OpenAI认为,Sora意味着“扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。”简而言之,Sora接近于一个4D-DiT,建立在扩散模型(diffusion model)和变分自编码器(VAE)的基础上,结合了transformer和DDPM的技术。DiT是Google提出的图像识别模型架构,将VAE、ViT、DDPM和VAE解码器相结合,实现了在有限数据上训练高性能模型。VAE将图像编码为潜在表示,ViT用于提取图像特征,DDPM用于生成噪声图像,VAE解码器用于生成图像。
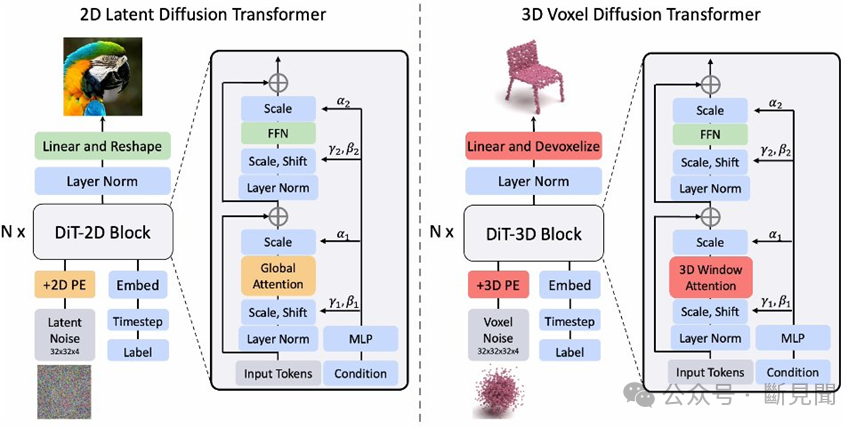
(来源:Mo et al., 2023)
一、核心创新
Sora的核心是对时空域中的图像patches的处理与学习。patches的思想源于Google深度学习团队的ViT算法,即将图像分割成众多类似于文本分析token的patch,然后用以训练transformer模型。但是,当应用到视频时,传统算法需要将原始图像切割成固定大小的patch,这限制了生成视频的质量和效果。
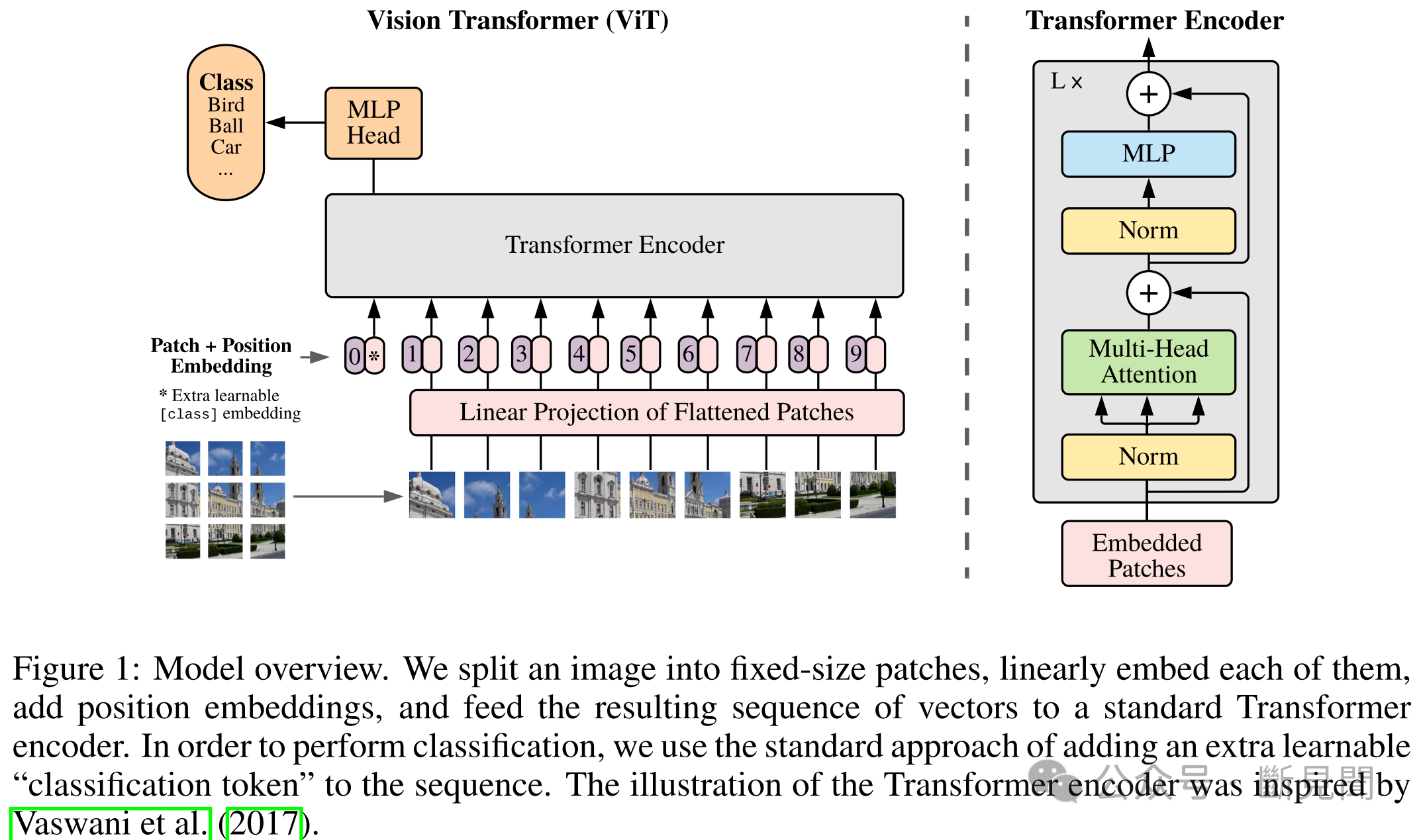
(来源:Dosovitskiy et al., 2020)
Sora通过降维生成时空patches保持了原始图像的纵横比和分辨率。这一改进对于捕捉视觉数据的真实本质至关重要,使得Sora能够在无需预处理步骤(如调整大小或填充)的情况下,高效处理各种各样的视觉数据,并确保每一份数据都对模型的理解有所贡献。(感觉有点像从看单根裸K线,到固定的K线组合,再到任何有信息的模式;或者像张三丰搞太极拳的路数)
此前的图像和视频生成算法通常会调整、裁剪或修剪以符合标准尺寸,如时长为4秒,分辨率为256x256。但是,Sora生成的视频分辨率可达1920x1080p(1080x1920p),时长可达60秒,构图也更加合理,内容逻辑性和连贯性也更好,并且可以直接将图片或视频作为prompt输入。因此,Sora实现了更少的数据量就能表达视频、图像等视觉信息,可以有更多的数据用于训练,得到的输出质量也会更高。
