�����ҪĿ���Ƿ����Ҷ�˫�ز�ֵĸ��������⣬�Լ���������˫�ز��ʱʹ�õ�Stata���롣��ע�⣬��������ֻ��ÿ��˫�ز�ָ�ʽ��һЩϸ�ڽ����˸���������ϸ���������Ķ���Щ���ġ�
���䡢��ͳ�ͽ̿���˫�ز��
˫�ز�֣�����˼�壬�漰������ʱ�ڶ�����Ⱥ����бȽϡ���һ���������Ⱥ��֮����еģ����ڶ������������ʱ��֮����еġ��ڴ���ʱ��֮���Ϊ���ܴ�����Ⱥ�壬����Ϊ���ܴ�����Ⱥ�塣������λ����Ϊ�����顣˫�ز��ͨ��������ʶ����ƽ�������Ⱥ���ϵ�ƽ������ЧӦ��ATT�������������ƶ���Щ��δ��������ת��Ϊ�������Ƶ��˵�ƽ��ЧӦ����ʵ֤�о��У�ʵʩ˫�ز�ֹ淶����������������˫��̶�ЧӦ��TWFE���ع飺
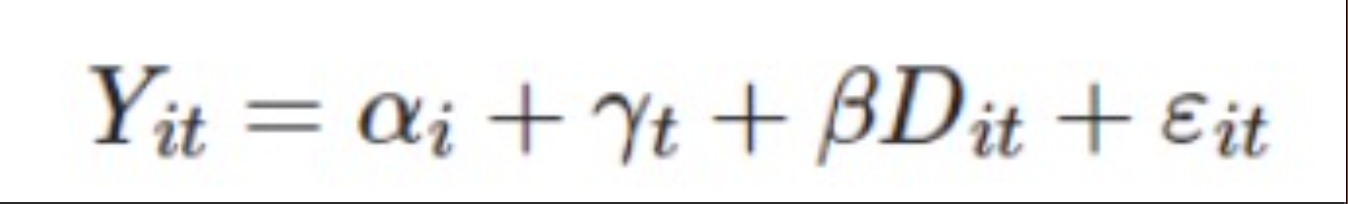

˫�ز�֣�Difference in Difference�����DID������ƽ�����ơ���Ԥ�ںʹ���ЧӦͬ���ԣ�TWFE�ع��еĹ��ƽ�����ڲ������ߴ��������ЧӦ��Ȼ�������ҵ��ǣ�����TWFE�ع�ͨ���Դ���ЧӦ�������Բ������Ƚ��ԡ����ǵ�ǰDID������һ�����ŵ��о����⡣
��Ҫע����ǣ���������ֻ�������������ߴ�����absorbing treatment����һ��һ������������ߴ���������δ�����κ�ʱ����ڶ������˳����ߴ�����һЩ�о���Ա���Խ�DID�ƹ㵽�����������ߴ�����Ҳ��Ϊ��ת�������ߴ�����switching treatment��������ƣ����ǿ��еģ�����Ҫ����ļ��衣
��Stata�У�����ʹ������xtreg��areg��reghdfe��xtdidregress��������TWFE�ع顣��Ҫע����ǣ�xtdidregress��������Stata 17����߰汾����reghdfeֻ���ڰ�װ��reghdfe��ftools��֮��ʹ�á���ϲ��ʹ��reghdfe����Ϊ����������ѡ��Ҽ����ٶȽϿ졣reghdfe�Ļ�������£�
reghdfe Y D, absorb��id t��cluster��id��
absorbѡ��ָ���̶�ЧӦ��clusterѡ��ָ����������ļ���
����˫�ز�ֵĸ�ʽ���漰����ʱ��κ�����Ⱥ�壬�����Ϊʲô�ҳ�֮Ϊ���䡢��ͳ�ͽ̿����ʽ��������ζ�š��������������硢���һ�֣�չʾ��DID����Ĺؼ����ۣ���ͳ��ζ�š���ͳ�������Ѿ������˺ܳ�ʱ�䣬�����ִ�Ӧ������ʱ���̿�����ζ�ţ����Ѿ�������̿����б����ܹ�������Jeffrey Wooldrige�ġ�������������ݵļ������÷�������2010����Bruce Hansen�ġ���������ѧ����2022���������Щ���ܴ����ĸ�����ͬһʱ�ڽ��д�����TWFE DID�����ƹ㵽��ʱ�ڶ�������������ִ�����ʱ����Ϊ�ֿ����ߴ�����block treatment����
��2017��֮ǰ�������о���Ա�������ΪTWFE DIDҲ���������ƹ㵽�����ڲ�ͬʱ�ڽ������ߴ��������������������staggered treatment����Ȼ������ʵ������ˣ���������������������������Բ����ס�
��̬˫�ز���µ�Bacon�ֽ�
���ȣ�ʲô�Ǿ�̬˫�ز�֣�Static DID������̬˫�ز�ֵĹ��Ƶ��ǣ�һ������ʱ��仯�ĵ�һ����ЧӦ��Ҳ����˵��ͨ�����о�̬˫�ز��ģ�ͣ�����ֻ�õ�һ����ֵ������ʹ��һ��ϵ���ܽ�������ʵʩ�����Ĵ���ЧӦ�������˫�ز������һ�־�̬˫�ز�֡�
��Σ�ʲô��Bacon�ֽ⣨Bacon Decomposition��������������DID��, ��TWFE���ƴ���ЧӦ������, ��Bacon�ֽ�ʶ�����ƫ�������������Goodman-Bacon��2021���������������֤����˫�ز�ַֽⶨ����ָ��TWFE˫�ز�ֹ������������ڽ�������������������п��ܵ�����/��ʱ��˫�ز�ֹ������ļ�Ȩƽ��ֵ��Ϊ��ǿ����һ���֣����߽�˫�ز�ֹ�����дΪImage��
˫�ز�ַֽⶨ���dz���Ҫ����Ϊ���������ǣ��ھ����˫�ز���У���������ڶ��ʱ��ν������ߴ����ĸ��壬�ʹ���һ�֡����á��ıȽ�������������ڴ���֮ǰ��֮�����ڴ����������ڴ�������бȽϡ����������о�̬˫�ز��ģ��ʱ����Bacon�ֽ⣬���Կ������ǵĹ��ƽ���������Ժδ��Ĺ��ס����磬һ������˫�ز�ֹ��ƽ������ֻ����Ϊ��һ��Ȩ�ؽϴ�IJ��õıȽ��г����˸��Ľ����
��Stata�н���Bacon�ֽ⣬Andrew Goodman-Bacon�����ᰢ����˹��������У���Thomas Goldring��������������ѧ����Austin Nichols������ѷ����д��bacondecomp������������£�
bacondecomp Y D, ddtail
YΪ�������DΪ�������������ddtailѡ�����ڸ���ϸ�ķֽ⡣
Stata 18��������2023��4��25�գ�������һ���µĹ�������estat bdecomp������ִ��Bacon�ֽ⡣��������didregress��xtdidregress����֮����ͨ������graphѡ��������ɴ���ͼ����
�ź����ǣ�Stata�е�Bacon�ֽ���ھ���ǿƽ��������ݵ��������Ч�����ھ��в�ƽ��������ݵ������Ϊ�˽���Bacon�ֽⲢ�ҵ�����ÿ��ϵ����Ȩ�أ����Գ�����Clement de Chaisemartin��Xavier D'Haultfoeuille��Antoine Deeb���������У���д��twowayfeweights��
ƽ��������ݵĺϳ�˫�ز�֣�Synthetic DID��
Arkhangelsky���ˣ�2022�������һ�ַ��������ϳ�˫�ز�֣�SDID��ǰ��, �ϳ�˫�ز�ַ�SDID�������ܺ�ʾ��, ��code�����ݣ������������˫�ز�֣�DID���ͺϳɿ��ƣ�SC�����������˵��ص㡣
��DID���ƣ�SDID���������д���ǰ���ڼ䴦����Ͷ�����֮����ں㶨�IJ��졣
��SC���ƣ�SDIDͨ�����¼�Ȩ��ƥ�䴦��ǰ�������ſ���ͳ�ġ�ƽ�����ơ����衣
SDID�Ĺؼ��������ҵ�����Ȩ�أ�wi������ȷ���Ƚ��������ߴ���ǰ������ѭƽ�����Ƶĸ���Ͷ�����֮����еģ����ҵ�ʱ��Ȩ�أ���t��������Щ�����ߴ������ڼ�����Ƶġ����ߴ���ǰ�ڼ䡱���ߵ�Ȩ�ء�ͨ������ЩȨ��Ӧ���ڱ�˫�ز�֣��ض���������ڼ�������Ȩ�أ������ǿ��Եõ����ߴ��������ЧӦ��һ�¹��ơ����˵��ǣ��÷�������Ӧ�����н������ߴ�������������ҵ��ǣ��ڲ�ƽ��������ݵ��������ʹ�ø÷����������������ƶ�̬ЧӦ��
��Stata�У�����ʹ��sdid������Damian Clarke��Exeter��ѧ����Daniel Pailañir��������ѧ����д����ʵʩSDID����������£�
sdid depvar groupvar timevar treatment, vce��vcetype��
���У�depvar���������groupvar��ָʾ����ı�����timevar��ָʾʱ���ڼ�ı�����treatmentָʾ���ض�ʱ���ڼ��ܵ����ߴ����ĸ��塣vce��vcetype����һ����ѡѡ�����ָ�����ڹ��Ʒ���ķ��������õ��ƶϷ���������������bootstrap�������з���jackknife������ο������placebo�������ƶϷ���noinference�������ֻ��һ��������ܴ���������ʹ���������͵��з�������ʹ�ð�ο������������Ҫ����һ�����ܴ����������Ķ��ո��塣
ֵ��ע����ǣ�����ʹ��graph��g1onѡ���ͼ������Arkhangelsky���ˣ�2022�е�ͼ1������ʾ����Ȩ�أ�ɢ��ͼ����ʱ��Ȩ�أ����ͼ���ͽ�����ƣ���ͼ����
��̬˫�ز�֣�Dynamic DID��
ͨ�����о���Ա�Խ����ƾ�̬ЧӦ�������⣻���ǿ��ܻ��뿴�����ߵij���ЧӦ�����磬һ��Sibal Yang��Canvas�Ϸ������µ����⼯����ô�ڽ�ֹ����֮ǰ��ÿһ�죬���⼯��ѧ���Ҹ��е�Ӱ����ʲô��������Σ�����Ķ�̬˫�ز��ģ��������������ЧӦ��ʱ����仯������������Ƕ�̬˫�ز��ģ�͵�һ��ʾ����
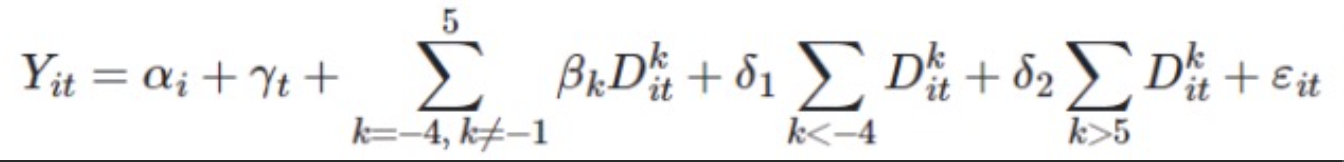
�ڶ�̬ģ���У��о���Ա��Ҫ������ع����Ե����⡣������ع����Ե����������������ʾ�ų�-1�ڼ�Ĵ�����������������ߴ���ǰ�����һ���ڼ䣩�����⣬�����ҶԽ�Զ������ڼ�����˷��飬��Ҳ�ǽ����ƽ������ij���������
������˫�ز�ֵĸ�ʽ�У�Ҫ��ȡ����ƫ���ƾ�Ҫ�Ⱦ���˫�ز�ָ��ӵöࡣ�����������ѧ����ͼ���������⣬����������������Ŭ��������������ֻ���ܼ���ȫ�µģ���̬�ģ�˫�ز�ֹ���ֵ�Լ���Stata��ʹ�����ǵ���Ӧ�����ע�⣬����ijЩStata�����ڿ����У�����ڽ���Ӧ�����о�֮ǰ������Ķ����ǵ������ĵ���
���ڽ���Ȩ�ص�˫�ز�ֹ��ƣ�Interaction-Weighted Estimator for DID��
Sun��Abraham��2021��Ϊ��̬/��̬�̶�ЧӦTWFEģ���е�ϵ��ʶ������˼��衣������ԣ��������ЧӦ��ʱ��仯������k����k�ı仯������ô��̬TWFE�̶�ЧӦģ���еĹ���ֵ������ƫ����ڶ�̬TWFE�̶�ЧӦģ���У�����ֵ��ͬ���Լ�������Ȼ��Ч������k���ܴ�����֮�䲻�ᷢ���仯�����ź����ǣ�����������ЧӦ��������ʱ����̬�Ͷ�̬TWFE�̶�ЧӦģ���еĹ���ֵ������ƫ�
Ϊ��Ӧ��TWFEģ���е�ϵ������Ⱦ���⣬Sun��Abraham��2021�������һ�ֻ��ڽ���Ȩ�أ�IW���Ĺ��Ʒ��������ǵĹ���ֵͨ�����ƶ����ض��������ƽ������ЧӦ����cohort-specific average treatment effect on the treated, CATT���Ŀɽ��ͼ�Ȩƽ��ֵ����������б�����Ϊͬʱ�״ν������ߴ��������и�����ɵ�Ⱥ�顣
����һλ���ߣ�Liyang Sun����ʡ����ѧԺ������д��һ��Stata������eventstudyinteract������ʵʩ���ǵ�IW���Ʒ������������Ƶ��������䡣Ҫʹ��eventstudyinteract��������밲װ��һ����������avar����������£�
eventstudyinteract y rel_time_list, absorb��id t��cohort��variable��control_cohort��variable��vce��vcetype��
��ע�⣬���DZ������һ�����ʱ��ָ���б��������ھ���Ķ�̬˫�ز�ֻع���һ����
���ҵ��ǣ����������estout��������̫���ݣ���ˣ�Ҫ��ͼ���б�������������Ҫ�Ƚ�����洢��һ�������У�Ȼ���ٴ����þ���
DID��˫���Ƚ�����ֵ��Doubly Robust Estimator for DID��
ǰ�أ�˫���Ƚ�DID, �����DID��һ������
Callaway��Sant'Anna��2021���ر��ע�ֽ����������������g��ʱ��t��ƽ������ЧӦ�����С�����Ǹ��ݸ����״ν������ߴ�����ʱ��ζ���ġ����ǽ��ò�����Ϊ�����-ʱ��ƽ������ЧӦ������ATT��g, t����ʾ������������ֲ�ͬ���͵�DID���Ʒ��������Ƹò�����
����ع飨outcome regression��OR����
����ʼ�Ȩ��inverse probability weighting��IPW����
˫���Ƚ���doubly robust��DR����
�ڹ����У�Callaway��Sant'Anna����ʹ��DR��������Ϊ�÷���ֻҪ��������ȷ��ָ���Ƚ���Ľ��������÷�ģ���е�һ��������һ�������ߣ���
����λ������Fernando Rios-Avila������д��һ��Stata������csdid������ʵʩCallaway��Sant'Anna��2021���������DID���Ʒ��������ڲ�������2✖2��DID���ƶ���ʹ��drdid�����õģ����Ҫ����csdid�����DZ��밲װ������������csdid��drdid��
��������£�
csdid Y covar, ivar��id��time��t��gvar��group��
Ҫ�������ģ�ͣ�������Ҫgvar��������Ϊ���ܴ����ĸ����״ν������ߴ�����ʱ�䣬����δ�������ߴ����ĸ������0����ע�⣬�������������ǽ�Э���������ڻع��У���ijЩ����£�ƽ�����Ƽ�����ܽ��ڶԹ۲쵽��Э�������е����������
��������м������õĹ���ϵ��������Ĭ�Ϸ�����dripw������������ʼ�Ȩ����ͨ��С���˷���˫���Ƚ�DID����ֵ���÷���������Sant'Anna��Zhao��2020�����о�������ʹ��method�� ��ѡ������Ϊ�������õķ��������⣬Ĭ������£����Ƶ����Ƚ��ͽ�������Ȼ������������ѡ��ɹ�ѡ������ʹ��wbootѡ����г˻�Wild Bootstrap���ơ���Stata�����������help csdid���˽������ϸ��Ϣ��
Callaway��Sant'Anna��2021�����ṩ��һЩ�ۺϷ����������γɸ�������������������Stata�У����ǿ���ʹ��post-estimation estat��csdid_estat�������ɾۺϹ��ƽ�������ʹ������������bootstrap procedures�����Ʊ����Ƽ�ʹ�õڶ������
˫�ز�ֵĶ���-ʱ�����ֵ
��2020��������Cl��ment de Chaisemartin��SciencePo����Xavier D'Haultfœuille��CREST��д��һϵ�����ģ�����˲�ͬ��˫�ز�ֹ��Ƽ��������ǵ���Ҫ���װ�����
������ЧӦ��ʱ����Ⱥ���������ʱ�����ǵĹ���ֵ����Ч�ġ�
���ǵĹ���ֵ�������ߴ�����ת���������������˳�������Ȼ����Ҫ����ļ��裻de Chaisemartin��D'Haultfœuille��2020����ȷ����˹���Y��1����ǿ�����ԡ�Y��1���Ĺ�ͬ�����Լ�ʼ�����ض�ʱ�䴰���н������ߴ������ȶ�Ⱥ��Ĵ��ڡ�
���ǵĹ���ֵ��������������н������ֵ����ߴ������ۿۣ������ߴ���ʱ��̣���Ȼ�ܵ����ߵ�Ӱ����Ծ�СһЩ����������Ǿ���ѧ��ͳ��ѧ�ܹ��ܺý�ϵ�֤�ݡ�
��������˼��ְ�ο������ֵ��ͨ��ģ��ʵ�ʹ���ֵ���죩���Լ��顰��Ԥ�ڡ��͡�ƽ�����ơ����衣
��ע�⣬��ʹ����δ���ܴ�����Ⱥ����Ϊ�������һع���û�п��Ʊ���ʱ�����ǵĹ���ֵ����ֵ�ϵȼ�����һ���н��ܵ�Callaway��Sant'Anna��2021���Ĺ���ֵ�����⣬��ע�⣬de Chaisemar��D'Haultfœuilleʹ�á�staggered��һ�����ƺ�����������ת���Ĵ�����ơ��������dz���һ�£�ͨ�����dz��������ߴ������Ϊ�������ʹ������������������ʹ���������������ͬ����ܵ�����Ӱ���ʱ����ڲ������ơ�
de Chaisemar��D'Haultfœuille��д��һ��Stata������did_multiplegt������Ӧ�����ǵĹ���������������£�
did_multiplegt Y G T D
����Y�ǽ��������G��Ⱥ�������T��ʱ�������D�Ǵ�������������������кܶ�ѡ�����ֻ���ܼ�����Ҫ��ѡ�
���ָ����robust_dynamicѡ���ʹ��de Chaisemartin��D'Haultfoeuille��2022��������Ĺ���ֵ������ʹ��de Chaisemar��D'Haultfœuille��2020���еĹ���ֵImage�����Ҫ���ƶ�̬����ЧӦImage�������ָ��robust_dynamic�����ǿ���ʹ��dynamic��#��ѡ��ָ��Ҫ���ƵĶ�̬ЧӦ��������
��ָ����robust_dynamicʱ��Stataʹ��de Chaisemartin��D'Haultfoeuille��2022��������ij���ְ�ο����long difference placeboes�������ǿ���ʹ��firstdiff_placeboѡ��ʹStataʹ��de Chaisemar��D'Haultfœuille��2020���������һ�ײ�ְ�ο����ͨ��placebo��#��ѡ�����ָ��Ҫ���Ƶİ�ο������ֵ�������������������Ե��������е�ʱ��������
������ͨ��ʹ�������������Ʊ������ǿ���ʹ��cluster����ѡ����Ҫ��Stata���ض�������ʹ�ÿ���������block bootstrap��������ֱ����cluster������ʹ�ý���������������лع�֮ǰʹ��group�����������ɽ����
discount��#��ѡ���������Ƕ�����к��ڹ��ƵĴ���ЧӦ�����ۿۡ�
������Ĭ����ÿ���ع�֮������ͼ�Ρ�ͨ��graphoptions����ѡ����ǿ�����ͼ�ε���ۡ�
����λ����Ϊ���ǵ���������д��һ����Ϣ�ḻ���ĵ�������һ�����ij��������֣��������������������help did_multiplegt���鿴�ĵ���
���ڲ岹��˫�ز�ֹ���ֵ��Imputation Estimator for DID��
Borusyak��Jaravel��Spiess��2023�������һ��ʹ�ò岹���̵�����������Ч�Ƚ�˫�ز�ֹ���ֵ���岹�����ܵ���ӭ��ԭ�������
���ڼ����ϸ�Ч��ֻ��Ҫ����һ����TWFEģ�ͣ���
�岹�����������ɵؽ�ƽ�����ƺ���Ԥ�ڼ��������ֵ��ϵ������
����һλ���ߣ�Kirill Borusyak���ش�ѧѧԺ������д��һ��Stata������did_imputation������ʵʩ���ǵIJ岹�������Թ��ƶ�̬����ЧӦ�������¼��о��е�ǰ�����Ƽ��顣��������£�
did_imputation Y id t Ei, fe��id t��horizons��#��pretrends��#��
���У�horizonsѡ�����Stata����ϣ�����ƶ��ٸ�ǰհ�ڵĴ���ЧӦ����pretrendsѡ�����StataҪ��ijЩʱ�ڽ���ǰ�����Ƽ��顣ǰ������ϵ������Ϊpre1��pre2�ȡ���ǰ���ᵽ�ķ�����ͬ�������ǰ������ϵ������������Ӱ�촦��ЧӦ���ƺ���������ƣ�����ʼ����ƽ�����ƺ���Ԥ�ڼ����¼��㣩��
���⣬Borusyak��Jaravel��Spiess��2022����һƪ��ɫ�����ģ�ָ���˾���˫�ز���г��������ġ���Ȩ�ء����⡣�������ij�������ΪOLS���ƶԴ���ЧӦ��ͬ����ʩ���˷dz�ǿ�����ơ������Ϊʲô��Щ��������ѧ�ҳƾ���Ķ�̬˫�ز��Ϊһ������Ⱦ�Ĺ���ֵ��
����...