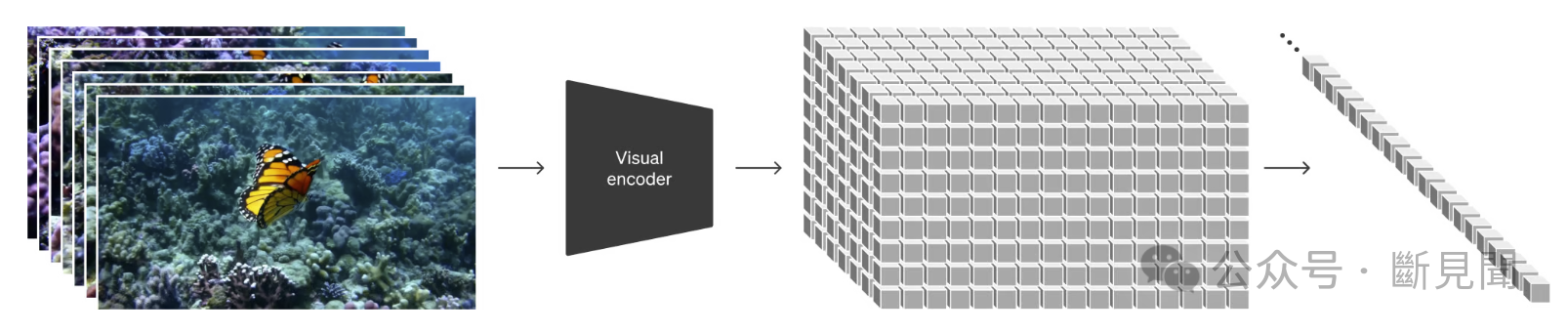
(来源:OpenAI)
Sora 的另一个重大突破是其所使用的架构。传统的文本到视频模型,如 Runway,是扩散模型,而文本模型像 GPT-4 则是 Transformer 模型。Sora用Transformer架构替换U-Net架构,大幅提升了模型扩展性。在此基础上能够生成非常长的视频。制作2秒视频和1分钟视频之间的区别是巨大的。在Sora中,这可能是通过允许可自回归采样的联合帧预测实现的。
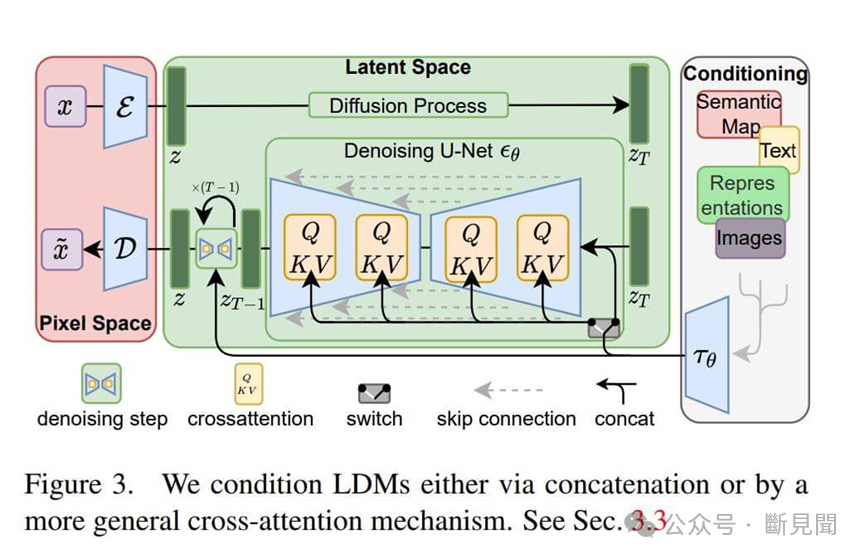
(来源:Rombach et al., 2021)
Sora还有一个重大突破是软物理模拟。Nvidia的研究科学家和人工智能代理专家Jim Fan认为,Sora的核心是一个物理引擎,是“对许多世界的真实或幻想的模拟”,并且模拟渲染了直观的物理,推理和基础。Sora 必须学习一些“隐式”形式的文本到3D、3D 转换、光线追踪渲染和物理规则,以便尽可能准确地对视频像素进行建模。GPT-4 需要在内部学习某种形式的语法、语义和数据结构,才能生成可执行的 Python代码。虽然Sora采用了世界模型,但OpenAI的Sora和Meta的Young的世界模型在架构理念上存在明显差异。Young的模型是基于数据驱动,即读取信息后去生成,而Sora模型是希望成为数据驱动与逻辑驱动相结合的世界模拟器。
二、主要影响
Sora对游戏、电影、短剧、广告等等涉及视频制作的行业都带来了革命性的影响。
长尾视频。长尾视频内容通常指的是那些规模较小、受众群体较少、主题较为冷门、制作难度较大的视频内容。Sora通过端到端的视频生成,为长尾视频内容提供了更多的供应来源,使得长尾视频的多样性得以实现,从而为长尾视频内容提供了更多的可能性。
游戏引擎。Sora可以生成与游戏引擎渲染相似的视频,但OpenAI完全没有讨论训练源和构建,这可能意味着数据是Sora成功的关键因素。它的训练数据也可能包括游戏引擎渲染数据,以提高对3D场景和物理规律的理解。英伟达(Nvidia)的研究科学家和人工智能代理专家Jim Fan推测,Sora很可能是在合成数据上接受训练的,例如虚幻引擎5的超逼真渲染,而不仅仅是真实视频。这也意味着我们可以看到这些视频环境变回3D世界,并为Vision Pro或Quest头戴式设备实时生成虚拟或游戏环境。
电影制作。Sora模型有望改变电影制作的传统流程,为电影行业带来创新和变革。1)可能会降低传统电影制作的成本,因为它减少了对物理拍摄、场景搭建、特效制作等资源的依赖;2)可能创造出属于自己的电影类型,独特的风格和形式;3)个人创作者和小型团队也能够制作出具有专业水准的视频内容,这可能会催生新的电影制作风格和流派,增加电影市场的多样性;4)实时视频生成能力可以用于现场直播、虚拟现实(VR)和增强现实(AR)等领域;5)在科幻、奇幻等类型的电影中,Sora可以用于生成复杂的特效场景,如模拟物理现象、创造虚拟角色等,提高制作效率并降低成本;6)可以根据观众的喜好和反馈生成定制化的视频内容,为电影制作提供更加个性化的解决方案;7)可能会引发关于版权和知识产权的新讨论,特别是在内容原创性和版权归属方面。
广告。与电影类似,成本的下降预计是非常显著的。与此同时,广告创意人员可以利用Sora快速测试不同创意,加速创意实现过程,无需进行昂贵的前期制作。此外,Sora使个人和小团队也能制作专业水准的视频广告,可能催生新的广告风格和流派。
自动驾驶。Sora模型将显示精准度和效率提升十分显著,并具备更丰富的理解能力。对于机器人核心,视觉信息占据70%的比例,因此对家庭服务机器人和陪伴机器人等具有较大提升价值。特斯拉在自动驾驶的过程中,一直在解决一个叫感知的问题。这次的Sora也在不断优化数据的感知。