DZ�ں�ѡ���ģ�Dube���ˣ�2023����
ʵ��
�ڱ����У��ҽ�չʾ�����ʵ֤������ʹ���������Ʒ������ر���ʹ��Stata�е��ض�����/��������
ʱ��̶�ЧӦ��TWFE����ϳ�˫�ز�֣�SDID��
������ҽ�ʹ��������ʵ��������ݼ���չʾ�������TWFE�ع顣������У��һ���չʾ����SDID�Ĵ��룬Ȼ����бȽϡ�
�ҽ�ʹ�õ�����������ƪ���ģ�
"OW05_prop99.dta"����Orzechowski��Walker��2005��������Դ������ȡ���°汾��Abadie���ˣ�2010����Arkhangelsky���ˣ�2021��ʹ����Щ�����������99����������˰���Լ������������˾����۵����̵�Ӱ�졣��ע�⣬����һ���ֿ����ߴ�����block treatment���İ�����
"BCGV22_gender_quota.dta"����Bhalotra���ˣ�2022��������ʹ����Щ��������������Ա����������Ϊ��Ů����ϯλ��������и�Ů������Ӱ�졣��ע�⣬����һ�����������İ�����
"SZ18_state_taxes.dta"����Serrato��Zidar��2018��������ʹ����Щ��������������ҵ˰�ռ�˰/��˰��˰�պ;��û��Ӱ�졣��ע�⣬����һ�����������İ�����Ȼ����Serrato��Zidar��2018��ʹ�ö�̬�����ģ�ͣ�����δ�����Ȩ�����⣩��������ǵĽ�����ܴ���ƫ����⣬��ע�⣬���ҵ���sdid���������ж�̬ģ�ͣ����������ʹ��SDID������Serrato��Zidar��2018���Ľ����
�ҽ�ʹ�õĻع����������
xtdidregress��Stata��������������������������˫�ز�ֻع顣ʹ�ô���������ǿ���ʹ��estat��������ͼ������һЩ�������顣
xtreg��areg��reghdfe����������й̶�ЧӦģ�ͣ���Ҳ��������Ӧ��������˫�ز�ֻع顣
sdid����������SDID���ⲿ���ͨ��method����ѡ����ǻ�����ʹ���������б�˫�ز�ֺͺϳɿ���ģ�͡�
xthdidregress����Stata 18�����һ�����ڹ���������ATT�������ע�⣬xthdidregress�����������ּ�Ȩ��ʽ����ѡ��ʹ��aipw����ǿ����ʼ�Ȩ��Ҳ��Ϊ��˫���Ƚ�����������Stata 18���ĵ�û����ȷ˵��������������λ������������Ҳ²���������˼��Դ��Callaway��Sant'Anna��2021������ע�⣬�ع��estat aggregation����������ͬһ���ʱ���ڻ���ATT������ָ��ʱ�䴰���ڵĶ�̬ЧӦ��������ͼ����
�ڴ˴������ҵ������������ݼ������лع���������롣
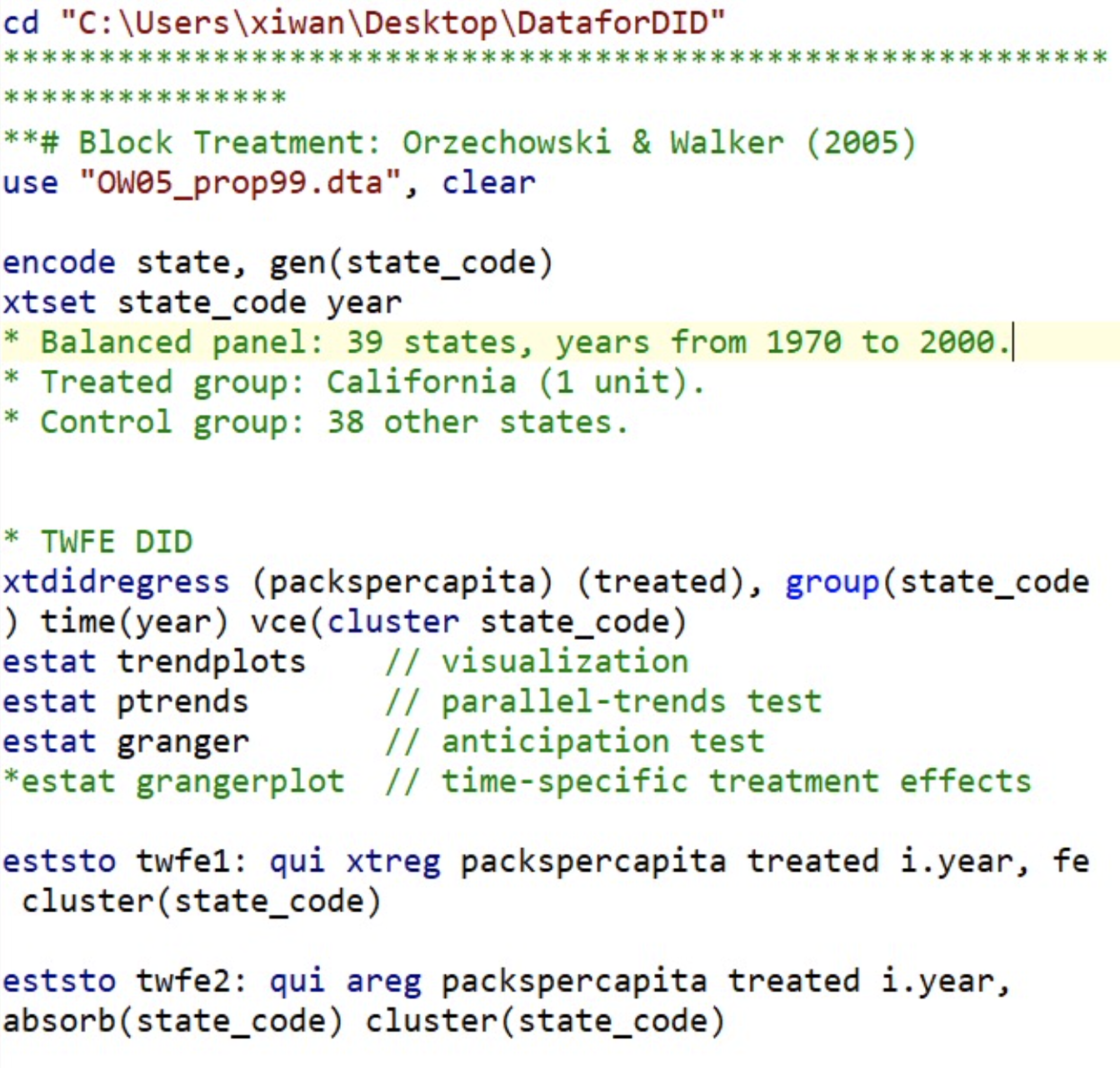
������Щ���뾭�����ԣ�����ֱ����Stata���У����ݸ����ĺ������������Ĵ���1����
cd "C:\Users\xiwan\Desktop\DataforDID"
**# Block Treatment��Orzechowski & Walker��2005��
use "OW05_prop99.dta", clear
encode state, gen��state_code��
xtset state_code year
* TWFE DID
xtdidregress��packspercapita����treated��, group��state_code��time��year��vce��cluster state_code��
estat trendplots // visualization
estat ptrends // parallel-trends test
estat granger // anticipation test
*estat grangerplot // time-specific treatment effects
eststo twfe1��qui xtreg packspercapita treated i.year, fe cluster��state_code��
eststo twfe2��qui areg packspercapita treated i.year, absorb��state_code��cluster��state_code��
eststo twfe3��qui reghdfe packspercapita treated, absorb��state_code year��cluster��state_code��
estout twfe*, keep��treated��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adjusted R2"��fmt��"%9.0fc"3����
* Sythetic DID
eststo syn_did��sdid packspercapita state year treated, vce��placebo��seed��1��///
graph g1on ///
g1_opt��xtitle��""��///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��///
g2_opt��ylabel��0��25��150��ytitle��"Packs per capita"��///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��///
graph_export��"prop99_did_", .pdf��
ereturn list
matrix list e��omega��// unit-specific weights
matrix list e��lambda��// time-specific weights
estout twfe* syn_did, keep��treated��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adjusted R2"��fmt��"%9.0fc"3����
* Compare SDID, DID, and SC
foreach m in sdid did sc {
if "`m'"=="did" {
local g_opt = "msize��small��"
}
else {
local g_opt = ""
}
sdid packspercapita state year treated, ///
method��`m'��vce��noinference��graph g1on `g_opt' ///
g1_opt��xtitle��""��ytitle��""��///
xlabel��, labsize��tiny����///
ylabel��-100��25��50, labsize��small����///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��///
g2_opt��title��"`m'"��xtitle��""��ytitle��""��///
xlabel��, labsize��small����///
ylabel��0��25��150, labsize��small����///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��
graph save g1_1989 "`m'_1.gph", replace
graph save g2_1989 "`m'_2.gph", replace
}
graph combine "sdid_2.gph" "did_2.gph" "$figdir\sc_2.gph" "sdid_1.gph" "did_1.gph" "sc_1.gph", ///
cols��3��xsize��3.5��ysize��2��///
graphregion��fcolor��white��lcolor��white����
graph export "compare_sdid_did_sc.pdf", replace
*****************************************************
**# Staggered Treatment��Bhalotra et al.��2022��
use "BCGV22_gender_quota.dta", clear
drop if lngdp==.
tab year
isid country year
* Balanced panel��115 countries, years from 1990 to 2015.
* Treated group��9 countries.
* Control group��106 other states.
eststo stagg1��sdid womparl country year quota, vce��bootstrap��seed��3��///
graph g1on ///
g1_opt��xtitle��""��ytitle��""��xlabel��, labsize��tiny����///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��///
g2_opt��ytitle��""��///
plotregion��fcolor��white��lcolor��white����///
graphregion��fcolor��white��lcolor��white����///
��
ereturn list
matrix list e��tau��// adoption-period specific estimate
matrix list e��lambda��
matrix list e��omega��
matrix list e��adoption��// different adoption years
eststo stagg2��sdid womparl country year quota, covariates��lngdp, optimized��vce��bootstrap��seed��3��
eststo stagg3��sdid womparl country year quota, covariates��lngdp, projected��vce��bootstrap��seed��3��
estout stagg*, ///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N, nostar labels��"Observations"��fmt��"%9.0fc"����
******************************************************************
**# Staggered Treatment��Serrato & Zidar��2018��
use "SZ18_state_taxes.dta", replace
keep if year >= 1980 & year <= 2010
drop if fips_state == 11 | fips_state == 0 | fips_state > 56
xtset fips_state year
* Balanced panel��50 states, years from 1980 to 2010.
* Treated group��15 states.
* Control group��35 other states.
* Construct dependent variables
gen log_rev_corptax = 100*ln��rev_corptax+1��
gen log_gdp = 100*ln��GDP��
g r_g = 100*rev_corptax/GDP
* Screen out the tax change with a pre-determined threshold
local threshold = 0.5
gen ch_corporate_rate = corporate_rate - L1.corporate_rate
replace ch_corporate_rate = 0 if abs��ch_corporate_rate��<= `threshold'
gen ch_corporate_rate_inc =��ch_corporate_rate > 0 & !missing��ch_corporate_rate����
gen ch_corporate_rate_dec =��ch_corporate_rate < 0 & !missing��ch_corporate_rate����
* Contruct treatment dummies
** Static
gen change_year = year if ch_corporate_rate_dec==1
bysort fips_state��egen tchange_year = min��change_year��
gen treated =��year >= tchange_year��
** Dynamic
gen period = year - tchange_year
gen Dn5 =��period < -4��
forvalues i = 4��-1��1 {
gen Dn`i' =��period == -`i'��
}
forvalues i = 0��1��5 {
gen D`i' =��period == `i'��
}
gen D6 =��period >= 6 & period != .��
* Static DID
local ylist = "log_rev_corptax log_gdp r_g"
local i = 1
foreach yvar in `ylist' {
quietly{
eststo areg`i'��areg `yvar' treated i.fips_state, absorb��year��cluster��fips_state��
eststo hdreg`i'��reghdfe `yvar' treated, absorb��fips_state year��cluster��fips_state��
eststo sdid`i'��sdid `yvar' fips_state year treated, vce��bootstrap��seed��2018��
local ++i
}
}
estout areg1 hdreg1 sdid1 areg2 hdreg2 sdid2 areg3 hdreg3 sdid3, keep��treated��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adj. R2"��fmt��"%9.0fc" 3����
* Dynamic DID��sdid cannot do this��
local ylist = "log_rev_corptax log_gdp r_g"
local i = 1
foreach yvar in `ylist' {
quietly{
eststo areg`i'��areg `yvar' Dn5-Dn2 D0-D6 i.fips_state, absorb��year��cluster��fips_state��
eststo hdreg`i'��reghdfe `yvar' Dn5-Dn2 D0-D6, absorb��fips_state year��cluster��fips_state��
local ++i
}
}
estout areg1 hdreg1 areg2 hdreg2 areg3 hdreg3, keep��D*��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adj. R2"��fmt��"%9.0fc" 3����
**# Stata 18 new command��xthdidregress
local controls = "FederalIncomeasStateTaxBase sales_wgt throwback FedIncomeTaxDeductible Losscarryforward FranchiseTax"
local ps_var = "FederalIncomeasStateTaxBase sales_wgt throwback FedIncomeTaxDeductible FranchiseTax"