算力。因为模型大小是可以调节的,且并非固定的时间和空间占用密度,故而不能直接用图的对应的token数和帧数以及时间这样去简单放大它的计算量。此外,涉及到OpenAI的大模型竞争对手是否会进行视频训练的预测,和用户量的预测。Sora模型参数量可能约为30亿,在视频生成领域具有巨大的应用前景,预计会有多个类型的模型训练主体加入竞赛:以Stability AI为例,创始人兼首席执行官Emad Mostaque是Stable Diffusion的开发公司之一,该公司领导了扩散模型的开发,认为Sora的工作“证明你几乎可以扩展任何模式”,“该公司现在需要‘获得更多的计算’来竞争并达到这些相同的水平。”用户规模的推测方面,预计所有的B端用户都会使用相关技术。根据彭博社报道,GPT-4经过6个月的测试后正式向公众开放,参考GPT-4,预计Sora或将于8月向公众开放。让我们拭目以待吧。
三、A股映射
此处并非故意留白。
参考文献
https://openai.com/research/video-generation-models-as-world-simulators#fn-25
https://towardsdatascience.com/explaining-openai-soras-spacetime-patches-the-key-ingredient-e14e0703ec5b
Dosovitskiy, Alexey, et al., 2020. An image is worth 16x16 words:Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Mo, S., et al., 2023. DiT-3D:Exploring Plain Diffusion Transformers for 3D Shape Generation. ArXiv. https://api.semanticscholar.org/CorpusID:259341920.
Rombach, R. et al., 2021. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).
全文完
(太难了,不保证理解的准确性)

