xthdidregress aipw��log_gdp `controls'����treated `ps_var'��, group��fips_state��vce��cluster fips_state��
* Visualizing ATT for each cohort
estat atetplot
graph export "SZ18_cohort_ATT.pdf", replace
* Visualizing ATT over cohort
estat aggregation, cohort ///
graph��xlab��, angle��45��labsize��small����legend��rows��1��position��6������
graph export "SZ18_cohort_agg_ATT.pdf", replace
* Visualizing ATT over time
estat aggregation, time ///
graph��xlab��, angle��45��labsize��small����legend��rows��1��position��6������
graph export "SZ18_time_agg_ATT.pdf", replace
* Visualizing dynamic effects
estat aggregation, dynamic��-5/6��///
graph�� ///
title��"Dynamic Effects on Log State GDP", size��medlarge����///
xlab��, labsize��small��nogrid��///
legend��rows��1��position��6����///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
��
graph export "SZ18_dynamic_ATT.pdf", replace
Bacon�ֽ⡢�¼��о�ͼ�Ͱ�ο������
����ͨ���������´��뽫Ҫʹ�õ����ݼ����ص�Stata�У�
use "http://pped.org/bacon_example.dta", clear
������ݰ���1964����1996������49���ݣ�������ʢ��������������������˹�Ӻ������ģ����ݼ���Ϣ���ر���������鿪ʼ��ݺ���ɱ�����ʣ�����Щ���������Stevenson��Wolfers��2006�����ڹ������������棩����Ů����ɱ�ʵ�Ӱ�졣
���������һ���������ĸһ�ַ�ɢ��������Ů����ɱ���о�̬��˫�ز�ֹ��ƣ�
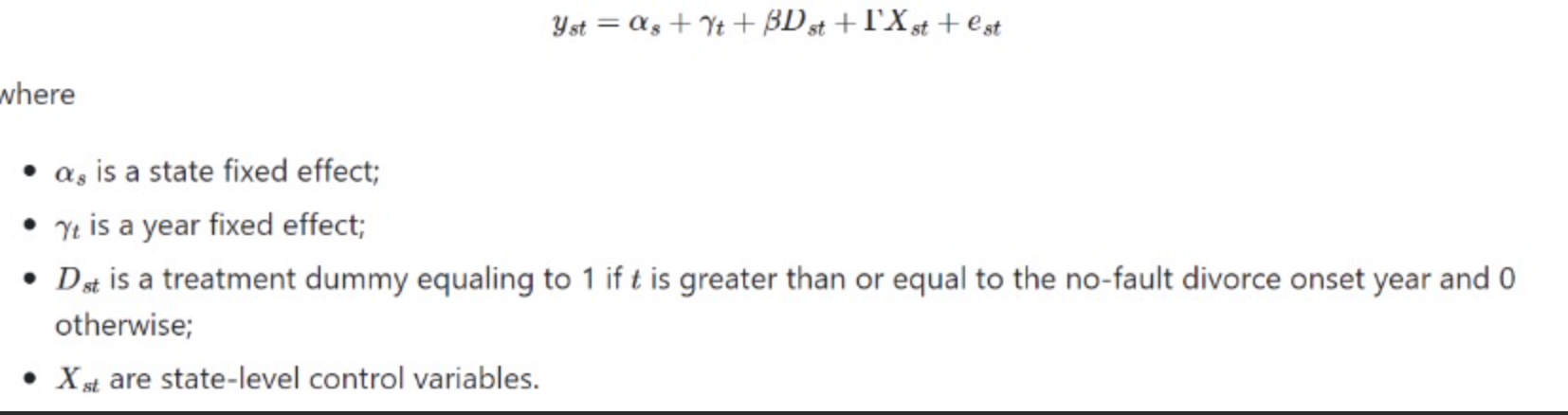
������������õ�������鷨���ݣ�����������������ݡ�
������������Ĺ���ϵ��Ӧ��ͬ�������ڲ�ͬ���㷨��������Rƽ����ͬ����
xtdidregress��asmrs pcinc asmrh cases����post��, group��stfips��time��year��vce��cluster stfips��
xtreg asmrs post pcinc asmrh cases i.year, fe vce��cluster stfips��
areg asmrs post pcinc asmrh cases i.year, absorb��stfips��vce��cluster stfips��
reghdfe asmrs post pcinc asmrh cases, absorb��stfips year��cluster��stfips��
���У�asmrs����ɱ�����ʣ�post�����ߴ�����������������������ǿ��Ʊ�����Stata�����˫�ز��ϵ��Ϊ-2.516�������Ϊ2.283�����������������졣
Ȼ�����ǿ��Զ�TWFE DIDģ��Ӧ��Bacon�ֽⶨ����
bacondecomp asmrs post pcinc asmrh cases, ddetail
�������Bacon�ֽ���Ϊ�°汾bacondecomp�ó��ġ����У�Timing-groups��ʾ��ͬ���ߴ���ʱ������IJ��죬��ռ������ЧӦ�� 37.76%����Ӧ���Ǿɰ汾bacondecomp�е�Earlier T vs. Later C ��Later T vs. Earlier C�����ֵ�Ȩ�أ�Always_v_timing��Ȩ��Ϊ37.8%����Ӧ���Ǿɰ汾bacondecomp�е�T vs. Already treated�����´��������Ѵ�����ĶԱȲ��졣Never_v_timing��Ȩ��Ϊ23.9%����Ӧ���Ǿɰ汾bacondecomp�е�T vs. Never treated�����������Ӧ�Ŵ�δ���ܴ������Ķ�����IJ��졣��ͬ���ڵIJ���ռ��Ϊ 0.509%��ʼ�մ������δ���ܴ������ЧӦ��ռ 0.0018%��
Ҫ��ƫ���Ҫ�ǿ�T vs. Already treated���°汾�е�Always_v_timing��Ȩ�ء�
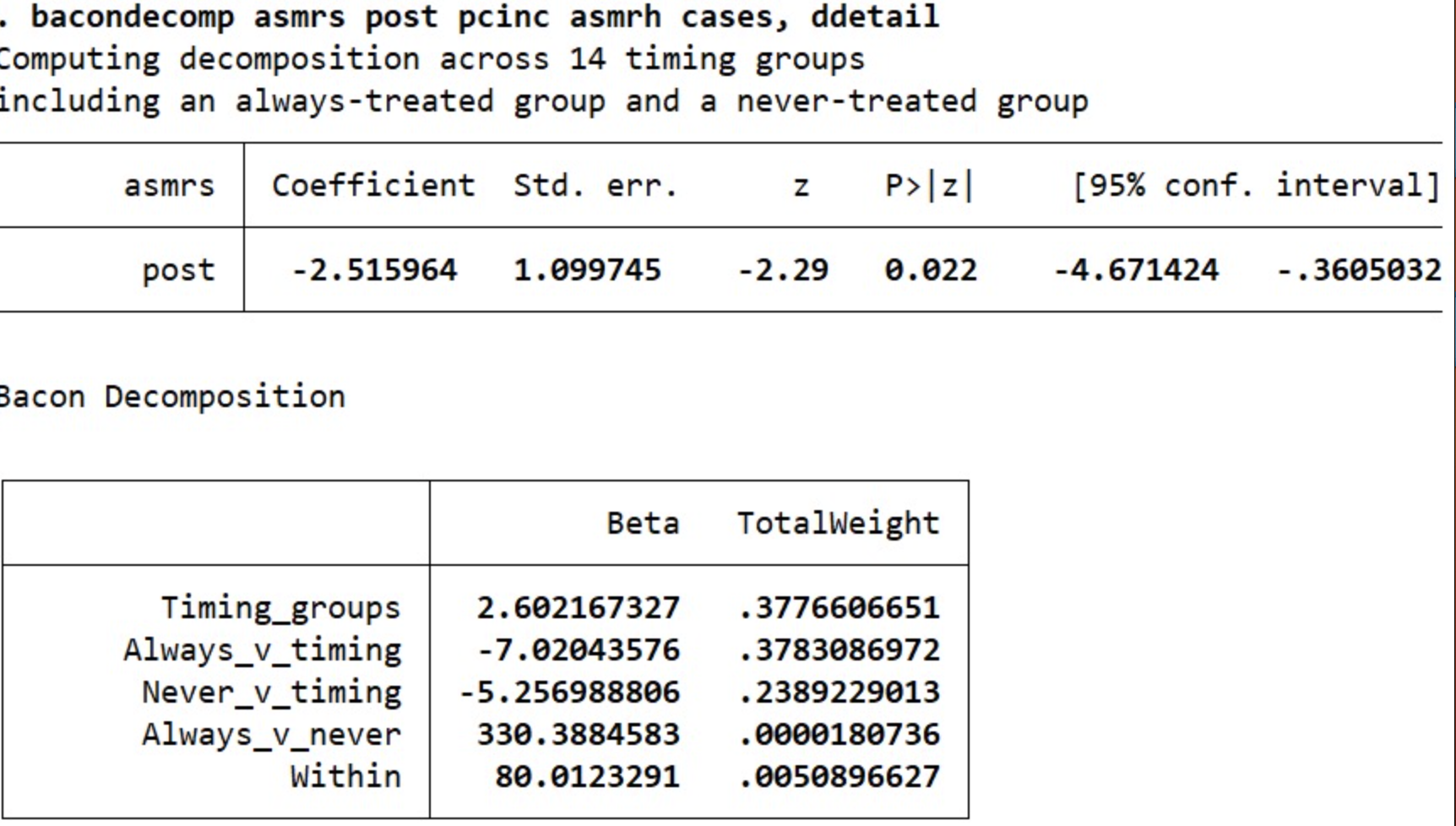
���������ݼ�����14��ʱ���飨�ڲ�ͬʱ����ܴ���������Ϊ�˴˵Ķ����飩������һ����δ���������һ��ʼ�մ������顣����Ȩ�ط����ʼ�մ������ʱ����֮��ıȽϡ�
���ǻ�����ʹ�����±��루��xtdidregress֮���зֽ⡣ɢ��ͼ�����������ҵ���
estat bdecomp, graph
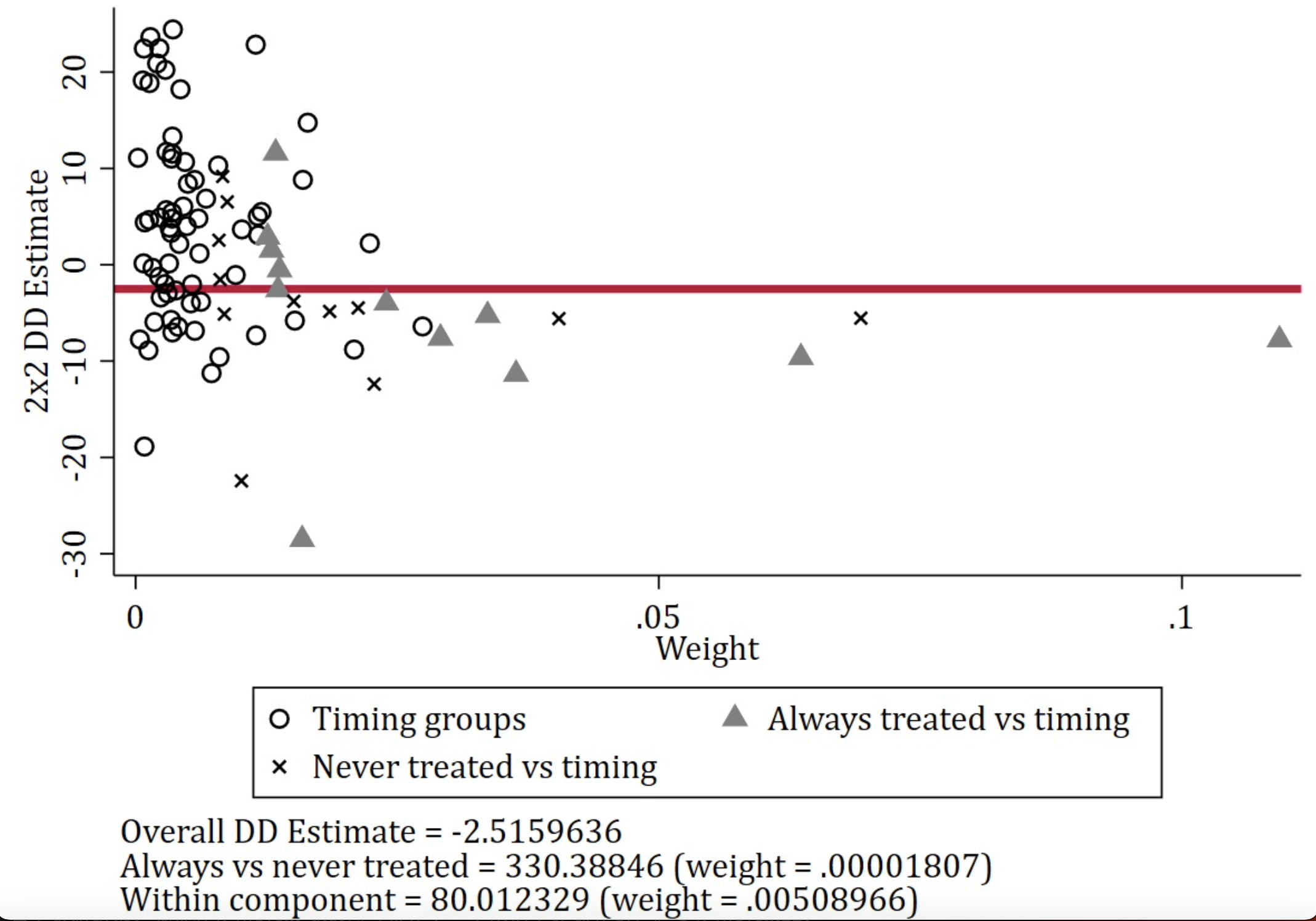
���ס��Bacon�ֽ���Ϊһ����Ϲ��ߣ�������һ�������������ֽ��������DIDģ���С����õ����ıȽϡ������س̶ȣ��������ܽ�������⡣
���������ҽ��е�����Ӧ�Ķ�̬DID�ع顣��ʹ��eventdd�����Ϊ������ͬʱ����ģ�Ͳ�����ͼ������������������һЩ�����Ļع飨����xtreg��reghdfe�������ڴӸ�DID�ع��л��ƽ�������Ƽ�ʹ��event_plot����������һ��ʾ������ϸ���ܣ���Ҫʹ��eventdd�����밲װ��������������eventdd��matsort��
�����ͨ�����ѡ��ο������ʱ�䲢�ظ�����1000��TWFE�ع�������ʱ�䰲ο�����顣�������ʹ��Stata��������permute��ɵġ���������ʾ���������Ĺ��ƿ��ܲ���������һ�����ɹ۲��ʱ�����ơ���ο�������ͼ�����ɸ�������dpplot�����������������ҵ���
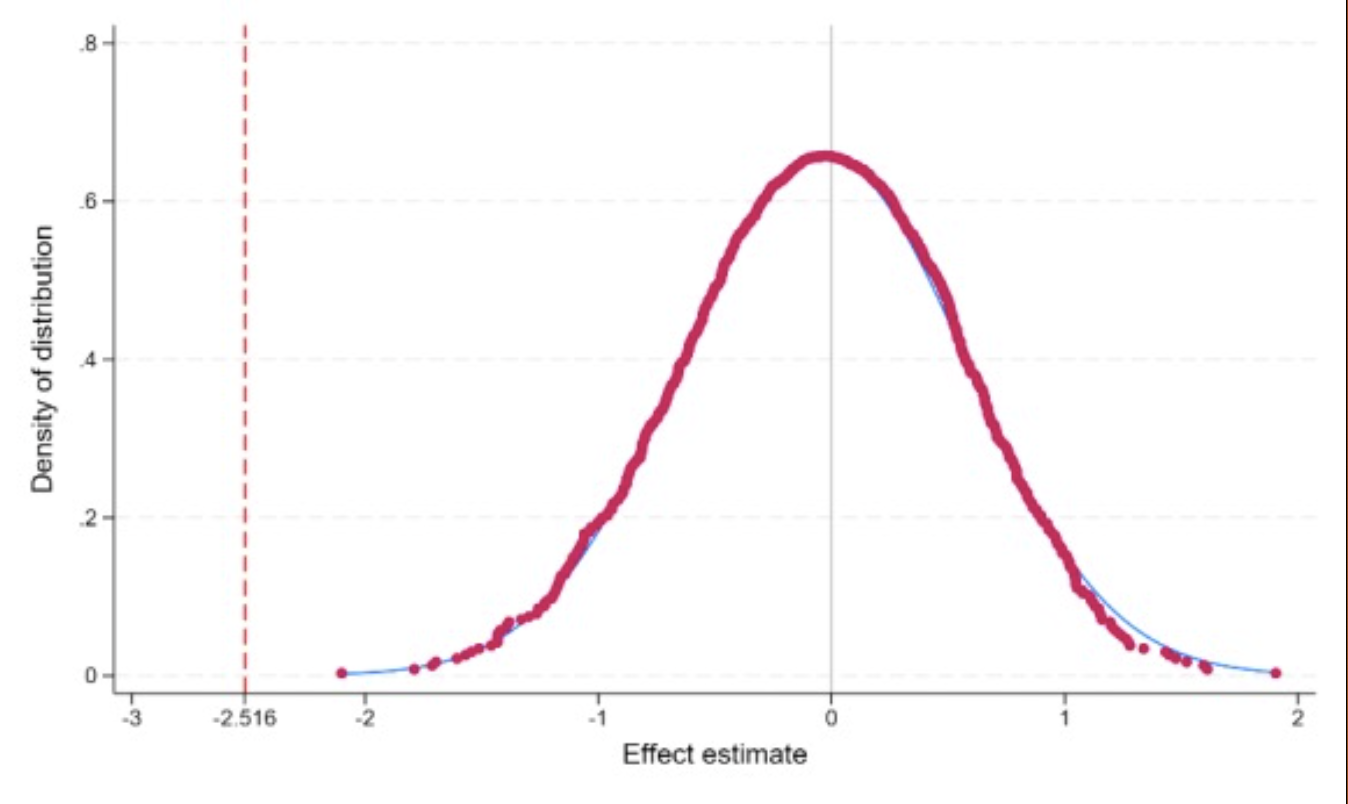
�����ı�������������ҵ���
������Щ���뾭�����ԣ�����ֱ����Stata���У�������Ĵ���2����
*** Bacon Decomposition *************************
use "http://pped.org/bacon_example.dta", clear
* We see multiple treatment years.
tab year
tab _nfd // the year of the passage of no-fault divorce law
* Regression of female suicide on no-fault divorce reforms
eststo reg1��quietly reghdfe asmrs post pcinc asmrh cases, absorb��stfips year��cluster��stfips��
estout reg1, keep��post pcinc asmrh cases _cons��///
varlabels��_cons "Constant"��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��///
stats��N r2_a, nostar labels��"Observations" "R-Square"��fmt��"%9.0fc" 3����
bacondecomp asmrs post pcinc asmrh cases, ddetail
graph export "DID_Decomposition_bacondecomp.pdf", replace
xtdidregress��asmrs pcinc asmrh cases����post��, group��stfips��time��year��vce��cluster stfips��
estat bdecomp, graph
graph export "DID_Decomposition_estat.pdf", replace
*** Event Study Plots *****************************************************
gen rel_time = year - _nfd
* The following uses "xtreg".
eventdd asmrs pcinc asmrh cases i.year, ///
timevar��rel_time��method��fe, cluster��stfips����///
noline graph_op�� ///
xlabel��-20��5��25, nogrid��///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
legend��order��1 "Point Estimate" 2 "95% CI"��size��*0.8��position��6��rows��1��region��lc��black������///
��
* The following uses "reghdfe".
eventdd asmrs pcinc asmrh cases, ///
timevar��rel_time��method��hdfe, cluster��stfips��absorb��stfips year����///
noline graph_op�� ///
xlabel��-20��5��25, nogrid��///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
legend��order��1 "Point Estimate" 2 "95% CI"��size��*0.8��position��6��rows��1��region��lc��black������///
��
* Only balanced periods in which all units have data are shown in the plot.
eventdd asmrs pcinc asmrh cases i.year, ///
timevar��rel_time��method��hdfe, cluster��stfips��absorb��stfips year����balanced ///
noline graph_op�� ///
xlabel��, nogrid��///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
legend��order��1 "Point Estimate" 2 "95% CI"��size��*0.8��position��6��rows��1��region��lc��black������///
��
* Only specified periods are shown in the plot; periods beyond the window are accumulated.
eventdd asmrs pcinc asmrh cases i.year, ///
timevar��rel_time��method��hdfe, cluster��stfips��absorb��stfips year����///
accum leads��5��lags��10��///
noline graph_op�� ///
xlabel��, nogrid��///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
legend��order��1 "Point Estimate" 2 "95% CI"��size��*0.8��position��6��rows��1��region��lc��black������///
��
*** Placebo Test *****************************************
* Randomly select a placebo treatment time and run TWFE regression for 1000 times
permute post coefficient=_b[post], reps��1000��seed��1��saving��"placebo_test.dta", replace����reghdfe asmrs post pcinc asmrh cases, absorb��stfips year��cluster��stfips��
use "placebo_test.dta", clear
dpplot coefficient, ///
xline��-2.516, lc��red��lp��dash����xline��0, lc��gs12��lp��solid����///
xtitle��"Effect estimate"��ytitle��"Density of distribution"��///
xlabel��-3��1��2 -2.516, nogrid labsize��small����///
ylabel��, labsize��small����caption��""��
graph export "placebo_test_plot.pdf", replace
���������Ķ�̬ DID
���һ�ҹ�˾�Ե������ڹ����г���ͨ�����۵ļ۸���ڲ�Ʒ�����dzƸù�˾��������Ʒ�����ֲ���ƽ�����������Ϊ���ܶԽ����г�����ҵ�;��ò���������Ť�����á����ǵ����ֲ���Ӱ�죬WTO������Э������������ȡһЩ�������ж���Ӧ�������������Ϊ������͵ķ������ж��Ƕ��ض���Ʒ���ض����ڹ����սϸߵĽ��ڹ�˰��ϣ��������ƽ�ĵͼ���ߵ������۸Ӷ�����Խ��ڹ�����
������ҽ�ʹ�ö�̬DIDģ���������������й�������ʵʩ�ķ�������˰��2000�굽2009��Ķ�̬ЧӦ��Bown��Crowley��2007��������ЧӦΪ��ó���ƻ�������ͨ��ʹ���������ձ�����������IV��FE��GMMģ�������ƾ�̬����ЧӦ���йظ����ĵ��������������������ҵ���
�ҽ�ʹ��һ������Ʒ-�ꡱ��������ݼ��������ݼ��Ǵ�ȫ���������ݿ���й��������ݺϲ���������л�廪��ѧ�й��������ģ����ҽ����еĶ�̬DIDģ�����£�

��������˵�������������ڡ���Ʒ-�ꡱ�IJ�����о��ࡣ
�������������й�����Щ�ܵ�������������˰�IJ�Ʒ�����������������й�����Щ�����˷��������鵫����δ�ܵ���������˰�IJ�Ʒ����ע�⣬��û�н���Щ��δ���ܵ���IJ�Ʒ��������顣ԭ���Ƿ����������Ƿ�����ģ��ܵ���IJ�Ʒ�ij��ڼ۸�ʼ�յ���û�н��ܵ���IJ�Ʒ������ҽ��ܵ���������˰�IJ�Ʒ��δ������IJ�Ʒ���бȽϣ���ô�ҵĹ��ƺܿ��ܴ���ƫ��
���ڶ��ض���Ʒ����6λ�������Ͻ��б��룩ʵʩ��������˰����ݵ���Ϣ�洢�ڱ���year_des_duty�С���ʹ��������������������һϵ�����ʱ�����������
gen period_duty = year - year_des_duty
gen Dn3 =��period_duty < -2��
forvalues i = 2��-1��1 {
gen Dn`i' =��period_duty == -`i'��
}
forvalues i = 0��1��3 {
gen D`i' =��period_duty == `i'��
}
gen D4 =��period_duty >= 4��&��period_duty != .��
��ͳ�ϣ��о���Աʹ�����ߴ���ǰ��ϵ��������Ԥ���ƣ�pre-trends�����������ǰ��ϵ����0û���������죬��ô���ǻ�ó�ƽ�����Ƽ�������Ľ��ۡ�Ȼ����Sun��Abraham��2021��֤��������������������ȱ�ݣ�����Ҫ����������
ʹ��˫�ز�ֵĽ�����Ȩ���Ƶģ�interaction-weighted estimation of DID���������£�
gen first_union = year_des_duty
gen never_union =��first_union == .��
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
eventstudyinteract ln_`y' Dn3 Dn2 D0-D4, \\\
cohort��first_union��control_cohort��never_union��\\\
absorb��product year��vce��cluster product#year��
}
������Ҫ����Stataÿ������ij�ʼ����ʱ���Ӧ�ı������ĸ�����������Ϊfirst_union�����ڴ�δ�������ߴ����ĸ��壬�ñ���Ӧ����Ϊȱʧ�����⣬���ǻ���Ҫ�ṩһ�������������Ӧ�ڶ����飬�����Ǵ�δ���ܴ����ĸ���������ܴ����ĸ��塣������ҽ���δ���ܴ����ĸ�����Ϊ�����飬������һ����Ϊnever_union�ı�������ʾ����
ֵ��ע����ǣ�Kirill Borusyak��д��һ����Ϊevent_plot�İ������ڷ���ػ���˫�ز�ֹ��ƽ������������ϵ���ͣ�����еĻ���Ԥ����ϵ�����Լ��������䡣��ʹ����������������ͼ������չʾ���ĸ���������Ķ�̬ЧӦ�����ڻ�ͼ����ͨ�����Զ����ͼ���ͣ���ʵ���ϣ������Կ��ӻ���Ҫ��������ô�ߣ����Խ�ʡ�ܶ�ʱ�䣬ʹ��Ĭ�����ͣ�ʹ��default_lookѡ���
˫���Ƚ����ƣ�doubly robust estimation of DID���ı������£�
gen gvar = year_des_duty
recode gvar��. = 0��
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
quietly csdid ln_`y', ivar��product��time��year��gvar��gvar��\\\
method��dripw��wboot��reps��10000����rseed��1��
csdid_estat event, window��-3 4��estore��cs_`y'��wboot��reps��10000����rseed��1��
}
cs_did������Stata��������п�����ʾһ���dz�������������������csdid֮ǰ������quietly������⣬������Ӧ���У��Ҹ����IJ�ͬʱ���������Դ���ЧӦ�������ǿ粻ͬ���ЧӦ����������Callaway��Sant'Anna, 2021�������-ʱ��ƽ������ЧӦ������ˣ���ʹ��csdid_estat����-3��4�ڼ�������ܹ��ƽ�������ڽ�������е��������϶̡���ֵ��ע����ǣ���ʹ��wbootѡ��������Wild Bootstrap�����ظ�10,000�Ρ�
��֮ǰһ������ʹ��event_plot�����������ͼ��չʾ��̬ЧӦ����Σ���ʹ��default_lookѡ���ʡʱ�䣻���⣬��ʹ��togetherѡ�ǰ���ͺ�����ʾΪһ�����������ߡ�
de Chaisemartin��D'Haultfoeuille��DID���Ƶı������£�
egen clst = group��product year��
local ylist = "value quantity m_quantity company_num"
foreach y in `ylist'{
did_multiplegt ln_`y' year_des_duty year treated, ///
robust_dynamic dynamic��4��placebo��2��jointtestplacebo ///
seed��1��breps��100��cluster��clst��
}
����ʹ��de Chaisemartin��D'Haultfoeuille��2022���Ĺ��Ʒ�������Ϊ������ƶ�̬ЧӦ��ֵ��ע����ǣ���ʹ�ó���ְ�ο�����а�ο�����飻��̬ЧӦ��ʹ�ó���ֵ�˫�ز�ֹ���ֵ�����Ƶģ����ʹ�ó���ְ�ο������ȷ�����֮�£�һ�ײ�ְ�ο������ֵ������ʱ���֮���˫�ز�֣��������������firstdiff_placebo������˵����̬����ЧӦ��ͼ�ν���������ģ������ɱȽϵģ���
������ۿ����������ҵ���https://www.statalist.org/forums/forum/general-stata-discussion/general/1599964-graph-for-the-dynamic-treatment-effect-using-did_multiplegt-package����
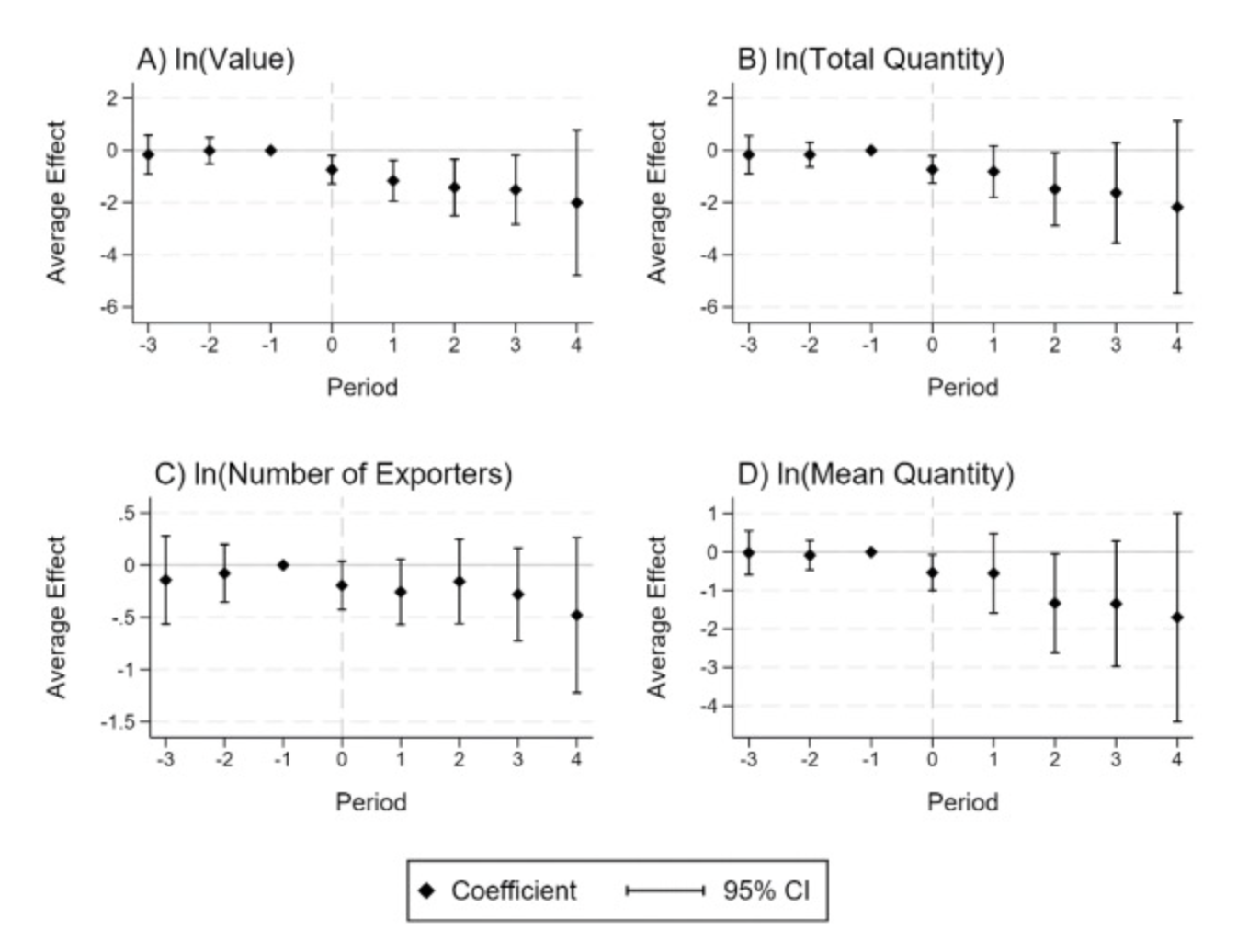
�Ҹ��˲�ϲ��did_multiplegt�Զ����ɵ�ͼ�Σ����Ҳ��ҵ��ǣ�graphoptions�� ��ѡ���������������ˣ���ѡ�ز������ƽ���洢�ھ����С�Ȼ����ʹ��event_plot�����ͼ�Ρ�����ͼ�εĹ���������Ӧ��Sun��Abraham��2021���Ĺ���ֵʱ�����ķdz����ơ��ҵ�����ͼ��չʾ���£�
imputation DID���Ƶı������£�
gen id = product
gen Ei = year_des_duty
local ylist = "value quantity company_num m_quantity"
foreach y in `ylist'{
did_imputation ln_`y' id year Ei, \\\
fe��product year��cluster��clst��horizons��0/4��pretrends��2��minn��0��autosample
}
������ҪΪ����Ĵ��������ṩһ������������ȱʧֵ��ʾ��δ���ܴ����ĸ��塣�Ұ��������ĵ���������ΪEi��
�����������ҵ�ʹ�ò岹�������ƵĶ�̬ЧӦ������ͼ�Σ��������¡���Σ���ʹ����default_lookѡ�����ʹ��togetherѡ�����ǰհ���ͺ�����ʾΪ�����ֱ��ò�ͬ��ɫ��ʾ�����ߡ�
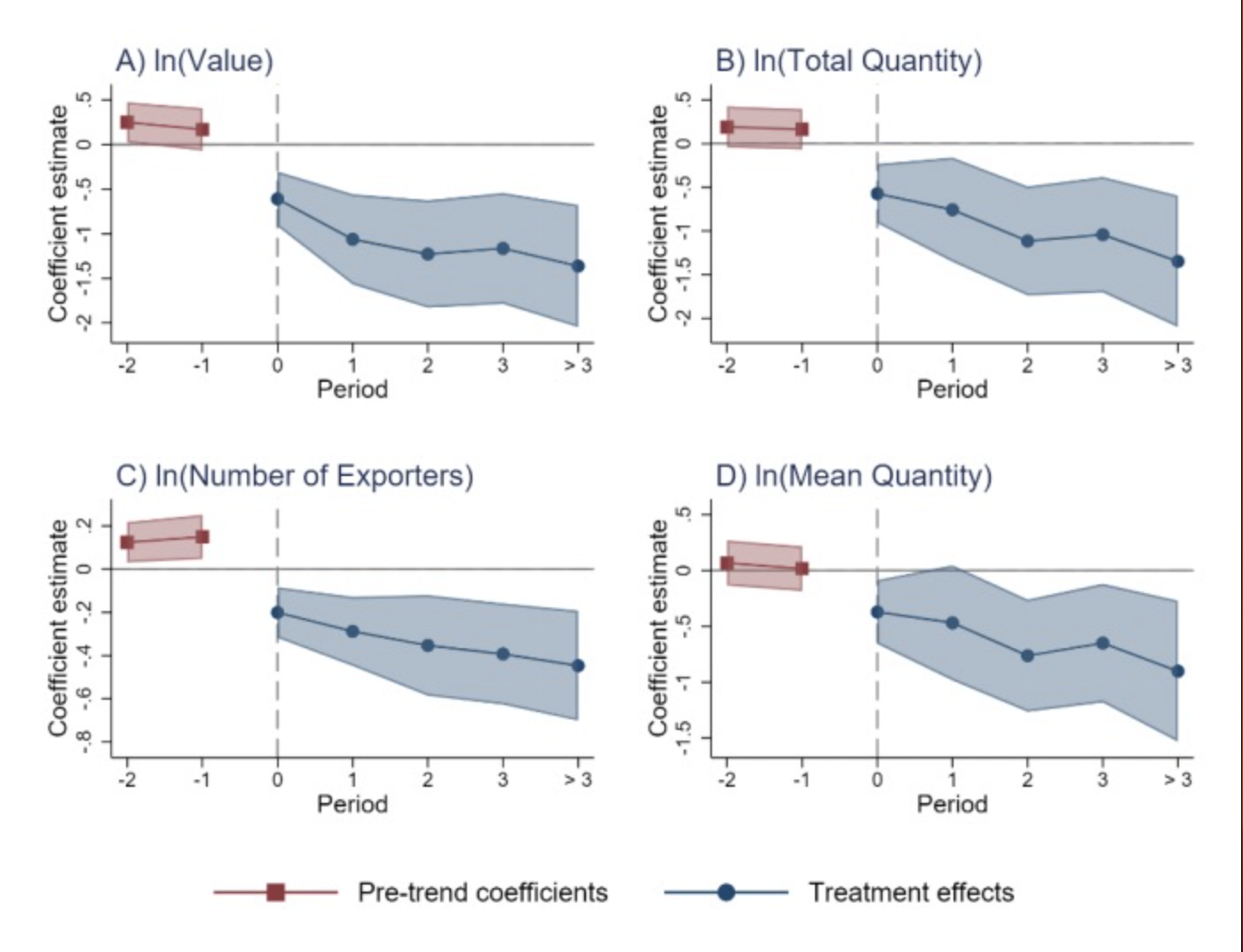
�ܽ�һ�£����۲������ֹ��Ʒ������������ʾ������������˰���ն��ĸ�������������˳����Ҹ����Ӱ�졣
������Щ���뾭�����ԣ�����ֱ����Stata���У�������Ĵ���3����
cd "C:\Users\xiwan\Desktop\DataforDID"
clear all
*************************************************
use "CCD_GAD_USA_affirm.dta", clear
**# Create a series of dummies for duty impositions
gen period_duty = year - year_des_duty
gen treated =��period_duty < . & period_duty >= 0��
gen Dn3 =��period_duty < -2��
forvalues i = 2��-1��1 {
gen Dn`i' =��period_duty == -`i'��
}
forvalues i = 0��1��3 {
gen D`i' =��period_duty == `i'��
}
gen D4 =��period_duty >= 4��&��period_duty != .��
**# Classical Dynamic DID
* install reghdfe ftools
encode hs06, generate��product��// string variables not allowed for xtset and regression
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
quietly{
eststo reg_`y'��reghdfe ln_`y' Dn3 Dn2 D0-D4, absorb��product year��vce��cluster product#year��
}
}
estout reg*, keep��D*��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adjusted R-Square"��fmt��"%9.0fc" 3����
******************************************************
**# Sun and Abraham��2021��
* install eventstudyinteract avar
gen first_union = year_des_duty
gen never_union =��first_union == .��
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
* Regression
eventstudyinteract ln_`y' Dn3 Dn2 D0-D4, cohort��first_union��control_cohort��never_union��absorb��product year��vce��cluster product#year��
* Visualization
if "`y'"=="value"{
local panel = "A��"
local title = "ln��Value��"
}
if "`y'"=="quantity"{
local panel = "B��"
local title = "ln��Total Quantity��"
}
if "`y'"=="company_num"{
local panel = "C��"
local title = "ln��Number of Exporters��"
}
if "`y'"=="m_quantity"{
local panel = "D��"
local title = "ln��Mean Quantity��"
}
forvalue i=1/7 {
local m_`i' = e��b_iw��[1,`i']
local v_`i' = e��V_iw��[`i',`i']
}
matrix input matb_sa=��`m_1',`m_2',0,`m_3',`m_4',`m_5',`m_6',`m_7'��
mat colnames matb_sa= ld3 ld2 ld1 lg0 lg1 lg2 lg3 lg4
matrix input mats_sa=��`v_1',`v_2',0,`v_3',`v_4',`v_5',`v_6',`v_7'��
mat colnames mats_sa= ld3 ld2 ld1 lg0 lg1 lg2 lg3 lg4
event_plot matb_sa#mats_sa, ///
stub_lag��lg#��stub_lead��ld#��///
ciplottype��rcap��plottype��scatter��///
lag_opt��msymbol��D��mcolor��black��msize��small����///
lead_opt��msymbol��D��mcolor��black��msize��small����///
lag_ci_opt��lcolor��black��lwidth��medthin����///
lead_ci_opt��lcolor��black��lwidth��medthin����///
graph_opt�� ///
title��"`panel' `title'", size��medlarge��position��11����///
xtitle��"Period", height��5����xsize��5��ysize��4��///
ytitle��"Coefficient", height��5����///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
yline��0, lpattern��solid��lcolor��gs12��lwidth��thin����///
xlabel��-3 "< -2" -2��1��3 4 "> 3", labsize��small����///
ylabel��, labsize��small����///
legend��order��1 "Coefficient" 2 "95% CI"��size��*0.8����///
name��sa_`y', replace��///
graphregion��color��white����///
��
}
* install grc1leg��net install grc1leg.pkg, replace
grc1leg sa_value sa_quantity sa_company_num sa_m_quantity, ///
legendfrom��sa_value��cols��2��///
graphregion��fcolor��white��lcolor��white����///
name��sa_fig, replace��
gr draw sa_fig, ysize��5��xsize��6.5��
graph export "SA_DID_Trade_Destruction.pdf", replace
***************************************************************
**# Callaway & Sant'Anna��2021��
* install csdid drdid
gen gvar = year_des_duty
recode gvar��. = 0��
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
quietly csdid ln_`y', ivar��product��time��year��gvar��gvar��method��dripw��wboot��reps��10000����rseed��1��
csdid_estat event, window��-3 4��estore��cs_`y'��wboot��reps��10000����rseed��1��
}
estout cs_*, keep��T*��///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adjusted R-Square"��fmt��"%9.0fc" 3����
* Visualization
local ylist = "value quantity company_num m_quantity"
foreach y in `ylist'{
if "`y'"=="value"{
local panel = "A��"
local title = "ln��Value��"
}
if "`y'"=="quantity"{
local panel = "B��"
local title = "ln��Total Quantity��"
}
if "`y'"=="company_num"{
local panel = "C��"
local title = "ln��Number of Exporters��"
}
if "`y'"=="m_quantity"{
local panel = "D��"
local title = "ln��Mean Quantity��"
}
event_plot cs_`y', default_look ///
stub_lag��Tp#��stub_lead��Tm#��together ///
graph_opt�� ///
xtitle��"Period"��ytitle��"ATT"��///
title��"`panel' `title'", size��medlarge��position��11����///
xlab��-3��1��4, labsize��small����///
ylab��, angle��90��nogrid labsize��small����///
legend��lab��1 "Coefficient"��lab��2 "95% CI"��size��*0.8����///
name��cs_`y', replace��///
��
}
grc1leg cs_value cs_quantity cs_company_num cs_m_quantity, ///
legendfrom��cs_value��cols��2��///
graphregion��fcolor��white��lcolor��white����///
name��cs_fig, replace��
gr draw cs_fig, ysize��5��xsize��6.5��
graph export "CS_DID_Trade_Destruction.pdf", replace
*********************************************************
**# de Chaisemartin & D'Haultfoeuille��2020, 2022��
* install did_multiplegt
egen clst = group��product year��
local dep = "value quantity company_num m_quantity"
foreach y in `dep'{
* Regression
did_multiplegt ln_`y' year_des_duty year treated, ///
robust_dynamic dynamic��4��placebo��2��jointtestplacebo ///
seed��1��breps��100��cluster��clst��
* Visualization
if "`y'"=="value"{
local panel = "A��"
local title = "ln��Value��"
}
if "`y'"=="quantity"{
local panel = "B��"
local title = "ln��Total Quantity��"
}
if "`y'"=="company_num"{
local panel = "C��"
local title = "ln��Number of Exporters��"
}
if "`y'"=="m_quantity"{
local panel = "D��"
local title = "ln��Mean Quantity��"
}
forvalue i=1/8 {
local m_`i' = e��estimates��[`i',1]
local v_`i' = e��variances��[`i',1]
}
matrix input matb_DIDl=��`m_1',`m_2',`m_3',`m_4',`m_5',0,`m_7',`m_8'��
mat colnames matb_DIDl= lg0 lg1 lg2 lg3 lg4 ld1 ld2 ld3
matrix input mats_DIDl=��`v_1',`v_2',`v_3',`v_4',`v_5',0,`v_7',`v_8'��
mat colnames mats_DIDl= lg0 lg1 lg2 lg3 lg4 ld1 ld2 ld3
event_plot matb_DIDl#mats_DIDl, ///
stub_lag��lg#��stub_lead��ld#��///
ciplottype��rcap��plottype��scatter��///
lag_opt��msymbol��D��mcolor��black��msize��small����///
lead_opt��msymbol��D��mcolor��black��msize��small����///
lag_ci_opt��lcolor��black��lwidth��medthin����///
lead_ci_opt��lcolor��black��lwidth��medthin����///
graph_opt�� ///
title��"`panel' `title'", size��medlarge��position��11����///
xtitle��"Period", height��5����xsize��5��ysize��4��///
ytitle��"Average Effect", height��5����///
xline��0, lpattern��dash��lcolor��gs12��lwidth��thin����///
yline��0, lpattern��solid��lcolor��gs12��lwidth��thin����///
xlabel��-3/4, nogrid labsize��small����///
ylabel��, labsize��small����///
legend��order��1 "Coefficient" 2 "95% CI"��size��*0.8��position��6��rows��1��region��lc��black������///
name��DIDl_`y', replace��///
graphregion��color��white����///
��
}
grc1leg DIDl_value DIDl_quantity DIDl_company_num DIDl_m_quantity, ///
legendfrom��DIDl_value��cols��2��///
graphregion��fcolor��white��lcolor��white����///
name��DIDl_fig, replace��
gr draw DIDl_fig, ysize��5��xsize��6.5��
graph export "CD_DIDl_Trade_Destruction.pdf", replace
*****************************************************
**# Borusyak, Jaravel & Spiess��2022��
* install did_imputation
gen id = product
gen Ei = year_des_duty
local ylist = "value quantity company_num m_quantity"
foreach y in `ylist'{
quietly{
eststo imp_`y'��did_imputation ln_`y' id year Ei, fe��product year��cluster��clst��horizons��0/4��pretrends��2��minn��0��autosample
}
}
estout imp*, ///
coll��none��cells��b��star fmt��3����se��par fmt��3������///
starlevels��* .1 ** .05 *** .01��legend ///
stats��N r2_a, nostar labels��"Observations" "Adjusted R-Square"��fmt��"%9.0fc" 3����
* Visualization
* install event_plot
local ylist = "value quantity company_num m_quantity"
foreach y in `ylist'{
if "`y'"=="value"{
local panel = "A��"
local title = "ln��Value��"
}
if "`y'"=="quantity"{
local panel = "B��"
local title = "ln��Total Quantity��"
}
if "`y'"=="company_num"{
local panel = "C��"
local title = "ln��Number of Exporters��"
}
if "`y'"=="m_quantity"{
local panel = "D��"
local title = "ln��Mean Quantity��"
}
event_plot imp_`y', default_look ///
graph_opt�� ///
xtitle��"Period"��ytitle��"Coefficient estimate"��///
title��"`panel' `title'", size��medlarge��position��11����///
xlab��-2��1��3 4 "> 3", labsize��small����///
ylab��, angle��90��nogrid labsize��small����///
yline��0, lcolor��gs8��lpattern��dash����///
legend��size��*0.8����///
name��imp_`y', replace��///
��
}
grc1leg imp_value imp_quantity imp_company_num imp_m_quantity, ///
legendfrom��imp_value��cols��2��///
graphregion��fcolor��white��lcolor��white����///
name��imp_fig, replace��
gr draw imp_fig, ysize��5��xsize��6.5��
graph export "Imputation_DID_Trade_Destruction.pdf", replace
��Stata�Ͼ�������������ֱ��ʹ�á�
���ݺʹ������ӣ�
https://pan.baidu.com/s/1uA5b2xxJ9gADU6kPtQZ9-A
��ȡ�룺qy2q
���ڽ��������DID���ο���1.120ƪDID˫�ز�ַ��������ºϼ�, ��������,�����, �����ղأ�2.��ʵ˫�ز�ַ�DID, ����¼��о�����Bacon�ֽ�ľ���Ӧ���ģ�3.ǰ�أ����ڻ���DID, ��ν���ƽ�����Ƽ����أ�4.����DID��DID��DID, ����Stataִ�������������¹����ѧϰ��5.DIDǰ�أ�5�ַ��������¼��о������ЧӦ, ��ʹ�û���ϵ������������, ��ϸ��������ݣ�6.�¼��о�����չ�������������ʶ��, ����8ƪ�ṩ���ݺʹ�������£�7.�Ƽ��ý��������ڣ�DID���¼��о�����չ�������������ļ���ʵ�����ݺʹ��룡8.����ѧϰ�Ѿ���������������, �����¼��о����������ʶ���������ЧӦ�ˣ�9.ǰ��, ģ��˫�ز�ַ�FDID�������ܺ�ʾ��, ��code�����ݣ�10.˫�ز�ַ����¼��о�����������Ҫ�����11.ǰ��, �ϳ�˫�ز�ַ�SDID�������ܺ�ʾ��, ��code�����ݣ�12.���пռ����ЧӦ��˫�ز�ַ�������ȫ����, ���ۺͲ������У�13.����Sun��Abraham��2021����TWFE���ƶ��ڻ�DID����ͼչʾ�������ϸ���code��

















